
基于xDeepFM的铁路货物运输时间预测
2022-03-15 09:21:38蒋哲远葛承宇米希伟
交通运输工程与信息学报 2022年1期
蒋哲远,葛承宇,陈 超,米希伟
(北京交通大学,交通运输学院,北京 100044)
0 引言
运输时间预测是交通运输领域的一个经典问题,近年来,很多学者围绕公路、航空、水运运输时间预测方面开展研究,一些模型已取得较好的效果。然而,相比于这些研究,铁路货运时间预测至今仍是一个难点,这是因为铁路货运专业背景较强、货物列车运营模式复杂、受到各种因素的影响和制约较多。准确预测铁路货物运输时间不仅能给铁路部门、货主及收货人带来直接利益,而且对解决列车调度、物流交付、运输合同制定等诸多重要问题有着重要的意义。
国内外已提出了许多经典的运输时间预测模型,差分整合移动平均自回归模型(Autoregressive Integrated Moving Average model,ARIMA)是一种经典的时间序列预测模型,该模型结构简单,计算方便,预测结果可以外延,但模型对数据规律具有依赖性,抗干扰能力较差,难以适应日趋复杂的时间序列预测问题。模糊模型、卡尔曼滤波模型等非线性参数回归模型也是一类经典的时间序列预测模型,相比于ARIMA 类模型,这类模型的抗干扰能力得到增强,但仍存在预测数据外延性差,邻近特征点或训练集需要及时更新的缺点。
近年来,伴随着人工智能理论的快速发展,机器学习方法在诸多领域中显示出优势,在时间序列预测方面,随机森林模型[1]、支持向量机[2]、人工神经网络[3]等模型得到了广泛应用,一些学者已将这些模型应用于运输时间预测。Huang 等[4]提出一种基于SVR(Support Vector Regression)算法和KF(Kalman Filter)算法的混合模型来预测列车运行时间,该模型结合了2 种算法的特点,可以实现更短计算时间下的高准确率预测,其研究表明,支持向量机在对小样本和高维数据集预测时能取得良好的预测效果,但不适用于大规模训练样本和高度稀疏数据。袁志明等[5]采用随机理论研究了列车的到站时间预测,在分析列车到站时间不确定性的基础上,提取特征指标,挖掘历史行车数据,以提高列车到站时间预测准确性为优化目标,提出一种基于随机森林的列车到站时间预测模型,其研究表明,随机森林模型能在大数据集和高维数据集预测中取得优良的预测结果,但由于其本身的复杂性,预测所需时间和空间较大,当数据噪音较大时,会出现过拟合现象。随着深度学习的飞速发展,神经网络已成为目前运输时间预测的主要研究方向。孙略添等[6]运用灰色模型对技术站列车晚点进行预测,再综合运用马尔可夫和改进的神经网络模型进行修正和预测,最后将2种方法进行了对比,结果显示文中所建的神经网络模型在大规模数据集情形下预测精度更高。He等[7]提出了一种基于卷积神经网络的深度时空预测模型(Deep Spatial-Temporal,Deep ST),文中在考虑外部因素的基础上对不同时间尺度的历史数据特征进行建模。之后He 等[8]又提出了深度时空残差网络(Spatial-Temporal Resnet,ST-Resnet),此模型先将不同时间尺度分别用残差单元建模,再进行特征融合。但这种方法难以显式地对时间序列的时序依赖关系进行建模,为解决这个问题,一些研究者提出了利用卷积计算和循环神经网络对时序依赖关系进行建模的方法[9]。Yu 等[10]提出了一种时空图卷积网络(Spatio-Temporal Graph Convolutional Networks, ST-GCN)来解决时空序列预测问题。Kong等[11]提出了一种分层时空长短期记忆(Hierarchical Spatial-Temporal Long-Short Term Memory Network,HST-LSTM)模型,该模型可以结合双向历史信息进行位置预测。范光鹏等[12]提出一种基于长短期记忆(Long-Short Term Memory Network, LSTM)和Kalman 滤波的混合时间预测模型,其中LSTM 模型用来预测车辆到站的基础时间序列,Kalman滤波模型用于对基础时间序列数据动态调整。Che 等[13]提出了基于GRU 的多变量缺失时间序列递归神经网络(Deep Learning Model Based on Gated Recurrent Unit,GRU-D),该模型可以准确地捕捉到时间序列的长期依赖关系。虽然相比于经典预测模型,基于深度神经网络的运输时间预测模型取得了更好的预测效果,但目前已提出的模型仍然难以深入挖掘运输时间中复杂的显式特征交互信息和高阶特征关联信息。
铁路货物运输时间受线路长度、线路数目、限速、列车优先级、列车速度、车站到发线数、货场配线数、车站作业计划等相关因素的影响,且这些相关因素存在复杂的交叉关系。现有的铁路货物运输时间预测模型大多没有充分考虑特征交叉或者仅通过人工经验进行特征交叉,而当特征量较多、特征交叉较复杂、计算量较大时,人工方法难以提取出所有关键交叉特征。不同于运输时间预测领域,在推荐系统领域[14],特征交互的研究众多,一些模型已取得很好的效果。因此,本文引入推荐系统领域中压缩交互网络(Compressed Interaction Network,CIN)算法,并结合深度神经网络(Deep Neural Network,DNN),设计了面向铁路货物运输时间预测的xDeepFM(Extreme Deep Factorization Machine)模型。
本文的主要贡献如下:
(1)针对铁路货物运输时间受诸多复杂因素耦合影响的情况,提取较为重要的影响因素,并把各影响因素的特征交互纳入考虑,创新性地将智能推荐算法领域的xDeepFM 算法引入运输时间预测问题,为铁路货物运输时间预测提供了新方法。
(2)在以ReLU 函数为激活函数的基础上引入了稀疏规则算子正则化函数,减少无用特征,生成有限的关键特征,有利于自动选择特征,优化算法效率。
(3)xDeepFM 预测模型既能兼顾低阶和高阶特征交互,又能兼顾显式和隐式特征交互,同时也具备记忆与泛化的学习能力,可以有效提高铁路货运时间预测精度,为具有多种影响因素、不同因素交叉影响的复杂场景预测问题提供新思路。
1 问题描述与数据处理
1.1 问题描述
本文以一列具有货物运输任务的列车按照列车运行时刻表准时从起点站发车,途经各个中间站并根据列车改编计划、乘务计划等完成相关任务,最终到达终点站的一个OD 货运[15]过程为研究对象,预测单列车一个OD对的货物运输时间。
1.2 数据来源
本文所采用的数据来自于由运筹学和管理科学研究协会(Institute for Operations Research and the Management Sciences, INFORMS)于2020 年举办的“铁路运筹学应用大赛”所提供的比赛数据,其中数据信息包含了列车运行时刻表、列车改编信息、乘务计划信息、列车优先级、列车最大运行速度等列车信息,以及站间距离、线路数目、线路允许通过最大速度、货场配线数、车站到发线数量等车站线路信息。
1.3 数据提取
根据预处理和特征提取的原始数据,以单列车从起点站出发完成一次货运任务到达终点站为一次完整的货运过程,提取该过程中影响货物运输时间的因素如下所示:
(1)列车运行区段线路长度,即列车从起点站出发到达终点站的总路程。该参数对铁路货物运输时间造成直接影响,为主要影响因素之一。
(2)最大允许速度,即列车在运行区段所允许的最大速度。该参数为轨道限速和列车最大运行速度中的较小值,对铁路货物运输时间造成主要影响。
(3)列车改编信息,即列车在编组站是否需要编组。
(4)乘务人员变更,即在中间站乘务人员是否需要换班。
(5)线路数目,即列车运行区段线路轨道数。
(6)货场配线数,即货场的可用装卸线数量。
(7)车站到发线数,即车站货物列车到发线数目。到发线数目对列车到发、列车会让造成影响,从而间接影响铁路货物运输时间。
(8)各优先级列车数,即在列车运行区段范围内存在的不同优先级列车数。由于不同优先级列车相遇时,低优先级列车需要会让高优先级列车,对货物运输时间造成一定影响。
将上述特征因素组成特征向量,作为模型的一组输入参数。对样本进行编号分组,样本编号i包含特征如下:列车运行区段线路长度为x(i);车站到发线数为m(i);货场配线数为D(i);相同方向相同优先级列车数量为p1(i);相反方向相同优先级的列车数量为p2(i);相同方向较高优先级的列车数量为p3(i);相反方向较高优先级的列车数量为p4(i);相同方向较低优先级的列车数量为p5(i);相反方向较低优先级的列车数量为p6(i);最大允许速度为v(i);乘务人员变更为O(i);列车改编信息为B(i)。
输入特征向量为:

货物实际运输时间为Y(i)。
根据上述方法,在原始数据中一共提取4 000条样本数据,每一样本数据有12维度。
2 xDeepFM预测模型
2.1 DNN模型
铁路货运受影响的特征因素多、数据量大,而DNN拥有处理高阶特征、海量数据的优点,在预测上有优势,因此本文选用DNN 作为模型框架的一部分,旨在利用其强大的非线性映射能力学习高阶特征交互。本文采用的DNN 为多个全连接层搭建,其基本结构如图1所示。

图1 DNN网络结构

2.2 CIN模型
在基于深度学习的特征融合模型中,特征交互的方式可以分为隐式特征交互和显式特征交互两种[16]。由于DNN 模型有黑箱性质,其学习的是隐式的特征交互,特征形式未知、不可控,同时,模型最终的输出表现为一种特殊的向量扩张,特征交互发生在元素级而不是特征向量之间。
为使模型可自动学习显式的高阶特征交互,并使特征交互发生在向量级上,本文引入压缩交互网络(CIN)模型。在CIN 中,隐向量是单元对象,将输入的原特征和神经网络中的隐层都分别变换成一个矩阵,记为X0和Xk。CIN 中每一层的神经元全是依据前一层的隐层以及原特征向量演算得来,其计算公式如下:


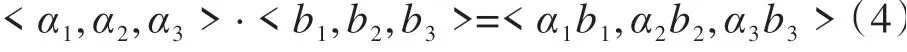
其中第k层隐层含有Hk条神经元向量。隐层的计算可以分成两个步骤:(1)根据前一层隐层的状态Xk和原特征矩阵X0,算出一个中间值Z^k+ 1,在此中间值上,用Hk+1个尺寸为m×Hk的卷积核产生下一隐层的状态,最后学习出的特征交互阶数由网络的层数确定,每一隐层都通过一个池化操作连接到输出层,确保输出单元可以产生不同阶数的特征交互模式。
2.3 xDeepFM模型
由于影响铁路货物运输时间的因素具有特征阶数高,存在复杂特征交互且主要在特征向量之间存在互相影响关系等特点,本文将DNN 模型与CIN 模型合并到端到端框架中,生成一种新的显式交叉高阶特征方法xDeepFM 模型[17]。此模型结构可以分成四个模块,分别是嵌入层、CIN、DNN 和线性模块。嵌入层的作用是将特征向量转换为具有固定大小的向量,将多个方面组成的高维稀疏分类特征通过神经网络嵌入到低维密集特征。CIN 模块的作用是进行显式特征交互,而

式中:λ*表示正则项;θ表示参数集。
其模型结构如图2所示。

图2 xDeepFM模型结构
2.4 评价指标
本文选取均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)和平均绝对百分误差(MAPE)来评估xDeepFM模型的性能,其公式如下:
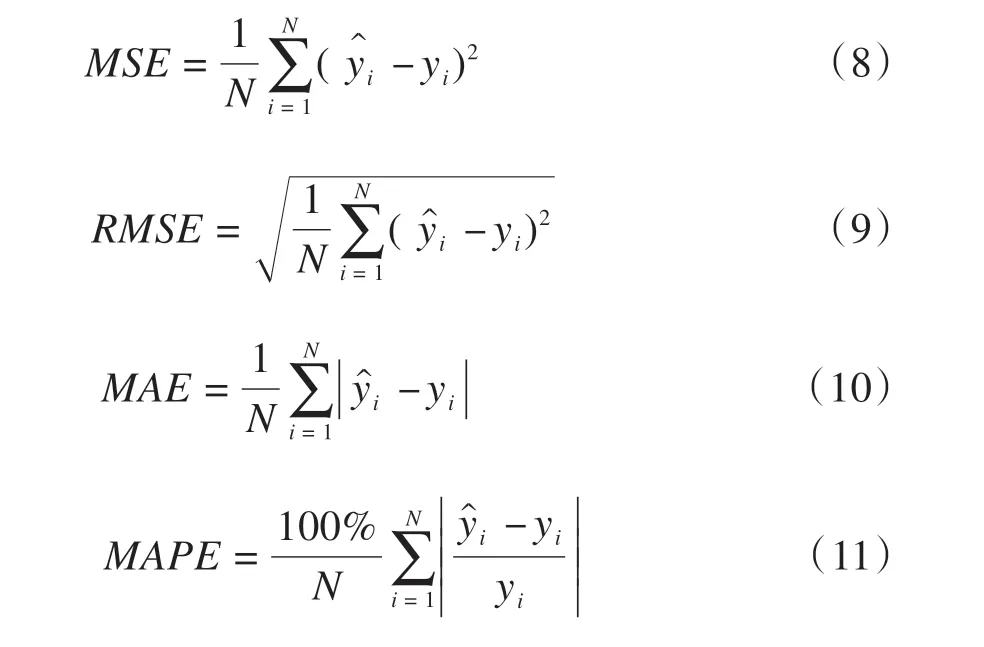
式中:N为货物运输时间预测的总样本数目;yi为货物运输时间预测值;yi为货物实际运输时间。
3 模型参数敏感性分析
本节对模型超参数的敏感性进行分析,使用上述处理完成的数据,对以下参数进行具体分析,包括:(1)CIN 隐含层的数量;(2)CIN 每层神经元数量;(3)DNN 隐含层的数量;(4)DNN 每层神经元数量;(5)batchsize 的大小。在研究分析某一具体参数时,固定其他参数为最佳参数,同时改变研究参数的设置来进行实验,训练次数都设置为150 次,最后使用最优参数训练模型。
3.1 CIN隐含层的数量
CIN 隐藏层数量的影响如图3(a)所示。图中可以看到xDeepFM 的模型性能在开始时随着网络深度的增加而增加。但当网络深度设置大于3时,模型性能下降,这可能是由于网络深度加深引起的过拟合造成的。基于此本文将CIN 隐含层的数量设置为3。
3.2 CIN每层神经元数量
由于3.1表明CIN 隐含层的数量设置为3时有最佳效果,在此实验中将CIN 隐含层数量固定在3。每层神经元数目的增加,表示CIN 中特征映射数目的增加。如图3(b)所示,当神经元数量从6 增加到40 时,xDeepFM 的模型性能先增长后下降,每层神经元数量设置为10时,模型性能相对更优。因此本文最终选用的CIN网络结构为[10 10 10]。
3.3 DNN隐含层的数量
图3(c)展示了DNN 隐藏层数量的影响。可以观察到xDeepFM 的模型性能在开始时随着网络深度的增加而明显优化。但当网络深度设置大于4时,模型性能下降,且模型训练时间增加,隐藏层数量的增加可能引起网络的过拟合。所以本文将DNN 隐含层的数量设置为4,模型既有较好的训练效果,也有比较快的训练速度。
3.4 DNN每层神经元数量
由于3.3 表明DNN 隐含层的数量设置为4 时有最佳效果,在此实验中将DNN 隐含层的数量固定在4。经训练发现,DNN 网络每层神经元数目设置为[2x2x x x]时,模型有较好的性能。此次实验主要研究DNN 每层神经元数量对模型的影响。当神经元数量较少时,模型训练效果较差;当神经元数量改变较少时,模型性能变化不显著。因此,本文从神经元数量x=200 开始,以100 为增量增加到x=500 进行实验。如图3(d)所示,xDeepFM 的模型性能刚开始时随着神经元数量的增加而增长,在x=400 时达到最优,随后模型性能开始下降。因此最终将DNN 网络结构设置为[800 800 400 400]。
3.5 batchsize的大小
batchsize的大小是机器学习中一个重要参数,表示一次训练所选取的样本数。batchsize 的大小影响模型的优化程度和速度,batchsize 设置大,通常收敛快,需要训练的次数少,准确率上升较稳定,但精度不高。batchsize设置小,通常精度较高,但收敛慢,准确率易出现震荡。如图3(e)所示,当batchsize 从400 增加到1 000 的过程中,训练次数固定在150 次,将batchsize 设置为800 时,模型在有较高精度的同时也有较快的收敛速度。因此,本文的batchsize设置为800。

图3 参数敏感性分析
4 预测结果
在完成了上述数据处理、特征映射及模型参数寻优后,将数据处理得到的4 000 条样本数据以3:1的比例划分训练集和测试集,前3 000条数据作为训练集,剩下的1 000 条数据作为测试集。设置CIN 网络结构为[10 10 10]、DNN 网络结构为[800 800 400 400]、batch 为800、训练次数为150 次,以最优参数进行模型训练,最后得到的预测结果,其性能指标如表1。

表1 xDeepFM性能指标
较小的MSE 和RMSE 以及较小的MAE 和MAPE 都表明xDeepFM 预测模型的高预测准确度。针对铁路货运受很多复杂因素耦合影响的实际情况,xDeepFM预测模型拥有其独特优势:(1)拥有嵌入层模块,对数据进行Embedding 映射,将特征向量转换为具有固定大小的向量,将多个方面组成的高维稀疏分类特征通过神经网络嵌入到低维密集特征。(2)拥有CIN 模块提取显式特征交互,能够使特征交互发生在特征向量与向量之间,解决传统深度神经网络特征交互发生在特征元素之间、与实际铁路货物运输时间影响因素交叉影响情况不相符的问题。(3)在ReLU 函数为激活函数的基础上引入了稀疏规则算子正则化函数,去除无用特征,产生少量关键特征,有利于特征自动选择,提高算法效率。(4)拥有线性模块,把原始特征数据作为输入进行线性回归,使得模型具有更强的记忆与泛化学习能力,有利于模型在铁路货物运输时间预测的推广与应用。
通过实验表明,xDeepFM 预测模型既能兼顾低阶和高阶特征交互,又能兼顾显式和隐式特征交互,同时也具备记忆与泛化的学习能力,对受复杂交叉因素影响的铁路货物运输时间预测具有不错的预测准确度。
5 模型对比
为了研究本文建立的xDeepFM 模型的预测性能,在训练集和测试集相同的条件下,本文使用最小二乘支持向量机(Least Squares Support Vector Machine,LSSVM)模型、随机森林模型、DNN 模型、卷积神经网络(Convolutional Neural Networks,CNN)模型和LSTM 模型对铁路货运时间进行预测。选取样本编号400 到500 的预测结果进行可视化,五种比较模型和xDeepFM 模型预测效果对比结果如图4所示。

图4 不同模型预测效果图
总体而言,xDeepFM 模型预测的运输时间与实际运输时间基本相符,拟合效果好。其优越性能更体现在复杂货运情况中,如图5 所示,当货运作业环节多、干扰多、运输时间较长时,对比模型并不能较好地考虑影响因素的交互,导致预测效果不佳,而xDeepFM 模型,在引入学习高维特征交互的能力后,能够对复杂特殊情况做到一个较好的预测。实验表明,xDeepFM 模型预测精度更高、鲁棒性更好、对隐式特征提取能力更强,并能显式呈现特征交互,因此更适用于解决该问题。
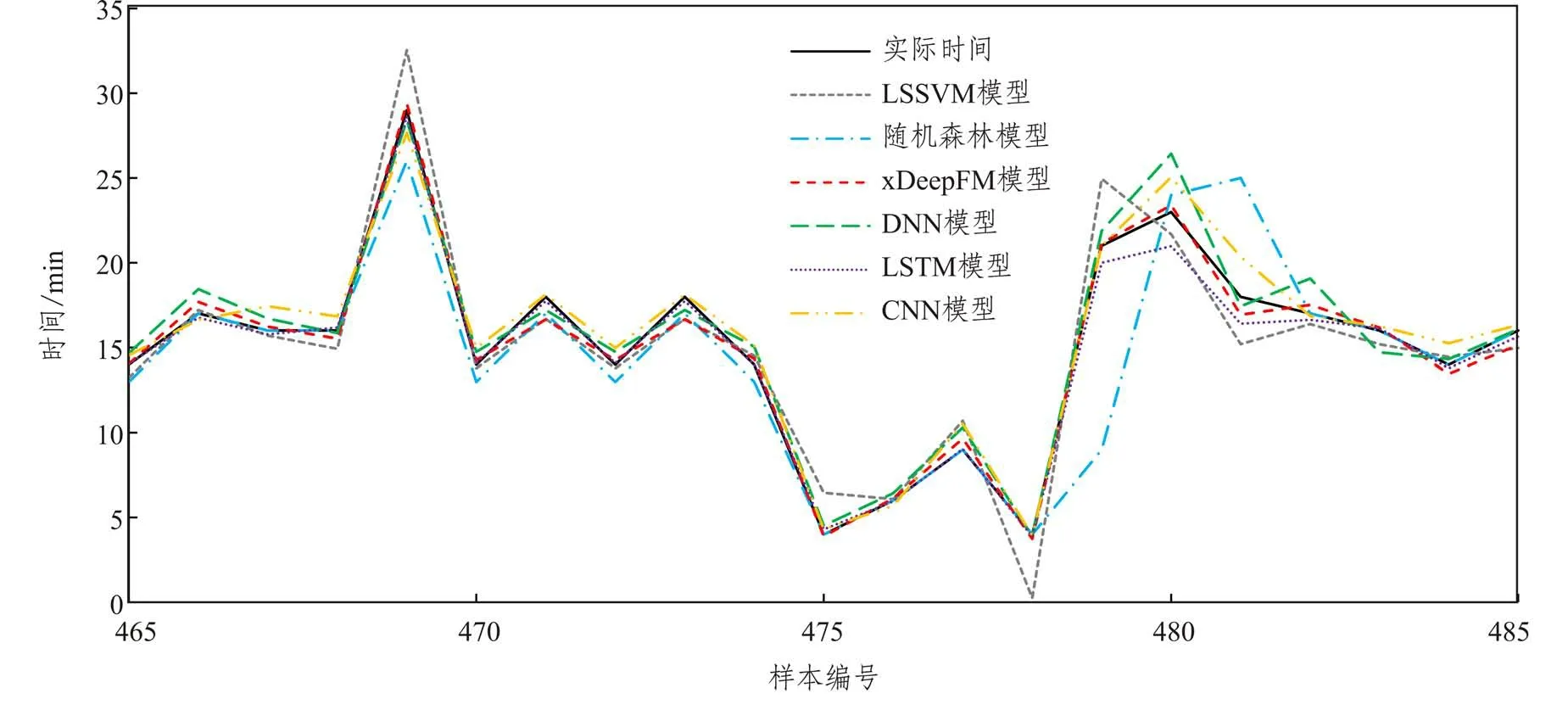
图5 预测效果放大图
MSE 和RMSE 度量预测值与真实值的偏差,MAPE和MAE度量预测误差相对于真实值精度的指标,能够评价模型的预测精确度。通过表2可以发现,xDeepFM 预测模型的预测效果不仅明显优于LSSVM 模型、随机森林模型此类经典模型,而且与DNN 模型、CNN 模型以及LSTM 模型这些新颖的深度学习模型相比,也显示出其优越的预测性能。
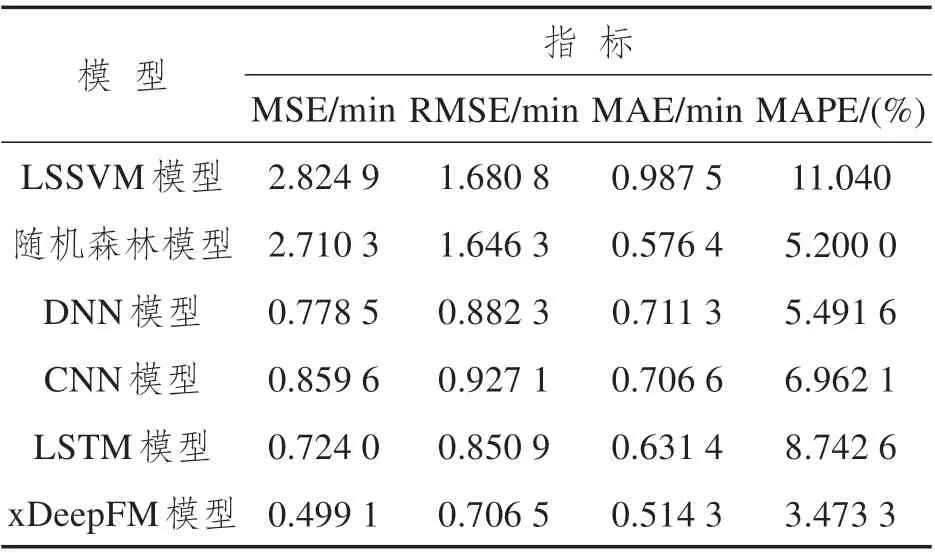
表2 模型性能指标对比
xDeepFM 预测模型具有其独特的优点:(1)它可以学习高阶和低阶、显式和隐式的特征交互。(2)表达能力强,精度高,可以发掘出向量级的交互特征。(3)在向量级而不是元素级发生特征交互。但xDeepFM 预测模型也有其不可忽视的缺点,其训练速度相对较慢,难以在几秒之内迅速得到较好的预测结果。实验结果表明,本文所建的xDeepFM模型具有更好的预测性能。
6 结束语
本文改进了多应用在广告点击率预测[18]的推荐系统模型,将CIN 和DNN 合并融合,兼顾低阶、高阶特征和显式、隐式特征,构建了一种基于xDeepFM 的铁路货物运输时间预测模型。本文所建的xDeepFM 模型预测精确度高,和LSTM 模型相比,本文模型的MSE 提升了31.1%,MAPE 提升了60.3%,且实际案例分析表明所建的xDeepFM模型可以适用于具有多种影响因素、不同因素耦合影响的复杂预测场景,在铁路货物运输时间预测方面有较大的优势和发展前景。
猜你喜欢
自然杂志(2021年6期)2021-12-23 08:24:46
小哥白尼(趣味科学)(2021年4期)2021-07-28 02:23:50
云南画报(2021年4期)2021-07-22 06:17:10
小学生学习指导(低年级)(2019年6期)2019-07-22 03:32:48
小学生学习指导(低年级)(2019年3期)2019-04-22 03:34:42
现代装饰(2018年5期)2018-05-26 09:09:01
小猕猴智力画刊(2016年6期)2016-05-14 21:40:48
电源技术(2015年5期)2015-08-22 11:18:38
弹箭与制导学报(2015年1期)2015-03-11 15:32:06
现代企业(2015年5期)2015-02-28 18:51:08
