
基于词向量空间模型的机器翻译质量评价分析
2022-04-02 11:12:50陈柯柴启栋
中国科技术语 2022年2期
关键词:机器翻译
陈柯 柴启栋
摘 要:文章从问题意识视角出发,以石油术语为基础,引入词向量空间模型的方法展开三个相关实验对机器译文和人工译文进行对比研究,探索机器翻译结果在空间模型中的演绎和呈现。实验结果显示机器翻译对于石油术语的语言翻译准度能达到0.403。文章尝试结合计算机技术、语言学和翻译学等不同领域量化论证两种翻译结果在语义层面的接近和靠拢程度,以期探索评价分析机器翻译系统输出结果质量的新途径。
关键词:机器翻译;向量空间模型;石油术语;语义相似度
中图分类号:H085;H083;TP391 文献标识码:A DOI:10.12339/j.issn.1673-8578.2022.02.003
Abstract:From the perspective of problem awareness, this paper conducted an indepth terminology analysis on machine translation and manual translation by training vector space model. Three experiments were performed by the means of training the vector space model to compare the results of machine translation. These experiments demonstrate the similarity between machine translation and manual translation is 0.403. Integrated with computer technology, linguistics and translation, this paper focuses on the semantic similarity between machine translation and manual translation that aims to blaze a new way for results evaluation of machine translation.
Keywords:machine translation; vector space model; petroleum terms; semantic similarity
收稿日期:2021-05-26 修回日期:2021-09-24
基金项目:陜西省2021年外语学科专项课题项目(2021ND0624);西安市2021年社会科学基金重点项目(WL78)
引言
随着计算机科学技术、语言学、逻辑学和信息学等相关学科的一体化发展,机器翻译研究无论在理论层面还是工程实践层面都已经积累了丰富的经验[1],机器翻译方法完成了从基于规则的翻译方法到基于统计的翻译方法再到神经网络机器翻译方法的转变[2]。作为国内较为流行的在线机器翻译平台,有道翻译为我们带来极大便利。但有道翻译作为机器翻译的典型代表能否准确完善地处理垂直学科领域科技语言翻译任务以及机器翻译质量评价等问题仍值得深入研究。但是,已有的机器翻译结果质量分析大多是横向对比,鲜有研究对一种机器翻译软件进行纵向的深入探究分析。本文从问题意识角度出发,以石油术语为语言分析基础,借助词向量空间模型的方法开展术语语义范围界定、翻译结果空间模型追踪和文本相似度对比实验与结果分析,依照从局部到整体的思路设计三个分实验,着重关注机器翻译系统对特定学科语言在语义层面的处理和翻译能力。
1 相关研究论述
机器翻译是利用计算机实现从一种自然语言转换为另一种或多种自然语言文本的过程[2]。它涉及语言学、计算机科学、数学等多个学科,是一门交叉学科。目前对机器翻译结果的分析研究主要涉及译文质量评价。译文质量评价的途径有很多种,最流行的有“打分法”和“统计法”等方法[3],有不少学者使用类似方法对不同在线翻译平台译文进行质量评价。其中,罗季美[4]利用统计分析法在汽车技术文献翻译方面对人工译文和机器译文进行了细致对比,将机器译文错误细化分类。杨玉婉[5]以文本《潜艇水动力学》为基础,利用Google和腾讯翻译对文本进行英汉和汉英翻译后评价译文质量。蔡欣洁和文炳[6]以外宣文本汉英翻译为例测试了四种不同的在线翻译平台,发现了翻译结果的一些共性问题,并根据译文质量对四种在线翻译平台的可接受度进行排序。也有学者利用量化评测的方法对机器译文进行评测。Almahasees[7]利用BLEU自动测评指标对Google和Bing机器翻译结果进行译文质量评测。Benková等[8]结合人工测评和BLEU自动测评等指标对Google和European Commissions MT tool基于两种机器翻译方法——统计机器翻译(SMT)和神经网络机器翻译(NMT)——进行质量评测,结果显示在新闻文本英语对斯洛伐克语的翻译表现上NMT性能较为突出。
上述机器翻译结果评价分析大多是不同翻译软件的横向对比,即以一种文本作为输入得到不同版本的译文,在不同版本译文之间横向对比正误率和错误类型。这样的研究方法虽然能快速高效地分析出不同版本译文之间的异同,但也存在局限,如参照标准相对模糊、未能量化机器翻译评价过程等。因此,本研究尝试结合计算机技术、语言学和翻译学为一体,提出一种新的纵向机器翻译结果质量评价方法,探索机器翻译质量评价新的途径。
2 研究思路与方法
2.1 研究问题
(1)有道翻译结果语义层面与初始信息的接近程度。
(2)石油术语在向量空间模型中的描绘与表示。
2.2 研究方法gzslib202204031124本实验采取定量分析和定性分析相结合的研究方法。首先选取一定数量石油术语,以全国科学技术名词审定委员会公布的《科学技术名词·工程技术卷·石油名词》[9]中的翻译作为标准翻译,以有道翻译结果作为对照翻译。然后大量收集石油相关领域的语料,语料清洗后利用Word2vec进行词向量模型训练并保存。然后,将上述标准翻译和对照翻译分别嵌入到向量空间模型中,借助向量空间模型描绘不同单词的意义,分别开展术语语义范围界定、翻译结果空间模型追踪和文本相似度对比实验,量化探究有道翻译对原始信息的保留程度。
2.3 数据收集
从《科学技术名词·工程技术卷·石油名词》和《石油工业概论》[10]中提取400条常见英语石油类术语分类归纳并转换为txt格式。利用有道翻译软件收集对比样本,将有道英汉翻译结果分类归纳为txt格式,进行数据清洗和加工。收集石油相关领域语料建模并保存,借助Python等软件进行数据导入和处理,并且进行结果描述和分类研究。
3 模型构建
3.1 语料获取与预处理
首先找到一些国内石油领域的caj格式的论文及相关领域的pdf格式的书籍,批量地将caj和pdf格式语料转化为txt文件,成功转化的文件有7103个,获取字符2 819 107个。因为原始文本是caj和pdf特殊格式,在语料转化过程中会有空格、标点符号、断句、连词的问题出现,所以删除过滤所有的空格、标点等无效字符,得到1 814 455个有效字符。借助Python工具包对所得中文语料进行分词和去停用处理后获取石油领域840 000个有效分词,将有效分词转为txt文件并保存。
3.2 模型构建及初始参数设置
使用Word2vec对整个语料集进行了预训练,分别训练了50维、100维和150维的词向量。在三个模型的训练中维度size分别为50、100和150,sg等于1,窗口window选择默认值5,随机采样的配置阈值sample为1e3,迭代次数iter为2。为了让收集的罕见词在最大程度上得到预训练,min_count设置为3。语料训练得到三个不同维度的模型,分别为word2vec_50.model、word2vec_100.model和word2vec_150.model,最终比较实验结果和权衡计算速度,选取了100維的向量作为全局向量空间模型的嵌入。
4 实验分析与结果讨论
4.1 机器翻译结果语义范围界定与分析
词向量是用来表示词语的向量,也被认为是词的特征向量,把词语映射为实数域值的过程叫作词嵌入。向量空间模型是一种广泛应用于信息检索的模型,具有利用空间相似性来逼近语义相似性的优点[11]。度量语义相似性的方法实际上被映射为向量相似性的度量[12],也就是对于需要计算语义相似性的两个词可以转化为多维向量空间中的数值形式以便于计算和整理。语义范围界定实验加载上述利用石油领域单语语料训练的向量集合word2vec_100进行词嵌入作为背景向量,再将有道翻译结果和标准翻译分别编码转化为输入向量,使这些向量能较好地表达和计算不同词之间的相似和类比关系。在实验预处理方面我们对文档做一定的降维处理以提高模型准确度。
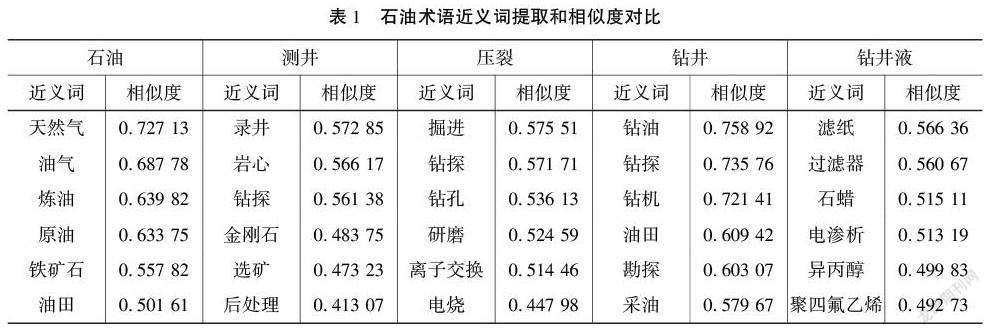
选取若干个常用石油术语的标准翻译编码转换为向量数值形式输入,按照其相似度的数值降序提取语义范围内意义最为接近的的词语,通过判断提取的词语是否覆盖机器翻译结果来测量两种翻译结果语义层面的叠加程度,界定两种翻译结果的语义范围。近义词提取对应的距离数值在[0, 1]区间内,越接近于1,代表两个词语越相近,语义相关性越强;反之,代表两个词语语义距离越远。在此,选取典型的石油术语整理列举如表1:
借助预训练模型word2vec_100提取部分石油术语的近义词和相似度,通过样本对比分析,发现部分石油术语的有道翻译结果偏离甚至超出其相似度范围,这说明了有道翻译结果与标准翻译的语义叠加范围较小,也反映了两者之间语义层面上的差异程度较大。接下来利用模型可视化工具对翻译结果做进一步探讨。
4.2 翻译结果在空间模型中的追踪与对比
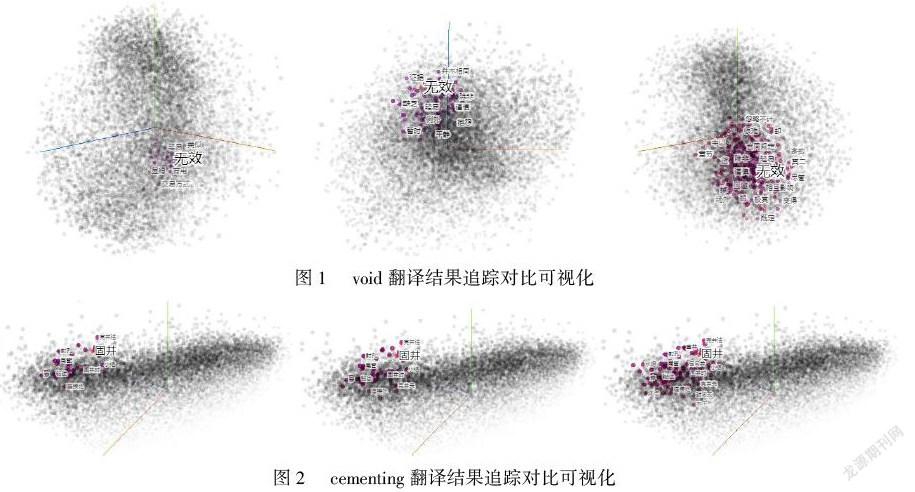
利用模型可视化工具TensorFlow,把预训练模型word2vec_100通过主成分分析(PCA)降维方法映射到低维空间Embedding Projector中,选取一定数量的有道翻译结果作为初始样本输入,逆向观察以有道翻译结果为参照的词语语义相似范围。我们以选取的石油术语carbon residue、gas rock、fault、cementing、void等为例进行对比分析。在石油领域,上述术语的意思分别为:残碳、盖层、断层、注水泥、孔隙;而有道翻译结果为:碳渣、天然气的岩石、缺点、固井、无效。
实验思路:把void的有道翻译结果“无效”呈现在三维可视化的向量空间模型中,以“无效”为中心词,通过收缩中心词周边词汇的范围来不断追踪标准翻译“孔隙”,借助周边词汇数值来量化有道翻译结果和标准翻译结果的距离差值和靠拢程度。实验操作为:首先把void有道翻译结果呈现在向量空间中,把它的周边词汇范围数值设置为100个,结果未追踪到目标词汇“孔隙”;然后把周边词汇范围扩大为150个,也没有发现目标词汇;继续扩大至200个,最终未能找到目标词汇(可视化结果见图1)。以同样的方法,对石油术语“cementing”进行分析后发现把周边词汇范围增加至100个以后能追踪到标准翻译结果(可视化结果见图2)。
模型内追踪对比实验结果说明,在语义范围上,石油术语“void”有道翻译和标准翻译的词汇距离至少为200个,语义相差较大;术语“cementing”的有道翻译结果在空间模型上与标准翻译结果的交汇点至少出现在100个词之后。这说明针对该术语的两种翻译结果存在较远的语义距离。接下来我们从文本相似度的角度继续开展实验论证有道翻译对于石油术语文本整体翻译的处理能力。gzslib2022040311244.3 有道翻译结果与标准翻译文本相似度分析
文本相似度不仅体现在语言片段组合的似然性,更重要的是反映语言片段所体现的语义吻合度[12],“余弦值”在自然语言处理中被广泛地用于计算词向量的相似性[13]。余弦值的范围在[0,1]之间,值越接近于1说明两个向量的夹角越接近于零或趋于重合,也就意味着这两个向量的相似度越高;反之,相似度越低。
5 结语
本文借助计算机技术从词向量空间模型的方法出发,分别开展了语义范围界定、空间模型追踪和文本相似度对比等具体实验操作对机器译文质量进行量化分析,尝试提出一种从局部到整体的机器翻译质量评价途径,希望能为机器翻译性能提升提供一定的语言分析基础,为译后编辑人员衡量机器译文质量可接受程度提供参照。事实上半个世纪以来,机器翻译无论在理论层面还是实践层面都取得了巨大进步,已经实现从基于规则的翻译方法到基于大规模语料库翻译方法的转变。特别是近年来,随着神经网络的兴起,“深度学习机器翻译”技术是迅速发展的另一个突破点。但本次实验结果证实了机器翻译对于特定垂直学科领域语言翻译效果并不理想,也说明了加强机器翻译错误深层研究和分类学科语料库建设的必要性。本实验也存在一定的局限性,比如语料样本规模小、模型构建不完善等。因此,这也是未来工作方向之一。
参考文献
[1]李沐,刘树杰,张东东,等.机器翻译[M].北京:高等教育出版社,2018:51-53.
[2]POIBEAU T.机器翻译[M].连晓峰,译.北京:机械工业出版社,2019:38-42.
[3]张霄军.翻译质量量化评价研究综述[J].外语研究,2007(4):80-84.
[4]罗季美.机器翻译中的术语错译分析[J].中国科技术语,2013,15(1):41-45.
[5]杨玉婉.神经机器翻译的译后编辑:以《潜艇水动力学》英汉互译为例[J].中国科技翻译,2020(4):21-23.
[6]蔡欣洁,文炳.汉译英机器翻译错误类型统计分析:以外宣文本汉译英为例[J].浙江理工大学学报,2020(44):27-34.
[7]ALMAHASEES Z M. Assessing the Translation of Google and Microsoft Bing in Translating Political Texts from Arabic into English[J]. Int. J. Lang. Lit. Linguist,2017(3):1-4.
[8]BENKOV L,MUNKOVA D,BENKO L,et al. Evaluation of EnglishSlovak Neural and Statistical Machine Translation[J]. Applied Science,2021(11):2-17.
[9]石油名词审定委员会.石油名词(全藏版)[M].北京:科学出版社,1995.
[10]任晓娟,徐波.石油工业概论[M].2版. 北京:中国石化出版社,2015.
[11]沈思,孙豪,王东波.基于深度学习表示的医学主题语义相似度计算及知识发现研究[J].情报理论与实践,2020(5):183-190.
[12]王青,馬萧.问题意识视域下机器翻译质量评估研究[J].湖南社会科学,2020(6):144-151.
[13]冯志伟.词向量及其在自然语言处理中的应用[J].外语电化教学,2019(2):3-11.
作者简介:陈柯(1975—),女,西安石油大学外国语学院教授,硕士生导师,主要研究方向为翻译。先后主持完成全国商科教育科研“十二五”规划课题、陕西省哲学社会科学课题、陕西省“十二五”规划课题、陕西省教育厅课题、陕西省重大理论与现实课题,并连续5年获西安社会科学规划课题资金资助。通信方式:1295242889@qq.com。
猜你喜欢
现代电子技术(2017年6期)2017-04-10 20:38:56
青春岁月(2017年1期)2017-03-14 11:28:47
读与写·下旬刊(2016年12期)2017-02-09 09:04:24
考试周刊(2017年2期)2017-01-19 09:13:50
考试周刊(2017年2期)2017-01-19 09:12:54
智富时代(2016年12期)2016-12-01 17:03:10
科教导刊·电子版(2016年23期)2016-10-31 10:14:04
现代经济信息(2016年10期)2016-05-24 22:55:15
电脑知识与技术(2016年5期)2016-04-14 11:12:38
同济大学学报(社会科学)(2014年1期)2014-07-16 16:28:41
