
基于信息截断的低复杂度多进制LDPC码译码器
2022-04-11 10:43王瑞雪陈为刚
信号处理 2022年3期
王瑞雪 陈为刚
(天津大学微电子学院,天津 300072)
1 引言
低密度奇偶校验(Low-Density Parity-Check,LDPC)码以其优异的纠错性能被广泛应用于5G 移动通信[1-2]和卫星通信[3-4]等领域。定义在伽罗华域GF(q=2p)(p>1)的多进制LDPC 码的纠错能力明显优于其对应二进制形式[5],但其译码算法的硬件实现复杂度较高,限制了它在实际场景中的应用。
多进制LDPC 码的译码算法分为软判决译码算法和硬判决译码算法,软判决译码算法如扩展最小和(Extended Min-Sum,EMS)[6-7]、网格EMS(Trellis EMS,T-EMS)[8]、最小最大(Min-Max,MM)[9]和网格MM(Trellis MM,T-MM)[10-11]等在校验节点更新时需要利用信道中的软信息来搜索满足奇偶校验方程的符号,计算复杂度较高。相比较之下,硬判决译码算法只需要在校验节点更新中对有限域元素进行简单的校验和运算,使得计算复杂度低,消耗存储资源少,但其译码性能存在恶化现象。因此,硬判决译码算法适用于信道条件好,要求硬件实现复杂度低的系统。主要的硬判决译码算法有大数逻辑可译码算法(Majority-Logic Decodable Algorithm,MLDA)[12-14]和广义比特翻转译码算法(Generalized Bit-Flipping Decoding Algorithm,GBFDA)[15]。
MLDA 对低码率码译码时性能较好,但是随着码率的增加纠错性能会下降。GBFDA 是一种适用于高速率码的译码方法,该算法定义了可靠性矩阵,对于速率高且列权重小的码,可实现更准确的解码并获得更好的纠错性能。基于比特翻转译码算法,文献[16]中提出了可多比特翻转的并行化方法,且其性能逼近最小和译码算法。基于GBFDA,研究者又提出增强串行广义比特翻转译码算法(Enhanced Serial GBFDA,ES-GBFDA)[17]并进行硬件实现。在译码过程中对数似然比(Loglikelihood Ratio,LLR)的值可能会超过其量化比特数,因此,GBFDA 和ES-GBFDA 均需要控制LLR 值增长的操作,例如裁剪操作[18],即当一个元素的大小大于其量化位数可表达的最大值时,将该元素所在的列减去一个常数。文献[19]中的裁剪操作通过串行处理来实现,但每次迭代所需时钟周期数需乘上q,造成较大延迟。文献[17]中的裁剪操作通过并行处理来实现,由于每个符号的裁剪信息必须与其他符号共享,因此增加了路由拥塞。简化增强串行广义比特翻转译码算法(Simplified ES-GBFDA,SESGBFDA)[20]在初始化时将所有符号的LLR 值减去最可靠符号对应的LLR 值,避免了裁剪操作,并且不会对频率或延迟造成不利影响。ES-GBFDA 对多进制LDPC 码译码需存储校验节点更新得到的每个符号的次数,即“投票”数,用于计算变量节点的外信息,因此会消耗较多的存储资源。为降低存储需求SES-GBFDA 仅用一个比特来量化“投票”数,从而使存储量减少了45%,同时引入了0.05 dB 的性能损失。
为进一步降低多进制LDPC 码译码器实现的存储需求和计算复杂度,本文提出一种基于信息截断的译码算法,即截断SES-GBFDA(Truncated SESGBFDA,T-SES-GBFDA)。该译码算法仅利用每个符号所对应的q个LLR值中有限的t个值进行译码,从而降低译码器实现的存储需求。进一步,针对所提出的译码算法设计了部分并行的译码器架构,在变量节点的处理中仅使用t≪q个并行的基本更新单元代替文献[20]中所使用的q个基本更新单元来完成变量节点矢量消息的处理,具有较低的计算复杂度。基于现场可编程门阵列(Field Programmable Gate Array,FPGA)平台的译码器实现结果表明,提出的多进制LDPC 码译码器以较小的性能损失和吞吐量的降低换取了硬件资源消耗的显著降低,因此所设计的译码器适用于硬件实现复杂度要求低,但吞吐量要求不高的通信场景中。
2 截断简化增强串行广义比特翻转译码算法(T-SES-GBFDA)
为降低多进制LDPC 码译码器的存储需求和计算复杂度,本文基于SES-GBFDA提出将可靠性信息截断的T-SES-GBFDA,接下来介绍该算法的具体流程,为了方便算法的描述,首先对算法中所用到的符号进行说明。
定义在伽罗华域GF(q=2p)(p>1)上的多进制LDPC 码(N,K),N为码字符号长度,K为信息符号长度,其校验矩阵HMN为M行N列,其中hmn表示校验矩阵中第m行n列的元素,校验矩阵中校验节点的度为dc,变量节点的度为dv。假设信息序列采用二进制相移键控(Binary Phase Shift Keying,BPSK)调制,并使调制后的信息序列经过加性高斯白噪声(Additive White Gaussian Noise,AWGN)信道,将在接收端接收到的序列定义为y=(y1,y2,…,yN),其中yn=(yn,0,yn,1,…,yn,p-1)代 表GF(q) 上 的(Ln(0),Ln(1),…,Ln(2p-1))。R(nj)表示在第j次迭代一个域元素。第n个符号的LLR值表示为Ln=中,从校验节点传递到变量节点n的GF(q)上的元素。表示在第j次迭代中,从变量节点n传递到校验节点的GF(q)上的元素。表示在第j次迭代中,变量节点n相关联的t(t≪q)元组,该元组中的元素为非负整数,并由GF(q)上的元素En,i(1 ≤i≤t)索引,索引为En,i的分量表示变量节点n为域元素En,i的可靠性度量。是一个标志矩阵,表示在第j次迭代中,变量节点n相关联的t元组,其成分是0 或1,并由GF(q)上的元素En,i(1 ≤i≤t)索引;若校验节点更新的符号为Rn,则将由符号Rn索引的矩阵置1,代表校验节点对符号Rn进行了“投票”,其余符号对应的矩阵置0。则T-SES-GBFDA译码算法可以表示为:
1)初始化
①截断初始消息向量及对应域元素
首先计算初始消息向量L={L1,L2,…,LN}中第n(1 ≤n≤N)个符号的LLR值Ln=(Ln(0),…,Ln(2p-1)),其中Ln(z),z∈{0,1,…,2p-1}的计算公式如下所示,
其中,z∈GF(q),zmax为最可靠的符号,zmax,l为符号zmax转换为二进制后第l+1 个比特。对数似然值的计算将Ln(z)归一化为最可靠的符号,以避免使用裁剪操作来控制中的数据增长。当被量化为Qb比特时表示的最小值和最大值分别为和,最可靠的符号可以从0增长到,也就是说最多可以获得次投票。然后将Ln降序排列
其中En,i表示第n(1 ≤n≤N)个符号的LLR 值降序排列后排在第i(1 ≤i≤q)个位置上的域元素。最后将初始消息向量及对应域元素进行截断,即
其中1 ≤t≤q-1。
②参数赋值
其中1 ≤n≤N,1 ≤i≤t,j为迭代次数,m为 行索引。
2)迭代译码,在以下步骤中1 ≤n≤N,1 ≤i≤t
其中GFmax是在1 ≤i≤t时求解外信息最大时所对应的域元素。该步骤首先计算t个域元素对应的外信息,然后计算t个外信息中的最大值,并选择外信息最大值对应的域元素作为截断操作的采用使该步骤不需计算所有域元素的外信息并比较大小,只需要计算t个域元素对应的外信息并进行比较,因此将该步骤的计算复杂度由O(q)降低为O(t)。
②计算校正子s
③计算校验节点候选项Rn
⑤更新m,m=m+1,如果m=M则进行下一步,否则返回执行步骤①。
⑥更新j,j=j+1,如果j=Itmax则进行下一步,否则令m=1,并返回执行步骤①,其中Itmax为最大迭代次数。
3)译码判决
其中1 ≤n≤N,1 ≤i≤t,GFmax是在1 ≤i≤t时求解中最大值所对应的域元素。由图1 所示的多进制LDPC 码译码信息传递示意图可知,对LLR 值及其对应域元素截断后,变量节点需要处理的信息长度由q减短为t,变量节点和校验节点之间的信息传递没有变化。
针对定义在GF(32)上,码长为837 个符号,码率为0.85,准循环校验矩阵H124,837校验节点度dc和变量节点度dv分别为27 和4 的多进制LDPC 码,使用T-SES-GBFDA 进行迭代译码,最大译码迭代次数Itmax设置为10。图2 为将LLR 截断为不同长度后进行译码的误帧率(Frame Error Rate,BER),由图可知,当截断长度为20时,基本无性能损失;当截断长度为16 时,在FER 为10-3处,有0.05 dB 的损失;当截断长度为10 时,在FER 为10-3处,有0.16 dB 的损失;当截断为7时,性能损失很大且较早的出现误码平台问题。
图3 为将LLR 截断为10 并量化为不同比特时的比特错误率(Bit Error Rate,BER),在BER 为10-5时,将LLR 截断为10 并量化为6 比特与未量化相比,BER 性能损失约为0.15 dB,量化为5 比特与6 比特时两者的BER 性能差距不大,量化为4 比特时性能损失较大,因此我们不考虑4比特的量化。
表1 总结了SES-GBFDA 和所提出的译码算法每次迭代所需要的计算复杂度,在译码判决过程中只需进行整数比较且其计算复杂度与迭代过程中的整数比较相同,其中r=dc×M=3348 表示校验矩阵中非零元素的个数。SES-GBFDA 算法和TSES-GBFDA 算法进行10 次迭代译码并进行译码判决的操作总数分别为2744120 和961310,其中TSES-GBFDA 算法的截断长度t取10。与SESGBFDA相比,我们提出的译码算法计算操作数减少了65%,且性能损失较小。如果未将LLR 及其域元素截断,则译码器所需存储的比特数为q×(Qb+dv)×N,截断后需要存储的比特数为(Qb+dv+p) ×t×N。当t=10,Qb=5 时,截断操作可以将存储量减少51.4%。

表1 两种译码算法每次迭代所需的计算复杂度Tab.1 Computational complexity required per iteration for two decoding algorithms
3 低复杂度译码器硬件实现
3.1 译码器整体架构设计
本文设计的译码器采用T-SES-GBFDA 进行译码,迭代次数设为固定值,在达到最大迭代次数之后直接进行译码判决,不对译码结果进行校验。采用部分并行架构来保证译码器吞吐量,即变量节点和校验节点消息的处理采用并行实现,变量节点和校验节点之间消息传递采用串行实现。令Qb表示量化比特数,Wid=Qb+dv+p表示存储一种域元素相关消息所需比特数。如图4 所示为多进制LDPC 码译码器的整体架构,译码器包括:拼接单元、dc个变量节点处理(Variable Node Processing,VNP)模块、校正子计算单元、dc个校验节点更新(Check Node Update,CNU)单元和校验矩阵存储单元。VNP 模块包括二输入选择器、消息存储单元和变量节点更新(Variable Node Update,VNU)单元。
对译码器整体架构中数据流向进行详细的介绍。拼接单元将第n(1 ≤n≤N)个符号截断后的LLR 值Ln={Ln(En,1),…,Ln(En,t)}及对应域元素En={En,1,…,En,t}与dv个0 进行拼接得到位宽为Wid 的向量Vni=[Ln(En,i),0000,En,i](1 ≤i≤t),并将其按照i=t,…,1 的顺序拼接得到位宽为Wid ×t的向量Vn={Vn7,Vn6,…,Vn1}作为VNP 模块的输入。在VNP 模块中,向量Vn以及向量Fnew共同作为二输入选择器的输入,其中Fnew为VNU 单元对消息存储单元输出的消息向量F更新后的消息向量;将选择器的输出存储在消息存储单元中;VNU单元通过处理消息存储单元的输出向量F和CNU的投票符号Rn得到向量Fnew和新的硬判决符号Qn;dc个VNU 单元的输出Qn1,…,作为VNP 单元的输出。校正子计算单元根据Qn1,…,和校验矩阵存储模块输出的校验矩阵的非零元素计算得到校正子s。dc个CNU 单元根据Qn1,…,、s和校验矩阵存储模块输出的校验矩阵中非零元素的逆元素求解得到dc个校验节点的投票符号Rn1,Rn2,…,
表2统计了译码器译码过程所消耗的时钟周期数,其中N为多进制LDPC 码码字符号长度,M为校验矩阵的行数,Itmax为译码的最大迭代次数,q为伽罗华域的大小。由于初始化过程是将向量Vn存储在消息存储单元中,设定为每个时钟周期输入1 个符号的相关消息,则初始化过程需要N个时钟周期。迭代更新过程按照校验矩阵的行来进行,并且插入了流水线寄存器,在设计的译码器架构中,VNP 模块以及CNU 单元的一次更新消耗5 个时钟周期,则译码迭代过程需Itmax×M× 5 个时钟周期。为充分利用资源在译码判决过程中直接利用VNP模块来完成,此时译码判决是dc路并行执行,因此所消耗的时钟周期数是块循环矩阵的大小q-1 再加上两个延迟(消息存储单元的输出延迟和流水线寄存器),即为q+1个时钟周期。

表2 译码过程所需的时钟周期数Tab.2 The number of clock cycles required for the decoding process
3.2 消息存储单元设计
消息存储单元的作用是存储译码过程中多进制LDPC 码N个符号的Wn、Wmn以及域元素En,该模块包括地址生成器和RAM。RAM 的深度为q-1,将LLR 截断后需要存储一个符号的t个域元素相关的消息,每个域元素相关消息包括Wn(En,i)、Wmn(En,i)以及该域元素En,i(1 ≤i≤t),需要的比特数为Wid,则对一个符号t个域元素相关消息的存储需要Wid ×t比特,因此RAM 的宽度为Wid ×t。图5 展示了第一个消息存储单元的RAM 中存储内容分布,E1,1为第1 个符号中最可靠的域元素,Wn(E1,1)为域元素E1,1对应的LLR值,Wmn(E1,1)为域元素E1,1对应的投票标志矩阵;En,i为第n个符号中第i可靠的域元素,Wn(En,i)为En,i对应的LLR值,Wmn(En,i)为域元素En,i对应的投票标志矩阵。则dc个RAM 所需存储的总比特数为Wid ×t×(q-1) ×dc。
3.3 VNU单元设计
VNU 单元对外信息Wn-βWmn的值进行排序,以找到最可靠的符号作为新的硬判决符号Qn,并对Wn和Wmn进行更新。另外,在译码判决阶段,为降低硬件资源的消耗,对VNU 单元中的资源进行重复利用,将投票标志矩阵Wmn置0,并根据dc个RAM 中存储的Wn进行译码判决,此时VNU 单元只用来对译码结果进行判决,不对向量F更新。VNU 单元的电路结构如图6所示,包含串并转换单元、投票定位单元、t个基本更新(Basic Update,BU)单元、并串转换单元以及比较网络单元。VNU 单元的输入为RAM 输出的向量F和CNU 单元投票的符号Rn,输出为更新后向量Fnew和硬判决符号Qn。
串并转换单元将向量F转换为向量Fi=[Wn(En,i),Wmn(En,i),En,i](1 ≤i≤t),其转换方式为Fi=F[(i+1) × Wid -1:i× Wid]。
投票定位单元通过将符号Rn与域元素En,i(1 ≤i≤t)的值进行比较来确定t个域元素的位置使能sym_seli(i=1,…,t),作为BU 单元中Wn(En,i) 和Wmn(En,i)更新的使能。若Rn=En,i,则将第i个域元素的位置使能sym_seli置1,其余域元素的位置使能置0;如果域元素En,i(1 ≤i≤t)中没有与符号Rn相等的域元素,则将所有域元素的位置使能置0。sym_seli=1 代表CNU 单元“投票”了第i个域元素。文献[17]所设计的VNU 单元中将符号Rn分别与q个域元素对比并生成q个域元素的位置使能,在我们所设计的VNU 单元中,只需要将符号Rn分别与t≤q个域元素进行对比并生成t个域元素的位置使能即可,可显著降低所需比较器和寄存器的数目。
t个BU 单元的作用是分别计算t个域元素中不同元素En,i(1 ≤i≤t)关联的外信息Wn-βWmn并对Wn(En,i)和Wmn(En,i)进行更新。相比于文献[16,19]的VNU 单元中需要q个BU 单元,我们提出的电路结构仅需要t(t<<q)个BU 单元来完成,将VNU单元的计算复杂度由O(q)减少至O(t)。BU 单元的电路结构如图7 所示,其中变量节点的度dv=4;Ui=[Wn(En,i),Wmn(En,i)](1 ≤i≤t),Uinew为Ui经 过BU 单元更新后的向量;dv_sel 为变量节点使能,其值为“00”、“01”、“10”和“11”分别表示此时更新的为第1、2、3、4 个变量节点。对Wn(En,i)的更新:当sym_seli为0时,选择器M0选择Wn(En,i)作为输出;当sym_seli为1时,若选择器M0选择Wn(En,i)+1 作为输出,否则选择器M0选择Wn(En,i)作为输出。Ui[0]、Ui[1]、Ui[2]、Ui[3]分别代表第1、2、3、4 个校验节点是否对此符号进行投票。对于选择器M1的参数β表示假设在先前迭代中收到的投票数,此处我们采用文献[20]中的值,即β=2。BU 单元中的减法器为有符号数的减法,因此其输出为Qb+1 比特,其功能是计算符号Rn对应的Wn(En,i)-βWmn(En,i)的值。对Wmn(Eni)的更新:使用投票更新单元对Wmn进行更新,即对Ui[3:0]的更新,其更新取决于sym_seli和dv_sel,当dv_sel分别为“00”、“01”、“10”和“11”时,分别将Ui[0]、Ui[1]、Ui[2]、Ui[3]的值替换为sym_seli的值。拼接单元将更新后的Wn(En,i)和Wmn(En,i)进行拼接得到向量Uinew。
比较网络单元的作用是对t个域元素对应的外信息进行比较,并选择外信息最大值对应的域元素作为当前节点的硬判决符号Qn,采用文献[21]中提出的一个最小值查找器的电路架构。图8 为对7 个域元素进行比较的比较网络单元的电路结构,其中选择量化比特数为Qb=5,有限域p=5,则比较网络单元的位宽为Qb+p+1=11,输入的前Qb+1=6 位是后p=5 位所代表符号的LLR 值。所设计的比较网络单元将7 个输入分为三级比较,包括6 个二输入选择器和6 个比较器,其功能是对7 个值进行比较,并输出最大值以及最大值对应的域元素。图中每个输入的前六位为一个种域元素对应的外信 息Wn(En,i)-βWmn(En,i),后五位为其对应的域元素En,i。
3.4 校正子计算单元和CNU单元设计
CNU 单元根据校正子s、校验矩阵中非零元素的逆元素和变量节点的符号Qn来计算满足校验节点可靠性更高的符号Rn,用来翻转下次迭代中变量节点的硬判决符号Qn。dc个CNU 单元首先用dc个有限域乘法器将校正子s分别与相乘,然后采用dc个有限域加法器将相乘的结果分别与Qn1,…,相加得到校验节点的投票符号Rn1,…,当校正子s=0 时,CNU 单元根据该校正子计算的投票符号Rn=Qn;当s≠0 时,CNU 单元根据该校正子计算得到投票符号Rn≠Qn用来翻转变量节点硬判决符号Qn。
3.5 校验矩阵存储单元设计
校验矩阵存储单元用来存储校验矩阵中的非零元素以及非零元素的逆元素。对于随机的校验矩阵,不仅需要存储矩阵中的所有非零元素,还需要存储矩阵中的所有非零元素所在的位置。随机的校验矩阵比规则的校验矩阵所构造的多进制LDPC 码的译码性能更好,但存储随机校验矩阵中非零元素的位置会消耗较多的存储资源,因此本文采用准循环校验矩阵。校验矩阵存储单元包括地址生成器和ROM,图10 为校验矩阵中元素在ROM 中的存储分布,ROM 的位宽为dc×p,深度为2M,其中hmn1,…分别代表校验矩阵HM×N的第m行中第1,…,dc个非零元素分别代表校验矩阵HM×N的第m行中第1,…,dc个非零元素的逆元素。将校验矩阵中第i行的非零元素依次存储在ROM 偶数地址中,将校验矩阵中第i行的非零元素的逆元素依次存储在ROM 奇数地址中。
4 硬件实现结果及分析
本设计在Xilinx Virtex-VI XC6VLX240T 的FPGA 上实现,完成了定义在GF(32)上,码长为837个符号,码率为0.85,准循环校验矩阵H124,837的dc和dv分别为27和4的准循环多进制LDPC 码译码器的实现,在译码器的实现中LLR 值截断长度t为10,量化比特数Qb为5。
经过统计得到译码器在FPGA上实现的BER曲线如图11 所示。在BER=10-4处,硬件性能仿真比软件浮点仿真差0.25 dB。造成这种差距的主要原因是定点运算的精度损失以及对软信息的截断处理。
表3 统计了使用ES-GBFDA、SES-GBFDA 和TSES-GBFDA 等译码算法实现译码器的综合结果,表中多进制LDPC 码的码长和码率相似,因此它们之间的资源可以进行比较。由于我们提出的T-SESGNFDA 算法是基于ES-GBFDA 和SES-GBFDA 译码算法进行的改进,因此我们对这三种译码器消耗的硬件资源与达到的吞吐量进行了比较。与文献[17]中的ES-GBFDA 译码器相比本文所实现的译码器查找表和寄存器资源分别减少了82%和79.3%,但是吞吐量仅是其20.5%。与文献[20]中的SES-GBFDA 译码器相比本文所实现的译码器查找表和寄存器资源分别减少了64.5%和76.3%,但是吞吐量仅是其12.6%。文献[17,20]使用分布式RAM 存储中间消息,减少了读出中间消息的延时,使吞吐量有较大的提高,但是消耗了较多的查找表,本文使用Block RAM 来存储中间消息,显著降低了查找表的消耗,但是Block RAM 有读出时延,因此吞吐量较低。表3中吞吐量的计算方法如式(10)所示,其中Th 表示译码器的吞吐量(单位为Mbps),N代表一个LDPC 码码字的符号数,p为伽罗华域GF(2p)中2的阶次,f为译码器可以达到的最大频率(单位为MHz),Ldec代表一个码字译码结束所需消耗的时钟周期数。
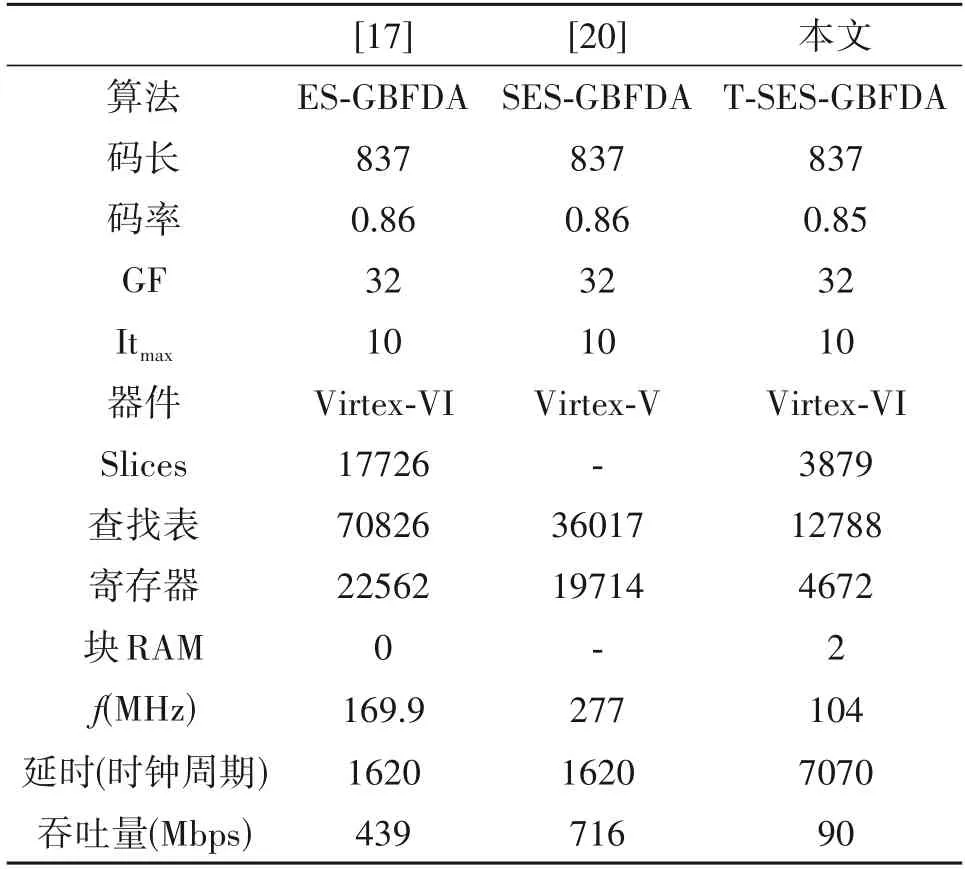
表3 多进制LDPC译码器综合结果Tab.3 Synthesize results for non-binary LDPC decoder
从图3 可看出,所提出的译码方法在信噪比为5.2 dB、截断长度为10、量化为5 比特时的BER 达到了4×10-6,所实现的译码器架构,在104 MHz 时达到了90 Mbps 的吞吐量,消耗的查找表和寄存器资源较少,适用于无线通信系统,例如:DVB-S2 和IEEE 802.11 n 等,接下来我们还可以通过使用分布式RAM 代替块RAM 来减少每次消息向量的读出延迟,进一步提高其吞吐量,使其适用于光通信。
5 结论
针对多进制LDPC 码译码器实现复杂度较高的问题,提出了面向SES-GBFDA算法的初始化信息截断的T-SES-GBFDA 算法,从而有效降低复杂度。进一步,基于所提出译码算法设计了低复杂度部分并行译码器的电路结构。对于定义在GF(32)上的多进制LDPC 码,仅使用10 个基本更新单元来处理变量节点消息的更新,显著降低了计算复杂度。在FPGA 平台实现了设计的译码器架构,实现结果表明,与SES-GBFDA 译码器相比,所提出译码器的吞吐量达到90 Mbps,并且查找表和寄存器资源消耗分别减少了64.5%和76.3%,适用于吞吐量要求不高并且要求硬件实现复杂度低的通信系统中。所提出的译码器在译码性能损失较小的情况下,在性能与复杂度之间实现了良好折中。
猜你喜欢
深圳大学学报(理工版)(2022年5期)2022-09-27
中学生学习报(2022年15期)2022-04-17
沈阳工业大学学报(2021年6期)2021-11-29
机电工程技术(2021年3期)2021-09-10
现代电子技术(2021年7期)2021-04-08
现代计算机(2021年36期)2021-03-14
电脑知识与技术·经验技巧(2017年9期)2018-02-24
海峡姐妹(2017年10期)2017-12-19
三联生活周刊(2017年33期)2017-08-11
银行家(2017年1期)2017-02-15
