
集时空聚类和指标筛选的公共交通通勤者识别
2022-03-15 09:21:58陈学武
交通运输工程与信息学报 2022年1期
周 航,陈学武
(1.杭州市规划设计研究院,杭州 310020;2.东南大学,a.江苏省城市智能交通重点实验室,b.现代城市交通技术江苏高校协同创新中心,c.交通学院,南京 211189)
0 引 言
通勤出行在城市出行总量中仍占据绝对多数,同时存在明显的时空规律性,较为适合公共交通方式通过线路布设、班线运营等方面的高效组织来提升城市交通资源的使用效率。公共交通通勤者识别作为后续此类群体出行特征分析的基础工作,在公共交通规划与管理研究中至关重要。
早期由于技术限制,国内外文献多通过传统通勤调查或居民出行调查研究公共交通通勤特征[1],直接从被调查的通勤乘客来分析使用公共交通工具出行的乘客特征;后期随着信息技术的发展,学者大多基于公共交通刷卡数据,辅以其他数据或者机器学习等新技术手段,来开展公共交通通勤人群的识别研究。目前较为常见的依托公共交通刷卡数据的通勤者识别方法大致分为三种:一是利用刷卡数据中的“卡类型”字段来识别,部分国家如日本会发行针对通勤(学)人群的“通勤票”[2];二是融合公共交通刷卡数据、空间数据、出行调查数据等数据来识别,如识别职住地后再提取公交通勤者出行信息[3];三是仅使用公共交通刷卡数据,从时间的重复性和稳定性角度设置识别规则,包括一周首次刷卡总次数和首次刷卡时间差[4]、高频OD 对的出行频次[5]和出发时间标准差[6]等指标,或是利用聚类[7-9]、分类[10]、神经网络[11]等机器学习算法进行判别。
目前研究多为直接对指标设定筛选规则来识别公共交通通勤者,选取指标时主观性较强,阈值设定单一,无法较完整和准确地表征通勤者出行规律;当仅使用机器学习算法识别时,仍存在指标计算复杂、对通勤者表征程度不足的问题;同时,识别方法较少考虑实际数据质量,实用性较弱。因此,本文基于南京市公共交通系统刷卡和设施数据,提出一种集时空聚类和指标筛选的公共交通通勤者识别方法,以时空密度聚类算法(Densitybased Spatial Clustering of Applications with Noise,ST-DBSCAN)为基础算法,根据数据条件提出两步聚类法和线路相似性整合法,为基于职住地与指标识别的筛选操作缩小了识别范围,可操作性和通用性强,能够为公共交通通勤乘客的相关分析提供数据基础,同时对公共交通设施与服务优化提供一定的参考依据。
1 研究数据
1.1 数据描述
本文以南京为例,研究的公共交通系统数据分为刷卡和设施数据两类,时间为2019 年3 月,如表1所示。刷卡数据包括公交、轨道交通和公共自行车刷卡数据,包括乘客个人和乘车时空信息(其中公交刷卡数据受一票制计费和设备记录影响,下车均无位置信息,部分上车无位置信息),匿名乘客编号项为公共交通系统乘客的唯一标识。设施数据为这三类公共交通方式的线路和站点信息,包括站点线路编号和空间信息。

表1 公共交通系统基础数据示意
1.2 数据处理
通勤者的通勤出行具有时空和模式上的稳定性,可以作为通勤者识别的依据。乘客每次公共交通出行(如图1所示)的信息提取是基础,需要对数据进行预处理、换乘识别和出行信息整合操作。
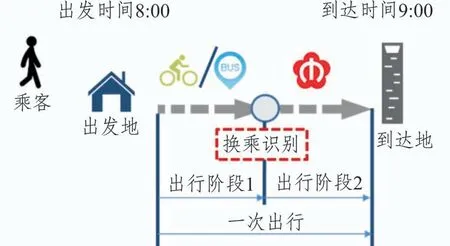
图1 一次公共交通出行示意
数据处理具体步骤为:
Step1 数据清洗。剔除错误和重复数据,统一字段格式,并将刷卡表整合为一份公共交通系统刷卡数据,共2 239 532条数据。
Step2 换乘识别。由于存在同一次出行对应多条数据的情况,故需要识别乘客的换乘行为,将不同出行阶段的记录整合为一条出行记录(见图1)。本文采用经纬度空间距离计算与公交线路可换乘站点提取并行的方法,判别空间层面方式间换乘的可行性,阈值设为500 m[12]。将相邻出行阶段记录的时间差与95%分位时间阈值比较[13],得出最终的换乘行为识别记录。
Step3 出行信息整合。将每位乘客每日每次出行的第一阶段出发地信息作为该次出行的出发地信息,最后一阶段的到达地信息作为该次出行的到达地信息(见图1),整理后得到1 562 668条公共交通出行数据。
本文基于出行时空规律性来识别通勤者,故需要提取出部分关键的出行字段(如表2所示),包括乘客编号USERID、出发时间ONTIME、出发地经度ON_LNG、出发地纬度ON_LAT、到达地经度OFF_LNG、到达地纬度OFF_LAT以及乘坐线路名称TRIPROUTE。

表2 通勤者识别所需出行字段示意
2 通勤者识别方法
2.1 识别思路
本文所提识别方法分为相似性出行整合和两步筛选两个步骤:首先,依据乘客在研究周期的出行集合中是否存在相似性出行,对乘客进行初步筛选,以获得具有规律性出行特征的候选通勤者;然后,通过识别候选通勤者的职住地并完成对应的通勤出行初步提取操作,再利用识别指标进行筛选,以得到最终的通勤者识别结果。方法流程如图2所示。
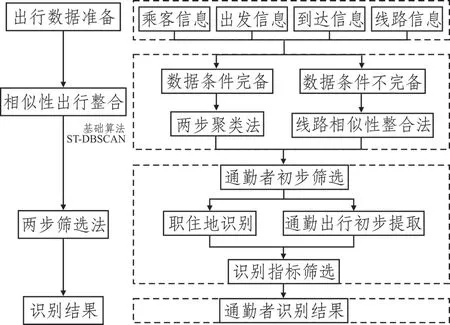
图2 城市公共交通通勤者识别流程
2.2 相似性出行整合法
本文中的相似性出行是指具有相似起讫点位置和出发时间的出行集合,每位乘客在研究周期内的出行都将被分为不同的组别,同一组别的出行即为同一类出行。类似地,时空聚类指的是根据一定的相似性准则将时空实体划分成一系列较为均匀的子类(即时空簇)[8],其中相似性的判定依据为时空聚类中的聚类参数,时空实体在本研究中即为公共交通出行,聚类结果即为相似性出行,每次出行记录均被赋予对应的组别号。考虑到公交刷卡记录存在信息缺失问题,故将相似性出行整合法分为两类:数据完备时,采用基于ST-DBSCAN 算法的两步聚类法;数据不完备时,对缺失数据采用线路相似性整合法,与完整数据的两步聚类结果进行整合。
2.2.1 基于密度的时空聚类算法(ST-DBSCAN)
本文将ST-DBSCAN 算法作为基础算法的原因在于:(1)该算法考虑时间和空间双重要素、可识别高密度的簇和低密度的噪声、无需确定初始核和簇数量等优势,常被用于出行模式划分领域[9];(2)本文所获取的出行数据位置为经纬度信息,相比其他算法研究使用的站点编号[10]更为精确,适用于空间聚类算法。算法是将时空实体STi的时空邻近域的空间形状定义为一个圆柱体,底面半径为R,高为2ΔT,该邻近域内的实体数目即为STi的密度,当密度大于等于设定的最小密度值MinPts时,该实体STi即为核心对象。若STi+1位于核心对象STi的时空邻近域,则STi+1从STi直接密度可达。密度可达是直接密度可达的传递闭包,密度相连是密度可达的传递,且为对称关系,水平视角下时空密度连接示意如图3 所示。时空邻近域的划定和最小密度的取值为算法关键参数,即空间半径R、时间窗口ΔT和密度阈值MinPts。
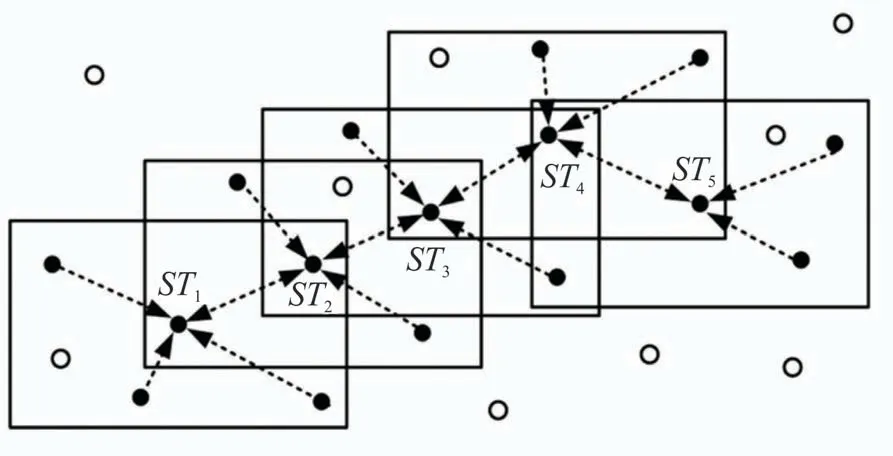
图3 水平视角下的时空密度连接示意[14]
本文基于一整月的研究数据进行聚类操作,通过多参数组合比选,将轮廓系数和CH值作为聚类效果评价指标,并依据肘部法则,最终选定参数R=1 200 m,ΔT=30 min,MinPts=5。R和ΔT分别代表本研究中位置和出发时间相似的判定范围,即相似出发时间差距应≤60min(2ΔT),相似位置差距应≤1 200 m(R);而MinPts=5 则代表位于相似判定范围的出行记录数应≥5 个,即同类时空出行的次数不小于5次/月。
2.2.2 数据完备条件下的两步聚类法
当每次出行的出发地经纬度、到达地经纬度和出发时间3个要素齐全时,经以下步骤可完成对每位乘客多次出行的聚类操作(流程见图4虚线框内部分)。
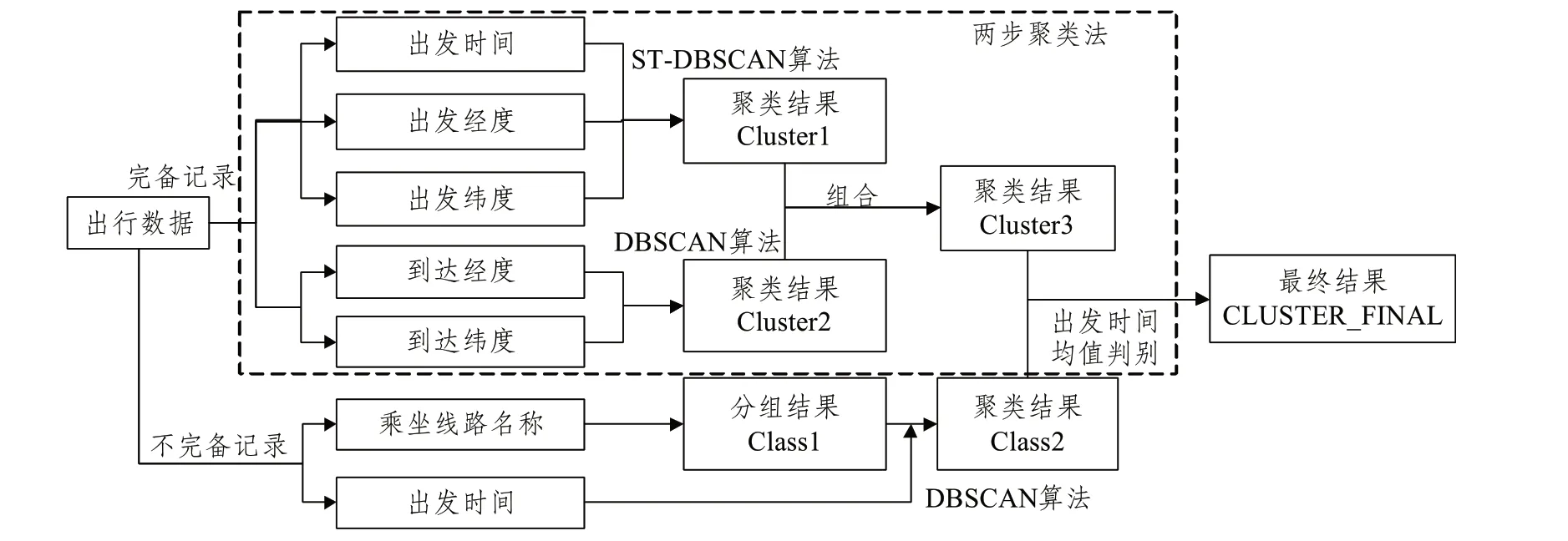
图4 两步聚类法(虚线框内)与线路相似性整合法(整体)流程
Step1 对每次出行的出发地经度、纬度和出发时间进行ST-DBSCAN 算法聚类,得到Cluster1。以USERID=42 的乘客出行为例,此步聚类结果如图5(a)所示,分为噪声点、Cluster1=1 和Cluster1=2三类。噪声点(圆圈)的位置和出发时间较分散,而Cluster1=1(三角)和Cluster1=2(方块)的位置和出发时间相对集中。
Step2 对每次出行的到达地经度和纬度进行DBSCAN 算法聚类,得到Cluster2。乘客42 在此步的聚类结果如图5(b)所示,分为噪声点、Cluster2=1和Cluster2=2三类。
Step3 对每次出行,将对应的Cluster1 和Cluster2 直接组合为最终聚类结果Cluster3(如Cluster1=1 且Cluster2=1 时,Cluster3=1)。只有Cluster1 和Cluster2 取值均非噪声时,Cluster3 按类别顺序取值。乘客42 的最终聚类结果如图5(c)所示,分为噪声点、Cluster3=1和Cluster3=2三类。噪声点(细实线)代表无规律的出行;Cluster3=1(粗实线)的出发地、到达地位置和出发时间均集中,代表一类具有时空相似性的出行集合;Cluste3=2(粗虚线)代表另一类相似出行集合。
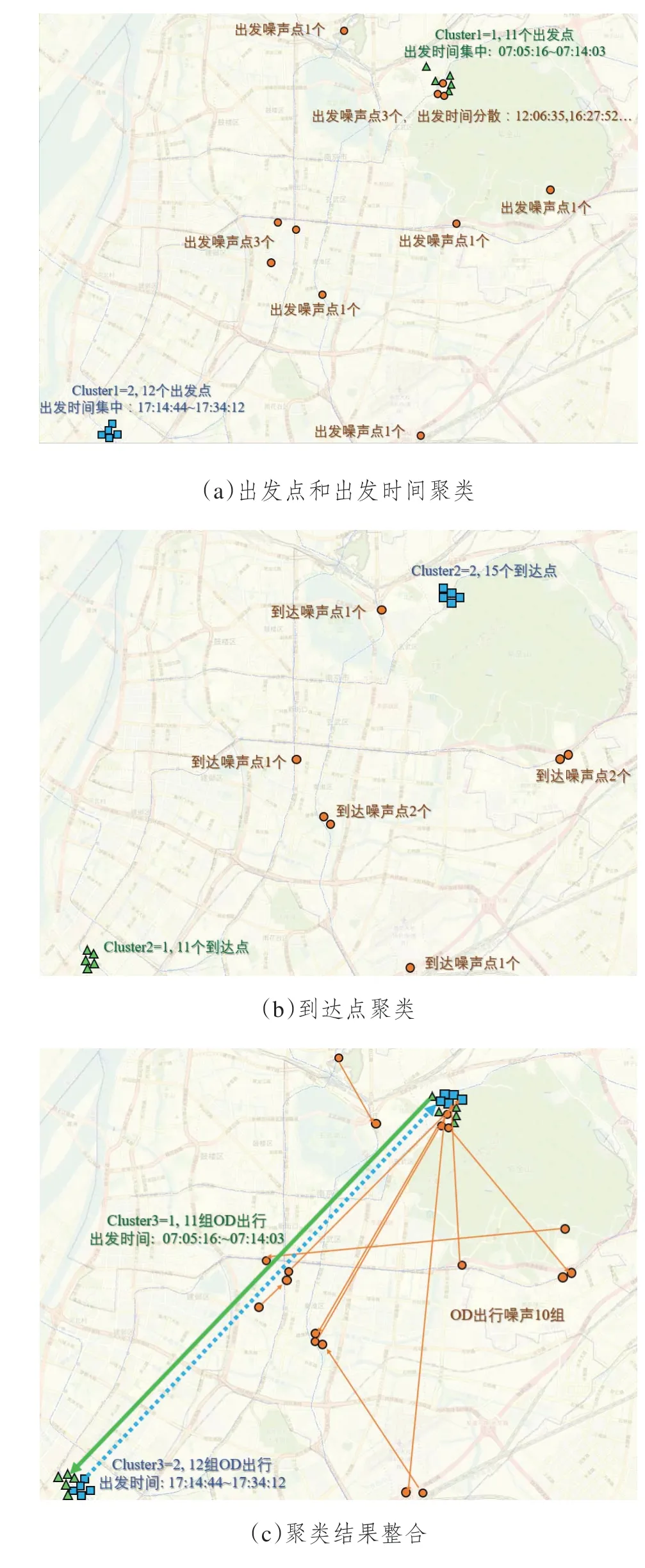
图5 两步聚类法各步骤聚类结果示意(USERID=42)
2.2.3 数据不完备条件下的线路相似性整合法
当部分出行的起终点位置存在缺失时,无法按上述数据完备条件下的方法完成聚类,因此将出发时间和乘坐线路名称两个字段作为判别属性,即考虑出行时间和线路选择的稳定性,将符合要求的出行加入到数据完备条件下的聚类结果中,得到最终整合结果(流程如图4所示)。
整合步骤如下:
Step1 对出行数据按乘坐线路名称字段分组为Class1,提取频次≥2 的Class1,并对每个Class1分组进行出发时间的聚类,提取其中频次≥2 的子类为Class2。
Step2 将每个Class2 子类中出行数据的出发时间与数据完备条件下聚类结果的各分组Cluster3 出发时间均值相比较,若低于30 min 则将此Class2 子类的类别号更新为Cluster3 分组的类别号,另外若Class2 子类中超过60%的出行未加入Cluster3分组,该子类自成一类。
Step3 将处理后的Cluster3 和自成一类的Class2 进行整合,得到最终的聚类结果CLUSTER_FINAL。
以USERID=9 的乘客出行为例,该乘客一月内共56 次公共交通出行,其中信息完整和不完整的出行均为28 次。对信息完整的28 次出行进行两步聚类法,得到聚类结果如图6 所示,得到噪声和Cluster3=1两组(图中未标注噪声数据)。然后,对信息不完整的28 次出行进行操作,得到的13 条非噪声数据结果如表3 所示。其中Class2=1 分组的出发时间与Cluster3=1的出发时间相近,故将其加入Cluster3=1 分组,而Class2=2 分组自成一类。经过两步聚类法和线路相似性整合法操作后,得到最终聚类结果为噪声、CLUSTER_FINAL=1 和CLUSTER_FINAL=2三组。

表3 不完备出行数据的线路相似性整合结果

图6 完备出行数据的两步聚类结果
2.3 基于职住地与指标识别的两步筛选法
2.3.1 基于职住地识别的通勤出行标识
在提取通勤出行前,需要先对每位乘客的职住地进行判别。一般假设乘客每日首次出行的出发地是居住地[8],通过对乘客的长期出行数据进行空间密度聚类可较易得到,点数最多的簇的空间位置即为居住地所在区域。而工作活动仅为日常活动中的一类,难以直接识别工作地。考虑到通勤出行的规律性特征,统计处理乘客的相似性出行可识别出工作地,步骤如下:
Step1 基于上文得出的相似性出行数据,分别对从居住地出发前往的到达地和回到居住地的出发地进行空间密度聚类,空间阈值R仍取1 200 m,密度阈值为5个;
Step2 统计聚类结果中各簇的点数,点数最多的簇所在空间位置即为工作地所在区域。
将从居住地出发和到达工作地频次最高的组别内出行标记为上班,反之为下班。对于公交出行记录位置缺失导致的部分出行起讫点所属类别无法识别问题,可根据同类别相似性出行的标识结果或根据出发时间来确定。
2.3.2 通勤识别指标提取与阈值设定
城市公共交通通勤者出行的规律性强,在时间和空间上较为固定,采用的线路方案具有多样性,使用的出行方式较为稳定。高峰出行次数、出行天数、首次刷卡时间差、出发时间标准差、出行链重复次数、出行往返次数、相似出发站点频次等指标[3,5,6]常被用于进行通勤识别研究。
上文的相似性出行整合操作,已将时间和空间的相似性以及线路方案的多样性等考虑在内,并且经过候选通勤者筛选和通勤出行标识后,出行信息已融合职住信息。由于密度聚类算法中密度连接特性可能导致出发时间域的扩展,出发时间差仍需进一步考虑。由于居民活动多样、个人习惯差异、可选方式多样等原因,出行往返次数较难表征通勤者的特性。因此,在对候选通勤者进行二次筛选时,选择出行天数、单次出发时间差和工作往返出发时间差作为识别指标。单次出发时间差是指研究周期内多次特定类型出行的出发时间标准差,需对去程(出发至工作地)和返程(从工作地返回)两类出行分别计算;工作往返时间差是指去程出发时间与返程出发时间的差值。若部分通勤者只有单程(即去程或返程),则无需计算工作往返出发时间差。
在出行天数指标的阈值设定方面,大多数通勤者识别研究采用类似指标频次的阈值一般为2~4 次/周(约8~16 次/月)[5,6,15],Ma[8]等人通过TOPSIS评价方法和ISODATA 算法完成人群分类后,统计发现通勤者与非通勤者的月出行天数分布曲线交点为11,故本文将出行天数阈值定为11。在单次出发时间差指标的阈值设定方面,研究多将其设定为1 小时[6],然而考虑到工作去程与返程出行的出发时间特征存在差异性,下班回家的出发时间往往较为不稳定,故此处将上班去程以及返程单程的出发时间差阈值分别定为1 小时和3 小时。在工作往返出发时间差指标的阈值设定方面,大部分研究均采用6 小时作为类似指标停留时长的阈值[3],此处也定为6小时。
3 参数验证和方法有效性比较
通勤者识别过程中的相似性出行整合和指标筛选操作需要确定多项阈值,其对识别效果具有重要影响。考虑到数据获取滞后性及匿名性,本文结合参数验证和方法有效性比较验证结果。通过问卷调查获取公共交通通勤者在通勤出行频次、时间等方面的真实特征,以验证本文所提方法中的指标取值合理性,问题设置如表4 所示。
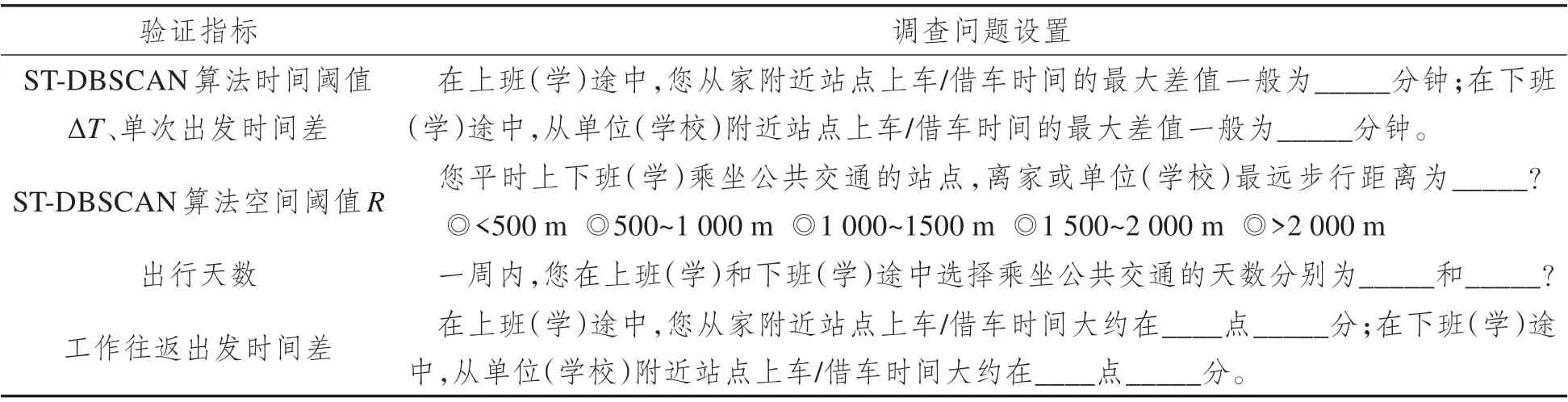
表4 验证指标与调查问题设置
调查采用网络问卷形式,获得有效样本152份。调查中通勤者上班出发时间差均低于1h,下班出发时间差低于3 h的人数占比为96.4%(见图7(a)),即处于单次出发时间差(工作去程和返程的阈值分别为1 h 和3 h)和算法时间阈值(ΔT为30 min(2ΔT=1 h))设定范围的比例较高。站点步行距离是实际居住地与公共交通出行出发站点间的距离,与算法空间阈值的物理意义相近,低于空间阈值(1 200 m)的人数占比≥82.2%(见图7(b))。调查中公共交通通勤与非通勤人群平均一周采用公共交通上班或下班的天数分别为4.7和0.7,通勤人群相应值均高于出行天数指标阈值(11 天/月)。被调查者的工作往返出发时间差均超过工作往返出发时间差指标阈值(6 h)。本文中相似性出行整合和指标筛选步骤中的阈值设定较合理。
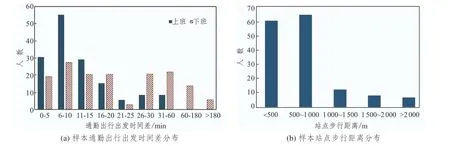
图7 样本通勤出行出发时间差和站点步行距离分布
本文采用与已有方法对比的方式验证结果是否有效,选取的是根据一周内早、晚高峰出行频率来判断通勤乘客的方法,早高峰(6:30~9:30)首次乘车次数=2,晚高峰(16:30~19:30)首次乘车次数=2 和早晚高峰首次乘车总次数=6 时,准确率达98.34%[15]。基于研究数据,本文方法共识别6 787人,对比方法共识别5 982 人,识别重合率仅37.0%。其余35.8% 的人数被对比方法排除,27.2%的人数被本文方法排除。本文识别结果在满足对比方法要求的基础上,在非早晚高峰时段和职住地出行空间规律的通勤者判别上表现出色,两者识别结果满足指标要求的比例如表4 所示。由于评判通勤乘客的量化标准暂未统一,此处仅能通过与其他方法结果的对比,来分析本文方法的应用优势。
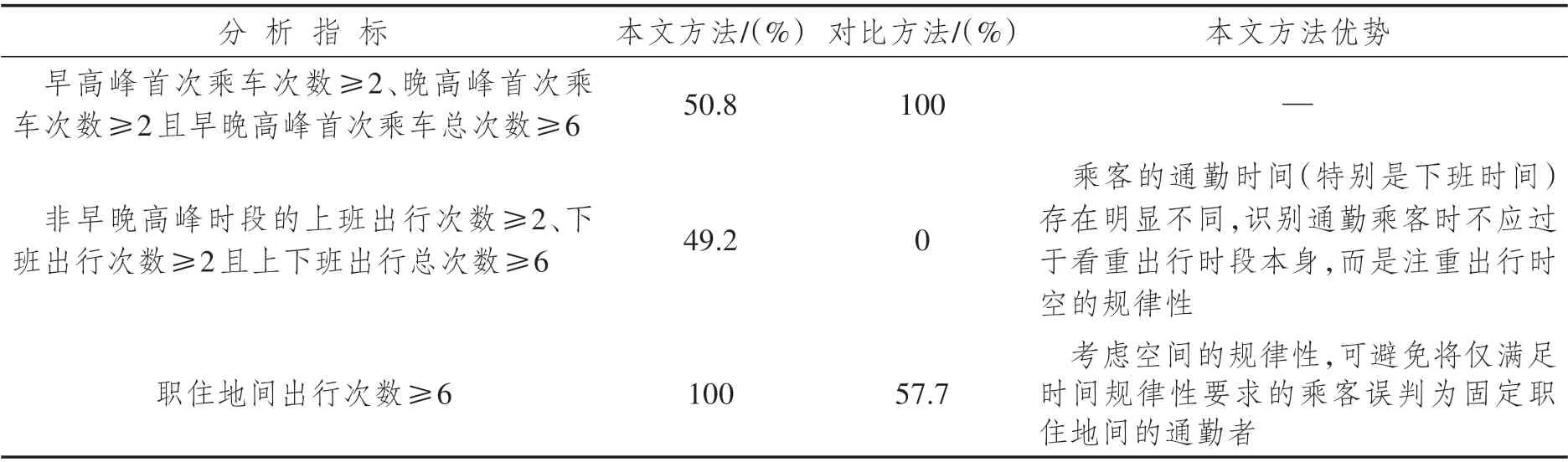
表5 本文方法与纯指标筛选方法[15]识别结果满足指标要求的比例
4 相似性出行整合与两步筛选结果分析
本文以南京为例,利用Python3.6编程环境,实现相似性出行整合操作,并通过Oracle11g 数据库软件统计筛选结果。操作全过程所处的硬件环境为3.8 GHz八核CPU、64 GB 内存和8 TB 硬盘。基于2 239 532 条公共交通出行数据,对46 418 位公共交通乘客分别完成相似性出行整合操作,统计发现大部分乘客的出行是无规律的(无相似性出行),其人数占比为样本总人数的55.6%。
最终识别出的通勤者出行天数均值在16.78天/月,单次出行出发时间差均值低于40min,同时标准差的均值低于15min,即出发时间较稳定,工作往返出发时间差均值为10.16 h。通勤者的人均出行频次明显比非通勤者要高,分别为55 次/月和30 次/月。相比非通勤者,通勤者2019 年3 月的日出行量呈现工作日稳定在较高水平,周末明显下降的变化趋势(见图8(a))。同时,以2019 年3 月13 日(周三)为例,通勤者与非通勤者的出行时段分布如图8(b)所示。通勤者的出行时段明显集中于6:00~9:00 和16:00~19:00 两个高峰时段,其他时段的出行量明显较低,但样本中66.7%的通勤者不完全在传统早晚高峰时段进行通勤。通勤者的6:00~19:00间的出行量变化相对平缓,波峰与波谷的差距不大。可以看出,识别出的通勤者出行日和出行时段变化规律与城市人口通勤或通学习惯一致,同时更贴合实际通勤者的多样化特征。
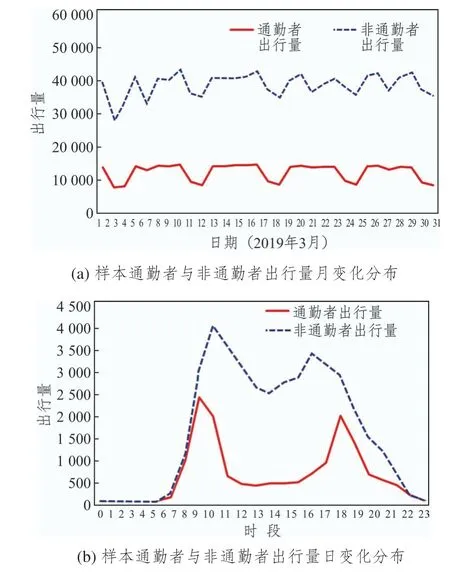
图8 通勤者与非通勤者出行量月变化与日变化分布
5 结束语
本文融合时空聚类和指标筛选思路进行公共交通通勤者识别,以时空聚类算法中的ST-DBSCAN 算法为基础算法,进行具有相似出行OD 和出发时间的出行整合操作,并选取出行天数、单次出发时间差和工作往返出发时间差3 项指标作为通勤识别指标完成二次筛选。基于南京市数据,经时空聚类,发现样本中55.6%的乘客不满足本文设定的出行时空规律;经指标筛选后得到的公共交通通勤者人均出行频次为55 次/月,工作日出行明显集中于6:00~9:00 和16:00~19:00 时段,符合传统对通勤者特征的认知,但样本中66.7%的通勤者不完全在传统早晚高峰时段进行通勤,本文识别结果较贴合实际通勤者更加多样化的通勤特征。
区别于传统研究的指标筛选思路,本文所提的通勤识别方法存在四点优势:(1)不局限于传统早晚高峰时段,注重出行的时空规律性;(2)基于出行起终点的经纬度位置进行聚类,相比站点聚类更为精准;(3)针对数据完备与不完备条件提出不同的处理方法,更符合实际数据状况;(4)基于相似性整合结果利用指标二次筛选,补充通勤者其他特征的判别条件。识别结果可为公共交通通勤者的特征分析以及相应设施布局和服务优化提供研究基础,如多层次通勤公共交通服务体系的构建。由于ST-DBSCAN 算法在时空域上具有一定的延展性,以及参数设置对识别结果存在影响,后续研究可考虑增加簇中时空阈值的限制,同时结合实际数据拟合识别指标,分析取值不同时通勤者与非通勤者的特征差异性以改进方法并进一步论证,使结果更为符合通勤者出行特征规律。
猜你喜欢
数学物理学报(2022年5期)2022-10-09 08:56:44
城市公共交通(2021年3期)2021-04-15 06:39:16
北京航空航天大学学报(2020年10期)2020-11-14 09:25:58
河北画报(2020年8期)2020-10-27 02:54:20
山东工业技术(2017年23期)2017-11-28 09:15:38
演艺科技(2017年8期)2017-09-25 16:08:33
自动化学报(2017年1期)2017-03-11 17:31:10
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
中国交通信息化(2016年3期)2016-06-05 02:21:43
城市道桥与防洪(2014年6期)2014-02-27 07:27:24
