
应用最大信息系数和支持向量机估测森林蓄积量
2022-03-28 02:33罗为检
东北林业大学学报 2022年1期
罗为检
(国家林业和草原局中南调查规划设计院,长沙,410014)
森林是地球上最大的有机碳库,在陆地碳循环中发挥着不可替代的作用。为了实现森林的多功能服务并且对其进行可持续经营管理,人们则需要在时间和空间上了解其资源分布和发展的信息[1]。传统的森林资源信息获取方法都是通过森林资源一类、二类调查获得的,这种方式虽然可以获得较为准确的数值,但是其工作量巨大,同时需要耗费大量的人力、物力和财力,并且在有些特殊环境条件下,调查人员无法到达目标区域。因此,遥感技术在森林资源调查中的应用潜力早已被研究人员所发掘[2]。
近几十年,随着不同传感器的发射,利用遥感技术提取森林参数的方法与技术也发展的十分迅速。在诸多遥感数据中,光学遥感数据从上世纪70年代就已经开始研究,其研究时间最长,技术积累最多,数据源最丰富,数据性能最稳定,不仅可以用于地物识别,而且已广泛应用于遥感定量观测研究。在早期的森林资源检测过程中,所使用的遥感数据以中低分辨率为主,如MODIS、NOAA/AVHRR、Landsat TM/ETM+等遥感数据常被用于森林遥感监测。在1995年,Gemmel利用TM遥感数据,并探究了许多遥感因子与蓄积量的关系,他的实验结果说明郁闭度对蓄积量的影响程度最大,其次是TM数据的第4波段和第5波段,这为其他学者在蓄积量的研究提供了重要的理论的基础[3];Fazakas使用TM数据,通过KNN算法在瑞典对一部分森林估测了蓄积量,其实验结果表明,将遥感影像多个像元结合起来与地面特征对应相比于单一像元估测精度更高,结果更有说服力[4]。还有如Labrecque(2006)、Alkan(2012)、Gizachew(2016)等学者使用Landsat系列数据在估算森林的蓄积量以及生长量的问题上做出了大量的研究,他们的实验结果均证明了Landsat系列遥感数据具备很好的林分参数估测潜力[5-7]。
中国的国土面积位居世界第三,截止到2020年3月,中国的森林覆盖率更是达到22.96%,超过总陆地面积的五分之一。在我国当前的林业发展与建设绿水青山的大社会背景下,准确的绘制出森林的蓄积量分布已经成为当前一个极为重要的研究内容。介于此,本研究以湖南省株洲市为研究区,采用Landsat8 OLI为遥感数据源,通过最大信息系数对遥感变量进行筛选,并构建多元线性回归模型和基于四种不同核函数的支持向量机回归模型对研究区的森林蓄积量进行估测,使用十折交叉的验证方法进行精度验证。为市域级单位的森林蓄积量估测提供理论依据和技术支持。
1 研究区概况
株洲市位于湖南省东部,湘江下游,地理坐标为北纬26°3′5″~28°1′7″、东经112°57′30″~114°7′15″(见图1)。研究区总面积11 262 km2,森林覆盖率42.2%。该地区四季分明,雨量充沛、光热充足,风向冬季多西北风,夏季多正南风,年降水量1 400~1 700 mm,年日照时间1 400 h,无霜期在286 d以上,年平均气温17 ℃,属亚热带季风性湿润气候。
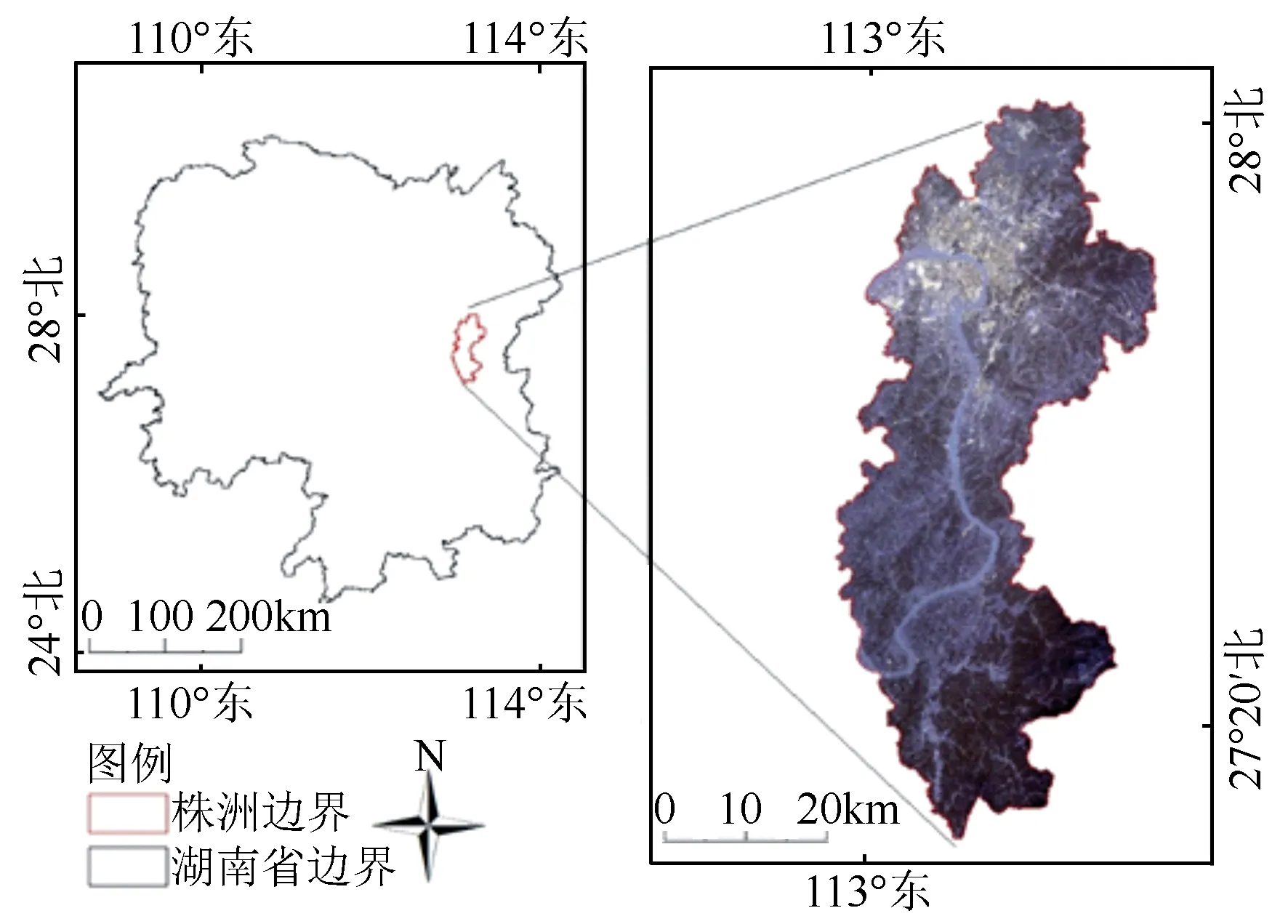
图1 研究区位置图
2 研究方法
2.1 数据的获取及预处理
本次研究以2014年湖南森林资源二类调查的样点调查数据中的活立木蓄积量作为研究样本,每个样地大小为25 m×25 m,通过计算样本的标准差对样本进行筛选,剔除离群值较大的样本后余下90个样点作为研究样本,样点的活立木蓄积量最大值为526.96 m3/hm2、最小值为51.97 m3/hm2、平均值为257.15 m3/hm2、标准差为112.63 m3/hm2,样本的森林蓄积量分布51~530 m3/hm2,变异系数为45.8。样点分布如图2所示。

图2 样本分布图
研究使用的Landsat8遥感影响拍摄于2013年8月,与地面调查时间基本一致。用于研究的影像包括蓝、绿、红、近红外及两个短波红外在内的6个波段。用ENVI5.3软件实现数据的预处理(包括辐射定标、大气校正、几何校正和地形校正)[8-10]。将样点位置通过ARCGIS软件导入到遥感影像中,并提取样地所在像元的灰度值作为该样点的遥感因子。
2.2 遥感变量的获取
本次实验中通过遥感影像提取出用于建模的遥感变量共131个,包括遥感因子和地形因子两类。其中遥感因子有:Landsat8 OLI的单波段、植被指数和纹理共生矩阵[11-16](见表1、表2);地形因子有海拔、坡度和坡向。

表1 植被指数计算公式
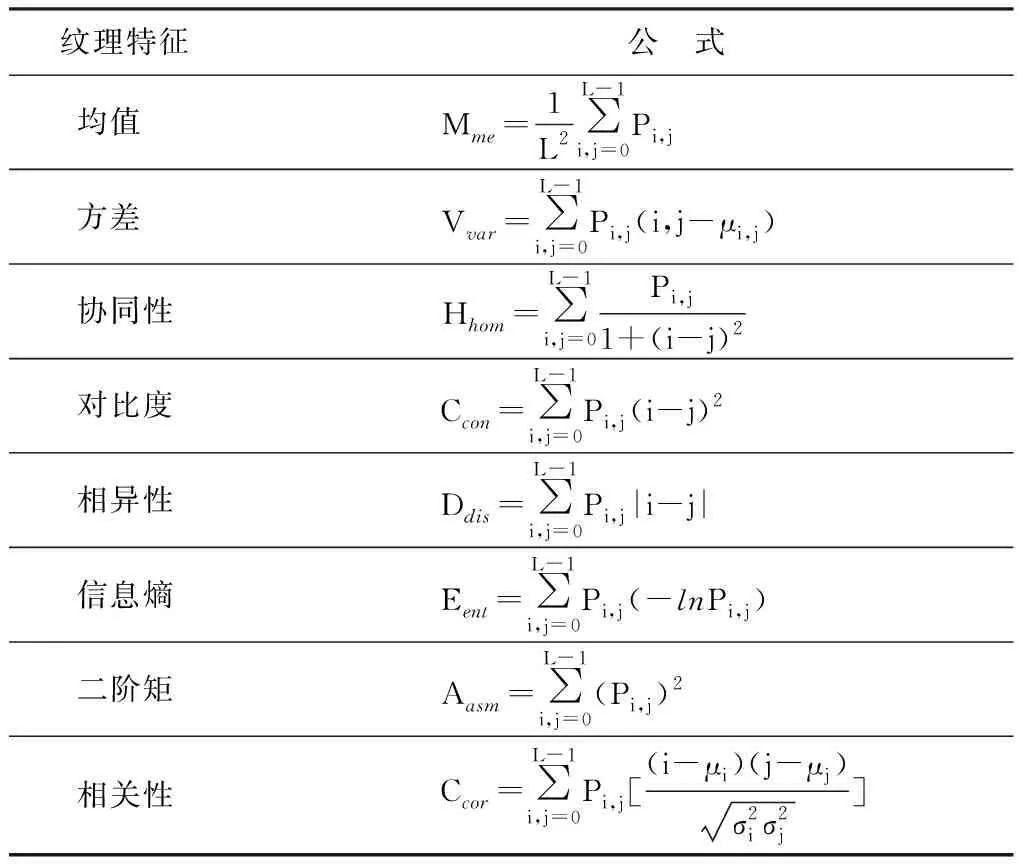
表2 纹理特征计算方法
2.3 基于最大信息系数的特征变量选择
如果将提取的所有变量都带入模型中,则会导致信息冗余和模型的可解释性降低,因而要对特征变量进行筛选。常用的变量降维方法有Pearson相关系数(PC)和随机森林重要性(RF)等。其中,PC是判断变量之间线性关系的强弱,且可以表示出变量的单调性,但PC只对线性关系敏感,对于非线性变化的变量则无法用其数值来体现,某一些特征变量可能与蓄积量存在非线性关系[15];随机森林(RF)选择变量是通过决策树算出每个变量平均减少了多少不纯度,并把它平均减少的不纯度作为特征选择的值,但是这种方法存在偏向,对具有更多类别的变量会更有利,所以这中变量的降维方法主要用于图像的分类[16]。
最大信息系数(MIC)是通过对连续型变量实施不等间隔的离散化寻优来挖掘变量之间的线性和非线性关系,同时还可以广泛地挖掘出特征之间的非函数依赖关系[17]。最大信息系数的计算方法如下:
利用互信息和网格划分方法来进行计算.其中互信息可以看成一个随机变量中包含的关于另一个随机变量的信息量,或者说是一个随机变量由于已知另一个随机变量而减少的不肯定性。在本实验中,森林蓄积量(F)与遥感变量(R)的互信息I(F;R)定义为
式中:P(F,R)为F和R的联合概率密度;P(F)和P(R)分别为F和R的边缘概率分布密度。
将F分别与每一个R看作为一个数据集A,把F的取值范围划分为a个区间,R的取值范围划分为b个区间,这样在F-R的散点图上来看,所有的点就被分为a×b个区间,数据集A在不同的区间划分方法中,会得到不同的数据分布情况,不同区间划分方式中的最大值即为最大信息值,经归一化处理后得到最大信息系数(MIC),其数学表达式为:
式中:B(n)=n0.6。
最大信息系数是衡量两个变量之间相关性(包括线性相关和非线性相关)大小的一种标准,由公式可知,其取值分布在0到1之间,取值越大,则说明相关性越强,反之则越弱。
最大信息系数相比于线性相关系数具有普适性和公平性的优点[18]。当样本数足够多时,最大信息系数可以反应出变量之间的线性和非线性关系,同时也能反映出非函数依赖关系的强弱,并且能为不同类型的单噪生成都相似的关系给出相近的最大信息系数值。
2.4 支持向量机回归模型的构建
支持向量机模型的主要思想是将低维空间中的向量用非线性函数映射到一个高维特征空间,在高维空间中寻求线性回归超平面,从而解决低维空间中的非线性问题[19]。在支持向量机回归模型中,核函数的选择是极为重要的一个环节,选择不同的核函数将会直接影响模型的预测性能[20]。因此,本实验应用4种常见的核函数(见表3)构建了4种支持向量机模型(多项式核的PK-SVR模型、径向基核的RK-SVR模型、拉普拉斯核的LK-SVR模型和Sigmoid核的SK-SVR模型[21]),探讨最适合用于森林蓄积量估测的核函数。

表3 支持向量机核函数
2.5 模型评估
本研究中,应用十折交叉验证方法并计算模型预测结果的决定系数(R2)和相对均方根误差(RRMSE)对模型进行精度验证与评价[22]。
3 结果与分析
3.1 遥感变量选择
由表4可知,通过计算遥感变量与森林蓄积量的最大信息系数将遥感变量进行排序,其中最大信息系数最高的前10个变量,由于部分遥感变量间存在较为严重的共线性问题,如这10个变量中的蓝波段与绿波段,通过共线性诊断,最后确定建模的遥感变量为B3、IARV、IEV、IRV25、ISAV0.35。

表4 遥感变量最大信息系数
3.2 不同模型估测的森林蓄积量
由图3可知,4种不同核函数的支持向量机回归模型均取得了较好的拟合结果,其决定系数(R2)均大于0.5,其中多项式核的模型拟合结果最好,其决定系数(R2)为0.61。

图3 5种模型实测值与预测值散点图
由图4可知,4种不同核函数的支持向量机回归模型的预测结果的样本残差值都在100m3·hm-2之内,当蓄积量真实值在小于300m3·hm-2时,残差基本均匀分布在X轴两侧,当真实值大于300m3·hm-2时,残差基本都在X轴上方且远离X轴,表示模型对该样本存在较为严重的低估。
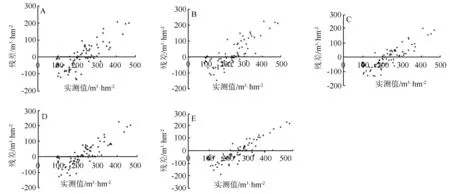
A为多项式核的模型(PK-SVR);B为径向基核的模型(RK-SVR);C为拉普拉斯核的模型(LK-SVR);D为Sigmoid核的模型(SK-SVR);E为多元线性回归模型(MLR)。
由表5可知,4种不同核函数的支持向量机回归模型的估测精度均明显高于多元线性回归模型,相对均方根误差比多元线性回归模型降低了5~10个百分点,其中多项式核模型的估测结果最佳,其决定系数为0.61,均方根误差为69.26m3·hm-2,相对均方根误差为31.2%。
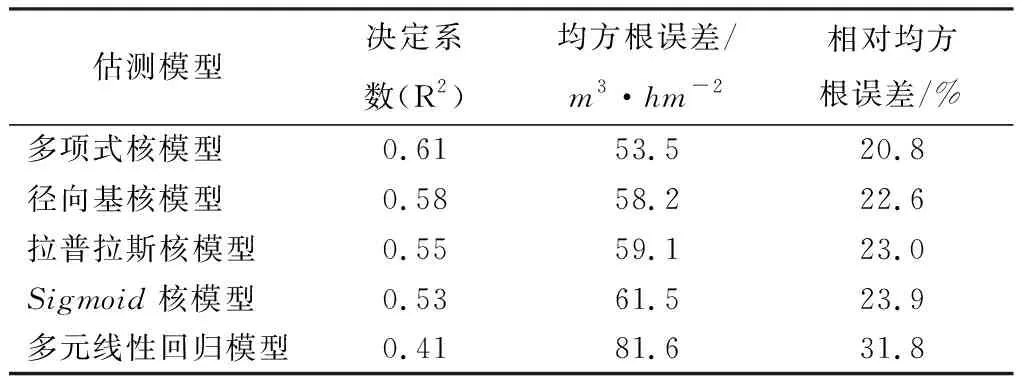
表5 不同模型的预测结果
3.3 4种不同核函数模型估测的森林蓄积量空间分布
由图5可知,4中模型对于研究区的总体蓄积量估测分布规律基本一致,总体来说,研究区南部及东南部森林分布较为集中,蓄积量较大;在北部及中部地区,人为活动较多,森林覆盖相对分散,蓄积量较小。

PK-SVR为多项式核的模型,LK-SVR为拉普拉斯核的模型,LK-SVR为Sigmoid核的模型,PK-SVR为径向基核的模型。
4 结论与讨论
本研究以湖南省株洲市为研究区,以Landsat8OLI数据作为遥感数据源和同时期的林业二调数据,分别构建了多项式核模型(PK-SVR)、径向基核模型(RK-SVR)、拉普拉斯核模型(LK-SVR)、Sigmoid核模型(SK-SVR)和多元线性回归模型(MLR)等蓄积量估测模型,并使用十折交叉方法进行精度验证,得到了以下结论:利用Landsat8OLI数据进行森林蓄积量的估测时,4种核模型均取得了较好的拟合结果,并且其均方根误差都低于25%,说明使用Landsat8OLI遥感数据构建核蓄积量估测模型是可行的;4种核模型的估测结果均明显优于多元线性回归模型,RK-SVR模型取得了最佳的估测结果,说明径向基核函数在4种核函数模型中对森林蓄积量估测的精度最高。
核模型比传统的线性模型更强的蓄积量估测能力,通过4种不同的核函数进行对比,当核函数不同时,核模型的蓄积量预测结果有明显的差异,可见核函数的选择对核模型的预测结果具有决定性的作用。通过残差分析发现,当蓄积量的真实值小于300m3·hm-2时,各模型的预测结果相对于总体来说较为准确并且残差均匀的分布在X轴两端;当蓄积量真实值大于300m3·hm-2时,几种模型的预测结果并不理想,均存在着较为严重的低估。当蓄积量大于300m3·hm-2时,森林的光谱反射率达到饱和,随着蓄积量的增加,其光谱值不再发生变化,导致使用数学模型对大蓄积量样本进行预测时,估测值始终在300m3·hm-2左右。因此,在预测蓄积量较大的成熟林或过熟林时有待进一步研究。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高二数学)(2021年12期)2021-04-26
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
娃娃乐园·3-7岁综合智能(2017年9期)2018-02-01
娃娃乐园·3-7岁综合智能(2017年8期)2018-02-01
娃娃乐园·3-7岁综合智能(2017年7期)2018-02-01
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
新高考·高二数学(2014年7期)2014-09-18
福建中学数学(2011年9期)2011-11-03
