
采用BERT-BiLSTM-CRF 模型的中文位置语义解析
2022-03-07 06:57邓庆康李晓林
软件导刊 2022年2期
邓庆康,李晓林
(1.武汉工程大学计算机科学与工程学院;2.智能机器人湖北省重点实验室,湖北武汉 430205)
0 引言
中文位置语义解析是指将非结构化的中文位置信息拆分成若干最小位置要素,是中文分词在地理信息领域的应用。随着互联网相关技术的迅速发展与普及,位置信息已被广泛应用于各种网页端和移动应用端,如北斗卫星导航系统、地图类软件、外卖软件、打车软件等。随着互联网越来越开放化,网络上大量位置信息数据来源于用户上传与共享的文本位置信息,这些信息很大程度上是用户根据个人理解上传的信息,缺乏统一标准及格式,存在语义模糊、表意不清、结构混乱等问题。因此,有效的中文位置语义解析算法显得尤为重要,已成为地理信息领域应用需要解决的核心问题之一。
传统中文位置语义解析主要是通过规则和统计两种方法进行的。基于规则的中文位置语义解析主要依靠中文位置信息字典,如马照亭等利用地理编码库编制地址字典对地名∕地址进行分词;张雪英等通过构建地址特征库提高对中文位置的解析准确率;赵阳阳等通过测试证明FMM算法能够实现对地名地址串的拆分,有效解决了对未登录地址名称的识别问题。基于统计的中文位置语义解析主要依靠传统的机器学习方法,如应申等利用统计决策树对城市地址进行集中分词;谢婷婷等先利用统计规则统计词频,经过预处理后再对地址串进行切分;王勇等利用隐马尔可夫模型(Hidden Markov Model,HMM)对地名语义进行解析。传统的中文位置语义解析方法虽已十分成熟,但忽略了位置词与位置词之间的联系,对中文位置解析的效果与泛化能力都较差。
近年来,随着神经网络模型被广泛应用于中文分词领域,如Switch-LSTM模型、CNN-BiLSTM模型、BERT模型等,中文位置信息也利用神经网络模型进行语义解析。如张文豪等对比长短记忆(Long Short-term Memory,LSTM)网 络和双向长短记忆(Bi-directional Long Short-term Memory,BiLSTM)网络在中文位置语义解析中的效果,证明利用这两种模型进行位置语义解析都能得到很高的准确率;程博等根据中文位置信息具有行政区划的层级规范,提出中文位置信息的层级标注策略,将BiLSTM 与CRF(ConditionalRandomField)相结合进行位置语义解析,能得到更好的分词效果。
上述方法虽然都具有可行性,但仍存在许多问题有待解决。传统的中文位置语义解析方法忽略了位置词之间的联系,致使解析效果与泛化能力很差。当前神经网络模型应用于中文位置语义解析,虽然分词准确率较高,但是存在多义词解析效果差、泛化能力差等问题。
针对上述问题,本文提出一种基于BERT-BiLSTMCRF 模型的中文位置语义解析算法。首先利用BERT(Bidirectional Encoder Representation from Transformers)预训练模型对中文位置信息进行预训练,获取所有层中的上下文信息,增强中文位置信息的语义表征能力,然后通过BiLSTM 模型提取向量特征信息,最后通过CRF 模型的转移概率矩阵得到全局得分最高的标注序列作为最终结果。利用该模型进行中文位置语义解析,得到的整体解析准确率和多义词解析准确率都较高,并且针对不同区域的位置信息数据集具有很好的泛化能力。
1 模型设计
1.1 BERT-BiLSTM-CRF 模型
BERT-BiLSTM-CRF 模型的系统结构如图1 所示。首先,利用BERT 预训练模型将位置信息转化为特征向量,并将特征向量作为BiLSTM 网络的输入;然后,特征向量在前向LSTM 与后向LSTM 的作用下获得隐藏向量,将隐藏向量转化为定长的文本向量,再将此向量输送到CRF 层,即将BiLSTM 层中的So-ftMax 层替换成CRF 层;最后,将BiLSTM网络输出的向量与CRF 层中的参数相结合,以获得整个句子的标签分数,并找到位置信息的最佳标签。
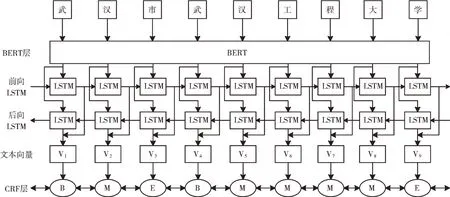
Fig.1 Structure of BERT-BiLSTM-CRF model图1 BERT-BiLSTM-CRF 模型结构
1.2 BERT 预训练模型
在自然语言处理领域,通常使用Word2Vec 方法进行词嵌入操作,但这种操作文本序列的解析是静态的。2018 年由Devlin 等提出的BERT 模型通过无监督方式学习,能保存深层的特征信息,具有更好的泛化能力,其结构如图2所示。Bert 模型主要由双向Transformer 的encoder 结构组成,利用Mask 预训练任务学习token 的上下文语义信息,并利用下一句预测任务学习句子的顺序特征信息。在掩码语言模型任务中,会随机选择15%的位置信息进行遮掩,之后将80%的被遮掩位置信息用maskedtoken 取代,10%的被遮掩位置信息用随机产生的词语取代,余下被遮掩的位置信息保持原状。
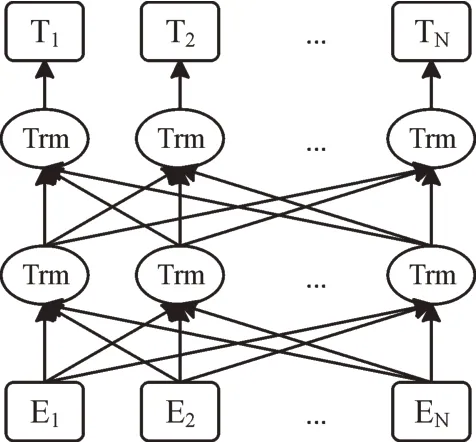
Fig.2 Structure of BERT图2 BERT 结构
双向Transformer 是一个完全基于注意力机制的模块,其编码单元如图3 所示。Transformer 由多个重叠的单元组成,每个单元又由两部分组成,第一部分是自注意力机制(self-attention),第二部分是前馈神经网络(FeedForward-Network)。单元内部的子层之间设计了残差连接,如图3中虚线所示,该连接可保证把上一层信息完整地传到下一层。当输入部分进入Transformer 特征抽取器时,在第一个子层中首先经过自注意力层,然后进行残差处理与标准化;在第二个子层中把从自注意力层得到的输出传递到前馈神经网络中,然后同样进行残差处理与归一化。因为单一自注意力机制无法获取更多子空间信息,而多头注意力机制可获取句子级别的语义信息。该机制采用多个自注意力机制进行并行计算,将多组输出乘以随机初始化的矩阵,最后通过线性变换输出最终结果。

Fig.3 Transformer coding unit structure图3 Transformer 编码单元结构
1.3 BiLSTM 模型
循环神经网络(RNN)是一种典型的深度学习模型,在理论上可处理序列数据并学习任意长度的上下文信息。但当数据长度过长,会出现梯度消失问题,致使其无法继续优化。因此,RNN 是长度相关的。由于RNN 的这一缺陷,在文献[17]中提出长短期记忆网络模型,这是一种改进的RNN 模型。LSTM 网络单元如图4 所示。
LSTM 单元内部计算公式可定义如下:

σ
是Sigmoid 函数,f
、i
和o
分别代表遗忘门、输入门与输出门,W
、W
、W
和W
代表权重矩阵,b
、b
、b
和b
代表误差,h
代表隐藏状态,x
、h
、C
代表输入,h
、C
代表输出。最后,当有n个LSTM 单元时,可获得输出向量(h
,h
,h
,…,h
)。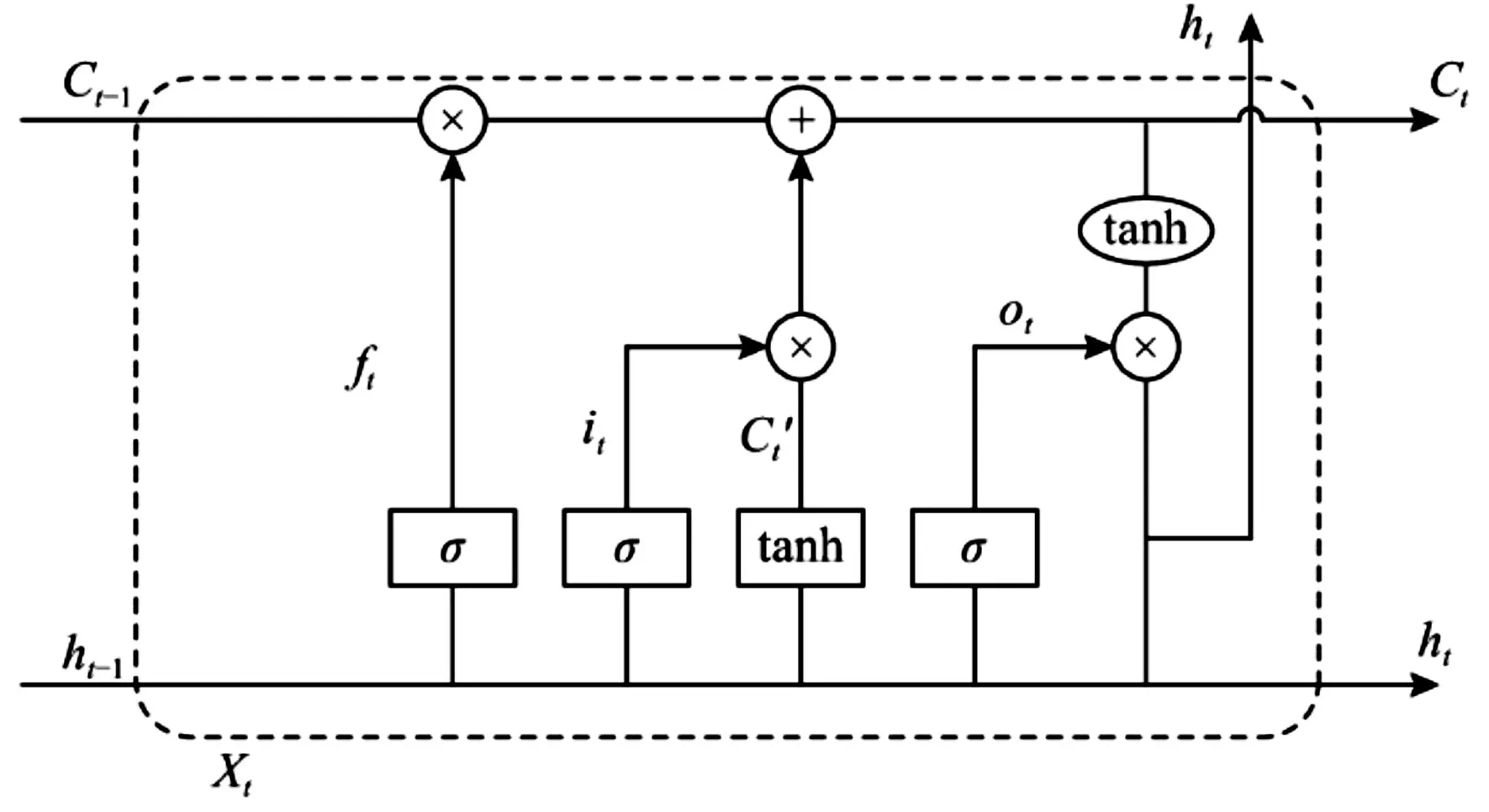
Fig.4 Structure of LSTM cell图4 LSTM 单元架构

1.4 CRF 模型
相邻标签通常在标签任务中具有很强的依赖性。考虑到该问题,本文利用条件随机场(CRF)共同解码给定输入句子的标签信息。CRF 是一种序列标记模型,其在序列标记任务中具有优势,因其考虑了标记之间的顺序与相关性。因此,在给定带有句子X
的预测序列y
=(y
,y
,y
,…,y
)情况下,本文使用CRF 模型获得标签最佳序列。设A
表示CRF 层中的过渡矩阵,其中A
表示从标签y
到标签y
的过渡分数。P
是BiLSTM 的输出得分矩阵,其中P
代表属于标签y
的单词i
的置信度得分,将得分s
(X
,y
)定义为式(7)。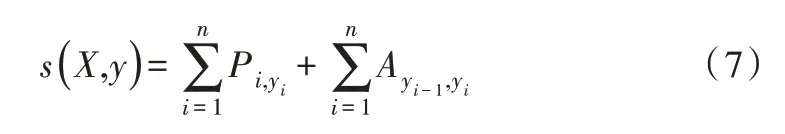
s
(X
,y
)越高,预测越准确。因此,可利用式(8)获得最可靠的输出。
2 实验结果与分析
2.1 实验数据
中文位置信息没有现成的数据集,本文从网上获取到25 万条关于武汉市的原始中文位置信息数据集,以及3 万条关于孝感市的原始中文位置信息数据集。原始中文位置信息存在数据重复、缺失及结构混乱等情况,故需要对数据进行预处理后再使用。剔除不规则的中文位置信息数据后,筛选得到用于本次实验的20 万条武汉市标准中文位置信息数据集和2 万条孝感市标准中文位置信息数据集。数据集格式如表1 所示。

Table 1 Standard Chinese location information format表1 标准中文位置信息格式
将20 万条武汉市标准中文位置信息数据集分别按照数量2 万、6 万和12 万随机分成A 组、B 组及C 组,并将全数据集设置为D 组,每组都按照7∶2∶1 的比例分为训练集、测试集与验证集,每组数据集规模如表2 所示。将2 万条孝感市标准中文位置信息数据集设置为E 组,只作为测试集使用。

Table 2 Dataset size表2 数据集规模
2.2 实验环境
本文实验环境配置如下:操作系统为Ubuntu18.04,CPU型号为Intel Xeon E5-2665,GPU型号为GTX1080Ti;内存为64G,显存为11GB;Python 版本为3.7.0,Pytorch 版本为1.7.0。
BERT 模型参数设置如下:版本为BERT-Base;网络层数为12,隐藏层为768;多头数量为12,总参数量为110M,序列最大长度为128;train_epochs 为20,train_batch_size 为16;学习率为5e-5,dropout 率为0.5;BiLSTM_size 为128。
2.3 标注与评价指标
目前,常用的序列标注策略有很多,本文在中文位置语义解析实验中选择使用BMES 4 位序列标注策略,其中B表示位置词词首,M 表示位置词词中,E 表示位置词词尾,S表示位置单字词。例如位置信息“湖北省∕武汉市∕东西湖区∕东吴大道∕与∕新城十路∕交叉口”标注后的结果为“湖∕B北∕M省∕E武∕B汉∕M市∕E东∕B西∕M湖∕M区∕E东∕B吴∕M大∕M道∕E与∕S新∕B城∕M十∕M路∕E交∕B叉∕M口∕E”。
本文采用中文分词任务中常用的准确率(Precision,P)、召回率(Recall,R)与F1 值进行评价,具体为:
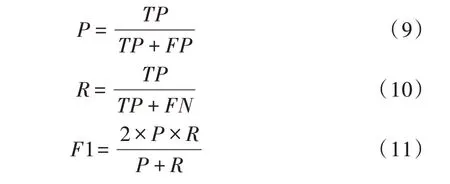
其中,TP 指此模型正确划分中文位置信息的词数,FP指此模型错误划分中文位置信息的词数,FN 指模型实际未识别的实体数量。例如,中文位置信息“湖北省∕武汉市∕江夏区∕光谷一路∕武汉工程大学”经过本实验的中文位置分词模型被划分为“湖北省∕武汉市∕江夏区∕光谷一路∕武汉∕工程∕大学”,TP 为4,FN 为3,FN 为1,则P=0.57,R=0.8,F1=0.67。
2.4 实验结果与分析
本文对比了两个神经网络模型LSTM 和BiLSTM-CRF,以证明BERT-BiLSTM-CRF 模型在中文位置语义解析中可获得更好效果。其中,LSTM 和BiLSTM-CRF 模型都是使用word2vec 模型进行预训练的。
本文利用3 种网络模型分别在A、B、C、D 4 组数据集上进行实验,每组数据集进行实验时,训练集、测试集都来自于同组数据集,3 种模型在A、B、C、D 组数据集上的实验结果分别如表3-表6 所示。
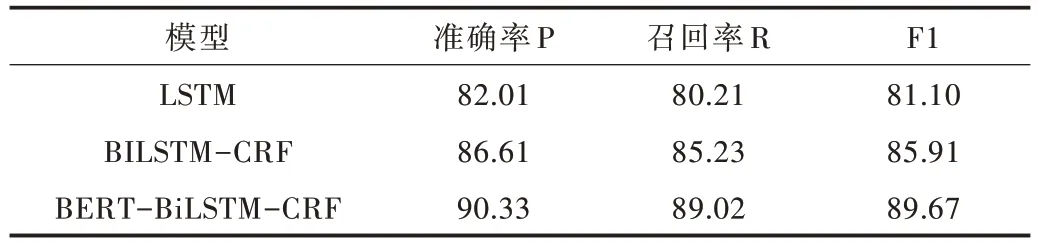
Table 3 Experiment result of three models in A group表3 3 种模型在A 组实验结果 单位:%
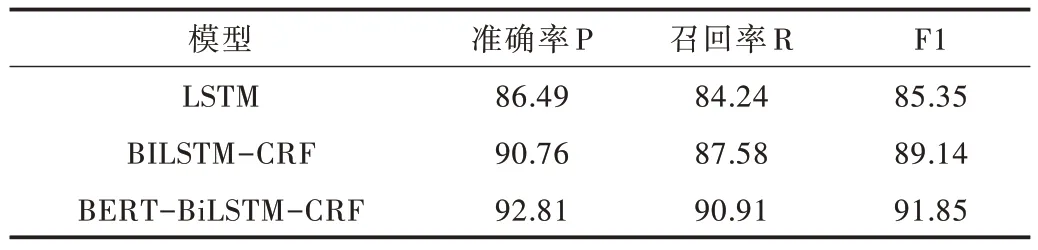
Table 4 Experiment result of three models in B group表4 3 种模型在B 组数据结果 单位:%
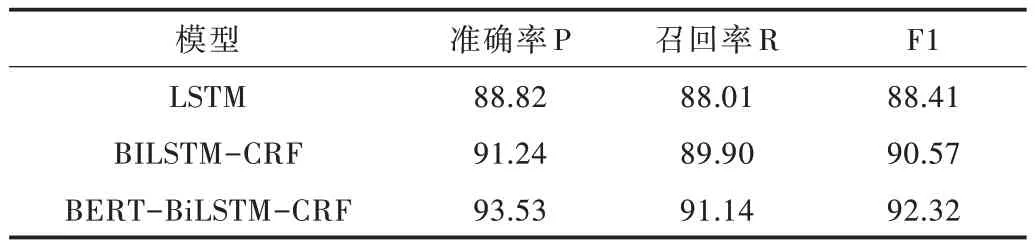
Table 5 Experiment result of three models in C group表5 3 种模型在C 组数据结果 单位:%
从3 种模型分别在4 组数据集上的分词结果可以看出,3 种神经网络模型随着中文位置信息训练集数量的不断增加,位置分词的准确率P、召回率R 和F1 值也不断增加。其中,BERT-BiLSTM-CRF 模型在不同数据集上得到的准确率P、召回率R 和F1 值都是最高的。在表6 中,准确率P 最高达到93.91%,F1 值最高达到93.96。即使在中文位置信息数据集较少的情况下,表3 中BERT-BiLSTMCRF 模型的分词准确率F1 值也超过了90%,达到90.33%。LSTM 模型的分词效果相比其他两种模型较差,主要因为LSTM 模型是随着时间推移进行顺序处理的,不能在未处理特征与已处理特征之间建立联系。相较于BERT-BiLSTM-CRF 模型,BiLSTM-CRF 模型的预训练过程是静态的,没有考虑到位置信息词的多层特性。引进BERT 预训练模型后,模型的准确率P 与F1 值都显著提高,说明BERT预训练模型训练得到的向量具有更多、更好的文本特征,能较好地表征位置信息词的多义性。由此可见,本文提出的模型不仅能提高中文位置信息的解析准确率,而且还能提高多义词的解析准确率。

Table 6 Experiment result of three models in D group表6 3 种模型在D 组数据结果 单位:%
因为D 组数据集和E 组数据集来源于不同城市,本文采用D 组数据集作为训练集与验证集,采用E 组数据集作为泛化能力实验中的测试集,分别在4 种模型上进行泛化能力实验。实验结果如表7 所示。
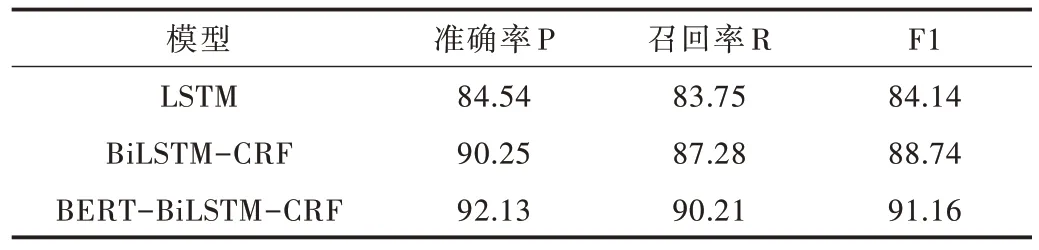
Table 7 Generalization ability experiment result表7 泛化能力实验结果 单位:%
由表7 中不同模型的实验结果可知,BERT-BiLSTMCRF 模型的准确率P、召回率R 和F1 值明显高于LSTM 模型与BiLSTM-CRF 模型。与表6 中的实验结果进行对比,BERT-BiLSTM-CRF 模型在不同测试集上的准确率、F1 值差距很小,仅在2%的范围内,而BLSTM、BiLSTM-CRF 模型因为测试集的变化,在表7 中的准确率、召回率和F1 值大幅下降。因此,在跨区域中文位置信息数据集上,BERT-BILSTM-CRF 模型具有较好的泛化能力。
3 结语
随着地图类软件在人们生活中的应用越来越广泛,当前常用于中文位置语义解析的神经网络模型存在多义词解析效果差、泛化能力较差等问题。鉴于此,本文提出一种采用BERT-BiLSTM-CRF 模型的中文位置语义解析模型,首先使用BERT 模型对中文位置信息进行预训练,获取中文位置信息所有层中的上下文信息,增强位置信息的表征能力,然后通过BiLSTM-CRF 模型进行解密,获取全局最优结果。实验结果表明,该模型相比于LSTM 与BiLSTMCRF 神经网络模型,将其用于中文位置信息解析能取得更好的分词效果及多义词解析效果。而且在不同区域中文位置信息数据集作为测试集的情况下,该模型具有更好的泛化能力。
根据中文位置信息的特点,后续可在序列标注中融入更丰富的信息,并进一步增加模型提取位置的特征信息,以提升中文位置信息解析的效果与泛化能力。
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
开放教育研究(2020年2期)2020-03-31
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
语文世界(小学版)(2018年3期)2018-03-22
摄影之友(影像视觉)(2016年2期)2016-08-16
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
外语学刊(2011年3期)2011-01-22
外语学刊(2011年1期)2011-01-22
