
基于多尺度与混合注意力机制的苹果目标检测
2022-03-10 09:34:58毛腾跃宋阳郑禄
中南民族大学学报(自然科学版) 2022年2期
毛腾跃,宋阳,郑禄
(中南民族大学 计算机科学学院& 湖北省制造企业智能管理工程技术研究中心,武汉 430074)
在苹果产业中,苹果采摘机器人在解决人工采摘效率低、采摘成本高以及劳动力短缺等问题时发挥着重要作用.视觉系统是采摘机器人高效完成采摘任务的关键因素,然而自然环境下生长的果实,受果实重叠、枝叶遮挡、光照等诸多因素的干扰,增加了采摘机器人视觉系统的识别难度,降低了采摘的成功率[1-2].因此要实现果实的自动化采摘,首要的任务是解决自然环境下果实目标的精准检测.
目前国内外在苹果目标检测方面的研究已取得一定进展[3-5].JI 等[6]提出一种基于颜色和形状特征的支持向量机果实识别算法,识别准确率为89%,识别一幅图像的时间是352 ms.但针对叶片遮挡的情况,识别的平均错误率较高.王丹丹等[7]针对无遮挡的苹果目标采用K-means 聚类算法和Normalized Cut(Ncut)算法进行目标轮廓的提取,而对于双果重叠导致的苹果轮廓信息不完整的问题,则采用Spline 插值算法进行轮廓重建,平均分割误差和平均分割重合度分别可以达到5.24% 和93.81%.孙飒爽等[8]针对枝条遮挡下的单个苹果目标,在Lab 颜色空间下,采用K-means 聚类算法分割图像中的苹果目标,然后采用数学形态学方法提取果实的轮廓信息,再依次进行空洞填充、伪轮廓去除等操作,最后采用轮廓的曲率特征对苹果目标进行重建,重建的准确率在84%以上.刘晓洋等[9]针对自然环境下着色不均匀的苹果目标,提出一种基于超像素特征的果实分割方法,首先采用SLIC 简单线性迭代聚类算法将图像进行超像素的分割,然后提取每个超像素的颜色和纹理特征,最后采用SVM 支持向量机对其进行分类.上述方法主要利用果实的颜色、形状与纹理特征等信息人工提取特征,然后通过分类器得到预测结果,算法的局限性大,表达能力有限,鲁棒性差,难以满足采摘机器人在自然环境下工作的需求.
近年来,随着深度学习的兴起与发展,许多研究者将卷积神经网络应用到农业领域中,取得了显著的成果.BARGOTI 等[10]提出基于数据增广技术的Faster R-CNN[11]检测算法,验证了数据增广技术对于水果检测的有效性.MAI 等[12]提出将一个多分类器融入到Faster R-CNN 网络中,用于小水果的检测.王丹丹等[13]提出基于ResNet-44 的R-FCN(Region-Based Fully Convolutional Network)用于识别疏果前的苹果目标,识别精度和速度均有提高.TIAN 等[14]提出YOLOv3-Dense 算法用于检测果园中不同生长阶段的苹果.岳有军等[15]提出在Mask RCNN 的网络中添加边界加权损失函数对苹果目标进行检测.相比传统的机器学习方法,上述方法避免了人工设计特征的不足,检测算法性能明显提升.但是面对复杂的自然环境,当前算法的检测精度仍达不到实际应用的要求.针对以上研究工作存在的问题,本文在YOLOv3 的基础上,提出一种基于多尺度与混合注意力机制的目标检测模型PM-YOLOv3.首先,为了提高模型的多尺度特征表达能力,引入多尺度卷积对标准卷积进行优化,重新构建YOLOv3 的特征提取网络;然后,在卷积模块间引入注意力模块,增强重要特征的表达能力;最后采用K-means 算法对先验框重新进行聚类,获取最优的先验框尺寸.本文所提出的PM-YOLOv3 检测模型不仅能够提高检测性能,对于复杂环境下的苹果目标检测也更具鲁棒性.
1 YOLOv3与CBAM结构
1.1 YOLOv3
YOLOv3 是单阶段的端到端目标检测算法,它的核心思想是将整张图片直接输入网络,然后提取图片中的特征信息来预测目标的位置和类别.YOLOv3 主要由特征提取网络、多尺度预测层两部分组成,其网络结构如图1所示.
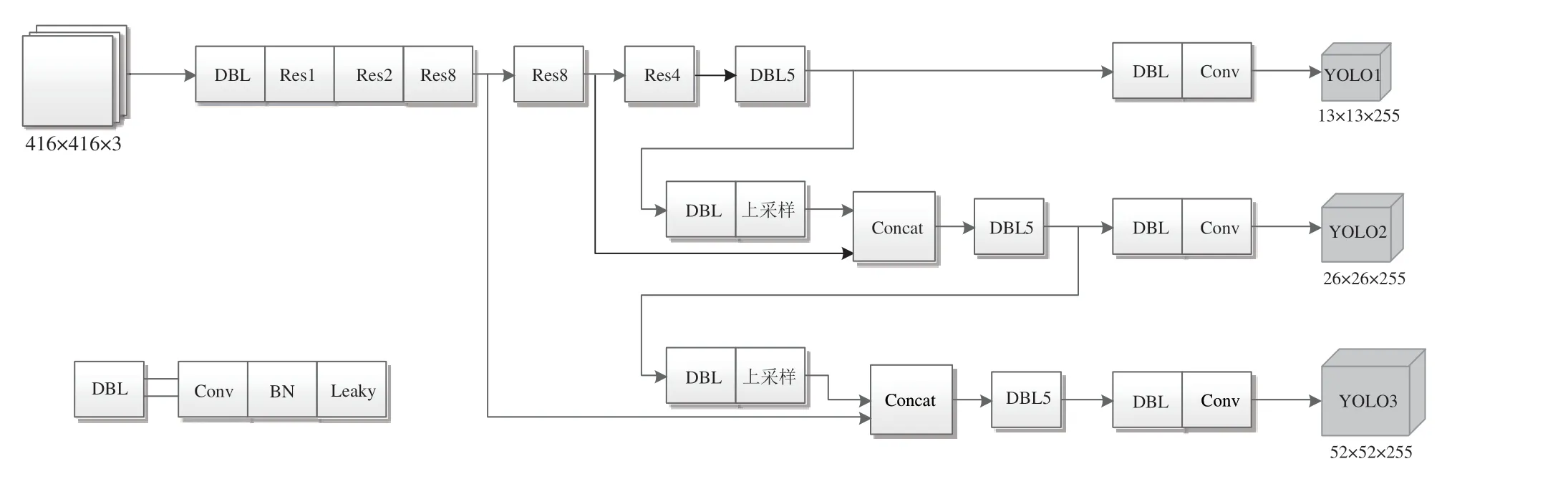
图1 YOLOv3网络结构Fig.1 YOLOv3 network structure
YOLOv3 的特征提取网络DarkNet-53[16]借鉴残差网络ResNet[17]的思想,在网络中使用大量的残差结构,避免神经网络在网络层数过深时发生梯度弥散.DarkNet-53 是一个具有53 个卷积层的全卷积神经网络,网络结构中主要使用3×3 和1×1 的卷积构建残差模块,去除了池化层,特征图的降采样采用步长为2 的卷积进行替换,在每个卷积层后分别使用批量归一化和激活函数,加快算法的收敛速度,同时防止模型出现过拟合的现象.
YOLOv3 的预测层为了解决小目标检测不敏感的问题,采用3 个不同尺度进行目标检测.3 个尺度分别是13×13、26×26、52×52,其中最小的13×13 特征图感受野较大,用于检测图像中较大的目标,而较大的52×52 的特征图由于其具有较小的感受野,因此用于检测图像中较小的目标.
1.2 CBAM
注意力机制是深度学习领域中一个重要的概念,学者们在不同的应用领域对其进行了充分的研究.它的作用是让算法将注意力更多地集中在重点区域,获得该区域更多的细节信息,抑制无用的信息.CBAM[18]是一种由空间注意力机制和通道注意力机制两个部分组成的注意力模型,对于卷积神经网络中生成的特征图,可以在通道与空间两个维度,依次进行推导,分别得到两个权重系数,然后将权重系数与输入的特征图相乘,得到最终的特征图.由于CBAM 是一个轻量级的注意力模块,可以在各种神经网络中添加,并进行训练,在保持开销较小的同时提高神经网络的性能.注意力模块结构如图2所示.
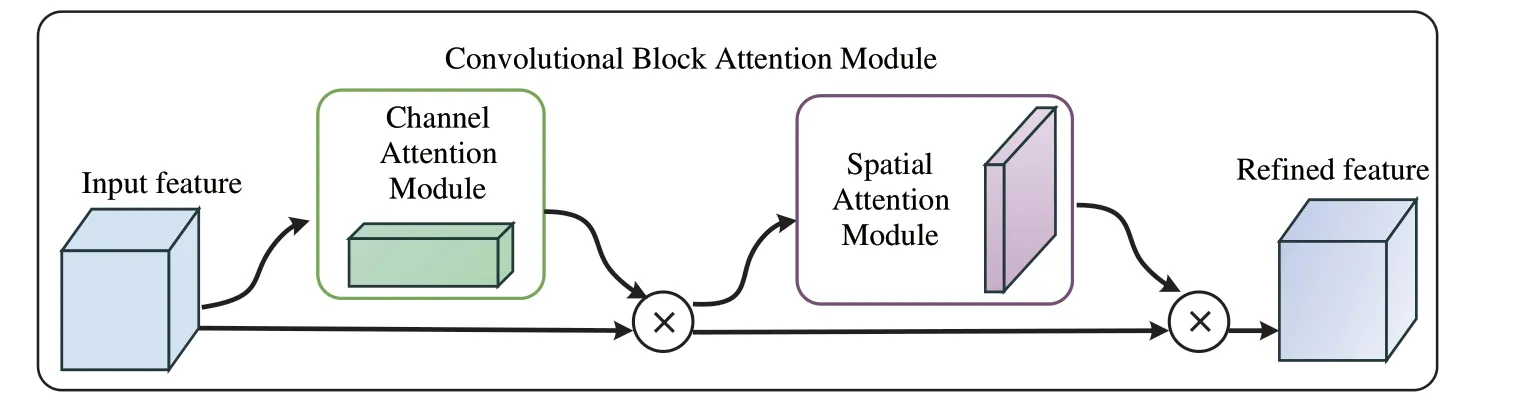
图2 CBAM注意力机制模块Fig.2 CBAM attention mechanism module
2 改进的YOLOv3网络
2.1 特征提取网络的改进
YOLOv3使用的特征提取网络是DarkNet-53,网络中大量采用3×3 和1×1 的常规卷积,而常规卷积在进行运算时,直接对输入的特征图进行卷积,得到输出特征图,获取到的特征信息有限.而且采摘机器人进行采摘任务时其视觉系统获取的图像中往往存在多个尺度的目标,距离摄像头较近的目标尺寸偏大,而距离较远的则尺寸较小,因此,如果仍然采用常规卷积进行特征的提取,会导致提取到的部分特征信息丢失,出现漏检的情况.
针对上述问题,本文在YOLOv3 网络结构的基础 上,引 入 多 尺 度 卷 积PSConv[19](Poly-Scale Convolution),替换特征提取网络中的常规卷积,以更精细的粒度进行多尺度特征融合,增强神经网络对尺度变化的鲁棒性.多尺度卷积针对单个的卷积层,使用多种不同的扩张率,并将它们均匀地分配到每个滤波器的单个卷积核中.这些扩张率沿着滤波器的输入和输出通道轴周期地进行变化,集成多尺度特征.在神经网络中采用多尺度卷积替换常规卷积,可以在不增加计算复杂度的情况下,进行更细粒度的多尺度特征学习,获得图像的重要特征,提高算法的特征提取能力.
对于多尺度卷积,设F∈RCin×H×W表示输入的特征图,在卷积滤波器G∈RCout×K×K的不同卷积核中,采用不同的扩张率,然后与输入张量进行卷积,得到输出特征图H∈RCout×H×W,其中D∈RCout×Cin是由两个正交维护中的通道方向和滤波器方向的扩张率组成的矩阵,元素D(c,k)与滤波器中的特定通道相关联,其详细计算过程如公式(1)所示:
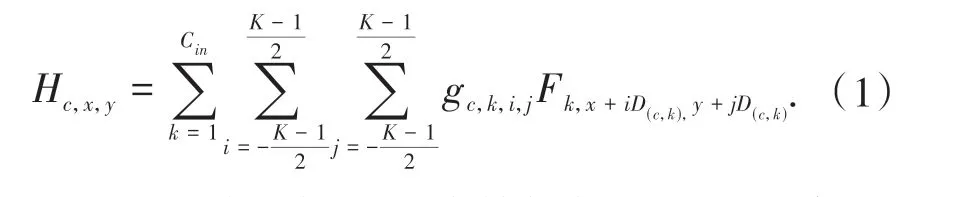
改进后的特征提取网络结构如图3 所示,保留原网络中输出尺寸为208×208 和104×104 的两个残差模块,将输出尺寸为52×52、26×26 和13×13 的三个残差模块中的3×3 卷积采用多尺度卷积替换,提高算法的多尺度特征提取能力.
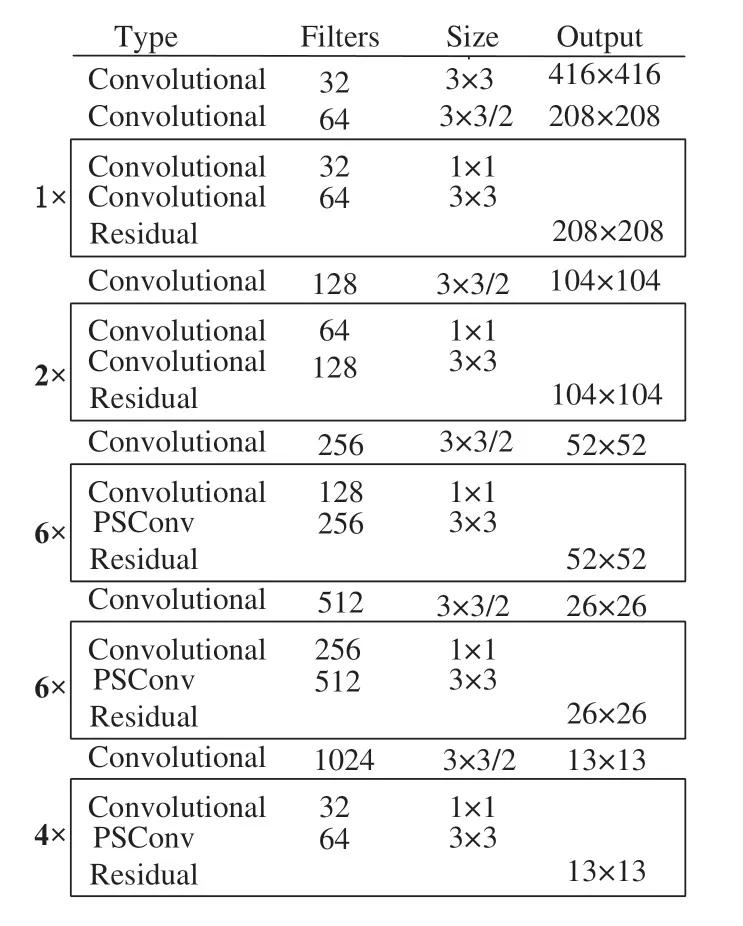
图3 改进的YOLOv3网络结构Fig.3 Improved YOLOv3 network structure
将普通卷积替换为多尺度卷积后,虽然能够不增加计算的复杂度,但是过深的网络层数,仍然会存在大量的参数.因此,继续对网络的层数进行削减,将输出尺寸为52×52、26×26 的两个残差模块的数量由原来的8 个减少为6 个,构建了45 层的特征提取网络,在提高检测准确性的同时,保证了检测速度.
2.2 增加注意力机制
自然环境下生长的果实,受树叶遮挡、枝条遮挡等干扰因素的影响,导致苹果采摘机器人采集到的图像,背景信息复杂多变,给果实的识别与定位带来了困难.因此本文借鉴注意力机制的特点,在YOLOv3 网络中,添加CBAM 注意力模块以加强算法在复杂的背景中获取更多的丰富的特征信息,提高算法检测的准确率.
YOLOv3 的多尺度预测层,采用了类似FPN[20](Feature Pyramid Networks)的结构,将特征提取网络中提取到的特征信息,在3个不同尺度上进行融合,然后进行目标检测.因此本文在YOLOv3 特征提取网络的基础上,对多尺度预测层中的每个分支中分别添加一个CBAM 模块,将特征提取网络中获取到的特征信息,在通道和空间两个维度上使用注意力机制,进行权重的自适应学习,以较小的开销提升算法的检测性能.
2.3 先验框改进
先验框是一组预先定义好的具有不同尺寸的固定的参考框.在进行目标检测时,首先将先验框作为初始预测,然后进行回归调整.采用与数据集相匹配的先验框,不仅可以加快模型的收敛速度,而且可以进一步提升目标检测的精度.YOLOv3 中采用的9 个先验框是在COCO 数据集上采用K-means 聚类算法得到的,比较适合多个类别目标的检测.
从表1可以得到,重庆地区的机插水稻面积2007年是2006年的21.4倍,2008年相对于2007年水稻机插面积增加90%;机插水稻与传统手工种植水稻的方法相比较,增产率在10%以上;机插水稻每年的产量,也在以13.3%以上的速率增长,因此机插水稻的使用技术也在不断成熟。
由于自建的苹果数据集与COCO 数据集中目标尺寸不同,如果仍采用原始算法中的先验框进行苹果目标的检测,则会影响算法对果实的识别与定位精度.因此,采用K-means聚类算法,以1-IOU的值来计算样本点到聚类中心的距离,对自建的数据集,重新进行聚类,得到9 种不同尺寸的先验框,如表1所示.
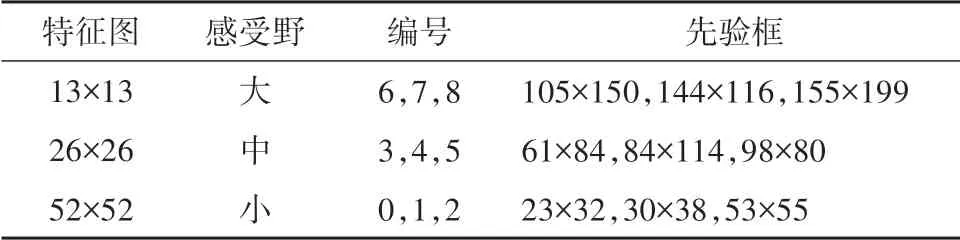
表1 先验框尺寸Tab.1 The size of the prior box
3 实验结果与分析
3.1 实验数据集
本文采用的数据集由两部分组成:一部分来源于文献[10]中的图片,另一部分是从网上下载的高质量图片,共收集1600张图片,然后进行人工筛选,将重复的图像去除,最终获得1400 张图片,并将图片统一按比例缩放为500×375 像素.由于该数据集的数量不足,为了防止算法训练过程中出现过拟合的现象,采用数据增广技术扩充数据集,分别对图片进行水平翻转、垂直翻转、正逆时针旋转以及添加噪声等操作,如图4 所示,共得到2400 张图片.然后采用LabelImg 图像标注工具对数据集进行标注(苹果被遮挡面积≥50%,不进行标注).

图4 数据增广操作Fig.4 Data augmentation operations
3.2 实验环境与算法训练
本实验基于Linux 平台通过Python 语言实现,采用Ubuntu 20.04 的操作系统,硬件配置为Intel(R)Xeon(R)CPU E5-2630 v4 @ 2.20 GHz,显卡为NVIDIA GeForce GTX1060,采用Pytorch 深度学习框架.
算法训练时,随机选取数据集中1920张作为训练集,100张作为验证集,380张作为测试集.网络中输入图像的尺寸设置为416×416,批处理的大小为16,动量系数为0.9,权重衰减正则系数设为0.0005,学习率的初始值设置为0.001.
在训练过程中采用Adam 优化器自动调整学习率.模型进行训练的过程中,损失函数曲线见图5,可以看出,在前50个epoch时,损失下降得比较快,训练100 个epoch 后,损失函数下降较慢,训练450 个epoch时逐渐趋于平稳,算法已经达到了收敛.
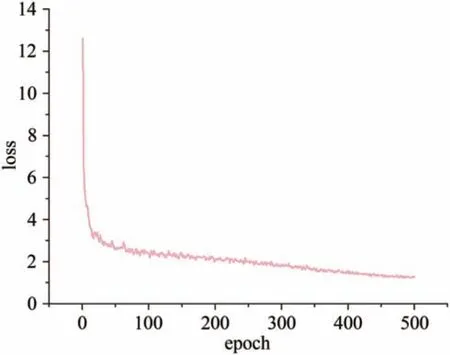
图5 损失函数曲线Fig.5 Loss function curve
3.3 评价指标
为了更好地评估本文改进算法的有效性,采用精确率(Precision)、召回率(Recall)、F1分数(F1-score)3 个指标来对算法的泛化性能进行评估.F1 分数是精确率P与召回率R的调和平均(Harmonic Mean),是一个同时考虑精确率与召回率的评价指标,避免精确率或召回率的单一极大值,用于综合反映整体的指标.计算公式为:
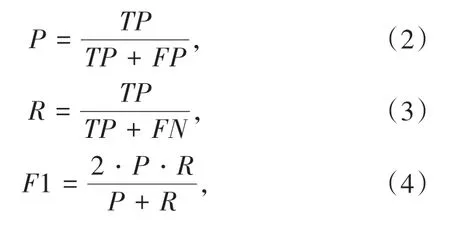
其中TP表示样本为正预测的结果为正;FP表示样本为负预测的结果为正;FN表示样本为正预测的结果为负.
3.4 实验分析
为了验证本文改进方法的有效性,设计了消融实验对算法的检测性能进行评估.其中实验Ⅰ采用原始的YOLOv3算法,由特征提取网络DarkNet53和多尺度预测层组成.实验Ⅱ则采用改进后的特征提取网络DarkNet45,预测层仍使用原算法中的预测网络.实验Ⅲ采用DarkNet53 作为特征提取网络,在预测层的3个分支中添加注意力模块CBAM.实验Ⅳ采用本文提出的改进算法PM-YOLOv3 进行目标检测.实验结果如表2所示.
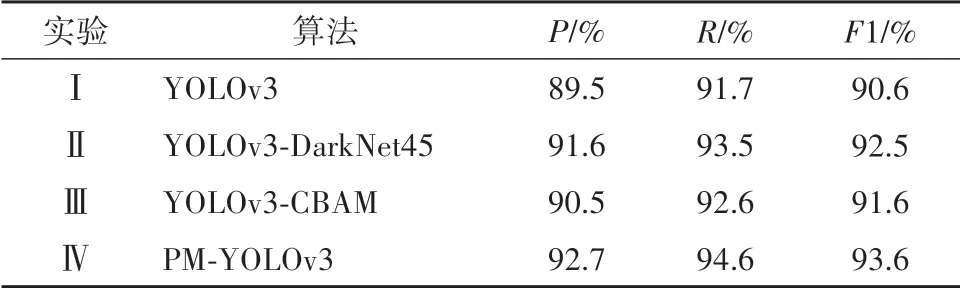
表2 不同改进策略的检测性能对比Tab.2 Comparison of detection performance of different improvement strategies
对比实验Ⅰ和实验Ⅱ可以看出,本文对特征提取网络的改进是可行的,精确率P、召回率R、F1 值均有显著的提升,优于原始的YOLOv3算法,说明在特征提取网络中融入多尺度卷积,能够有效地融合不同尺度间的内在关系,实现上下文信息的多尺度提取,提升算法的特征表达能力.
结合实验Ⅰ和实验Ⅲ的结果来看,添加注意力机制后,检测性能也有小幅度的提升,其中F1 值为91.6%.表明注意力机制模块,可以将特征提取网络中提取到的特征信息,按照重要程度,进行权重的自适应分配,使得关键的信息分配较大的权重,对于一些无用的信息则分配较小的权重,让算法能够将注意力集中于重点的区域,从而提升算法的检测性能.
综合所有实验结果可以看出,改进后的算法明显优于原算法,并且将多尺度卷积和注意力机制进行融合的实验效果是高于单独引入其中一个模块的,其中精确率P为92.7%,召回率R为94.6%,F1值为93.6%,均有明显的提升,表明本文的改进算法,有利于多尺度目标和密集目标的检测,减少了漏检的情况,有效地提高了检测精度.
3.4.2 不同场景下检测效果对比
为了验证本文对自然环境下苹果目标检测的有效性,随机选取6 张图片,即包含稀疏完整、重叠遮挡两种不同情况,采用YOLOv3 和PM-YOLOv3 进行目标检测.其中YOLOv3 算法检测结果用绿色标注,PM-YOLOv3 检测结果用棕色标注.检测结果见图6.

图6 不同场景下的检测效果对比Fig.6 Comparison of detection effects in different scenarios
从图6可知,稀疏完整的苹果目标,因为没有枝叶、枝条遮挡等干扰因素存在,改进前后的算法均能准确地识别出果实.而对于重叠遮挡的苹果目标,受遮挡因素的影响,YOLOv3 会存在漏检的情况,而本文提出的PM-YOLOv3 算法,检测效果优于YOLOv3,能够准确地检测出遮挡情况下的果实.因此,本文的改进算法能够适应自然环境下的苹果目标检测,具有较强的泛化能力.
针对上述两种情况,采用改进前后的算法在测试集上分别进行验证实验,结果如表3所示.
从表3 中可以看出,对于处于不同场景下的苹果果实,改进后算法的检测精度均高于YOLOv3,而且在重叠遮挡的情况下,本文提出的改进方法精确率可以达到90.3%,召回率为92.5%.结果表明本文所提的改进策略是可行的,针对不同场景下果实目标的检测具有较好的检测效果.
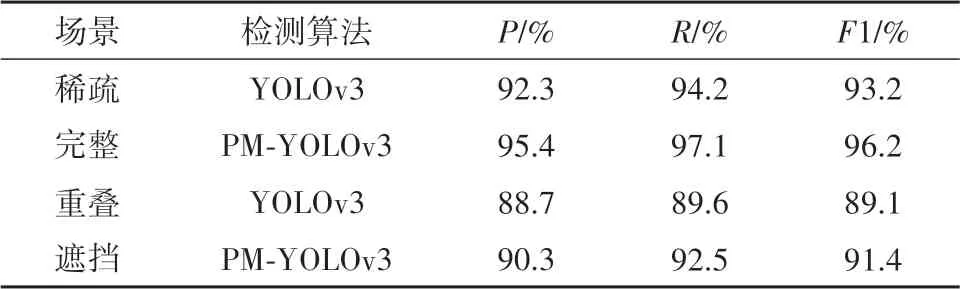
表3 不同场景下的检测性能Tab.3 Detection performance in different scenarios
3.4.3 改进后的算法与其他目标检测算法对比
为了进一步验证本文所提出算法的有效性,将本文的算法PM-YOLOv3 与目标检测中广泛使用的其他算法进行对比实验,包括YOLOv3、Faster R-CNN、YOLOv4[21],实验结果如表4.
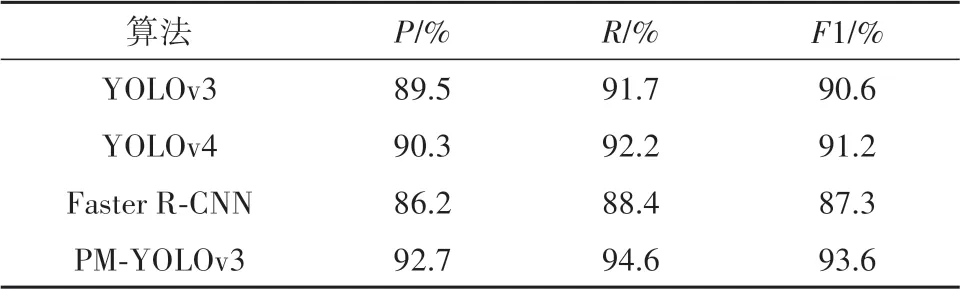
表4 改进后算法与其他目标检测算法对比Tab.4 Comparison between the improved algorithm and other target detection algorithms
从表4可以看出,与其他目标检测算法相比,本文的算法具有更高的检测精度,F1 值可以达到93.6%.与Faster R-CNN 算法相比,精确率和召回率分 别 提 高6.5% 和6.2%,F1 值 提 高6.3%. 而 与YOLOv4 相比,也有小幅度的提升,验证了本文提出的改进策略的有效性,能适用于自然环境下苹果目标的检测.
4 结语
本文针对自然环境下苹果目标受环境影响导致苹果采摘机器人识别与定位不准确的问题,提出了一种基于多尺度与混合注意力机制的苹果目标检测模型.首先,采用多尺度卷积替换常规卷积,聚合图像中的多尺度信息,削减网络层数,在保证算法检测速度的同时,提高算法的检测精度;然后,在网络的卷积层间添加注意力机制模块,增强特征的表达能力;最后,使用K-means 聚类算法重新聚类先验框.实验结果表明:本文的方法可以显著提高算法的检测性能,在测试集上的F1 值可以达到93.6%,对自然环境下的苹果目标检测具有较强的鲁棒性,可以为苹果的自动化采摘提供技术支持.
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
电子制作(2018年19期)2018-11-14 02:37:08
传媒评论(2017年3期)2017-06-13 09:18:10
自动化学报(2017年11期)2017-04-04 02:52:58
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
太空探索(2016年5期)2016-07-12 15:17:55
噪声与振动控制(2015年4期)2015-01-01 07:08:21
时代英语·高三(2014年5期)2014-08-26 17:01:17
轴承(2010年2期)2010-07-28 02:26:12
