
基于Word2vec_BiLSTM的用餐评论情感分析
2022-03-16 12:54秦精俏王玉珍
枣庄学院学报 2022年2期
秦精俏,王 彤,王玉珍
(兰州财经大学 信息工程学院,甘肃 兰州 730020)
0 引言
随着移动互联网+电子商务的快速发展,餐饮行业也实现了网络化、平台化。餐饮行业的蓬勃发展使得大批真实评论数据不断涌现。这些带有情感倾向性的文本评论数据有着重要价值,一方面,对于商家而言,通过收集客户意见,可以改进和完善餐品,从而提高产品竞争力;另一方面,对于消费者而言,通过了解文本评论信息,可以选择质优物美的餐品。而利用人工方法进行情感分析,效率低且准确率不高,利用计算机进行情感分析且准确高效。常见的中文文本情感分析方法有两种:一是基于情感词典的词袋模型方法,二是基于传统机器学习的方法。但是,以上两种方法忽略了语义之间的关系且人工标记数据工作量大。近年来深度学习在情感分析中有着广泛的应用。
缪亚林等[1]提出一种基于CNN和BiGRU结合的神经网络,对豆瓣影评进行情感倾向检测;叶星鑫等[2]提出ALBERT_AFSFN模型,对三个不同类型的数据集进行测试;王文松等[3]提出AM_CNN模型,将课程评价文本经过注意力机制处理后,进行卷积和池化操作;尼格拉木·买斯木江等[4]提出BERT_BiGRU集成模型,对慕课课程评论数据进行特征提取和情感倾向性分析,然后进行文本评论的主题提取;王儒等[5]利用微博短文本数据,构建不同的神经网络模型,研究细粒度情感分析在中文文本中的应用。
综上所述,情感分析已经成为挖掘各领域热点话题的重要手段,但是不同模型在不同类型的数据中表现不一,且餐饮行业客户情感分析的研究成果相对较少。因此,采用word2vec_BiLSTM模型对16000条用餐评论数据进行情感分析,并且采用对比试验来验证选用模型的有效性。
1 相关模型
1.1 预训练模型概述
使用预训练模型的主要作用体现在两个方面:一是针对相应的文本,提取相关特征,学习到相应的语义表征;二是进行微调,有针对性地对网络模型进行修正。采用word2vec捕获单词的语义信息,以词向量的形式嵌入模型中,得到每一个词或字出现的概率分布,以此提取文本特征。
1.2 RNN基线模型
RNN是目前最常见的循环神经网络之一,作为一种具有记忆功能的神经网络,在情感分析方面有着良好的表现。RNN的结构包括输入层、隐藏层、输出层,其基本结构如图1所示。

图1 RNN结构图
图1中x表示t时刻输入的训练样本,u表示t时刻输入样本的权重,s表示样本在此刻保留的记忆,w表示输入的权重系数,v表示输出样本的权重系数。其中,RNN的核心在隐藏层,其展开如图2所示。
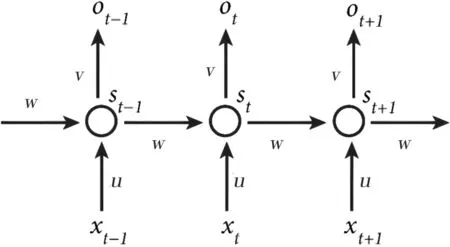
图2 RNN隐藏层展开图
计算过程如下:
ht=uxt+wst-1st=f(ht)ot=g(Vst)
(1)
虽然RNN在处理时间序列上有历史性突破,但存在梯度消失和梯度爆炸的问题,导致RNN很难处理远距离的语义信息,为解决此类问题引入LSTM。
1.3 LSTM基线模型
LSTM解决了RNN梯度消失的问题。在RNN的基础上增加更为复杂的内部单元来处理上下文信息,使得LSTM可记忆长文本信息。LSTM中有3个基本的门控,分别为输入门、遗忘门、输出门。其中,输入门负责将当前信息输入到LSTM中;遗忘门负责将历史信息遗忘并记忆新输入的信息,使得有用信息得以传递;输出门负责将当前信息输出。门控技术实现了LSTM对信息的存储和更新。通过Sigmoid函数和点乘运算实现门控,其结构及工作过程如图3所示。
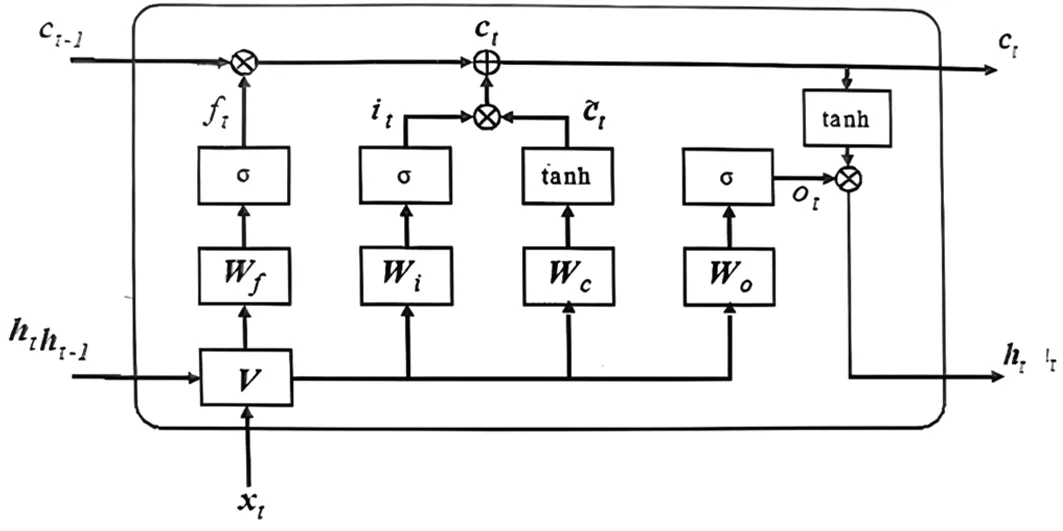
图3 LSTM单元结构
LSTM是由t时刻的输入向量xt、当前时刻记忆单元Ct和隐藏层ht等参数组成,详见表1。

表1 LSTM参数表
LSTM计算过程为:上一时刻的信息通过遗忘门的计算来决定哪些信息会被丢弃,从而得到遗忘门的输出信息ft;然后将信息通过输入门,计算出该时刻需要保存的信息Ct;最后,通过输出门输出当前值。具体计算过程如下所示:
ft=σ(Wf·[ht-1,xt]+bf)it=σ(Wi·[ht-1,xt]+bi)
(2)
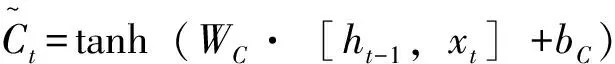
(3)
ot=σ(WoV+bo)ht=ot·tanh(ct)
(4)
虽然LSTM可以解决RNN不能学习远距离历史信息的问题,但是中文情感分析时通常需要结合上下文的语义。因此,为解决LSTM无法分析文本下文信息的问题,引入BiLSTM基线模型。
1.4 BiLSTM基线模型
Graves A等[6]首次提出BiLSTM,是为了解决LSTM单项处理文本的问题。BiLSTM由两个方向相反的LSTM叠加而构成。BiLSTM的结构如图4所示。
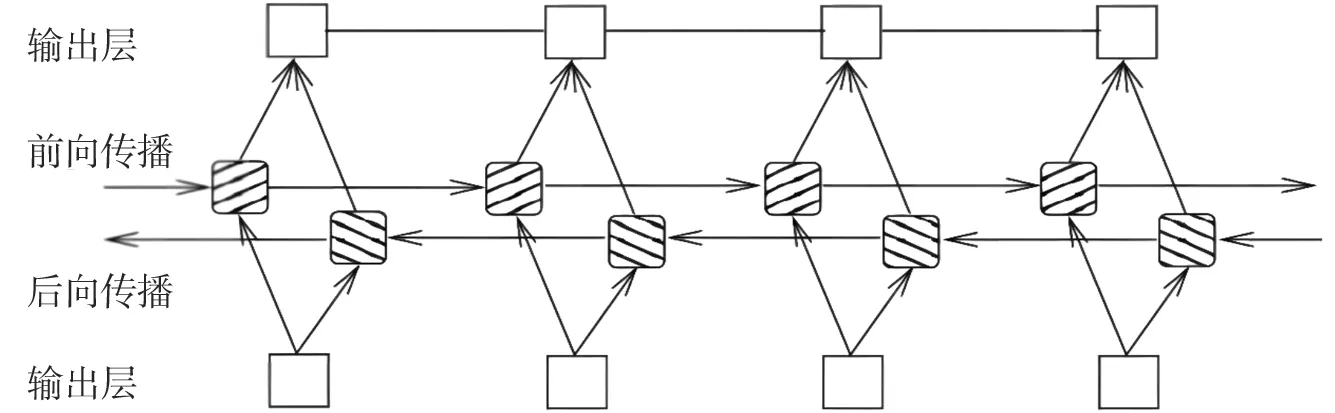
图4 BiLSTM单元结构
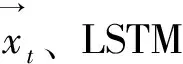
表2 BiLSTM参数表

(5)
2 相关算法模型搭建
2.1 试验环境配置
试验采用Anaconda工具包,基于Spyder,使用python3.6编程语言,框架为keras2.3.1+tensorflow 2.1.0,操作系统为windows10,内存16 GB。
2.2 试验数据集
试验所使用的数据集爬取自“饿了么”美食外卖平台“今日推荐套餐”中的客户评价信息,包含16000条数据。经过人工标注,正向评论8000条,负向评论8000条。正类样本与负类样本均衡后,将处理好的数据保存至txt文件中。数据初始形式如图5所示。

图5 数据初始形式
2.3 词向量
在中文文本情感分析过程中,将包含情感倾向性的评论语句用词向量表示,采用word2vec中的词向量数据sgns.zhihu.bigram.bz2预训练词向量。通过绘制评论长度直方图(如图6所示),观察到每段评论文本长度不一。通过索引化、标准化,文本长度为32时覆盖率达95.59%。为节省训练时间,抽取前50000个词,维度为300,构建新的词向量,对于超出50000的词向量用“0”进行填充。
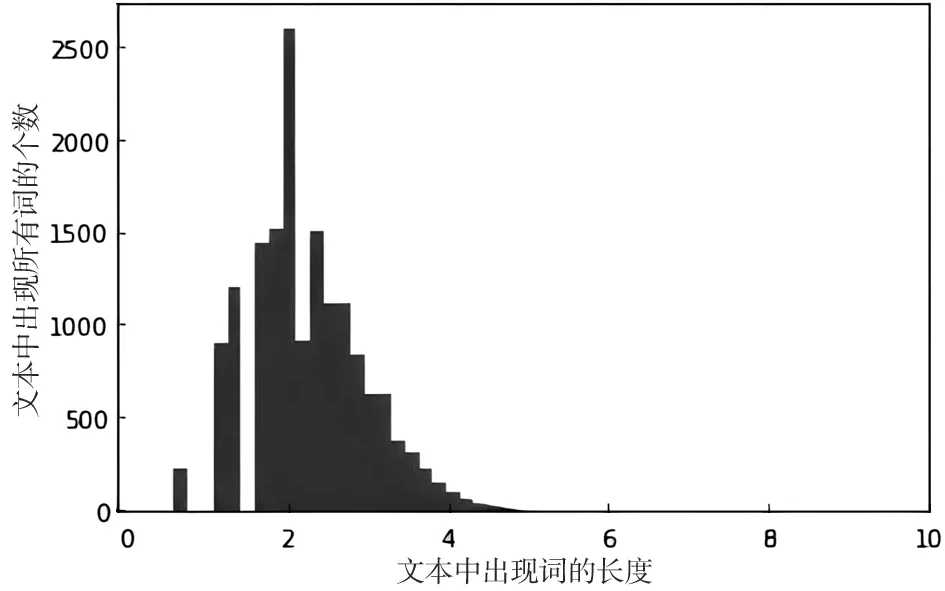
图6 评论文本长度
2.4 神经网络参数
在模型训练过程中,参数调节对于最终情感分类的准确性至关重要。从词向量维度、每批次抽取的样本数量、防止过拟合的dropout取值及训练速度等方面进行对比试验,最终选定模型的超参数(如表3所示)。
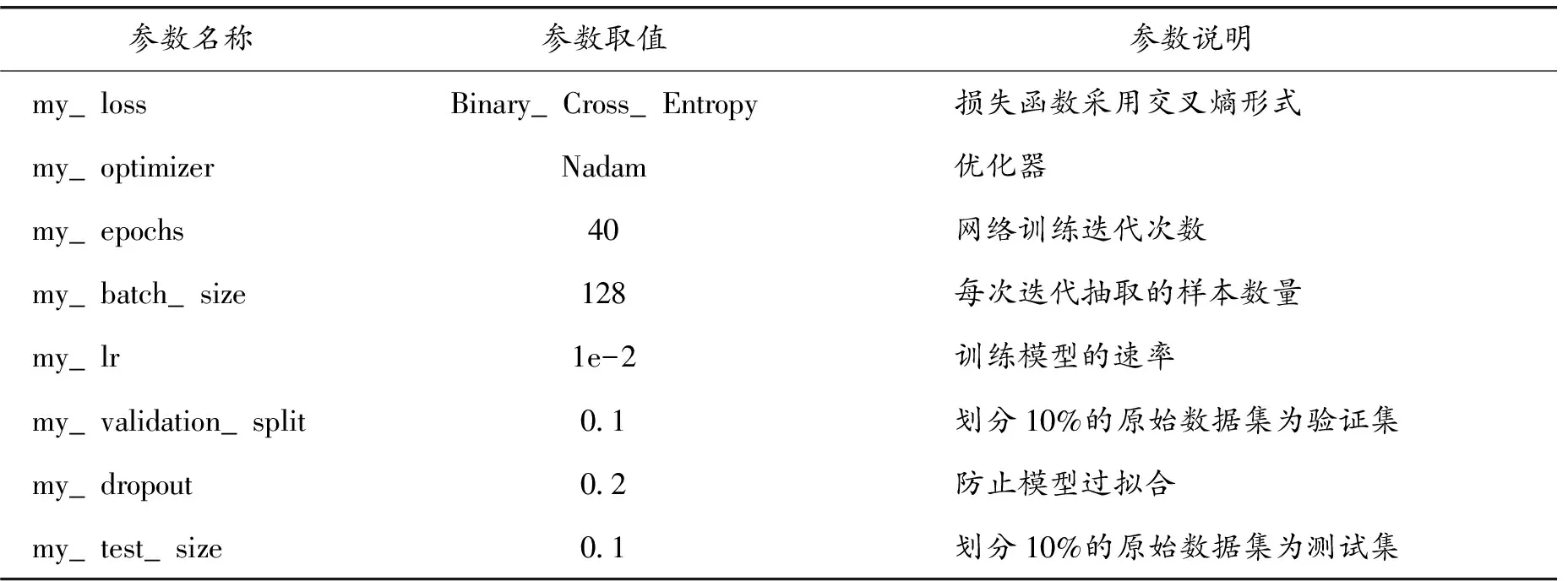
表3 模型超参数
2.5 试验评价指标
评价指标由ACC、Precision、Recall、F1值构成,通过混淆矩阵中的TP、FP、TN及FN计算得到。其中,T含义为预测正确,F含义为预测错误,P含义是预测方向为正向,N含义是预测方向为负向。具体公式如下:

2.6 试验结果分析
将用餐评论数据在RNN、LSTM和BiLSTM三个模型中进行对比训练,设置神经网络参数dropou=0.2,每次训练结果存在一定偏差。试验结果分析前,20次训练结果中选择模型整体效果最好的一次。三个模型的网络结构如表4~6所示,模型之间的性能比较如表7所示。
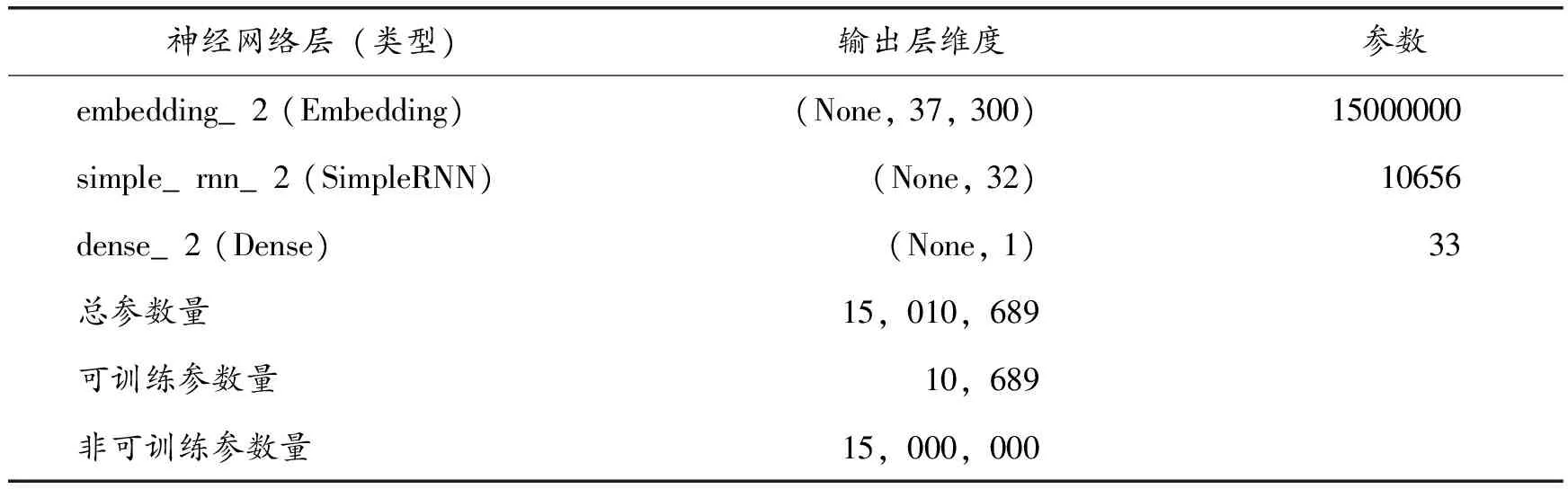
表4 RNN模型结构
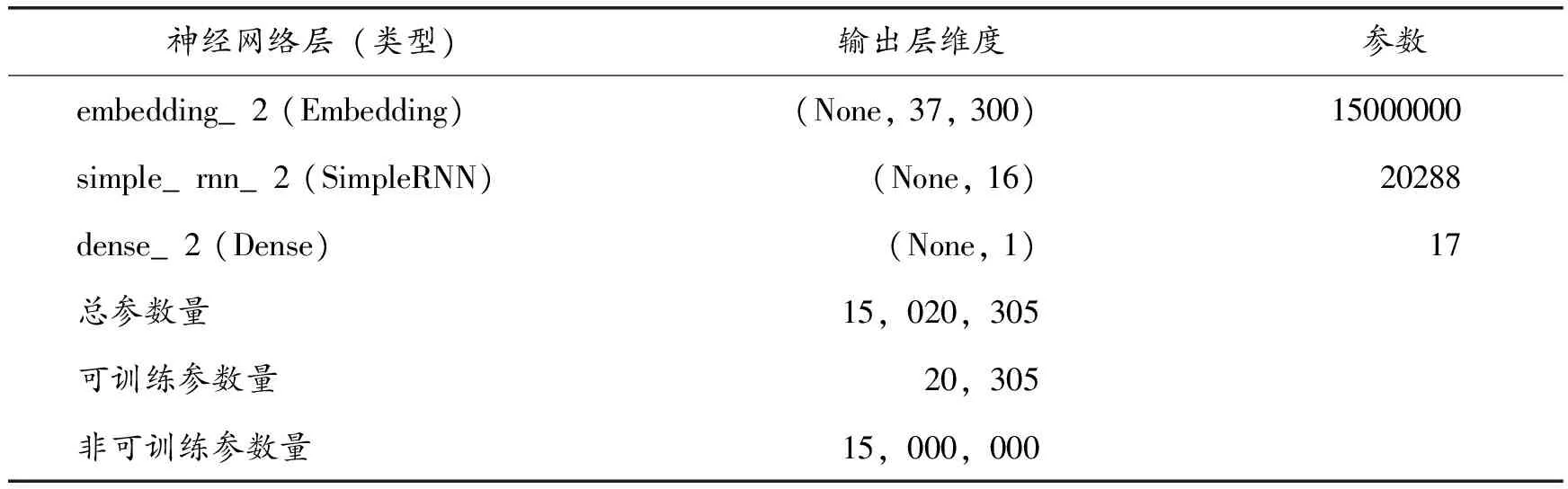
表5 LSTM模型结构
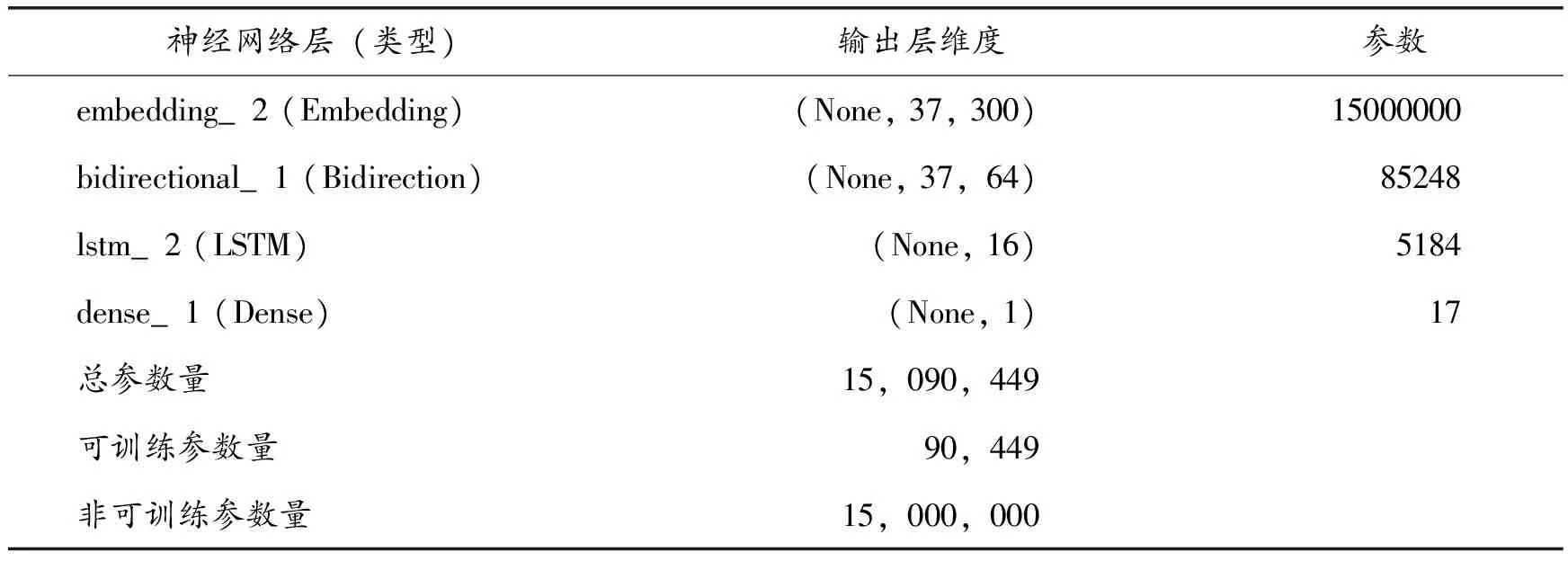
表6 BiLSTM模型结构

表7 试验结果
由表7可知,LSTM模型比RNN模型正确率更高,损失率更低。对比RNN模型的正确率,LSTM模型的正确率提高了2.9%说明LSTM更为复杂的内部单元对远距离的评论语句有更好的解释效果;LSTM模型的精确率提高了1.94%,其召回率、F1值也分别提高了0.77%和1.35%,其损失率降低了0.0742。对比加入了双向结构之后的LSTM模型,BiLSTM模型的正确率提高了1.62%,说明加入双向机制对提高正确率有一定效果;BiLSTM的精确率提高了1.7%,其召回率、F1值也分别提高了3.2%和2.5%,其损失率降低了0.0006,说明BiLSTM模型在准确性和全面性两个方面都有明显提升。
为更加直观地观察三种模型的准确率和损失值,现将各个模型的ACC和LOSS变化趋势绘制成折线图,如图7~9所示。
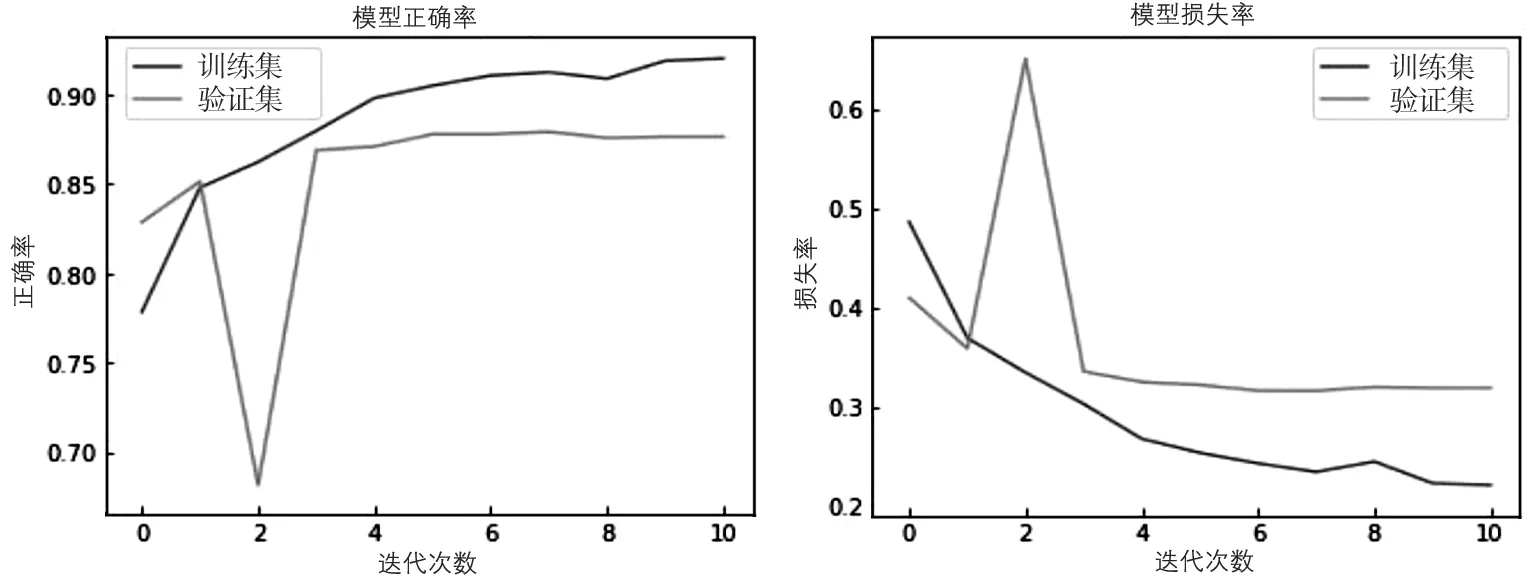
图7 RNN评价指标情况
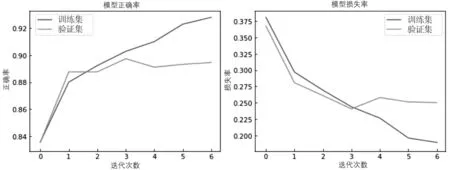
图8 LSTM评价指标情况
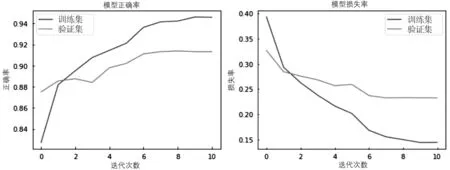
图9 BiLSTM评价指标情况
RNN随着时间步的增长在模型训练集中的表现趋于良好,ACC达到90%以上,LOSS可降低至0.2;但在第2个时间步的验证集上,RNN的ACC比率突然降低,LOSS突然升高,出现过拟合现象,说明RNN模型本身在此数据集中存在缺陷。LSTM模型整体趋势随着时间步的增长平稳增长,在第3个和第4个时间步中有所波动,第4个时间步后以趋于平稳。BiLSTM模型整体表现最优,随着时间步的增长而更加稳定,无明显波动情况出现;同时,LOSS的下降速度在第1个时间步后开始减慢,在第6个时间步后趋于平缓。总体来看BiLSTM在此中文文本数据集分类中效果最好。
3 结语
针对用餐评论数据,采用三种不同类型的基线模型进行中文文本情感分析,设置三种模型的对比试验,分别通过指标体系和折线图的方式对比模型分类性能的优良。试验结果表明,BiLSTM在学习上下文的语义过程中表现最优,为研究文本情感分类提供了一种有效的方式。但是,在研究过程中发现,需要通过对文本评论数据的情感极性进一步划分细粒度来确定该评论用户的真实情感,所以下一步要将研究重点放在多模型集成方式对文本情感进行细粒度的划分上面。
猜你喜欢
云南教育·小学教师(2022年4期)2022-05-17
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中国生殖健康(2020年5期)2021-01-18
艺术评论(2020年3期)2020-02-06
小太阳画报(2019年10期)2019-11-04
中华诗词(2018年9期)2019-01-19
电子制作(2018年18期)2018-11-14
小资CHIC!ELEGANCE(2018年20期)2018-07-06
高中生学习·高三版(2016年9期)2016-05-14
