
基于卷积神经网络的苗语孤立词语音识别
2022-03-07 06:57张学文冯夫健李学林
软件导刊 2022年2期
张学文,王 林,冯夫健,谭 棉,李学林
(1.贵州民族大学数据科学与信息工程学院;2.贵州省模式识别与智能系统重点实验室,贵州贵阳 550025)
0 引言
语音识别技术在汉语、英语和一些常用少数民族语言(藏语、蒙语、维尔吾语)中已有一定研究基础,但关于低资源、无文字的少数民族语言(苗语、普米语、佤语、白语)的语音识别研究成果较少。在历史上,苗语只有语言,没有通用文字,其语言和文化仅通过口授相传,相关文字资料留存有限,且受其他常用语言的影响,使用苗语交流的人越来越少,导致苗族的语言文化正逐渐走向消亡。为了更好地传承和保护苗族语言文化,苗语语音语料库的构建和语音识别逐渐成为相关学者的研究重点。
1 相关研究
早期语音识别方法主要基于动态时间规整算法(Dynamic Time Warping,DTW)和隐马尔可夫模型(Hidden Markov Model,HMM)实现。例如,徐利军采用DTW算法和放宽起始点的DTW算法对孤立词语音识别进行研究,发现相较于原始DTW算法,放宽起始点的DTW算法能有效降低噪声干扰,但语音识别率改善不明显;易雪蓉等利用HMM 模型对声调语音模型进行研究,通过改造语音模型和语言模型提高近音字和同音字的识别率,但对轻声和四声词识别效果不理想。
传统模型在小词汇识别方面取得了良好效果,但针对大量词汇、非特定人语音的识别效果有待提升。近年来,深度学习技术在语音识别方面受到广大研究者的青睐。例如,Sundermeyer等将前馈神经网络(Feed Forward Deep Neural Network,FDNN)和递归神经网络(Recursive Neural Network,RNN)引入声学模型中,在法语语音识别任务中,RNN 的效果优于FDNN,但需进一步改进最佳列表的解码;Naing 等以深度神经网络—隐马尔科夫混合模型(DNN-HMM)为网络框架,设计了一种自动噪声检测前端技术对孤立词进行识别,其在高噪声条件下的识别率高于梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficient,MFCC);李云红等提出一种结合深度玻尔兹曼机(Deep Boltzmann Machine,DBM)的DNN-HMM 语音识别方法,在词错率和句错率方面比传统DNN-HMM 模型均有所下降;Ashar等将卷积神经网络(Convolutional Neural Networks,CNN)与MFCC 特征相结合,其对存在背景噪音的说话人识别精度达87.5%,但该方法的计算复杂度较高;Shetty 等将Transformer 框架引入语音识别系统中,其对低资源语言识别任务的识别效果优于RNN 模型;Li 等改进了语音识别系统中的RNN-T 模型,相较于类似尺寸的混合模型,该模型能有效降低识别错误率。
在少数民族语言语音识别研究中,韩清华等采用HMM 模型对安多藏语非特定人孤立词语音识别进行了研究,但仅针对小量词汇进行了识别,且识别效果有待提高;Pan 等提出一种基于动态贝叶斯网络(Dynamic Bayesian Network,DBN)的算法对藏语语音进行识别,相较于传统的HMM 识别算法,该算法提高了抗噪声的识别能力,但需要设计适合大量词汇和连续语音识别的DBN 识别模型;Li等对基于机器学习的孤立词识别算法进行研究,通过提取不同特征向量,在不同分类器下提高了词语音识别的准确性;Hu 等利用混合单元进行语言建模,通过引入插值LM 提高模型的识别性能,降低对维吾尔族语言语音识别的错词率。目前,关于苗语数据收集、发音特点等已有一定研究,但在语音识别方面研究成果较为欠缺。例如,李一如对黔东苗语的比较结构进行了分析;李学林等对贵州省中部苗语音素边界检测方法进行了研究,实现了音素边界的划分,但需要对音素进行人工标注;杨建菊等基于HMM 对苗语连续语音识别系统进行初步设计和识别测试,但语音识别系统规模较小、复杂度较低。
由于苗语存在文字缺失、地域差异等问题,采用现有语音识别方法难以直接对其进行识别。为此,本文以汉语拼音为媒介标注苗语语音,构建包含常用字词句的苗语语音语料库,引入CNN 建立苗语孤立词汇识别模型;然后以自建苗语语音语料库的数据作为实验数据集验证该模型对同地域和不同地域苗语孤立词语音识别的有效性,检验具有地域差异的苗语孤立词语音对模型识别效果的影响。
2 语音语料库构建
语音语料库是语音识别研究的基础。苗语文本语料库需要借助汉字拼音或国际音标进行语音标注。苗语虽然没有通用文字,但多数语法结构与汉语相似。因此,苗语语料库的构建需要参考汉语、英语及其他少数民族语言语料库的构建方法,语料选取要尽可能覆盖苗语语言内容,根据苗语的发音特点及语法结构构建相对完备的苗语语音语料库,为苗语语音识别研究提供数据基础。
2.1 苗语声韵母、声调特点
贵州中部苗语是基于声韵母、声调组合发音,本文参考贵州大学出版社出版的《苗族语文读本》中所列苗语声韵母及声调标注方法对苗语语料库进行标注,苗语声母、韵母、声调如表1 所示。

Table 1 Initial consonants,vowels and tone of Hmong language表1 苗语声母、韵母、声调
2.2 苗语语料库构建
本文建立的苗语语音语料库主要参考小学语文课本、贵州普通话考试测试题以及《苗族语文读本》内容进行录制采集,语料应充分展示中部苗语声母、韵母、声调的特点。选取具有代表性的字词句进行录制,语料库包含苗语的100个常用字、800个常用词和100个常用语句。采用单声道麦克风在安静环境下进行语音录制,采样频率为44 000Hz,保存格式为WAV。语料库构建包含苗语语音资源采集、语音数据预处理、语音标注和存储4个步骤,具体如图1 所示。

Fig.1 Construction flow of Hmong language corpus图1 苗语语料库构建流程
3 苗语孤立词识别模型
首先提取苗语语音的MFCC,以MFCC 特征作为语音识别网络的输入训练模型,并采用测试数据对模型进行测试。苗语孤立词的识别流程如图2 所示。
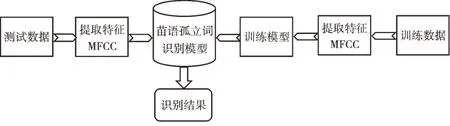
Fig.2 Identification process of isolated words in Hmong language图2 苗语孤立词识别流程
3.1 MFCC 特征提取
MFCC 是语音识别研究领域常用的语音特征,是在Mel标度频率域提取出来的倒谱参数,其与频率的关系可表示为:

f
为频率,单位为H
z。在cnn-24 文件夹下有一个命名为“get-mfcc.py”的代码,其功能为提取语音的MFCC 特征参数。MFCC 特征提取的过程为:
(1)读取语音WAV 文件,获取语音波形和采样率;
(2)对波型进行快速傅里叶变换,对特征参数进行归一化处理,归一化处理方法表示为:

μ
为原始特征的均值,σ
为标准差。(3)将二维特征参数(600,13)扩充为三维数据(600,13,1),便于输入CNN 中进行训练。
3.2 模型参数设置
苗语孤立词识别模型由4个卷积层、2个池化层、1个全连接层、1个Softmax 层组成。模型的输入为提取的MFCC 特征,对输入特征进行卷积操作后,采用ReLU 激活函数对卷积核的输出值进行非线性变换,然后进行最大池化操作。全连接层采用的激活函数为ReLU 函数,采用dropout 方法解决训练模型过拟合问题,即在全连接层后添加dropout 层,参数值分别设为0.25、0.4,学习率设为0.000 1。苗语孤立词的识别网络框架如图3 所示。模型参数设置如表2 所示。

Fig.3 Recognition network frame of isolated words in Hmong language图3 苗语孤立词识别网络框架

Table 2 Model parameter settings表2 模型参数设置
4 实验方法与结果分析
4.1 实验数据
选取苗语语料库中24个常用苗语孤立词汇作为实验数据,分别为爸妈、吃饭、读书、回家、今天、朋友、起床、睡觉、耳朵、早晚、中午、我们、家里、现在、说话、后面、明天、跑步、眼前、眼睛、走路、昨天。在实验数据集中创建24个语音文件夹,以汉语拼音的形式命名,将苗语语音存放于对应的汉语拼音文件夹中。文件命名的数字代表汉字拼音的声调,例如“chifan14”代表“吃饭”这个词的语音数据,其中“14”代表吃饭两个字的声调。苗语语音词汇对应的汉语拼音标注文件名如表3 所示。
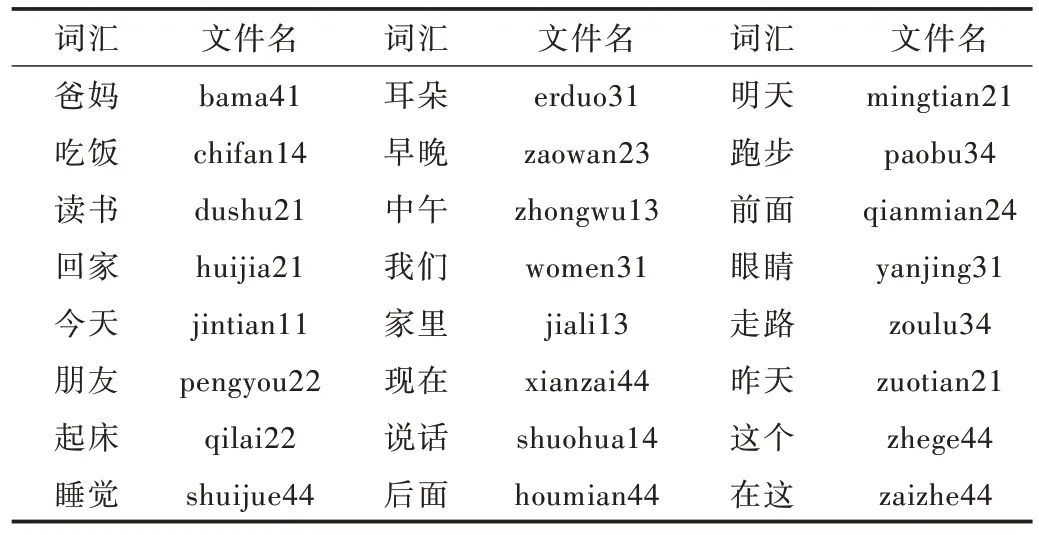
Table 3 Vocabulary checklist表3 词汇对照
采用write 函数对语音文本进行定义,该函数可将语音样本生成为.txt 格式。引入random 函数使生成的数据具有随机性,该函数可将实验数据集中的数据顺序打乱,然后将这些乱序的语音数据按照设定的比例随机分为训练、验证、测试数据集,具体数据量如表4 所示。

Table 4 Amount of training,verification and test data表4 训练、验证、测试数据量
4.2 实验环境
采用Adobe Audition 3.0 录制苗语语音数据。实验在Windows10的64位系统上进行,处理器为Intel(R)Core(TM)i7-7700 CPU@3.6Hz。以Keras 深度学习框架为基础,编程语言使用Python3.7。
以词汇识别准确率为评价指标,当输入测试数据与输出对应标签相符时,则表明该词汇识别正确,反之识别错误。词汇识别准确率表示为:

M
表示苗语孤立词识别正确个数,N
表示苗语孤立词识别总数。4.3 实验结果与分析
为验证本文模型的有效性和稳定性,选取苗语语料库中部分常用词汇作为实验数据,在24个常用词汇组成的数据集上设置3 组不同的实验,通过accuracy 和loss 曲线变化情况判断模型的识别效果和收敛情况。
首先,采用苗语孤立词识别模型对同一地域的苗语语音进行识别,结果如图4 所示。可以看出,对于同一地域的苗语语音,苗语孤立词识别模型的训练精度与验证精度均大于95%,迭代40 次之后模型趋于平稳。该模型能有效识别以汉语拼音标注的苗语孤立词。
然后,采用苗语孤立词识别模型对不同地域的苗语语音进行识别,结果如图5 所示。可以看出,对于不同地域的苗语语音,苗语孤立词识别模型的训练精度大于95%,验证精度小于95%,二者之间存在差距。该模型在训练和验证阶段的loss 值也存在差距。
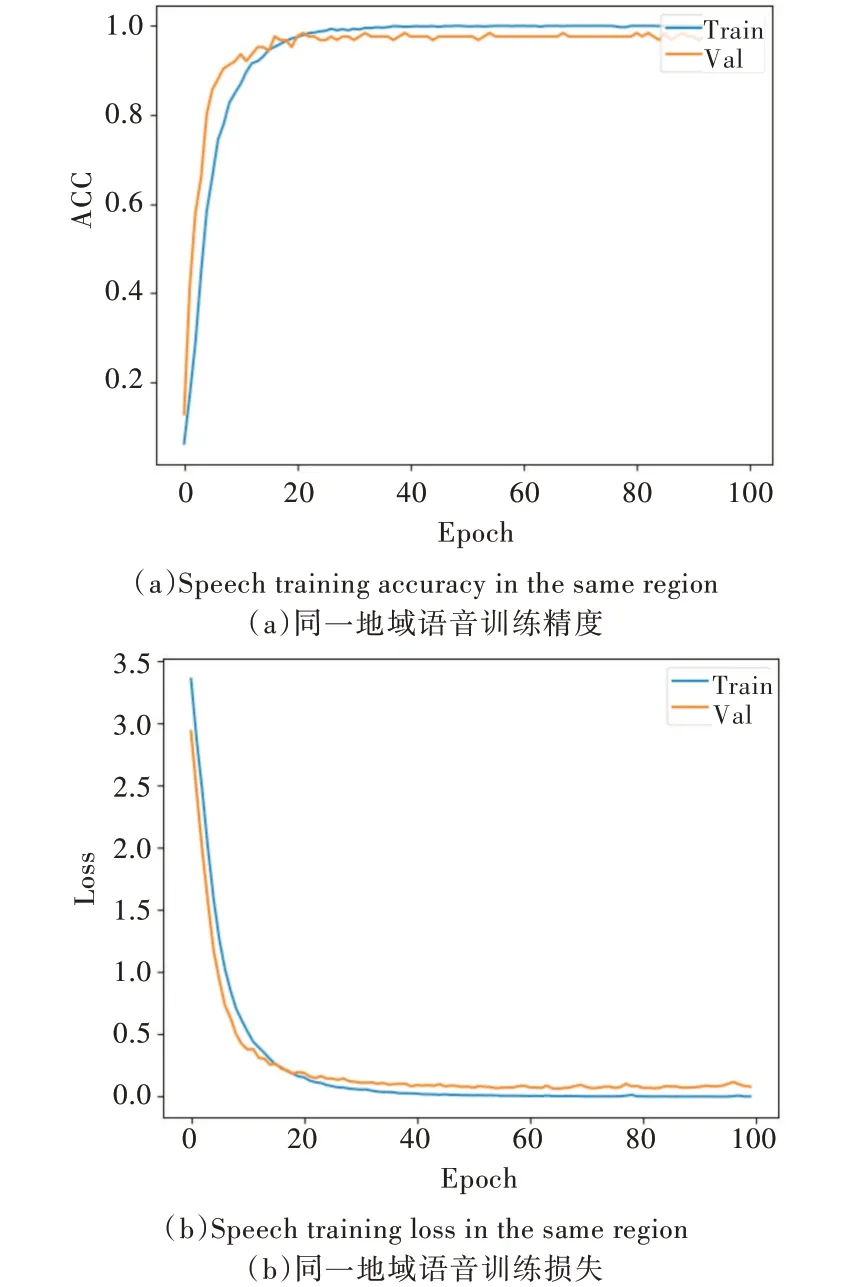
Fig.4 Speech recognition effect in the same region图4 同一地域语音识别效果
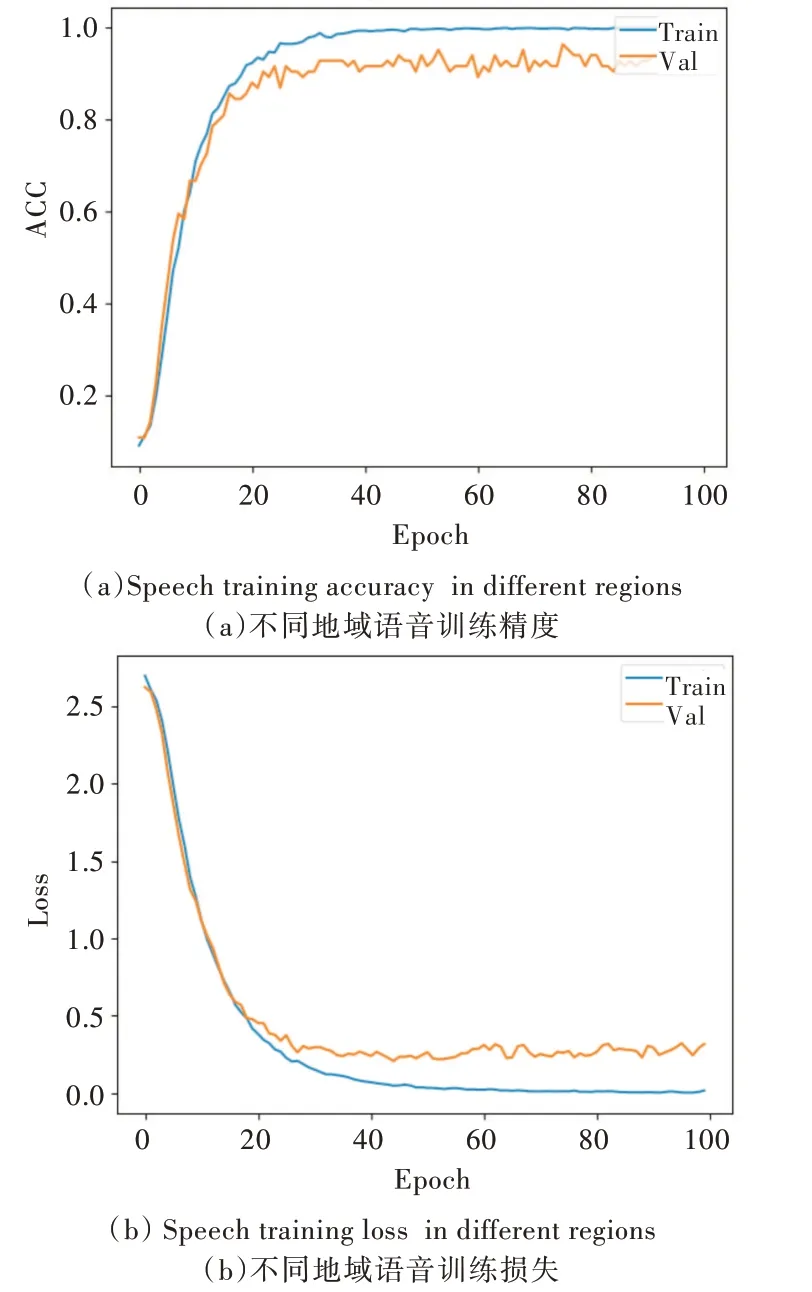
Fig.5 Speech recognition effect in different regions图5 不同地域语音识别效果
最后,采用苗语孤立词识别模型对同一地域和不同地域融合的苗语语音进行识别,并打乱数据集的原始排序,以验证该模型识别组合地域语音的稳定性,结果如图6 所示。可以看出,对于组合地域的苗语语音,苗语孤立词识别模型的训练精度和验证精度比较接近,说明该模型对组合地域苗语语音识别具有稳定性。

Fig.6 Speech recognition effect in combined regions图6 组合地域语音识别效果
以上3 组实验的训练精度和测试精度具体数据如表5所示。可以看出,苗语孤立词识别模型在同一地域语音上的识别准确率达97%,在不同地域语音上的识别准确率达94%,而将两个数据集合并为一个数据集训练该模型时,识别准确率为95%。
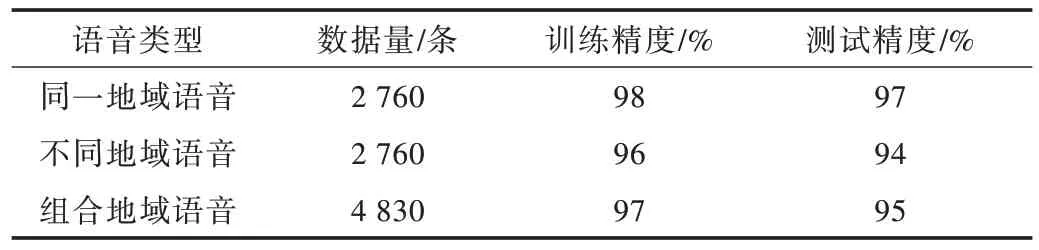
Table 5 Comparison of data of 3 groups of experiments表5 3 组实验数据比较
由以上数据可知,苗语孤立词识别模型能有效识别采用汉语拼音标注的苗语语音,对同地域苗语语音的识别效果优于不同地域苗语语音,说明该模型会受到地域差异的影响,泛化能力还有待提升。当同一地域与不同地域语音合并为一个数据集训练模型时,相较于不同地域语音识别,模型的识别效果略有提升,说明模型对组合地域的语音识别效果良好。
5 结语
针对苗语因无文字而难以直接进行语音识别的问题,本文首先借助汉语拼音对苗语进行语音标注,构建了包含苗语常用字词句的语音语料库;然后构建基于CNN 的苗语孤立词语音识别模型,对同地域、不同地域以及组合地域的苗语进行识别。结果表明,该模型能有效识别出苗语孤立词语料库中同地域和不同地域的常用词。然而,由于该模型受到苗语地域差异的影响,识别效果不够稳定。未来拟通过对苗语语料库发音人、录制内容、录音设备、录音格式、存储方式以及标注方式等进行规范化以完善语料库构建,利用苗语语音数据的多样性提高模型的泛化能力。此外,还在此基础上研究连续语音的自动分割技术,为苗语连续语音识别奠定基础,最终实现苗语与其他语言的互译。
猜你喜欢
贺州学院学报(2022年2期)2022-08-12
——以凯里地区为例
文化产业(2021年11期)2021-09-14
消费导刊(2020年23期)2020-07-12
天津外国语大学学报(2020年1期)2020-03-25
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
创新作文(1-2年级)(2018年12期)2018-04-24
语言与翻译(2015年4期)2015-07-18
