
基于改进Yolov3的驾驶员疲劳检测
2022-03-30 07:26朱峰陈建陈靖芯严明向露
科学技术与工程 2022年8期
朱峰, 陈建, 陈靖芯, 严明, 向露
(扬州大学机械工程学院, 扬州 225000)
随着城市化进程不断加快,中国汽车的需求量和保有量也急剧上升。截至2020年9月,中国汽车保有量达到了2.75亿辆,随着车辆保有量的增加,交通事故的发生率也在逐年上升。2017年交通事故共计20.3万起,因车祸死亡人数6.3万人,2018年交通事故较2017年上升20.6%,2019年交通事故较2018年下降18.3%[1],虽然事故率有所下降但仍不容乐观。研究表明疲劳驾驶是致使车祸发生的重要原因之一,如果能够在交通事故前检测出驾驶员的疲劳行为并及时提醒可以有效减少因疲劳驾驶而导致的车祸的发生,因此研究疲劳检测算法对改善交通道路安全有着重要意义。
目前疲劳检测主要分为三大类:基于车辆信息的检测方法,基于驾驶员信息的检测方法和基于多信息融合的检测方法[2]。基于车辆信息的检测方法包括车辆加速度信息、车辆转向角信息等来判断驾驶员的疲劳情况,该方法对于外界环境变化敏感,针对于不同的路况、驾驶员驾驶习惯、天气等变化因素难以定量分析,所以并不是疲劳驾驶的主要研究方向。基于驾驶员信息的检测方法分为两种信息类型,一种是驾驶员的生理参数,主要检测参数包括脑电信号、心率等;另一种是驾驶员的行为特征,包括眼动特征、嘴部状态,头部姿态等,不论是驾驶员的生理参数还是行为特征在当前科技迅速发展的情况下都是容易收集并处理的,由于此方法能够直接检测疲劳特征并且驾驶员在驾驶时不需要佩戴接触式实验设备,所以目前大量研究都集中于此。基于多信息融合的检测方法指的是将两种或两种以上的特征通过相应的信息融合算法判断驾驶员的疲劳状态,该方法虽然较前两种更为复杂,但是算法融合多种特征准确率高,鲁棒性强,更加适用于多变环境,基于多信息融合或将成为疲劳识别的主流方向。
Lang等[3]结合单位时间里眼睛闭合时间所占的百分比(percentage of eyelid closure over the pupil over time,PERCLOS)和平均闭眼速度(average eye-closure speed, AECS),提出了一种新的驾驶员疲劳检测算法,并验证了算法的有效性。Yang等[4]提出了一种基于动态贝叶斯网络、信息融合和多种背景和生理特征的驾驶员疲劳识别,实验证明接触生理特征(特别是心电图和脑电图)是判断驾驶员的重要因素。Wang等[5]提出一种眼睛和嘴巴特征的疲劳检测算法,该方法有效解决了眼睛被遮挡而无法检测到相关特征的问题。Wei等[6]提出一种融合多源信息的自适应动态识别模型,该模型在决策级中引入了动态基本概率分布,并且在决策级融合中结合前一时间步上的疲劳状态,提高疲劳识别的准确率。Zhang等[7]将卡尔曼滤波与专用开源跟踪学习检测(track-learning-detection, TLD)滤波器相结合,开发一种鼻子跟送算法,并基于鼻子跟踪置信度、嘴角周围梯度特征和人脸运动特征等开发一种用于打哈欠检测的神经网络。胡习之等[8]通过改进SSD(single shot multiBox detector)算法的脸部识别并基于面部特征分析对疲劳驾驶进行研究,并取得较好的检测结果,对将来的疲劳检测算法研究有重要意义。
为此,结合深度学习和传统的机器学习实现基于面部特征信息的驾驶员疲劳检测系统。首先基于改进的Yolov3(you only look once)算法实现人脸识别并结合卡尔曼滤波算法进一步加强算法的准确性。使用一种基于提升树的关键点检测算法提取脸部关键点,同时使用多个脸部特征进行疲劳检测以达到准确率高鲁棒性强的检测目的。
1 具体研究方法
1.1 基于改Yolov3的人脸检测算法
Yolo由Redmon等[9]于2016年首次提出。在Yolo提出之前,传统的检测算法的流程通常是先通过计算机图形学(或者深度学习)的方法,对图片进行查找,找出若干个可能存在物体的区域,将这些区域截取在进行分类。而Yolo不需要提前找到可能存在目标的图像位置,可以实现端到端的目标检测。
1.1.1 Yolov3基本结构
Yolov3的主干框架是DarkNet53,相较于其他网络框架,DarkNet53中大量使用残差神经网络,这样的做法有效解决了由于网络深度过深而导致在进行梯度下降时候产生的梯度消失的问题。Yolov3还使用了特征金字塔的方法输出3种尺度的特征层分别对不同尺寸的物体进行检测,有效解决了小目标物体漏检的问题,具体的框架如图1所示。
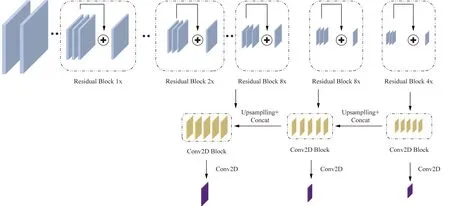
Residual Block 1x为残差结构;Conv2D Block为卷积结构;Upsamplling为上采样Concat为张量拼接图1 Yolov3结构Fig.1 Yolov3 structure
1.1.2 维度聚集
Yolov3算法在实际预测的过程中并不是直接预测Bounding-box的高和宽,而是通过边框回归得来的。其过程可以简要概述为作者提前设置好anchor box的宽和高,网络通过不断学习尺度缩放值进行边框回归从而完成预测,具体预测宽和高表达式为
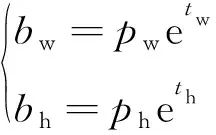
(1)
式(1)中:bw、bh分别为最终预测的边框宽和高;pw、ph分别为提前设置好的anchor box的宽和高;tw、th分别为从网络训练得到的预测值。
由此可见,选择合适anchor box的尺寸对于整个网络非常重要,其值影响着目标检测的准确率和网络训练速度。通过K-mean聚类方法选择合适的边框宽和高,不同于传统的聚类算法选择欧几里得距离作为聚类的条件,而是使用IOU的值作为条件,具体可表示为
d(Box,Centroid)=1-IOU(Box,Centroid)
(2)
式(2)中:d为将处理后的IOU作为欧氏距离;Centroid为聚类时被选为中心的边框;Box为样本边框;IOU为被选为中的边框与样本边框的重合度。
选取anchor box数量k为2~12分别对训练样本进行聚类分析并计算每种情况下平均交并比的值,计算结果如图2所示。
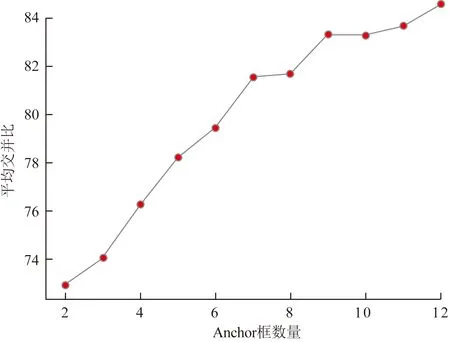
图2 Anchor框数与平均交并比关系Fig.2 The connection between the number of Anchor frames and the average IOU
可以看出,随着k值的增大,曲线逐渐变得平缓,曲线的拐点k=9时可以作为最佳anchor box数量。数据集对应的3个anchor box分别为(33,74)、(40,153)、(56,127)、(63,132)、(90,153)、(109,227)、(122,229)、(131,266)、(174,333)。
1.1.3 模型的训练
数据集采集于模拟驾驶员驾驶的视频集。通过安装在车辆前的摄像头拍摄模拟驾驶人员的脸部视频,得到1 200张数据集通过数据增强(旋转,平移、镜像等)得到最终数据集2 500张,数据集通过Python自带的Labelimg库进行标注,并按照90%的训练集和10%的验证集来训练,部分数据集如图3所示。训练时设置Batch size=8,迭代次数Epoch=100,使用Adam梯度下降、自适应学习率衰退、提前停止过拟合等技巧。具体训练配置如表1所示。

图3 部分数据集Fig.3 Partial data set
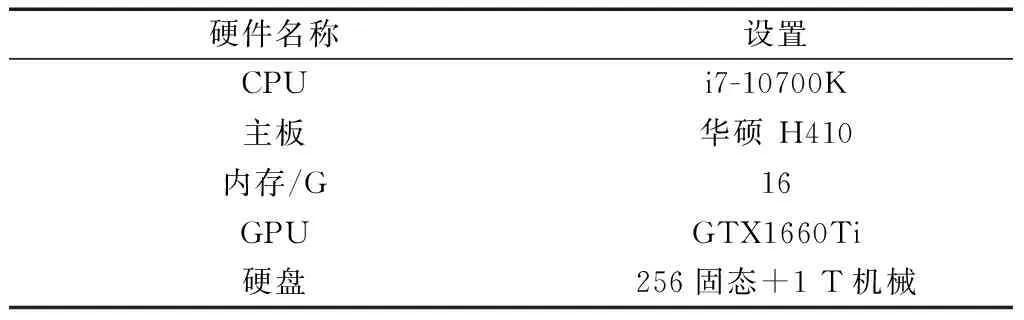
表1 实验环境配置 Table 1 Experimental environment configuration
1.1.4 模型的评估
目标检测算法的准确度通常用准确率Precision和召回率Recall来评估,其计算方法分别为
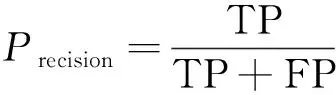
(3)
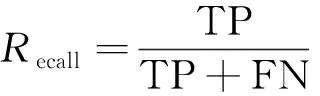
(4)
式中:TP为识别正确的目标数量;FP为错误识别目标的数量;FN为没有被识别出来的目标数量。
由于目标的检测准确率和召回率与置信度息息相关,取值不同的置信度,准确率和召回率也随之改变,所以二者结合后的平均准确率(average precision, AP)可以用来衡量算法的综合性能,算法改进前后的AP如表2所示。
算法改进前后检测同一张图片结果对比如图4所示。可以看出,改进后的算法在置信度和边框定位的准确性度上都优于改进前的算法,能够较好地完成人脸检测的任务。

表2 改进前后检测效果对比Table 2 Comparison of detection effect before and after improvement

图4 Yolov3改进前后检测结果对比Fig.4 Comparison of test results before and after Yolov3 improvement
1.2 基于卡尔曼滤波的脸部追踪
1.2.1 卡尔曼滤波的基本原理
在利用上述相关的算法进行人脸检测时,若发生遮挡物遮挡或者转身等复杂情况时,可能会出现检测失败的情况,当检测失败时就可以利用卡尔曼滤波算法[10]进行人脸的运动预测。卡尔曼滤波是对于含有不确定信息的动态系统做出有根据的预测,卡尔曼滤波算法由预测和更新两个部分组成,状态预测的表达式为
(5)
先验估计协方差方程为
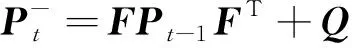
(6)
更新部分包括卡尔曼增益,修正估计和更新后验协方差矩阵,卡尔曼增益更新的表达式为
(7)
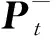
修正估计的表达式为
(8)
后验估计协方差矩阵更新表达式为
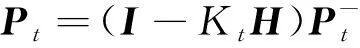
(9)
式(9)中:Pt为t时刻后验估计协方差矩阵;I为单位矩阵;Kt为卡尔曼增益;H为系统测量系数;Pt-为t时刻系统的先验估计协方差。
基于Yolov3与卡尔曼滤波算法的目标检测流程如图5所示。首先使用Yolov3算法进行人脸检测,若检测过程中遇到遮挡或者检测出来的边框置信度未达到设置的阈值时则卡尔曼滤波算法介入进行边框左上角和右下角坐标追踪与预测。
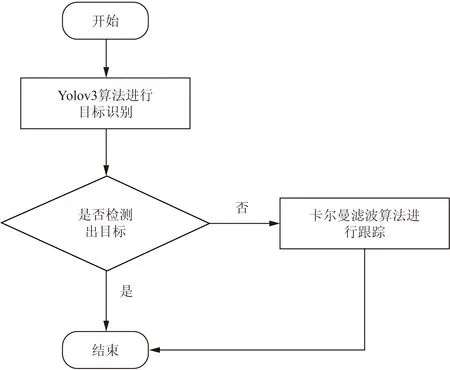
图5 卡尔曼滤波跟踪流程图Fig.5 Kalman filter tracking flow chart
1.2.2 实验结果
截取一段实验录制视频,每间隔10帧利用卡尔曼滤波进行脸部追踪,预测结果如图6所示。可观
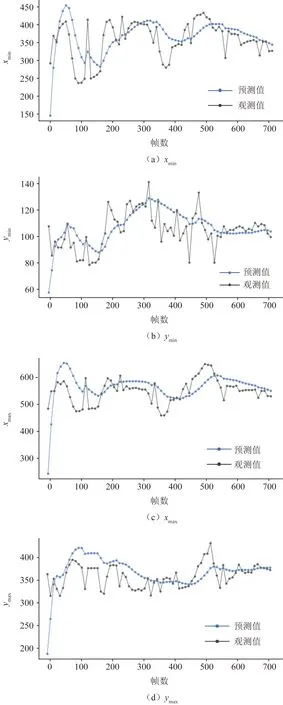
xmin、ymin、xmax、ymax分别为追踪框的左上角和右下角坐标图6 卡尔曼追踪结果Fig.6 Kalman trace results
测出在初期进行追踪时,预测值与观测值有较大的误差,随着时间的增加,预测值与实际值愈发接近,最终能够取得较稳定的结果。
1.3 驾驶员面部特征提取
进行基于面部特征的疲劳研究时,眼睛与嘴巴作为疲劳时特征变化较明显的部位,通常用来作为评判疲劳的特征参数。选取眼睛和嘴巴为特征同时进行提取相关参数进行进一步分析。
1.3.1 特征点定位
采用一种基于提升树的人脸对齐算法[11],算法的主要原理实际采用加法模型与向前分步算法,模型的表达式为
fm(x)=fm-1(x)+T(x;θm)
(10)
式(10)中:fm(x)、fm-1(x)为当前层和上一层的计算结果;T(x;θm)为当前层的提升树;m为树的序号;x为输入图像;θm为上一级提升树的更新值。
基于提升树的人脸对齐算法具体实现过程如下:首先在训练样本中随机挑选一张图像作为初始形状,对于所有训练图像输入的初始形状是相同的,但是不同的是该初始图像在各个训练图片上提取出来的特征是不相同的。作者以提取的不同特征作为输入从而进行提升树的分裂,提取的特征就是图像中随机两点的像素差。通过将像素差与阈值对比实现树的分裂,将图像分入叶结点时计算平均残差,并将残差作为输入输出给下一课树,这样不断对提升树进行更新从而实现最终的形状预测。利用该方法进行关键点检测得到的结果如图7所示。共检测关键点68个点,其中点37~42和点61~68分别是眼部和嘴部特征点,用于疲劳特征参数的研究。

图7 关键点检测Fig.7 Key point detection
1.3.2 疲劳判别参数
(1)PERCLOS准则。在许多研究证明眼部状态的变化能够很好地反映当前的疲劳状态,通常情况下,当人进入疲劳状态时,眼睛眨动的频率会变低并且眼睛闭合的时间相对清醒状态变长。单位时间里眼睛闭合时间所占的百分比(percentage of eyelid closure over the pupil over time,PERCLOS)[12]常作为判别眼部疲劳状态的参数,指特定时间内眼睛闭合程度超过某一阈值所占时间比,采用P80为评判标准,PERCLOS原理如图8所示。
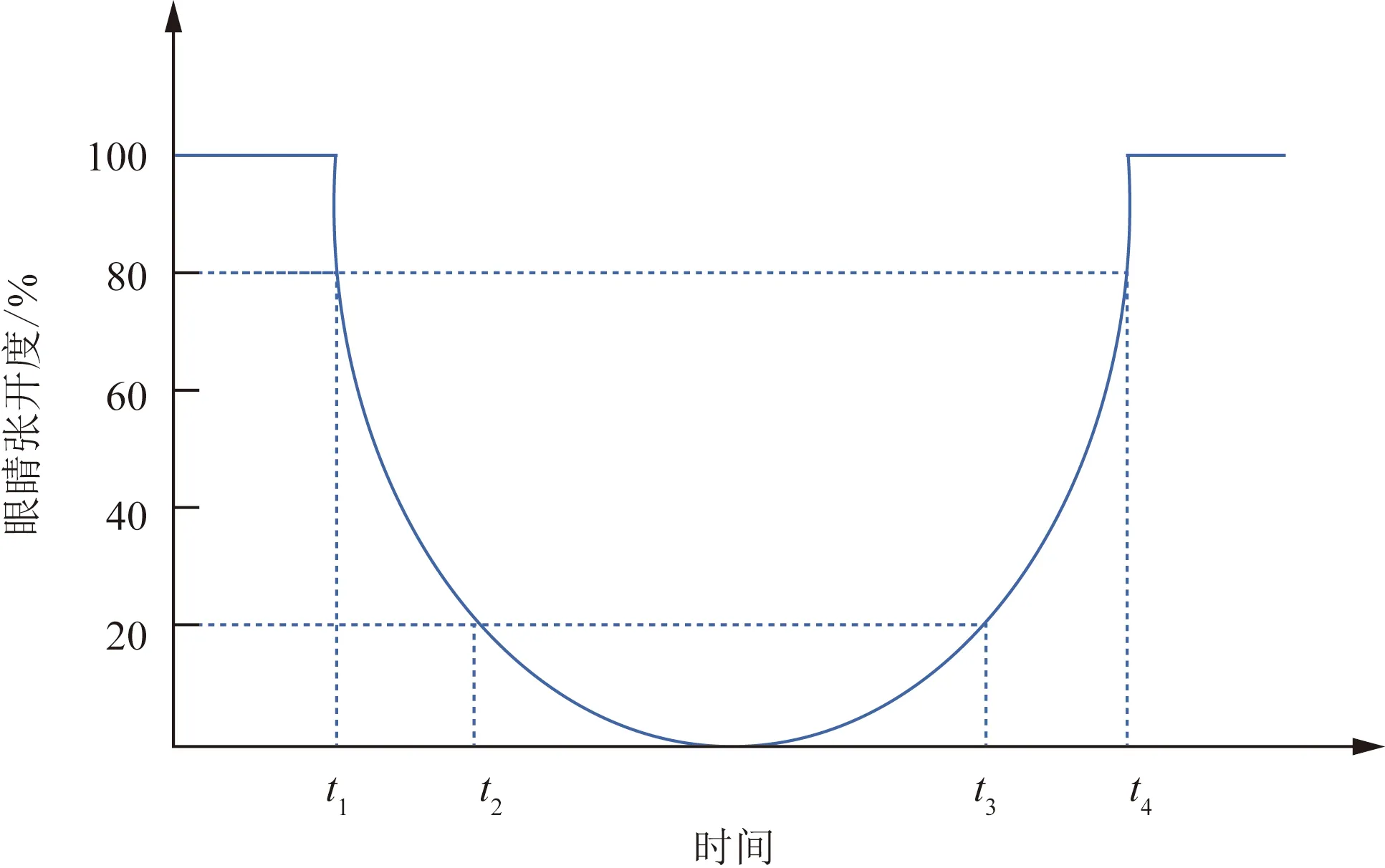
图8 PERCLOS原理图Fig.8 PERCLOS principle
在实际计算过程中使用某段时间内眼部疲劳的帧数占总帧数的百分比来计算PERCLOS的值,其计算公式为
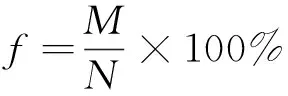
(11)
式(11)中:f为PERCLOS值;M为特定时间内闭眼帧数;N为特定时间内帧数和。
(2)眼部持续闭合时间。眼部持续闭合时间指在特定时间内眼部维持闭合状态所持续的时间,在疲劳状态下,随着疲劳程度的增加眼部持续闭合时间也会变长,以正常状态下眼睛闭合持续的最长时间为阈值判断是否疲劳。
眼部的睁闭情况通常用EAR(eye aspect radio)来计算,EAR表示眼睛纵横比,即眼睛宽度与长度的比值。正常情况下,人眼睁开时宽度与长度的比值是一个固定的值,当人眼闭合时,眼睛长度不变,宽度迅速变小,纵横比就会发生变化。眼部周围特征点P1~P6如图9所示。
EAR的计算公式为
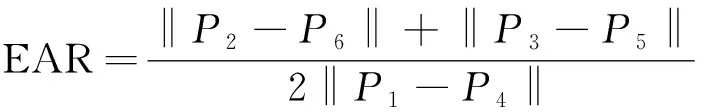
(12)
式(12)中:P1~P6为眼部周围的特征点的坐标。
(3) 嘴部开合程度。嘴部的特征变化与疲劳状态也有着密切关系,通常情况下,当人处于疲劳状态时,打哈欠的行为也会增加,若某一段时间内打哈欠的频率超过正常状态下的频率,那么可以判断处于疲劳状态,通常用嘴部纵横比(mouth aspect ratio, MAR)来衡量嘴部的开闭程度。嘴部特征点M1~M6如图10所示。
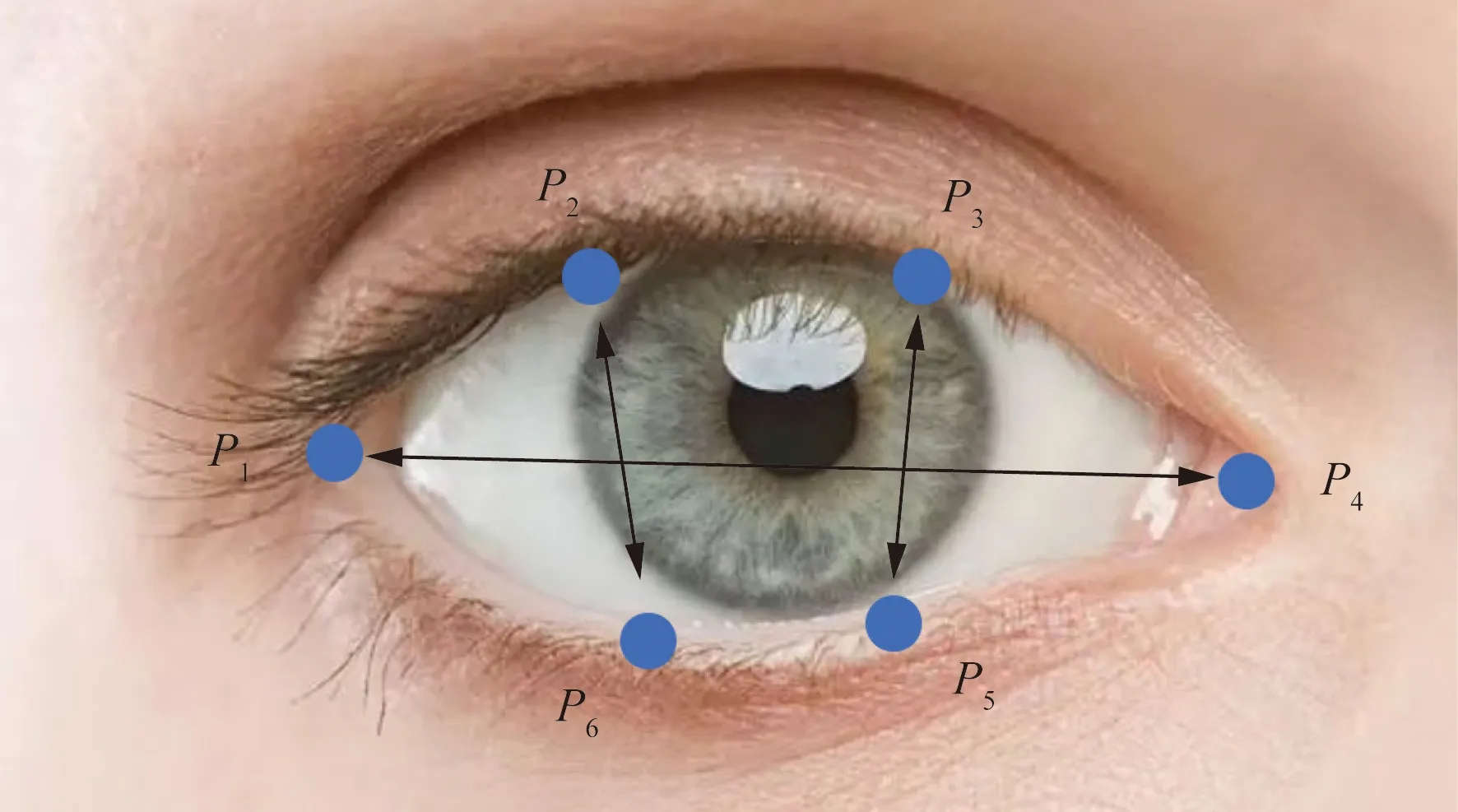
图9 眼部特征点 Fig.9 Ocular feature points
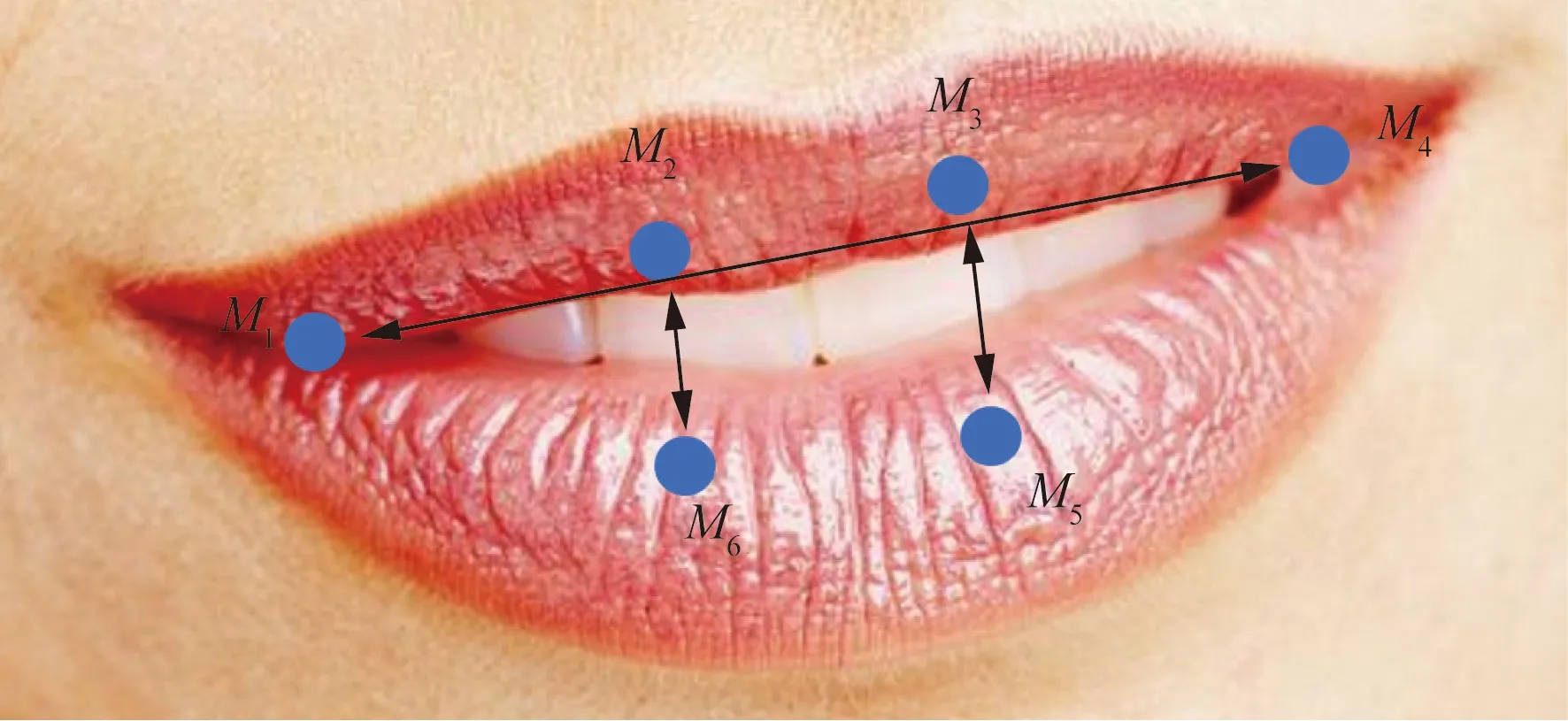
图10 嘴部特征点Fig.10 Mouth feature points
嘴部纵横比公式为
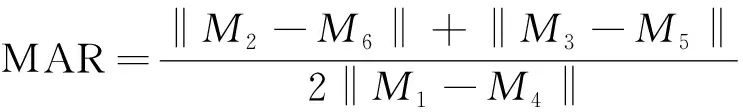
(13)
式(13)中:M1~M6为嘴部特征点的坐标。
1.3.3 疲劳判别过程
使用单一特征判断疲劳状态准确率较低,所以将特征组合进行多特征融合从而使得判别结果效果更佳。
疲劳判别流程如图11所示,具体过程为:①检测过程中若PERCLOS超过一定阈值且眼部持续闭合时间大于正常状态下最长闭眼时间那么则判定为疲劳状态;②检测过程中嘴部打哈欠次数超过阈值且满足眼部疲劳判别条件之一则判定为疲劳状态。
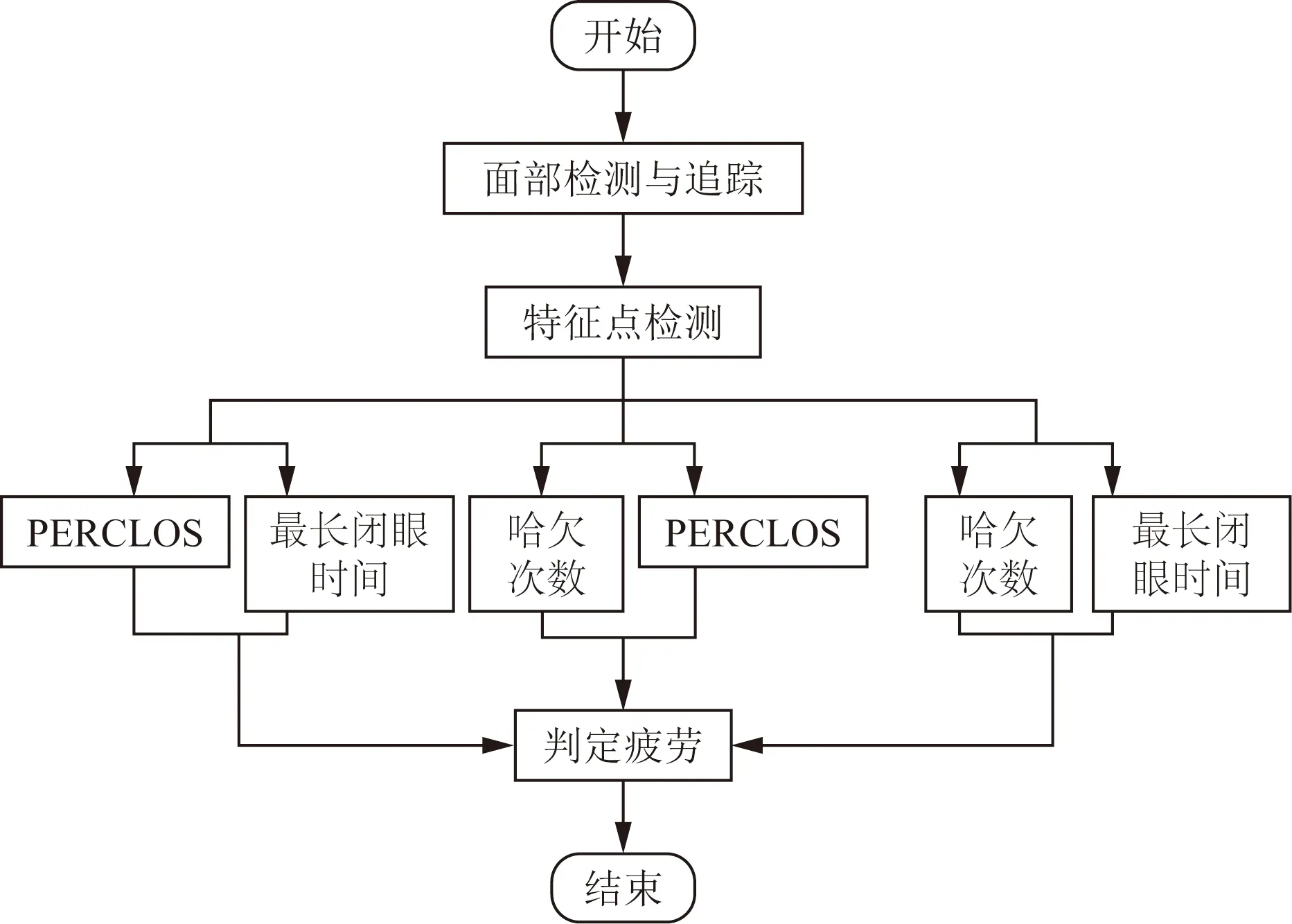
图11 疲劳判别流程图Fig.11 Fatigue identification flow chart
2 实验与分析
2.1 阈值确定
通过模拟驾驶录制的视频数据进行实验与分析,共录制8位驾驶员分别在清醒状态与疲劳状态下模拟行车的视频,分别计算样本在清醒状态下和疲劳状态下的ERA和MAR,其中某个样本分析结果如图12所示。
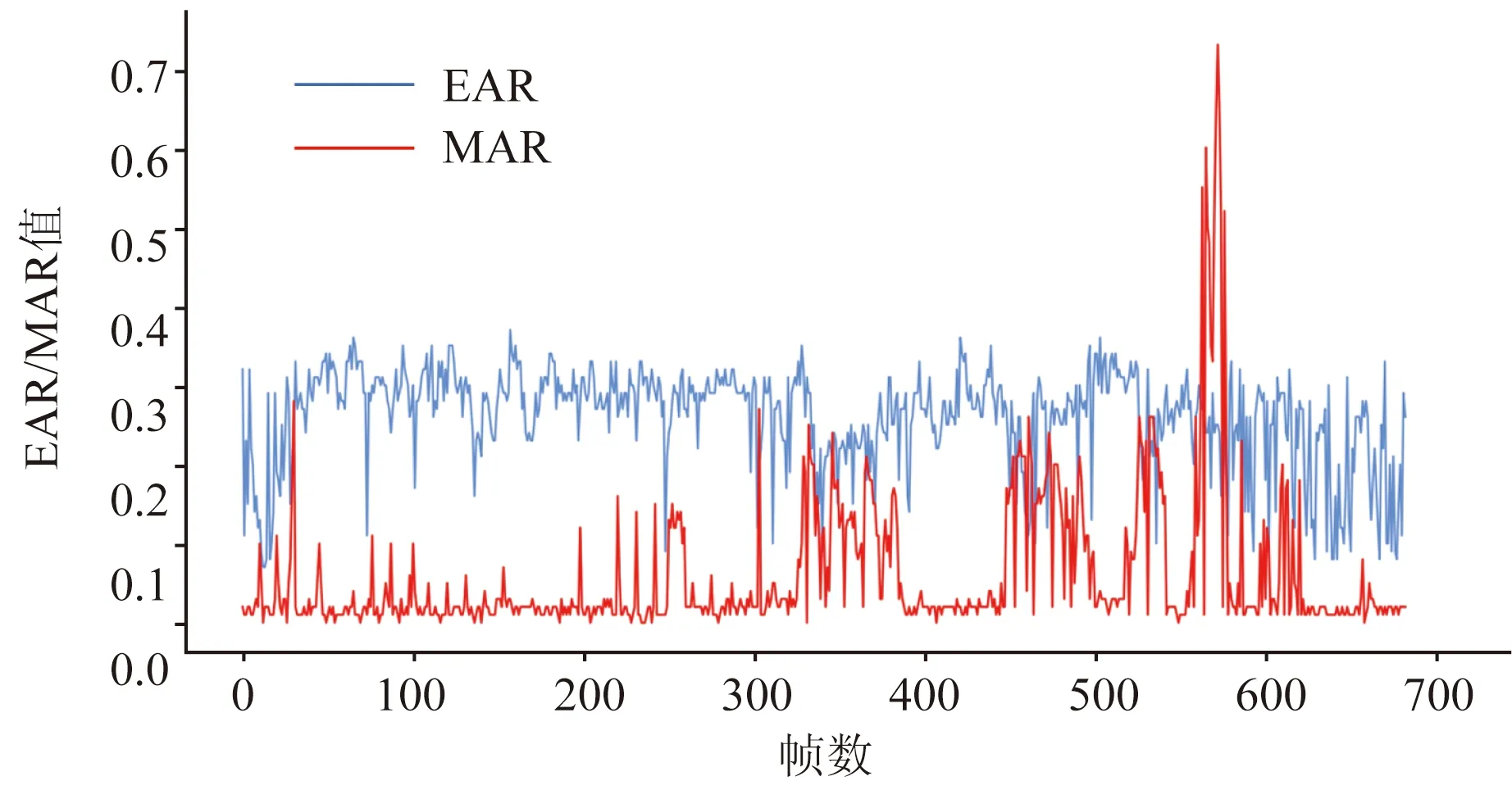
图12 某个样本在清醒和疲劳状态下的ERA和MAR分析结果Fig.12 ERA and MAR analysis results of a sample under awake and fatigue conditions
图12中前500帧是清醒状态下的EAR与MAR,后200帧是疲劳状态下的EAR与MAR,可以看出,进入疲劳状态时眼部处于闭合状态明显多于清醒状态并且哈欠次数增多。选取EAR=0.2,MAR=0.4作为眼睛和嘴巴开闭程度的阈值,当EAR<0.2则说明眼睛处于闭合状态,当MAR>0.4说明嘴巴处于张开状态。
2.2 样本检测与结果分析
将模拟驾驶录制的视频数据分割成20 s为一个样本,共计108个样本,将样本进行人工标定得到共108个实验样本,其中清醒样本85个,疲劳样本23个。检测结果如表3所示。结果显示清醒状态下检测正确率为94.1%,疲劳状态下检测正确率为86.9%,平均正确率为92.5%,能够达到较高的检测水平。
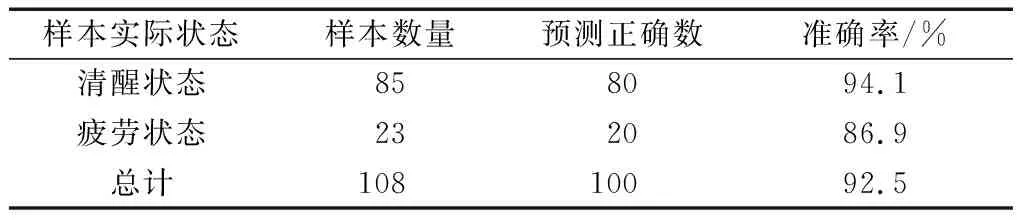
表3 疲劳检测结果Table 3 Fatigue test results
3 结论
针对脸部特征在疲劳时的变化,基于多信息融合设计了一套疲劳检测算法,得出如下结论。
(1)首先针对复杂的驾驶环境,对Yolov3算法边框进行维度聚集生成9个新的Anchor Box,实验表明改进Yolov3算法在自建的数据集上AP提升了16.7%。
(2)为解决因人脸遮挡或误判导致的漏检,结合Yolov3算法与卡尔曼滤波算法进行人脸追踪,实验表明结合算法能够有效地对目标进行跟踪,具有更强的鲁棒性。
(3)基于多信息融合进行疲劳检测,算法在实车数据检测平均正确率达 92.5%,能够达到检测疲劳的要求。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中学生博览·文艺憩(2020年12期)2020-12-23
黄河之声(2020年19期)2020-12-07
新课程·下旬(2019年3期)2019-05-08
电子制作(2019年23期)2019-02-23
农业工程学报(2018年10期)2018-06-05
摄影之友(影像视觉)(2018年1期)2018-03-22
北京航空航天大学学报(2017年9期)2017-12-18
摄影之友(影像视觉)(2017年11期)2017-11-27
中国惯性技术学报(2017年1期)2017-06-09
