
基于孪生网络的目标跟踪研究综述
2022-03-13 23:23韩明王景芹王敬涛孟军英刘教民
河北科技大学学报 2022年1期
韩明 王景芹 王敬涛 孟军英 刘教民




摘 要:近年来,基于孪生网络的目标跟踪算法由于在跟踪精度和跟踪效率之间能够实现良好的平衡而备受关注。通过对基于孪生网络的目标跟踪算法的文献进行归纳,对现有孪生网络目标跟踪算法进行了全面总结,对孪生网络的2个分支结构进行了讨论。首先,介绍了基于孪生网络目标跟踪的基本架构,重点分析了孪生网络中主干网络的优化,以及主干网络的目标特征提取问题。其次,对目标跟踪过程中的分类和回归2个任务展开讨论,将其分为有锚框和无锚框2大类来进行分析研究,通过实验对比,分析了算法的优缺点及其目标跟踪性能。最后,提出未来的研究重点:1)探索背景信息训练,实现场景中背景信息传播,充分利用背景信息实现目标定位。2)目标跟踪过程中,目标特征信息的更加丰富化和目标跟踪框的自适应变化。3)从帧与帧之间全局信息传播,到目标局部信息传播的研究,为准确定位跟踪目标提供支撑。
关键词:计算机图象处理;目标跟踪;孪生网络;深度学习;特征提取
中图分类号:TN520 文献标识码:A
DOI:10.7535/hbkd.2022yx01004
收稿日期:2021-08-04;修回日期:2021-12-20;責任编辑:王淑霞
基金项目:河北省高等学校科学技术研究重点项目(ZD2020405);河北省“三三三人才工程”资助项目(A202101102);石家庄市科学技术研究与发展计划项目(201130181A)
第一作者简介:韩 明(1984—),男,河北行唐人,副教授,博士,主要从事计算机视觉、图像处理方面的研究。
通讯作者:王景芹教授。E-mail:jqwang@hebut.edu.cn
Comprehensive survey on target tracking based on Siamese network
HAN Ming1,2,WANG Jingqin2,WANG Jingtao1,MENG Junying1,LIU Jiaomin2
(1.School of Computer Science and Engineering,Shijiazhuang University,Shijiazhuang,Hebei 050035,China;2.State Key Laboratory of Reliability and Intelligence of Electrical Equipment,Hebei University of Technology,Tianjin 300130,China)
Abstract:In recent years,the target tracking algorithm based on Siamese network has attracted much attention because it can achieve a good balance between tracking accuracy and tracking efficiency.Through the intensive study of the literature of target tracking algorithm based on Siamese network,the existing target tracking algorithm based on Siamese network was comprehensively summarized.Firstly,the basic framework of target tracking was introduced based on Siamese network,and the optimized backbone network in Siamese network and its target feature extraction were analyzed.Secondly,the classification and regression tasks in the process of target tracking were discussed,which were divided into two categories of anchor frame and anchor-free frame.The advantages and disadvantages of the algorithm as well as the target tracking performance were analyzed through experimental comparison.Finally,the focus of future research is proposed as following:1) Explore the training of background information,realize the dissemination of background information in the scene,and make full use of background information to achieve target positioning.2) In the process of target tracking,the target feature information is enriched and the target tracking frame is changed adaptively.3) Research from the global information transmission between frames to the target local information transmission provides support for the accurate target positioning and tracking.
Keywords:
computer image processing;target tracking;Siamese network;deep learning;feature extraction
视觉目标跟踪是人机交互、视觉分析和辅助驱动系统应用中最基本的问题,也是计算机视觉中一项基本又具挑战性的任务。近年来,目标跟踪取得了一定的研究成果,尤其是随着深度学习的研究,利用大量已知数据集进行网络模型训练,捕捉目标深度语义特征,实现对目标外观表征的同时,增加对语义特征的表征,从而助力目标跟踪[1-2]。结合深度学习目标跟踪算法吸引了大量学者进行不断的研究和探索。但是在目标跟踪过程中,随着目标运动和背景变化,跟踪过程中出现的目标被遮挡、剧烈变形、光照变化、背景相似物干扰等复杂情况,导致目标跟踪精度和实时性面临巨大挑战。
卷积神经网络(CNN)在处理各种各样的视觉问题中具有非常优秀的表现,尤其是在特征提取方面[3-5]。因此一些目标跟踪算法将其嵌入到跟踪框架中,其中SiamFC[6]就是典型代表。SiamFC[6]通过计算响应图的最大值位置推断目标的位置,将基于孪生网络的目标跟踪问题转化成一个相似度匹配问题,在超大规模数据集上离线学习目标特征,并将初始帧作为目标跟踪模板,通过输入模板图像和搜索图像,提取搜索图像特征,之后与模板特征作相似度匹配,得到得分响应图,然后根据得分值最大的原则确定目标跟踪的位置。
近年来,基于孪生网络架构的目标跟踪器因目标跟踪性能高,以及在跟踪精度和跟踪效率之间能够实现良好的平衡而受到高度关注。基于孪生网络的目标跟踪器一般分为2个分支:第1个分支[7-9]通过细化Siamese网络的模板子网和实例子网,增强了Siamese网络的表示能力,这些算法努力实现对目标对象的定位,但忽略了对对象大小的估计;第2个分支[10-12]将视觉跟踪问题视为分类任务和回归任务的结合,分类任务将响应图上的特征点分类为目标和背景,回归任务是通过回归估计目标的准确状态。第2个分支的典型代表是SiamRPN[13],它借鉴了经典目标检测算法Faster R-CNN[14]的区域提议网络,将跟踪问题转化到区域提议网络中,该网络用于估计新帧内目标的位置和形状,从而避免了多尺度测试,大大提高了目标的跟踪速度。TAO等[15]提出了SINT(siamese instance search tracker)来训练一个孪生网络识别与初始对象匹配的候选区域的图像位置;SiamFC[6]采用互相关操作融合输入特征;VALMADRE等[16]首先将相关滤波器解释为全卷积连体网络中的可微层;CAO等[17]提出了一个动态加权模块,使离线训练的Siamese网络具有更强的适应性;SiamRPN++[18]在SiamRPN[13]的基础上通过引入更深层次的神经网络进一步提高其性能;ZHU等[19]提出了一种有效的采样策略来控制训练数据的分布,学习到一个更有区别性的模型。HE等[20]提出了一个双卷积Siamese网络,一个分支用于学习外观特征;另一个分支用于学习语义特征;SiamMask[21]扩展了SiamRPN[13],增加了一个分支和损失函数,用于二值分割任务,统一了视觉目标跟踪和分割。
基于深度学习的目标跟踪算法的综述研究主要集中在相关性滤波和神经网络的分类综述研究中,文献[22]基于孪生网络的研究进行综述,内容包括相关滤波算法的和孪生网络相关的目标跟踪2大部分,主要对基于孪生网络的目标跟踪中的典型算法进行了综述。本文基于孪生网络目标跟踪算法的发展,根据孪生网络的2个分支结构进行综述讨论,一方面是Siamese主干网络的优化及目标特征的提取,另一方面是孪生网络目标跟踪中的分类任务和回归任务,总结为有锚框和无锚框2大类,根据讨论与分析,对未来孪生网络目标跟踪的研究方向进行思考。
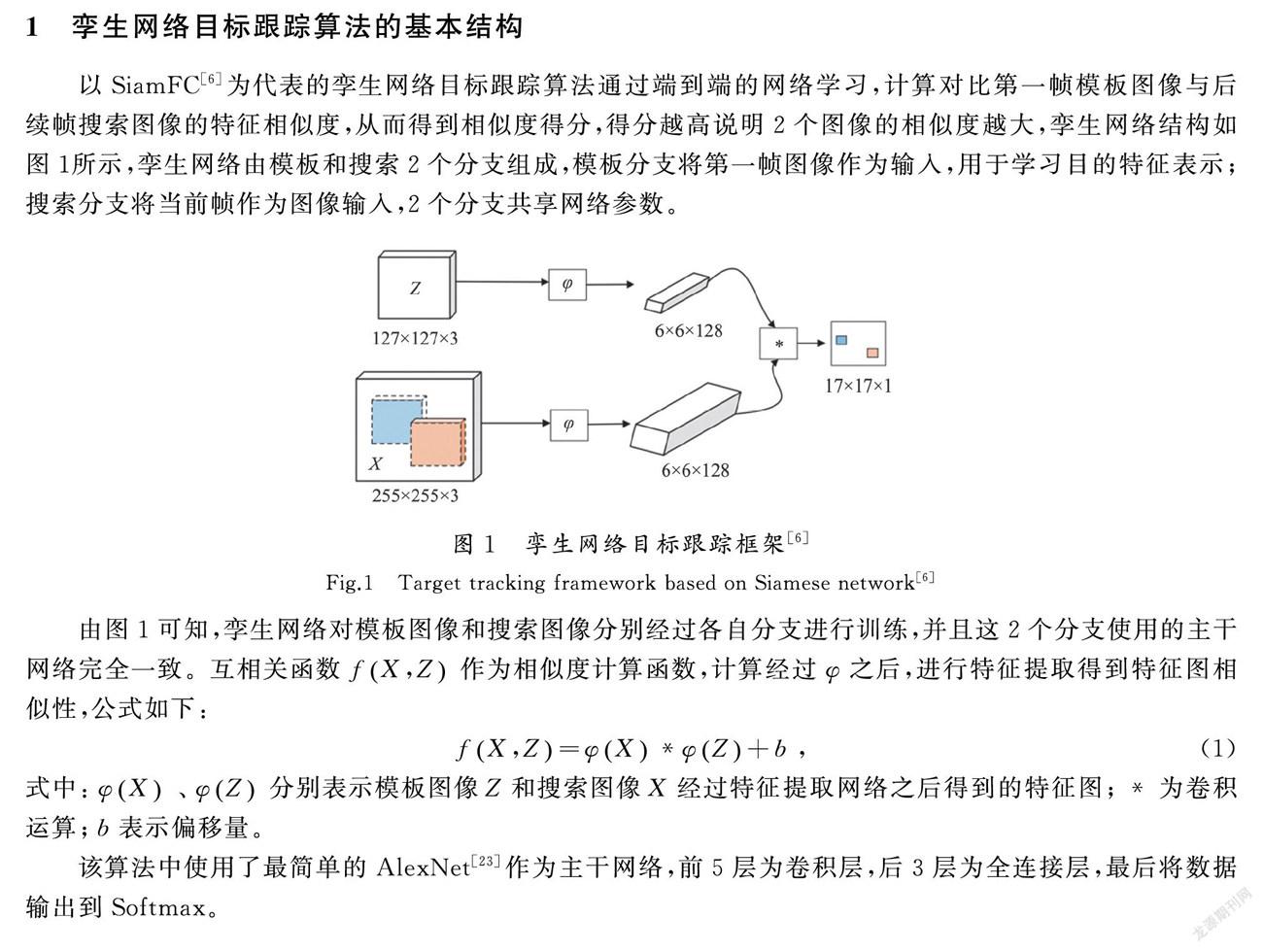
1 孪生网络目标跟踪算法的基本结构
以SiamFC[6]为代表的孪生网络目标跟踪算法通过端到端的网络学习,计算对比第一帧模板图像与后续帧搜索图像的特征相似度,从而得到相似度得分,得分越高说明2个图像的相似度越大,孪生网络结构如图1所示,孪生网络由模板和搜索2个分支组成,模板分支将第一帧图像作为输入,用于学习目的特征表示;搜索分支将当前帧作为图像输入,2个分支共享网络参数。
由图1可知,孪生网络对模板图像和搜索图像分别经过各自分支进行训练,并且这2个分支使用的主干网络完全一致。互相关函数fX,Z作为相似度计算函数,计算经过φ之后,进行特征提取得到特征图相似性,公式如下:
fX,Z=φX*φZ+b,(1)
式中:φX、φZ分别表示模板图像Z和搜索图像X经过特征提取网络之后得到的特征图;*为卷积运算;b表示偏移量。
该算法中使用了最简单的AlexNet[23]作为主干網络,前5层为卷积层,后3层为全连接层,最后将数据输出到Softmax。
2 Siamese主干网络优化及图像特征提取
2.1 Siamese主干网络优化及应用
近几年,基于AlexNet[23]作为主干网络的孪生网络跟踪器[6-7,13,15,24-26]在运行速度和跟踪准确性上都备受关注。但是轻量级的卷积神经网络Alexnet对于复杂环境下的目标跟踪效果较差,尤其是在处理复杂环境问题(旋转、光照变化、变形、背景相似等)时,容易出现跟踪漂移和跟踪丢失的问题。随着对深度神经网络特征嵌入更广、更深层、更有效的研究,一些学者用更深更宽的网络取代前景网络,如VGG[27],Inception[28]和ResNet[29]。通过对比发现,用更深更宽的网络取代浅层主干网络,并没有得到预期效果,而是出现了因为网络深度和宽度的增加导致性能下降的情况。因此近几年出现了多种主干网络优化算法。
更深更宽网络未能取得更好的跟踪效果,主要原因是网络的架构主要是为图像分类的任务而设计的,而不是主要面向目标跟踪,因此在跟踪任务中对目标的定位精确度不高。通过对Siamese网络结构进行分析,发现神经元感受野的大小、网络步幅和特征填充是影响跟踪精度的3个重要因素。其中感受野决定了用于计算机特征的图像区域,较大的感受野能够提供较大的图像上下文,而较小的感受野可能导致无法捕捉目标物体的结构。网络的步幅会影响定位精度,尤其是对于小尺寸的跟踪目标。同时,网络的步幅控制输出特征映射的大小,从而影响特征的可辨别度和检测精度。此外,对于完全卷积的结构,卷积的特征填充在模型训练中产生了潜在的位置偏差,当目标移动到搜索范围边界附近时,很难做出准确的预测。ZHANG等[30]为了实现对更广更深网络的应用,首先,基于“瓶颈”残差块,提出了一组内部裁剪残差(CIR)单元。CIR单元裁剪出块内受填充影响的特征,从而避免卷积滤波器学习位置偏差。然后,通过CIR单元的堆叠,设计了更深网络和更宽网络2种网络架构。通过实验对比发现,基于“残差块”的主干网络跟踪器在跟踪性能上有较大提升。
为了提升特征提取能力,才华等[31]通过分析残差网络的特点,将深层网络ResNet50[32]作为主干网络,但是在使用时对ResNet50进行修改优化处理,使其摆脱由于网络深度或宽度增加造成性能大幅下降的问题。首先,为了实现更多特征的保留减少步长;然后,通过应用扩张卷积增加其感受野。网络设计中对浅层特征和深层特征进行了融合处理,为了增加感受野,将Conv4中的步长设置为1,扩张率设置为2,Conv5的步长设置为1,扩张率设置为4。该算法将修改后的ResNet50作为主干网络充分利用了残差网络的优势,使其除能够获取颜色、形状等底层特征外,还能够利用后边的层获取特征丰富的语义信息,通过深度互相关,实现更有效的信息关联,使其具有更少的参数,从而减少超参数优化。
为了使提取特征更加丰富,SiamRPN++[18]将MobileNet作为主干网络,其处理速度相对较高,速度高于70帧/s。杨梅等[33]将一种参数较少、复杂度较小轻量级网络MobileNetV3作为主干网络对目标进行特征提取,并进行了3方面的改进:1)为了保留深层特征图中足够多的信息,删除了2个步长为2的卷积层,将网络的总步长由32改为8;2)为了减少padding造成的最大响应点的偏移影响,用3×3的卷积核替换原来5×5的卷积核,并利用剪裁操作去除最外层特征;3)为了得到更多的特征信息,将网络中bneck的3×3卷积步长改为1,并使用1×1的卷积核调节网络通道数。在该算法中FPS达到了67帧/s,FPS降低的主要原因是由于增加了注意力模块,在OTB50数据集实验中,精度达到了0.773,成功率达到了0.566,相对于SiamFC分别提升了7.5%和5.3%。该方法针对目标变形、尺度变化、快速运动、背景干扰、低分辨率等问题,在精确度和成功率上都相对提高,但是网络训练好之后一直依赖于第一帧的目标模板,当出现目标遮挡、背景与目标相似时容易跟踪丢失,使得算法整体性能下降。
浅层网络的典型代表SiamFC算法和深层网络典型代表算法SiamRPN,SiamRPN++等的工作原理以及优缺点的对比如表1所示。
随着对主干网络的不同优化,孪生网络架构更加合理,在运行速度、成功率和重叠率上均有不同程度的提升。深层次主干网络的应用使得网络在提取更深层次目标特征信息上更加完善,提取的特征信息更加全面,在进行目标跟踪时充分利用目标浅层特征和深层特征,不仅充分利用了目标的外观信息,同时结合目标的语义信息,使得目标跟踪过程更加准确。
2.2 Siamese网络的图像特征提取
对主干网络进行不同的优化操作,无论是浅层网络还是深层网络的优化,目的是更加准确、高效地提取目标特征,使特征表达更加全面,信息更加丰富。传统的基于孪生网络的目标跟踪算法采用卷积神经网络提取目标图像的特征,在提取图像特征时对于每个通道内的图像特征平等对待,从而导致图像不同通道内的不同信息表达不准确,对目标跟踪有利的特征得不到增强,冗余特征得不到抑制。同时,对于目标跟踪过程而言,每一帧图像中都包含有目标信息和背景信息,而传统算法中则没有考虑二者在目标跟踪中的不同作用。
目标跟踪过程中总会面临长程跟踪和目标遮挡导致消失问题,当目标出现遮挡或者是需要长程跟踪时,对整体跟踪网络架构的要求更加严格和高效。为了解决这一问题,SiamRPN[13],SiamRPN++[18]和DaSiamRPN[19]都做了相关工作,将搜索策略从局部扩展到全局来检测目标是否跟踪丢失。QIN等[34]设计的模板更新方法旨在解决跟踪过程中由于遮挡造成的目标丢失问题。目前解决目标遮挡问题大致可分为2种解决办法:其一,在进行网络离线训练时增加遮挡情况下的训练,提高跟踪时的准确性,但是训练数据的情况覆盖不全,使得训练结果不一定适合于所有的场合;其二,通过匹配样本与目标模板的特征,尤其是深度语义特征,通过对比整体深度特征与目标模板的相似性进行判断,但是在这个过程中由于需要匹配整个图像,导致准确性降低,时间复杂度增加,实时性降低。针对这些问题,注意力机制在时空2个领域都表现出了优势。
2.2.1 基于注意力机制的图像特征提取
注意力机制(attention mechanism,AM)[35]在计算机视觉领域内的目标检测、图像分类等任务中都得到了不同程度的应用,通过注意力机制实现对图像中有效信息的聚焦关注。为了使目标跟踪算法更多地关注空间位置和通道位置上对目标跟踪有利的特征,WANG等[36]提出了残差注意力机制网络,在编码解码模式下使用注意力模块,重新定义特征图,网络不仅性能更好,而且对噪声更鲁棒。该算法充分利用残差注意力机制强化图像的关键特征,对于目标遮挡、目标与背景相似、光照变化等复杂环境下的目标跟踪具有较强的适应能力,但是随着网络注意力模块的应用,算法的实时性还有待提升。HU等[37]引入了一个紧凑的模块来发展通道之间的关系,利用平均池化层的特征来计算通道之間的注意力。
不少研究者将注意力机制引入到孪生网络目标跟踪中。首先,对于通道注意力模块,通过对图像的不同通道赋予不同的权重,让图像特征的外观语义更加立体化,在目标跟踪中更加关注前景目标的通道内特征;其次,对于空间注意力模块而言,通过对特征图上不同空间位置分配不同的权重,增加前景目标的空间位置权重,进而突出前景目标。文献[38—39]均以残差网络作为主干网络,都是在主干网络之后增加了高效通道注意力模块,增大对首帧信息的利用率,通道注意力模块对输入的特征在每个通道中都进行全局平均池化和最大池化运算,文献[38]在不减少通道数的前提下,进行跨通道交互学习,进而丰富目标特征信息,进一步削弱其他干扰特征,有效解决目标跟踪过程中剧烈形变和旋转等情况。但是文献[39]为了提升模型对通道的建模速度,将通道依赖关系限定在相邻的K(K<9)个通道内。
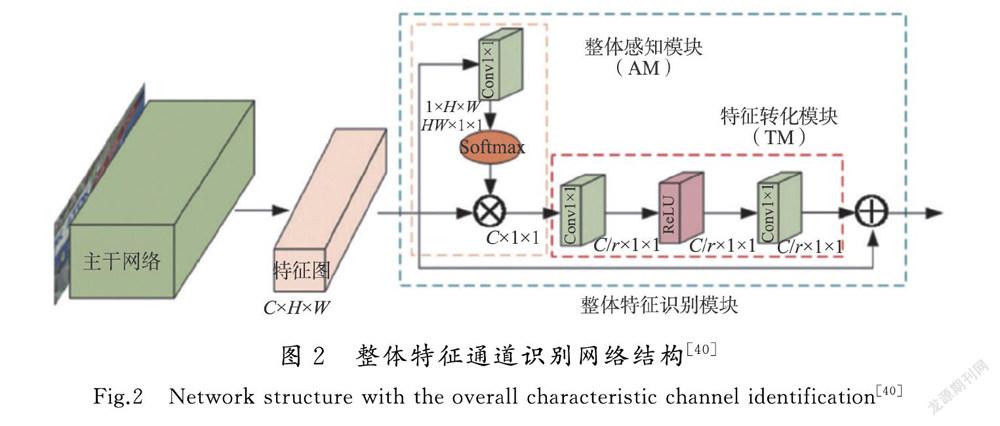
以上研究在通道注意力使用过程中,关注了每个通道的特征表达,但却忽略了每个特征点对于整体特征的重要性。宋鹏等[40]提出了整体特征通道识别的自适应孪生网络跟踪算法,以ResNet22作为主干网络,在Conv3阶段的第4个卷积层加入高效通道注意力机制,在提取特征之后利用整体特征识别功能计算全局信息,获取整体特征中各个通道之间的依赖关系。整体特征通道识别网络结构如图2所示。
由图2可知,通过整体感知模块和特征转换模块之后逐像素相加,实现了将整体特征与通道特征的聚合,从而提取出更为丰富的语义特征,提高跟踪精度。
在相同的测试环境下,从实验效果来看文献[38-39]在OTB50测试集上的跟踪精度高于文献[40],在VOT2016和VOT2018测试集上的EAO(expected average overlap),文献[38-39]相对于文献[40]的0.348 2和0.261 0都要高,其中文献[38]达到了0.448和0.405。造成文献[40]测试数据低的原因,主要是使用了简化的自注意力机制,造成了部分精度的损失。
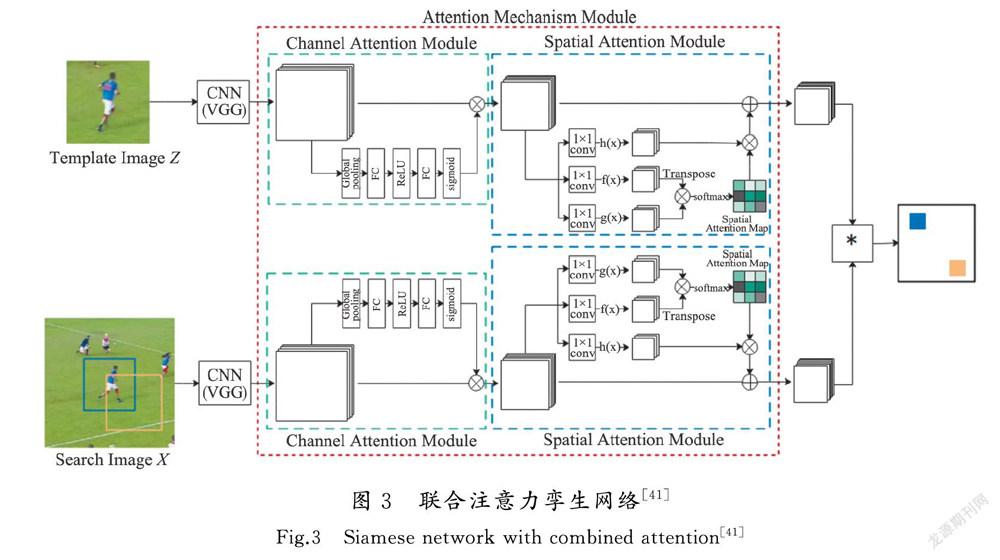
为了提高模型对于关键特征的关注度,增大前景贡献,抑制背景特征,充分利用空间信息,不少学者将通道注意力与空间注意力相结合,提出时空注意力网络或联合注意力网络,从而增强卷积网络对正样本的辨别能力。文献[41-43]设计全局联合注意力机制,对提取的特征作进一步操作,增强网络的辨别能力。其网络结构如图3所示,该网络基于空间和通道联合注意力机制提高特征的判别能力。通过实验对比可知,该算法在OTB实验数据集上取得了较好的效果,尤其是当背景中出现相似物干扰和目标快速运动时具有较好的鲁棒性,但是当目标出现长时间遮挡时,这类算法需要再次长时间适应,性能下降,那么就需要在后续的研究中对长时间遮挡时的时空序列的图像连续性进行研究。
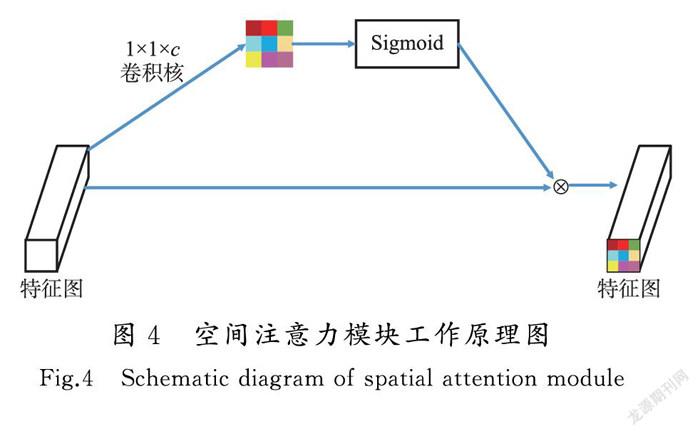
其中通道联合注意力机制与文献[38—39]相似,在此基础上增加了空间注意力模块,空间注意力模块通过建立不同特征图之间的空间信息关系来增强网络的特征表达能力。其中空间注意力模块首先通过1×1×256的卷积核对图像特征进行降维处理,然后将降维处理之后的特征图经过Sigmoid函数进行归一化处理,从而得到特征图中每一个空间位置的权重,最后通过每个位置的权重与特征图φ(z)相乘得到响应图,响应图中最大值的位置即为目标跟踪位置。空间注意力模块工作原理如图4所示。
为了使图像特征更好地进入网络,文献[44]利用Mish函数代替了ReLU激活函数,提高准确性和模型的泛化能力。
2.2.2 不同对比算法试验验证
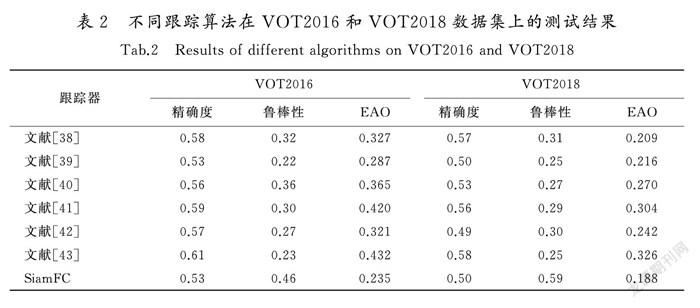
为了验证不同算法的性能优劣,本文进行了对比试验,主要从跟踪精确度、鲁棒性和EAO 3个方面进行评价,实验环境为Intel(R) Xeon(R) CPU E5-2660 V2 @3.50G Hz×40,2个显卡NVIDIA GTX 1080Ti GPUs共计内存16 GB。在上述实验环境下,将文献[38-43]在VOT2016和VOT2018数据集上进行试验对比,结果如表2所示。
由表2可知,在VOT2016数据集的测试上,文献[43]的跟踪精度结果优于其他算法,文献[38]鲁棒性效果最好,文献[43]次之。从VOT2018上的跟踪效果来看,文献[43]的跟踪精度依然较高,鲁棒性与文献[39]持平,从EAO的表达效果来看2个数据集中文献[43]均最优。
虽然研究者将目标特征通过主干网络进行了多信息化的提取,使得图像特征表达更加清晰。通過通道特征的表达使得图像特征的外观语义更加立体化,通过空间特征的表达使得图像的空间位置更加准确。将二者进行联合可使目标的深度特征提取信息更加丰富,从而进一步增强网络的判别能力。但是随着网络深度的增加,算法的复杂度越来越大,这对前期网络训练和后期实时跟踪都将产生负面影响,因此需要在前期增加更多、更详细、更有效的图像标签,利用这些先验信息提高训练的精度,同时在特征提取时还应研究更加轻型的网络结构和算法,进一步降低算法的时间复杂度,在实现目标特征丰富化表示的同时,实现目标的高效跟踪。
2.3 孪生网络的最新优化应用
近几年孪生网络的发展取得了长足进步,网络结构越来越优化,尤其是特征提取越来越侧重于突出前景目标,以有利于目标的准确定位跟踪。但是当出现复杂环境变化,例如光照变化、背景相似物干扰、目标形变、目标遮挡等情况时,如何设计出高精度、高鲁棒性和实时性的目标跟踪算法仍然具有很大的困难。如何提高复杂场景下的目标跟踪,实现端到端的跟踪效果还需要进行不断优化。一些学者对孪生网络的结构作优化处理,使跟踪过程精确度更高,鲁棒性更强,主要表现在从时空信息、上下文信息等多个角度综述孪生网络的最新优化应用,同时对目标跟踪过程的模板动态更新问题进行了研究。
2.3.1 多角度孪生网络最新目标跟踪应用
多角度孪生网络目标跟踪研究,不再集中于目标特征提取的某些或者某几个方面,而是针对时空性和上下文信息,针对基于孪生网络目标跟踪过程中目标遮挡,或者是光照剧烈变化等情况下出现目标时空连贯信息缺失,最终导致目标跟踪失败的问题,而目前大多数研究没有考虑时空信息和上下文信息。GCT(graph convolutional tracking)[45-46]采用图卷积跟踪方法,该方法综合考虑了历史目标样本的时空结构及其对应的上下文信息,图卷积跟踪(GCT)主要利用时空图卷积网络(GCN)实现历史目标结构化表示,并设计了一个上下文的GCN,利用当前框架的上下文学习自适应特征进行目标定位。首先,该算法通过图结构把前T帧视频的时空信息连接为一个整体,通过将每一帧中的候选区域分为M个部分,然后将M个部分组成一个团,其中每一个团代表一个空间信息,然后将不同帧的团连接在一起构成时空信息。其次,通过图卷积计算每个节点的结果,并再次经过上下文的图卷积将输出结果做一次softmax操作,然后输出模板特征。最终图卷积网络在统一框架下,实现目标的时空外观建模以及上下文感知的自适应学习,最终实现目标的准确定位。
YU等[47]在2020年的CVPR会议上提出了可变形孪生注意力网络SiamAttn,该可变形注意力机制可提高网络对目标特征的表达能力,在目标外观剧烈变化、相似物干扰等复杂环境下具有更强的鲁棒性以及更好的区分前景与背景能力。该网络与2.2节的注意力机制不同,该注意力机制设计了可变形的自注意力特征和互注意力特征,其中自注意力特征包含空间特征和通道特征,可在空间域学习丰富的上下文信息,在通道域进行有选择的权重赋值,增强通道特征之间的相互依赖性;互注意力特征则负责聚合搜索区域和模板区域之间的相似特征信息,进一步提高特征的区分能力。
SiamAttn[47]网络首先经过可变注意力机制提取特征,然后利用SiamRPN[13]提取候选区域,得出候选区域得分最高的区域,然后经过区域修正模块,对预测结果进行进一步修正,同时生成包含跟踪目标的目标框和掩膜,实现准确跟踪,整体网络架构如图5所示。
通过对比实验可以发现,SiamAttn算法在VOT这种带旋转跟踪框的数据集上可以更好地定位目标,相较于其他算法其定位效果有更为明显的提升。该算法通过自注意力和互注意力相结合,提高模型目标区分能力,与其他跟踪器的区别在于该方法提供了一种自适应的隐式模型特征更新方法,将卷积层和池化层替换为可变形的卷积层和可变形的池化层,用来增加每个像素点的感受野,从而更加准确、有效地提取目标特征。
基于Siamese网络的跟踪器将视觉跟踪任务定义为相似性匹配问题。几乎所有流行的Siamese跟踪器都是通过目标分支和搜索分支之间的卷积特征互相关联来实现相似性学习的。但是,由于需要预先确定目标特征区域的大小,这些互相關方法要么保留了大量不利的背景信息,要么丢失了大量的前景信息。此外,目标与搜索区域的全局匹配也在很大程度上忽略了目标结构和部分层次信息。GUO等[48]设计了一个部分到部分的信息嵌入网络,提出了一个目标感知孪生图注意网络。通过证明发现模板和搜索区域之间的信息嵌入可以用完全二分图来建模,该图通过图的注意力机制来编码模板节点和搜索节点之间的关系。通过学习注意力得分,每个搜索节点可以有效地从模板中聚合目标信息。然后,所有搜索节点生成一个响应图,该响应图包含丰富的后续解码任务的信息,在此基础上,提出了一种图注意模块(GAM)来实现部分到部分的信息传播,而不是在模板和搜索区域之间进行全局信息传播。这种局部与局部相似度匹配方法可以大大降低目标形状和姿态变化的影响。此外,该算法没有使用预先确定的区域裁剪,而是研究了一种目标感知的模板计算机制,以适应不同对象的大小和长径比变化。该算法通过引入GAM,实现了面向对象的信息嵌入策略,提出了一种新的跟踪框架,即孪生网络图注意跟踪(SiamGAT)网络。
2.3.2 跟踪模板更新
目标跟踪过程中单纯利用第一帧图像作为模板进行目标跟踪,容易因目标遮挡、剧烈光照变化和相似背景等问题出现跟踪漂移。为解决整个跟踪过程中仅使用第一帧图像作为模板的单一问题,QIN等[34]采用高置信度的多模板更新机制来确定模板是否需要更新。
为了防止干扰物和背景特征被添加到模板中,将峰值的得分与相关能量相对应,以保证模板的有效性。利用平均峰值相关能量APCE能够反映遮挡程度,可通过以下计算得到:
Fmax=max(R),(2)
Fmin=min(R),(3)
APCE=|Fmax-Fmin|2mean∑w,hFw,h-Fmin2,(4)
式中:Fmax,Fmin和Fw,h分别表示响应图最大值、最小值和坐标(w,h)处对应的响应值;R表示响应图;mean()表示均值函数。在上述公式中分子代表峰值,分母代表响应图的波动。峰值和波动可以反映对跟踪结果的置信程度。当目标不被遮挡时,APCE变大,反映图上只有一个尖峰;相反,如果目标被遮挡或缺失,APCE显著降低。
将APCE计算为多个响应映射的和,并判断是否超过了阈值,如果APCE大于阈值,则表明结果是可靠的,可以进行模板更新:
RT=η×RT+(1-η)×RX,(5)
式中:η表示更新率;RT表示模板图像特征;RX表示高置信度的搜索图像特征。
3 分类与边框回归任务
SiamRPN算法引入区域推荐网络,将目标跟踪过程中的目标相似度匹配问题转化为分类和回归问题。RPN网络分为相似度匹配部分和监督部分,其中监督部分一个分支用于前景和背景的分类,另外一个分支用于边框回归。
3.1 基于有锚框的分类与边框回归目标跟踪
SiamRPN[13]采用滑动窗口算法产生大量的锚框,从而生成候选区域,通过对anchor网络进行训练,最终计算出分类分支的类别预测结果,计算出每个anchor属于背景和前景的概率。在训练过程中,在响应得分图的每个像素点的位置上都生成5个anchor,5个anchor的宽高比分别为[3,2,1,1/2,1/3],由于最后网络的输出特征图尺寸为17×17,则共设置1 445(17×17×5)个anchor,但是这些anchor的中心点对应搜索图像中的位置并不是整个搜索图像,只是搜索图像中心128×128的区域。SiamRPN不需要进行尺度估计,而是根据生成的锚框以及网络特征,直接预测目标的中心位置,分别使用分类任务和回归任务,可能导致预测目标的中心位置出现不匹配的现象,最终使得跟踪结果性能降低。
SiamRPN++[18]和DaSiamRPN[19]网络同SiamRPN[13]相似,基于RPN的孪生网络目标跟踪器主要依赖于密集的锚框策略,实现剧烈形变目标的高准确定位,但是多锚框的设置使得分类和回归任务的复杂程度增加,同时大量的冗余锚框降低了跟踪器的跟踪效率,从而影响跟踪的速度和精度。
为了解决大量锚框冗余造成的跟踪速度和精度降低的问题,文献[49]通过思考anchor的生成问题,将导向锚框网络中关于锚框的解决方法引入目标检测,通过2个条件概率分布实现anchor的生成,公式如下:
p(x,y,w,hI)=p(x,yI)p(w,hx,y,I),(6)
式中:(x,y,w,h)表示图像I的中心坐标和宽高;px,yI和pw,hx,y,I分布分别为给定图像特征之后anchor中心点的概率分布和给定图像特征和中心点之后的形状概率分布。
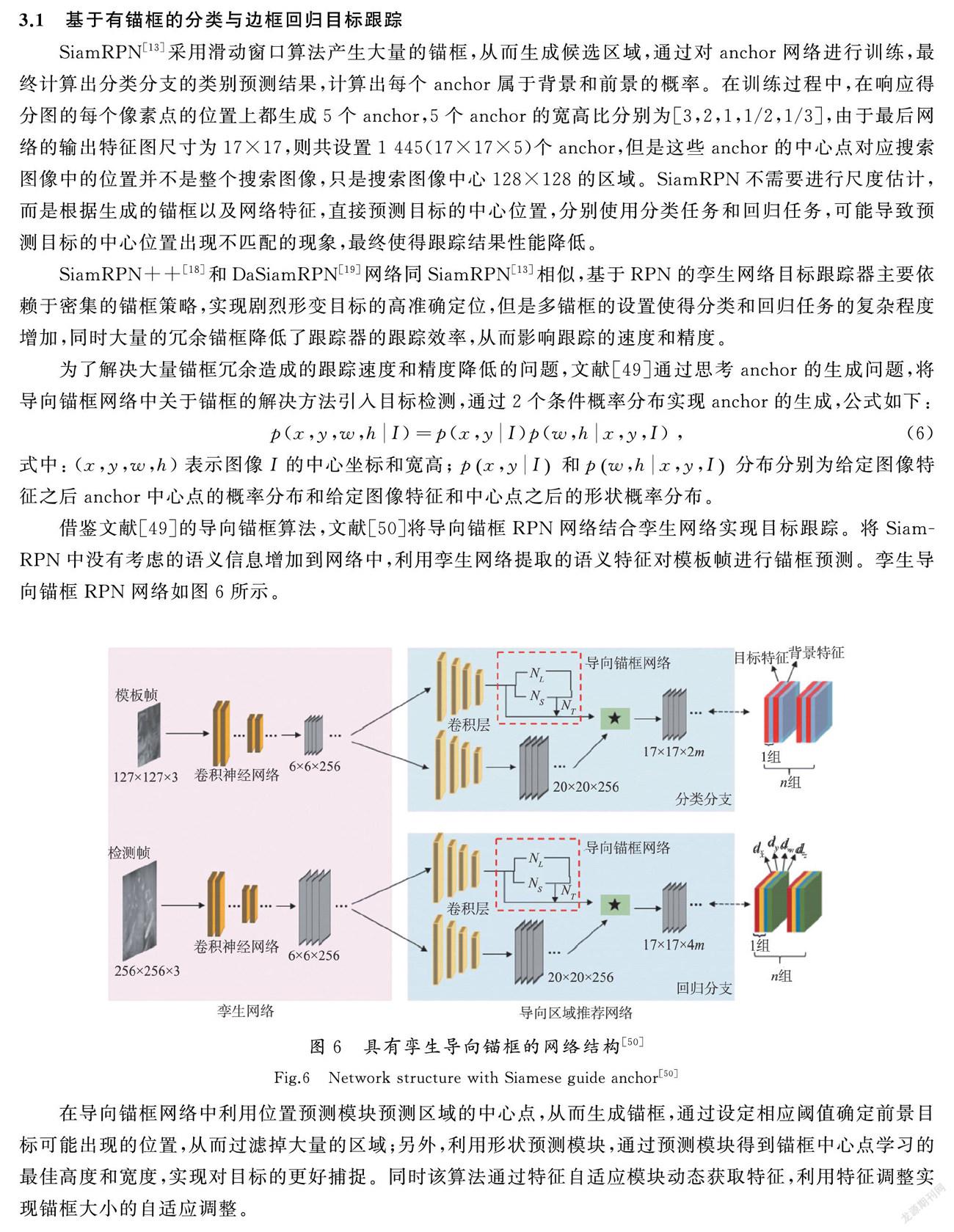
借鉴文献[49]的导向锚框算法,文献[50]将导向锚框RPN网络结合孪生网络实现目标跟踪。将SiamRPN中没有考虑的语义信息增加到网络中,利用孪生网络提取的语义特征对模板帧进行锚框预测。孪生导向锚框RPN网络如图6所示。
在导向锚框网络中利用位置预测模块预测区域的中心点,从而生成锚框,通过设定相应阈值确定前景目标可能出现的位置,从而过滤掉大量的区域;另外,利用形状预测模块,通过预测模块得到锚框中心点学习的最佳高度和宽度,实现对目标的更好捕捉。同时该算法通过特征自适应模块动态获取特征,利用特征调整实现锚框大小的自适应调整。
李明杰等[51]将孪生区域提议网络(RPN)与锚框掩码相结合,将3D卷积操作与FCN[6]网络引入到固定卷积操作范围的锚框掩码机制。首先,在FCN网络上利用3D卷积学习连续3帧图像的IOU热度图的时空信息;然后,在FCN网络进行全卷积操作,预测下一帧图像的锚框掩码图片。相较于SiamRPN[13]中的每个锚点对应生成K个锚框,该算法的锚框掩码生成原理如图7所示,先利用先验知识,将图像特征图与生成的锚框掩码进行点乘运算,得到一个稀疏矩阵。由图7可知,通过锚框卷积运算之后得分框和回归框都会出现大量的0,根据0的数量滤掉无效锚框,实现真实目标锚框的预测。
基于anchor的孪生网络首先需要借助初始人工设定的锚框,在目标跟踪过程中需要不断进行多次迭代,使目标跟踪框越来越接近真实目标。基于锚框的方法通过多次迭代实现了目标跟踪框的逐渐修正,使得跟踪更加准确,该方法大多通过滑动窗口的方法实现,导致产生大量锚框,使得算法的整体计算复杂度增加,实时性下降。为了提高算法性能,Siammask[21]采用锚框掩码进行目标位置的预测,该算法对于高帧率视频以及没有出现目标遮挡和目标消失的情况,网络性能较高,鲁棒性高,但是在遮挡等情况时性能变差。因此,为了进一步提高对目标的跟踪性能和跟踪效率,一些研究人员提出了anchor-free网络。
3.2 基于无锚框的分类与边框回归目标跟踪
目前主流的基于孪生网络的深度学习模型SiamRPN[13],SiamRPN++[18],DaSiamRPN[19],SSD(single shot multibox detector)[52]等依賴于一组预定义的锚框,实现高效的目标跟踪。但是基于锚框的检测器具有明显缺点:一方面,需要预定义一组具有较大参数和固定超参数的锚框,使得检测性能对与锚框相关的超参数过于敏感;另一方面,为了解决目标跟踪过程中目标的尺度和剧烈形变问题,需要设置大量锚框,导致正负样本严重不平衡,同时增加了算法的复杂度。为了解决上述问题,有学者提出了anchor-free的目标跟踪算法。
张睿等[53]采用anchor-free机制,设计了无锚框网络,包括回归分支和分类分支。在回归分支中利用像素点的位置回归方法直接预测采样点到目标区域边界的4个距离值,相对于锚框机制而言,可以有效减少人为设定的超参数的数量,同时增加正样本数。在分类分支中引入了中心度分支,中心度C(i,j)为
C(i,j)=Tk*(i,j)min(l*,r*)max(l*,r*)×min(t*,b*)max(t*,t*),(7)
式中,定义k*(i,j)=(l*,t*,r*,b*)表示中心度得分图中任意位置(i,j)所对应的采样点(x,y)到目标真实边界区域的4个距离。
其中
Tk*(i,j)=1, k*(i,j)(n)>0, n=0,1,2,3,0, other。(8)
式(8)表示采样点(x,y)是否在目标区域内,由式(8)可知,如果在目标区域内取值为1,否则为0。
将式(8)代入式(7),当采样点落在目标区域外部时,式(7)表示的中心度值为0,对于落入目标区域内部的采样点而言,距离目标中心越近中心度值越高,相反,则越低。最后将相同位置的分类结果与中心度结果进行相乘运算,实现对边缘点的有效抑制。
FCAF[54]和文献[55]提出了端到端离线训练的FCAF模型,采用深度网络ResNet50提供更深层次的特征表示,同时引入多特征融合模块,将低级细节信息和高级的语义信息进行有效融合,提高目标的定位性能,用anchor-free 提议网络代替候选提议网络(region proposal network),AFPN(anchor-free proposal network)网络由相关段和监督段组成,其中,相关段通过深度方向互相关实现,监督段由分类分支和回归分支2个分支组成。另外,为了抑制低质量边界框的预测,SiamCAR[56]对像素级进行分类。SiamCAR算法由2个简单的子网络组成,一个用于特征提取的孪生子网络,一个用于边框预测的分类回归子网络,主干网络采用ResNet50。 该算法与现有的基于区域建议的跟踪器(如SiamRPN[13],SiamRPN++[18]和SPM[22])不同,其提出的框架是anchor-free网络。SiamCAR算法通过anchor-free策略,将网络的回归输出变成了特征图映射在搜索区域上的点与选定的目标区域边界(样本标注gt,ground-truth)4条边的距离。通过观察分类得分图和中心度得分图,决定最佳目标中心点,然后提取最佳目标中心点与gt框4条边的距离,得到预测框,从而实现跟踪。但是,SiamCAR算法将预测的位置映射到原始图像可能会导致偏差,从而导致跟踪过程中出现漂移。
为了解决上述问题,在获得目标区域内多个相邻像素的预测结果后,对多个相邻点的预测结果进行加权平均,得到最终目标框,但其带来的后果是增加了计算过程的复杂度。虽然anchor-free方法可以简化基于锚的跟踪器的区域候选模块,但是基于语义分割的网络输出仍然需要后续进行处理。
为了提高无锚框全卷积孪生网络跟踪器的跟踪性能,谭建豪等[57]在训练过程中引入了相似语义干扰物,同时融合高中低3层特征,提高跟踪器的鲁棒性,在无锚框使用上与FCAF[54]和文献[55]类似,基于像素直接进行预测回归,在每个位置仅仅预测一次目标的状态信息,不再进行锚框相关的编码过程,减少算法复杂度。为了提高目标跟踪的准确性,YUAN等[58]提出了多模板更新的无锚孪生网络目标跟踪算法,采用一种基于多层特征的双融合方法将多个预测结果分别进行组合,将低级特征映射与高级特征映射连接起来,充分利用空间信息和语义信息。为了使结果尽可能稳定,将多个预测结果相结合得到最终结果。针对模板更新问题,采用了一种高置信度的多模板更新机制。用平均峰值相关能量来决定模板是否需要更新,采用模板更新机制实现目标跟踪模板的准确更新,同时算法中使用无锚框网络实现逐像素目标跟踪,直接计算对象类别和边界框。一个完全卷积的单级目标检测器(FCOS)[59]消除了预先定义的锚框集,同FCAF[54]类似以逐像素预测的方式解决目标检测,完全避开了与锚框有关的大参数和复杂计算。CenterNet[60]使用三元组检测每个对象,包括一个中心关键点和2个角落。这些无锚框方法可以达到与基于有锚框方法的精确度相似,但是速度更快。
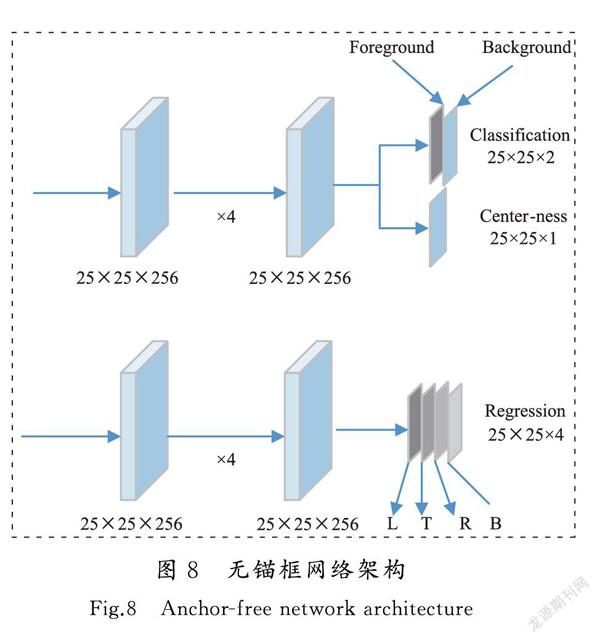
无锚框网络计算方法[53-57]网络结构如图8所示,整个网络可以分为2个分支:分类分支对每个点进行分类,回归分支对该点的目标包围框进行回归。对于每个响应图,分类网络输出一个分类特征图和它的2个维度,分别表示对应点的前景和背景分数。回归分支输出一个回归特征图,并在对应点上编码预测边界框的位置。无锚预测操作完全消除了有锚边界框相关的复杂计算和复杂的调参问题。
3.3 有锚框与无锚框网络对比
无论是有锚框还是无锚框的网络结构都将孪生网络的跟踪任务分为了分类和回归2个部分,分类任务通过对每个像素点进行分类实现前景和背景的分类,回归任务通过对目标位置的回归实现跟踪框的回归,生成回归特征图。通过分类和回归任务实现对目标中心位置和尺度的预测,实现目标的准确有效跟踪。但是这些算法在使用分类和回归任务时是分别进行使用的,二者之间的任务没有很好地进行联系使用,导致部分模型在预测目标前景和背景的分类結果与边框的回归预测结果不符合,在跟踪过程中不能得到最优结果。
基于上述分析,如何将分类任务的最高得分与边框预测的最佳位置相匹配实现最优跟踪,是目前需要研究的问题。通过分析发现,分类损失函数主要目的是提高正样本IOU的精度,回归损失函数主要是提升边框回归的定位精度。因此,如何增强分类任务与边框回归任务的联系成为研究重点。从损失函数的角度出发,需要对分类损失函数和回归损失函数进行改进研究,实现分类损失函数与回归损失函数的联合使用,从而实现分类的最高得分即是跟踪边框的最佳回归位置,实现二者的关联匹配。
有锚框网络和无锚框网络的孪生网络目标跟踪算法的工作机制以及优缺点对比如表3所示。
4 研究展望
基于孪生网络的跟踪算法在发展过程中越来越注重算法的实时性和准确性,尤其是针对复杂环境下目标跟踪的研究。各类算法都在不断地对实时性和准确性进行完善和优化,孪生网络架构的优势逐渐显现,未来基于孪生网络的目标跟踪算法研究将从以下几个方面展开。
1)背景信息的训练。目前大多数基于孪生网络的跟踪算法均未考虑背景信息,在目标训练过程中,只考虑目标的外观信息,但是当背景中出现相似性物体干扰时,对背景信息的训练显得尤为重要。因此,如何实现对背景信息的训练,并实现有价值的信息在场景中进行传播,充分利用目标外观模型和场景信息特征实现对目标的准确定位是值得深入研究的问题。
2)目标富含更多自身语义信息的特征提取。目前大多数算法将目标特征作为一个整体与搜索区域进行相似性计算。但是,在跟踪目标过程中往往会产生较大的旋转、位姿变化和严重遮挡,对变化目标进行全局匹配的鲁棒性不强。因此,在目标跟踪过程中,实现更多自身语义信息的嵌入,使目标特征更加突出,研究目标跟踪过程中目标的大小和宽高比的变化,逐步实现跟踪框的自适应性,是一项重要的研究内容。
3)帧与帧之间的信息传播。孪生网络中的模板区域和搜索区域之间的信息嵌入是一个全局信息传播过程,其中模板向搜索区域传递的信息是有限的,信息压缩过多,最终会导致部分信息出现丢失,因此,需要考虑目标跟踪过程中帧与帧之间目标部分的信息传播,因为在跟踪过程中目标的部分特征相对于形状和姿态的变化往往是不变的,更具有鲁棒性,对于目标的跟踪定位会更加准确。帧与帧之间目标局部信息的传播将成为准确跟踪定位的重要研究内容。
4)跟踪模型的通用性。在目标跟踪的多种实际场景中,通过大量数据集进行训练,或者是通过特定数据集进行离线训练,实现快速、准确的学习到目标的特征表示,从而实现准确、快速定位跟踪目标,以及利用跟踪模型实现通用特征的提取等方面都值得深入研究。
参考文献/References:
[1] XIAO T,LI H S,OUYANG W L,et al.Learning deep feature representations with domain guided dropout for person re-identification[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR):IEEE,2016:1249-1258.
[2] LIU Q K,CHU Q,LIU B,et al.GSM:Graph similarity model for multi-object tracking[C]//Proceedings of the Twenty-Ninth Interna-tional Joint Conference on Artificial Intelligence.[S.l.]:[s.n.],2020:530-536.
[3] KRISTAN M,MATAS J,LEONARDIS A,et al.The visual object tracking VOT2015 challenge results[C]//2015 IEEE International Conference on Computer Vision Workshop (ICCVW).[S.l.]:IEEE,2015:564-586.
[4] TOSHEV A,SZEGEDY C.DeepPose:Human pose estimation via deep neural networks[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition.[S.l.]:IEEE,2014:1653-1660.
[5] LONG J,SHELHAMER E,DARRELL T.Fully convolutional networks for semantic segmentation[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).[S.l.]:IEEE,2015:3431-3440.
[6] BERTINETTO L,VALMADRE J,HENRIQUES J F,et al.Fully-convolutional Siamese networks for object tracking[C]//Computer Vision-ECCV 2016 Workshops.Cham:Springer International Publishing,2016:850-865.
[7] KUAI Y L,WEN G J,LI D D.Masked and dynamic Siamese network for robust visual tracking[J].Information Sciences,2019,503:169-182.
[8] LI Xin,MA Chao,WU Baoyuan,et al.Target-aware deep tracking[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).[S.l.]:IEEE,2019:1369-1378.
[9] LI Peixia,CHEN Boyu,OUYANG Wanli,et al.GradNet:Gradient-guided network for visual object tracking[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV).[S.l.]:IEEE,2019:6161-6170.
[10]侯志強,陈立琳,余旺盛,等.基于双模板Siamese网络的鲁棒视觉跟踪算法[J].电子与信息学报,2019,41(9):2247-2255.
HOU Zhiqiang,CHEN Lilin,YU Wangsheng,et al.Robust visual tracking algorithm based on Siamese network with dual templates[J].Journal of Electronics & Information Technology,2019,41(9):2247-2255.
[11]FAN Heng,LING Haibin.Siamese cascaded region proposal networks for real-time visual tracking[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).[S.l.]:IEEE,2019:7944-7953.
[12]沈雁,王环,戴瑜兴.基于改进深度孪生网络的分类器及其应用[J].计算机工程与应用,2018,54(10):19-25.
SHEN Yan,WANG Huan,DAI Yuxing.Deep siamese network-based classifier and its application[J].Computer Engineering and Applications,2018,54(10):19-25.
[13]LI Bo,YAN Junjie,WU Wei,et al.High performance visual tracking with Siamese region proposal network[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.[S.l.]:IEEE,2018:8971-8980.
[14]REN S Q,HE K M,GIRSHICK R,et al.Faster R-CNN:Towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[15]TAO R,GAVVES E,SMEULDERS A W M.Siamese instance search for tracking[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).[S.l.]:IEEE,2016:1420-1429.
[16]VALMADRE J,BERTINETTO L,HENRIQUESJ,et al.End-to-end representation learning for correlation filter based tracking[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).[S.l.]:IEEE,2017:5000-5008.
[17]CAO Y,JI H B,ZHANG W B,et al.Visual tracking via dynamic weighting with pyramid-redetection based Siamese networks[J].Journal of Visual Communication and Image Representation,2019(65).DOI:10.1016/j.jvcir.2019.102635.
[18]LI B,WU W,WANG Q,et al.SiamRPN++:Evolution of siamese visual tracking with very deep networks[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).[S.l.]:IEEE,2019:4277-4286.
[19]ZHU Zheng,WANG Qiang,Li Bo,et al.Distractor-aware siamese networks for visual object tracking[C]// European Conference on Computer Vision,Munich.[S.l.]:ECCV,2018:101-117.
[20]HE A F,LUO C,TIAN X M,et al.A twofold Siamese network for real-time object tracking[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.[S.l.]:IEEE,2018:4834-4843.
[21]WANG Q,ZHANG L,BERTINETTO L,et al.Fast online object tracking and segmentation:A unifying approach[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).[S.l.]:IEEE,2019:1328-1338.
[22]陳云芳,吴懿,张伟.基于孪生网络结构的目标跟踪算法综述[J].计算机工程与应用,2020,56(6):10-18.
CHEN Yunfang,WU Yi,ZHANG Wei.Survey of target tracking algorithm based on siamese network structure[J].Computer Engineering and Applications,2020,56(6):10-18.
[23]KRIZHEVSKY A,SUTSKEVER I,HINTON G E.ImageNet classification with deep convolutional neural networks[C]//Proceedings of the 25th International Conference on Neural Information Processing Systems.[S.l.]:Curran Associates Inc,2012:1097-1105.
[24]DONG X P,SHEN J B.Triplet loss in Siamese network for object tracking[C]//Computer Vision-ECCV.Cham:Springer International Publishing,2018:472-488.
[25]GUO Q,FENG W,ZHOU C,et al.Learning dynamic Siamese network for visual object tracking[C]//2017 IEEE International Conference on Computer Vision (ICCV).[S.l.]:IEEE,2017:1781-1789.
[26]ZHANG Yunhua,WANG Lijun,QI Jinqing,et al.Tructured Siamese network for real-time visual tracking[C]// European Conference on Computer Vision.Amsterdam.[S.l.]:ECCV,2018,351-366.
[27]KAREN S ANDREW Z.Very deep convolutional networks for large-scale image recognition[C]// International Conference on Learning Representations.San Diego:ICLR,2015:1-14.
[28]SZEGEDY C,LIU W,JIA YQ,et al.Going deeper with convolutions[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Boston:IEEE,2015:1-9.
[29]HE K M,ZHANG X Y,REN S Q,et al.Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Amsterdam:IEEE,2016:770-778.
[30]ZHANG Z P,PENG H W.Deeper and wider Siamese networks for real-time visual tracking[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Long Beach:IEEE,2019:4586-4595.
[31]才华,王学伟,朱新丽,等.基于动态模板更新S的孪生网络目标跟踪算法[J/OL].吉林大学学报(工学版).[2021-03-18].DOI:10.13229/j.cnki.jdxbgxb20200962.
CAI Hua,WANG Xuewei,ZHU Xinli,et al.Siamese network target tracking algorithm based on dynamic template updating[J/OL].Journal of Jilin University(Engineering and Technology Edition).[2021-03-18].DOI:10.13229/j.cnki.jdxbgxb20200962.
[32]马素刚,赵祥模,侯志强,等.一种基于ResNet网络特征的视觉目标跟踪算法[J].北京邮电大学学报,2020,43(2):129-134.
MA Sugang,ZHAO Xiangmo,HOU Zhiqiang,et al.A visual object tracking algorithm based on features extracted by deep residual network[J].Journal of Beijing University of Posts and Telecommunications,2020,43(2):129-134.
[33]杨梅,贾旭,殷浩东,等.基于联合注意力孪生网络目标跟踪算法[J].仪器仪表学报,2021,42(1):127-136.
YANG Mei,JIA Xu,YIN Haodong,et al.Object tracking algorithm based on Siamese network with combined attention[J].Chinese Journal of Scientific Instrument,2021,42(1):127-136.
[34]QIN X F,ZHANG Y P,CHANG H,et al.ACSiamRPN:Adaptive context sampling for visual object tracking[J].Electronics,2020,9(9):1528.
[35]WANG Q,TENG Z,XING J L,et al.Learning attentions:Residual attentional Siamese network for high performance online visual tracking[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:4854-4863.
[36]WANG F,JIANG M Q,QIANC,et al.Residual attention network for image classification[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Hawaii:IEEE,2017:6450-6458.
[37]HU J,SHEN L,SUN G.Squeeze-and-excitation networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:7132-7141.
[38]柏羅,张宏立,王聪.基于高效注意力和上下文感知的目标跟踪算法[J/OL].北京航空航天大学学报.[2021-03-10].https://kns.cnki.net/kcms/detail/detail.aspx?FileName=BJHK20210308000&DbName=CAPJ2021.
BAI Luo,ZHANG Hongli,WANG Cong.Target tracking algorithm based on efficient attention and context awareness[J/OL].Journal of Beijing University of Aeronautics and Astronautics.[2021-03-10].https://kns.cnki.net/kcms/detail/detail.aspx?FileName=BJHK-20210308000&DbName=CAPJ2021.
[39]邵江南,葛洪伟.融合残差连接与通道注意力机制的Siamese目标跟踪算法[J].计算机辅助设计与图形学学报,2021,33(2):260-269.
SHAO Jiangnan,GE Hongwei.Siamese object tracking algorithm combining residual connection and channel attention mechanism[J].Journal of Computer-Aided Design & Computer Graphics,2021,33(2):260-269.
[40]宋鹏,杨德东,李畅,等.整体特征通道识别的自适应孪生网络跟踪算法[J].浙江大学学报(工学版),2021,55(5):966-975.
SONG Peng,YANG Dedong,LI CHANG,et al.An adaptive Siamese network tracking algorithm based on global feature channel recognition[J].Journal of Zhejiang University (Engineering Science),2021,55(5):966-975.
[41]齐天卉,张辉,李嘉锋,等.基于多注意力图的孪生网络视觉目标跟踪[J].信号处理,2020,36(9):1557-1566.
QI Tianhui,ZHANG Hui,LI Jiafeng,et al.Siamese network with multi-attention map for visual object tracking[J].Journal of Signal Processing,2020,36(9):1557-1566.
[42]程旭,崔一平,宋晨,等.基于时空注意力机制的目标跟踪算法[J].计算机科学,2021,48(4):123-129.
CHENG Xu,CUI Yiping,SONG Chen,et al.Object tracking algorithm based on temporal-spatial attention mechanism[J].Computer Science,2021,48(4):123-129.
[43]ZHANG D L,LV J G,CHENG Z,et al.Siamese network combined with attention mechanism for object tracking[C]//The International Archives of the Photogrammetry,Remote Sensing and Spatial Information Sciences.[S.l]:[s.n.],2020:1315-1322.
[44]ZHANG F B,WANG X F.Object tracking in Siamese network with attention mechanism and mish function[J].Academic Journal of Computing & Information Science,2021,4(1):75-81.
[45]GAO J Y,ZHANG T Z,XU C S.Graph convolutional tracking[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Long Beach:IEEE,2019:4644-4654.
[46]YAN S J,XIONG Y J,LIN D H.Spatial temporal graph convolutional networks for skeleton-based action recognition[C].The 32nd AAAI Conference on Artificial Intelligence.USA:Artificial Inteligence,2018:7444-7452.
[47]YU Y C,XIONG Y L,HUANG W L,et al.Deformable Siamese attention networks for visual object tracking[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).[S.l.]:IEEE,2020:6727-6736.
[48]GUO D Y,SHAO Y Y,CUI Y,et al.Graph attention tracking[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).[S.l.]:IEEE,2021:9538-9547.
[49]WANG J Q,CHEN K,YANG S,et al.Region proposal by guided anchoring[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).[S.l.]:IEEE,2019:2960-2969.
[50]尚欣茹,溫尧乐,奚雪峰,等.孪生导向锚框RPN网络实时目标跟踪[J].中国图象图形学报,2021,26(2):415-424.
SHANG Xinru,WEN Yaole,XI Xuefeng,et al.Target tracking system based on the Siamese guided anchor region proposal network[J].Journal of Image and Graphics,2021,26(2):415-424.
[51]李明杰,馮有前,尹忠海,等.一种用于单目标跟踪的锚框掩码孪生RPN模型[J].计算机工程,2019,45(9):216-221.
LI Mingjie,FENG Youqian,YIN Zhonghai,et al.An anchor mask siamese RPN model for single target tracking[J].Computer Engineering,2019,45(9):216-221.
[52]LIU W,ANGUELOV D,ERHAND,et al.SSD:Single shot multibox detector[C]// Computer Vision-ECCV 2016.Las Vegas:Springer International Publishing,2016:21-37.
[53]张睿,宋荆洲,李思昊.基于无锚点机制与在线更新的目标跟踪算法[J].计算机工程与应用,2021,57(20):210-220.
ZHANG Rui,SONG Jingzhou,LI Sihao.Object tracking with anchor-free and online updating[J].Computer Engineering and Applications,2021,57(20):210-220.
[54]HAN G,DU H,LIU J X,et al.Fully conventional anchor-free Siamese networks for object tracking[J].IEEE Access,2019,7:123934-123943.
[55]杜花.基于全卷积无锚框孪生网络的目标跟踪算法研究[D].南京:南京邮电大学,2020.
DU Hua.Research on Object Tracking with Fully Conventional Anchor-free Siamese Network[D].Nanjing:Nanjing University of Posts and Telecommunications,2020.
[56]GUO Dongyan,WANG Jun,CUI Ying,et al.SiamCAR:siamese fully convolutional classification and regression for visual tracking[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).[S.l.]:IEEE,2020:6268-6276.
[57]谭建豪,郑英帅,王耀南,等.基于中心点搜索的无锚框全卷积孪生跟踪器[J].自动化学报,2021,47(4):801-812.
TAN Jianhao,ZHENG Yingshuai,WANG Yaonan,et al.AFST:Anchor-free fully convolutional Siamese tracker with searching center point[J].Acta Automatica Sinica,2021,47(4):801-812.
[58]YUAN T T,YANG W Z,LI Q,et al.An anchor-free Siamese network with multi-template update for object tracking[J].Electronics,2021,10(9):1067.
[59]TIAN Z,SHEN C H,CHENH,et al.FCOS:Fully convolutional one-stage object detection[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV).Long Beach:IEEE,2019:9626-9635.
[60]ZHOU Xingyi,WANG Dequan,PHILIPP K.Objects as Points[C]// IEEE Conference on Computer Vision and Pattern Recognition.Long Beach:CVPR,2019:1-12.
3475501908271
猜你喜欢
导航定位学报(2022年5期)2022-10-13
电机与控制学报(2018年9期)2018-05-14
计算机应用(2016年10期)2017-05-12
科技创新与应用(2016年36期)2017-02-21
电脑知识与技术(2016年27期)2016-12-15
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
科技视界(2016年5期)2016-02-22
