
基于深度强化学习的城市交通信号控制综述
2022-03-15 09:21徐东伟丁加丽魏臣臣
交通运输工程与信息学报 2022年1期
徐东伟,周 磊,王 达,丁加丽,魏臣臣
(浙江工业大学,a.网络空间安全研究院,b.信息工程学院,杭州 310000)
0 引言
近年来,随着我国车辆保有量的急剧增加,交通拥堵已成为全国大中小城市普遍存在的交通问题,带来的负面问题也愈加严重。因此,交通拥堵问题的缓解刻不容缓[1]。交叉口是道路交通网络的关键节点和主要瓶颈,因此交叉口信号智能控制在缓解交通拥堵方面起着至关重要的作用。
随着计算机技术和数据处理技术的进步,交通系统正逐步朝着智能化方向发展。人工智能技术的发展使得以最少的人为行为干预控制交通系统成为可能。基于自适应控制方法的交通信号控制系统是目前广泛应用的信号控制系统,相比于固定配时系统,自适应交通信号控制系统提高了交通灯控制的的灵活性以及道路运行效率,但它难以应对大规模交通路网的交通信号协调控制[2]。
自Mikami[3]于1994 年首次将强化学习(Reinforcement learning,RL)用于交通信号控制优化以来,强化学习在区域交通信号控制系统中的应用越来越广泛[4,5]。但由于传统的强化学习方法适用于状态离散化的模型,因此,将强化学习方法直接应用于交通信号控制系统会导致计算复杂度过高。随后,由深度学习与强化学习结合的深度强化学习(Deep Reinforcement Learning,DRL)[6]方法的诞生,使得城市交通信号控制技术进一步迈入智能时代。
本文将介绍深度强化学习在城市交通信号控制中的研究与应用,并讨论基于深度强化学习的交通信号控制系统面临的挑战和有待解决的问题。
论文后续部分安排如下:第1部分简述主要的深度强化学习方法的基本理论,并介绍交通仿真环境;第2部分介绍深度强化学习方法在单交叉口交通信号控制领域的应用,并根据策略学习方法的不同进行分类和讨论;第3部分介绍深度强化学习的多交叉口信号控制协同优化,并对不同方法进行对比,分析优缺点,简要介绍目前用于交通信号控制仿真实验的路网环境和数据来源;第4部分讨论交通信号控制未来的研究方向和挑战。随着深度强化学习在智能交通系统控制中的广泛应用[2],希望本篇综述能为研究深度强化学习在交通中的应用提供参考。
1 概述
深度强化学习模型结合了深度神经网络和强化学习,适合处理高维数据和连续状态的科学问题。下面首先介绍强化学习的理论背景,然后介绍主流的深度学习模型。
1.1 强化学习
在强化学习中,智能体执行特定的动作并不一定能得到特定的状态,通常将执行动作后转到某个状态的概率建模为一个状态转化模型。在真实的环境转化过程中,环境转移到下一个状态的概率与之前多个环境状态有关。为了简化环境状态转化模型,在强化学习中假设转化到下一个状态的概率只与上一个状态有关,即假设状态转化具有马尔可夫性,因此强化学习模型大多由马尔科夫决策过程(Markov Decision Process, MDP)建模。MDP 模型按照情节逐步计算,每个情节的终止点为终止时间T[7]或终止状态sT[8]。
由于MDP 中利用贝尔曼方程求解状态值函数,即利用上一次迭代周期内的状态值更新当前迭代周期内状态的状态值,因此通常利用动态规划(Dynamic Programing,DP)[9]思想求解强化学习模型。在智能体状态转移概率和奖励函数未知的情况下,通常会使用蒙特卡洛(Monte Carlo,MC)[10]思想求解强化学习问题,即智能体通过采样多个完整经验的情景近似估计状态值函数。然而当环境中没有完整的状态序列,即智能体无法采样完整的经验情景时,MC 就无法求解强化学习问题。时间差分(Temporal Difference,TD)[11]方法是MC思想与DP 思想的结合,它采用单步更新的方式,从采样的不完整经验中学习值函数,不需要采样完整的经验样本。TD方法与MC方法相比提高了模型的灵活性和学习能力,因此目前绝大多数(基于值和基于策略梯度的)强化学习乃至深度强化学习算法都以TD方法为基础。
对于基于值的强化学习模型,每次迭代更新状态值函数,值函数将状态动作对映射为值。Q学习(Q Learning)[12]与SARSA[13]均为根据TD 思想提出的基于值的强化学习算法。Q 学习是一种离线的方法,通过最大化动作的Q 值来更新智能体的策略,而SARSA 是一种在线方法,根据Q 函数得到的策略更新智能体的行为。
对于基于策略梯度的强化学习模型,在每次迭代后采用策略梯度更新策略。最简单的策略梯度算法是蒙特卡洛策略梯度算法,将MC思想融入基于策略梯度的强化学习模型,利用MC方法计算状态值函数,近似替代策略梯度的价值函数。蒙特卡洛策略梯度方法基于完整的经验更新值函数参数,导致模型的学习效率较低。Degris[14]提出行动者-评判者(Actor-Critic,AC)方法,将基于值的算法与基于策略梯度的算法结合,并采用TD 思想实现Actor 策略函数的参数更新,使算法参数更新变为单步更新。行动者基于概率选择动作,评判者基于行动者的行为评估行为得分,然后行动者根据评判者的评分修改选择行为的概率。由于基于策略梯度的方法不需要搜索连续空间以及在表格中储存相应的值,所以对于高维数据问题,基于策略梯度的方法通常优于基于值的方法[15]。
1.2 深度强化学习
在交通信号控制的实际场景中,其任务具有高维状态空间和连续动作空间特征,传统的强化学习方法无法计算所有状态的值函数和策略函数。随着深度学习在监督学习领域应用的成功,基于深度学习的函数拟合器可以实现有效的函数逼近,训练好的神经网络可以实现最优策略和价值函数的学习。下面将介绍目前应用于交通信号控制的主流深度强化学习方法。
1.2.1 基于值的深度强化学习模型
由于基于值的强化学习算法将Q 值存储在表格中学习Q 函数,且在网络复杂和状态空间维数较高时传统强化学习方法难以计算,因此通过深度神经网络逼近Q 函数。Mnih[16]等人首次提出将深度神经网络与Q 学习结合的方法,即深度Q 网络,使用CNN近似计算环境的Q值。此外,针对传统强化学习方法的不稳定和偏差现象,Mnih[17]等人提出使用目标网络和经验回放稳定深度Q 网络的学习过程。其中,经验回放可以去除观测值之间的相关性并实现数据的随机采样、目标网络的周期性更新,能够减少每次采取动作后得到的Q 值与目标值之间的相关性。
尽管深度Q 网络(Dee Q Network, DQN)中利用了经验回放和目标网络,但仍无法克服DQN 的弱点——Q 学习容易过估计动作Q 值的问题。因此,Van[15]等人提出双重深度Q 网络(Double Deep Q Network, DDQN),将动作选择和值函数估计解耦,在计算实际Q 值时,动作选择由评估网络完成,值函数估计由目标网络完成,有效提高了模型的稳定性。由于均匀采样容易导致出现次数少但价值高的经验得不到高效利用而降低学习效果,Schaul[18]等人提出一种优先处理重要操作的方法——优先经验回放,通过应用具有比例优先级或排名优先级的样本,具有高TD 误差的样本在概率排名上高于其他样本,并根据分配的概率对经验进行抽样,这种方法在提升效果的同时还可以加快学习速度。此外,Wang[19]等人提出决斗深度Q 网络(Dueling Deep Q Network, Dueling DQN),将DQN 中直接估算Q 值改为估算状态值函数S和依赖于状态的行为优势函数A,这种方法在每次网络更新时,可以将状态下的所有动作的Q值更新。
1.2.2 基于策略梯度的深度强化学习模型
由于AC 的行为选择取决于评判者的值,导致AC 方法难以收敛,因此Lillicrap[20]将AC 方法与DQN 结合,提出深度确定性策略梯度算法(Deep Deterministic Policy Gradient, DDPG),该方法使用非线性函数近似表示值函数,使得函数能够稳定收敛,解决了Q 函数更新的发散问题,同时使用经验回放机制批处理学习,从而使训练过程更加稳定。在DDPG 的基础上,基于AC 方法的面向连续动作空间的DRL方法还有双延迟深度确定性策略梯度算法(Twin Delayed Deep Deterministic Policy Gradient,TD3)[21],通过延迟智能体更新和添加噪声的方式提高算法稳定性。此外,针对AC 方法难以收敛的问题,Mnih[22]提出A3C(Asynchronous advantage Actor-critic) 方法,与DQN 采用经验池降低数据间的相关性不同,A3C 采用异步的方法降低数据间的相关性。通过创建多个并行的子线程,让多个拥有子结构的智能体在并行的子线程中更新主结构的参数,降低数据间的相关性,加快收敛。但由于A3C 中各个智能体异步独立更新,会导致难以达到最优全局策略,A2C (Advantage actor-critic) 通过构建多个并行的同步子线程,在每轮训练中,全局网络会将子线程更新的梯度进行汇总并求平均,得到一个统一的梯度从而更新主网络的参数。
1.3 多智能体强化学习模型
多智能体强化学习(Multi-Agent Reinforcement Learning,MARL)系统遵循马尔可夫博弈(随机博弈)。在马尔可夫博弈中,所有智能体根据当前的环境状态同时选择各自要执行的动作,这些被选择的动作构成的联合动作会影响环境状态的转移和更新,并且会影响智能体获得的奖励。多智能体的马尔可夫博弈过程如图1所示。
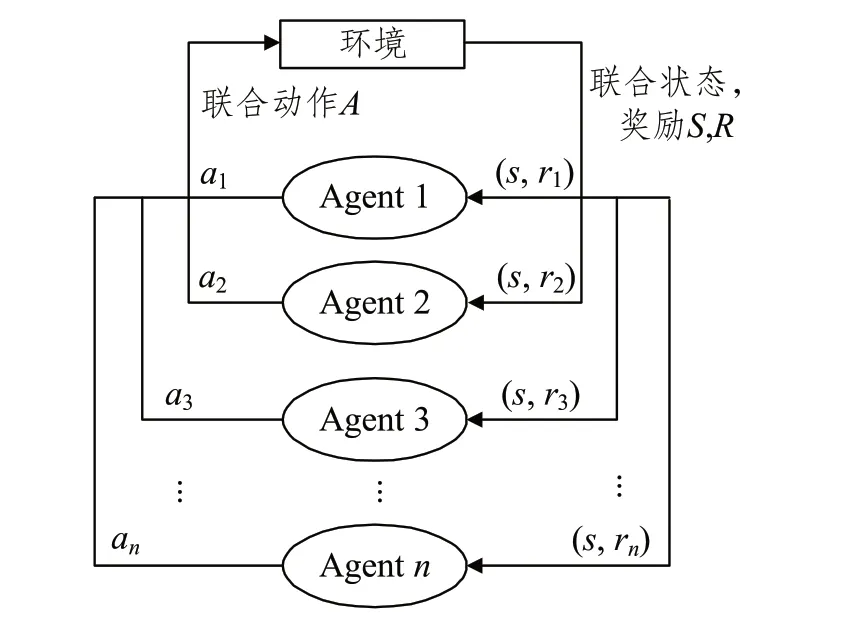
图1 多智能体的马尔可夫博弈过程
由于多智能体的学习和控制过程更加复杂,智能体之间存在的关系通常分为三类:竞争关系、半竞争半合作关系和完全合作关系,差异体现在算法的奖励函数中[23]。智能体具有半竞争半合作关系的系统通常使用混合奖励函数,在平衡贪婪和协作的重要性后学习最佳策略组合。具有完全竞争关系的智能体通常只优化智能体自身的控制策略。而具有完全合作关系的智能体在策略学习过程中考虑其他智能体影响的方式可以分为:无需协作、隐式协作和显式协作。无需协作方式假设最优联合动作唯一,因此不需要协作,但这种方式只在特定的场景下有效。分散Q 学习(Distributed Q-learning)[24]是一种无需协作的学习方法,在智能体学习的过程中不需要知道其他智能体的动作。隐式协作通过学习其他智能体的策略达到最优联合动作。显式协作在协商选择动作时需要通信,并逐步完善通信机制,在训练结束后根据通信机制做出决策。
在隐式协作方式中,为了得到最优策略,每个智能体需要考虑其他智能体的动作和状态,得到联合动作值函数,通常只适用于小规模的多智能体问题。平均场论(Mean Field Theory, MFT)[25]是一种隐式协作的多智能体强化学习模型。MFT 假设所有智能体是同构的,动作空间相同且动作空间是离散的,将智能体与其邻居智能体之间的相互作用简化为两个智能体之间的相互作用。算法将值函数转化为只包含邻居之间相互作用的形式,对联合动作做了简化,但仍然使用全局状态信息。通过与平均场论结合,提出了MF-Q 算法和MF-AC 算法[25],用以改进针对多智能体的Q 学习和AC 方法。基于平均场论的多智能体强化学习方法主要解决随着智能体数量的增加、智能体动作维度过高导致计算复杂度增大的问题,方法主要思想是将智能体的动作空间降维为二维动作空间。
1.4 基于深度强化学习的交通信号控制问题
在基于深度强化学习的交通信号控制中,路网中的交通信号通常由一个智能体独立控制或多个智能体协同控制,智能体表示交通信号灯,环境通常表示路网中带有交通信号灯的交叉口,状态st表示t时刻的环境信息,如车辆位置、车辆速度、车辆队列长度等;智能体决定采取下一时刻的动作使得奖励最大化,奖励通常表示车辆平均等待时间或队列长度等。在决策过程中,智能体会结合输入的状态、奖励做出相应的动作。下面介绍基于深度强化学习的交通信号控制方法在状态、动作和奖励方面的设定。
1.4.1 状态
智能体根据定量表示的环境状态决定采取的动作。由于方法结构的不同,基于深度强化学习的交通信号控制使用了许多种不同的状态表示。大部分作者将交叉口分割为固定长度的网格,通过每个网格中的布尔值确定该位置是否存在车辆,这种网络化的表示形式实现了交通状态编码的离散化,可以获得高分辨率的真实交叉口信息[26-28]。一些工作通过交叉口当前的快照获得车辆的速度、加速度以及交通灯的信号相位等信息[8,29,30],如Garg[31]将图像作为状态输入神经网络计算预定义动作的概率分布。还有一类广泛使用的状态定义方法是将交叉口各个车道的特定信息的平均值或总值作为特征组成一个状态向量,这些特定信息包括交叉口第一辆车的累计等候时间、交叉口一定距离内的车辆总数、车辆的队列长度以及信号灯的相位持续时间等[32,33]。还有一些研究将左转车占比作为状态信息[26]。
对于多交叉口交通信号控制问题,状态定义还包括附近交叉口信息,如交通灯信号相位、车辆数量以及平均队列长度等[34,35]。
1.4.2 动作
智能体在获得当前环境状态后,会从动作集中选择要采取的动作并观察动作带来的奖励及新的环境状态。当智能体选择改变相位的动作时,为保证交通安全,会执行黄灯过渡阶段[27]。对交通信号控制的智能体有不同类型的动作定义:(1)设置当前相位持续时间[36];(2)设置当前相位持续时间与预定义的相位总周期持续时间的比率[37];(3)在预定义的交通信号循环相序中,由当前相位改变到下一相位[38,39];(4)在预定义的相位中选择需要更改的相位[32,40-42]。由于大多数单交叉口交通信号控制问题中,动作集合通常为离散的,如保持当前相位或选择其他相位,因此,基于策略的深度强化学习方法较少应用于单交叉口信号控制中。
1.4.3 奖励
在强化学习中,车辆等待时间、累计延迟和队列长度是最常见的奖励定义。等待时间为车辆静止或速度小于某个阈值的时间[43,44],累计延迟为连续的绿灯之间的总延误差值[8,45],队列长度为每个车道的累计队列长度[2,46]。此外,为同时强调交通拥堵和行程延迟,有些作者将等待时间与权衡系数相乘后与队列长度相加[32,33]。在多交叉口问题中,通常会设置全局奖励和局部奖励,局部奖励反映每个交叉口的交通状况,提高每个智能体的稳定性;而全局奖励使得智能体协作以学习整个路网的最优策略。在智能体的学习过程中,首先通过局部奖励关注局部任务,然后利用学习到的局部信息优化全局策略。Lin[5]等人将交叉口的净流出量作为全局奖励,交叉口东西方向和南北方向队列长度差值的绝对值的相反数作为局部奖励,系统最终的奖励函数为局部奖励和全局奖励与系数相乘后相加的混合函数,即系统中智能体的关系为半竞争半合作关系。
1.5 交通信号控制仿真环境
由于多数交通信号控制系统使用仿真环境进行实验验证,因此本小节主要介绍用于交通信号控制的城市交通仿真软件。目前,基于仿真环境的城市交通信号控制研究中,使用的交通数据可以分为自主设定的交通数据和真实交通数据,如Natafgi 等人[47]利用黎巴嫩的真实交通数据在仿真软件中进行交通信号自适应控制实验。
目前的城市交通仿真环境主要有SUMO(Simulation Urban Mobility)[48]、Paramics[49]、VISSIM[50]、CityFlow[51]和MATLAB[52]等。其中,SUMO是最受欢迎的开源交通仿真软件,能够允许用户根据自己的目的设置和修改仿真环境,且可以通过Python 中的流量控制接口(TraCI)库与SUMO交互,同时设置和修改仿真环境。在2015 年SUMO 被首次使用后,此软件成为该领域最常用的软件;Paramics 于1992 年开发至今,其仿真环境中的路网建模和编程接口都较为完善和成熟;VISSIM由德国PTV 公司开发,可与西门子、飞利浦等多家公司的设备兼容;CityFlow作为近几年新的交通模拟软件,与SUMO 相比速度更快,已经被越来越多的研究学者使用,有望成为下一个主流的交通仿真软件。它是一种新的开源仿真软件,可以基于合成数据或真实数据进行多智能体交通信号控制仿真;MATLAB 使用频率较低,主要功能为数据分析计算,在交通信号控制仿真的实际应用中,通常与VISSIM 集成实现仿真。目前研究中使用的交通仿真软件多数为开源交通仿真软件。
交通系统是一个涉及车辆、道路和交通环境的复杂系统,含有许多不确定的因素。利用交通仿真工具,不仅可以将复杂交通信号控制问题具体场景化,而且可以在仿真环境中反复进行低成本实验。由于当前交通信号控制大多在仿真环境中进行,而智能交通信号控制DRL 模型的研究工作是为了推动智能交通信号控制的实际应用,因此基于真实路网构建仿真环境路网是后续研究工作的必然发展方向。
2 基于深度强化学习的单交叉口信号控制优化
目前用于交通信号控制系统的深度强化学习方法大致可分为两类:(1)基于值函数的方法,有深度Q 网络[39]、双重深度Q 网络[15]、决斗深度Q 网络[19]、双重决斗深度Q 网络(Double Dueling Deep Q Network)[29]、具有优先经验回放的深度Q 网络(Prioritized Experience Replay)[18]等;(2)基于策略梯度的方法有:优势行动者-评论者(Actor-Critic,A2C/A3C)[22]等。
近年来,强化学习与深度学习相结合的深度强化学习方法在交通信号控制领域应用越来越广泛,并且取得了令人满意的结果。单交叉口交通信号控制主要由单个智能体进行训练和执行,基于值和基于策略的方法都可以很好地满足需要。还有许多学者从改进深度学习模型的输入或深度强化方法、考虑车辆异质性、考虑路网关键点等方面入手,优化用于交通信号控制的深度强化学习模型。基于深度强化学习的单交叉口信号控制系统方法汇总于表1。
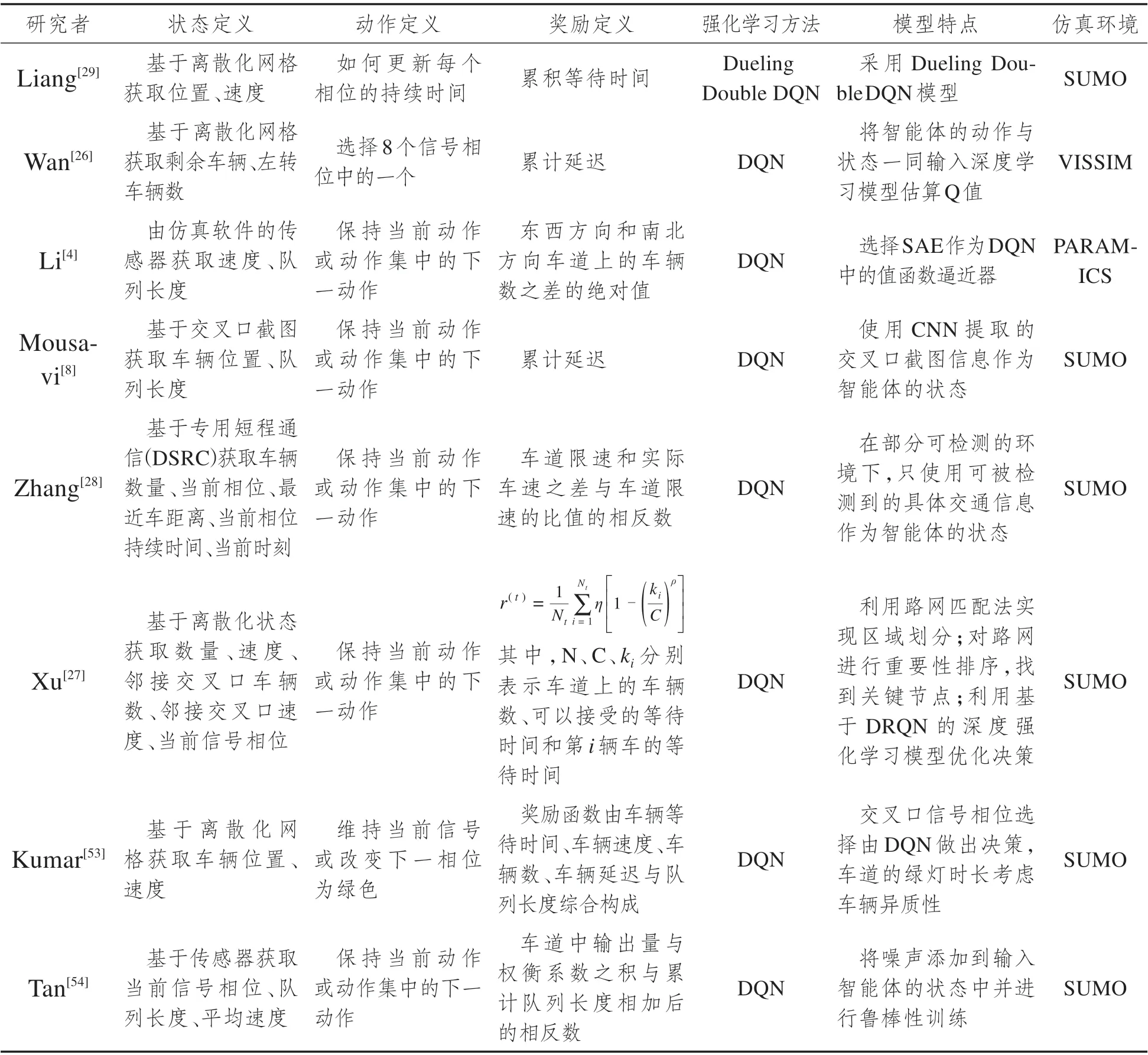
表1 基于深度强化学习的单交叉口信号控制系统方法
2.1 改进深度强化学习方法
为了解决DQN 容易高估Q 值的问题,Liang[29]等人提出将双DQN 与决斗DQN 结合的方法——双重决斗DQN,以增强模型的稳定性,其中,使用CNN 分别作为Q 值函数逼近器和目标网络。与其他大多数方法不同的是,作者将动作集定义为如何更新交叉口每个相位的持续时间。此外,作者使用优先经验回放提高有意义的经验采样率,与DQN 方法相比,明显减少了车辆在高峰时期的平均等待时间,并提高了模型的可收敛性。这也是首次将决斗网络、目标网络、双Q 网络和优先经验回放结合到一个框架中来处理交通信号控制问题,为面向强化学习的交通信号控制系统提供新的思路,但双DQN和决斗DQN在提高模型学习效果的同时也会使得模型的训练过程不稳定。
Mousavi[8]等人分别提出基于值的交通信号控制方法和基于策略梯度的交通信号控制方法。其特点在于,将交叉口的截图直接作为状态输入CNN 获得车辆位置和队列长度,且仿真结果优于浅层神经网络和固定时间的交通信号控制方法。实验验证了这种方法在模拟环境中的可行性,并且在智能体训练和应用过程中没有出现不稳定性问题。但是模拟环境与实际物理场景可能不同,由于这种方法应用交通模拟器采集的车辆位置图像和队列长度以找到信号的最优控制策略,因此现实环境中干扰物较多的情况下如何保证识别准确率也需要考虑。
Wan[26]等人将动作和状态同时作为神经网络的输入估算Q 值并输出某一个动作,根据智能体的两个动作执行时间间隔确定动态折扣因子,时间间隔越长,则折扣因子越小,即时间间隔越久的动作对当前值函数的影响越小。在与DQN 等方法的对比实验中发现,将动作作为输入添加到神经网络中,训练结束后只需要输出一个动作的值可以使DQN 的训练难度降低。但是DQN 框架只能在离散动作空间中使用,因此尝试在连续动作空间应用该方法处理交通信号控制问题更具有现实意义。
2.2 自编码器结合深度强化学习方法
Gender[55]等人根据交通环境中的具体信息(车辆位置、速度等信息),将状态表示为类图,使用离散交通状态编码,在DQN 中使用卷积神经网络(Convolutional Neural Network, CNN)估算离散动作的Q 值。但是Q-learning 方法中使用贪婪策略虽然可以快速让Q 值向可能的优化目标靠拢,但容易导致过度估计。Q 值过度估计会使策略产生震荡,使得模型策略陷入局部最优,导致最终得到的算法模型有很大的偏差,因此Li[4]等人通过将DQN 中的值函数逼近器由传统的DNN 更改为堆栈自编码器(SAE)。这些方法主要着重于不同深度学习模型在强化学习中的应用。
2.3 模式模糊推理结合深度强化学习方法
一些方法通过改变交叉口输入或利用模糊推理定义车辆优先级实现单交叉口交通信号控制的优化。如Kumar[53]等人首先根据车辆种类将道路运行模式分为三类:公平模式、优先模式和紧急模式,通过模糊逻辑推理确定道路当前运行模式,并根据车辆类型分配相应车道的绿灯时间。其次,智能体的动作集合为选择维持当前动作或切换动作集合中的下一相位,绿灯持续时长则由道路运行模式决定。
该方法与改进的深度强化学习方法有很大不同,通过考虑车辆的异质性(例如优先安排应急车辆通过)最小化等待时间,与其他几种基于模糊推理、神经网络或只基于优先级的方法比较,在减少CO2排放和平均等待时间上有积极效果。但模糊推理需要大量内存,在智能体数目较多时会损失精度。
2.4 关键节点挖掘结合深度强化学习方法
Xu[27]等人认为路网中的关键节点对缓解交通拥堵起着至关重要的作用,关键节点被识别为如果发生故障将导致道路网络交通效率大幅降低的节点,因此优化关键节点的信号控制具有重要意义。文中将交通信号控制系统分为两个阶段,分别为路网关键节点发现阶段与信号控制策略学习阶段。路网关键节点发现阶段,通过地图匹配方法实现路网区域划分,并将路网划分为三分图,然后根据三分图对每个交叉口的重要性进行排序,实现路网关键节点被发现;在发现路网关键节点后利用基于深度回归Q 网络(Deep Recurrent Q Network,DRQN)的交通信号策略学习实现对关键节点的控制,在DRQN 中值函数逼近器为LSTM,在每个情节中利用ε-贪婪策略选择一个动作。
较大规模的交通路网更容易导致交通拥堵,要解决这一问题就需要更多的智能体或输入的状态空间维数增加,这会导致智能体学习效率降低。该方法通过对关键节点进行优化控制提高大规模路网交通效率,且仿真结果略优于基于DQN 的交通信号控制方法。但实验中缺乏流量峰值时的对比实验,当路网处于流量峰值时,在路网中选取的关键节点的数量和规则也需要考虑。
2.5 鲁棒性增强结合深度强化学习方法
Tan[54]等人将双DQN 作为交通信号控制策略学习方法,状态定义为当前信号相位、队列长度和道路中车辆的平均速度。图2 给出了深度强化学习循环过程[54],为进一步提高交通信号控制系统的鲁棒性,将噪声信息添加到状态集的队列长度中,而其他状态则不受影响并通过多层神经网络进行对抗训练,提高模型的抗噪能力。

图2 深度强化学习循环过程[54]
由于深度强化学习交通信号控制在实际应用时,模型的鲁棒性和安全性是最关键的问题,因此通过在模型训练过程中添加适当噪声模拟现实世界中状态信息获取不准确的情况,以有效提高模型的鲁棒性。在实验中证明经过对抗训练的智能体在不同噪声场景下具有更好的表现,这为深度强化学习交通信号控制系统从模拟环境走向现实环境提供了可行方案。
2.6 部分可观测车辆结合深度强化学习方法
目前大多数研究都是在环境为完全可观测环境的假设上进行的,Zhang[28]等人通过设置部分车辆为不可观测车辆,利用DQN、优先经验存放和目标网络实现在部分可观测环境中改善交通信号控制。方法的特点是由于部分车辆可检测,因此论文选择交叉口中更具体的信息作为状态,如可检测到的车辆数量、当前相位、最近车辆的距离、当前相位持续时间和当前时刻。其中,将当前时刻作为状态输入是为了模拟现实生活中的交通模式。将模型分为训练阶段和执行阶段,将训练阶段训练好的模型应用于未知的执行阶段的环境。设置车辆检测率从0%到100%进行改变,分别观测交通信号控制的结果,通过训练阶段与执行阶段的不同检测率设置,检验模型性能。实验结果表明,模型的迁移性较好,具有一定的实际意义。
这是一种在部分检测场景下优化交通控制问题的新方法,追求以更低的检测率来实现较优的交通流量控制。这种方法考虑到了稀疏、中等和密集三种车流量的情况,虽然在稀疏车流和密集车流情况下优化结果大有不同,但依然能提供良好的整体优化方案。此外,在密集车流量情形下,相比于其他完全可观测的场景,该方法中能被检测到的车辆通行时间缩短,但总体的车辆等待时间还有待进一步优化。
3 基于深度强化学习的多交叉口信号控制协同优化
近年来,多交叉口交通信号控制越来越成为人们的研究热点。本节通过对多交叉口交通信号控制方法和技术进行对比,将基于深度强化学习的多交叉口信号控制系统方法汇总于表2。

表2 基于深度强化学习的多交叉口信号控制系统方法

续表2
3.1 智能体中心化结合深度强化学习方法
Arel[56]等人利用路网中的中心化的Q 学习网络控制多交叉口。中心智能体接收其邻近智能体的流量信息学习价值函数,并且设置了中心智能体的奖励函数与多智能体的平均奖励函数优化中心智能体的策略。中心智能体的邻近智能体采用最长队列优先(LQF)的方式实现信号控制,中心智能体通过将Q 学习结合前馈神经网络实现Q 值估计。
该方法通过中心智能体和邻近智能体之间不同的控制方式,并由邻近智能体向中心智能体提供本地交通数据信息从而与中心智能体进行协作控制。实验结果清楚地证明了基于多智能体RL 的控制优于LQF 控制的孤立单交叉口控制。同时这也是一种分布式的控制方式,因此具有良好的可扩展性,可较好地应用到规模较大的路网中。
3.2 复杂状态表示结合深度强化学习方法
Rasheed[57]等人通过考虑相邻智能体的动作,以多智能体协作的方式学习最佳联合动作,且通过每个智能体的Q 值相加后得到全局Q 值。此外,为使环境更接近真实情况,实验中考虑暴雨天气对交通状况的影响,将暴雨程度作为状态输入DQN中实现交通信号控制。
一些强化学习交通信号控制方法容易受到维数灾难的困扰,环境的表示和动作空间可能是高维和复杂的,这会使得模型训练难以收敛。因此Rasheed[57]等人研究了在高流量和高干扰的交通网络场景下进一步解决维数灾难的应用,与基本模型相比,该模型在仿真中能够获得较高奖励,并在真实交通路网下进行了实验验证。
3.3 改进深度强化学习方法
由于DQN 自身收敛效果差的缺点,Gong[58]等人将双重决斗DQN应用于多交叉口交通信号控制中。将智能体动作空间中的部分动作设置冻结期,处于冻结期的动作无法被选中,以提高模型的稳定性。Kim[59]等人也将双重决斗DQN 与优先经验回放应用于多交叉口交通信号控制优化,将时刻、温度等作为特征预测交叉口下一时刻的流量,并将预测值和智能体的动作输入NoisyNet,实现强化学习智能体的探索过程。相较于基于ε-贪婪的探索方法,NoisyNet更加适用于高维动作空间。针对多交叉口交通信号控制,利用分布式强化学习的思想,每个智能体在更新Q 值网络时考虑其相邻智能体上一时刻的Q值,通过多智能体协作获得全局最优值。将双重决斗DQN作为多交叉口信号控制的方法能够解决模型的过估计问题,但由于算法对数据和环境的要求较高,模型训练难度较高,因此模型的迁移性较低。
Chu[32]等人根据IDQN[65]提出多智能体A2C(MA2C),在非完全观测的条件下,将每个智能体的相邻智能体的最新策略与智能体当前状态一同输入DNN 网络中,并且将距离较远的智能体的信息按比例缩放,提高算法的稳定性和可收敛性。文中使用混合奖励函数,智能体之间的关系为半竞争半合作关系。其中全局奖励为所有智能体即时奖励之和。将全局奖励与提出的空间折扣因子相乘后,再与时间折扣因子相乘得到反馈给每个智能体的折扣全局奖励,最终每个智能体的混合奖励为反馈的折扣全局奖励与邻居智能体折扣后的值函数相加之和。实验结果显示该方法在平均奖励和队列长度以及路网中的车辆吞吐量上均优于无协作的IA2C 和贪婪算法。当路网规模扩大时,基于分散训练的多智能体模型的训练效率会降低,因此可扩展性较差。
3.4 图卷积神经网络方法
Li[44]等人在训练时考虑到全局状态实现协作,将其他智能体的相位信息以布尔值形式存放在离散表格中,并将其输入值函数逼近器中实现信息共享,每个智能体通过DQN 学习策略。但智能体单独训练的方式可能会导致模型难以稳定收敛。由于DQN 中常用的状态信息学习模块通常基于CNN,而CNN 对于拓扑结构的信息处理能力较差,因此Nishi[41]等人使用图卷积神经网络(GCN)直接提取路网几何特征,并以分布式方式控制交叉口交通信号,使用N 步神经拟合Q 迭代(NFQI)批处理收集的数据从而更新Q值。
与其他一些多交叉口控制方式不同,这种方法不是直接与其他智能体进行通信,而是通过所提出的方法学习控制策略且每个交通信号灯由单独学习的策略控制。GCN 能够根据远距离道路之间的交通关系自动提取特征,且这种方法拥有两倍于基于强化学习方法的学习效率,更快地找到最优策略。在与基于CNN的深度强化学习方法对比实验中,基于GCN的深度强化学习方法略有提升,但模型中智能体属于完全竞争型,降低了网络的稳定性。
3.5 独立双Q学习方法
Wang[61]等人提出一种基于协作的独立双Q 学习(Co-DQN)方法。Co-DQN 采用置信上限法则(UCB)进行智能体的动作探索行为。在多智能体学习过程中,为保证模型收敛和降低复杂度,作者应用基于平均场论的多智能体强化学习模型,减少动作空间维度,提出了独立双Q 学习方法。在提出的独立双Q 学习方法的基础上,每个智能体的奖励函数由智能体自身和其相邻智能体的加权奖励函数之和代替,相邻智能体之间共享状态信息,得到的Co-DQN模型提高了训练过程的稳定性。
该方法与MA2C、IQL 等较为先进的方法相比具有更高的奖励,且该方法的奖励比较稳定。但置信上限法则的收敛速度较慢,对高度复杂问题的解决能力有限,不适用于大规模路网中的智能体训练。
3.6 中心训练结合分散执行框架方法
Li[30]等人将多智能体深度确定性策略梯度(MADDPG)算法应用于多交叉口交通信号控制的优化。在MADDPG 算法中,智能体利用中心训练-分散执行(Centralized Training Decentralized Execution, CTDE)框架,同时训练需要全局信息的Critic 网络和只需要局部信息的Actor 网络,并使用Critic 网络对Actor 网络进行参数更新,执行时Actor网络只了解局部信息也能获得近似的全局最优策略。每个智能体根据其他智能体的全局信息训练学习策略,并根据其他智能体的预估策略调整局部策略。由于每个智能体有单独的奖励函数,因此MADDPG 算法可应用于存在完全合作、完全竞争和半竞争半合作关系的任务中。与基于DDPG的仿真结果相比,基于MADDPG 的算法可将收敛性提高,且平均车辆等待时间明显降低。
Wu[62]等人在MADDPG 的基础上提出MARDDPG,与MADDPG 的不同之处在于,MARDDPG在Critic 网络和Actor 网络中添加了循环神经网络(LSTM)提高模型在非完全观测环境下的稳定性。此外,为了提高算法的训练效率和收敛速度,将参数共享机制融入Critic 网络。为了更加符合实际情况,将多交叉口中的车辆设置不同优先级,如公交车比私家车具有更高的优先级,并进一步考虑行人的影响。MARDDPG 的仿真结果相比MADDPG有所提高。
基于MADDPG 的方法与基于MARDDPG 的方法都采用AC 网络实现,但Critic 网络的输入空间会随着道路网络规模的扩大而线性增加,导致模型难以收敛,可以通过考虑相邻模型的信息提高模型的可收敛性。
3.7 信息交换结合深度强化学习方法
在智能体协作过程中,通过相邻交叉口获得的信息维度较低且时滞较严重,导致智能体之间通信的鲁棒性降低。为解决这一问题,Xie[33]等人提出了一种基于信息交换的方法来解决交通信号控制问题,即用非即时信息代替即时信息,使用上一时刻的观测信息代替当前时刻的观测信息。提出的模型可分为三部分:信息抽象块、信息交换块和DQN。其中,信息抽象块将局部智能体上一时刻的信息通过神经网络学习后得到的较低维通信协议传送给其他智能体,且所有智能体之间共享信息抽象块的参数。信息交换块根据智能体之间影响的重要性和智能体对其他智能体的敏感性自动学习通信协议参数、分配权重。Q网络块根据信息交换块输入的影响系数和其他输入信息输出Q值。为缓解局部可观测问题,文中假设将交叉口之间信息和当前局部观测信息整合后作为完全可观测状态。
图3 给出了实验结果中的车辆平均队列长度和车辆平均延迟时间对比图[33],与MA2C和IQL等方法相比,该方法可获得最低的平均队列长度和平均延迟。智能体间共享参数能够提升算法的训练效率,但这种方法只适用于较为简单的路网,对具有不同动作空间的交叉口适用性较差。
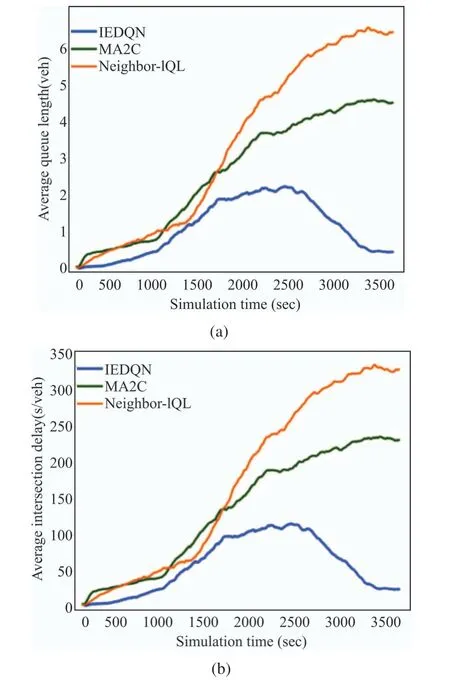
图3 三种算法的车辆平均队列长度和车辆平均延迟时间对比[33]
3.8 元学习器结合深度强化学习方法
Zang[63]等人将基于值的元学习方法[65]应用于交通信号控制中,元学习过程可分为训练过程和测试过程,目的是训练一种通用的元学习器,训练好的模型可以适应不同种类和数量的交叉口。通过两个模块交替更新参数实现:个体适应模块和全局适应模块,其中个体适应模块每个时刻逐步优化参数,全局适应模块通过批采样任务同步更新,并最终将最优的全局适应模块的参数传递给个体适应模块。其中,个体适应模块的参数学习方法为FRAP++,FRAP++是作者基于FRAP 方法[67]改进后的方法,将相位表示由求和改为求均值后提高了模型的迁移能力。
这种方法提高了模型的迁移性,训练好的元学习器可以适应新的交叉口,通过转移先前学习的知识提高交通信号控制中深度强化学习的学习效率。
3.9 归纳动态图强化学习方法
Devailly 等人[60]基于归纳图强化学习(Inductive Graph Reinforcement Learning,IG-RL)将交叉口中的对象(车道、信号灯以及车辆)建模为拓扑结构图中的节点,对象之间的物理连接关系建模为拓扑结构图中的边,由节点和边构成动态拓扑图,采用GCN在相同类别的节点间、同交叉口中的对象间共享参数。其中,拓扑结构图中的节点表示交通信号控制器的状态(当前相位、连接关系),连接节点表示交叉口入口车道与出口车道的连接关系(与拓扑结构图中节点的当前相位有关),车道节点表示车道状态,车辆节点表示车辆状态。通过分布式RL 训练模型,训练过程中,在多种路网拓扑结构、交叉口拓扑结构、交通车辆分布的环境中收集经验,并通过学习到的经验更新共享参数。通过包含多样性路网拓扑结构的训练集限制相邻交叉口的影响,提高训练过程的稳定性和模型的可扩展性。将在多种路网拓扑结构中训练好的模型应用于测试路网,根据模型在测试路网中的表现评估模型的可迁移性。作者设计了丰富的实验,在IG-RL 中分别只考虑车辆级别信息和车道级别信息,验证了基于车辆级别信息训练模型的泛化能力更好,可迁移性更高,模型在正常流量和高峰流量情况下能获得更好的控制效果。
由于在真实交通环境中进行交通信号控制的研究较难实现,目前绝大多数基于深度强化学习的交通信号控制研究都是在仿真环境中完成的。前面介绍了目前常用的仿真软件,仿真软件可根据不同环境和参数实现不同场景下的仿真。目前大多数仿真实验都是通过在仿真软件中构建单个或多个网格路网实现多交叉口或单交叉口的交通信号实验[29,41,56,61],许多工作中分别将真实的路网结构和基于仿真软件构建的网格路网作为实验路网[30,57,65]。如Chu[32]等人将Monaco 市的真实路网作为实验路网,同时构建了一个5*5的网格路网作为实验路网。
还有一些研究不仅使用真实路网,还根据一些公开的交通数据设置相应的模拟参数,使得仿真情况更接近实际场景。如Gong[58]等人使用佛罗里达州Orlando 市Seminole 县的真实路网作为实验路网,并根据Seminole 县提供的真实信号控制时序作为对比方法,从Orlando 市区交通研究(Orlando Urban Area Transportation Study,OUATS)中获取了2009 年Orlando 市Seminole 县相应路网的日常OD 矩阵,并依此规划车辆轨迹。Zang[63]等人使用通过监控捕捉的杭州和济南地区的部分十字路口车辆信息,以及美国Atlanta 和Los Angeles 通过沿街摄像机捕捉的车辆完整轨迹分别作为试验数据集,进行模型的可迁移性对比。文中使用的路网和数据集均是通过美国ITS DataHub 网站的公开真实数据集,ITS DataHub 中的数据集包括连接车信息、自动车辆数据、车辆轨迹现场测试数据以及天气数据等。表3 总结了基于强化学习的交通信号控制仿真实验路网及数据。

表3 基于强化学习的交通信号控制仿真数据及路网
DRL 算法需要依靠大量的数据集,通过不断的探索寻找最优交通信号控制策略。训练完成后的智能体迁移性较差,在不同的交通流分布下表现出不同的性能。但是仿真实验的车流量、车轨迹的分布等大多由作者设定,因此智能体训练时的车流量要符合真实的交通流量分布。但是,不同模态(工作日和周末、高峰和平峰等)的车流分布往往会有很大差别,这种情况会给交通信号控制的DRL模型训练和通用性造成困难。
4 总结与展望
本文针对基于深度强化学习的交通信号控制方法做了全面的调查,并按照单智能体(单个交叉口信号控制)和多智能体(多个交叉口协同控制区域交通流量)两部分进行总结,且列举了可用于交通信号控制实验的模拟环境。下面对未来的研究方向进行探讨。
4.1 状态空间、奖励机制
正如前面所述,基于深度强化学习的交通信号控制使用许多种不同的状态表示,较多的状态具有大规模的状态空间,而强化学习作为一种不断试错去学习最优策略的算法,会导致学习效率的下降。学习效率的下降同样也会带来交通信号控制中交通拥堵的出现。最新的研究[42,68]表明,简易的状态空间和大规模复杂的状态空间训练得到的智能体性能相近,但是简单的状态能节约计算成本并提高学习效率。因此建议应用简单的状态作为智能体的输入,提高交通信号控制智能体学习效率。
奖励作为强化学习的重要环节,因此不同的奖励机制会影响运行结果。现有文献通常使用一种替代奖励,该奖励可以在行动后有效测量,例如平均等待时间、平均队列长度、平均速度、车辆吞吐量等均可作为智能体的奖励激励智能体学习最优策略。由于不同奖励设置的出现,奖励中多个因素的权重设定也成为困扰。因此,研究人员需要寻找最能确切反映智能体学习目标的因素,以更高效的方式控制交叉口交通流量。
4.2 算法复杂度
为了提高模型的性能,一些基于值的深度强化学习方法通过优化策略学习过程防止模型过估计动作的Q 值。一部分工作[41]将用于值函数逼近的深度学习方法由CNN 替换为GCN 提高交通信号控制系统的性能;还有一部分工作[58]引入3DQN等先进方法。虽然这些方法能够提高模型性能,但同样也增加了算法的复杂度和模型的收敛难度。过高的算法复杂度与传统的信号控制理念严重相违背,因此在追求模型高性能的同时要兼顾算法复杂度。
4.3 安全性
深度强化学习在交通信号控制应用中表现出了卓越的性能,但由于其模型内部的黑盒性质以及不可解释性,导致人们无法完全信任模型作出的决策。尤其是使用智能交通信号灯控制交叉口车辆流通时,对决策结果一味的信任可能会导致交通严重堵塞。因此深度强化学习系统真正应用到实际之前,探究深度强化学习系统的鲁棒性十分重要。安全性对于实际应用是至关重要的,基于深度强化学习的多交叉口交通信号控制系统若受到攻击,对城市交通的影响难以想像。因此,针对深度强化学习的安全漏洞[70]研究可以推动研究人员找到抵御对抗性干扰的方法提高模型的鲁棒性,这能够在很大程度上提高交通控制系统的安全性,加快深度强化学习在交通信号控制中的实际应用。
4.4 模型鲁棒性
由于目前绝大多数交通信号控制研究都是在仿真环境中完成的,使用的交通数据和交通路网通常是由人为设定的数据仿真生成,缺少真实性,训练好的模型应用到实际问题中的效果难以保证。因此,如何提高模型的鲁棒性同样是深度强化学习交通信号控制系统最关键的问题。虽然面向强化学习的元学习方法[63]和Devailly 等人[60]利用GCN 建立动态关系被应用在交通信号控制中,通过提高算法对新的交通场景的适应能力,从而提高模型的迁移性。未来可以通过大量的真实数据集,包括环境中交叉口附近的车辆、人群以及建筑物等信息构造一个更加逼真的交通环境。此外,还可以通过考虑人群轨迹等信息等进一步优化交通信号控制系统。这是从模拟环境到现实世界转换的关键。
4.5 公平性
在实际设计交通信号控制系统时,公平性是非常重要的。由于当前大部分的深度强化学习交通信号控制方法是一种在线的自适应控制方式,即当前相位持续时间结束时才能确定下一相位,这会导致驾驶员不知道要在交叉口等待多长时间。然而在实际场景中,这种特性会导致实际应用过程无法展示红灯倒计时时间,并且拥有红灯倒计时装置的路口同样有助于减少启动延迟。这或许也是能够略微减少车辆等待时间的有效方法之一,值得研究人员深入考虑。
4.6 混合驱动思想
传统的信号控制方法将交通信号控制作为一个优化问题,交通模型可以通过最大压力控制器来减少路网中干线交通网络的队列长度,但在现实世界中交通状况容易受到众多因素干扰且这些因素很难在交通模型中进行描述。而强化学习算法可以描述有效的状态信息,但有学者意识到单纯的强化学习算法并不是最好的,因其存在一些问题:(1)采样效率低:模型训练中需要从经验回放池采样几万甚至更多的样本进行训练,计算成本巨大。(2)激励函数:强化学习总是需要一个奖励函数。设定的奖励函数必须准确地与实现的目标相同,但是奖励函数的定义也是关键性问题。奖励过于丰厚或匮乏都会影响智能体学习最优策略。(3)泛化能力差:DRL 有可能会过度适应训练环境,导致该模型在其他环境中迁移性较差。因此在交通信号控制方法的改进中,将强化学习算法与传统交通信号控制算法结合或许是一种有效的改进思路。
综上所述,当前通过DRL 解决交通拥堵问题的研究大部分依托于模拟交通数据和仿真交通网络。但我们不能局限于在仿真环境中带来的实验效果,在未来研究中,可以嵌入混合交通流、紧急车辆优先等管理思想增强决策实用性;深入分析DRL 学习参数对性能的影响,提高决策的可靠性;利用真实的交通流数据、在实际交通路网中进行实验,最终达到提高区域车辆通行效率,推动DRL在智能交通控制中的发展和实际应用。
猜你喜欢
建材发展导向(2022年14期)2022-08-19
建材发展导向(2021年19期)2021-12-06
西部交通科技(2021年9期)2021-01-11
铁道通信信号(2020年3期)2020-09-21
天津建设科技(2020年2期)2020-05-13
铁道通信信号(2020年8期)2020-01-05
中国交通信息化(2019年11期)2019-08-13
中国交通信息化(2019年1期)2019-03-26
中国交通信息化(2019年2期)2019-03-25
环球飞行(2018年7期)2018-06-27
