
基于覆盖的变精度粗糙直觉模糊集模型研究
2022-04-14 09:19薛占熬荆萌萌姚守倩张艳娜
郑州大学学报(理学版) 2022年3期
薛占熬,荆萌萌,姚守倩,张艳娜
(1.河南师范大学 计算机与信息工程学院 河南 新乡 453007;2.“智慧商务与物联网技术”河南省工程实验室 河南 新乡 453007)
0 引言
粗糙集理论[1]是由Pawlak于1982年提出,该理论主要用来处理不确切、不准确等问题,已经广泛应用于人工智能等多个领域[2-4],由于经典的粗糙集具有严格的等价关系,并没有考虑到噪声的影响。针对传统粗糙集的这种局限性,Ziarko[5]提出了变精度粗糙集,通过设定一个参数值β,将噪声的影响考虑进去,从而使正负域的区间增大,缩小了边界域,给分类提供了更大的容错性。因此,许多学者将它推广到一些更普遍的应用领域。Jiang等[6]基于模糊邻域,通过模糊逻辑运算提出了两种基于覆盖的变精度模糊粗糙集。Huang等[7]引入概率集值信息系统的概念,提出了基于巴特查理亚距离的λ-容差关系的扩展变精度粗糙集模型。Yang等[8]提出了一种基于变精度粗糙集最小误分类代价的新模型。为了进一步提高粗糙集的鲁棒性和泛化能力公差关系,Kang等[9]以概念格作为理论基础,提出了一种新的计算粒度公差关系的可变精度粗糙集模型。为了提高分类系统的容错能力,Chen等[10]定义了颗粒包含、变精度邻域逼近集和正区域等概念,并提出了一种变精度邻域粗糙集模型。为了更有效地处理不精确性问题,薛占熬等[11]将模糊变精度粗糙集与多粒度相结合,定义了基于L-模糊近似空间的广义L-模糊可变精度粗糙集中的左下(右下)和左上(右上)近似算子。
模糊集理论[12]是由Zadeh于1965年提出,该理论主要用来描述模糊现象和模糊概念。直觉模糊集(intuitionistic fuzzy sets,IFS)理论[13]由Atanassov于1986年提出,该理论推广了Zadeh模糊集,通过增加一个非隶属度,使之更好地刻画模糊概念,更符合人们的思维过程。因此,引起了国内外学者极大的关注,也取得了一些有意义的成就。Zhou等[14]提出一个基于关系的直觉模糊粗糙近似算子的一般框架。杨倩等[15]利用度量加权的概念把直觉模糊等价关系推广为度量加权直觉模糊优势关系,建立了度量加权直觉模糊序信息系统。Liu[16]提出了一些新的直觉模糊集之间和元素之间相似度的度量方法。薛占熬等[17]针对直觉模糊环境下的三支决策建模问题,综合考虑了决策者的不同风险偏好所引起的阈值变化,提出一种基于前景理论的直觉模糊三支决策模型。张利亭等[18]定义了新的直觉模糊相似关系以及直觉模糊相似关系的截关系,并用直觉模糊相似关系的截关系代替经典决策粗糙集模型中的等价关系,得到一种基于不完备信息系统的直觉模糊三支决策方法。
基于覆盖的粗糙集是对粗糙集的一种拓展,已经广泛应用于多个领域[19-22],成为众多学者们的研究热点。Li等[23]从颗粒的角度给出了两个覆盖之间的尺度关系的定义,并在多尺度覆盖的基础上研究了邻域和近似算子的一些性质,从而构建了基于多尺度覆盖的粗糙集模型。Zhang等[24]将多粒度粗糙集与覆盖概念相结合,提出4种多覆盖粗糙集模型。胡军等[25]从规则置信度出发,建立了一种覆盖粗糙模糊集模型。在大规模覆盖的近似空间中使用集合表示来计算最小和最大描述非常耗时且容易出错,Liu等[26]为了处理这一问题,提出了基于矩阵的覆盖粗糙集最小和最大描述计算方法。Dai等[27]提出一种新的用于不确定度评定的覆盖物偏序,即覆盖粗糙集的不确定度测量。薛占熬等[28]结合直觉模糊集和覆盖概念,提出覆盖粗糙直觉模糊集(covering rough intuitionistic fuzzy sets,CIFS)模型。Wang等[29]提出了一种新的覆盖粗糙集模型不确定性测度——上粗糙熵和下粗糙熵。
近几年,将覆盖粗糙集和变精度粗糙集相结合的研究引起了许多学者的关注,并取得了一些有意义的成果[30-33]。本文在上述研究的基础上,对变精度粗糙集和直觉模糊集的结合进行深入研究。通过设定变精度中的两个约束条件(α,β),将其引入到CIFS模型中,提出基于覆盖的变精度粗糙直觉模糊模型,同时又考虑到元素邻域、规则置信度及元素与最小描述之间的关系,定义了有关该模型的4种类型,并证明了该模型的相关性质,分析了该模型与现有模型之间、以及4种模型之间的关系。其次,在所给模型的基础上重新定义了该模型的近似质量和粗糙性测度。最后,通过实例分析证明所提出的模型在实际应用中的有效性。并改变两个约束条件(α,β)的取值,分析得出α和β较合理的取值范围。
1 基础知识
定义1[34]设U是非空有限论域,C是U的一个子集族。如果C中的所有集合都非空,且∪C=U,则称(U,C)为覆盖近似空间。
定义2[34]设(U,C)为一个覆盖近似空间,对x∈U,称Md(x)={K∈C|x∈K∧(∀S∈C∧x∈S∧S⊆K⟹K=S)}为x的最小描述。
定义3[13]设X为非空集合,A={(x,μA(x),νA(x))|x∈U}称为X上的一个直觉模糊集合。其中μA(x):U→[0,1]表示的是U中元素x属于A的隶属度,νA(x):U→[0,1]表示的是U中元素x属于A的非隶属度,并且满足0≤μA(x)+νA(x)≤1。
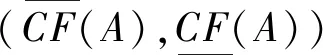
(1)
其中:
我们将该模型称为Ⅰ型覆盖粗糙直觉模糊集模型。

(2)
其中:
我们将该模型称为Ⅱ型覆盖粗糙直觉模糊集模型。

(3)
我们将该模型称为Ⅲ型覆盖粗糙直觉模糊集模型。

(4)
其中:
μ′A(x)、ν′A(x)分别为对象x关于A的模糊覆盖粗糙隶属度、非隶属度,下文类同,不再赘述。
我们将该模型称为Ⅳ型覆盖粗糙直觉模糊集模型。
在这4个模型中,Ⅰ模型的上、下近似隶属度是在包含元素的所有集合中求出最大、最小值,上、下近似非隶属度是在包含元素的所有集合中求出最小、最大值。Ⅱ模型的上、下近似隶属度是在包含某元素的所有集合中求出交集,然后在所求出的交集中选出最大、最小值,上、下近似非隶属度是在包含某元素的所有集合中求出交集,再在所求出的交集中选出最小、最大值。Ⅲ模型的上、下近似隶属度与非隶属度都是在每一个元素与最小描述的集合中求出最大、最小隶属度与非隶属度,最后在所求出最大、最小隶属度与非隶属度的基础上,选出最小、最大隶属度与非隶属度。可以看出,Ⅱ模型相比Ⅰ模型缩小了集合中元素的个数。Ⅲ模型通过加入最小描述,既没有算集合中全部元素,也没有把集合中大部分元素摒弃,使得到的上、下近似介于前两者之间,Ⅳ模型不仅加入最小描述,还考虑到元素与论域中其他元素间的关系,得出的结果清晰,符合实际情况。
2 基于覆盖的变精度粗糙直觉模糊集模型
2.1 基于覆盖的变精度粗糙直觉模糊集的4种模型
定义8设(U,C)为覆盖近似空间,IFS(U)为U上所有直觉模糊集组成的集合,对A∈IFS(U),∀x∈U,令0<α<β<1,P⊆C,上、下近似的隶属度为F1(y),非隶属度为N1(z),则A关于覆盖近似空间(U,C)的Ⅰ型覆盖变精度粗糙直觉模糊集为

α,N1(z)>1-β};
β,N1(z)≥1-α},
(5)
其中:
定义9设(U,C)为覆盖近似空间,IFS(U)为U上所有直觉模糊集组成的集合,对A∈IFS(U),∀x∈U,令0<α<β<1,P⊆C,上、下近似的隶属度为F2(y),非隶属度为N2(z),则A关于覆盖近似空间(U,C)的Ⅱ型覆盖变精度粗糙直觉模糊集为
α,N2(z)>1-β};
β,N2(z)≥1-α},
(6)
其中:


(7)
其中:




(8)
其中:
覆盖近似空间中A的上、下近似的集合是由两个约束条件(α,β)来逼近的,若
则A是可定义的;否则,称A是不可定义的。
定义12在覆盖近似空间(U,C)中,A关于(U,C)的近似质量定义为
(9)
近似质量反映的是下近似所有元素的隶属度之和占整个论域元素个数的百分比。显然,下近似的隶属度之和越大,得到的百分比越高。
定义13在覆盖近似空间(U,C)中,A关于(U,C)的粗糙性测度定义为
(10)
其中:0≤δ(α,β)≤1。
粗糙性测度反映的是边界域所有元素的隶属度之和占上近似所有元素的隶属度之和的百分比。显然,上近似元素中包含的下近似元素个数越多,得到的百分比越低。
定理1设(U,C)为一个覆盖近似空间,A,B∈IFS(U),0<α<β<1,则该模型具有以下性质(以Ⅳ模型为例):


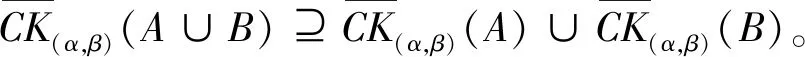
证明:
1)当直觉模糊集A退化为模糊集U时,∀x∈U,μU(x)=1,νU(x)=0,由定义7可知,μ′U(x)=1,ν′U(x)=0,且P(∪Md(x),U)=1;对∀x∈U,
则
同理,对∀x∈U,μφ(x)=0,νφ(x)=1,由定义7可知,μ′φ(x)=0,ν′φ(x)=1,且P(∪Md(x),φ)=0;对∀x∈U,
则
2)因A⊆B,对于∀x∈U,有μA(x)≤μB(x),νA(x)≥νB(x),μ′A(x)≤μ′B(x),ν′A(x)≥ν′B(x)。则有关A的上、下近似隶属度与非隶属度有4种情况,如下所示:


以下仅对①这一情况进行证明。

则
对∀x∈U,P(∪Md(x),A)≤P(∪Md(x),B),
因此
所以

因
故
μA(x)≤μ′B(x),μ′A(x)≤μB(x)。
则
对∀x∈U,P(∪Md(x),A)≤P(∪Md(x),B),
因此
所以
因
故
νA(x)≥ν′B(x),ν′A(x)≥νB(x)。
则
对∀x∈U,P(∪Md(x),A)≤P(∪Md(x),B),
因此
所以
则
对∀x∈U,P(∪Md(x),A)≤P(∪Md(x),B),
因此
所以
类似可以证明其他3种情况,略。
综上
3)将A∩B⊆A,B代入式(2),
得
即
同理
4)将A,B⊆A∪B代入式(2),
得
即
同理
2.2 基于覆盖的变精度粗糙直觉模糊集模型的分析
对覆盖变精度粗糙直觉模糊集模型与现有模型之间的关系进行分析讨论。分为以下几种情形。

退化为
进而退化为
其中:
情形2设(U,C)为覆盖近似空间,当α=0,β=1时,即没有变精度的出现,则该模型退化为覆盖粗糙直觉模糊集。即
退化为
情形3当没有覆盖存在时,即此模型中的近似空间(U,C)退化为Pawlak近似空间(U,R),那么U的划分U/R={[x]R|x∈U}便构成了U的覆盖,∪Md(x)即为[x]R,此时,该模型退化为变精度粗糙直觉模糊集。即
退化为
其中:

退化为
退化为
2.3 4种覆盖变精度粗糙直觉模糊集模型的关系
本节主要说明4个模型之间存在的相互联系,具体关系如下。
定理2设(U,C)为覆盖近似空间,当所有元素在一个集合中,即只有一个覆盖时,Ⅰ模型和Ⅱ模型相同。
证明:
充分性:假设C有多个覆盖,那么存在x属于U,使|Md(x)|≠1,令A1、A2为Md(x)中的两个元素,并且A1≠A2,则|∪Md(x)|≠|∩Md(x)|,所以P(∪Md(x),A)≠P(∩Md(x),A),即
所以,当有多个覆盖时,Ⅰ、Ⅱ模型中元素所在的集合势必不一样,则两模型不会相同。那么要使两模型相同,则必须只有一个覆盖,这样无论是求元素的交集还是并集,都是这个集合,所以这2个模型没有差别。
必要性:设x属于U,当覆盖C中只有一个集合时,则|Md(x)|=1,所以|∪Md(x)|=|∩Md(x)|,则P(∪Md(x),A)=P(∩Md(x),A),所以有
因此,当覆盖C中只有一个集合时,Ⅰ模型和Ⅱ模型相同。
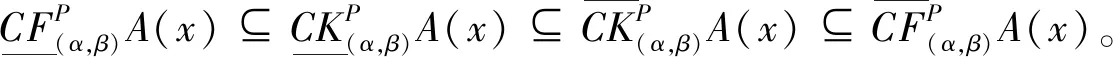
证明:∀x∈U,令
由A中的隶属度与非隶属度可知,q≤μ′A≤Q,r≤ν′A≤R。因q≤μA≤Q,r≤νA≤R,所以有以下4种情况,分别为
1)μ′A≤μA,ν′A≤νA;2)μ′A≤μA,ν′A≥νA;
3)μ′A≥μA,ν′A≤νA;4)μ′A≥μA,ν′A≥νA。
以下对4种情况分别进行讨论。
1)当μ′A≤μA,ν′A≤νA时,
所以
2)当μ′A≤μA,ν′A≥νA时,
所以
3)当μ′A≥μA,ν′A≤νA时,

4)当μ′A≥μA,ν′A≥νA时,
所以
即
由于Ⅲ模型加入了最小描述,所以,当集合中元素个数不是1个的时候,其最小描述是不相同的,即|∪Md(x)|=|∩Md(x)|≠K,所以,无法比较与其他模型之间关系。
3 实例分析
本节通过信用卡申请的实例分析证明Ⅰ~Ⅳ模型在实际应用中的有效性,并用控制变量法验证这4个模型的优越性。通过改变两个约束条件α、β的取值,计算该模型的上、下近似,近似质量以及粗糙性测度,得出α和β的较合理取值范围。
3.1 Ⅰ~Ⅳ模型的实例分析
假设有6个信用卡申请者共组成一个论域U={x1,x2,…,x6},这6个申请者分别由4个专家E1、E2、E3、E4对他们的收入水平进行好(high)、中等偏上(aboveaverage)、中等偏下(belowaverage)、差(low)4个级别的评价,得到的覆盖为
C={high,aboveaverage,belowaverage,low}=
{k1,k2,k3,k4},
k1={x1,x2},k2={x2,x3,x4},
k3={x3,x4,x5},k4={x5,x6}。
high={(x1,0.7,0.2),(x2,0.3,0.6),
(x3,0.5,0.4),(x4,0.2,0.7),
(x5,0.6,0.3),(x6,0.8,0.1)},
Aboveaverage={(x1,0,0.7),(x2,0.2,0.6),
(x3,0.5,0.5),(x4,0.7,0.2),
(x5,1,0),(x6,0.6,0.3)},
Belowaverage={(x1,0,0.6),(x2,0,0.9),
(x3,0.6,0.2),(x4,0.3,0.6),
(x5,0,0.9),(x6,0,0.7)},
low={(x1,0,0.8),(x2,0.1,0.8),
(x3,0,0.9),(x4,0,0.6),
(x5,0.7,0.1),(x6,0.8,0.1)}。
解:分别用Ⅰ型、Ⅱ型、Ⅲ型和Ⅳ型来求出覆盖变精度粗糙直觉模糊集的“high”上近似和下近似、近似质量以及粗糙性测度,分3步进行计算。
1)由最小描述定义知:
2)由定义7,求出A的隶属度与非隶属度:
μ′A(x1)=0.5,μ′A(x2)=0.43,μ′A(x3)=μ′A(x4)=
0.4,μ′A(x5)=0.53,μ′A(x6)=0.7。
ν′A(x1)=0.4,ν′A(x2)=0.48,ν′A(x3)=ν′A(x4)=
0.5,ν′A(x5)=0.38,ν′A(x6)=0.2。
3)设α=0.3,β=0.52。
① 由定义8、定义12和定义13得到Ⅰ模型的上近似、下近似、近似质量和粗糙性测度:
② 由定义9、定义12和定义13得到Ⅱ模型的上近似、下近似、近似质量和粗糙性测度:
③ 由定义10、定义12和定义13得到Ⅲ模型的上近似、下近似、近似质量和粗糙性测度:
④ 由定义11、定义12和定义13得到Ⅳ模型的上近似、下近似、近似质量和粗糙性测度:
从例子中可以很直观地看出4种模型中元素上、下近似隶属度和非隶属度有所不同,并且对元素的近似描述也不相同。但是这4个模型的上近似隶属度与非隶属度值没有太大的变化,究其原因,可以从求解过程中得出,通过设定α、β这两个约束条件,计算出来的结果是Ⅰ、Ⅱ模型的下近似的隶属度和非隶属度几乎没有,是因为这两个模型只是单纯地求元素的并集或交集,再在并集或交集中求出最大或最小值,这样就会导致许多元素被分到边界域。Ⅲ模型用元素与最小描述之间的联系去计算,既没有算集合中全部元素,也没有把集合中全部元素摒弃,这样得出的结果介于前两种模型之间。但是此模型也是单纯地对最小描述中的元素进行求大和求小,所以,算出来的结果也不是很理想。Ⅳ模型不仅考虑到元素与最小描述之间的联系,也把其他元素考虑进去,这样使比较多的元素列入下近似中去,从而算出来的结果较合理,与实际情况接近。
从结果中也可以看出Ⅰ、Ⅱ模型的近似质量是一样的,说明无论是从对象的全邻域还是近邻域去求隶属度和非隶属度,其结果都没有变化。虽然Ⅲ模型近似质量有所增加,但对隶属度与非隶属度也只是单纯地求大与求小,并没有准确地反映实际情况。而在Ⅳ模型中,近似质量有较明显的增大,说明下近似中的元素逐渐增多,符合实际情况。再从这4个模型的粗糙性测度的结果看,前三个模型的值都很高,说明元素被分到下近似的个数很少,而Ⅳ模型所求出的结果相对前三个模型而言,增加了下近似中元素个数,即上近似元素中包含的下近似元素个数变多,符合实际情况。
3.2 模型阈值取值分析
由3.1可知,Ⅳ模型与前3个模型相比,符合实际情况。因此本小节在Ⅳ模型中对α、β的取值范围进行分析。
设论域U={x1,x2,…,x7},U上的一个覆盖C={{x1,x2},{x2,x3,x4},{x3,x4,x5},{x6,x7}},直觉模糊集A={(x1,0.7,0.2),(x2,0.6,0.3),(x3,0.8,0.1),(x4,0.9,0),(x5,0.5,0.4),(x6,0.4,0.3),(x7,0.7,0.1)}。
解:
1)由最小描述定义知:
2)由定义7,求出A的隶属度与非隶属度:
① 当α1=0.1,β1=0.8时:
② 当α2=0.2,β2=0.7时:
③ 当α3=0.3,β3=0.6时:
④ 当α4=0.4,β4=0.5时:
从例子中可以看出,当α1=0.1,β1=0.8与α2=0.2,β2=0.7时,求出来的近似质量为0,粗糙性测度为100%,说明下近似中的元素个数为0,显然不符合实际情况,当α3=0.3,β3=0.6与α4=0.4,β4=0.5时,元素被分到下近似中的个数逐渐增多,元素被分到边界域中的个数逐渐减少,从而符合实际情况。所以,α取值范围在(0.3,0.4),β取值范围在(0.5,0.6)时,该模型符合实际情况。
4 结束语
在覆盖粗糙集理论和变精度粗糙集理论基础上,通过设定变精度中的两个约束条件(α,β),提出基于覆盖的变精度粗糙直觉模糊模型,同时又考虑到元素邻域、规则置信度及元素与最小描述之间的关系,定义了有关该模型的4种类型,证明了此模型的一系列性质,进而研究了此模型与现有模型之间的关系以及4种模型之间的相互关系。接着定义了基于覆盖的变精度粗糙直觉模糊集模型的近似质量和粗糙性测度。最后实例分析证明该模型的有效性,并分析得出α和β较合理的取值范围。
猜你喜欢
聊城大学学报(自然科学版)(2022年5期)2022-10-29
农业工程学报(2022年7期)2022-07-09
北京大学学报(自然科学版)(2022年2期)2022-04-09
闽南师范大学学报(自然科学版)(2022年1期)2022-03-28
电子技术与软件工程(2019年8期)2019-07-16
智富时代(2018年1期)2018-03-26
智富时代(2018年1期)2018-03-26
数学教学通讯·高中版(2017年3期)2017-04-17
海峡科技与产业(2016年11期)2016-12-26
数学学习与研究(2016年22期)2016-12-23
