
基于深度学习的实时姿态识别算法生成人物二维动画
2022-03-28 07:46易茹
太原学院学报(自然科学版) 2022年1期
易 茹
(安徽工贸职业技术学院 艺术与传媒学院,安徽 淮南 232007)
0 引言
人工智能技术在20世纪90年代开始崭露头角,机器视觉技术经过20年的发展,已广泛应用于视频监护、虚拟成像、影视制作等行业[1]。尤其是人物建模生成二维动画的技术,是目前科技研究的热点之一。人物建模的关键在于人物运动状态下的姿态识别及模拟,对视频图像的预处理、人物边缘轮廓绘制提炼,并运用大数据分析建模最终生成人体二维动画模型[2-3]。随着机器学习在图像处理领域的应用逐渐成熟,将深度学习与计算机二维动画成像技术结合成为可能,Arikan O等人提出了使用Toronto大学的通用模型-线框模型建模,建模方法效率较高,图像取材简单,但是数据噪声过大,影响了动作的精确度[4]。浙江大学CAD&CG国家重点实验室通过曲线/曲面建模以及真实感图形绘制,辅助以计算机动画模拟进行人体动作建模,实验效果较好,但特征匹配的精确度值对最终的建模结果影响较大。国内其他的科研单位,尚处于学术探索和研究阶段,提出的算法在应用时往往对硬件的计算能力有较高的要求[5]。从国内外研究情况来看,人物姿态的识别及二维动画生成的关键在于对人物本身的每个动作的姿态提取、图像压缩以及后续的提炼运用,而深度学习领域的卷积神经网络在医学图像的处理上展示了强大的优势[6]。本文将着重研究深度神经网络与动画成像技术的有效结合,提出改进的卷积神经网络架构,实现多人运动复杂场景下实时的、二维的人物姿态输出。运用动画建模技术生成二维的动画图像,对比经典的算法,本文算法明显提高了动作识别的精准度以及算法的执行速度。
1 DLHPE人体姿态识别算法(deep leraning&human posture estimation)
将深度学习的神经网络架构应用于人体姿态、识别算法,其输入数据为视频摄像机获取的真彩图像。首先对真彩图像进行缩放处理,经过神经网络结构多次处理后,形成人体姿态的关键输出点位,与真彩图像的位置相呼应,最终形成人体姿态模型图。在此基础上进行动画加工,生成最终的二维动画[7]。
上述过程是目前研究人员已经论证并实施的算法,针对此算法,本文对神经网络处理算法进行了优化,让原本需要多次迭代处理的图像的过程简化为仅需一次执行,同时结合聚类算法对关键点进行归类处理,提升整体效能的同时改进了算法准确性。算法结构如图1所示。
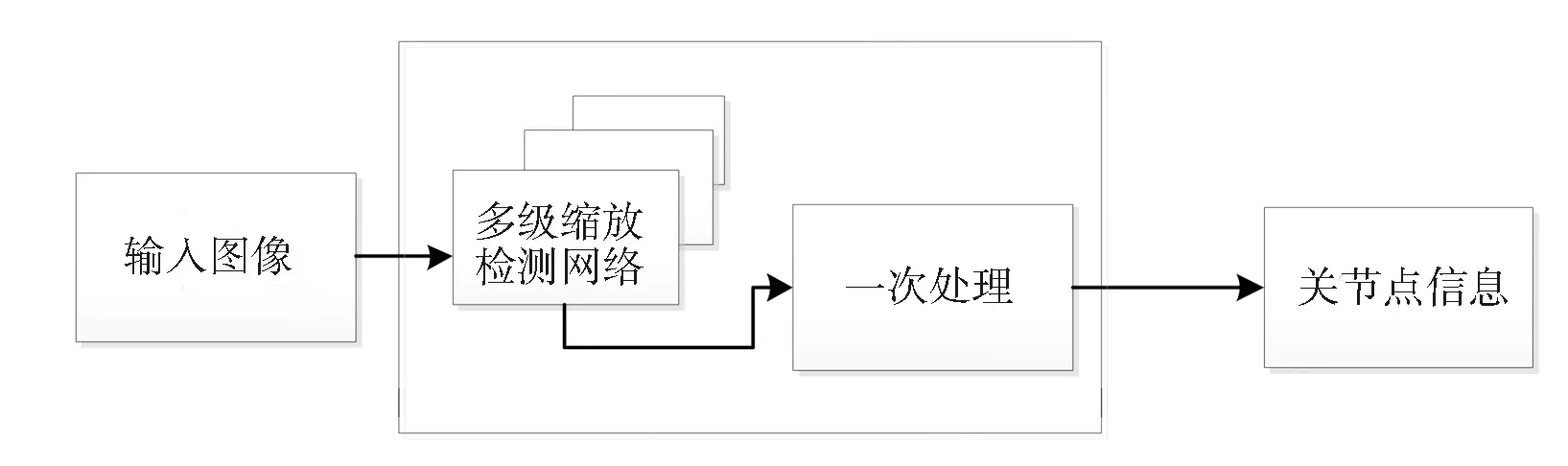
图1 卷积神经网络的网络结构图
本文提出的算法基于由下而上的人体姿态识别算法,在多人复杂的环境下,率先识别人员运动的关键点,然后经过关键点的合理链接形成人体运动骨骼图。利用卷积神经网络处理基础图片时,只需要进行一次卷积即可完成分析。首先根据人体关节点坐标、关节层级和类型,建立人体有向链路的特征图,便于图像的数字化处理进而完成卷积运算,如图2所示。
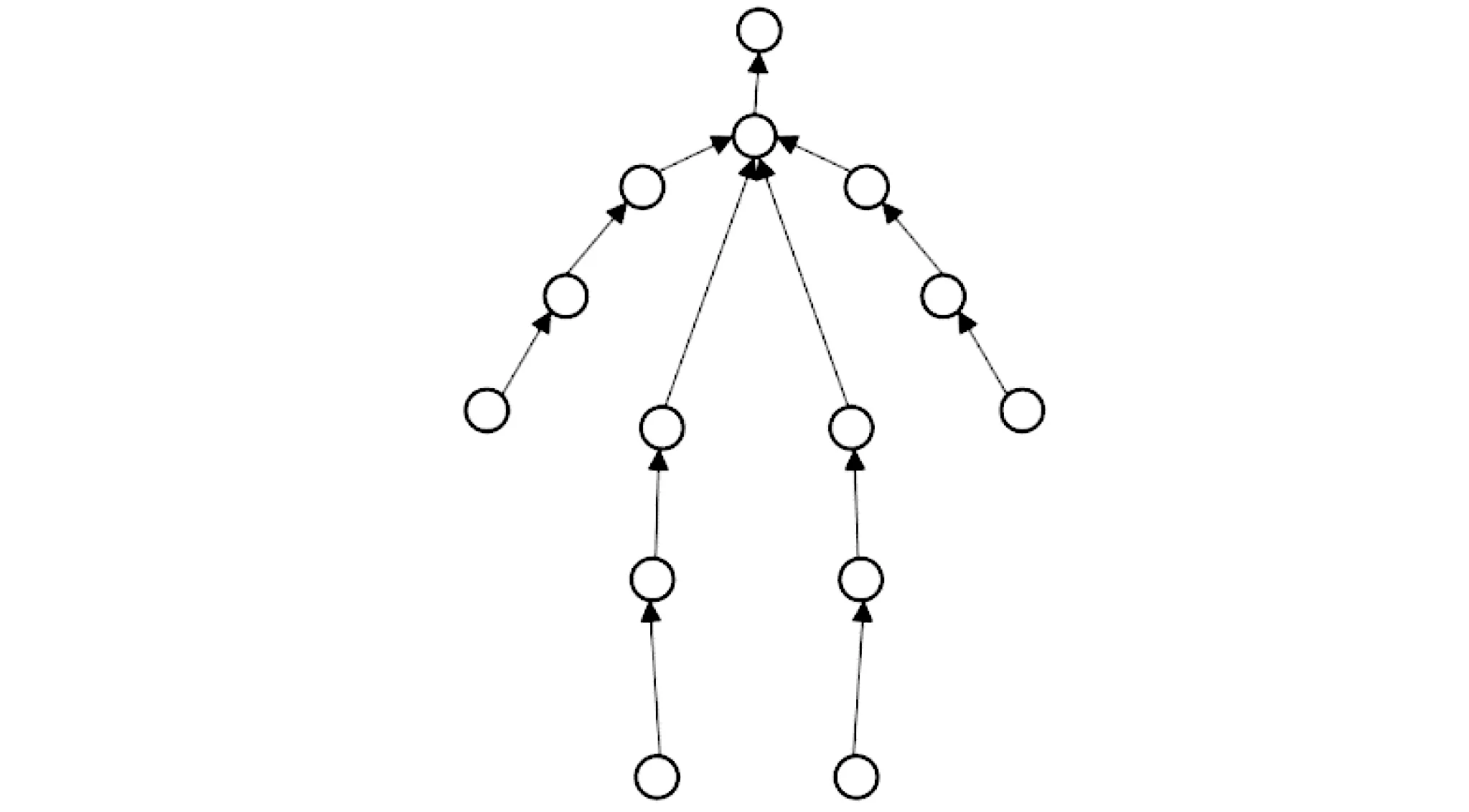
图2 人体有向链路的特征图
图2所代表的人体特征图中,对关键关节点的坐标、层级及类型以特征向量的形式标识,对于特征点(x,y),其对应的特征向量为公式(1):
{Pc,Tto}
(1)
式中:Pc代表特征点(x,y)及其对应关节所归属的类型的概率值;Tto代表特征点的父节点的坐标值与该特征点本身坐标的偏置值,该数值为特征向量值。
基于概率论基础知识,以像素值为(w,h)的图像为例,进行卷积神经处理后,其热图特征图的大小为(w/8,h/8,9),对应的偏置特征向量图的大小为(w/8,h/8,2)。标识该图像对应的热图中坐标点(x,y)的特征向量值代表了关节坐标点的类型及其概率值,计算方法如公式(2):
{Phead,Pneck,Pshoulder,Parm,Phahd,Ppelvis,Pknee,Pfoot,Pbackground}
(2)
对人体姿态识别过程中的关键关节点分类和归类,本文采取的处理方式为以限定范围的视野数据为输入,对局部输入区域的像素进行针对性的分类,提升算法执行效能。
通过偏置向量值计算目标所在的位置进行归类,无需投入精力运算方向的特征向量映射矩阵,极大地提升了卷积神经网络的处理能力。本文的算法采用局部输入像素法处理图像,识别人体左右方向难度较大,因此,在预处理阶段进行左右识别处理,以降低卷积神经网络的处理难度。
本文所采用的端到端的全卷积神经网络的整体架构如图3所示。

图3 端到端的全卷积神经网络的整体架构
在图3所示网络结构图中,输入图片卷积部分采用的前端处理结构为ResNet34,即残差网络结构,对图片完成多轮迭代卷积处理的图片大小已经缩小数倍,此时应用层间残差进行连接来改善网络的深度处理能力,避免出现网络梯度消失的问题。
第二部分核心是反卷积部分,在图片采样的同时,进行卷积操作。在逐层卷积的过程,通过层间的连接完成特征图层的累加操作,从而降低因为原始图片经过反复缩放后引起的图像分辨率变小的问题。
第三阶段为中间图像生成阶段,通过反卷积操作得到输出特征向量图,进行图像检测过程处理,该过程经过3个1×1的卷积缩小后的特征图数据量的残差模块处理后,使用3×3的卷积完成特征提取。
第四阶段为图像生成处理模块,通过2个不同的图像处理环节,获得热图和卷积层级链接图。这个部分引入了注意力模块,该模块对于高注意力值的图片设置高权重,并将图片的分辨率处理分为2个部分,一是生成关键关节点的热图,二是生成对应的链接图,从而加速处理过程。
最后一个阶段为输出阶段,使用1×1的卷积层完成反卷积层处理,并与中间图像生成阶段的输出图串联,获得最终生成结果。
在输入图像识别阶段,算法的核心在于RestNet34的残差网络结构。深度学习的原理是通过设置深层网络提升学习效果,但是由于前向反馈及传播次数的增加导致梯度消失以及梯度爆炸出现的频率变高,因此,本文引入了残差来改善上述问题,残差x1+1的计算公式为:
x1+1=x1+F(x1,W1)
(3)
其中:x1代表网络的输入数据;F(x1,W1)代表网络的输出数据;W1代表残差的输出单元。通过公式(3)可以发现,深度神经网络学习的输入与输出存在差异,残差的网络在正向传播时能避免网络层数增加造成传输质量的降低,也可以避免梯度消失,实现正常回传。本文采用的VGG为19层,属于深度训练网络,引入残差结构来避免层数增加造成的传播质量下降问题非常关键。
在图像生成的阶段,采用了基于注意力处理模块完成关节点连接生成热图的动作。注意力处理模块主要包含卷积块和3×3的卷积层,考虑到各种级别的特征图所对应的检测对象的比率不同,图像生成阶段会引入掩码图,进行层级匹配。具体结构如图4所示,包含通道注意力和输出注意力模块,分别用于提取特征图和增强特征图。
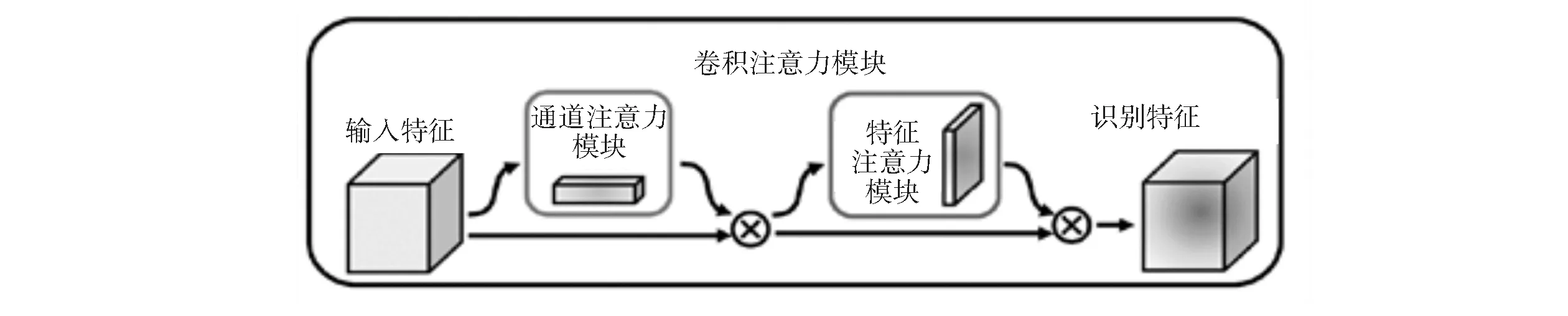
图4 注意力网络结构图
另外,经过实验发现,常用的损失函数对于引入残差网络的深度学习网络性能和速度提升作用不明显,本文提出了新的带有掩码的L2损失函数的计算方法,如公式(4)所示。
(4)
其中:L代表损失;x,y是指的输入的数据样本;x′,y′是标签项值;h,w代表样本图片的高度和宽度。
2 实验结果与分析
2.1 训练过程
本实验的测试训练集选取了MSCOCO的大型图像数据集,该数据集包含了物理上的人物渲染架构机制,以及各种运动姿态下人体的关节信息、服饰信息、人物表情信息等,配合各种光流、背景、天气等情况,较好地满足人物姿态识别及二维动画建模的需要。训练过程中,提炼数据集中标注的人体关键点的位置坐标值和可见的类型识别值。在数据预处理阶段,采用了数据强化处理策略,规避可能出现的过度拟合,具体包括对图像的随机裁剪、缩小、反转、按随机角度旋转等。训练执行时,采用了牛顿动量法,设置期初学习率为0.002。通过自适应学习率的定量衰减,训练损失函数循环迭代10次后,在训练集的结果仍然保持的前提下,将学习率缩小到原来的十分之一。经过5 d的学习,完成本文提出神经网络算法的训练。图5是MSCOCO数据集样例。

图5 MSCOCO数据集实例图
2.2 结果与分析
在不同硬件条件下,将本文提出的算法与目前性能较好的Open Pose算法的执行性能进行对比分析。本文对GXT 1080Ti、GTX1070、GTX1060 3种型号显卡下的运算结果进行了对比,结果如表1所示。

表1 不同算法执行性能对比
本文提出DLHPE深度学习的神经网络算法的链接映射的损失率为58.7,分类的损失率为56.5,这个结果对比Open Pose算法,精确度提升2%左右,处理速度的提升如表1中所示,提升了8倍以上。实验中也对输入图像的背景、光线以及多人物多姿态情况对处理速度的影响进行了测试,结果是这些因素的影响可以忽略不计。图6为本文算法进行人物姿态识别结果示意图。

图6 本文算法进行人物姿态识别结果图
在本文提出的基于深度学习的人物姿态识别算法的基础上,进一步将该算法与经典二维人物动画生成算法Phase-Funcationed Neural Network相结合,进行了动画人物的生成[8]。根据用户的输入和运动轨迹,完成人物实时动作的二维展示。过程中通过使用特殊的相位函数进行模型权重的计算,通过对高度图等采样环境的变化和输入,获得权重矩阵,以完成计算骨架和动作变化。由于人体的动作具有时间周期的可循环重复性,所以借助特定时刻的循环相位信息,规范神经网络的输出值,遵循固定的周期,从而完成动画的生成。最终的动画生成效果如图7所示。

图7 二维动画生成结果图
3 结论
在进入智能化、大数据时代的今天,深度学习与动画的深度融合逐步成为数据挖掘和机器学习领域研究的热点。本文以深度学习技术的核心算法神经网络结构算法为基准,结合人物动作姿态识别和二维动画建模,实现了针对动画人物构建改进的卷积神经网络架构。实验比对发现,本文提出的模型在经典的人物姿态识别基础上,展示出了更精准的识别能力和良好的执行性能,改进后算法识别精准度提升约2%,性能提升了8~10倍,明显优于其他经典算法,实验数据充分说明了本文算法在对人体动作姿态识别方面的优势。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2020年10期)2020-11-14
学生天地(2020年3期)2020-08-25
电子制作(2019年13期)2020-01-14
自动化学报(2019年6期)2019-07-23
电子制作(2019年11期)2019-07-04
汽车观察(2018年9期)2018-10-23
中国自行车(2018年8期)2018-09-26
北京航空航天大学学报(2018年1期)2018-04-20
