
基于犹豫模糊相似的网络正能量推荐算法研究
2022-04-13 11:36臧振春李洁璐王美琦王娜娜
运筹与管理 2022年3期
臧振春, 李洁璐, 王美琦, 王娜娜
(1.周口师范学院 数学与统计学院,河南 周口 466001; 2.河南财经政法大学 计算机与信息工程学院,河南 郑州 450046; 3.河南财经政法大学 河南经济研究中心,河南 郑州 450046)
0 引言
当前,网络正能量在中国特色社会主义社会建设中逐渐被重视。何家华[1]将“网络正能量”定义为通过互联网工具和媒介所传播的积极向上、富有正义、乐观进取、感恩奉献等具有感染力和号召力的精神和力量。胡江伟[2]指出有效传播网络正能量是主流媒体展示党和政府执政能力的一种途径,也是媒体凝心聚力实现中国梦的重要方略。赵可金等[3]将正能量传播与中美关系联系在一起分析正能量对国家与外交的影响。孙莉等[4]通过分析正能量文字总结和谐语言类型,研究正确话语类型对网络正能量传播的意义。
针对犹豫模糊相似和推荐,学者们已有若干相关的研究成果。犹豫模糊相似的研究中,王森[5]等人将基于模糊评分的项目相似度与基于标签隶属度的项目相似度融合在一起形成新的项目相似度用于推荐。郭耿[6]提出一种基于改进模糊相似度的舆情演化规则,实验得出模糊观点的类型对舆情演化的周期与规模有影响的结论。胡悦[7]通过模糊神经网络和改进的粒子群优化算法对模糊神经网络的参数进行优化。Zhan等[8]使用一个向量来基于项目的特征在多个维度上测量用户相似度,提高了推荐系统的预测精度。Qian[9]提出了一种基于二分网络投影的概率犹豫模糊推荐决策方法。崔春生[10]从推荐系统中的推荐对象角度出发分析了用户的兴趣度指标及其取值方法。
本文针对网络正能量的语言与传统犹豫模糊评价性特点,结合这两种属性的评价因素,分别对不同属性的评价因素的算子特点计算其熵值从而得到因素权值,再结合不同距离公式与评价专家组对网络正能量的评价理想值计算备选网络正能量推荐组与其的距离,从而得到两者相似度,并根据不同相似值分级对备选事件进行推荐相关决策。在数值实验中也表明了该方法具有良好的推荐效果。
1 相关理论
定义1[11]定义A={
定义2[12]定义下标对称的语言术语集为S={sp|p=-τ,…,-1,0,1,…,τ}。其中,τ为正整数,s0表示中间性评估,其余的对称分布在s0两边。s-τ和sτ为语言变量的上下界。则S满足以下条件:
(1)如果α>β,则sα>sβ;
(2)存在否算子neg(sα)=s-α,特别地,neg(s0)=s0。
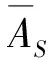
(1)EF(AS)=0,当且仅当∀c∈C,r(hs(c))={0}或者r(hs(c))={1};
(2)EF(AS)=1,当且仅当∀c∈C,r(hs(c))={0.5};
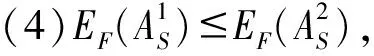
称EF(AS)为语言犹豫模糊集AS的模糊熵。
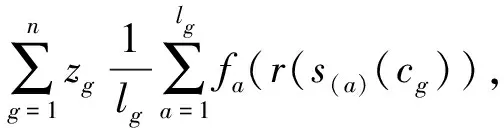
g(s(l-a+1)(cg)))]
(1)
其中zg为正实数,令fa:[0,1]×[0,1]→[0,1]满足:
(1)∀x,y∈[0,1],fa(1-x,1-y)=fa(y,x);
(2)fa(0,0)=0;
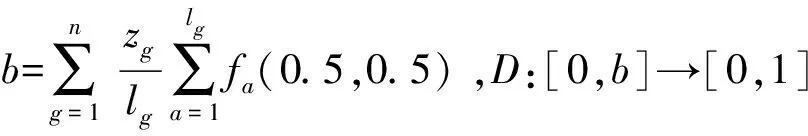

(1)E(h)=0当且仅当h={0}或h={1};
(2)E(h)=1,即h模糊性最高,当且仅当h={1/2};
(3)E(h)=E(hc);

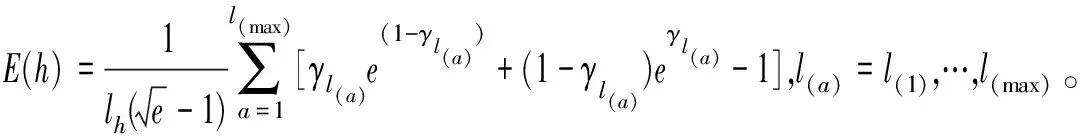
定义5[18]假设A1和A2为同一属性集的两犹豫模糊集,A1和A2的距离测度记为d(A1,A2),则其满足以下性质:
(1)0≤d(A1,A2)≤1;
(2)d(A1,A2)=0当且仅当A1=A2;
(3)d(A1,A2)=d(A2,A1);
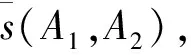
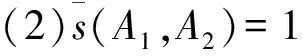
由定义可知,
(2)
经典的距离公式有Hamming距离和Euclidean距离,在此基础上,又发展出了犹豫模糊Hausdorff距离公式,设wj为cj对应的权重:
(3)
犹豫模糊Hausdorff距离能够较准确的对比两两犹豫模糊集的距离。
2 网络正能量推荐算法的实现
2.1 数据处理
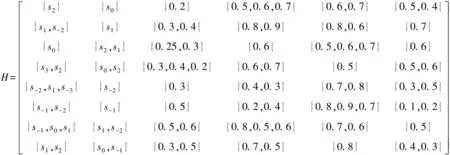
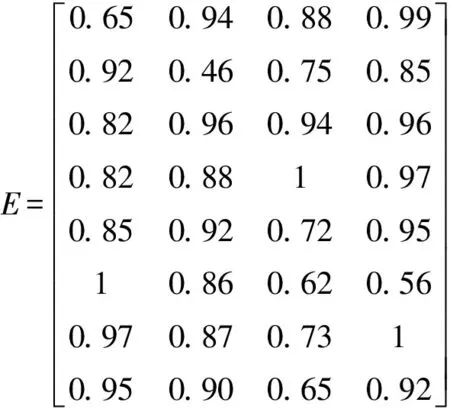
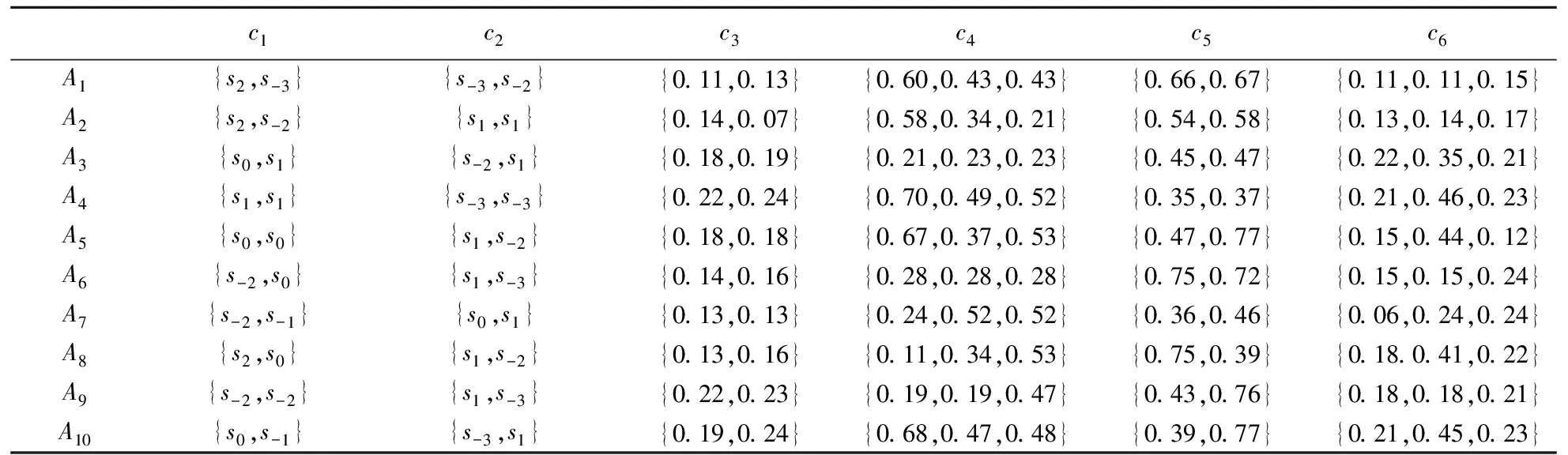
设待评价网络事件集为A={a1,a2,…,ai,…,am},网络正能量的犹豫模糊综合评价属性集为C={c1,c2,…,cj,…,cn},且集合中存在n1(n1 S={s-3=最低,s-2=一般低,s-1=稍低, s0=中,s1=稍高,s2=一般高,s3=最高} (4) 事件ai的各属性归属犹豫模糊集可综合记为Ai: (5) 在已有的关于数值犹豫模糊数据标准化的研究中,大多应用乐观法则和悲观法则两种方法[18]。由于要推荐的用户所要看的是网络正能量的新闻,可认为此用户为乐观型用户,本文中我们通过乐观法则对数据进行标准化。 令初始犹豫模糊评价矩阵为H: (6) hS={s(1),s(2),…,s(l)} (7) 其语言犹豫模糊评价集为HS;再令Ai″,i=1,…,m中所有犹豫模糊元的最大长度为lmax,分别在满足l hA*={γl(1),γl(2),…,γl(max)} (8) 其数值犹豫模糊评价集为HA″。 标准化后的评价矩阵记作M: (9) 设hS(cg)为语言犹豫模糊评价集中任一标准化后的犹豫模糊元,s(a)为语言犹豫模糊评价集hS中的语言术语元素,令语言犹豫模糊评价熵为: (10) 通过熵最小化原则,定义语言犹豫模糊评价属性的熵权计算公式: (11) 设hA″(ct)为数值犹豫模糊评价集中任一标准化后的犹豫模糊元,γl(a)为数值犹豫模糊元hA″中的第a小的元素,经定义4验证,数值犹豫模糊评价熵公式为: [γl(a)e(1-γl(a))+(1-γl(a))eγl(a)-1] (12) 同理,数值犹豫模糊评价属性熵权公式定义为: (13) 设语言犹豫模糊评价属性权重集为: (14) 数值犹豫模糊评价属性权重集为: W″={w″n1+1,…,wn″} (15) 则最终综合属性权重集为: W={w1,…,wn1,wn1+1,…,wn} (16) 其中,ɑ+β=1。一般地,ɑ=β=0.5。 首先通过Python获取网络正能量事件各属性的犹豫模糊理想值,记作: (17) (18) 则相似度公式可定义为: (19) 设置相似度的分段标准E: E={<[0,0.4],不推荐>,<(0.4,0.8], 一般推荐>,<(0.8,1],优先推荐>} (20) 易知,事件网络正能量相关性排序为: 优先推荐事件≻一般推荐事件≻不推荐事件 (21) 推荐算法综合实现步骤如下: 步骤1经咨询专家和调研结果得到犹豫模糊语言评价集和数值评价集,规范语言术语集S形式并整合为初始犹豫模糊评价矩阵H,并分别标准化语言犹豫模糊集和数值犹豫模糊集得HS和HA″,规范化后的评价矩阵M; 步骤2分别计算语言犹豫模糊元的熵Eig(HS)和数值犹豫模糊元的熵Eit(HA″),依次计算不同属性集的分权重集W′和W″; 步骤3计算属性集的综合权重集W; 步骤5定义各事件与理想值的相似度分段标准E,根据推荐阈值做不推荐,一般推荐或优先推荐决策。 在日常生活中,人们生活中在手机中获取的信息数不胜数,由于人们对信息不敏感,所以如何在人们得到信息之前对信息进行筛选就成了首要问题,本文根据网络正能量的特征将筛选网络正能量的影响因素分为6点:c1:敏感煽动性,c2:政府可控性,c3:传播途径广泛率,c4:评论互动率,c5:积极/消极的关键词率,c6:涉及不同范围词率。其中,c1和c2为语言评价集,分别描述事件的传播速率和政府管控程度,c3,c4,c5,c6为数值评价集,分别从传播途径效率,大众关注度,直观描述的正向性和关注人群分散度出发来对事件进行评价。在本节应用中,我们首先根据近期不同时段新闻选取八个热点事件作为推荐备选方案,并由专家组分别对不同影响因素做出评价:事件A1:我国绝对贫困人口全部脱贫;事件A2:离婚冷静期提议通过; 事件A3:民法典的诞生;事件A4:我国首支火星探测器“天问一号”抵达火星;事件A5:中印冲突;事件A6:中央督察组到地方车牌泄露;事件A7:“熟鸡蛋返生”论文被下架;事件A8:严查偷税漏税。 步骤1经调研与专家组评价集整合得初始犹豫模糊评价矩阵为: 利用公式(7)和(8)分别对语言犹豫模糊评价集和数据犹豫模糊评价集进行标准化,得到公式(9)形式的评价矩阵为: 步骤2根据公式(10)计算出语言犹豫模糊元的熵为: 同理,Ei2=1.99。 根据公式(12)计算出数值犹豫模糊元的熵为: 同理可求得其余犹豫模糊元熵值,E23=0.92,E33=0.82,E43=0.82等。 数值型犹豫模糊元的熵集可整合为: 根据公式(11)计算语言犹豫模糊集的不同属性的分权重集 步骤3根据公式(16)可得综合权重集W=0.5W′∪0.5W″={0.25,0.25,0.11,01.3,0.18,0.08}。 步骤4通过Python对热点新闻进行整合处理,选出其中10个正能量新闻,收集专家对每个属性的评分,得到标准化后的犹豫模糊集如表1所示。 表1 标准化的犹豫模糊评价集 选取正理想解作为正能量的犹豫模糊标准值,则: 用公式(18)计算出事件A1与专家评价网络正能量理想值的距离为: =(0.25×02+0.25×0.22+0.11×0.042+0.13×0.22+0.18×0.152+0.08×0.282)=0.16 同理得: d(A,A8)=0.22 步骤5由公式(20)可知 优先推荐事件为:A1 一般推荐事件为:A8,A3,A4,A7,A2,A5,A6 由公式(21)综合相似度值,可以得出推荐顺序为A1≻{A8,A3}≻A4≻A7≻A2≻A5≻A6 文章通过计算交叉熵确定属性权重,根据距离确定每个事件的相似度来明确网络正能量进行推荐,最后通过实例验证及结果分析证明了模型有效性,即其存在良好的应用前景。但在模型建立过程中,评价因素仅考虑到了语言术语隶属度和数值隶属度,没有考虑到存在其他数据集的情况,也缺少推荐对象的个体性分析,在未来研究中,将着重研究网络正能量推荐中存在的多种数据集形式,并拓展研究适用于更多数据集的推荐算法。
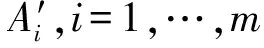
2.2 权重的确定
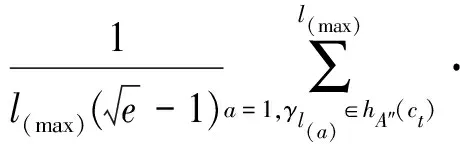
2.3 相似度计算
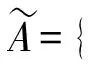
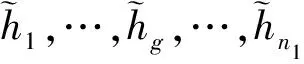
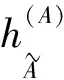
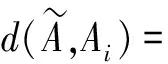
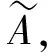
3 网络正能量推荐实例
3.1 网络正能量实例描述
3.2 推荐算法应用
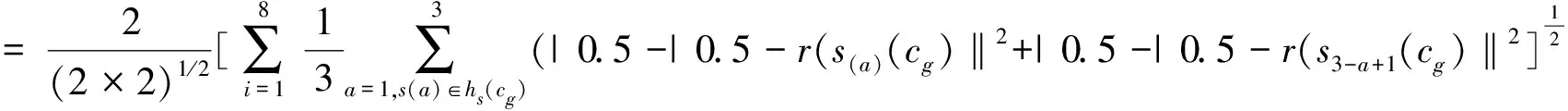
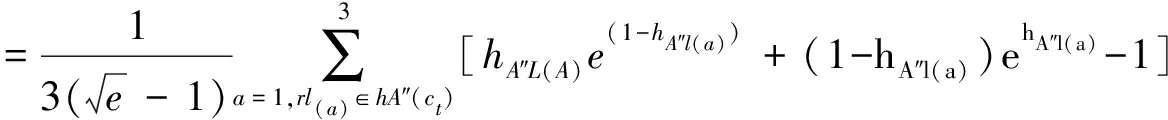
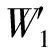
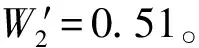

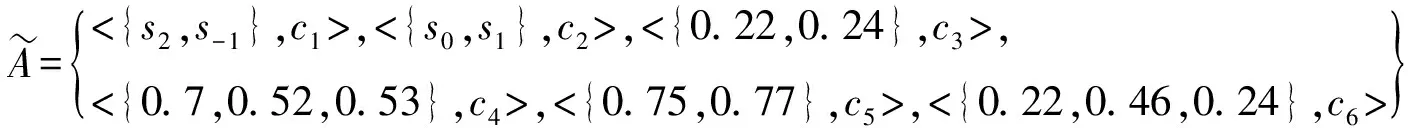
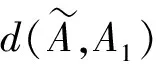

4 结论与展望
猜你喜欢
北华大学学报(自然科学版)(2022年4期)2022-08-17新高考·高二数学(2022年3期)2022-04-29新高考·高二数学(2022年3期)2022-04-29煤气与热力(2022年2期)2022-03-09中学生数理化·高一版(2021年11期)2021-09-05中央财经大学学报(2021年8期)2021-08-30数学大世界(2021年4期)2021-03-30舰船科学技术(2021年12期)2021-03-29舰船科学技术(2021年12期)2021-03-29火力与指挥控制(2020年7期)2020-08-22
