
基于情境信息迁移的因子分解机推荐算法
2022-03-22 03:35:50孙雨新曹晓梅王少辉
计算机工程与应用 2022年6期
孙雨新,曹晓梅,王少辉
南京邮电大学 计算机学院,南京 210000
根据互联网数据中心的预测报告[1]显示,到2025年全球的数据量将达到163 ZB,将会是现在的3~4倍。从大量信息中获取有效信息时,推荐系统作为一种信息筛选的工具,可以给用户提供良好的使用体验。推荐算法作为推荐系统的核心,帮助用户发现其感兴趣的项目,被应用于各大商业平台,发挥其独特的价值[2]。
传统推荐算法大多使用用户对项目的评分记录作为用户偏好的评价指标,通过计算用户或项目之间的相似度来生成推荐。虽然这种推荐方式应用广泛,但是评分记录数据通常比较稀疏,用户或项目之间存在联系较少,往往较难发现相似用户或项目,影响推荐准确率。与此同时,用户的兴趣偏好往往容易受周围环境影响,而仅使用评分记录的传统推荐算法未考虑这一影响,容易导致推荐结果过于单一,个性化程度低。随着当前计算机技术的迅速发展,数据收集系统在获取用户评分记录的同时,还能获取相应的情境信息(时间、地点、用户的年龄、性别等),充分利用这些信息可以使推荐更加客观、全面、精准[3]。目前,一些已有的推荐方案通过数据挖掘、机器学习等方法[4-9]处理情境信息,分析某些情境对用户偏好的影响,然而这些方法大多是针对某一情境信息进行数据集过滤划分,只利用特定情境信息下的数据样本,然后使用协同过滤推荐算法进行推荐预测。这些方法虽然可以利用情境信息提高推荐的个性化程度,在一定程度上提高推荐准确性,但是只使用特定情境下的数据样本进行数据集过滤划分,可能会产生样本数据不足、整体样本集利用率低下的问题,在训练数据不足的情况下会直接导致推荐结果单一,不能适应情境变化情况,最终反而致使推荐准确度下降。同时,结合了情境特征的多维评分矩阵会存在部分无关和冗余的特征,以及噪声数据等问题,进一步导致算法复杂度提高,影响推荐准确性。
针对这些问题,本文在传统推荐算法基础上提出了一种基于情境信息迁移的因子分解机推荐算法(factorization machine recommender algorithm based on the context information transfer,CITr-FM),该算法在充分利用多维情境信息的基础上,首先进行特征评估和筛选,计算不同情境特征的价值,去除多余特征求出最佳情境特征子集,再根据情境特征子集和特定情境信息划分数据集,将原数据集划分为满足特定情境信息的目标域数据集和不满足的源域数据集;其次利用迁移学习的自适应增强方法对源域数据集进行权重调整、样本迁移,最终得到符合特定情境信息的整体样本集,充分利用整体样本集,保证足量的训练数据,解决样本利用率低的问题;最后使用因子分解机[10]对调整后的数据样本进行推荐评分预测,利用因子分解机的特征组合和因子分解方法实现维度约简,降低模型复杂程度,同时有效缓解多维关系模型的稀疏性问题。分析和仿真实验表明,CITr-FM算法在充分利用情境信息进行个性化推荐的同时,又能解决预过滤引起的样本集利用率低问题,同时有效缓解多维评分数据存在的稀疏性问题,提高推荐的准确度。
1 相关工作
推荐算法多种多样,Manouselis等[11]将推荐算法分为三大类:(1)基于内容的推荐:根据用户给出的偏好信息,计算用户项目之间的相关性,推荐给用户相似的项目;(2)基于协同过滤的推荐:根据用户给出的部分项目的已知偏好信息,预测当前用户对于其他未评分项目的潜在偏好,或者利用部分对当前项目的偏好数据,预测指定项目的未评分用户的潜在偏好;(3)混合推荐:按照不同的混合策略将各种推荐算法进行组合。此外,Cai等[12]使用标签特征向量表示用户兴趣特征,根据单一隐式信息进行推荐;陈碧毅等[13]提出融合显式和隐式反馈信息的推荐算法;以及使用深度学习技术[14-15]的分层推荐模型都展示了推荐算法的不同研究方向。
近年来,随着情境信息在提高推荐精确度和用户满意度的作用日益显著,推荐算法中结合情境信息进行个性化的推荐的研究在不断增多。Wu等[6]阐述了情境信息的产生以及情境信息在丰富用户行为,刻画用户和项目背景,进而有效辅助分析用户偏好并建立用户模型起到的作用。情境信息预过滤能够筛选出满足特定情境信息的部分样本集,Adomavicius等[4]提出一种基于维度约简的预过滤推荐算法,将用户项目数据样本按照单一情境信息划分,然而预过滤方法只使用划分后特定情境信息下的数据样本,样本利用率较低并存在数据稀疏问题。Baltrunas等[7]考虑情境划分的方式,利用时间信息进行自适应分割将数据划分成多个代表类,但是该方法仍存在划分后的数据稀疏和样本利用率低问题。以上几种推荐算法都是利用单一情境进行用户聚类划分,而对于包含多维情境信息的用户评分模型,往往存在特征冗余和高维空间的数据稀疏问题,距离函数难以生效,无法进行有效的聚类划分。罗国前等[8]引入情境感知方法,在算法中加入了全局偏置和情境偏置进一步提高个性化推荐的准确度。Gu等[9]提出了一个情境感知矩阵分解模型AlphaMF,利用矩阵分解模型模拟用户隐式反馈,利用线性上下文特征和隐式反馈进行推荐,有效缓解冷启动问题。Oku等[16]利用SVM(支持向量机)处理高维数据模型,进行数据划分。由于直接使用机器学习模型处理高维数据,导致整体模型的复杂程度提高,并且花费较长时间构造和更新预测模型。
推荐算法经常面临着随着用户和项目数量增长导致的数据稀疏问题。研究结果表明,将迁移学习应用在推荐算法[17]可以在不改变原有数据的基础上,引入外部数据辅助原有数据生成推荐。Pan等[18]介绍了使用迁移学习对数据样本进行分布趋近处理,保证整体样本同分布的同时有效扩充原有数据样本,缓解稀疏问题。Li等[19]提出一种使用外部数据跨域迁移的CBT算法,将其他领域中密集数据信息的评分矩阵迁移到目标领域的稀疏评分矩阵中,以两个领域的评分模式的聚类信息作为桥梁,传递辅助信息中的有用信息。葛梦凡等[20]对不同领域数据集中的项目标签进行跨域迁移,结合不同领域标签计算目标域主题偏好,缓解目标域数据稀疏问题。这些方法在进行跨域处理时,会存在不同领域间用户、项目信息的异构问题,利用相似领域或者同领域的不同数据则能缓解此问题。Pan等[21]讨论了一种半监督协同过滤推荐算法,使用自适应性迁移学习迭代处理,将隐式信息整合到显式信息中。该方法在有效缓解数据异构问题的同时在显式信息充分融合隐式信息缓解稀疏性问题。
将情境信息融入用户-项目二元关系模型中生成多维评分模型的推荐算法,会存在一定的数据稀疏问题,利用矩阵分解可以缓解此问题。文献[22-23]充分利用标签信息、时间和信任关系等这些额外信息对用户偏好的影响,结合矩阵分解方法对多维信息进行降维,降低算法复杂程度同时缓解评分矩阵稀疏性问题。此后,Rendle提出了因子分解机模型,该模型可以处理包含任意实值的特征向量,使用矩阵分解引入隐向量解决多特征引起的模型复杂问题,使用因子化参数来建立特征变量的联系并通过交叉项特征缓解数据稀疏问题,提升预测的准确性。该方法保证了高维特征交互的可靠估计和模型的线性训练时间。胡亚慧等[24]在使用因子分解机的同时,利用文化差异这一用户背景信息对用户兴趣偏好的影响,针对不同情境下的用户文化背景进行用户兴趣预测。因子分解机在有效利用用户背景信息的同时又能缓解数据稀疏,进行个性化推荐。但该方法仅将多维特征信息利用因子分解机进行推荐模型预测,没有对情境信息进行分析处理,不能充分利用情境信息的价值。
通过实验对各种推荐算法进行验证比较后,得出本文提出的CITr-FM算法在进行推荐预测上的优势如下:(1)充分利用情境信息对用户偏好的影响,提取重要情境特征进行数据样本预过滤划分,可以提高推荐的个性化程度。(2)对划分后的部分数据使用迁移学习方法,调整数据分布,无需引入外部样本,提高样本利用率的同时使用因子分解机缓解稀疏性问题。(3)发挥情境信息在个性化推荐中的作用,提高推荐准确度。
2 基于情境信息迁移的因子分解机推荐算法
本章主要对CITr-FM算法的问题进行形式化定义,同时对算法进行理论分析论述和过程描述,并给出相关的流程图。
2.1 问题定义
为了便于形式化的描述,本文的符号标记见表1。

表1 符号定义Table 1 Definition of symbols

针对不同的使用场景,可以使用不同的情境信息。利用情境信息进行用户个性化推荐,在传统用户项目评分矩阵的基础上加入额外的环境情境信息构造多维评分矩阵,通过给定的用户信息U、项目信息I、情境信息C训练出预测模型。对于评分矩阵中存在的未知评分,可以通过预测模型计算相应评分,该评分代表了用户u在特定的情境C下对项目i的喜好程度。
2.2 算法设计
在本文中,为了充分利用环境情境信息,构建包含环境情境信息的特征矩阵,对用户-项目-环境情境多维信息进行one-hot编码[25],编码后的矩阵信息更便于进行特征重要性评估,处理后的数据形式如图1所示。
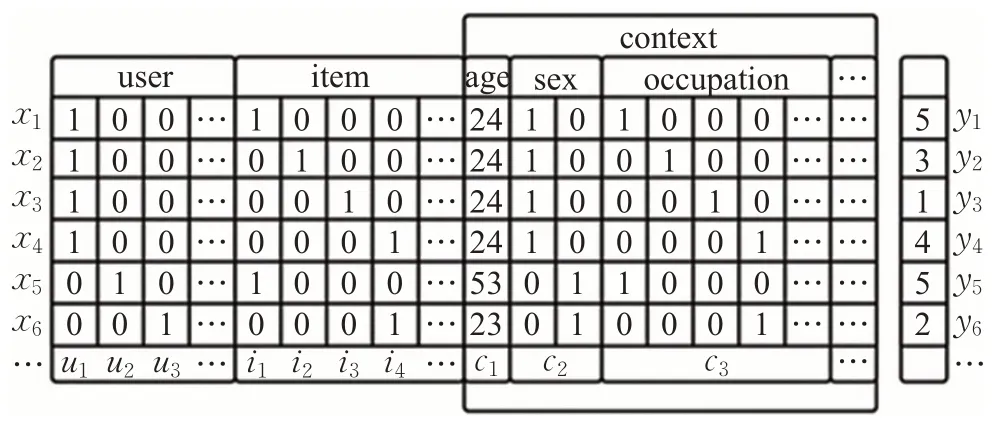
图1 用户-项目-环境情境信息评分矩阵Fig.1 User-item-environmental situation information scoring matrix
其中每一行表示用户u对项目i在环境情境c下的评分记录yi。以第一条记录x1为例,用户u1对项目i1在环境情境c11的条件下的评分y1为5分。原本m×n的用户项目评分矩阵转换为a×(b+1)的用户评分记录矩阵,其中a为评分个数,b为编码后的特征维度。
对编码处理后的多维关系模型,使用CITr-FM算法建立推荐模型。CITr-FM算法主要分为以下三个阶段:(1)情境预过滤:筛选重要特征然后根据筛选后的特征子集进行情境信息预过滤,得到满足当前情境信息的数据样本集Tt和其余数据样本集Ts;(2)样本迁移:利用迁移学习方法,将过滤后的样本集Ts,使用满足当前情境信息的Tt数据集进行样本权重调整和评分再预测,得到Ts调整后的数据样本(Xs,Ys);(3)推荐预测:调整后的样本集Ts和原样本集Tt合并为一个数据集T,将该数据样本集放入因子分解机模型进行推荐模型训练,充分利用情境信息对用户偏好的影响,最终预测用户对项目的偏好程度。整体算法的流程图如图2所示。
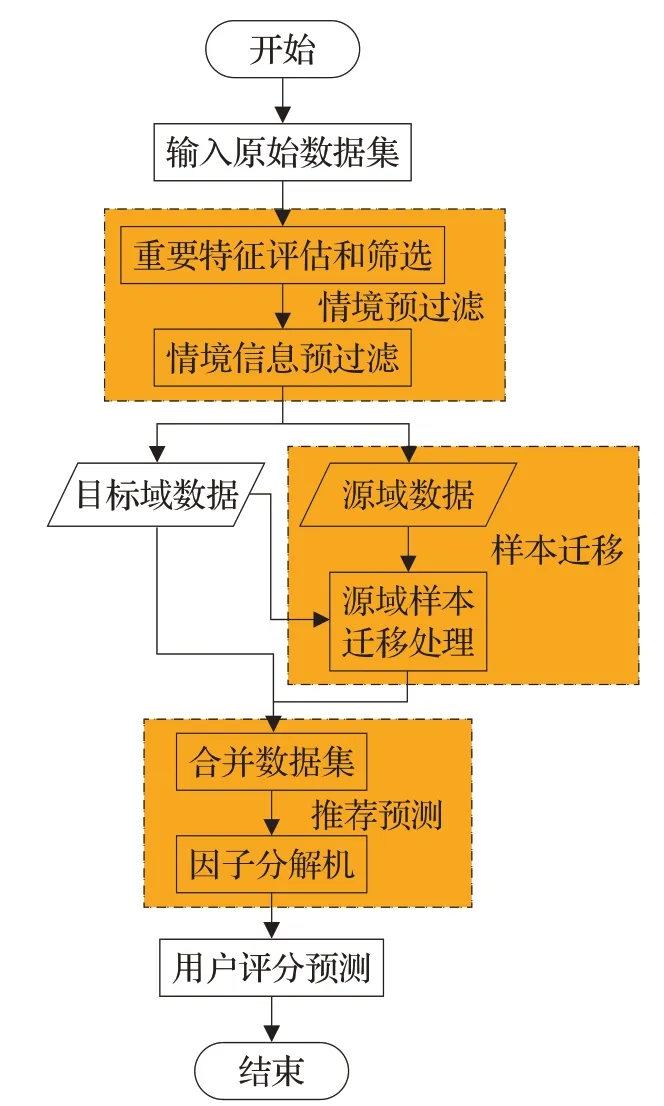
图2 CITr-FM算法流程图Fig.2 Flowchart of CITr-FM algorithm
2.3 算法实现
根据算法设计提出的内容,本文提出的CITr-FM算法的具体实现过程如下。
2.3.1 情境预过滤
传统推荐算法使用聚类算法来计算用户相似度,进行数据集分类,在加入情境信息的多维关系模型中,使用聚类算法不仅会提高计算复杂度,而且对高维数据进行聚类可能会失效。此外,不同数据集都需要考虑情境信息对用户的偏好的影响价值,并不是所有情境特征都会对推荐结果产生有效影响,冗余的情境特征[3]会提高算法复杂度,影响推荐准确度。对此,首先需要对包含情境特征的数据样本进行重要特征的筛选,本文使用XGBoost[26]算法进行特征重要性评估,相较于传统特征选择算法,XGBoost可以有效防止过拟合,同时进行并行优化,考虑数据集稀疏情况,大大提高算法的效率;然后根据特征重要性对环境情境特征进行排序,建立特征子集Xsub并利用前向搜索的思想依次往特征子集中放入排序后的特征;最后对不同的特征子集建立评分预测模型,计算不同特征子集下模型的AUC指标的值Rsub,将最优AUC指标的情境特征子集作为最优子集Xsub,并根据保留的多维重要特征Xsub和指定情况下的情境特征ck进行情境预过滤,将原数据集划分为两个子集Tt和Ts。
利用XGBoost筛选重要特征并进行情境信息预过滤的过程如图3所示。
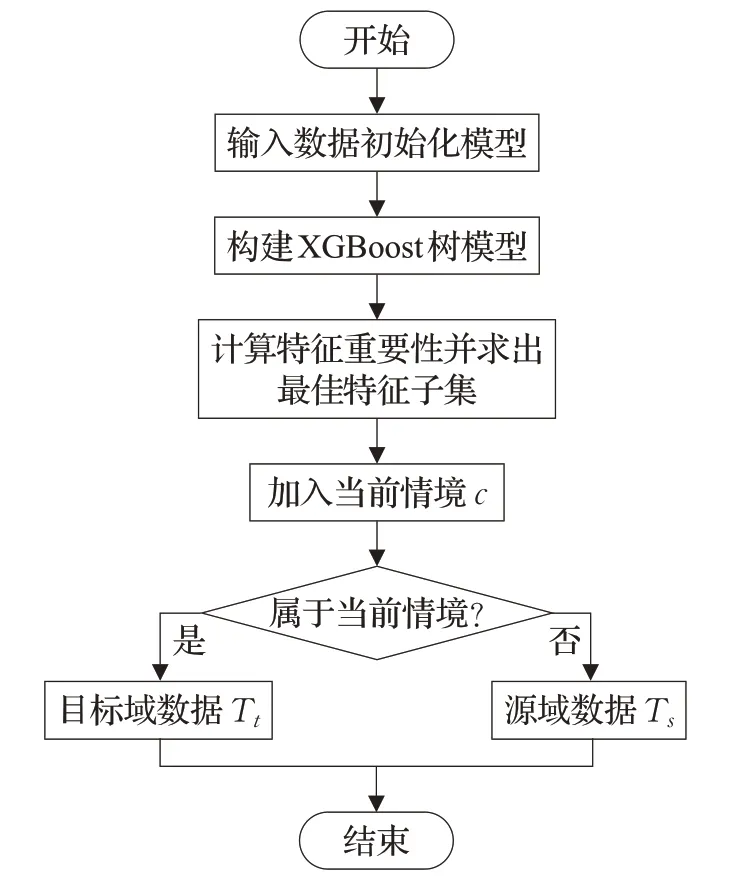
图3 情境预过滤流程图Fig.3 Flowchart of situational prefiltering
情景预过滤的主要步骤为:
(1)依次构建XGBoost树模型,直到整棵树深度到达M,构建过程中估计叶节点区域的值,能使得目标函数Loss尽可能小,最终得到回归树模型f(x)。
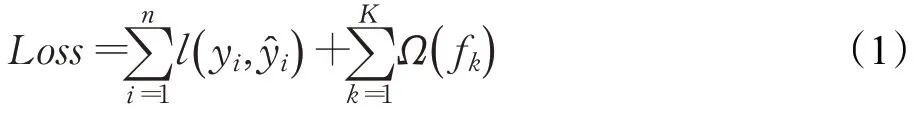
其中,第一部分为损失函数,第二部分为L2正则项。
(2)从顶至下遍历整个树模型,计算情境特征重要性,然后建立特征子集初始为空,前向搜索依次加入特征,顺序为排序后重要性从大到小,并在特征子集上进行建立预测模型,通过AUC指标Rsub求得最优特征子集Xsub。
(3)保留最优特征子集,对原评分记录进行特征缩减。加入当前情境信息ck,其中,其中j<k,k为最终保留的情境特征c的个数。
(4)对原数据集的评分记录进行情境信息预过滤划分。
通过该部分对原始数据集的处理后,将满足指定情境的数据样本划分为目标域数据Tt,即Xa×b评分记录中context部分中的情境特征与ck中情境特征相符的划分为目标域数据Tt,不相符的则与指定情境相关度较低,划分为源域数据Ts。
2.3.2 样本迁移
传统情境信息预过滤[6-7]方法只使用满足特定情境信息的样本集,这会导致训练样本不足引起模型训练不充分、样本利用率低问题。使用迁移学习方法对数据集进行迁移处理,可以充分利用整个样本集。由于目标域数据Tt和源域数据Ts属于不同的情境条件,因此这两部分的数据作为不同分布的数据集进行处理,源域数据Ts是不可以直接用来进行推荐模型训练。利用样本迁移技术,对与特定情境相关度较低的源域数据Ts进行数据迁移,从而确保源域与目标域的整体数据分布和特征分布相似。对此使用TrAdaBoost[27]算法的思想对划分后的数据集处理如图4。
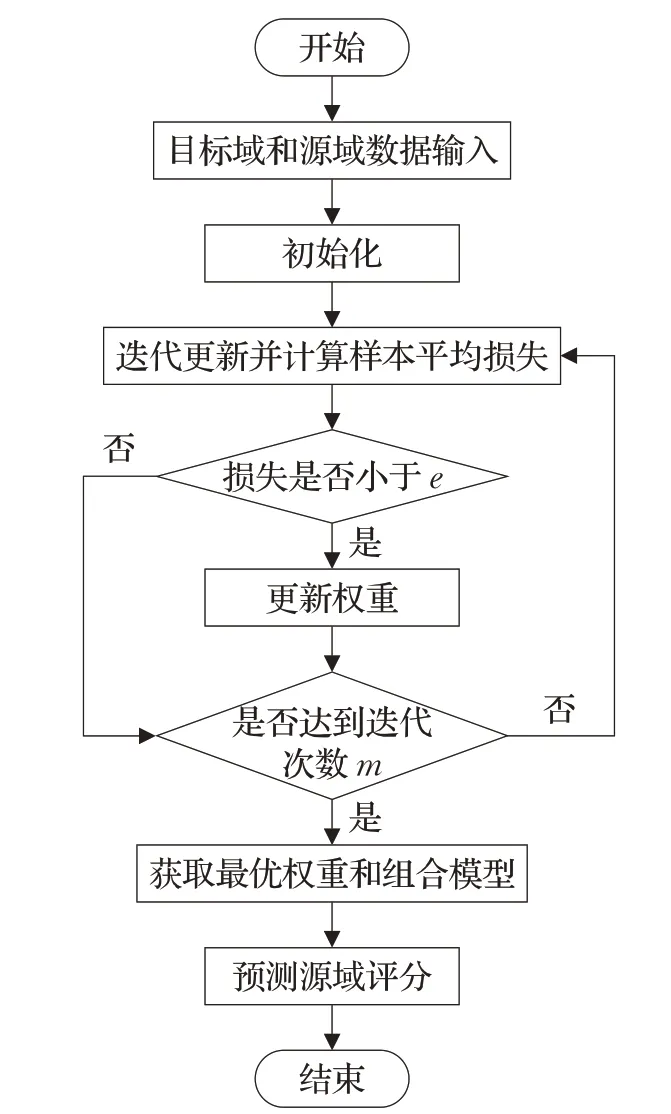
图4 样本迁移流程图Fig.4 Flowchart of instance transfer
经过划分后的目标域和源域数据,将含有评分的数据集Ts(大小为m)和Tt(大小为n)按顺序合并为T,其中前n个为Tt,后m个Ts,设置迭代次数为S。
(1)初始化样本权重向量W1=(w1,w2,…,wm+n),其中w1=w2=…=wm+n=1/(m+n),对样本权重和模型进行迭代更新,直到达到一定的迭代次数S。更新规则为:根据样本权重和整体数据集T训练得到分类器ft(x),计算平均损失εt并判断平均损失是否小于e,如果平均损失εt比e小,则可以进行权重调整。
(2)完成相应的迭代更新后,选择迭代过程中平均损失最小的第i次的样本权重向量Wi及其条件下的组合预测模型f(x)。
(3)源域样本利用调整后的权重向量Wi和组合预测模型f(x)进行样本评分预测,得到新的样本评分。
当需要进行权重更新时,更新的学习率为lr1,并且权重进行如下调整:
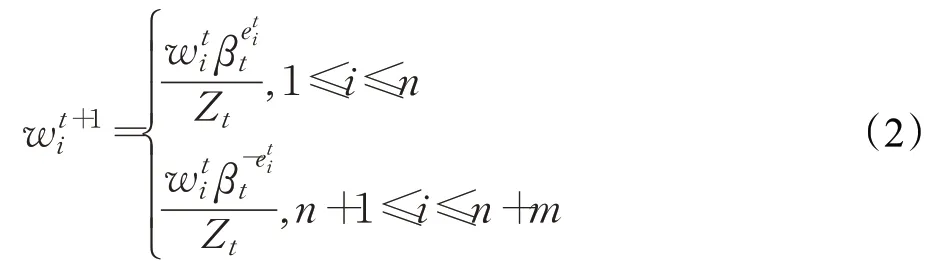
其中,wi为样本权重,Zt为标准化因子,βt为更新梯度。
不同部分的权重调整策略不同,对于目标域样本,如果预测错误,则说明模型欠拟合,需要增大权重;对于源域样本,如果预测错误,则说明不符合目标域数据分布,应该降低其权重。
预测模型使用组合预测器,组合分类器的个数为i,其中i为最佳迭代次数。在得到最优源域样本权重和组合预测器f(x)之后,利用训练好的预测函数f(x)计算源域样本在进行样本迁移,权重调整后的评分Ys=f(Xs),调整后的源域数据为(Xs,Ys)其样本分布和用户偏好更加符合目标域数据。
2.3.3 推荐预测
推荐预测部分主要工作是将样本迁移处理过的源域数据和目标域数据合并,再使用因子分解机建立推荐预测模型。因子分解机将多维的推荐预测问题表示为:U×I×C→R,该预测模型除了使用传统的用户和项目这两个特征外,还可以利用额外特征。本文使用的情境信息将作为额外的特征来提高整体推荐的个性化和准确性,对于输入输出可以表示为:
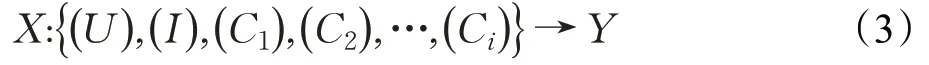
因子分解机在传统的线性函数模型的基础上,引入特征之间的交叉项,学习特征之间的关联信息,主要模型如下:


模型采用梯度下降方法进行参数调优,每一轮的学习率为lr2,在进行一定次数的迭代循环后可以得出最终的推荐预测模型,将源域Ts的样本的评分看成未知,即看作是无监督样本,进而进行用户评分预测。
3 仿真实验及分析
在开源的数据集MovieLens上,进行CITr-FM算法与其他典型推荐算法的对比实验,结果表明了CITr-FM算法的可行性。此外,本文还进一步分析了本文使用的算法的一些重要参数对结果的影响。
3.1 数据集及推荐结果分析
3.1.1 数据集与评价指标
本文实验主要使用Movielens数据集和Book-Crossing数据集,Movielens数据集是由GroupLens Research从MovieLens网站上收集到的关于用户对电影的评级数据,Book-Crossing数据集是Book-Crossing社区的用户对书本的评级数据。关于本文使用的MovieLens-100k、MovieLens-1M和Book-Crossing数据集,其中MovieLens-100k数据集(ML-100k)主要是由943名用户对1 684部的电影产生的共10 000条评级数据,该数据集已经进行了一定的处理,保证了每名用户至少有20条评级数据,并且每部电影有3次评级;MovieLens-1M数据集(ML-1M)主要是由6 040名用户对3 900部电影产生的共1 000 209条评级数据,处理方式同MovieLens-100k数据集;Book-Crossing数据集(Book-C)主要是由92 107名用户对271 379本书籍产生的1 031 175条评级数据,对该数据集进行评级标准化,将数据的评级调整为1~5评级。3个数据集的评分标准都为1~5评级,分数越高表明用户越喜爱,3个数据集相关属性详细统计如表2所示。

表2 数据集统计数据Table 2 Statistics of data set
本文将使用数据集进行迁移处理之后混合数据样本再进行随机划分,其中90%数据作为训练集,10%的数据作为验证集。确保不同数据集之间可以进行对比,统一使用的初始情境特征的C的个数为8,经过特征重要性评估筛选处理后,保留的情境特征个数为6,ck中的情境个数为半数以上。样本迁移中的权重更新误差e设置为0.5,TrAdaBoost算法中分类器的数量为[100,130]较好,学习率lr1为0.005。FM模型的学习率lr2为0.5,L2正则化参数λθ为0.005,隐向量个数k为8的时候,其模型收敛较快,推荐误差较低。
本文使用的评价指标主要为机器学习中常用回归算法的评价指标均方根误差(RMSE)和平均绝对误差(MAE),利用这两种算法可以对推荐结果的准确度进行评价。其公式如下:
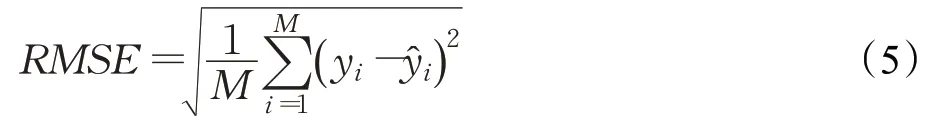
其中,yi表示用户对项目的原始评分,表示推荐算法的预测评分,使用的数据样本都为测试集中的数据包含M个测试样本。

其中,yi表示原始评分,表示预测评分,两个指标的评价结果都是所计算的数值越小,推荐结果更加准确。
3.1.2 推荐结果分析
本文提出的CITr-FM算法主要与以下几种传统推荐算法进行对比:(1)最近邻推荐算法(KNN),(2)非负矩阵分解推荐算法(NMF),(3)奇异值矩阵分解推荐算法SVD,(4)基于隐因子的SVD(SVD++),(5)集合矩阵分解推荐算法(CMF)[28],(6)情境感知矩阵分解算法(CAMF)[9],通过阅读相关算法的参考文献和介绍,并通过实验对相关算法的参数进行了调整,使各个算法的实验结果达到最优值。分别在三个数据集上使用上述推荐算法和本文的推荐算法进行推荐预测,在进行多轮实验后取评价指标的平均值,实验结果如图5所示。
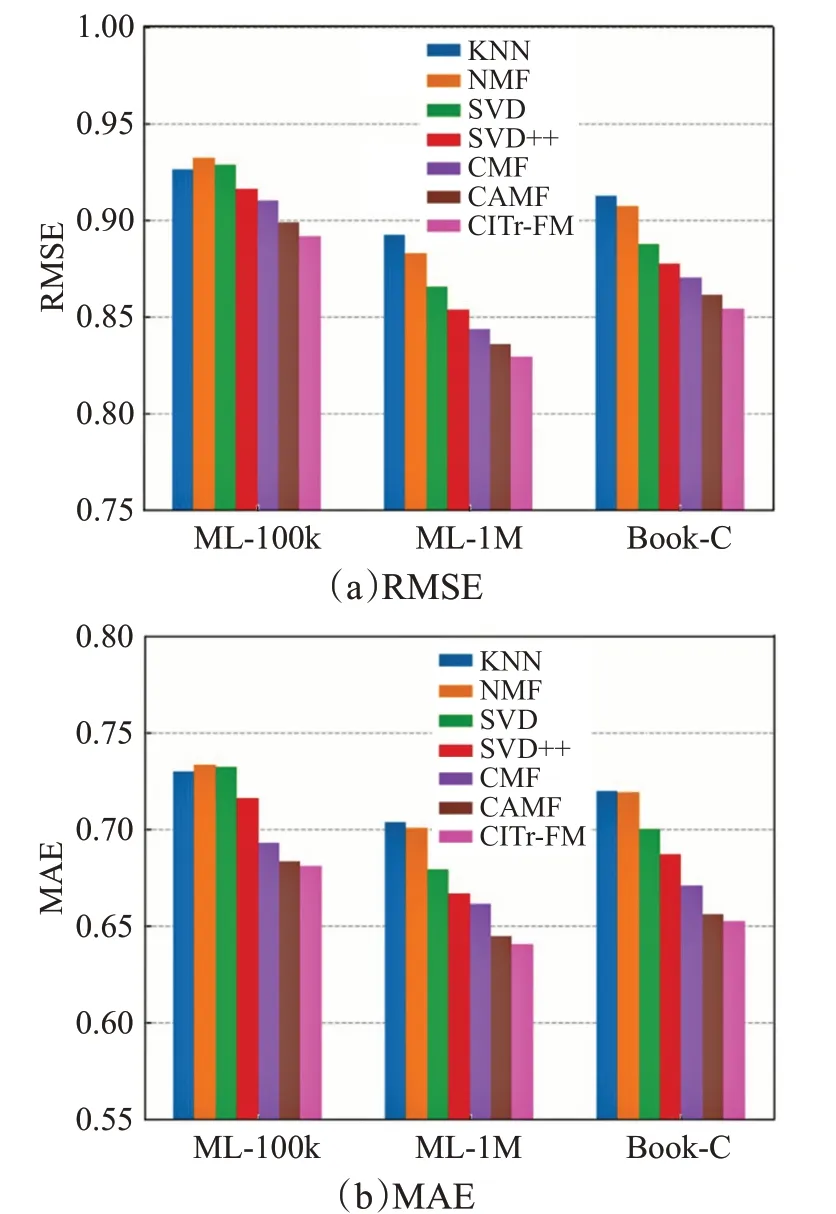
图5 不同数据集上的RMSE和MAE对比Fig.5 Comparison of RMSE and MAE on different data sets
从图5可以看出对于三个不同的数据集,本文提出的推荐算法都比推荐算法有更低的RMSE和MAE指标,并且本文提出的CITr-FM算法是针对特定的情境下进行用户个性化推荐的,因此,在使用测试集进行预测实验时,比传统的推荐算法有着更低的RMSE,预测结果的整体分布更加接近。通过三个数据集的验证,可以发现随着训练样本数据的增多,推荐算法的拟合效果更好,两种指标的误差更小,最终的预测能力更强。此外,通过使用Movielens数据集和Book-Crossing数据集这两种不同领域的数据集进行实验可以发现,对于包含情境信息的不同数据集,本文提出的CITr-FM算法都能比传统推荐算法产生更加准确的评分预测,体现了算法的有效性和适用性。
此外本文还对不同算法使用整体样本集进行多次迭代拟合训练,在使用ML-100k的数据样本进行多次的迭代训练后,各个算法之间的RMSE指标对比如图6所示,给出了在训练集和测试集上,使用数据集进行多次训练后的预测结果的RMSE指标,由图6可知,在随着使用整体数据集进行迭代循环训练的次数上升,算法中模型的拟合程度越来越高,最终参数接近整体最优。多次迭代后通过在测试集上进行验证时会发现,随着迭代次数的增多,预测结果的RMSE指标会先下降后上升,这是由于在进行过多次的epoch之后,造成预测模型过拟合的结果,可以发现当迭代次数在20次左右的时候,使用ML-100k数据样本达到整体最优。
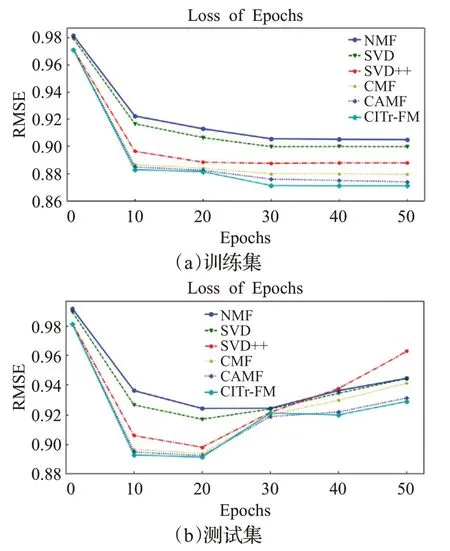
图6 不同算法在训练集和测试集上不同迭代次数的RMSE Fig.6 Different algorithms with different iteration times on training set and test set
3.2 重要参数的影响分析
本文提出的CITr-FM推荐算法的步骤中包含以下几个超参数会对最终推荐结果产生影响:(1)样本迁移算法TrAdaBoost中的分类器个数S和学习率lr1,(2)FM模型中的学习率lr2、正则化参数λθ和隐向量个数k。本次实验还对这些参数进行进一步实验,研究其对于推荐结果的影响。
对于TrAdaBoost算法的分类器个数S和学习率lr1lr1,使用Movielens-100k数据集,在进行情境预过滤后的数据集进行实验。首先固定分类器个数S,调整学习率从0.000 01到0.05并记录TrAdaBoost算法中预测结果的RMSE指标。然后固定学习率lr1和权重更新的阈值e,调整分类器个数从80逐渐增加到250个并记录迁移算法对于目标域数据的预测结果的RMSE指标,结果如图7所示。
由图7可以看出学习率lr1在0.005时,分类器的个数在[110,130]区间,可以获得最佳的迁移效果。
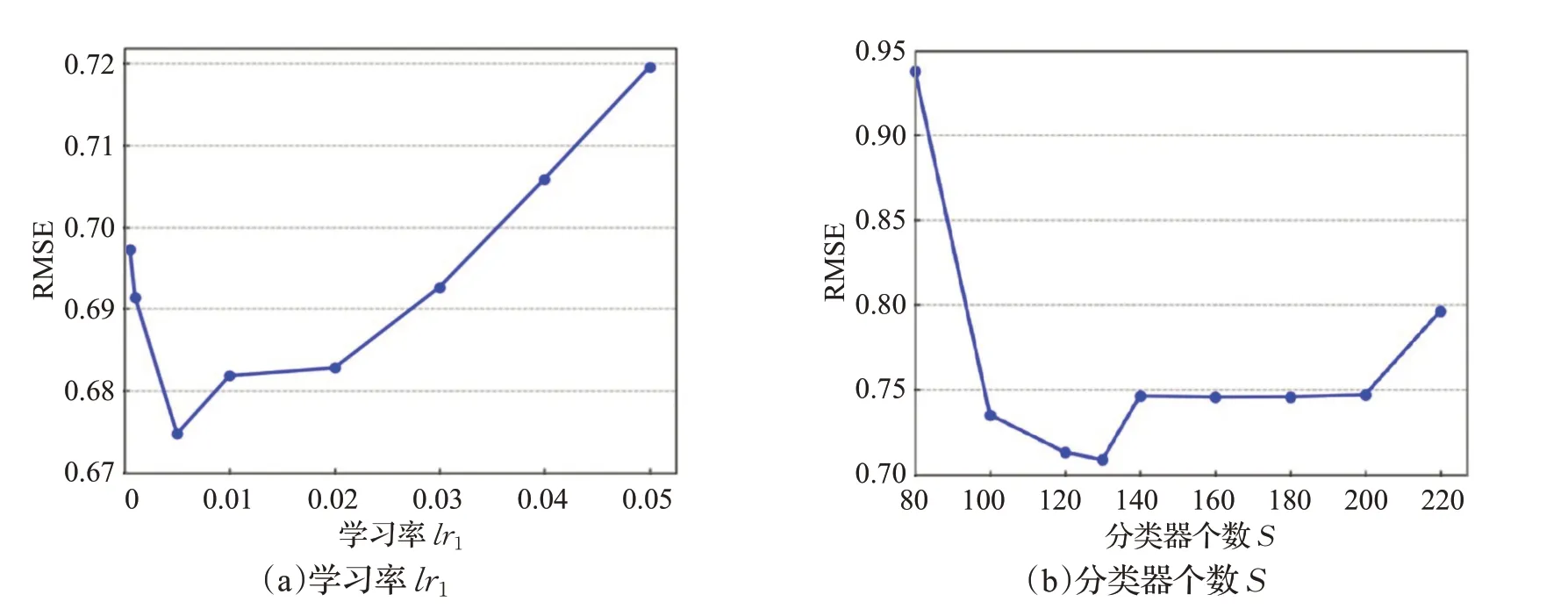
图7 学习率和分类器个数对TrAdaBoost算法的影响Fig.7 Influence of learning rate and number of classifiers on TrAdaBoost algorithm
对于FM中的学习率lr2、正则化参数λθ和隐向量个数k,首先固定其中的正则化参数λθ和隐向量个数k,调整学习率lr2从0.000 1到1,并记录FM模型对于处理后的数据集的预测结果的RMSE指标。然后固定其中的学习率lr2和隐向量个数k,调整正则化参数从0.000 1到0.01,并记录预测结果的相关指标。最后固定学习率lr2和正则化参数λθ,调整隐向量个数从1到30,并记录预测结果的相关指标。最终结果如图8所示。
由图8可知,FM模型的学习率lr2在0.5,正则化参数λθ在0.005,隐向量个数k的个数在8的时候,最终的CITr-FM算法的预测结果可以取得最低的RMSE误差损失,保证了整体的推荐性能最佳。
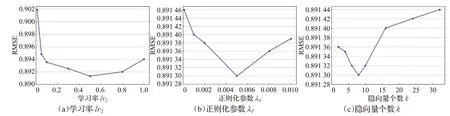
图8 学习率、正则项和隐向量个数对因子分解机的影响Fig.8 Influence of learning rate,regular term and number of implicit vectors on factorization machine
4 结束语
本文提出的基于情境信息迁移的因子分解机算法,通过特征评估筛选重要特征并结合情境信息进行数据集划分,分为符合特定情境信息的目标域和不相关的源域,充分考虑情境信息对用户偏好的影响;对源域数据进行样本迁移重新计算评分,保证其数据分布符合目标域数据分布;最后将整体数据整合后放入因子分解机中建立推荐模型。与传统推荐算法相比,能够有效利用情境信息进行个性化推荐,充分利用整体数据集和多维特征来缓解推荐算法中的稀疏性问题,提高了推荐的个性化程度和推荐准确度。下一步,将尝试结合不同领域的数据样本集,使用更高效的迁移方法,进一步探究如何将不同领域数据集中的异构情境信息与当前数据集相结合,利用外部数据进一步缓解数据稀疏问题。
猜你喜欢
黄河之声(2022年10期)2022-09-27 13:59:46
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
数学学习与研究(2017年3期)2017-03-09 18:12:42
