
命名数据网络中一种显式拥塞控制方法研究
2022-03-10 09:34邢光林胡青侯睿
中南民族大学学报(自然科学版) 2022年2期
邢光林,胡青,侯睿
(中南民族大学 计算机科学学院,武汉 430074)
随着互联网技术的快速发展,基于TCP/IP 的体系结构在安全性、移动性、可靠性和可扩展性等方面面临着诸多挑战[1],而信息中心网络(Information Centric Networking,ICN)[2-3]摒弃了传统的以IP 层为核心的协议栈结构,采用以信息为核心的协议栈结构[4],其关注信息本身并弱化信息位置,将网络通信方式从端到端的通信方式转变为以内容为中心的通信方式,逐渐成为未来网络架构的主流研究方向 之 一[5]. 其 中,命 名 数 据 网 络(Named Data Networking,NDN)因其耦合路由、网内存储等特点被认为是信息中心网络最具代表性的一个架构方案,受到了各国学者的广泛关注.
在NDN 中,使用了两种类型的包来实现消费者(即内容请求者)和生产者(即内容发布者)之间的通信,分别是兴趣包和数据包[6],所有的数据内容被指派一个唯一的内容名称.消费者将所需数据内容名称封装到兴趣包中并发送到NDN 网络,当NDN路由器接收到兴趣包后会根据数据内容名称将兴趣包以逐跳的方式转发至相应的生产者,生产者将消费者所需数据内容封装到数据包中,沿兴趣包所经路径原路返回至消费者,完成数据交互过程.每个NDN 节点维护三个数据结构,分别是内容存储(Content Store,CS)、待定兴趣表(Pending Interest Table,PIT)和转发信息库(Forwarding Information Base,FIB),其中CS为内容存储,PIT用于记录名称前缀和传入接口等信息,FIB 提供基于内容名称的路由.由于NDN 采用基于内容名称路由的无连接传输模式[7],这使得拥塞控制变得复杂,因为传输层的拥塞控制机制通常使用端到端的网络路径属性的估计来执行[8],同时拥塞控制对提高网络的性能具有重要意义,因此NDN的拥塞控制问题逐渐受到广泛关注.
本文提出一种显式拥塞控制方法(Explicit Congestion Control Method,ECM).当遇到突发流量导致链路发生拥塞时,路由节点为每个数据流配置一个计数器,转发兴趣包时计数器会相应递减,当计数器为零时(这意味着该数据流已经传输了其被允许的数据量),则当前数据流被标记为贪婪流,属于这些流的兴趣包被加入到缓存(整形)队列中,然后当前路由节点通知其下游路由节点降低兴趣包的转发速率(即显式拥塞通知),最后通过数据包将拥塞信息返回给消费者,消费者从而可根据拥塞信息来调整兴趣包的发送速率.
1 相关工作
NDN 中现有的拥塞控制研究工作可以大致概括为两种类型:由请求者驱动的拥塞控制机制和逐跳拥塞控制机制.
第一类方式借鉴了传统TCP/IP 的设计,通过在消费者方调整兴趣包的发送速率来达到拥塞控制的目的.速率调整使用的是“和式增加积式减少”(Additive Increase Multiplicative Decrease,AIMD).文献[9]提出了一种兴趣控制协议ICP(Interest Control Protocol),设置在消费者方的AIMD 控制器会根据当前网络的情况来调整发送窗口的大小.文献[10]提出了一种基于超时机制的CCTCP(Content Centric TCP)协议,通过替每个流设置多个拥塞窗口和RTO 超时重传机制来控制兴趣包的发送速率.以上都是基于超时驱动的拥塞控制策略,该类型的算法都是使用了RTT(Round Trip Time)作为超时的度量,但是由于NDN 的多源特性,消费者所请求的数据内容在网络中的分布通常是不确定的,这导致对RTT 的准确估算非常困难.因此,NDN 的学者更倾向于逐跳的显式拥塞控制机制.
逐跳拥塞控制机制依赖于中间路由节点,文献[11]提出了一种结合发送端与路由节点端的拥塞控制机制HR-ICP(Hop-by-hop and Receiver-driven Interest Control Protocol),它采用了逐跳的兴趣包整形方案,使得HR-ICP 能够比ICP 更快地检测和响应拥塞状态.文献[12]提出了一种采用显式拥塞通知的拥塞控制机制CHoPCoP(Chunk-switched Hop Pull Control Protocol),能够很好的处理NDN 中的多源、多路径问题.文献[13]提出了一种逐跳的兴趣包整形机制,通过监测路由节点输出链路上的兴趣包队列大小来计算和控制兴趣包的转发速率.文献[14]提出了一种基于公平性的路由节点主动队列管理方法,该方法通过流量速率整形来保证资源的公平分配.上述方法虽然获得了较好的性能,但是并没有考虑资源的公平分配,因此需要在中间路由节点处实施公平方案,以确保贪婪流不会垄断可用的网络资源.
本文借鉴速率控制协议(RCP)的思想,提出一种基于路由节点端的拥塞控制方法,当网络拥塞时,ECM 利用计数器和整形队列对标记为贪婪流的数据流进行降速处理,同时更新兴趣包中的拥塞信息域并将其逐跳反馈给下游路由节点,最后利用数据包将拥塞信息反馈给消费者,消费者据此调整兴趣包的发送速率,从而实现网络拥塞控制,在保证数据流的公平性的前提下考虑了不同数据流之间的优先级,保障了数据流的QoS.
2 算法设计和拥塞控制机制
2.1 数据流优先级
ECM考虑了链路带宽、数据流的优先级和延时要求,保证了各种优先级数据流的QoS要求.每个数据流所分配得到的带宽资源遵循最大-最小公平分配.设不同数据流QoS要求的延时上限为Di,瓶颈链路带宽为C,整形队列的最大长度为Qmax,路由节点j中数据流i的平均速率为rij,路由节点j中数据流i的最大数据包大小为Sij,沿路所经路由器数量为n,链路传播延时为Df,则数据流i的延时上限可以被写为:
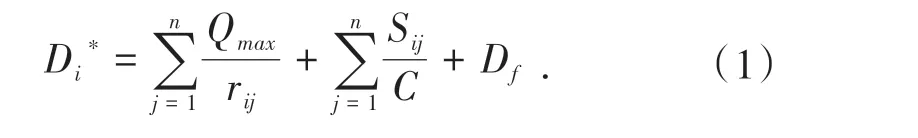
ECM引入了延时差值αi=Di-Di*来确定不同数据流的优先级.当路由节点按照ri为数据流分配带宽时,αi表示其QoS 要求的延时上限与公式计算得出的延时上限之间的差值,αi越小,表示根据公式计算得出的延时上限与QoS 要求的延时上限越接近,数据流对其被分配的带宽资源的变动越敏感,相应地优先级也越高.
2.2 ECM算法设计
ECM主要的流程图如图1所示.
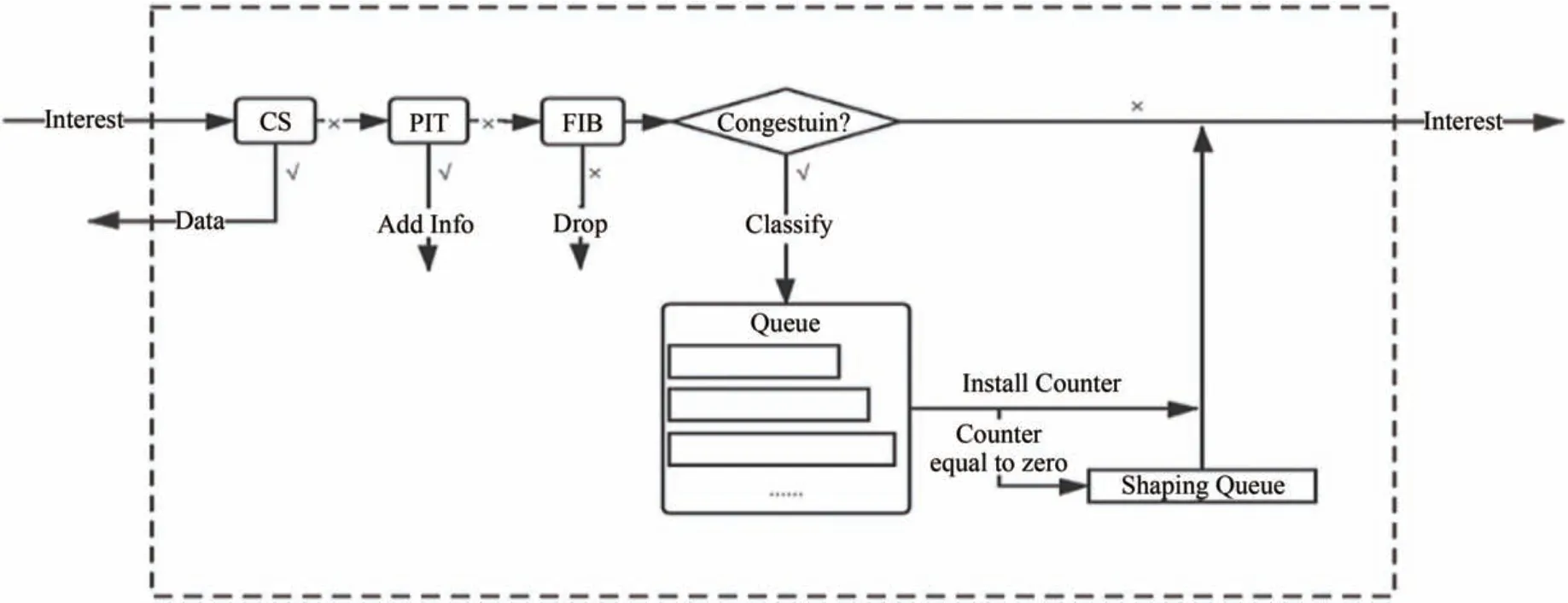
图1 ECM算法流程Fig.1 ECM algorithm process
ECM 算法运行在NDN 路由节点上,首先根据NDN 名字前缀的不同将兴趣包分为不同的流,之所以这样定义,是因为具有相同名字前缀的兴趣包具有相同或相似的状态,PIT 中唯一的名字前缀的数量决定了当前网络中活动的流的数量.当遇到突发流量导致链路发生拥塞时,路由节点会为每个数据流配置一个计数器,当兴趣包被转发时计数器会相应递减.当计数器大于零时,兴趣包直接转发;当计数器小于或等于零时,则当前数据流被标记为贪婪流,需要对其速率进行限制,将贪婪流的兴趣包暂时缓存于整形队列中而不是直接丢弃,既避免了进一步的拥塞,同时也降低了丢包率,直到相应计数器被重置更新后,整形队列中的兴趣包才被转发,计数器被重置更新的值为ECM 计算得到的相应数据流的转发(限制)速率.为了缓解当前链路的拥塞,还需要借助显式拥塞通知机制通知其下游路由节点降低兴趣包的转发速率,才不会因为队列持续增加导致延时过长,经过算法整形后的速率就是网络期望且不会造成拥塞的速率.ECM 核心算法的伪代码如算法1所示.
ECM 的速率控制算法是基于文献[15]中提出的速率控制协议(RCP)设计的.采用RCP 的动机思想在于其为所有流公平分配速率(即带宽)的优势,并以快速的下载时间实现网络带宽的优化利用.NDN 路由节点处理、转发和缓存数据包的能力为RCP 的实现和部署提供了很好的支持,此外,NDN的逐跳转发性质也能很好地契合RCP 的反馈机制.ECM 的速率控制方案的核心思想是,每个路由节点维护一个值R(t),该值表示当前路由节点支持的最大的数据包的返回速率,即当n个流的输入速率为ri(t)=(r1,r2,r3…rn)时,路 由节点的负载为sumR=,当sumR<R(t)时,链路没有发生拥塞,当sumR>R(t)时,链路发生了拥塞,需要执行ECM 算法来对数据流进行限制,R(t)的更新公式如下:
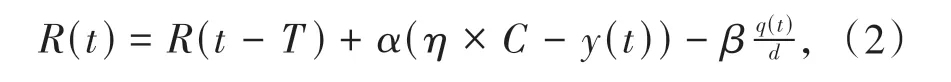
在公式中,η是目标链路利用率,α和β是控制稳定性和性能的参数,C为可用链路带宽,y(t)为路由节点在周期(t-T,t)内的总输入流量,q(t)表示时间t时缓冲队列的长度,d是消费者发送兴趣包和匹配数据包到达消费者之间的平均响应时间.
由于ECM 是具体到每个数据流的拥塞控制方法,因此还需要对R(t)进行分割,为了达到优化传输和负载平衡的目的,可以公式化为一个简单的凸优化问题,设当前路由节点中有n个活动数据流,兴趣包的发送速率为mi=(m1,m2,m3…mn),具体公式如下:
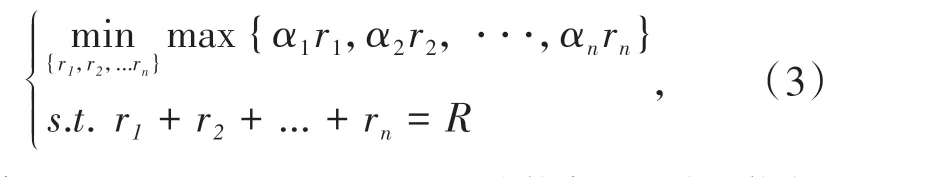
显然,当α1r1=α2r2= ···=αnrn时能够得到最优解值,继而得到每个数据流的转发速率为:
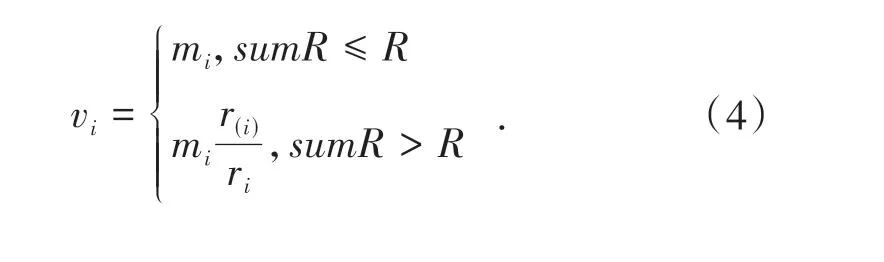

算法1 ECM 算法的伪代码符号约定:ri 流的输入速率vi 转发速率sumR 路由负载输入 n streams:r1,r2,…rn输出 n streams:r1,r2,…rn按照既定的规则被转发for each ri do sumR←sumR+ri end for if sumR>R //发生拥塞for each ri do calculate vi. //计算限制速率if counters>0 counters←counters-interest.data_size interest=Shaping_Queue_Dequeue(i)Forward(interest)end if else Shaping_Queue_Enqueue(interest)Limit_Rate←vi Congestion_Flag←Congestion_Flag+1 send NACK to downstream router end else end for if counter for each flow should be reset after some time for each ri do Update_Counters(vi) //更新计数器end for end if end if else Standard_NDN_Processing end else if Interest packet is satisfied copy Limit_Rate and Congestion_Flag in Data packet send Data packet to consumer end if
2.3 显式拥塞通知
本文通过拓展兴趣包的结构,增加两个字段:限制速率(Limit Rate)和拥塞标志(Congestion Flag)来实现显式拥塞通知.扩展之后的兴趣包结构如图2所示.
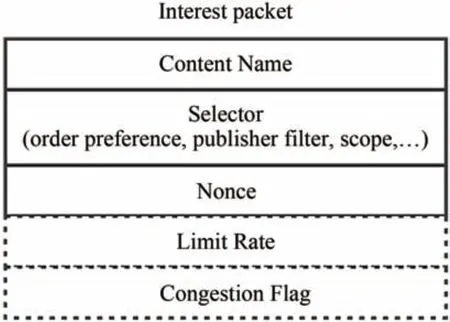
图2 兴趣包结构Fig.2 Interest packet structure
其中,限制速率为算法计算得到的兴趣包转发速率,拥塞标志表示兴趣包是否导致了拥塞的发生.当消费者开始发送兴趣包时,将限制速率初始化为兴趣包的发送速率,拥塞标志初始化为零.当遇到突发流量导致链路发生拥塞时,如果兴趣包所属的数据流相应的计数器小于等于零时,那么则判断当前兴趣包的输入速率过高,即认为其对网络拥塞做出了“贡献”,需要对其速率进行限制,将算法计算得到的转发速率更新到相应的限制速率字段,并且将拥塞标志加一,同时向该兴趣包传入的接口发送NACK,NACK 中封装的是限制速率,当下游路由节点(k-1)收到NACK 后不会自动通知其下游路由节点(k-2),而是提取限制速率作为新的计数器更新速率,并根据自身负载来决定是否发送NACK.这样可以减少更多的兴趣包传入该拥塞区域,从而暂时缓解网络的拥塞,但是这样也可能造成本来不拥塞的下游链路发生拥塞,因此要彻底解决网络的拥塞,还需要消费者根据网络的状况来改变兴趣包的发送速率.
当一个兴趣包即将被满足时,路由节点检查其拥塞标志,如果等于零,则直接返回数据包;如果大于零,则将限制速率复制到数据包中并原路返回给消费者.当消费者接收到数据包后,将数据包中的限制速率提取出来作为新的兴趣包发送速率,这样就可以将网络发生拥塞的概率降到最低,从而提高网络的吞吐量,保证网络的良好性能.
3 仿真实验
3.1 实验配置
在ndnSIM2.0 上进行了实验,来证明所提出的算法的有效性.ndnSIM2.0是一个基于ns-3的仿真平台,能够仿真多样化的部署场景,支持大范围的NDN实验.仿真实验采用的拓扑结构如图3所示.采用的是单瓶颈链路拓扑,其中消费者Src1 至Src3 每秒发送1000个兴趣包,三种数据流所能接收的最大延时Di分别为45 ms,50 ms 和55 ms,数据请求服从齐夫分布,链路的传播延时为10 ms,转发策略采用的是BestRoute.
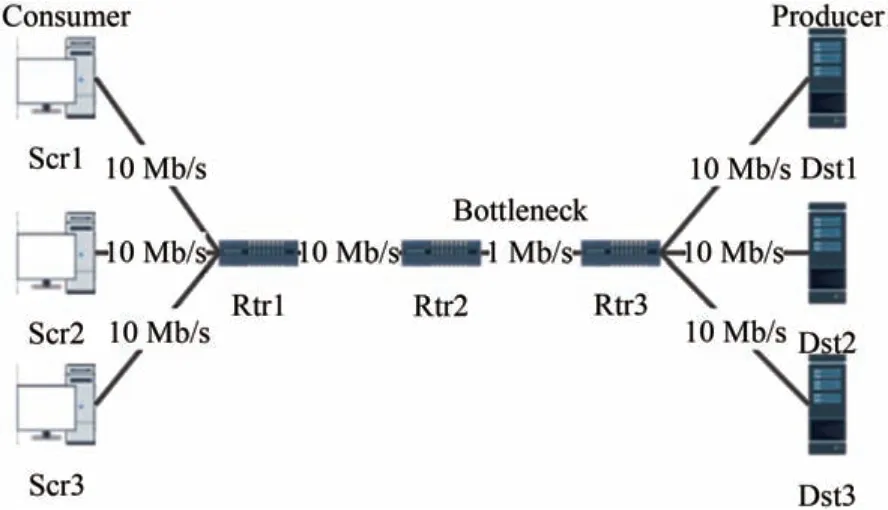
图3 网络拓扑Fig.3 Network topology
因为ECM 算法需要计算大量数据流的速率,但是其随着网络的拥塞状况也在发生变化.为了更好地验证算法的稳定性,场景二使用了与场景一基本相同的参数,但是瓶颈链路带宽从1 M 逐渐增加到6 M,观察平均丢包率的变化.
3.2 实验结果与分析
将提出的ECM 算法与ICP、HR-ICP 和CHoPCoP进行了比较,ICP 是一种类似于TCP 的兴趣包控制协议,设置在消费者的AIMD 控制器会根据当前网络的状况来调整输出窗口的大小,HR-ICP 在ICP 的基础上提出一种结合发送端与路由节点端的拥塞控制机制,CHoPCoP 使用显式拥塞通知而不是RTO计时器来更快地响应网络的拥塞信息.考虑的性能指标包括延时,数据接收速率和丢包率.
延时随时间的变化结果如图4 所示.三位消费者的延时都逐渐增加并收敛于40 ms 左右,收敛以后处于稳定状态,这是因为ECM 能够通过收集返回数据包携带的速率信息来实现一定程度上的路由节点协调,当网络中的负载达到相对均衡时,消费者将以接近恒定的速率发送兴趣包,因此明显改善了延时抖动性,说明了算法的稳定性.同时,收敛后的延时随数据流的优先级的增大逐渐减少,这样既保证了数据流的服务质量同时也提供了更好的体验质量.
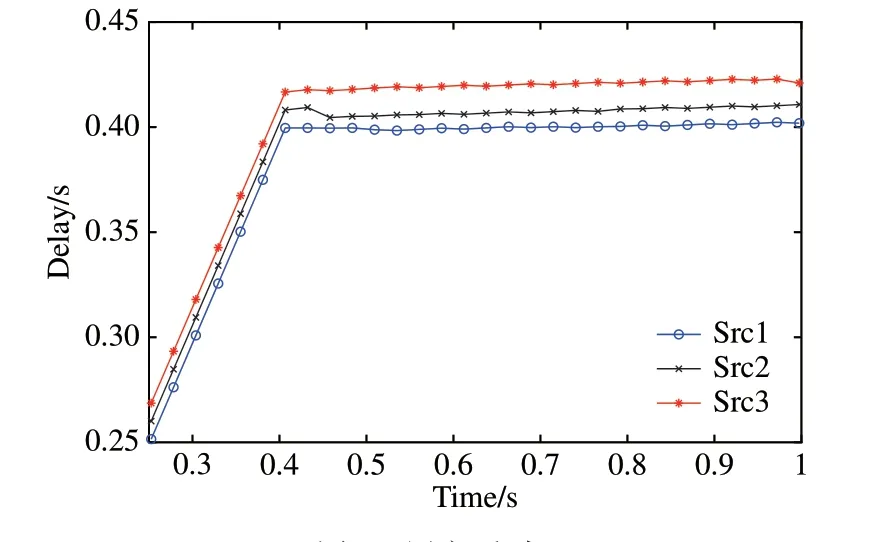
图4 用户延时Fig.4 Delay of users
图5显示了三种优先级数据流的瓶颈带宽分配情况.我们可以明显观察到,当网络发生拥塞时,系统分配带宽的情况和数据流的优先级是一致的,也就是说,当链路带宽不足的情况下,高优先级数据流的QoS得到了有效的保证.
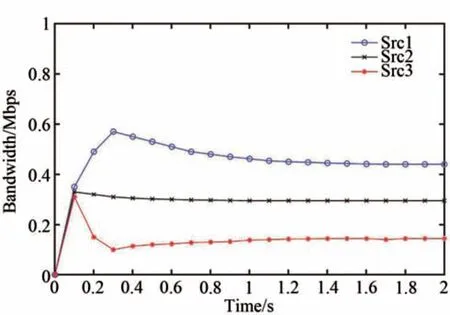
图5 不同优先级数据流的宽带分配情况Fig.5 Bandwidth allocation of different priority flows
图6比较了ICP、HR-ICP、CHoPCoP和ECM在仿真期间的数据接受速率.可以看到ECM 的性能是明显优于ICP 和HR-ICP 的,这是因为ICP 采用了拥塞窗口,慢启动会导致速率较低,同时由于拥塞窗口的增加,消费者发送的兴趣包增多,这样会导致兴趣包的排队时间增加,相应的RTT 也会增加,从而降低了ICP 的网络容量利用率,而HR-ICP 由于在中间路由节点能够检测拥塞从而与ICP 相比网络容量利用率更好,但其仍采用拥塞窗口来调节兴趣包发送速率.ECM 和CHoPCoP 都能很好地利用网络容量,由于CHoPCoP 使用了显式拥塞通知机制,使得其能更好地响应网络中的拥塞信息,从而更好地利用网络容量,但是ECM比CHoPCoP的稳定性更好.
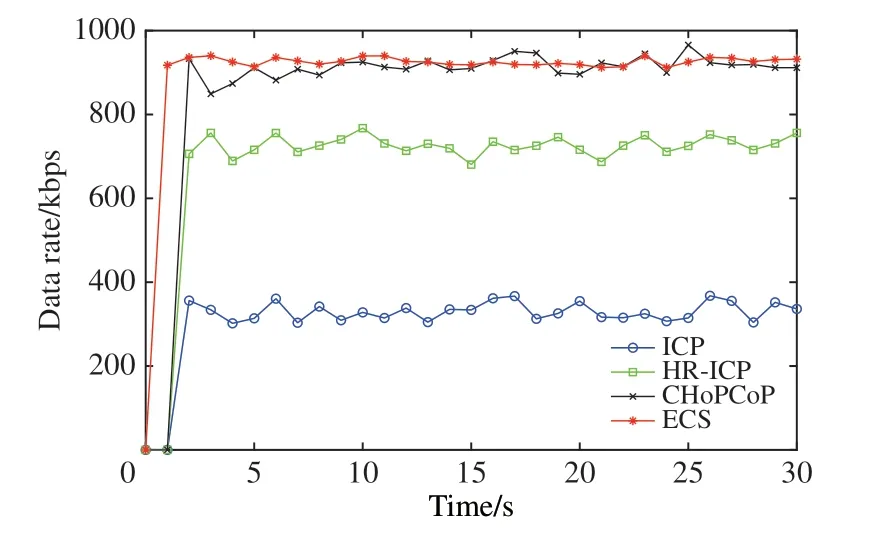
图6 四种方法的数据接收速率Fig.6 Data rate of four methods
图7 是这三种机制的数据接受速率的小提琴图.小提琴图是箱线图与核密度图的结合,显示了速率的中位数和四分位数以及速率的集中和离散程度,可以看到ECM 的数据分布是更集中的,同时根据表1的数据显示,ECM的四位方差最小,中位数最大,也说明ECM 在充分利用了网络容量的同时,保证了较好的稳定性.
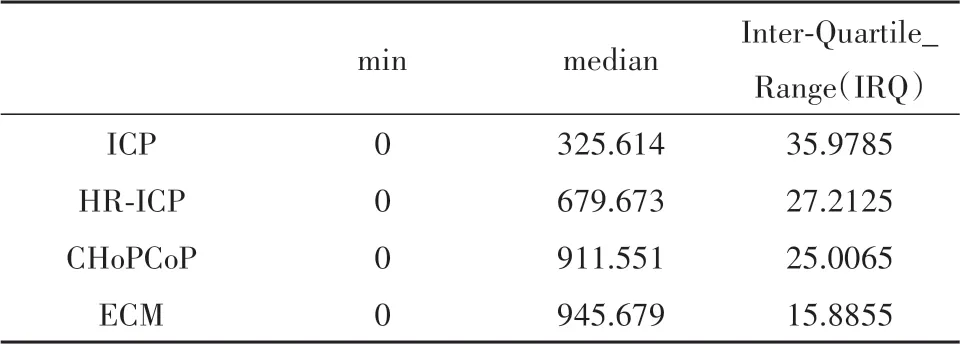
表1 数据接收速率统计Tab.1 Data rate statistics
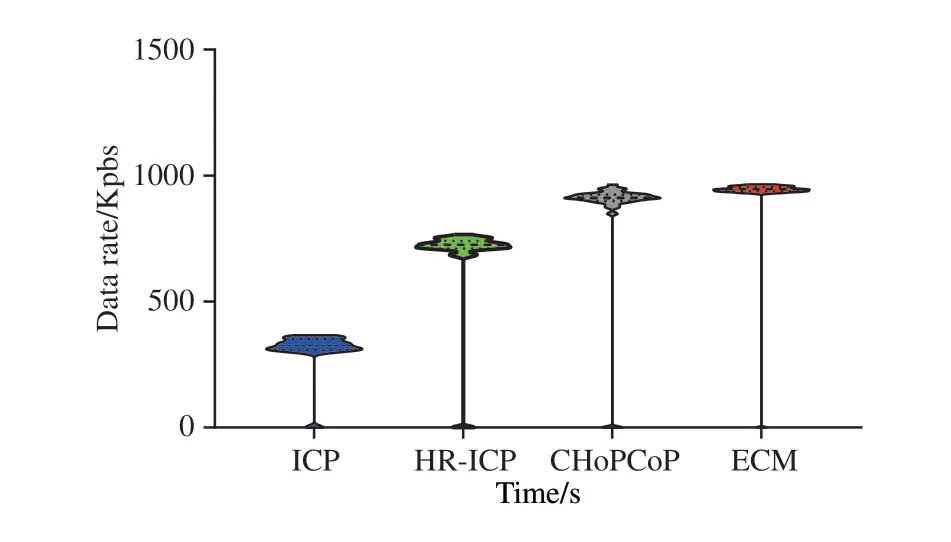
图7 数据接收速率的小提琴图Fig.7 Violin diagram of Data rate
图8是四种方法的平均丢包率随瓶颈链路的变化情况.可以看到ECM 的丢包率是最小的,这是因为ECM 将贪婪流的兴趣包暂时存于队列中而不是直接丢弃,这样不仅可以平滑网络流量,降低上游路由节点的拥塞状况,同时也降低了数据的丢失.ICP的丢包率最高,这是因为ICP是在链路因为丢包造成超时后才能检测到拥塞并进行拥塞控制,从而导致了较高的丢包率,HR-ICP 和CHoPCoP 的性能介于两者之间,这是因为HR-ICP 相比ICP 能够在中间节点更快地检测拥塞,而CHoPCoP 使用了显式拥塞通知机制,能够提前通知消费者潜在的拥塞,从而消费者可以更快地调节兴趣包的发送窗口,避免大部分丢包.
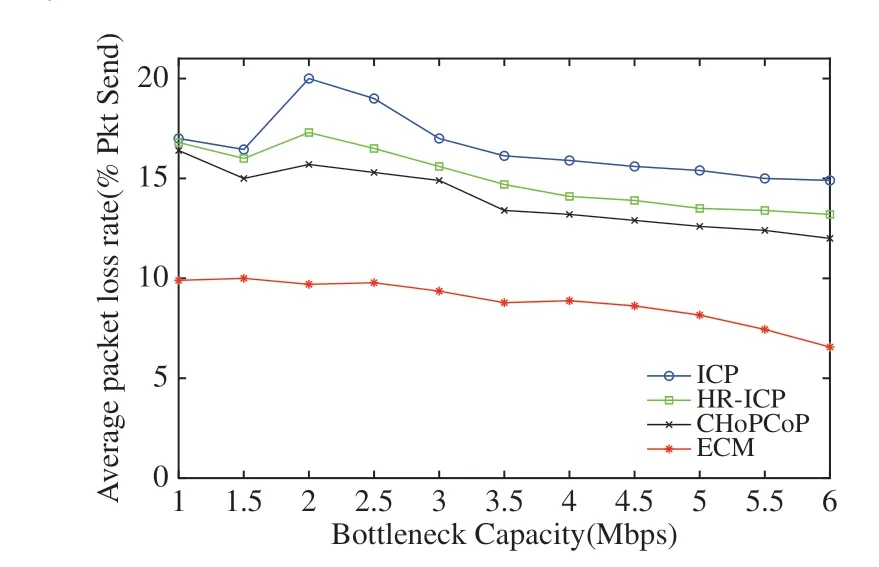
图8 四种方法的平均丢包率Fig.8 Average packet loss rate of four methods
三种优先级数据流的平均丢包率随瓶颈链路带宽的变化结果如图9所示.从中可以观察到,当瓶颈链路带宽相同时,高优先级数据流的平均丢包率低于低优先级数据流,这是因为当链路发生拥塞时,系统会优先给高优先级数据流分配带宽,因此网络中的服务质量也得到了有效的保证.
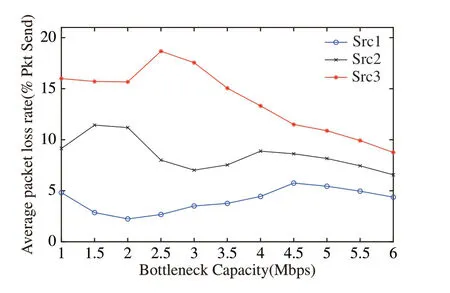
图9 不同优先级数据流的平均丢包率Fig.9 Average packet loss rate of different priority flows
4 结语
本文提出了一种显式拥塞控制方法,消费者可根据网络状态及时调整兴趣包的发送速率,在输出端口通过计数器和整形队列对贪婪流进行限制,同时通过显式拥塞通知机制使得网络能够更快地对拥塞信息作出反应. 仿真结果表明,与ICP 和CHoPCoP 这两种典型的拥塞控制机制相比,ECM 具有更好的网络容量利用率和稳定性以及更低的丢包率.
猜你喜欢
航空学报(2022年7期)2022-09-05
计算机与数字工程(2022年3期)2022-04-07
汽车维修与保养(2020年10期)2021-01-22
计算机与网络(2020年9期)2020-07-29
汽车维修与保养(2020年11期)2020-06-09
电脑知识与技术(2019年22期)2019-10-31
传播力研究(2019年24期)2019-10-21
网络空间安全(2019年10期)2019-03-20
物联网技术(2018年8期)2018-12-06
中国新通信(2016年2期)2016-03-11
