
一种特征融合的视频事故快速检测方法
2022-03-15 09:21:36章世祥
交通运输工程与信息学报 2022年1期
王 晨,周 威,章世祥
(1.东南大学,交通学院,南京 211189;2.华设集团股份有限公司,南京 210014)
0 引 言
交通事故可能导致财产损失和人员伤亡,并且可能引发交通拥堵,给交通应急管理带来极大的挑战[1,2]。为了有效提高事故应急处置的响应速度,减少由于救援不及时导致的人员伤亡和交通拥堵,研究交通事故的快速检测技术具有重要的现实意义。近年来,基于计算机视觉的交通事故检测逐步得到了研究者的重视,其主要原理是通过识别视频中的重要事故特征来实现对交通事故的自动检测。该技术可以有效降低人力成本,并已经取得了较高的检测精度[3~5]。因此,基于视频的事故检测技术具有重要的研究价值。
现有研究主要根据捕捉视频中的事故特征实现事故判别,该特征主要包括事故外观特征和运动特征。事故外观特征来源于事故发生后的车辆形变、非机动车或者行人摔倒等区别于正常行驶状态下的特征;事故运动特征需要在一段时间内连续观测获得,主要包括轨迹的交叉滞留、周围行人的聚集等特征。研究方法按事故特征提取方式主要分为:基于运动特征的方法和基于特征融合的方法。
基于运动特征的方法主要利用传统图像处理方法(如背景减除法[3,6~8]、稠密光流[9]、光流梯度[10]等)或深度学习方法(目标检测[11]、分割[12]等)实现车辆运行信息的提取(如加速度、位置、方向等),接着根据提取的运动信息设定事故判别规则,实现事故的检测。该类方法仅使用了运动特征作为事故判别依据,并未考虑事故外观信息,因此事故检测精度有限。近年来,基于特征融合的事故检测方法逐渐成为主流。一些研究主要采用三维卷积网络[13]、时空自编码器[14]或者双流神经网络[15]等同时捕捉事故外观和运动特征,因而获得了较高的检测精度。另外一些研究[16]通过检测异常的交通参与者(如摔倒的行人、侧翻的车等),并根据其运动规律设定相应判别规则,进而实现事故检测。然而,复杂的交通场景往往包含一些事故判别无关的外观特征(如道路、路侧房屋等,记作事故无关外观特征),以及一些事故判别相关的外观特征(如交通参与者位置与状态,记作事故相关外观特征)。在不进行特征筛选的前提下,这些融合特征提取网络因场景复杂、特征过多而难以收敛,并且这些模型因参数较多,难以保证事故检测的速度。因此,如何设计一个有效平衡检测精度与速度的事故检测模型成了本文的主要研究问题。
针对该研究问题,本文提出了一个基于特征融合的双阶段事故检测框架。该框架由外观特征筛选网络和融合特征提取网络两部分组成。其中,外观特征筛选网络使用残差网络来提高事故相关外观特征的筛选速度。为了进一步提高残差网络对事故相关外观特征的筛选能力,研究提出了一种事故注意力模块,该模型由通道注意力模块与空间注意力模块并联而成。融合特征提取网络由轻巧的、按时序排列的Conv-LSTM 模块构成,实现外观特征的微调和运动特征的提取。该检测框架的提出有望在有限算力的条件下平衡视频事故的检测精度和速度,从而在实际中得以应用。
1 研究方法
复杂交通场景下的一些事故无关外观特征(如道路、路侧房屋等)直接输入到融合特征提取网络中会产生冗余计算,从而导致模型难以收敛,因此,本文的基本思路是:先筛选事故相关外观特征,再提取融合特征,进而加速模型收敛。如图1所示,该网络主要包含两部分,分别为外观特征筛选网络和融合特征提取网络。首先,研究提出了嵌入事故注意力模块的外观特征筛选网络,并利用事故图像数据集进行预训练,使得训练模型具备忽略事故无关外观特征而侧重事故相关外观特征的能力。接着,事故相关外观特征被输入到按时间方向连接的Conv-LSTM 网络中,实现外观特征的微调和运动特征的提取(如车辆骤停、行人聚集等)。最终,研究基于提取的融合特征实现事故检测。
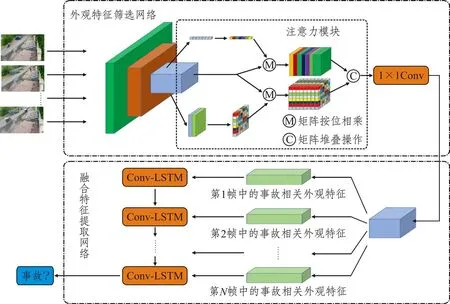
图1 基于特征融合的事故检测模型框架
1.1 基于事故注意力的外观特征筛选网络
研究采用嵌入注意力模块的残差网络为事故外观特征筛选网络。残差网络ResNet提出于2015年[17],采用残差模块(见图2)进行堆叠,实现了更深的网络结构以及更强的表达能力。其中,残差模块使用跳跃连接结构,有效保证了信息传输的完整性。表1 展示了现有常见残差网络的运算参数与其在ImageNet数据集(验证集)上错误率的对应关系。本文权衡模型大小和检测精度,选择了ResNet50作为基础的事故外观特征筛选网络。
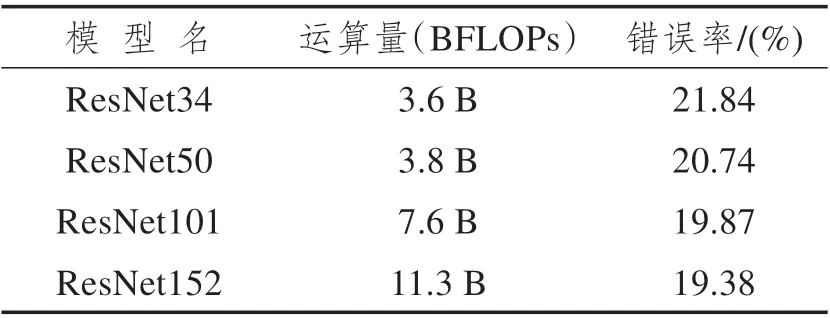
表1 常见残差网络的运算参数与其在ImageNet数据集(验证集)上错误率的对应关系
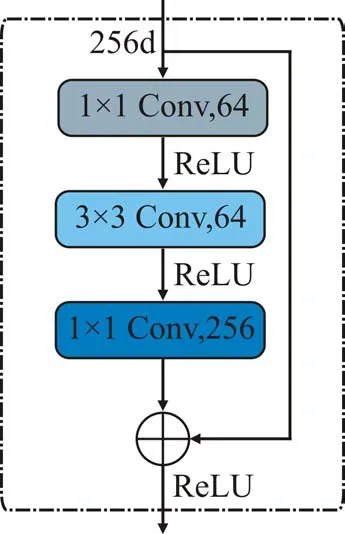
图2 残差模块结构图
目前,部分研究[18-19]表明视觉注意力机制能够加强卷积神经网络的特征筛选能力。为了进一步增强残差网络的特征筛选能力,本研究基于注意力机制,创新性地提出了一种事故注意力模块(图3)。该模块由两个注意力分支构成,分别为通道注意力分支与空间注意力分支。通道注意力[18]可以通过赋予事故特征高权重从而增强该类特征的识别能力;空间注意力[19]可以根据事故特征的空间分布实现快速定位能力。两者的结合可以有效地提升模型对于事故相关外观特征的筛选与定位能力。
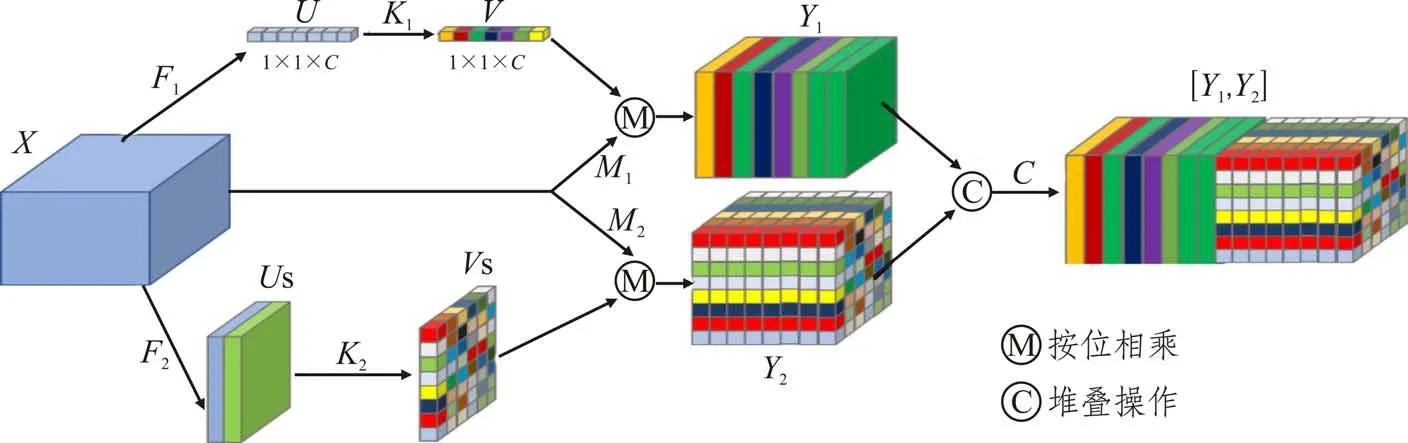
图3 事故注意力模块
在特征图中,每个通道代表了一类特征,通道注意力模块能够从输入特征图中学习到一种通道权重,这种通道权重将赋予特征图中不同通道以不同的权重,因此具有特征选择能力。具体地,通道注意力分支按通道维度采用全局平均池化操作,将输入X转换为U。接着将输出U经过一个权重为W的全连接层和一个softmax激活层(即图上的K1),输出注意力权重V。最后,将获得的注意力权重V与原始输入X按位相乘,调整输入特征图中各通道特征的权重,获得特征输出Y1。具体过程如下式所示:
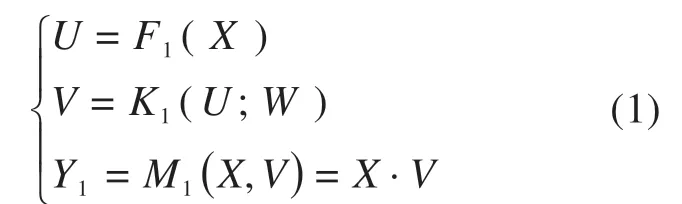
式中:F1为全局平均池化;K1为全连接层和激活层;M1为按位相乘操作,“·”为矩阵点积运算;X为原始输入;U为输入通过全局平均池化后的输出;V为通道注意力权重;Y1为通道注意力分支的特征输出。
同理,空间注意力模块能够从输入特征图中学习到一种按空间分布的权重,这种权重能够赋予不同空间位置以不同的权重,因此具有空间特征的定位能力。具体地,空间视觉注意力模块先是沿着通道对输入X进行最大池化和平均池化操作F2,获得网络输出US,如下式所示:

式中:F2为最大池化和平均池化操作;US为输入X进行最大池化和平均池化操作的输出。
接着,使用1×1 卷积层(参数为Wc)将双层特征图US转为单层特征图,并使用softmax激活函数将获得的单层特征图转为空间注意力权重VS,如下式所示:

式中:K2为1×1卷积(参数为W)和softmax激活运算;VS为获得的空间注意力权重分布。
最后,空间注意力权重VS和输入X进行加权求和,调整模型对输入X不同空间位置的重视程度,如下式所示:
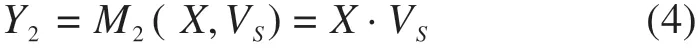
式中:M2为按位相乘运算函数;“·”是矩阵点积运算;Y2为空间注意力分支的特征输出。
通道注意力分支的特征输出Y1和空间注意力分支的特征输出Y2提取完毕后,模块将这两个输出按照特征维度进行堆叠,形成该注意力模块的最终输出[Y1,Y2]。可见,空间注意力模块赋予了图片中不同区域不同权重,有望提升ResNet50 网络快速定位事故发生区域的能力。
1.2 融合特征提取网络
外观特征筛选网络利用赋予事故相关特征较大权重的方式实现相关特征的筛选。该筛选的事故相关外观特征主要包括一些交通参与者(如机动车、非机动车、行人等)的位置信息及外观信息(如车辆的形状、是否受损等)。该相关特征作为后续融合特征提取网络的输入,可以有效降低该网络因处理庞大的无关特征而造成训练收敛等问题。本文选用卷积长短时间记忆网络Conv-LSTM[20]作为融合特征提取网络,该网络能够同时捕捉监控视频流中的事故外观特征和运动特征。
Conv-LSTM 模块是一种可以同时捕捉多维度特征的时空序列模型,其结构如图4所示。相比于传统LSTM 网络,该网络无需对数据进行铺平操作,有效地缓解因数据铺平而导致外观信息损失的问题。
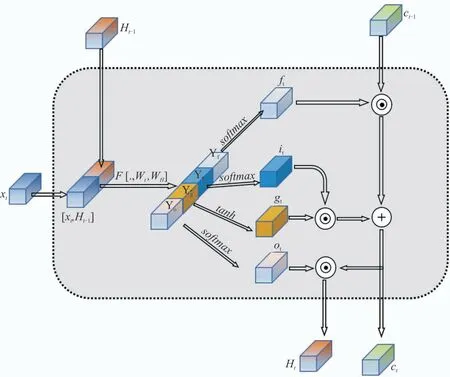
图4 Conv-LSTM模块结构图
Conv-LSTM 模块首先将输入沿着通道维进行堆叠,并引入了一维卷积对堆叠后的输入进行卷积运算,即:
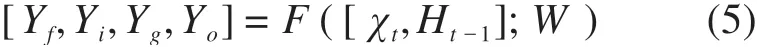
式中:χt和Ht-1为Conv-LSTM 模块的输入;[χt,Ht-1]为输入χt和Ht-1按通道维堆叠后的结果;函数F为1×1 卷积运算;[Yf,Yi,Yg,Yo]为输入[χt,Ht-1]通过1×1卷积层的四个输出的集合。
接着对[Yf,Yi,Yg,Yo]分别使用softmax激活函数得到[ft,it,gt,ot],即:
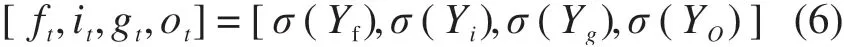
式中:σ(.)为softmax激活函数;[ft,it,gt,ot]为[Yf,Yi,Yg,Yo]经过softmax激活函数的输出结果。
最后通过门控操作获得时间步t时Conv-LSTM模块的输出,如式(7)和(8)所示:

式中:Ct-1为时间步t-1 时Conv-LSTM 模块的输出;Ct和Ht为时间步t时该模块的输出。
2 实验与结果分析
本研究的所有实验均在单个计算机上进行。该计算机配置如下:采用Ubuntu 20.04 操作系统;CPU 型号为Intel(R)Core(TM)i7-8700@3.20GHz;GPU 的型号为NVIDIA GeForce RTX 2070(8GB);事故检测框架的代码由Python=3.7.4 书写,由Pytorch1.6 深度学习框架实现。为降低深度学习算法随机性,本文所有实验的结果为五次训练取平均的结果。本文的代码现已开源①代码链接为:https://github.com/vvgoder/ResNet_ConvLSTM。
2.1 数据收集与处理
本研究借鉴以往研究中已经开源的视频事故数据库[21],并通过网络、交警部门等多方渠道进行数据收集。其中,开源数据集共包含1 416 段事故视频段,平均每段视频约包含366个视频帧。鉴于事故视频数量稀少且难以获取,为了提高模型收敛速度,降低对视频样本数量需求,本研究先收集了一套图片数据集进行外观特征筛选网络的预训练,在此基础上,额外收集了一套视频数据集对总模型进行参数微调。其中,图片数据集共包含5 061 张事故图片和5 573 张非事故图片。事故视频数据集共包含了420 个事故视频和432 个非事故视频,每段视频长度在20s 左右,所有视频分辨率均缩放至640×640大小。
2.2 模型预训练
为加速提出模型在视频数据集的训练和收敛过程,使得模型具备忽略事故无关外观特征,侧重事故相关外观特征的能力,研究首先基于图片数据集预训练外观特征筛选网络。训练过程的一些技巧和超参数设定如下:(1)外观特征提取网络利用ImageNet预训练权重进行初始化;(2)每批次同时处理32 张图片(batch size=32);训练轮次(epoch)设置为100;优化器选择Adam,迁移权重学习率设置为0.000 1,其他权重学习率设定为0.001,学习率每隔20轮降低为原来的一半。
同时,为了测试不同外观特征筛选网络的效果,研究以VGG16 网络和ResNet50 网络为基础网络,分别加入通道注意力模块[18]、空间注意力模块[19]以及事故注意力模块获得3 个拓展模型。其具体检测精度如表2(T:判断正确,F:判断错误,P:判断为事故,N:判断为非事故)所示。结果显示,相比于传统VGG 网络和残差网络,加入注意力机制后,扩展模型获得了更高精度。其中嵌入事故注意力模块的ResNet 模型获得了90.75%的准确率。

表2 外观特征筛选网络在测试集上的评估指标
2.3 模型对比
为了测试提出的事故检测框架的性能,本文主要从检测精度和速度两方面进行了模型比较,具体结果如下。
(1)模型检测精度对比
为了提高模型收敛速度,本文将预训练参数迁移至事故检测框架中,并使用330个事故视频和342 个非事故视频进行训练。为了测试提出框架的性能,本文引入了一个基于运行特征的经典模型(模型1),并将该模型与其余三个模型(模型2~4)进行检测精度比较。该经典模型利用规则式方法对提取的车辆运动特征进行异常分析与事故判别。表3展示了所有模型的表现。

表3 各事故检测模型测试集精度
相较于基于运行特征的经典模型(模型1),特征融合模型能够同时捕捉事故动作特征和外观特征,因此精度明显提升。模型2 虽然利用LSTM 网络引入了事故的运动信息,但在数据输入时需要铺平特征图而导致外观信息的损失,检测精度低于Conv-LSTM 类模型(模型3、4)。相比之下,Conv-LSTM 类模型(模型3、4)最大程度同时保留了事故的外观和运动特征(融合特征),提高了事故检测精度。模型4 中外观特征筛选网络嵌入了事故注意力模块,提升了模型事故定位能力,因此检测精度更高(88.89%)。
(2)速度对比与分析
为了测试提取框架的检测速度,本研究在单个GTX1060显卡(6GB,时钟速度为1506~1708 MHz)的测试环境下展开了系列实验。在检测速度方面,本研究提出的框架明显优于基于运动特征判别的事故检测模型(如表3 所示)。基于运动特征的检测模型通常利用目标检测和目标追踪模型来捕捉事故的运动特征,其在候选区域的选择和分类上耗费大量时间,导致检测速度无法很好地满足实时性要求。本文提出的模型采用轻量化的网络结构进行设计,因此检测速度更快(FPS>30)。
综合检测速度和精度,研究选取模型4作为最优模型,并进一步与一种典型的基于特征融合的模型(即C3D[13]模型)进行对比。结果如表4 所示,C3D 模型存在过拟合问题,训练准确率为99.85%,测试准确率为67.22%。原因是C3D模型比本文方法有更多的参数(超过10倍)。由于数据集有限,模型很容易被过拟合。在计算量FLOPS (Floating Point Operations)和检测速度FPS(Frame Per Second)方面,本研究提出框架也明显优于C3D模型。
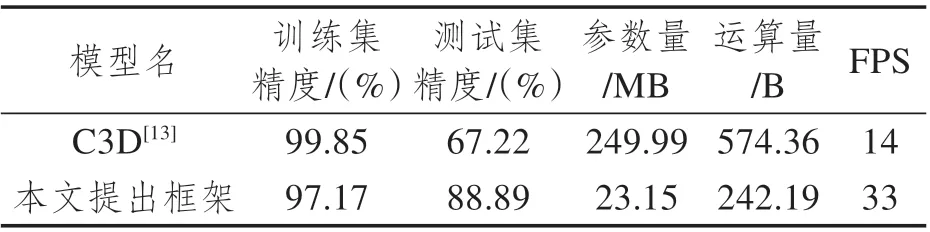
表4 本文提出框架与C3D模型的效果比较
2.4 模型分析
研究使用Grad-CAM 算法对最优模型(模型4)在部分视频数据测试集上的事故定位效果进行可视化(这里截取部分视频帧)。从图5可以看出,模型4可以较为准确地定位事故发生的大致区域,并随着事故发生位置的改变而动态变化。从事故3中紫红色区域的变化规律中可以看出,车辆碰撞行人后造成行人的摔倒和位置变化均能够被模型有效捕捉,体现了该模型在捕捉事故融合特征(外观特征和运动特征)的优势。

图5 动态可视化效果展示(模型4)
需要注意的是,该事故检测模型仍然存在一些漏检和误报情况。如图6所示,这些误检情况主要发生在拥堵场景和黑夜场景。首先,拥堵场景路况较为复杂且车辆重叠密集,导致拥堵环境下的事故与非事故存在较为相似的外观特征,混淆模型判别。其次,黑夜条件下因光照不足,网络难以捕捉交通参与者的位置,严重影响特征提取能力。

图6 误报和漏检情况
3 结 语
基于视频的交通事故快速检测对于提升交通事故应急管理水平具有重要意义。目前多数事故检测模型存在速度较慢或精度较低等问题,限制了其实际应用。为解决该问题,本论文提出了一种基于特征融合的双阶段事故快速检测框架,以实现有限的算力成本下事故检测精度和速度的平衡。总的来说,本文的主要贡献在于:
本文提出了一种基于特征融合的双阶段事故快速检测模型。实验结果表明,提出模型的检测精度达到88.89%,检测速度达到FPS>30(GTX1060 GPU)。相比传统基于运动特征的方法,提出方法具有更高的精度。相比其他经典特征融合模型(如C3D),提出方法在检测速度上更快。另外,本文提出了一种新型事故注意力模块,有效提高了残差网络特征选择和事故定位能力。最后,本文引入了Conv-LSTM 模型用于事故外观特征和运动特征的同步提取,实验证明该模型相较于传统LSTM方法效果更好。
当然,本文提出的方法仍存在一定的误判和漏检情况。在未来的研究中,可考虑利用细粒度分类方法以及图像增强方法解决拥堵场景和黑夜场景的事故检测,进一步提升事故检测的精度和速度。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31 08:59:12
阅读(快乐英语高年级)(2022年6期)2022-06-17 04:48:48
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
家庭影院技术(2021年10期)2021-11-20 06:08:52
电子制作(2018年11期)2018-08-04 03:25:38
紫禁城(2017年6期)2017-08-07 09:22:52
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
测绘科学与工程(2016年5期)2016-04-17 06:51:15
电子设计工程(2015年3期)2015-02-27 12:03:45
