
基于强化学习的无人机智能任务分配方法
2022-03-20 08:03费陈,郑晗,赵亮
弹箭与制导学报 2022年6期
费 陈,郑 晗,赵 亮
(武警士官学校基础部,杭州 311400)
0 引言
随着对危险领域探索的逐渐深入,传统有人驾驶飞机已经无法满足相关科学研究和工程应用的需求,而无人机的出现解决了这样的难题[1]。通常无人机是指能够自主控制或由地面操作人员操控、可自行推进飞行、能单次或循环使用的无人驾驶飞机[2-3]。随着无人化、智能化和导航技术的不断发展,无人机从最初的训练靶机,逐渐发展成为具有自主决策、自主攻击的侦察打击一体化无人机[4]。
由于小型无人机单机能力有限,因此,多架无人机通过协同合作组成的无人机联盟拥有广阔的应用前景[5-7],如何在满足不同约束条件的前提下,在较短的时间内尽可能将所有任务分配给无人机编队联盟,充分发挥无人机联盟协同工作效能,以实现性能最优化,是存在的无人机任务分配问题[8-10]。
针对这类问题,刘畅、胡大伟等[11-12]提出将无人机群的任务分配问题转化为车辆路径模型(VRP),该模型以美军的捕食者与全球鹰为研究对象,将无人机视为车辆,侦察目标视为顾客,采用禁忌搜索算法求解此问题;Choi等[13]开发出一个分散的任务分配框架,涉及一个基于市场的策略,通过协商的方法为无人机群分配任务;Rasmussen等[14]使用树搜索算法将任务分配给无人机群,该方法将问题表示为决策树,并使用树搜索算法来解决,同时还考虑了不确定情况下的任务分配;蒋硕等[15]提出一种改进的阶层分级粒子群优化算法(HGIWPSO),根据实数创建粒子和实际分配的映射关系,从而使分配问题得到解决;常松等[16]提出将无人机任务通过对改进的合同网算法进行分配,该方法通过优化每个无人机的负载平衡,结合时间和外部的约束条件,解决任务分配不合理的问题。综上所述,无人机群任务分配的研究存在处理信息量大、可靠性低、信息交互不全、任务完成度低等问题。
针对上述存在的局限性,人们又提出一种无人机联盟目标打击分层框架[17-19],将多个无人机视为一个联盟并对目标进行分类,形成任务簇,并将每个任务簇映射到无人机联盟中,将复杂的目标打击任务分配问题分为几个不同层次的子问题,通过解决每级的子问题,进而将复杂的问题简单化,降低了计算复杂度,避免多个无人机执行同一任务,缩短目标打击任务分配时间,提高目标打击完成度。同时引入多智能体强化学习算法(MADDPG),从状态空间、网络架构、动作集合、奖励函数4个方面进行设计,将该模型与无人机任务分配相融合,而多无人机则被视作一个联盟,联盟中各无人机协同工作,根据无人机相互之间观察互动和反馈奖励调整自身策略,以便奖励最大化,从而获得无人机联盟完成目标打击的最优策略,提升无人机目标打击的效率。
1 问题描述与任务分层框架设计
1.1 问题描述
文中场景设置如下[20]:假设战场上有数个打击目标和威胁源,目标和威胁源位置均固定不变,每个目标任务只需要一个无人机来进行打击,每个任务之间都相互独立,无人机一旦进入威胁源范围内,将被导弹打中而无法完成任务。无人机联盟随机出现在战场上,任务均匀分布在环境中,并按照距离最短原则分配给距离最近的无人机联盟,无人机联盟内将任务进一步进行细分,确保每个无人机可以规避危险,顺利完成任务。

图1 场景设置
因为无人机任务分配具备高维空间性与多元性的特征[21-22],所以给出简化研究问题的假定:将每个无人机看成是具备同样特点的同质性实体模型,在研究过程中,忽略无人机的外形和尺寸,并进行定义:
(1)
式中:(xi,yi)为无人机的位置坐标信息;vi为无人机的飞行速度;φi为无人机的偏航角。
将环境因素理想化[23],忽略自然环境因素对无人机的影响,重点考虑无人机的军事威胁,军事威胁主要是敌方导弹威胁。假设在二维空间环境中,敌方防空导弹的探测范围为360°,相当于一个以导弹位置为中心、导弹水平探测距离Rmax为半径的圆,定义为:
(2)
因此,导弹威胁的数学模型为:
(3)
式中UR为无人机当前位置与导弹位置的相对距离。
1.2 任务分层框架设计
认知心理学指出,生物智能体解决复杂问题的能力依赖于层级化的认知机制,即将复杂的问题分解成更简单的子问题[24]。这种分层方法能够以零样本的方式解决以前看不见的问题,无需试错。如图2所示,描绘了一只乌鸦如何解决由3个因果步骤组成的食物获取的难题:它首先拿起一根棍子,然后用棍子从管道里面拖出一个石头,最后用石头来触发机关,激活一个机制释放这个食物。

图2 基于MADDPG算法的无人机任务分层框架
受灵长类动物处理问题机制启发,提出一种基于任务分层的无人机联盟目标打击的任务分层框架,整个过程分为目标聚类、集群分配、任务目标分配。
1)目标聚类。目标聚类的目的是将彼此接近的目标归为一组,它是简化任务分配问题的关键和基本步骤,经过这一步,NT目标被划分为M个簇,M等于无人机联盟的数量,为了在无人机联盟之间平均分配工作负载,聚类算法必须平衡每个集群中的目标数量。
2)集群分配。集群分配的目的是将M个集群分配给M个小无人机联盟,通过强化学习算法,得出该级无人机目标任务分配的最优策略,即每个小无人机联盟被分配一个任务集群。
3)任务目标分配。在每个小无人机联盟内,通过多智能体强化学习算法(MADDPG),将小无人机联盟内的每个无人机与目标任务进行交互,获得这个小无人机联盟完成目标任务的最优策略。小无人机联盟中Leader获得联盟内目标任务分配的最优策略并将任务分配给每个无人机,确定攻击顺序。
其中,目标聚类和任务集群分配由无人机控制中心集中解决,而任务目标分配由小无人机联盟内部解决。
2 多智能体强化学习算法(MADDPG)设计
2.1 MADDPG算法
MADDPG框架如图3所示。

图3 MADDPG算法结构框架图
其核心思想是Actor-Critic网络:一个行动家网络π和一个评论家网络Q。π网络根据获取的状态计算要执行的动作,而Q网络评估行为网络计算的动作,以提高行为网络的性能。使用经验重放缓存区存储一定数量的训练经验,Q网络在更新网络时随机读取,以打破训练数据中的相关性,使训练更加稳定。在训练阶段,π网络只从自身中获取观察信息,而Q网络则获取其他主体的动作和观察等信息。在执行阶段,不涉及Q网络,只需要一个π网络,这意味着执行是分散的。
考虑具有N个无人机的场景,π={π1,π2,…,πN},表示N个智能体的策略,θ={θ1,θ2,…,θN},表示策略参数[25],那么无人机ri的期望回报梯度为:
(4)

(5)
(6)

通过最小化无人机ri的策略梯度来更新参与者网络,可以写为:
(7)
式中:K为样本的小批量大小;k为样本的指数。
2.2 动作设置、状态设置、奖励函数设置
2.2.1 动作设置
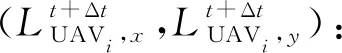
(8)
2.2.2 状态设置
将每架无人机当前的位置视为该架无人机的当前状态,针对无人机UAVi在t时刻的状态定义为:
St,UAVi=(SUAV1,SUAV2,…,SUAVi)=((vUAV1,x,vUAV1,y),(vUAV2,x,vUAV2,y),…,(vUAVi,x,vUAVi,y))
(9)
2.2.3 奖励函数设置
1)在威胁避开区设定一个奖励,当无人机进入威胁避开区后,会被给予一个负奖励。即RN=-1,(DU 2)无人机飞行过程中,假如无人机离得太近,会相互碰撞,导致各个无人机之间产生威胁,因此,为了防止无人机之间发生机械碰撞,设置一个奖励RC,当无人机之间距离低于安全性距离时,给予奖励RC。即RC=-1,(DLmn 3)在训练开始的时候,为了能精确引导无人机动作挑选,使无人机的每一步都获得奖励,制定距离奖励RS,并在每一步都测算无人机和目标的最近距离,将负距离做为奖励值,距离越近,奖励值越多。也就是说,RS=-dmin,其中,dmin是每个目标和每个UAV之间的最小距离之和。最终无人机的奖励函数设置为: RZ=RN+RC+RS (10) 文中设计了一个10 km×10 km的模拟仿真地图,初始化环境仿真结果如图4所示。 图4 初始环境 其中,(a)图包括1个无人机联盟(3架无人机)的初始位置、5个威胁区、3个目标的位置;(b)图包括2个无人机联盟(5架无人机)的初始位置、6个威胁区、5个目标的位置。 MADDPG算法模型采用确定性动作策略,即a=πθ(s) 。最大回合数为8 000,辅助网络的更新率为0.01,价值网络的学习率为 0.01,策略网络的学习率为0.001。 为了验证该策略的可行性,分别形成1个无人机联盟(3架无人机)和2个无人机联盟(2架无人机和3架无人机),建立任务分层框架并通过MADDPG进行训练,与任务不分层框架进行对比,3架无人机各自回报值变化曲线如图5所示。从图中可以看出,随着训练回合次数的增加,3架无人机各自回报值都逐渐增大,直至收敛。对比任务分层框架和任务不分层框架下MADDPG算法中每架无人机回报值变化曲线,可以发现,在任务分层框架下,每架无人机的回报值都比任务不分层框架下的回报值要大,说明任务分层框架比不分层框架具有更强的稳定性,每架无人机都能够更加准确的完成任务,确保任务完成度更高,获得更高的回报值。 3架无人机在任务不分层的情况下,收敛速度较快,这是因为3架无人机更倾向于找最容易完成的目标去完成,虽然一定程度上能够较快的完成任务,但是很可能导致多个无人机执行同一任务,无法达到多无人机协作完成多个目标任务的目的。 最终的整体回报值如图5(d)所示,由图可知,随着训练回合次数的增多,奖励逐渐增大,且在训练回合数达到2 000后,两种框架策略的奖励曲线趋于平缓,总体呈收敛趋势,但任务分层框架下的整体回报值明显高于任务不分层框架下的整体回报值。由于训练过程中存在随机噪声,所以训练时无论是哪个时刻都存在振荡现象。 5架无人机各自回报值变化曲线如图6所示,从图中可以看出,随着训练回合次数的增加,5架无人机各自回报值都逐渐增大,直至收敛。对比任务分层框架和任务不分层框架下MADDPG算法中每架无人机回报值变化曲线,可以发现在任务分层框架下,每架无人机的回报值都比任务不分层框架下的回报值大,说明任务分层框架比不分层框架具有更强的稳定性,每架无人机都能够更加准确的完成任务,确保任务完成度更高,获得更高的回报值。 最终的整体回报值如图6(f)所示,其训练奖励变化曲线规律与3架无人机训练奖励变化曲线(图5(d))大体相同。 图5 3架无人机网络参数变化 图6 5架无人机网络参数变化 在任务分层框架下,将MADDPG与DDPG、DQN算法进行对比,对比结果如图7所示。由图可知,在5架无人机中,与DDPG、DQN相比,MADDPG算法收敛速度最快,且收敛过程波动较少,收敛更加稳定。 图7 5架无人机任务分层-联盟算法对比 3种不同算法的无人机飞行轨迹对比图如图8所示。由图可知,对比3种算法,MADDPG 算法模型的飞行轨迹都进入各自目标区域,而且躲避了所有的威胁区;在DDPG算法模型的飞行轨迹中,第四架无人机进入威胁区,第一和第三架无人机进入同一目标区域,其余两架无人机都进入各自的目标区域内;DQN算法模型的飞行轨迹除了第三和第五架无人机进入威胁区外,其余三架无人机都进入各自的目标区域内。综合分析3种算法的奖励曲线变化图和飞行轨迹图,可以得出结论: 在任务分层框架下,MADDPG 算法训练表现优于 DDPG 算法和DQN算法。 图8 无人机飞行轨迹对比 针对无人机群目标打击任务分配问题,受灵长类动物处理问题机制启发,提出一种基于强化学习的无人机智能任务分配方法。该方法提出一种任务分层框架,将多个无人机视为一个联盟并对目标进行分类,形成任务簇,并将每个任务簇映射到无人机联盟中,通过MADDPG算法将任务簇内的目标与无人机联盟内的小无人机进行合理配对并对目标实施打击,得到MADDPG算法的回报值和飞行轨迹,并与DDPG算法、DQN算法的回报值和飞行轨迹进行对比。实验结果表明,在小样本任务分配中,与不分层框架相比,该方法可以提高目标任务打击完成度,提升目标打击的效率;在分层框架下,该方法在收敛速度、收敛稳定性、任务完成度等方面都优于其他两种算法并具有更好的表现。3 实验结果分析
3.1 参数设置

3.2 结果分析




4 结论
猜你喜欢
小资CHIC!ELEGANCE(2022年1期)2022-01-11数学物理学报(2020年3期)2020-07-27红领巾·探索(2020年5期)2020-05-19工程与建设(2019年2期)2019-09-02动漫星空(兴趣百科)(2018年4期)2018-10-26小学科学(学生版)(2018年9期)2018-09-21家教世界(2017年11期)2018-01-03中学生数理化·八年级物理人教版(2017年3期)2017-11-09法大研究生(2017年1期)2017-04-10华东理工大学学报(自然科学版)(2015年2期)2015-11-07
