
基于随机森林的轨道车辆门亚健康诊断应用研究
2022-03-18 10:34李俊伟刘显峰刘海全孙艳梅
轨道交通装备与技术 2022年1期
侯 飞 李俊伟 刘显峰 刘海全 徐 灿 孙艳梅
(1.济南轨道交通集团建设投资有限公司 山东 济南 250000; 2.中车青岛四方机车车辆股份有限公司 山东 青岛 266111 ; 3.南京康尼机电股份有限公司 江苏 南京 210000)
近年,越来越多算法用于轨道车辆门的健康状态监测,如贝叶斯网络[1]、Petri网[2]等。以上方法多用于故障诊断,对亚健康诊断鲜有提及。与故障相比,亚健康具有隐蔽性、潜伏性和模糊性,更难发现。因此,用于亚健康诊断的分类模型需兼备敏感性和高精度。随机森林(Random Forest , RF)是一种基于“Bagging”思想的非线性分类算法,基于RF的分类模型通过构建多个分类与回归树(Classification And Regression Tree ,CART)对数据建模[3],相比于单一分类方法,具有更高的精度。与常用分类器,如支持向量机和神经网络相比,建立在 CART决策树基础上的RF具有更强的数据挖掘、泛化能力和更理想的分类效果[4]。RF还具有训练速度快、对高维样本输入适应性良好的特点[5]。因此,选取RF应用于车辆门系统亚健康状态诊断。
1 基于随机森林的轨道车辆门亚健康诊断软件系统设计
1.1 随机森林算法介绍
对于分类问题,随机森林是包含多个决策树的组合分类器,通过集成基分类器,提高分类器性能。对于一个输入样本,N棵树有N个分类结果。随机森林集成所有分类投票结果,将投票次数最多的作为最终输出。构建流程如图1所示。
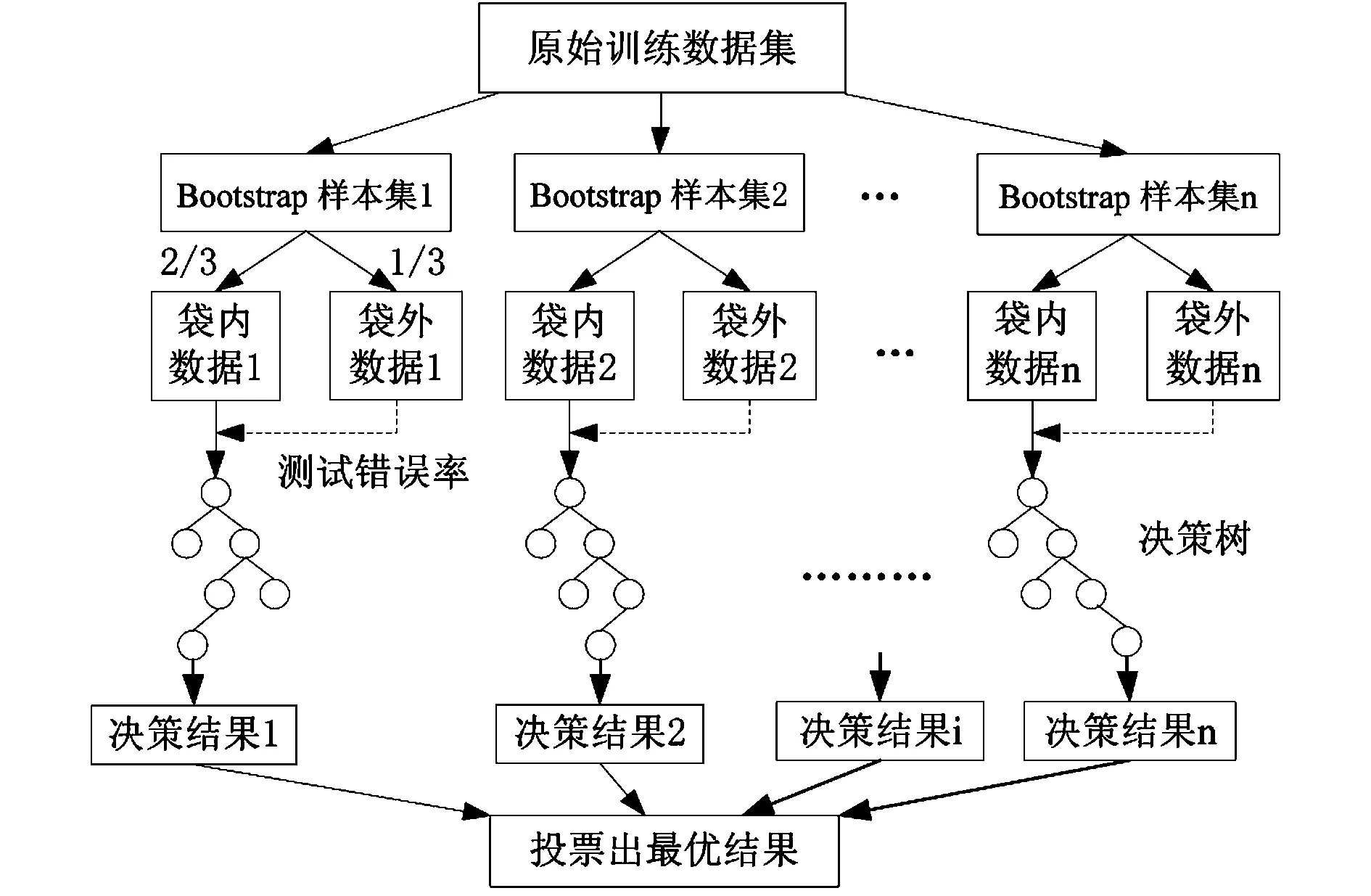
图1 随机森林构建流程图
为保证多个分类器之间的差异性,随机森林中的决策树生成时采用了两个随机方法,其生成规则如下:
(1)从原始训练集中,通过自助(bootstarp)重采样技术,随机有放回地抽取N个训练样本;
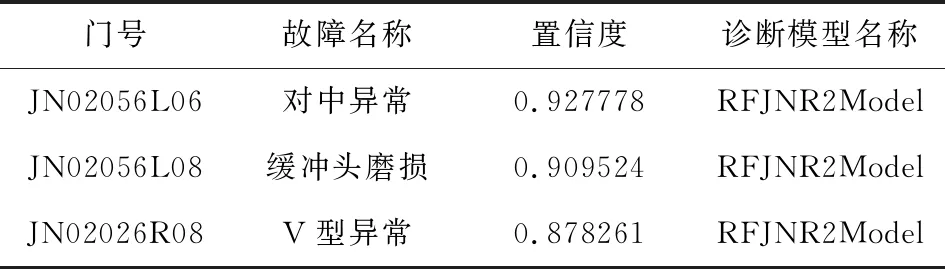
(2)如果每个样本的特征维度为M,指定一个常数m< 随机森林分类效果取决于:(1)森林中任意两棵树的相关性。相关性越大,错误率越大。(2)森林中每棵树的分类能力。每棵树的分类能力越强,整个森林的错误率越低。 以上两个因素互相制约,m越小,相关性越小、分类能力越低;m越大,相关性越大、分类能力越强。因此,如何选取最优的m是关键。假设总的特征数量为M,一般m可以是sqrt(M)、1/2sqrt(M)、2sqrt(M)。 另外,为降低错误率,在建决策树时,每棵树尽最大程度生长,且没有剪枝过程,使决策树具备高差异和低偏差。 基于随机森林算法的轨道车辆门亚健康诊断系统软件(以下简称“系统软件”)总体架构如图2所示,主要由守护进程、数据库读写模块、机器学习算法库、Log4Cplus日志组件、HttpClient工具组成。其中,守护进程由普通进程改造而成,以确保程序只有一个运行实例;程序崩溃时,将重新启动程序。基于随机森林的轨道车辆门亚健康诊断核心算法模块(以下简称“核心模块”)用于模型训练及测试、实际运营轨道车辆门的亚健康状况诊断、亚健康检修任务和预警信息的推送。DAO数据库读写模块用于读取数据库或者将原始数据、算法过程数据写入数据库。Log4Cplus日志组件记录服务器程序运行的过程,一般以文本日志的形式输出。HttpClient工具用来支持基于HTTP协议的预警信息触发。 图2 系统软件总体架构图 核心模块的实现包括离线建模和在线诊断两部分。离线建模的输入为有标签的训练特征及测试特征、亚健康标签,输出为随机森林亚健康诊断模型(以下简称“诊断模型”)。在线诊断的输入为无标签的正线运行数据特征、诊断模型,输出为预测亚健康类型、置信度。首先根据有标签数据建立诊断模型,然后在线诊断时调用诊断模型,诊断正线数据亚健康状况。 2.2.1离线建模总流程 模型训练输入为训练特征和类型标签,输出诊断模型;模型测试输入为测试特征和诊断模型,输出为预测平均准确率;调整诊断模型训练参数,多次训练与测试,选取平均准确率最高的模型为最优诊断模型;将最优模型序列化并存储。 用于训练及测试特征提取的原始数据为有标签数据,一般来源于试验或者正线维保记录。 2.2.2特征提取 根据原始数据提取特征值时,首先读取采集开、关门期间的电机转速、转角等运动参数;然后将运动过程分为若干阶段;最后计算各运动阶段统计特征值、总体时间和行程、部分运动阶段行程等特征参数。 2.2.3亚健康类型标签 亚健康类型标签生成方式如下:若区分健康与N种亚健康类型,输入训练特征维度为M×N×featureNum,则其对应亚健康类型标签维度为M×N。其中,M×N表示N种不同类型“亚健康”各M条数据,featureNum表示一种亚健康类型特征维度。 健康及亚健康数据类型标签定义为:健康-0,对中异常-1,缓冲头磨损-2,依此类推。 根据以上定义,对应类型标签为{0,0,...,0,1,1,1,...,1,2,2,...,2,.....,i,i,......,i,N,N,......,N},其中,“i,i,...i”表示有M个i,每个数字对应一种亚健康类型。 2.2.4模型参数筛选 随机森林诊断亚健康的准确率主要受诊断模型中的决策树棵数、最大深度影响。设置决策树棵数nEstimators上限值200,变化步长为10;设置最大深度maxDepth上限值10,变化步长为1,计算平均预测准确率meanAcc,测试结果如图3所示。 图3 平均预测准确率与决策树棵数、最大深度关系图 当nEstimators=10,maxDepth=9,或nEstimators=40,maxDepth=4,亚健康诊断平均准确率最高,为0.82。 根据以上模型测试结果,考虑模型复杂度越高,所需计算资源越多,选取模型训练参数:决策树棵数nEstimator=10,最大深度maxDepth=9,其他的为默认值。以此参数训练得到最优模型,序列化后,存储到本地文本之中,在数据库存文本名称,用于在线诊断的时候加载调用。 系统会对原始数据作初步过滤,以满足计算要求。首先,根据过滤后数据提取特征,在线诊断的特征提取方式与离线建模时一致,否则会造成模型不适用;然后,获取系统配置的诊断模型,调用模型诊断门亚健康状态;接下来,对诊断结果作进一步处理,根据模型诊断出的亚健康类型可能有多个,选取置信度最高的或者达到置信度阈值的作为结果输出;最后,依策略推送预警信息。 基于随机森林的轨道车辆门亚健康诊断系统软件部署在测试服务器上试运行,以济南地铁公司正线运行车辆门作为诊断对象。配置门基本信息和诊断模型信息,将门与系统诊断算法绑定。配置成功后,系统接收门正线运行数据。每天定时计算一天运行数据,诊断门亚健康状况。 系统上线运行一段时间后,诊断结果整理如表1所示。由表可见,基于随机森林的轨道车辆门亚健康诊断模型对于对中异常、缓冲头磨损、V型异常等亚健康类型有较高识别率。 表1 系统上线一段时间后的诊断结果 正线运行预警信息推送情况如图4所示。经现场检查反馈,预警情况属实。由此证明,该轨道车辆门亚健康诊断系统可成功诊断出地铁车辆门亚健康状况。 图4 Web界面推送预警信息 该亚健康诊断方法具有通用性和易扩展性。除地铁车辆门以外,对于其他类型轨道门系统,可根据门类型及其特点重新设计亚健康试验,得到试验数据;系统将利用试验数据自动进行离线建模,得到亚健康诊断模型。随着运营数据累积,亚健康诊断规则库将日趋完善,如置信度阈值、预警阈值等参数的设置将更加符合实际运行情况,诊断准确率也会逐步提高。 对运营地铁车辆门的亚健康诊断采用了一种基于随机森林的轨道车辆门亚健康诊断方法,相比于单一分类方法,随机森林方法具有更强的数据挖掘能力和更理想的分类效果。试验结果表明,当决策树棵数为10,最大深度为9时,平均准确率达90%左右。随着地铁运营数据的丰富,通过该方法建立的亚健康诊断规则库将更加完善,诊断准确率也会逐步提升。另外,在正线试运营一段时间后,基于该方法设计实现的系统能成功诊断出车辆门的亚健康状态,并推送出预警信息,用于指导地铁运维工作,这对于减少运维人力成本、降低运维工作量、提高地铁运营的安全性具有实际意义。1.2 系统软件总体架构

2 亚健康诊断核心模块实现
2.1 核心模块实现总体方案
2.2 离线建模

2.3 在线诊断
3 系统验证及结果分析

4 结束语
猜你喜欢
世界科学技术-中医药现代化(2021年8期)2021-12-21
当代陕西(2018年24期)2019-01-21
少先队活动(2018年5期)2018-12-29
时代英语·高一(2018年5期)2018-11-19
电子制作(2018年16期)2018-09-26
电子制作(2017年24期)2017-02-02
瞭望东方周刊(2016年33期)2016-09-08
科技资讯(2014年13期)2014-11-10
科技经济市场(2014年5期)2014-09-09
决策与信息·下旬刊(2013年1期)2013-03-11
