
基于评论文本的自适应特征提取推荐研究
2022-03-07 06:57胡海星王宜贵袁卫华张志军秦倩倩
软件导刊 2022年2期
胡海星,王宜贵,袁卫华,张志军,秦倩倩
(山东建筑大学计算机科学与技术学院,山东济南 250101)
0 引言
互联网的迅速发展,为用户提供了更便利的购物方式,同也为用户带来选择困扰,如何在众多信息中发现感兴趣的商品,成为电商平台亟待解决的问题。在该情况下,推荐系统发挥着越来越重要的作用,其可根据用户历史行为和偏好推荐当前用户可能感兴趣的商品,为用户提供个性化推荐服务。
传统推荐算法中,主流的协同过滤(Collaborative Filtering,CF)算法通过学习用户和商品的显式或隐式交互为用户推荐商品。其中,矩阵分解技术(Matrix Factorization,MF)较为常用,该技术将用户和商品映射成两个低秩矩阵,通过内积方式获取预测评分。PMF概率矩阵分解模型则利用矩阵分解思想结合高斯概率函数优化预测与实际评分的差值。尽管矩阵分解技术在推荐系统中能取得良好的性能,但该技术缺乏高阶特征交互学习能力,无法学习用户复杂的评分行为。
相比评分数据,评论文本包含了更丰富的语义信息,可反映用户偏好,并且能对推荐结果提供合理性解释。此外,评论文本通常还包含了商品特征信息。基于TF-IDF(Term Frequency-Inverse Document Frequency)推荐算法利用用户评论中的词频信息表示用户偏好进行推荐,但无法挖掘用户评论的语义信息。基于主题模型的推荐算法通常采用词袋模型,虽然考虑了用户的评论语义,利用评论提取潜在特征,但算法结合上下文学习用户评论语义信息的能力不足,无法有效提升推荐性能。
近年来,深度学习已经成功应用于计算机视觉、自然语言处理等领域,在基于评论文本的推荐系统中也取得了很好的效果。ConvMF 模型利用卷积神经网络(Convolutional Neural Network,CNN)从商品评论中提取特征,结合概率矩阵分解和用户评分数据获得预测评分,但未能考虑用户评论特征的重要性。DeepCoNN构建并行神经网络,联合建模用户和商品的评论特征用于推荐。D-ATTN模型和NARRE 模型加入了注意力机制,用于捕捉评论中的重要特征,并利用矩阵分解方法获取预测评分。DAML 模型在捕获用户和商品特征后,使用神经因子分解机进行特征交互。HAUP 模型使用基于双向门控循环单元网络(Bidirectional Gated Recurrent Units,Bi-GRU)的神经网络以处理评论的长期依赖,挖掘评论中单词和句子的信息,联合建模用户和商品特征,取得了较好的推荐性能。然而,以上方法也存在以下问题:
(1)大部分研究通常采用静态编码词向量表示文本特征嵌入,然而在实际中同一单词在不同上下文环境中表达的意义不一致,无法表达单词的多义性,导致模型对语义理解存在偏差。例如ConvMF、DeepCoNN、D-attn、NARRE、DAML等均使用word2vec或Glove等静态编码词向量对词向量进行预训练,使每个单词的嵌入表达与所处的上下文语境无关,因此会造成语义理解偏差,影响模型性能。
(2)在获取用户和商品特征后,将其进行并行拼接后直接进行评分预测,忽略了用户和商品特征在交互时不同推荐结果的贡献程度。例如DeepCoNN、DAML、Dattn、NARRE等进行特征并行拼接后通过矩阵分解或因子分解机(Factorization machine,FM)方法获取预测评分,忽略了二者对推荐结果的不同贡献。
通过上述分析,本文提出了基于评论文本的自适应特征提取推荐(Adaptive Feature Extraction Recommendation,AFER)模型,该模型利用动态词向量预训练模型BERT以解决静态词向量无法适应一词多意的问题,采用Bi-GRU 网络提取用户和商品评论的全局特征,加入注意力机制突出文本中的重要信息,抑制噪声信息。在此基础上,将用户和商品评论通过门控层(Gating Layer)进行自适应特征拼接,自适应平衡用户和商品特征的重要程度,增强其相关性。最后,利用因子分解机进行特征交互获得预测评分。实验表明,本文模型整体优于基准模型。
本文工作主要贡献如下:①基于AFER 模型使用预训练模型BERT 获取评论嵌入,以解决一词多意问题,提高评论特征表示能力,使用Bi-GRU 神经网络提取用户和商品评论特征,使用注意力机制抑制噪声数据,提高特征表达能力;②针对特征并行拼接策略未考虑用户和商品特征在交互时对推荐结果贡献程度的问题,提出AFER 模型自适应特征拼接策略,以捕捉用户和商品之间的细微差别以平衡二者重要程度。通过自适应拼接特征,增强二者交互的相关性,提高预测评分精度;③在6个Amazon 数据集上的实验表明,AFER 模型优于基准模型。
1 相关工作
1.1 基于主题模型的推荐方法
该方法常基于评论文本提取特征信息以提高评分预测 性能。HFT和CTR利用LDA(Latent Dirichlet Allocation)挖掘评论文本的潜在主题,通过矩阵分解得到预测评分。TopicMF通过非负矩阵分解(NMF)得到评论文本的潜在主题,并将该主题分布映射到矩阵分解后的用户和商品潜在因子。此外,该模型通过调整变换函数以应对潜在因素的不同重要程度。RBLT线性结合评分矩阵的潜在因素和评论文本的潜在主题表示用户和商品的特征,获得预测评分。RMR采用高斯混合模型对评论文本进行主题建模学习。上述模型在处理评论文本时,均基于词袋模型捕获评论的词频信息,无法保持词序信息,忽略了评论中丰富的上下文信息。此外,该方法仅学习评论的浅层线性特征,未能充分提取其非线性特征。
1.2 基于评论文本的深度学习推荐方法
随着深度学习在推荐领域的发展,基于评论文本与深度学习的推荐方法被广泛应用。ConvMF利用卷积神经网络和静态词向量嵌入提高推荐性能,但该模型仅考虑商品评论信息,忽略了用户评论信息的重要性。Deep-CoNN提出双塔结构模型,利用两个平行卷积神经网络分别对用户和商品评论信息进行特征提取,通过因子分解机捕捉用户和商品特征间的交互信息。但DeepCoNN 缺少对评论文本细粒度的特征交互。TransNets扩展了Deep-CoNN,引入额外的隐藏层将用户和商品的潜在特征转换为用户对商品的评论,而在测试时生成相应的评论进行预测评分。NGMM受到DeepCoNN 启发,使用混合高斯层替代因子分解机模拟用户对商品评分。
近年来,注意力机制被广泛应用以提升推荐性能。其通过模拟人脑处理信息方式,在面对大量信息时聚焦重要信息。D-attn在DeepCoNN 基础上引入局部和全局注意力以捕获评论文本的重要信息。NARRE加入注意力机制对每个评论进行评分,但仅通过矩阵分解方式预测评分,未能在交互层面上捕捉二者的相关性。MPCN加入协同注意力机制,在句子和单词级上选择最具代表性的评论信息以表示用户偏好和商品属性。HAUP利用注意力机制根据单词重要性识别重要的评论信息以捕获特征。DAML引入交互注意力机制以捕捉用户和商品评论的相关性,但未考虑句子级的细粒度信息和用户偏好。此外,在神经网络中,Bi-GRU 不仅能从前向传播获取信息,还能利用反向信息,获取更多重要特征,相比单向门控循环单元(Gated Recurrent Units,GRU)网络提取的文本特征更全面。
1.3 预训练模型
在自然语言处理任务中使用单词嵌入方法表达文本向量已被证明效果较好,例如词性标记、语法分析、机器翻译等。但该方法属于静态词向量,其词嵌入表达不会随上下文发生改变,存在一词多意问题。因此引入动态词向量解决该问题。2018 年Google 提出动态词向量预训练模型BERT在11 项自然语言处理任务中取得了出色的效果。BERT 是一种基于Transformer 双向编码器使用掩码语言模型和下一句子预测的双任务训练模型,可充分描述词、句子级及句间关系特征。在基于评论文本推荐中,DeepCLFM、SIFN和U-BERT均使用预训练模型BERT 得到评论嵌入表达,与使用静态词向量模型相比,预测性能提升较大。
本文提出的AFER 模型首先使用动态词向量技术BERT 解决了静态词向量单词的多义性问题,得到与评论文上下文相关的评论文本嵌入;其次针对特征并行拼接策略无法平衡用户和商品特征在交互时,推荐结果贡献程度问题,引入自适应特征拼接机制,动态平衡二者的重要程度;最后通过因子分解机进行特征交互,以获得更精确的预测评分。
2 模型介绍
2.1 问题描述
给定样本数据集合D,每个样本用一个四元组表示(u
,i
,r
,w
),其中u
表示用户,i
表示商品,r
表示用户u
对商品i
在1~5 整数范围内的评分,w
表示用户u
对商品i
的评论。d
表示用户u
对商品评论的集合,d
表示商品i
接收用户评论的集合。本文模型通过词嵌入技术得到评论文本d
和d
的词向量,利用深度学习技术从评论词向量中提取用户和商品特征,预测用户u
对商品i
的评分,最终达到为用户提供个性化推荐服务目的。本文所用符号及含义由表1 可见。2.2 模型结构


Table 1 Symbol description表1 符号说明

Fig.1 Architecture of AFER model图1 AFER 模型结构
2.2.1 与上下文相关的评论嵌入
嵌入层:读取数据集中的评论文本,构建用户评论集d
={w
,w
,w
,…w
}和商品评论集d
={w
,w
,w
,…w
}。其中,m
,n
表示集合中评论的数量,w
,a
∈[1,m
]表示用户对商品的一条评论,w
,b
∈[1,n
]表示商品接收的一条评论。当用户∕商品评论个数少于m∕n 时,使用c
维零向量补充,反之则截取前m∕n 条评论。预训练模型BERT 采用双向Transformer 模型,结合自注意力机制在大规模语料库预训练基础上,根据当前任务语料库进行微调,得到适合当前任务的词嵌入表示。用户评论集d
作为BERT 的输入,输出向量表示为O
,商品评论集d
对应的输出为O
。O
,O
表示如式(1)-式(2)所示。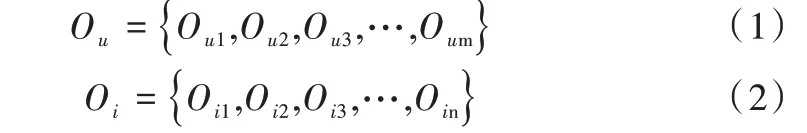
O
∈R
,O
∈R
,c
为BERT 基础版的词向量维度768。2.2.2 基于注意力机制的双向特征提取
Bi-GRU 层:单向GRU 从前向后单向传播,容易丢失重要信息,无法充分使用评论文本特征向量。本文基于评论文本嵌入表达,使用Bi-GRU 分别从前向和后向分别对O
,O
进行深层特征提取。
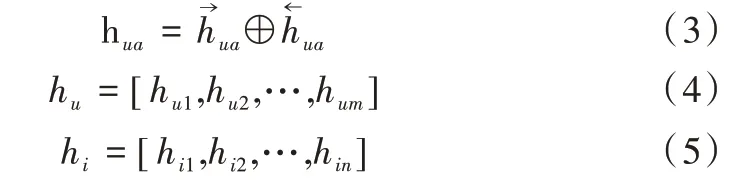
l
为GRU 网络的隐藏单元数量。此外,在GRU 网络中采用Dropout 技术防止过拟合问题。注意力层:将h
和h
输入全连接层前,AFER 模型利用注意力机制抑制Bi-GRU 网络产生的特征冗余。通过注意力机制获取用户和商品评论的注意力得分a
∈R
,a
∈R
,如式(6)-式(7)所示。利用注意力得分对每条评论进行加权求和,得到用户评论集特征
doc
∈R
,如式(8)所示。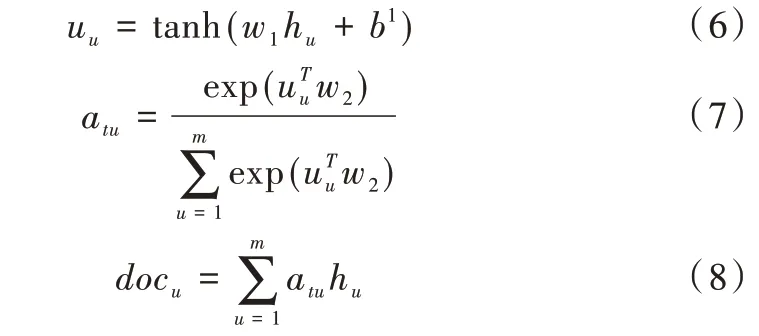
doc
∈R
,如式(9)-式(11)所示。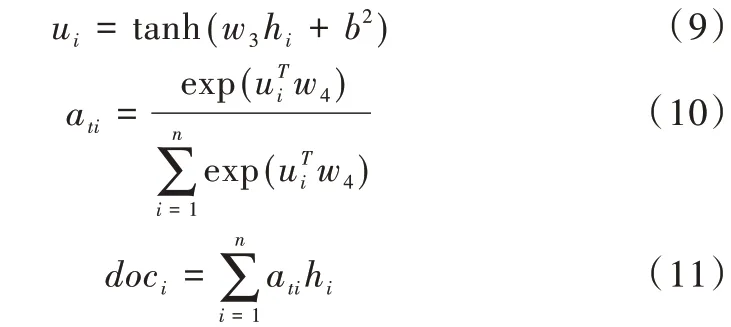
w
,w
∈R
,w
,w
∈R
均为随机初始化并可训练的参数,t
表示可设置的注意力机制向量维度,m
和n
为用户和商品的评论数量,h
,h
表示从用户和商品评论中提取的特征向量,b
,b
为偏置项。全连接层:将用户特征doc
和商品特征doc
表示送入全连接层进行整合,用户和商品特征维度为k
,用户u
偏好和商品i
属性的最终特征表示为fea
,fea
∈R
,如式(12)-式(13)所示。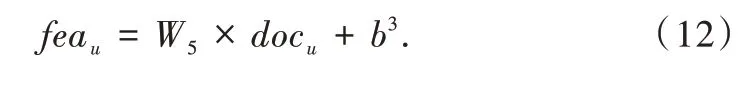
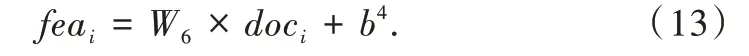
W
、W
∈R
为全连接层的权重参数,
k
表示特征中可设置的隐因子数量,doc
和doc
表示用户和商品的评论特征,b
、b
为全连接层的偏置项。2.2.3 自适应特征拼接
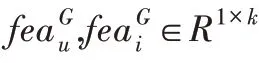
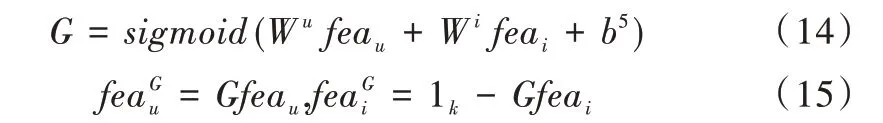
W
,W
∈R
为权重向量,因为G 的范围为[0,1],因此采用sigmoid
激活函数,b
为偏置项。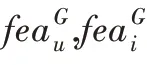
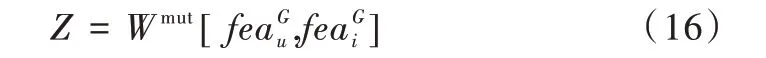
W
∈R
表示在特征拼接过程中随机初始化的权重矩阵,Z
表示经过自适应特征拼接后的自适应特征。2.2.4 评分预测
输出层:将自适应特征Z
送入因子分解机得到用户和商品的特征交互y
,如式(17)所示。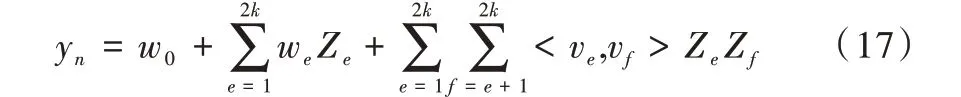
w
∈R
表示变量,w
∈R
为因子分解机一次项的权重,<v
,v
>为向量的内积,表示捕获二阶项交互的权重。
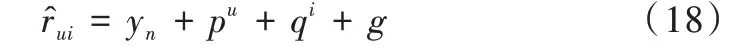
2.3 模型优化
本模型目标为用户对商品的预测评分,常用的损失函数为平方损失,即AFER模型的Loss损失函数如式(19)所示。
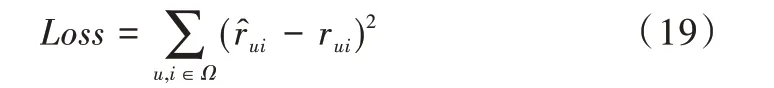
为了优化目标函数,本文选择自适应矩估计(Adam)优化模型,比传统的SGD 收敛更快。此外,本文在AFER中设置Dropout 以防止发生过拟合现象。
3 实验分析与比较
3.1 数据集与评价指标
3.1.1 数据集
为了验证AFER 模型的有效性,本文在6个亚马逊公开评论数据集中进行实验,数据集来自Amazon5-core:Baby,Grocery_and_Gourmet_Food,Instant_Video,Office_Product,Musical_Instruments,Automotive(简称为Baby、GandGF、IV、OP、MI、Auto)。在数据集中,仅使用每个样本的4个特征:用户ID、商品ID、用户对商品的评分(1~5 的整数)及用户对商品的评论文本,统计数据如表2 所示。
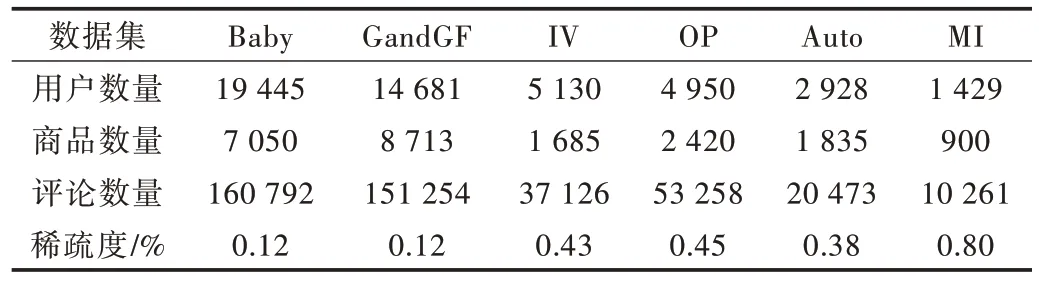
Table 2 Data set表2 数据集
3.1.2 评价指标
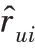
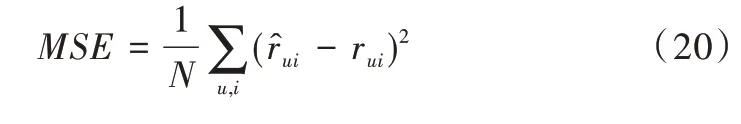
3.2 基准模型
为了评估AFER 模型性能,本文将其与以下6个基准模型进行比较。
(1)PMF。概率矩阵分解引入高斯分布利用评分数据学习用户和商品的特征。本文模型从评论信息和深度学习的优势与其进行比较。
(2)ConvMF。商品评论经过静态词嵌入后,使用CNN 学习商品评论特征,然后将商品特征和用户评分相结合,利用概率矩阵分解进行评分预测。本文模型从用户和商品联合建模的角度与其进行比较。
(3)DeepCoNN。深度协同神经网络,基于两个并行CNN 分别从用户和商品的静态评论嵌入中学习各自的特征,并行拼接后利用因子分解机进行交互获得预测评分。本文模型从动态评论嵌入、注意力机制及特征交互前的处理方面进行对比。
(4)D-attn。双注意力模型,利用全局和局部双重注意力机制以增强用户和商品特征的可解释性,利用矩阵分解预测评分。本文模型从词嵌入和特征交互过程上与其进行对比。
(5)NARRE。神经注意力回归模型,利用卷积神经网络和注意力机制学习用户和商品特征,利用LFM 实现评分预测。本文模型从动态评论嵌入和特征交互角度与其比较。
(6)DAML。双注意力交互学习模型,从评分数据和评论文本中学习用户和商品特征,通过神经因子分解机实现特征间的交互。本文模型在输入信息、评论嵌入、交互前的特征处理等方面与该模型进行对比。
3.3 实验设置
本文将每个评论数据集按照8∶1∶1 的比例随机分为训练集、验证集和测试集。本文参数设置如下:
(1)PFM 模型中,使用高斯函数初始化用户和商品的潜在特征。
(2)深度学习模型中,学习率设置为0.002,Dropout 设置为0.5,由于显存限制,DAML 模型Batch Size 设置为16,其余深度学习模型Batch Size 均设置为128;在NARRE 模型和DAML 模型中ID 嵌入维度为32;在注意力机制模型中注意力权重向量维度为100;在卷积神经网络的文本处理模型中,卷积核大小设置为3,个数设置为100;以上预训练的静态词向量模型为GoogleNews-vectors-negative300.bin,嵌入维度为300。
(3)预训练模型BERT 版本为uncased_L-12_H-768_A-12,隐因子数量设置为32,Dropout 设置为0.5,Bi-GRU网络中使用隐藏单元个数为100,注意力层向量维度为50。此外,使用的Tensorflow 库在Python3 上实现。
3.4 性能评估
如表3 结果对比所示,仅利用评分数据的PMF 模型预测效果低于其他使用评论数据模型。在使用评论数据模型中,DeepCoNN 模型的效果优于仅建模商品特征的ConvMF 模型,因为DeepCoNN 模型在考虑用户和商品评论重要性的同时,建模用户和商品特征。D-attn 模型引入注意力机制对比DeepCoNN 模型在效果上有所提升。NARRE模型为了提升评论的有效性,提出句子级注意力机制以评估每个评论。该模型在整体效果上有所提升,但数据集较小会导致模型性能变差。DAML 模型使用交互注意力机制以提高用户和项目特征的相关性,利用神经因子分解机进行特征交互,增强特征交互能力。通过对比实验,DAML 模型在中等数据集上的效果整体优于其他模型。
本文模型性能在各数据集上均有提升,其中在MI 数据集中效果最好,提升了5.80%;Baby 数据集则最差,仅提升了0.96%。AFER 模型通过引入动态词向量解决了一词多意问题,并且提出自适应特征交互机制,以平衡用户和商品特征间各自的重要程度,弥补用户和商品特征并行拼接的不足,提升了模型预测评分精度。

Table 3 Comparison of MSE results表3 MSE 结果对比
3.5 参数分析
本文在Baby,GandGF、IV、OP、Auto、MI 共6个数据集上分析了隐因子数量、GRU 隐藏单元数量及注意力权重向量维度对推荐性能的影响。
图2 展示了在[16,32,64,128,256]范围内,全连接层不同的隐因子数量对AFER 模型性能的影响,随着隐因子数量增多,模型性能逐渐变差。因为隐因子数量增多会引入更多训练参数,过拟合风险增大,导致模型性能下降。由图2 可见,当隐因子数量设置为32 时效果最好,因此本文在实验中将隐因子数量设置为32。
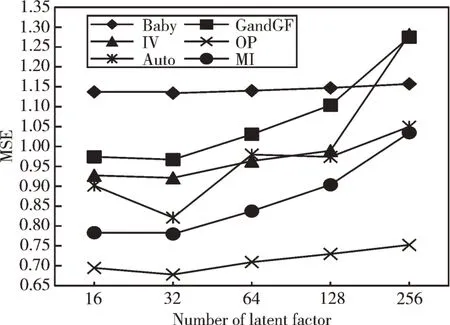
Fig.2 The impact of latent factor number on model performance图2 隐因子数量对模型性能的影响
GRU 隐藏单元数量是GRU 神经网络输出的隐藏层大小,表示从评论中提取特征的长度。本文从[50,100,150,200,250]范围内搜索GRU 隐藏单元数量对AFER 模型的影响。从图3 中可见,随着隐藏单元数量增多,AFER 模型在MSE 上没有呈现线性提升,在50~100 间,整体呈下降趋势,而在100~250 区间,结果逐渐变差。说明隐藏单元数量在某个阈值时可达到最优效果,反之则会增加预测误差。综合6个数据集上的表现,本文选取GRU 隐藏单元的大小为100。
本文将注意力向量维度限定在[10,30,50,70,90]范围,观察其对AFER 模型性能的影响。由图4 可见,当值超过50 后,模型性能逐渐变差。因此,在本文将注意力权重向量维度设置为50。
3.6 消融实验
本文使用以下3个变体与AFER 模型进行比较,分析每个组件在模型中的重要程度。
(1)AFER-word2vec。预训练阶段采用静态词向量word2vec 替代BERT 以进行文本嵌入表达。
(2)AFER-noAtte。不使用注意力机制的AFER 模型。
(3)AFER-noAdaptive。不使用自适应拼接机制的进行特征拼接AFER 模型。
Fig.3 The impact of GRU hidden unit number on model performance图3 GRU 隐藏单元数量对模型性能的影响
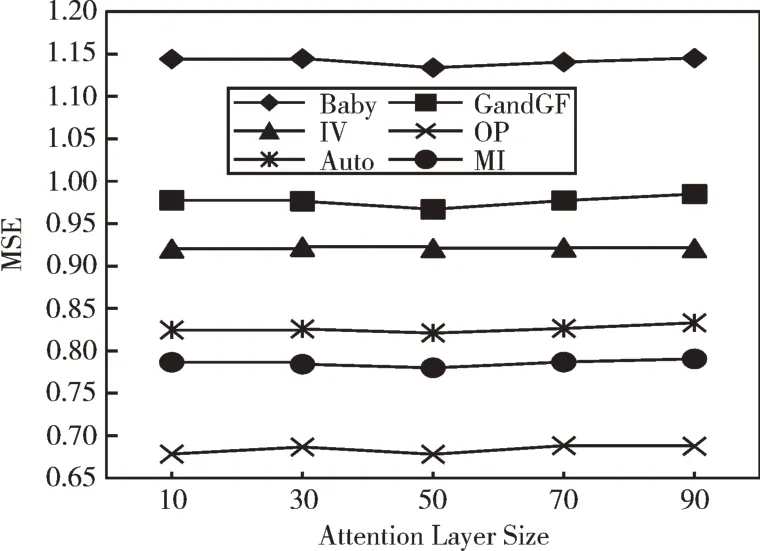
Fig.4 The impact of attention vector dimension on model performance图4 注意力向量维度对模型性能的影响
AFER 模型和三个变体模型结果对比如图5 所示。由图5 可见,AFER-word2vec 由于使用了静态词向量word2vec,其语义理解上的偏差导致了其性能最差。因此,动态词向量BERT 能提高对评论的语义理解能力,通过获取与上下文相关的评论嵌入表达可有效提高模型的推荐性能。在AFER 模型中,注意力机制用于突出评论的重要信息,抑制噪声信息。AFER-noAtte 模型性能低于AFER模型,证明了注意力机制的有效性。AFER 和AFER-noAdaptive 的结果对比展示了自适应机制的有效性,结果表明简单的特征拼接策略会忽略用户和商品特征之间差异,而基于门控层的自适应特征拼接可弥补其不足,增强二者间的相关性,提升模型性能。
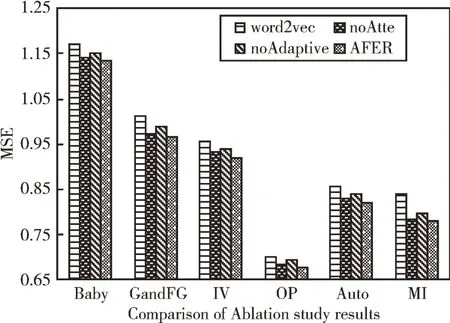
Fig.5 Comparison of ablation study results图5 消融实验结果对照
4 总结与展望
本文基于评论文本提出了AFER 模型,利用预训练模型BERT 得到适合当前任务与上下文相关的动态词嵌入表示,解决词向量静态编码方法带来的语义偏差问题;其次在考虑交互前特征拼接策略和用户商品间存在的不平衡性,设计了一种自适应特征拼接机制,平衡用户和商品各自的重要程度,增强二者相关性;最后在6个公开数据集上的实验结果表明,本文提出的模型可有效降低评分预测误差。未来将关注用户对商品的评论时间及评论的时间跨度,考虑用户在短期发生的兴趣偏移对推荐性能的影响。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
传媒评论(2017年3期)2017-06-13
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
中国卫生(2015年9期)2015-11-10
中国卫生(2014年3期)2014-11-12
中国火炬(2014年4期)2014-07-24
