
基于三支聚类的协同过滤推荐方法
2022-04-14 09:19康凯,胡军
郑州大学学报(理学版) 2022年3期
康 凯,胡 军
(1.重庆邮电大学 计算智能重庆市重点实验室 重庆 400065;2.重庆邮电大学 计算机科学与技术学院 重庆 400065)
0 引言
互联网的发展产生了海量的信息,也导致了信息过载[1-2]问题。因此研究人员提出了能自动根据用户的偏好信息将匹配的物品推荐给用户的推荐系统(recommender system,RS)[3]。其中协同过滤推荐(collaborative filtering,CF)算法使用用户和物品的交互信息进行推荐,并在许多领域都取得了很好的推荐效果。协同过滤算法可分为基于用户的协同过滤(user-based CF,UCF)算法和基于物品的协同过滤算法[4]。传统协同过滤算法搜索近邻时需要遍历整个用户空间,算法效率随着数据规模增长而下降,其可扩展性面临挑战[5]。文献[6]首先提出了基于聚类的协同过滤算法,算法使用目标用户所在的聚类簇替代全体用户空间,从而有效缓解可扩展性问题,但是预测评分精度不高。
为此,陆续有学者对聚类算法在推荐中的应用进行了研究,其主要目标是在保持聚类推荐算法的可扩展性优势的同时提高推荐精度。文献[7]提出了一种填充空白评分项的推荐算法,算法在填充后的评分矩阵上使用基于物品聚类的协同过滤算法进行预测,实验证明该算法可以提高预测评分精度。文献[8]通过对不同聚类簇的用户间的相似度添加不同的惩罚措施,并使用新的相似度产生预测评分,实验表明预测精度相比于传统协同过滤算法有所提升。文献[9]认为多次聚类能获得多个聚类结果,选择和目标用户最相似的聚类簇作为近邻搜索空间能提高近邻质量,实验结果表明该算法可以提高推荐精度和在线推荐效率,但聚类成本会增加。文献[10]提出了针对Top-N推荐任务的用户模糊聚类方法,实验表明该方法在精确度等指标上优于使用K-Means的协同过滤算法。文献[11]将模糊聚类与协同过滤结合,对目标用户在所属的所有簇中分别进行预测,将聚合后的评分作为最终的预测评分,实验表明精度优于传统基于聚类的协同过滤算法。文献[12]融合了用户偏好信息对聚类结果进行优化,实验表明推荐精度有所提高。
经过对基于聚类的推荐算法的研究和分析,现有研究按照聚类算法的不同可以分为硬聚类和软聚类算法[7-11,13]。现有聚类推荐算法都是使用单一的聚类规则进行聚类,其在用户的评分数据较少、信息不充足的情况下存在推荐准确率不高的问题。鉴于聚类的结果对发现的近邻质量有较大影响[6,9,11],对聚类环节进行改进就成为提升推荐精度的一种可行方案。基于此,本文提出了一种基于三支聚类的协同过滤推荐方法,并通过实验验证了该方法的有效性。
1 相关知识
1.1 基于用户的协同过滤算法
基于用户的协同过滤算法使用近邻用户对物品的意见在一定程度上预测目标用户的意见。常用的预测评分计算方法为


1.2 三支聚类
在信息不充足的情况下,人们往往会采取不同的策略进行决策,三支决策正是这样的策略方法。而推荐和聚类都可以视为决策的过程,已经有学者将三支决策用于优化推荐成本[14-15]。
近年研究表明三支聚类[16]在不完整数据上聚类准确度超过了传统聚类。通过将三支决策思想应用到聚类中,可将聚类簇分为三个区域,即核心域(Co(Cm))、边界域(Fr(Cm))和外部域(Tr(Cm))。核心域的用户完全属于该簇,外部域的用户完全不属于该簇,边界域的用户部分属于该簇,且可能同时属于多个簇。对不确定归属的用户采用的决策规则为
Tr(Cm)可以通过对Co(Cm)∪Fr(Cm)求补集得到,因此使用{Co(Cm),Fr(Cm)}就能刻画一个簇。
1.3 样本密度及距离
文献[17]提出了一种快速寻找到密度峰值点聚类(clustering by fast search and find of density peaks,DPC)算法,通过计算样本i的局部密度值ρi和距离值δi,绘制决策图后可以发现潜在的聚类中心。本文经过分析后认为决策图还可以区分聚类簇边缘的离散样本。本文使用文献[18]提出的改进方法计算为
其中:ρi为样本i的密度值;δi为样本i的距离值;dij为样本i与j之间的欧氏距离。样本点i与属于Neighbor(i)的样本距离越近,ρi越大,一般Neighbor(i)的大小取值为数据集规模的1.5%。
2 基于三支聚类的协同过滤推荐
现有的聚类推荐算法在面对信息丰富程度不同的样本时依然采用单一聚类算法进行划分,因此聚类结果易受到干扰。同时有些用户的评分过少,直接在原始数据上进行聚类的结果往往不够准确。
对图1所示的模拟数据为例进行聚类,可以看出位于中间区域的样本①、②难以确定归属,而其他样本则可以确定所属的簇。因此若能先对确定归属的样本进行聚类,并对不确定的样本延迟决策,则可以提高聚类结果准确性。
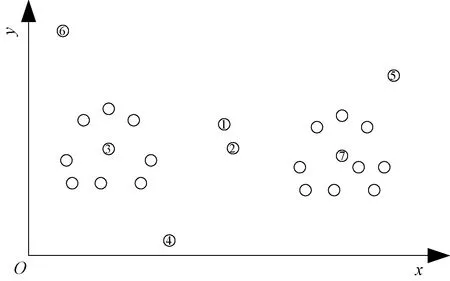
图1 模拟数据Figure 1 Artificial data
基于上述分析,为提升基于聚类的协同过滤算法的推荐精度,本文提出了基于用户的三支聚类方法,并在此基础上实现了一种协同过滤推荐方法。如图2所示,方法分为线下聚类和线上推荐两部分。线下聚类环节中,使用三支聚类算法对用户进行聚类;线上推荐环节中,在目标用户所在的簇中寻找最近邻,计算目标用户对目标物品的预测评分。

图2 基于三支聚类的协同过滤推荐方法Figure 2 Collaborative filtering recommendation method based on three-way clustering
2.1 三支用户聚类
推荐系统评分数据集的用户评分数据稀疏度高,特别是数据集中不同用户的评分数量相差较多,对评分数目过少的用户进行预测推荐的依据是不充足的。为此,先对用户进行划分,再进行聚类。
2.1.1用户划分规则 1)将全体用户中评分数量低于某个阈值的用户划分到边界用户fringes。
评分数据中每个用户的评分数量各不相同,提供给推荐系统的信息充足程度也不同,因此应首先考虑对信息更充足的用户先聚类,阈值选取为10。
2)使用1.3节介绍的方法计算每个用户的密度值ρu和距离值δu,并寻找到潜在的密度峰值点c;随后将用户划分到fringes或cores,划分规则为
其中:u为待划分的用户;cores为核心用户;fringes为边界用户。

图3 模拟数据上的DPC决策图Figure 3 Decision graph of DPC on artificial data
文献[17]指出,密度值ρu越低表示其周围的邻居数量较少,距离值δu越低则表示其不是密度峰值样本。图3为图1的决策图,从图1中可看出样本自动形成两个簇,位于中间区域的样本则需要确定所属的簇。根据密度值ρu和距离值δu的物理含义,可判断出图3中区域1的样本更可能会被划分到核心域,而区域2的样本更可能被划分到边界域。
依据2)将样本①、②、④、⑤、⑥划分到边界域中,样本③和⑦作为聚类中心,这与我们的直观印象是符合的,说明了划分规则的有效性。
2.1.2三支决策规则 由于边界用户fringes中的用户信息不充足,使用传统聚类方法划分可能出现误分类。因此考虑对fringes用户采用三支决策规则决定一个用户的归属。在三支决策中,用户可能被划分到某一个簇的核心域,也可能被划分到某一个或多个簇的边界域。具体划分规则如下。
1)计算用户u的邻居分布在各个簇的比例,该值也用来度量用户对边界域的隶属度,
其中:P(u|Cm)表示用户u的邻居中属于Cm的比例;Neighbor(u)为目标用户u的前λ个最近邻居;Cm为三支用户聚类算法第2步核心域聚类后的第m个簇;Co(Cm)为Cm的核心域。实验中λ取值过大或过小都不利于样本的分配,本实验中取值为10。
2)结合三支决策,使用P(u|Cm)值作为划分的参考依据。划分规则为
其中:Co(Cm)为第m个聚类簇Cm的核心域;Fr(Cm)为Cm的边界域;U为全体用户集合;α和β为基于三支决策的用户聚类算法的一对阈值参数。
针对稀疏评分数据的用户聚类算法,如算法1。
算法1基于用户的三支聚类算法
输入:训练集U,聚类簇数目N,三支决策阈值α和β,三支决策近邻数目λ。
输出:三支聚类结果C。
Step1 数据划分 按2.1.1节的划分规则,将训练集U划分为两个互补子集,即核心用户cores和边界用户fringes;
Step2 核心用户聚类 对cores用户调用K-Means算法,聚类结果即为聚类簇的核心域;
Step3 边界用户划分 按2.1.2节将fringes用户分配到已有簇的核心域Co(Cm)或边界域Fr(Cm)。
2.2 预测评分


图4 评分聚合示意图Figure 4 The fusion of prediction scores
具体计算方法为
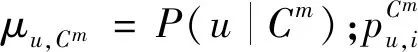
3 实验方法及结果
3.1 实验设计
为验证本文提出的基于用户的三支聚类协同过滤推荐方法的有效性,设计了对比实验,参与对比的实验算法有:基于用户的协同过滤算法(UCF)、基于K-Means用户聚类的协同过滤推荐算法(UCCF(K-Means))、基于模糊用户聚类的协同过滤推荐算法(UCCF(fcm))和本文提出的算法。
实验数据采用MovieLens-100k数据集,包含了943个用户对1 682部电影的100 000条评分数据,评分范围为1~5,分值高低代表喜好程度。采用K-fold交叉验证法将数据集按4∶1比例随机划分为互不相交的训练集和测试集,共产生5组不同的训练集和测试集。
采用的评价指标为平均绝对误差(MAE)和均方根误差(RMSE),计算为
其中:pu,i是用户u对物品i的预测评分;ru,i为测试集中的真实评分;k为测试集评分数量。MAE与RMSE值代表的意义相似,值越低意味着推荐精度越高,并且RMSE还能体现方差大小。
3.2 实验结果
实验采取网格搜索法确定三支决策阈值。首先固定α=0.6,β在[0.1,0.4]区间按步长0.1进行遍历取值,选取合适的β值;随后α在[0.5,0.9]区间按0.1的步长遍历并选取合适的α值。其他参数取值为聚类数目N=3;三支决策近邻数目λ=10;推荐系统近邻数目K=10。综合对比后α和β分别取值0.6和0.2。
随后验证聚类数目N对推荐精度的影响。聚类数目N取值范围为[2,6],其他参数不变。实验结果见图5。从整体趋势看,改变聚类簇数目N可以使推荐结果更加精准;但是当N取值过小或过大时,聚类结果都不能达到最符合真实分布的情况。从具体对比看,UCCF(K-Means)和UCCF(fcm)的MAE值随着N增加而降低,N=3时MAE值达到最低,本文算法在N小于4时取得最小值;N达到4之后三种方法的MAE值都持续增加。在相同条件下,UCCF(K-Means)的MAE值最高,本文提出算法的MAE值在三种算法中最低。

图5 MAE随聚类中心数目变化图Figure 5 Effect of cluster numbers on MAE
接着验证近邻数目K的影响。实验参数更改为聚类数目N=3,其他参数不变。实验中K取值区间为[5,20],步长为5。实验结果如图6。从整体趋势看,MAE值呈先下降后平缓趋势,说明随着K的增加,新增的邻居和目标用户的相似度是逐渐降低的,对提升推荐精度作用有限。从不同算法的对比看,K值取5时,各个算法的MAE值比较接近;随着K值增长到10,UCCF(K-Means)的表现最差,其余三个算法有差距但比较接近,本文的算法的MAE值最低;随着K值增大,UCCF(K-Means)、UCF、本文的算法三者之间的差距变大后保持相对稳定,本文的算法的精度依然最高。

图6 MAE随近邻数目变化图Figure 6 Effect of neighbor numbers on MAE
最后为了验证算法的稳定性,我们在划分好的5组训练集和测试集上进行了实验,分别对比了MAE和RMSE指标,近邻数目K=15。实验结果如图7、8。
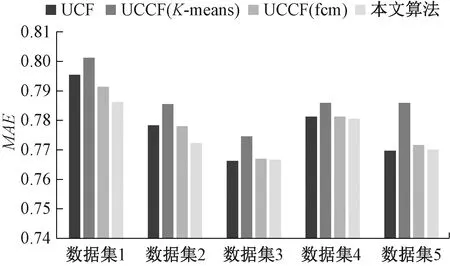
图7 算法在不同数据集下的MAEFigure 7 Comparison of MAE on different datasets

图8 算法在不同数据集下的RMSEFigure 8 Comparison of RMSE on different datasets
从图7可以看出在MAE指标上,UCCF(K-Means)在所有数据集下的MAE值都是最高的;与UCCF(fcm)相比,本文算法的MAE值更低,在2个数据集上有明显下降,另外2个数据集上略有降低;与UCF相比,本文算法的MAE值都不高于UCF的。从图8可以看出,RMSE指标仅在数据集5上略高于UCF的,但仍和UCCF(fcm)的相当,其他情况下优于UCF和UCCF(fcm)的值。
4 结论
本文将三支决策引入到推荐系统的聚类环节,将用户划分为核心用户和边界用户并分别应用不同的聚类规则,避免信息不充足的用户对聚类造成的干扰。实验结果表明提出的方法可以在不使用额外信息的前提下提高推荐预测精度。本文的研究对象是静态数据,后续可将本文的研究思路进一步应用于动态数据。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
机械工业标准化与质量(2022年8期)2022-10-09
北京航空航天大学学报(2022年8期)2022-08-31
南京理工大学学报(2022年1期)2022-03-17
汽车实用技术(2022年4期)2022-03-07
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
领导决策信息(2018年16期)2018-09-27
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
人大建设(2017年10期)2018-01-23
数学学习与研究(2017年3期)2017-03-09
