
基于自适应动态规划的非线性系统最优采样控制
2022-03-10 09:35梅俊顾和平
中南民族大学学报(自然科学版) 2022年2期
梅俊,顾和平
(中南民族大学 数学与统计学学院,武汉 430074)
最优控制问题旨在为系统设计一个控制器,以优化系统性能[1-2].通常,线性系统可用Riccati 方程求解[3].对于低维数的非线性系统,有学者提出了动态规划方法[4],将复杂的最优控制问题转化为一个多阶段的决策过程.但当系统状态变量维数增加时,动态规划方法的计算量会呈指数倍增长.于是,为了克服维数增长带来的难题,美国学者WERBOS提出了自适应动态规划(Adaptive Dynamic Programming,ADP),有效解决了复杂非线性系统的最优控制问题.
近年来,已经报道了许多基于ADP 的控制方法[5-7],其基本思想是利用函数近似结构来逼近动态规划方程中的成本函数和控制策略,使之满足Bellman 最优性原理.通常,传统的控制器是对系统进行实时控制的,控制器每时每刻都在更新,因此耗费大量宽带资源[8].为了降低控制器的执行次数,本文引入了采样控制方法[9-10].采样控制只在采样时刻更新控制器[11],并将这一控制信号保持到下一采样时刻,从而减少了控制频率.因此,与传统的控制相比,采样控制在合适的采样周期内可以使得系统信号传输更加高效[12].
目前,针对基于ADP 的非线性系统采样控制的研究鲜有报道,为此,本文将研究基于ADP 的采样控制方面的问题. 首先,根据Hamilton-Jacobi-Bellman(HJB)方 程 和 零 阶 保 持 器(Zero Order Holder,ZOH)的思想得出最优采样控制器;然后,利用评价神经网络(Neural Network,NN)逼近成本函数,并且通过最小二乘法训练得到评价NN 权值;另外,通过Lyapunov 稳定性理论得出系统稳定的充分条件,证明闭环系统一致最终有界(Uniformly Ultimately Bounded,UUB);最后,通过数值仿真的例子验证所提方法的有效性.
符号说明:Rn表示n维列向量,Rn×m表示n×m阶矩阵,‖ · ‖表示向量或矩阵范数,上标T 表示向量或矩阵的转置,N 表示正整数集,∇= ∂∂x表示梯度运算,λmin(·)表示矩阵的最小特征值.
1 问题描述
考虑如下连续时间非线性系统:
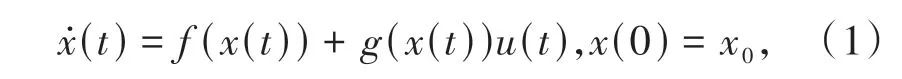
其中,x(t) ∈Rn为系统状态,f(·) ∈Rn和g(·) ∈Rn×m为光滑连续的系统动力学函数,u(t) ∈Rm为控制输入.假设f(0) = 0,f(·)在包含原点的有界闭集Ω ⊆Rn上是Lipschitz连续的.
定义如下成本函数:
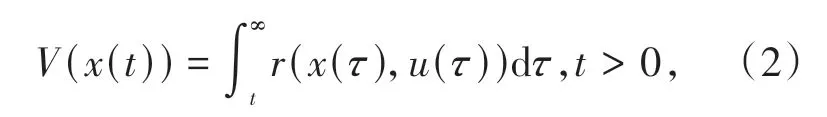
其中,r(x,u) =xTQx+uTRu为效用函数.Q∈Rn×n和R∈Rm×m均为正定矩阵.为简单起见,后续与时间t相关的变量或函数在表示时均省略t.假设V(x) ∈C1(Ω),则其满足如下方程:
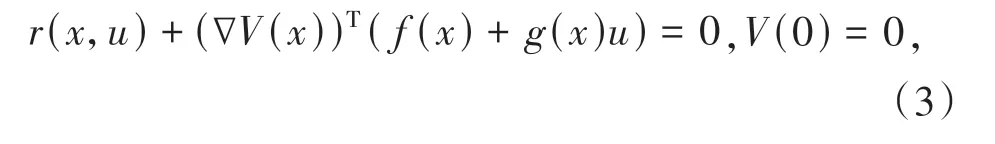
其中,∇V(x) = ∂V(x) ∂x.
定义系统(1)的Hamiltonian如下:
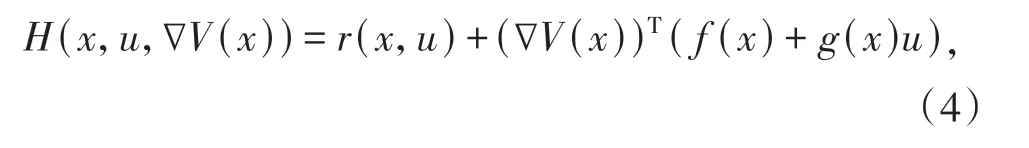
根据Bellman最优性原理可以得到如下HJB方程:
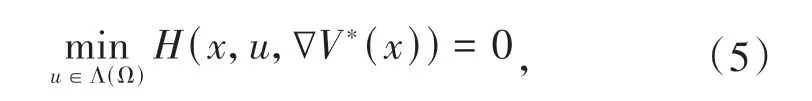
其中,Λ(Ω)为容许控制域,V*(x)为最优成本函数.假设方程(5)左端存在唯一极小值,即:
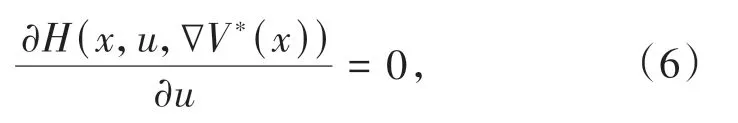
结合(4)~(6)式得到最优控制策略如下:
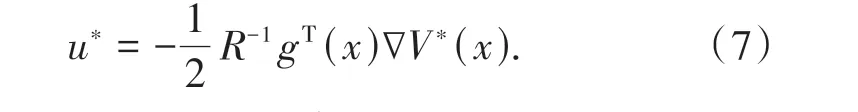
根 据(7)式,可 以 将HJB 方 程(5)写 为:
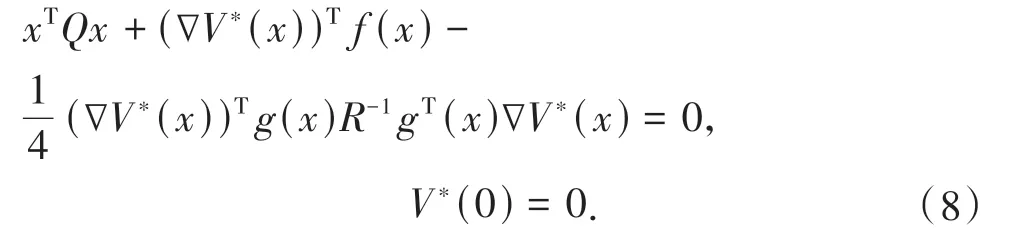
注控制目的旨在从HJB 方程(8)中解出∇V*(x),从而设计一个控制策略u*使得闭环系统(1)渐近稳定,同时将成本函数最小化.
2 采样控制器设计

结合(7)式和(9)式,设计最优采样控制器如下:
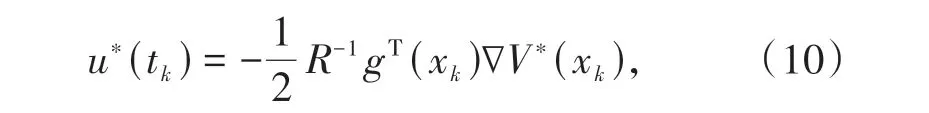
其中,xk=x(tk)为采样系统状态.
根据采样控制思想可以将系统(1)写为:
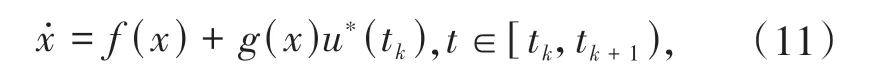
采样控制序列通过ZOH 转换为连续信号并作用在系统上,实现采样控制.由于最优控制u*可分为区间[t,t+T]上的最优控制以及区间[t+T,∞]上的最优控制,根据Bellman 最优性原理,对x(t) ∈Ω 和x(t+T) ∈Ω 可 将最优 成本函 数写为:
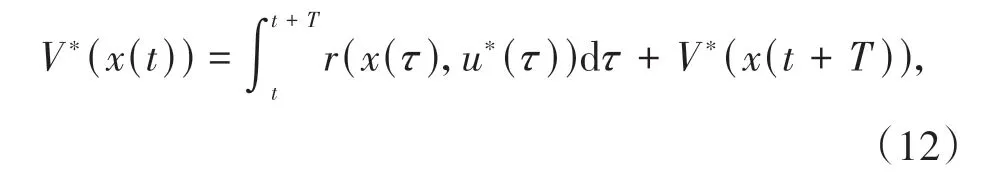
其中,t∈[tk,tk+1),V*(0) = 0.
假设1最优控制u*是局部Lipschitz 连续的,即:
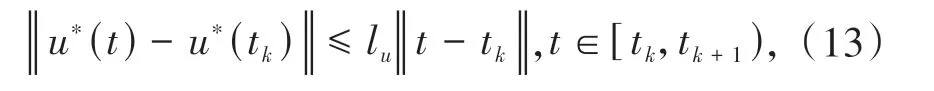
其中,lu为正的Lipschitz常数.
定理1在假设1 下,若成立,则系统(11)在最优采样控制器(10)的作用下渐近稳定.
证明选取Lyapunov函数L1:

当t∈[tk,tk+1)时,将(14)式沿着系统轨迹(11)式求导可得:
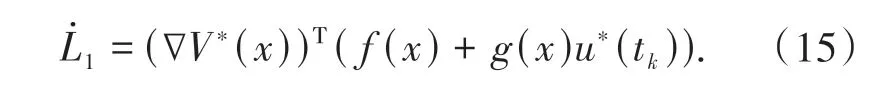
根据(4)式、(5)式和(7)式得:
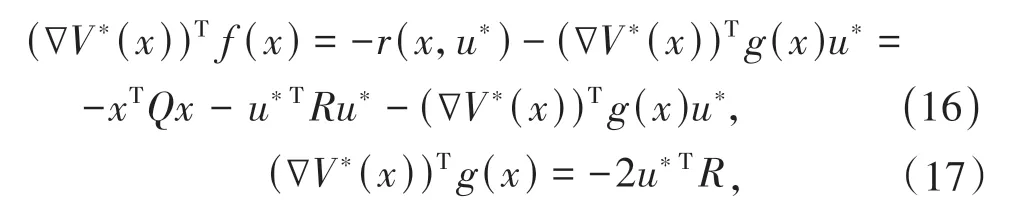
将(16)式、(17)式代入(15)式并结合(13)式可得:
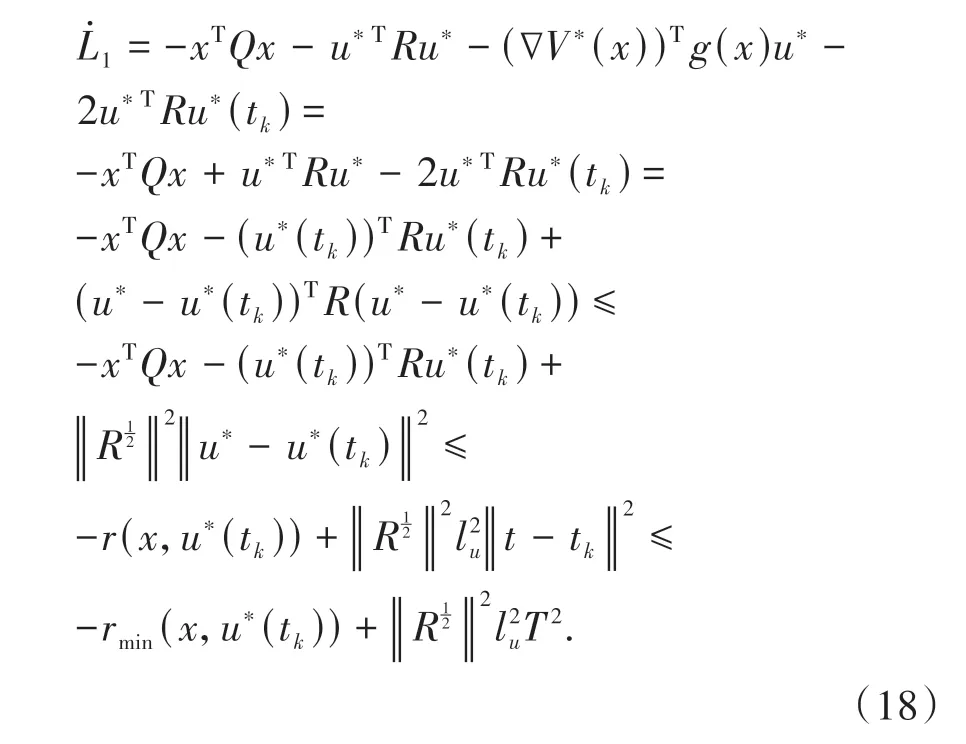
当t=tk+1时,对于连续的系统状态x,有ΔL1=V*(x+)-V*(x) ≤0,因 此 当Tmax时,有(x) <0成立,此时闭环系统(11)是渐近稳定的.其中,rmin(x,u(tk)) >0表示采样控制过程中的最小效用函数.
3 评价NN
由于HJB 方程的非线性特性,导致其直接求解∇V*(x)极其困难,因此本节应用ADP 方法的评价NN 结构逼近V*(x),进而得到∇V*(x).对于x∈Ω,构造评价NN结构如下:
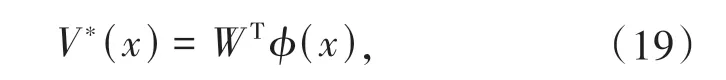
其中,W∈Rq为评价NN 输出层权值,隐含层权值均为1,在训练中不会改变;φ(x) ∈Rq为激活函数,q为隐含层神经元个数.对(19)式求关于x的偏导可得:
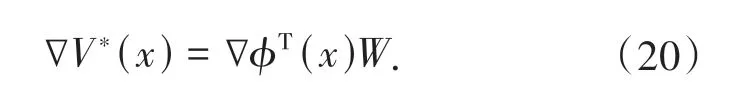
根据(20)式将(7)式和(10)式写为:
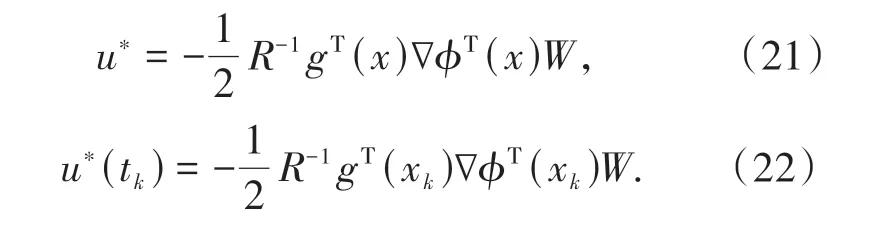
根据(19)式可以将(12)式写为:
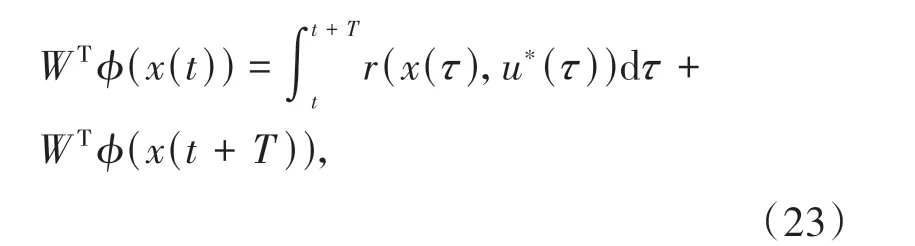
由于最优成本函数被NN 近似代替,故(23)式有残差:
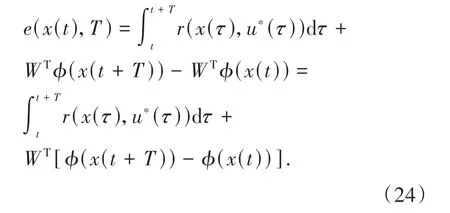
为了得到评价NN 权值自适应更新律,利用最小二乘法最小化目标函数:
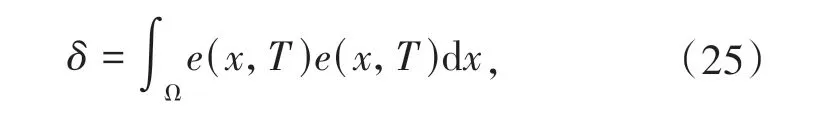
即,利用Lebesgue 积分的内积形式将其写为:
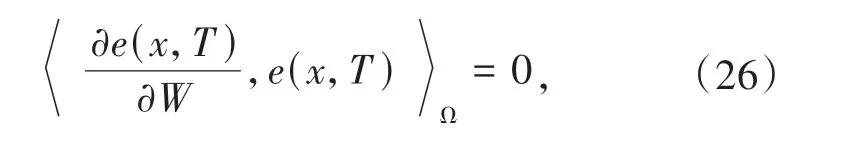
根据(23)式、(24)式可将(26)式写为:
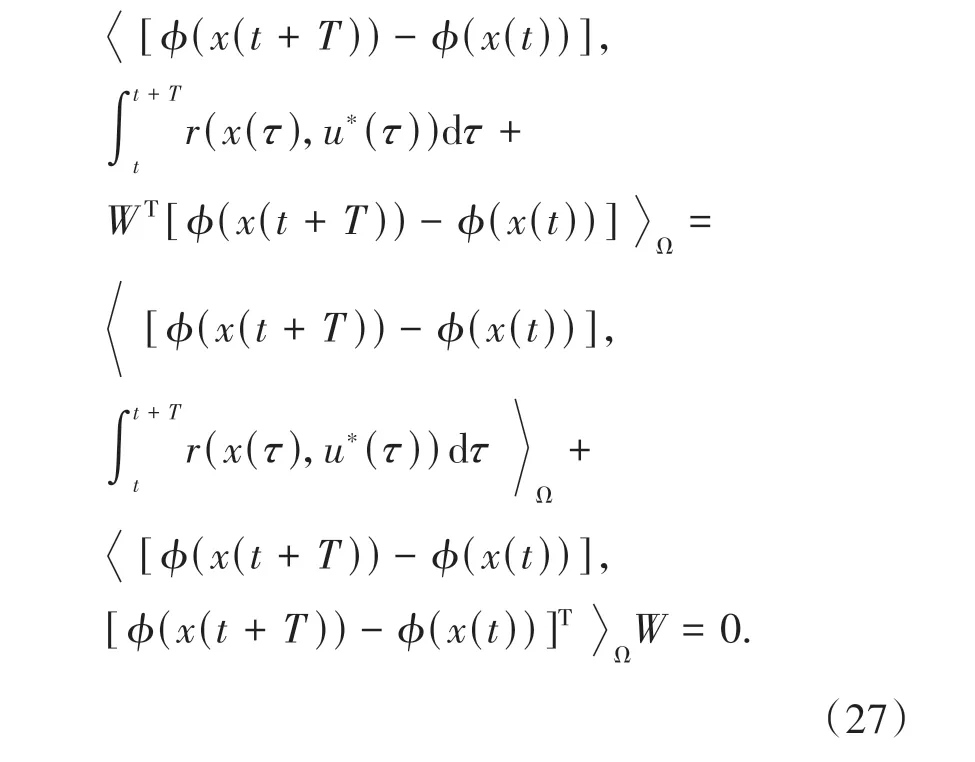
由(27)式可以得到评价NN自适应更新律:
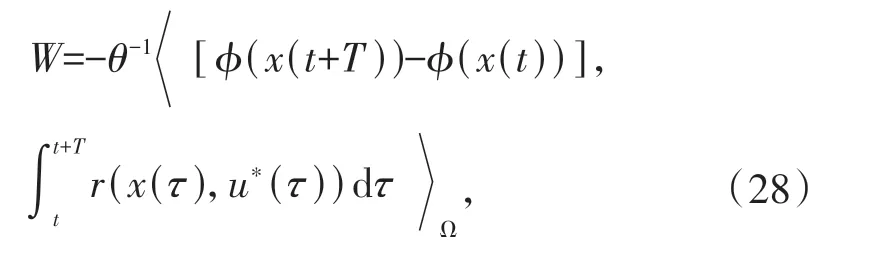
其中:
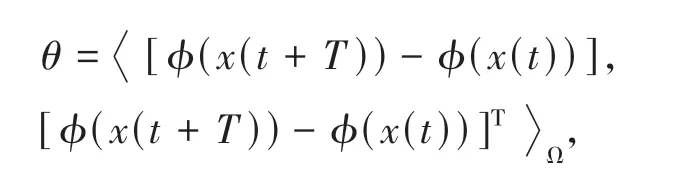
根据文献[13]知θ是可逆的.
4 稳定性分析
假设2设函数g(x)和激活函数的梯度∇φ(x)均有界,即其中bg、bφ均为正常数,x∈Ω为系统状态.
假设3设函数g(x)和激活函数的梯度∇φ(x)均是局部Lipschitz连续的,即:
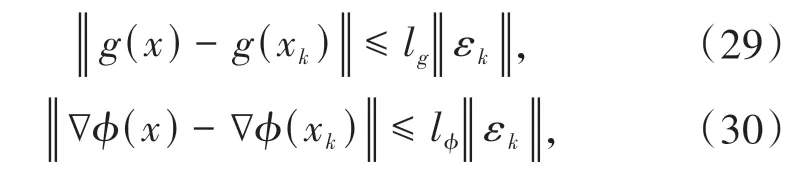
其中lg、lφ均为正的Lipschitz常数,x∈Ω为连续系统状态,xk∈Ω 为采样系统状态,εk=x-xk为采样状态误差.
定理2在假设2、假设3下,评价NN 权值自适应更新律为(28)式,若采样状态误差εk满足:
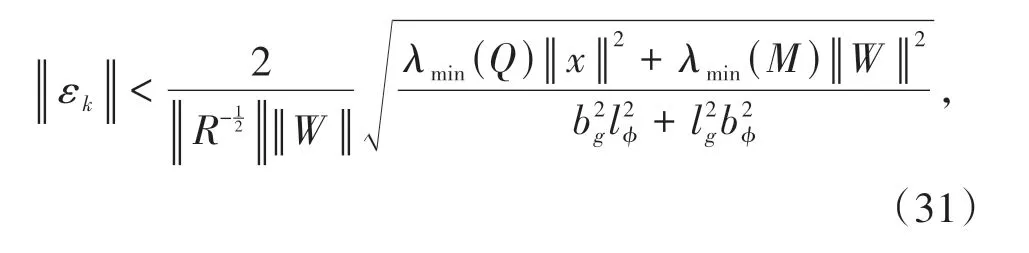
则系统(11)与最优采样控制器(22)形成的闭环为UUB.
证明选取Lyapunov函数L:

其中,L1=V*(x),L2=V*(xk).
情形1:当t∈[tk,tk+1)时,= 0,在最优采样控制u*(tk)的作用下,对L1沿系统轨迹求关于t的导数:
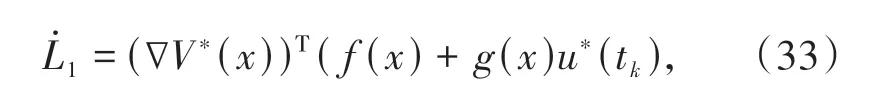
结合(16)式、(17)式,将(33)式写为:
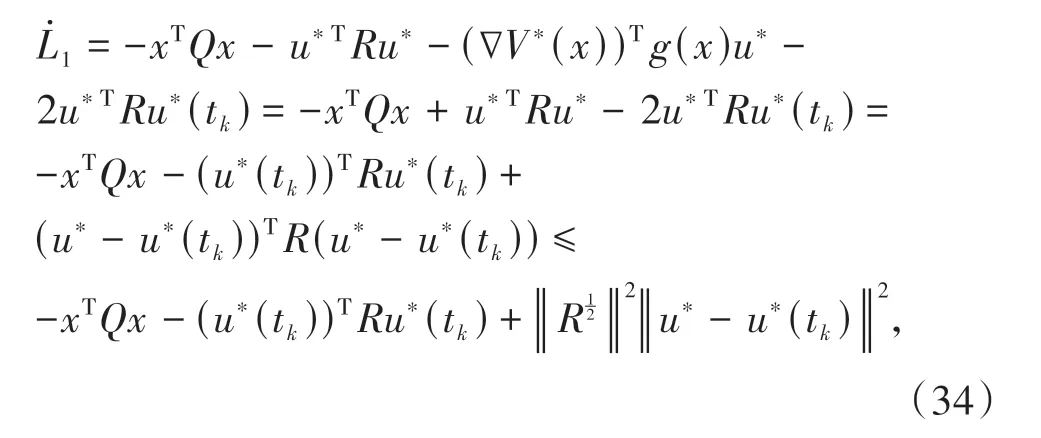
根据(21)式、(22)式有:
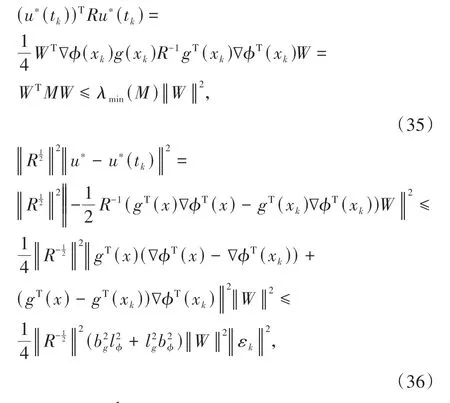
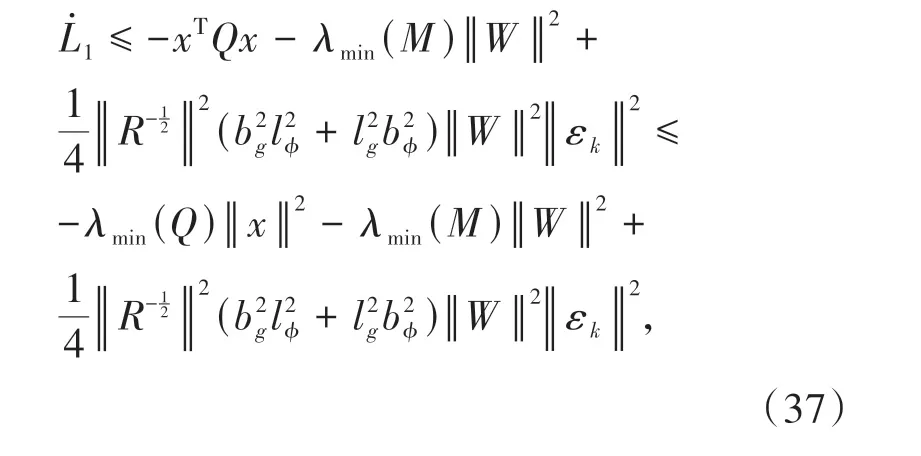
情形2:当t=tk+1时,由(32)式可得:
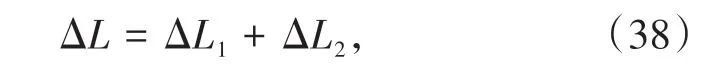
由于系统状态x是连续的,于是有:
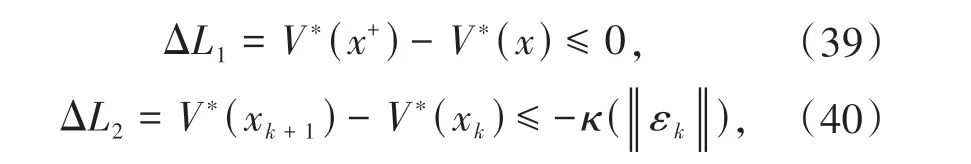
结合(38)~(40)式,可知Lyapunov 函数(32)是递减的,其中κ(·)为κ类函数.
综合以上两种情形,定理得证.
5 仿真分析
考虑如下非线性系统:
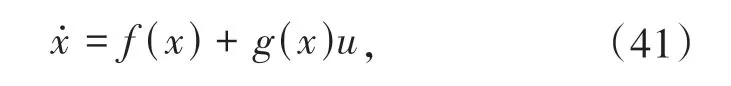
实验中取lu= 1,lg=lφ= 2,bg= 1,bφ= 3,则可验证假设1~假设3成立.从图1可以看出,系统状态x在最优采样控制器的作用下收敛到0.成本函数和最优采样控制输入的变化过程分别在图2 和图3 中展示.在图4中,评价NN权值最终收敛到稳定值,即W=[5 0 10]T.图5 表明:所提的方法优于传统方法(如连续控制),传统方法的控制器需要实时更新,而所提出的采样控制方法减少了控制器的更新频率,因而在实际应用中更节约通信资源.
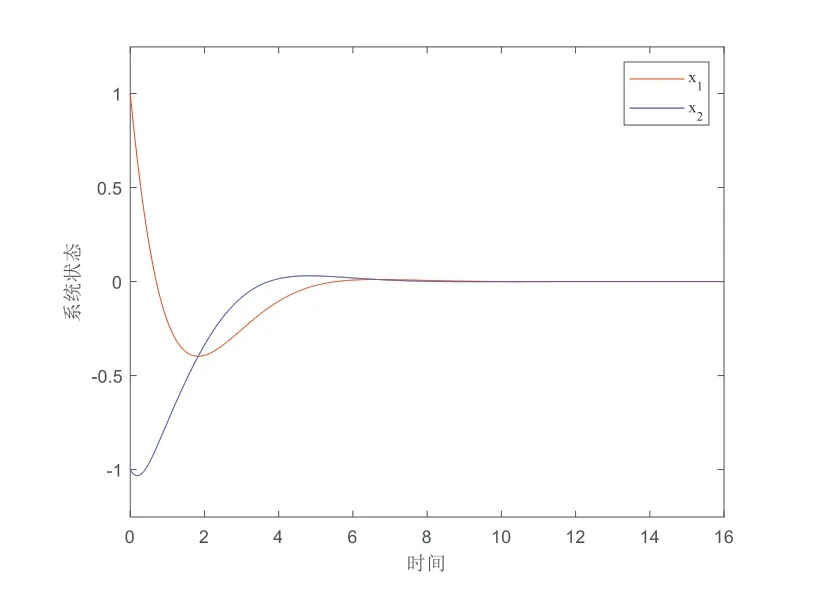
图1 系统状态的收敛过程Fig.1 The convergence process of the system state
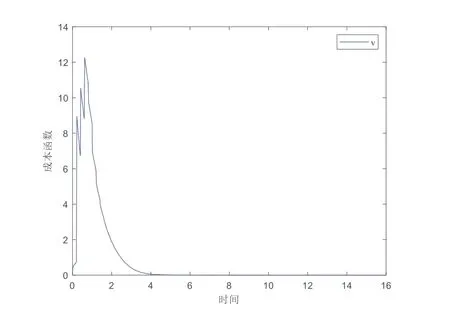
图2 成本函数的变化过程Fig.2 Change process of cost function
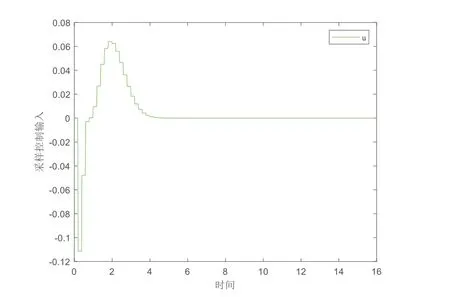
图3 最优采样控制输入的变化过程Fig.3 Change process of optimal sampling control input
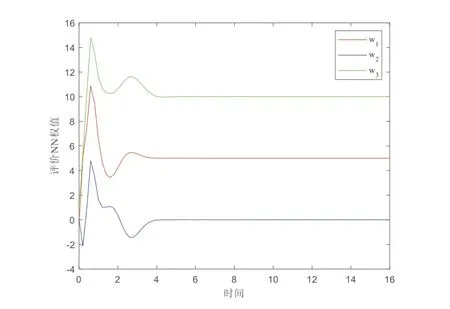
图4 评价NN权值的变化过程Fig.4 Change process of critic NN weights
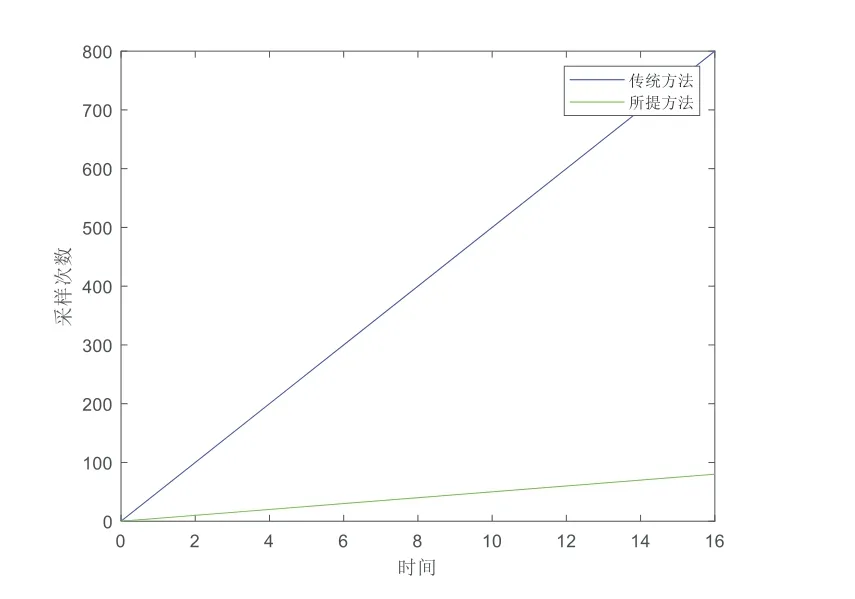
图5 采样次数对比Fig.5 Comparison of sampling times
6 结语
本文运用ADP 方法研究了非线性系统的最优采样控制.通过仿真发现:所提方法有效降低了控制器的执行次数,同时保证了系统的稳定性.首先,在原有的控制器上结合ZOH 设计采样控制器;其次,在自适应控制过程中利用评价NN 逼近未知的最优成本函数,并运用最小二乘法训练评价NN 权值;最后,通过一个非线性系统仿真验证了所提方法的正确性和有效性.在接下来的研究中,有望将基于ADP 的采样控制方法扩展到未知动力学的非线性系统中.
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
中国自行车(2022年3期)2022-06-30
领导文萃(2019年8期)2019-04-19
网络空间安全(2019年8期)2019-03-18
读友·少年文学(清雅版)(2018年12期)2018-04-04
科技视界(2016年1期)2016-03-30
物联网技术(2015年7期)2015-07-21
中学生数理化·八年级物理人教版(2014年2期)2014-04-02
科技传播(2012年10期)2012-06-06
