
基于SqueezeNet和YOLOv2的交通违法证据评价
2022-03-31 03:51刘洪龙李向阳徐正华卢朝晖
南华大学学报(自然科学版) 2022年1期
刘洪龙,李向阳*,徐正华,卢朝晖
(1.南华大学 资源环境与安全工程学院,湖南 衡阳 421001;2.浙江力嘉电子科技有限公司,浙江 绍兴 311800)
0 引 言
图像视频处理是当今计算机应用的重要领域,在交通安全监管领域有着重要应用。交通管理部门的非现场执法系统,针对不同的交通违法行为,识别原理各不相同,有些是基于视觉进行预识别,如不系安全带、驾车打电话等违法行为。
由于大量高清监控设备所监控的区域较大,一张针对特定车辆抓拍的照片中,往往存在多辆无关的车辆。在数据审核中,仅根据照片中特定目标区域图像质量,来决定该照片可否作为车辆的违法证据。如针对不系安全带、驾车打电话的违法行为,前排驾驶员所在区域的图像质量,决定了违法证据的可靠性。
图像质量评价一般分为两大类,主观评价方法和客观评价方法。客观评价方法一般分为,全参考、半参考和无参考三类。全参考和半参考需借助参考图像进行对比,无参考评价方法采用提取统计特征并利用分类器判断失真类型,然后利用对应回归模型估算图像质量[1-5]。
客观评价方法在交通违法证据分类评价中面对整幅图像,关键区域为驾驶员所在小尺度区域,同时缺乏参考图像,实际测试不能得到很好的评价效果。主观评价方法的决策者是人,该种评价方法最准确可靠。近年来随着深度学习在图像识别领域技术的发展,卷积神经网络AlexNet[6]、GoogleNet[7]、ResNet[8]、SqueezeNet等在图像分类任务中取得了较好的成果,目标检测算法以R-CNN、Fast R-CNN[9]、Faster-RCNN、YOLO各类方法在车辆检测中得到广泛应用。YOLO算法经过多次迭代从YOLOv1[10]、YOLO9000[11]、YOLOv3、YOLOv4到YOLOv5,YOLO算法在灵敏度和处理时间上得到了较好平衡。
机器学习应用于实际场景时面临无法获得该领域大量训练数据的主要障碍,除此之外还面临场景数据量小、模型需要强鲁棒性、个性化定制、数据隐私安全等一系列问题[1]。迁移学习是一种新的机器学习范式,即使在没有太多标签数据的场景下,也能够帮助提升模型性能[1]。
本文数据来源于某市公安局交警警察大队,主要针对基于机器视觉的交通违法预判图像,根据不同的违法行为,针对性地提取交通违法预判图像中的关键区域,再对图像关键区域做出质量评价。本文设计了一种SqueezeNet与YOLOv2结合的目标检测网络,提出了一种基于SqueezeNet网络的图像质量主观评价方法。本方法对交警非现场执法系统所抓拍的图像进行预处理,在剔除其中不符合质量要求的违法图像后,再递交工作人员审核,提高违法数据的录用率。
1 YOLOv2与SqueezeNet基本原理
1.1 YOLOv2基本原理
YOLO是一个端到端的目标检测网络[12],能够达到实时的检测效果[12]。YOLOv2网络由输入层、卷积层、池化层、全连接层和输出层组成[13]。YOLOv2借鉴了GoogLeNet思想,采用固定框来预测边界框,引入批量标准化处理,保证了稳定训练与加速收敛[14]。
YOLOv2可检测出目标物体在图像中的矩形边界位置,识别物体类别、给出物体分类与物体位置的置信度[15]。输入图像宽为W,高为H,将其划分为w×h个网格,其中n=W/w=H/h,n为特征检测层分辨率缩放倍数。每个网格中设置B个锚框(包围检测物体的边界框)来检测不同大小的物体,每个锚框预测5个参数,(tx,ty)代表物体中心坐标,(tw,th)表示物体的宽和高,to代表物体的置信度。锚框参数以及置信度计算方式为
bx=σ(tx)+cx,
(1)
by=σ(ty)+cy,
(2)
bw=pw×etw
(3)
bh=ph×eth
(4)
pR(object)×IOU(b,object)=σ(to),
(5)
上式中σ()为sigmoid函数;cx,cy为锚框所在网格左上角坐标;pw,ph为框宽和框高;bx,by,bw,bh为锚框参数,乘特征检测层缩放倍数n可得到检测物体在输入图片中的像素坐标(见图1)。
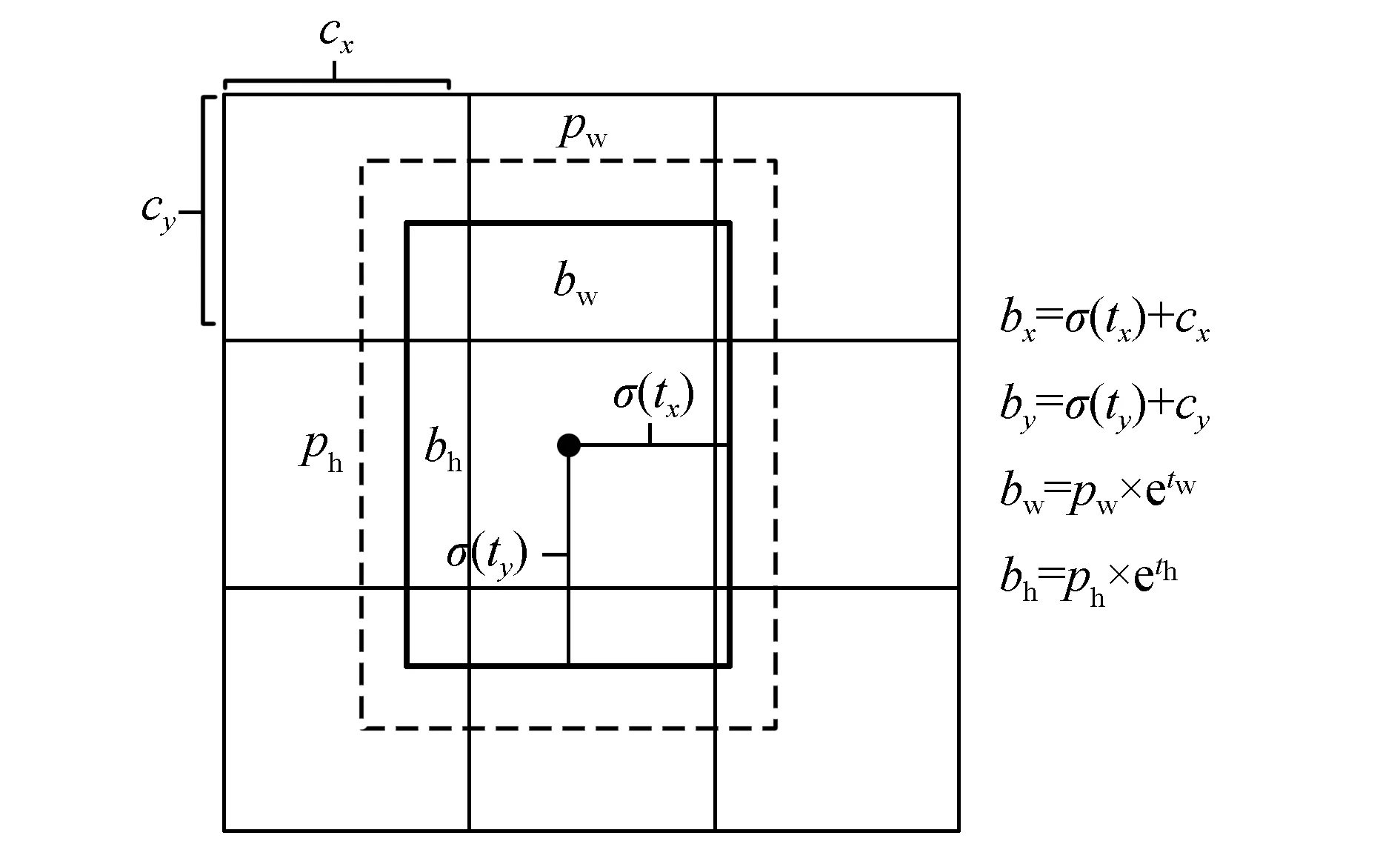
图1 检测物体预测位置Fig.1 Predicted position of detected object
式(5)为检测物体置信度,pR(object)为物体在锚框中的概率,IOU(b,object)为锚框与物体的重合度,即
(6)
本文只检测机动车1类,先利用公式(1)~(6)求出每个检测物体包围边界框参数和置信度。通过pR(object)×IOU(b,object)对所有结果排序,并使用非极大值抑制筛选检测目标获得检测结果。
在训练期间,YOLOv2对象检测网络优化了预测边界框和训练标签之间的MSE(mean-square error)损失[10]。损失函数Loss定义为
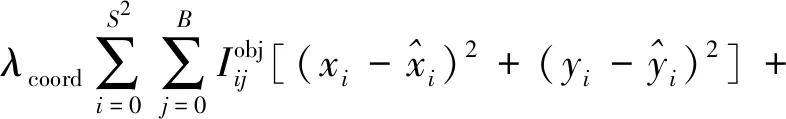
1.2 SqueezeNet基本原理
SqueezeNet由F.N.Iandola等人提出的一种轻量且高效的CNN模型,可以在保证不损失精度的条件下,将原始AlexNet压缩至原来的1/510(<0.5 MB)[16]。SqueezeNet具有模型参数少,对于分布式平行数据训练更加有效[17]等优点。
SqueezeNet的核心是Fire模块,包括squeeze和expand两部分。squeeze采用1×1的卷积核对上一层feature map进行卷积,降低feature map维数。expand包括1×1和3×3的卷积核且expand层卷积核(1×1和3×3卷积核的总数)数量大于squeeze层卷积核数量。SqueezeNet主要包含8个Fire模块,且以卷积层结束(见图2)。
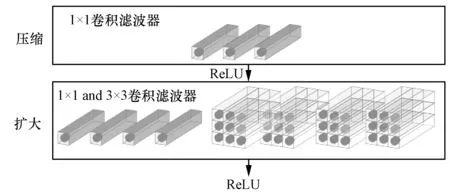
图2 SqueezeNet Fire模块Fig.2 SqueezeNet Fire module
2 交通违法证据评价模型设计
模型准确率的提高对训练样本标签数量有极大依赖性,较少的训练样本会导致模型过拟合。ImageNet数据集远大于交通违法图片样本集,采用迁移学习的方法将ImageNet训练过能识别1 000类物体的SqueezeNet应用到交通违法车辆识别与图像评价中,能够提高模型的泛化能力和防止模型过拟合。深度模型迁移学习有两种为基于特征和基于模型的方法,本文采用一起使用的方式,通过参数共享和微调,再次训练模型以更好地适应目标域。
2.1 特征迁移强化目标识别和提取
本文训练标签数据集为4 000张交通违法预判图像,由于训练集样本数量较少,既要保证机动车检测准确率,也要尽可能加快检测速度,故采用预训练后的轻量级网络模型SqueezeNet来增强特征提取能力。SqueezenNet初始网络深度为18层,通过ImageNet数据库的100多万张图像进行训练,可以将图像分类为1 000个对象类别,具有较强的特征识别能力。
改进后的YOLOv2目标检测网络采用在ImageNet数据库训练后的SqueezeNet网络替换YOLOv2原有骨干网络Darknet-19。该网络在SqueezeNet第2个Fire模块后的最大池化层后增加一个步长为2×2的通道转换层,在SqueezeNet最后一个卷积层(conv10)后的ReLU层融合特征后连接到检测子网。检测子网由两组卷积层、ReLU层、BN层,再加一个卷积层,YOLOv2预测边框转换层和输出层构成。该网络将28×28×128特征转换为14×14×512,和conv10后的ReLU层特征融合为14×14×1 512。该网络融合了高分辨率特征,从而增强了对小尺度目标的检测准确率。此处借鉴YOLOv2 passthrough layer[13]的设计思路,将网络识别准确率提升1%。本文使用改进后的网络检测交通违法车辆,检测违法车辆车窗区域,改进后的YOLOv2网络结构如图3所示。
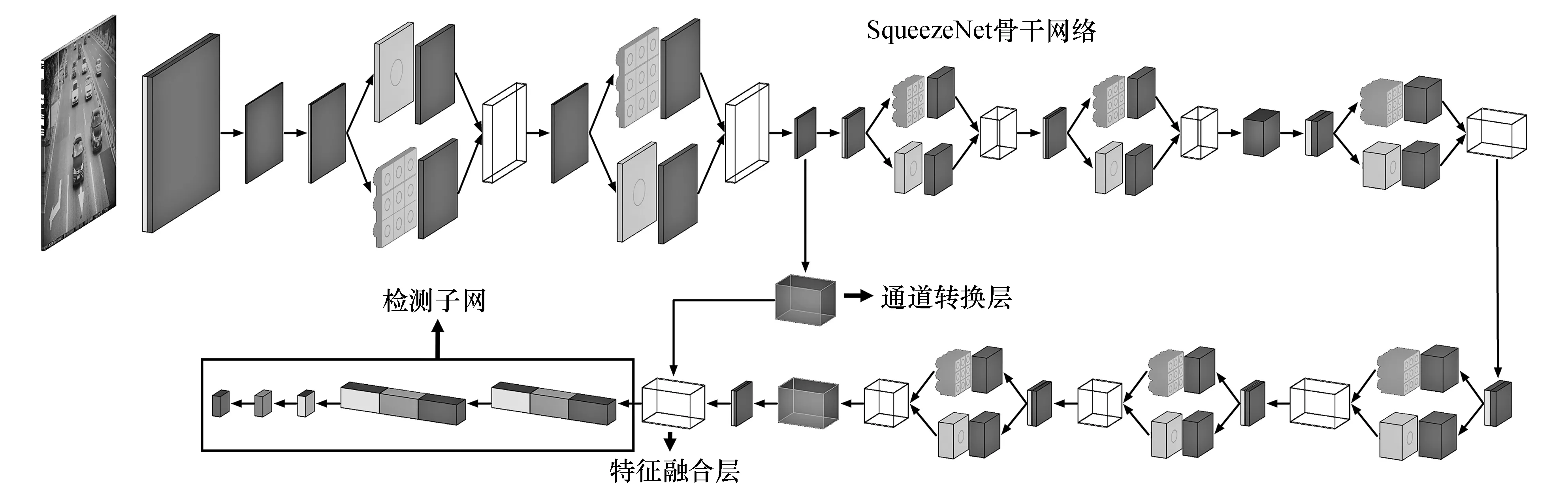
图3 改进后的YOLOv2网络Fig.3 Improved YOLOv2 network
2.2 模型迁移用于图像质量分类
模型迁移过程如图4所示,交通违法图像分类模型,选取SqueezeNet为骨干网络:1)在ImageNet数据集上预训练SqueezeNet,其最终分类器输出1 000类中的一类;2)预训练之后,之前的最终分类器被另一个随机初始化的Softmax分类器替换以预测2类图像质量,而分类器之前的层保持不变;3)之前的卷积层都被冻结,继续微调模型最后几个全连接层。

图4 SqueezeNet迁移学习流程Fig.4 SqueezeNet migration learning process
2.3 交通违法证据评价过程
当驾驶员在驾驶过程中拨打接听电话或未按规定使用安全带时,驾驶员所在图像区域为交通违法证据审核的关键区域,本文采用Softmax分类器对交通违法预判图像关键区域进行图像质量分类。SqueezeNetYOLOv2v1为训练后的机动车检测网络,SqueezeNetYOLOv2v2为训练后的交通违法车辆车窗检测网络,SqueezeNet网络为训练后的图像质量分类模型,交通违法证据评价过程包括下列步骤:
1)输入原始图像,使用改进的YOLOv2检测算法(SqueezeNetYOLOv2v1网络)检测机动车;
2)判断是否检测到机动车,若检测到则下一步,若未检测到则算法停止;
3)对所有检测到的机动车锚框参数ty+th进行排序,找出ty+th的最大值所在锚框,并从输入图像中裁剪该锚框,即为唯一违法车辆;
4)使用SqueezeNetYOLOv2v2网络对3)中唯一违法车辆检测车窗,并裁剪出车窗;
5)对4)中违法车辆车窗区域提取驾驶员所在关键区域;
6)使用SqueezeNet网络对5)中驾驶员所在关键区域进行图像质量分类,给出图像质量分类结果和预测准确率。
3 实验与分析
3.1 数据集
交通违法车辆数据采用交通监控反向抓拍得到,经过交通违法服务器进行一次判别,图像分辨率从4 096×2 208到8 192×2 208。本文取4 000张预判图像进行标签标注,标注内容为违法机动车、非违法机动车、违法机动车驾驶员所在区域和违法机动车牌照(见图5)。

图5 数据集样本标注Fig.5 Data set sample annotation
根据驾驶员所在区域图像筛选评价,将该区域图像成像质量进行质量好和差二分类标注。成像质量差的分类定义为人眼不能清晰地分辨出驾驶员所系安全带特征,不能分辨驾驶员是否在打手机,此类图像不能作为交通违法证据。图像成像质量差的分类主要包括,图像亮度过暗,亮度过曝,驾驶员所在区域有炫彩遮挡和成像模糊等情况,反之则认为图像质量好,可作为交通违法证据。
3.2 数据预处理

3.3 模型训练
模型训练在i5-10400@2.9GHz,16 G内存,GTX1660Ti 6 GB平台上对网络模型进行训练和测试。操作系统为win10,测试环境为CUDA development 11.0。机动车检测网络SqueezeNetYOLOv2v1和车窗检测网络SqueezeNetYOLOv2v2网络训练参数,输入图像分辨率为227×227×3,初始学习率为0.001,随机小批量Mini Batch为16,最大迭代数Max Epochs为30。驾驶员所在区域图像筛选评价SqueezeNet网络训练参数,输入图像分辨率为227×227×3,初始学习率为0.000 1,随机小批量Mini Batch为30,最大迭代数Max Epochs为70。
4个模型使用训练迭代损失函数来提高模型的训练进度和训练效果,4个模型的迭代训练损失函数整体呈下降趋势(图6为4个模型经过平滑处理的迭代训练函数曲线),前半段下降速度较快,后半段趋于平缓,在迭代800次后趋于稳定,趋向于极小值0。训练结果表明随着训练迭代次数的增加,识别效果越来越准确并趋于最优。
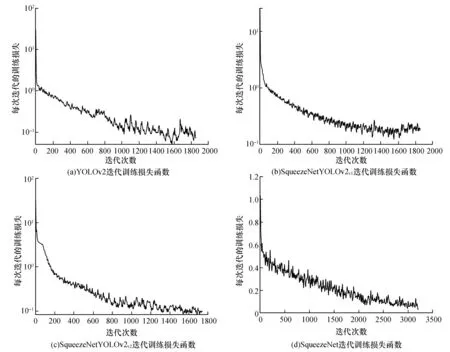
图6 4个模型迭代训练损失函数Fig.6 4 model iterative training loss function
3.4 训练结果
本文选取了4 000张方向抓拍交通违法图像作为YOLOv2、SqueezeNetYOLOv2v1、SqueezeNetYOLOv2v2、SqueezeNet网络的训练集与测试集。本文模型运行环境为i5-10400@2.9GHz,16 G内存,GTX1660Ti 6 GB的台式机。
使用4组不同的标注样本总计4 000个,分别对4个模型进行检验,设置IOU置信阈值为0.8,绘制精度-召回曲线(图7)与平均漏检-误报率曲线(图8)并计算平均精度。如图7、图8所示4个模型都经过ImageNet预训练后参数共享与微调,传统的YOLOv2模型平均精度值为0.85,替换原有Darknet-19采用SqueezeNet骨干网络的模型平均精度分别为0.966与1,平均精度提升明显。当训练样本较少时,采用ImageNet数据集微调方法比从零学习模型或纯监督学习方法能够达到更高的检测精度。
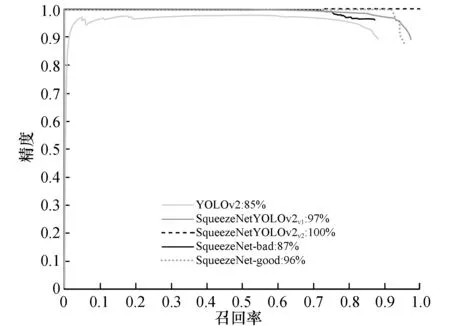
图7 精度-召回曲线Fig.7 Data set sample annotation

图8 平均漏检-误报曲线Fig.8 Average missed-false positive curve
测试结果(见表1)表明,传统的YOLOv2网络经过训练对交通违法图像中机动车的识别准确率为84.4%,识别速度为97.2帧/s。使用SqueezeNetYOLOv2v1结合的目标检测网络,对交通违法图像中机动车的识别准确率为99.3%,识别速度为49.8帧/s。SqueezeNetYOLOv2v2网络对违法车辆驾驶员区域识别的准确率为96.3%,识别速度为57.2帧/s。SqueezeNet驾驶员中心区域图像质量分类评价模型的分类准确率为92.6%,分类速度为28.7帧/s。
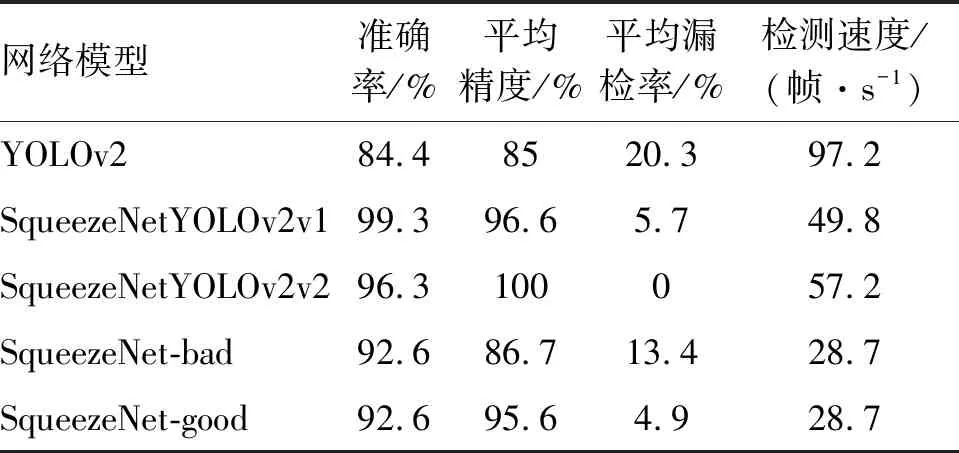
表1 4 000个样本集/1 000个测试集结果Table 1 4 000 sample set/1 000 test set results
由此可以看出,SqueezeNetYOLOv2v2结合的目标检测网络相较于传统YOLOv2网络,随着模型深度和参数的增加,识别准确率提升了14.9%。虽然驾驶员所在区域检测模型SqueezeNetYOLOv2v2与违法车辆SqueezeNet YOLOv2v1检测网络结构相同,但模型的输入图像分辨率不同。SqueezeNetYOLOv2v1的输入为整幅图像,SqueezeNetYOLOv2v2的输入为SqueezeNetYOLOv2v1检测到的唯一违法车辆,输入图像分辨率尺度变小从而导致SqueezeNetYOLOv2v2比SqueezeNetYOLOv2v1检测速度有所提升。
本文为查看SqueezeNet网络对驾驶员所在中心区域的图像质量分类效果引入类激活映射(class activation maps,CAM)[18],生成驾驶员所在区域热力图,突出了图像类的特定区域。本文选取4张交通违法图像进行展示(如图9),通过热力图所在范围发现,SqueezeNet网络类激活映射区域都集中在驾驶员区域,从侧面验证了模型的准确性。图9也展示了4张交通违法图像机动车检测、违法车辆检测和图像质量评价的结果和置信度。

图9 多尺度交通违法证据筛选结果Fig.9 Multi-scale traffic violation evidence screening results
4 结 论
本文为提高驾驶员开车打手机、开车不系安全带两种违法行为的预判准确率,减少交通违法证据审核无关区域,只对驾驶员所在关键区域进行判断的方法来提高模型运行速度和准确性。使用迁移学习的方式重新训练SqueezeNet与YOLOv2结合的模型对交通违法车辆和驾驶员所在区域进行目标检测,使用重新训练的SqueezeNet网络对驾驶员所在区域进行图像质量分类评价,提升了YOLOv2网络对机动车检测的准确率。使用Squeezenet为目标特征提取网络,减少了模型参数,既提高了模型的检测能力又保证了模型检测速度。通过改进后的YOLOv2模型,通过融合高分辨率细粒度特征提高了传统YOLOv2对小尺寸目标的检测敏感度。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
汽车实用技术(2022年14期)2022-07-30
新传奇(2022年12期)2022-04-20
汽车实用技术(2022年7期)2022-04-20
汽车实用技术(2022年4期)2022-03-07
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
证券市场红周刊(2021年42期)2021-10-30
计算机系统应用(2021年9期)2021-10-11
汽车与驾驶维修(汽车版)(2020年6期)2020-07-24
