
基于局部上下文和GCN的方面级情感分类模型
2022-03-28 06:31郑阳雨蒋洪伟
北京信息科技大学学报(自然科学版) 2022年1期
郑阳雨,蒋洪伟
(北京信息科技大学 信息管理学院,北京100192)
0 引言
近年来,很多人在各种电商网站的评论区及其他社交平台上发布评论来表达自己的情感或观点,社交平台文本数据呈指数级增长。对这些海量数据进行情感分析有助于获取用户的态度信息,了解用户的真正需求,帮助企业做出判断和决策。方面级情感分析就是要获取商品各方面(方面表示商品的属性或特征)的情感[1]。
传统机器学习方法通常通过构建情感词典或情感特征,再使用朴素贝叶斯模型(naive Bayesian model,NBM)、支持向量机(support vector machine,SVM)等分类器进行情感分类[2-3]。但是人工构建特征工程耗费大量的人力,有时需要结合语法分析等外部知识,模型的灵活性较差。
近年来兴起的深度学习方法能够自动学习方面和上下文的低维表示,较好地弥补了机器学习方法的缺陷。其中深度学习方法使用的预训练语言模型将自然语言用向量表示,通过对向量的操作来学习自然语言的交互特性。在最具影响力的语言模型中,Devlin等[4]提出的基于转换器的双向编码器表示(bidirectional encoder representations from transformers,BERT)预训练模型使用双层的Transformer结构在大型语料库上训练,摒弃了卷积神经网络(convolutional neural network,CNN)和循环神经网络(recurrent neural network,RNN)的结构,取得了突破性进展。Zeng等[5]认为方面的情感极性与相近的上下文更相关,提出了局部上下文关注(local context focus,LCF)机制,能更准确地预测方面的情感。Tang等[6]将目标方面和上下文综合考虑完成对句子的语义建模。Wei Xue等[7]基于CNN和门控机制提出的基于方面词嵌入的门控卷积网络(gated convolutional network with aspect embedding,GCAE)模型易于并行训练。Zhang等[8]在句子的依存关系树上建立神经网络,来利用句法信息和单词的长距离依赖关系。
许多研究将注意力机制[9]和神经网络结合,关注句子中更重要的部分。梁斌等[10]将CNN和多种注意力机制结合,与单纯的CNN、基于单注意力机制的CNN和基于注意力机制的长短时记忆(long short-term memory,LSTM)网络模型相比,取得更好的情感分类效果。Song等[11]针对RNN难以获得由时间截断的反向传播带来的长期依赖关系,采用注意力机制构建上下文和方面之间的模型。Ma等[12]通过方面和上下文的交互式学习提高情感分类性能。Huang等[13]通过注意力机制为方面和句子建模,模型性能优于以前基于LSTM的模型。
以上神经网络算法虽然考虑了方面的局部上下文,但忽略了其中隐含的情感信息。本文基于LCF模型,将门控卷积网络(gated convolutional network,GCN)[14]作为补充,进一步选择与方面相关的情感特征,并且采用表现出色的BERT预训练模型获得词嵌入,用于情感分类。
1 模型结构
为了进行方面级情感分析,本文提出一种基于局部上下文和门控卷积网络的方面级情感分类模型(aspect level sentiment classification model based on local context and gated convolutional network,LCGCN)。模型结构如图1所示,共包括5层:第一层是词向量输入层,使用预训练的BERT模型对输入的文本进行编码;第二层是动态加权层,使用上下文特征动态加权(context features dynamic weighted,CDW)的方法[5]捕捉局部上下文和方面的相关信息;第三层是门控卷积层,使用GCN捕捉与方面相关的情感特征;第四层是注意力层,采用多头自注意力(multi-head self-attention,MHSA)机制捕捉句子内部的语义关联;最后是输出层,使用Softmax分类器计算情感极性的概率分布,完成情感极性分类。

图1 LCGCN模型结构
1.1 词向量输入层
该层的任务是将语言文字映射为低维向量。本文使用BERT模型获得词嵌入矩阵,来获取文本的双向语义关系,充分抓取文本的语义特征。面对词语在不同句中拥有不同语义的问题,使模型更好地理解句子的整体语义,模型捕捉局部上下文特征的同时构建全局上下文表示。
局部上下文是指方面的邻近词,且与方面的语义相关。为了确定句子中的哪些词是方面的局部上下文,将评论语句作为初始局部上下文序列,使用CDW方法捕捉局部上下文特征。全局上下文包含词与词在句子层次上的依赖关系,为了充分保留句子的整体语义,并学习全局上下文和方面之间的相关性,把整个评论语句和方面词组合成句子对,作为全局上下文序列,例如“All of my co-workers stated that the food was amazing”,对于方面“food”,“that the”和“was amazing”可定义为“food”的局部上下文,它们与“food”的语义更相关,而全局上下文考虑整条语句,来学习方面的特征。
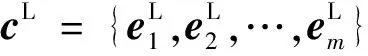
1.2 动态加权层
该层对全局上下文不做处理,以充分保留方面信息和句子的整体语义。为了捕捉方面和局部上下文的相关信息,本文采用Zeng等[5]提出的语义相关距离(semantic-relative distance,SRD)衡量初始局部上下文单词和特定方面的相关程度,接着使用CDW方法[5]获得与方面语义相关的上下文特征。
第i个位置的上下文词和特定方面之间的语义相关距离定义为
(1)
式中:p为方面的中心位置;m为方面的长度。当di高于阈值时,语义相关的局部上下文的特征将得到绝对保留,而当di不超过阈值时,与语义较不相关的局部上下文的特征将得到加权衰减,因此需要为每个局部上下文词构造特征向量来对特征加权,第i个位置的局部上下文词对于特定方面的语义相关的权重向量定义为
(2)
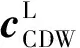
(3)
1.3 门控卷积层
门控卷积层采用GCN选择与方面相关的情感特征,GCN包含卷积网络和门控单元,卷积网络用于提取不同粒度的上下文特征,且通过并行计算减少运行时间,门控单元输出情感特征。
(4)
式中:frelu为ReLU激活函数,Wa和Va为权重矩阵;ba为偏置;a表示方面特征。
(5)
式中:ftanh为Tanh激活函数:Ws为权重矩阵:bs为偏置:s表示情感特征。选择方面特征和情感特征的相关信息:
cGCN=s·a
(6)
式中:cGCN是与方面相关的情感特征;“·”为向量点积。
1.4 注意力层
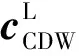
ocon=[cGCN;cG]×Wo
(7)
式中:“;”表示水平拼接;Wo为权重矩阵。
MHSA首先计算注意力分数,再对输入句子加权求和,在不同子空间中获得句子内部的语义关联。本文使用缩放点积注意力(Scaled dot-product attention,SDA)函数计算词的注意力分数:
(8)
(9)
式中:Q、K和V通过注意力层的输入ocon和各自的权重矩阵Wq∈Rdh×dq、Wk∈Rdh×dk、Wv∈Rdh×dv相乘得到,维度分别为dq、dk、dv,它们都通过dh/h得到,dh为隐藏层的维度,h为头的数量,fSoftmax表示Softmax函数。
假设第i个头部学习到的注意力表示为
Hi=fSDA(Qi,Ki,Vi)
(10)
式中:Qi、Ki、Vi是在第i个头部通过注意力层的输入和权重矩阵相乘得到。所有头部学习到的注意力将拼接起来,对输入特征表示加权,再经过一次线性映射得到注意力层的输出oMHSA:
oMHSA=ftanh({H1;H2;…;Hh}·WMHSA)ocon
(11)
式中:“;”表示向量拼接;ftanh为Tanh激活函数,以增强该层的学习能力;WMHSA为权重矩阵;oMHSA为注意力层的输出,包含句子内部的语义关联。
1.5 输出层
该层的任务是输出每条评论语句中方面的情感极性,包括积极、中性和消极3种情感。取出特征矩阵的第一条向量,它汇集了该矩阵的所有信息,再经过线性变换并输入到激活函数中得到特征表示:
xpool=ftanh(oMHSA[:,0]·Wd×d)
(12)
式中:oMHSA[:,0]表示特征矩阵oMHSA的第一条向量;Wd×d表示维度为d×d的权重矩阵;d为隐藏层的维度;ftanh表示Tanh激活函数。将xpool输入到全连接网络中,得到最终表示:
xdense=xpool·Wd×C
(13)
式中:Wd×C表示维度为d×C的权重矩阵;d为隐藏层的维度;C为情感类别的数量。最终使用Softmax预测情感极性y:
(14)
式中,fSoftmax为Softmax函数。
1.6 模型训练
本文通过最小化交叉熵损失函数对模型进行训练和更新,得到最优模型参数。由于中性情感是一种非常模糊的情感状态,标记中性情感的训练样本是不可靠的,因此在损失函数中加入标签平滑正则化(label smoothing regularization,LSR)[15],来防止模型在训练过程中给每个训练实例分配完全的概率,进而减少过拟合,如用0.1和0.9的平滑值替换分类器的完全概率0和1。
对于训练样本x,原始的真实分布为q(c|x),平滑的真实分布q′(c|x)通过LSR计算:
q′(c|x)=(1-ε)q(c|x)+εu(c)
(15)
式中:ε为平滑参数;c为情感标签;u(c)为标签的先验分布,设置为均匀分布u(c)=1/C,C为情感类别的数量。模型将预测分布p(c)和平滑的真实分布q′(c)的交叉熵作为损失函数,损失值为
(16)
2 实验与结果分析
2.1 数据集和参数设置
本文采用的数据是SemEval2014 Task4的竞赛数据集,包含笔记本和餐厅两个领域的用户评论子数据集,有3种情感标签:积极、中性和消极。数据集在不同情感极性下的训练集和测试集评论数量如表1所示。
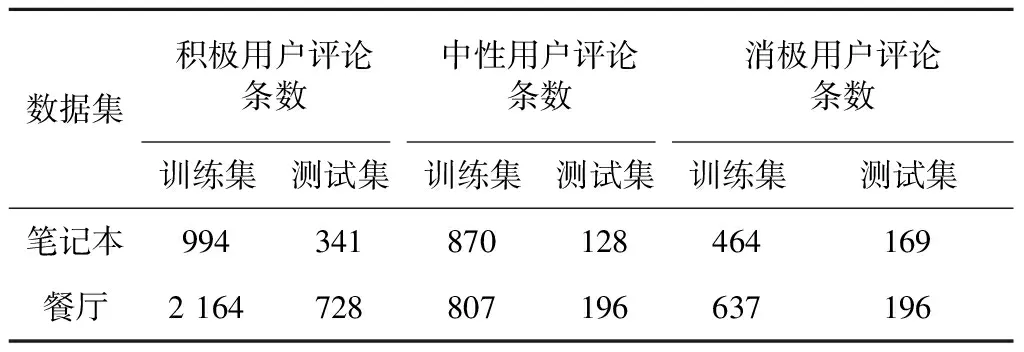
表1 实验数据统计
实验中,Glove[16]词向量维度为300,BERT预训练模型的维度为768。为了避免过拟合,本文在试验中采用了Dropout机制,LCGCN模型在两个子数据集上采用相同的超参数设置,如表2所示。

表2 模型的参数设置
2.2 实验结果与分析
为了全面评价和分析本文模型的性能,在SemEval2014 Task4数据集上进行实验,并与基线模型进行对比。基线模型如下:
1)AOA(attention-over-attention)[13]、交互注意力网络(interactive attention networks,IAN)[12]、基于方面词嵌入的注意力LSTM(attention-based LSTM with aspect embedding,ATAE-LSTM)[17]均使用Glove训练词向量,结合LSTM和注意力机制提取文本特征。AOA使用一个LSTM建模文本,IAN使用两个LSTM为方面和上下文单独建模,ATAE-LSTM按照注意力权重对LSTM的隐层状态加权求和,用于情感分类。
2)特定方面图卷积网络(aspect-specific graph convolutional network,ASGCN)[8]、记忆网络(memory networks,MemNet)[18]、目标独立的LSTM(target-dependent LSTM,TD-LSTM)[6]同样使用Glove训练词向量。ASGCN使用图卷积网络抽取方面特征,MemNet结合深度记忆网络和注意力机制,实现情感分类,TD-LSTM使用两个反向的LSTM分别构建左上下文和右上下文,实现情感分类。
3)GCAE-Glove和GCAE-BERT[7]分别使用Glove和BERT模型训练词向量,结合CNN和门控机制进行情感分类。
4)LCF[5]使用BERT训练词向量,使用CNN和MHSA处理全局上下文和局部上下文,实现情感分类。
为了保证实验结果的准确性,本次实验的模型均运行在相同的实验环境下。各模型的准确率和F1值如表3所示。

表3 各模型的准确率和F1值对比
从表3可以看出,相较于基线模型,本文提出的模型LCGCN在两个数据集上取得了比其他模型更好的分类效果,与LCF模型相比,准确率和F1值提高1~2个百分点,表明GCN能准确选择与方面相关的情感特征。相较于本文模型,GCAE-BERT模型没有区分局部上下文和全局上下文,未能充分获取上下文特征,也没有使用自注意力机制获取句子内部的语义关联,模型准确率和F1值较低。相比于使用Glove训练词向量的模型(如AOA、IAN、ASGCN、ATAE_LSTM、MemNet、TD_LSTM、GCAE-Glove),使用BERT的模型(如LCF、LCGCN、GCAE-BERT)实验效果更好,表明BERT预训练模型能更好地编码词语语义。
仅使用循环神经网络建模句子和方面的模型TD_LSTM效果总体上不够理想,原因是模型很难记住长距离信息,AOA模型和IAN模型都使用了循环神经网络和注意力机制,结果显示在餐厅数据集上IAN的模型效果只差1%~2%,而在笔记本数据集上IAN的准确率和F1值比AOA模型分别高出4%和6%,原因可能是IAN使用了两个LSTM建模方面和句子,有效避免笔记本数据集中方面和句子之间的依赖关系。ASGCN模型与ATAE_LSTM模型相比,忽略了不同上下文信息对方面的重要性,模型效果较差。MemNet模型比基于LSTM的模型效果更好,可能是LSTM通过顺序的方式对所有的上下文执行相同的操作,不能明确反映出每个上下文词的重要性。
3 结束语
本文基于LCF模型进行改进,提出了一种基于局部上下文和GCN的方面级情感分类模型LCGCN,保留了LCF模型中方面的局部上下文与该方面更相关的思想,使用门控卷积网络获得与方面相关的情感特征,采用多头自注意力机制捕捉句子内部的语义关联,还通过标签平滑正则化进一步解决过拟合问题,将BERT向量表示方法用于模型中,增强了模型性能。通过实验将本文模型和已有的模型作对比,证明了本文模型在情感分类任务中的有效性。
在下一步的工作中,考虑将句法结构特征融入到模型中,利用外部知识提高情感分类效果。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
长江学术(2015年1期)2015-02-27
