
A Multi-Agent Based Model for User Interest Mining on Sina Weibo
2022-03-01 00:12MeijiaWangQingshanLi
China Communications 2022年2期
Meijia Wang,Qingshan Li
1 School of Electronic Information and Artifical Intelligence,Shaanxi University of Science and Technology,Xi’an 710021,China
2 Software Engineering Institude,Xidian University,Xi’an 710071,China
Abstract: User interest mining on Sina Weibo is the basis of personalized recommendations, advertising,marketing promotions,and other tasks.Although great progress has been made in this area, previous studies have ignored the differences among users: the varied behaviors and habits that lead to unique user data characteristics.It is unreasonable to use a single strategy to mine interests from such varied user data.Therefore,this paper proposes an adaptive model for user interest mining based on a multi-agent system whose input includes self-descriptive user data, microblogs and correlations.This method has the ability to select the appropriate strategy based on each user’s data characteristics.The experimental results show that the proposed method performs better than the baselines.
Keywords: multi-agent system; user interest mining;adaptive model;Sina Weibo;online social network
I.INTRODUCTION
Sina Weibo, a popular microblogging service, allows people to publish short messages on the Web and discuss them.Sina Weibo has experienced substantial growth in recent years, reaching 411 million monthly active users[1].A large number of users have poured into Sina Weibo to share information about their lives and experiences,resulting in rich user-generated content.By analyzing data from Sina Weibo, user interests can be obtained,which is of great significance for recommendation systems,marketing promotions,personalized services,and so on.Therefore,the study of user interest mining on Sina Weibo has attracted increasing attention from researchers.
Great progress has been made in the area of user interest mining.However,previous studies have ignored the data differences among users and mined interests in the same way for all users,which reduces precision.In fact,users on online social networks have varied behaviors and habits that lead to unique user data characteristics.For example, when users are unwilling to disclose their background information, their user interests cannot be obtained.Meanwhile, many users are not currently active in Sina Weibo; consequently,their previously published microblogs may not be representative of their recent interests.Therefore,selecting user interest mining strategies adaptively based on user data characteristics is an important problem.
An intelligent agent is an autonomous entity that perceives its environment, directs its activity toward achieving goals and takes actions that maximize its chances of success.An agent is reactive, proactive and perceptive.A multiagent system is a computerized system composed of multiple interacting intelligent agents within an environment.Using a multiagent system to analyze user interests has notable advantages.Agents have the ability to actively perceive user data types and find the most appropriate method for user interest mining based on the current situation.Therefore, to improve the adaptability of user interest mining,this paper proposes a user interest mining model based on a multiagent system that analyzes the characteristics of the user data and determines the best plan.
The rest of this paper is organized as follows.In Section II, we review the related work.In Section III, we analyze Sina Weibo data to lay the foundation for further study.Section IV introduces our proposed adaptive model for user interest mining based on a multiagent system.Section V presents the experimental results.Finally,conclusions and further work are given in Section VI.
II.RELATED WORK
Previous user interest mining methods can be divided into three types: methods based on self-descriptive information, methods based on user-posted content and methods based on correlations.
(1)Methods based on self-descriptive data
Some online social networks ask users to provide short descriptions using tags.On this basis, [2] assumed that user interests can be obtained from the provided tags.However, [3] found that 78.2% of users did not tag themselves; nonetheless, when two users had interacted with each other, they may share latent common interests.Mining user interests based on selfdefined tags is feasible.In [4], the authors focused on the expertise and interest presentation of Twitter experts in the form of short informative summarization, exploiting the self-descriptive information (i.e.,“Meformer”data)and other information that describes the target user(i.e.,“Informer”data).[5]used a twomode to one-mode network mapping approach to construct an initial interest network represented by user tags,clustered the interest network to generate a hierarchal interest model, and combined social and interest graphs to build an interest-based matching graph.Many methods for user interest mining based on selfdescriptive information exist,and most focus on usergenerated tags; however, some users are unwilling to provide self-descriptive information.The authors of[6]found that nearly half of Sina Weibo users did not add self-descriptive tags,and 7%added only one tag.Personal descriptive information is missing for most users.Therefore, it is not always desirable to obtain user interests from self-descriptive information.
(2)Methods based on user-posted content
Classification models for determining user interests based on user bios and collected tweets were investigated in [7]; the classifications were based on supervised learning and lexical features.The experimental results showed that, of the methods investigated,a support vector machine (SVM) performed best.A semantic graph was constructed in[8]via Wikipedia,through which the proposed semantic spreading model could discover and leverage semantically related interest tags that did not appear in a user’s microblogs.[9] presented a semantic web approach to filter public microblog posts that match the interests from personalized user profiles.The approach automatically generated multidomain and personalized user profiles of interest, filtered Twitter stream data based on generated profiles, and delivered them in real-time.The authors of[10]collected published user data from online social network and annualized user interests and influence to solve the cold-start problem in recommendation systems.In [11], networks based on user interests were modeled by deducing intent from social media activities(e.g.,the comments and tweets of the millions of users of Facebook and Twitter,respectively).The study in [12] focused on the interest dimension of a learner model and presented Wiki-LDA as a novel method for effectively mining user interests from tweets.Wiki-LDA combines Latent Dirichlet Allocation(LDA),text mining APIs,and Wikipedia categories and had been shown to be effective for Twitter data interest mining and classification,where it outperformed standard LDA.The authors of[13]proposed a translation-based method using a frequency-based approach for keyword extraction to mine user interests from microblogs.Because user-posted content reflects user interests, analyzing user interests based on userposted content is popular.However,an open issue still exists: when users are not active on social networks,the posted content becomes outdated, which greatly reduces the accuracy of user interest mining.
(3)Methods based on social correlations
A computational method for inferring user interests was proposed in[14]that combined the degree of familiarity and topic similarity with social neighbors based on social correlation.In[15],to address the lack of semantic information in personalized recommendation systems, a user interest ontology was developed from friends in social networks.This study described the roles in a user interest model based on the user interest ontology.The researchers of[16]improved user interest inferences based on social neighbors.The proposed method exploited the correlations among user attributes to improve inference quality based on social correlations.Some researchers have demonstrated that user interests can be mined based on social correlations.However,some studies has proved that sometimes the social correlations between users was not entirely due to interests[17].Self-descriptive data and user-posted content reflected user interests more directly and accurately than the data of the social correlations of a user.
III.DATA ANALYSIS
To implement an adaptive user interest mining model,this study acquired Sina Weibo data by crawling data from 8000 users and analyzing self-descriptive information,microblogs and social correlations.
3.1 Self-descriptive Data
Self-descriptive information from Sina Weibo includes tags,signatures,and certifications.
Distribution statistics were calculated from tags, as shown in Figure 1.More than 2000 users did not tag themselves,but most users provided three tags.Therefore,Nearly 29%of the users cannot get any information from tags.
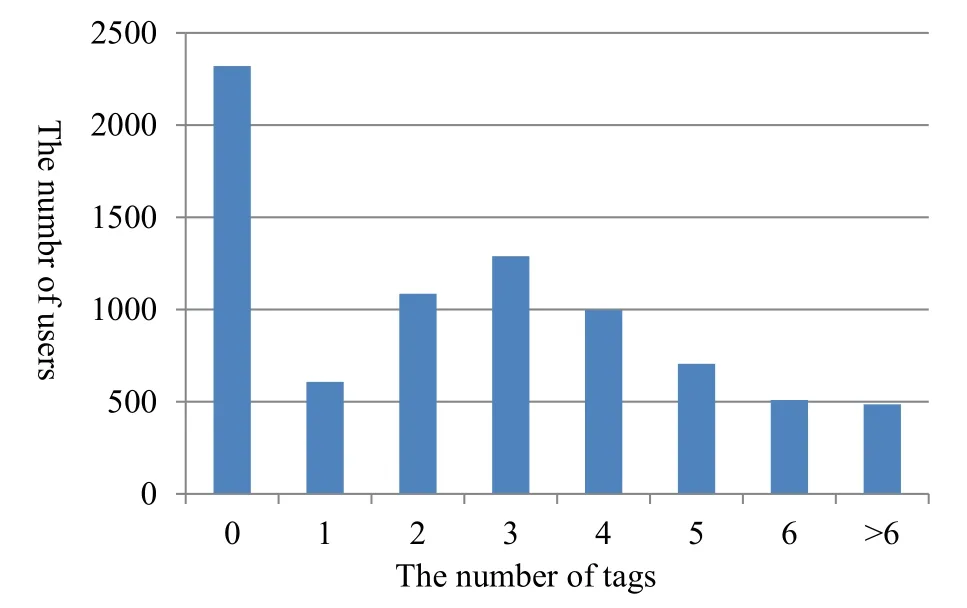
Figure 1. Distribution statistics of user tags.
A“signature”is a free-form sentence in which users describe themselves.There are 7268 users with signatures among the 8000 users.About 9 percent of the users do not provide signatures on Sina Weibo.
For Sina Weibo certification, the information provided by users is validated by the Sina Company.Among the 8000 users,1420 are certified users; thus,most users are not certified.What’s more, for most certificated users,the certifications are related to their jobs.
In addition, 5% of all sample users do not have any self-adaptive data.Therefore, these users cannot obtain any interest-related information from the selfadaptive data, although previous studies have proved the significance of self-adaptive data for user interest mining.
To analyze the contribution of tag, signature, and certification, 100 users were randomly selected from 1420 certification users, including 60 females and 40 males.User tags were directly taken as user interest words to construct the interest word setTfor a user.For signatures and certification,the keywords were extracted as user interest words,which were recorded as setsSandC.The union ofT,S,andCwas recorded asB.At the same time,the keywords were extracted from all microblogs of a user,which were regarded as user interest words, written as setU.For each user,the similaritySim(bi,uj)of interest wordbiinBand interest wordujinUwas was calculated, referred to[18].The correlation of interest wordsbiinBwas calculated as Eq.(1), whereJwas the number of elements in the setU.
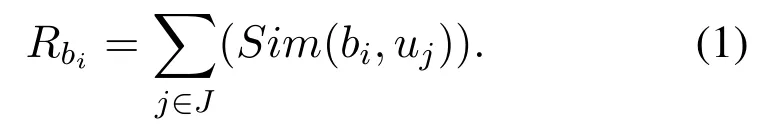
According to Eq.(1), the correlation of each interest word inBwas calculated.All the interested words were ranked based on correlation.The average ranking of all interest words in setsT,S,andCwere obtained respectively.The unions of the average rankings of all interest words in these three sets for all users were recorded as the setRs,RcandRt.K-S test was used to verify whether the data setsRs,Rc, andRtobeyed the normal distribution.The results are shown in Table 1.Rs,Rc, andRtobey the normal distribution.The results of the analysis of variance of the data sets are shown in Table 2.There are significant differences between these three data sets(significance level is 0.05).Furthermore, the differences between groups were compared.The results are shown in Table 3.It is obviously that there is significant difference betweenRcandRt.However, there is no significant difference betweenRtandRs, but the difference betweenRcandRsis significant.The Descriptive statistics forRc,Rt,andRsis shown in Table 4.It can beclearly seen that the ranking ofRcis relatively high,indicating that compared to tags and signatures,certification reflects user interests better.And the average ranking ratio of the certification, tags, and signatures is 7.9:11.4:11.9.To determine the weights,take the reciprocal of the ranking ratio of the three data sets,certification: tag: signature=13 : 9 : 8.In summary,it is possible to use tags, signatures and certifications to analyze user interests.Moreover,71%of users tag themselves, 91% have signatures, 18% are certified,and 5% of users do not have any self-adaptive data.Besides, the certification is more important than the tags and significations.The weight ratio of certification,tags and significations is 13:9:8.

Table 1. Normality Tests of Rc,Rt,and Rs.

Table 2. Analysis of variance of Rc,Rt,and Rs.
3.2 Microblogs
It has been proved microblogs are significant for user interest mining [19, 20].Then the number of the posted microblogs in the past month was calculated for each user; a statistical analysis is shown in Figure 2.More than 1000 users have posted microblogs in a range from 6 to 12,and nearly 1400 users have posted microblogs in a range from 12 to 18.However, more than 9.5%of users are in the range from 0 to 6.
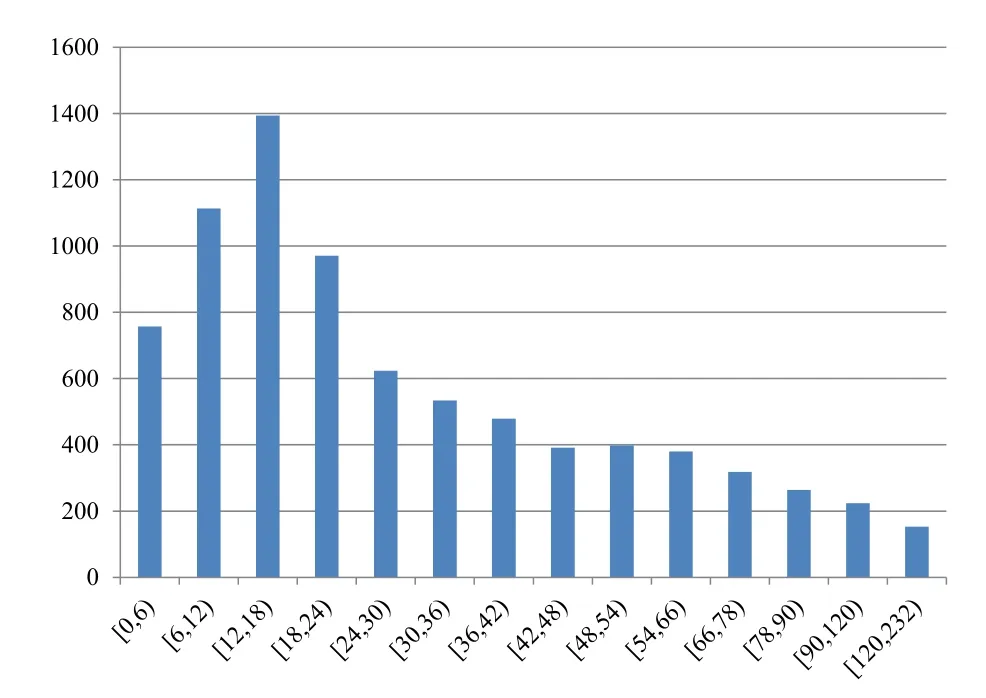
Figure 2. User counts by posted microblogs in the past month.
Therefore, for users who seldom post microbolgs,less interest-related information could be obtained from their microblogs.Therefore, there are some browsing users in Sina Weibo.They only obtain the required information they are interested in, but does not post anything.For these users, only the posted microblogs cannot fully obtain their interests, so it is necessary to further predict these users’interests based on other relevant data.
3.3 User Social Correlations
Social correlations include both followers and followees in Sina Weibo.When a user is interested in other users, he/she may become a follower of his/her interested users.Therefore, we assume that for users whose posted microblogs is less, the followees could be used to predict their interests.We randomly selected 100 users and analyzed the sources of the reposted, liked and commented microblogs for these users.We calculatedRvalue,Lvalue andCvalue for each user.Rvalue was defined as the ratio of the number of the reposted microblogs from the user’s followees to the total number of the user’s reposted micoblogs.Lvalue was defined as the ratio of the number of the liked microblogs from the user’s followees to the total number of the user’s linked micoblogs, whileCvalue was defined as the ratio of the number of the commented microblogs from the user’s followees to the total number of the user’s commented micoblogs.The distributions ofR,C, andLare shown in Figure 3.
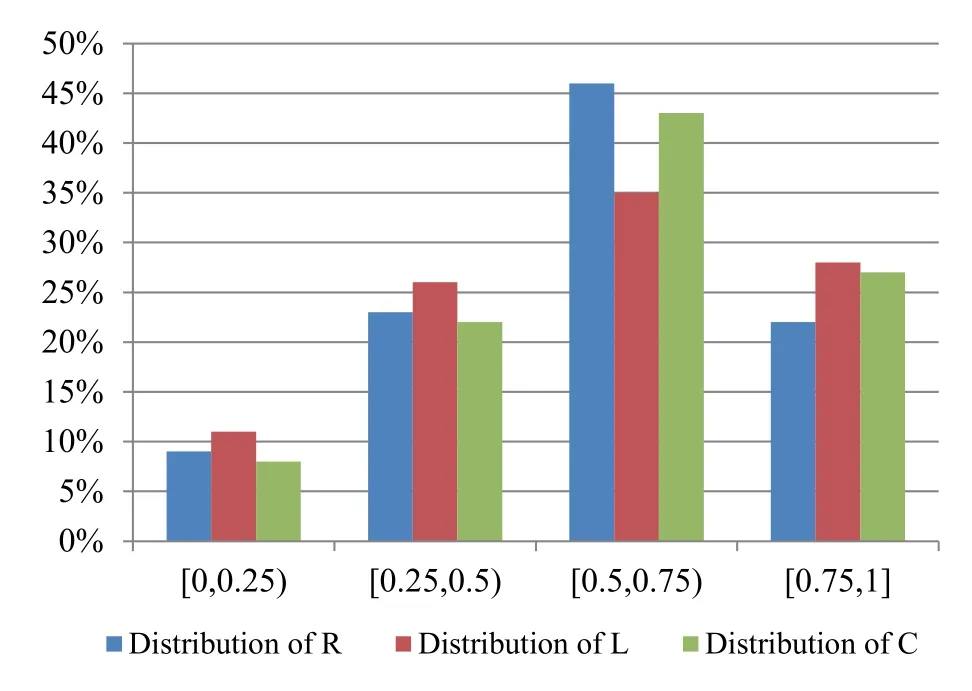
Figure 3. Distribution of R,C,and L.
It can be seen that at least 50% of the microblogs reposted by more than 68% of users are from their followees, and that more than 63% of users at least 50%of likes on microblogs are from followees,more than 70% of users at least 50% of comments on microblogs are from followees.Therefore, it is feasible to supplement the interests of the current user with the interests of his/her followees.The previous studies have shown that there are some special users on Sina Weibo, which are called celebrity users.Such users have greater influence and are often opinion leaders.The outstanding features include: (1) a huge number of followers; (2)a relatively small number of followees;(3)often certificated by Sina company;(4)the original microblogs have a large number of comments,likes, and reposts.We marked all celebrity users and non-celebrity users for the selected users’ followees,and analyzed the sources of the sample users reposted,liked,and commented microblogs.More than 92%of users reposte, liked, or commented microblogs from their following celebrity users, and the more obvious the celebrity features of the followees, the greater the probability that the user will repost, like or comment their microblogs in the future.In addition, for more than 75%of users,if they have once reposted,liked or commented microblogs from a non-celebrity followee,the more likely that they will repost,like or comment the followee’s microblogs in the future.The reason is that the celebrity users often have a strong domain.Obvious celebrity features reflects that the user is professional in this domain.Therefore other users will easily trust them.While for the followees who are non-celebrity users, the current user tend to trust information spread by these users who are more familiar with them.Therefore,it is feasible to utilize user followees to predict user interests.For the followees who are non-celebrity users, the higher the familiarity between the user and the followee, the more important the followee is for user interest prediction.For followees who are celebrity users,in addition to familiarity, users also pay attention to whether their celebrity features are obvious.The more obvious the features,the higher the user trust, and the more important it is for user interest prediction.In summary,self-adaptive data and user posted microblogs are a direct reflection of user interests.However,some users have less selfdescriptive data and microblogs.For these users,less interest information can be obtained, it is necessary to further predict their interests based on the theses followees,and further analyze their followees’data to supplement the current user’s interests.

Table 3. Difference between groups.
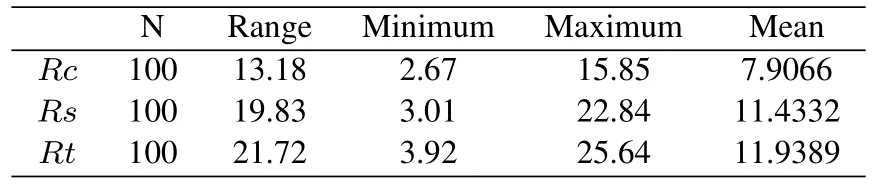
Table 4. Descriptive statistics of Rc,Rt,and Rs.
IV.PROPOSED METHOD
According to the data analysis in the preceding section, an adaptive model for user interest mining(AMUIM) is proposed.Based on a multi-agent architecture,the proposed method has the ability to perceive the user data characteristics and adopt an appropriate strategy to mine user interests.
All published self-descriptive data is available.The interests extracted from self-descriptive data are regarded as long-term static interests, and the interests extracted from microblogs are regarded as short-time dynamic interests.If the user’s posted microblogs in the past month is less than 10,then the followees’data are used to predict the current user’s interests.At this time,identify the type of the user’s each followee,calculate its contribution to the current user’s interests,and then supplement the current user’s interests.
As shown in Figure 4,AMUIM consists of two layers.The decision layer develops a plan for user interest mining,and the process layer executes the specific mining task.
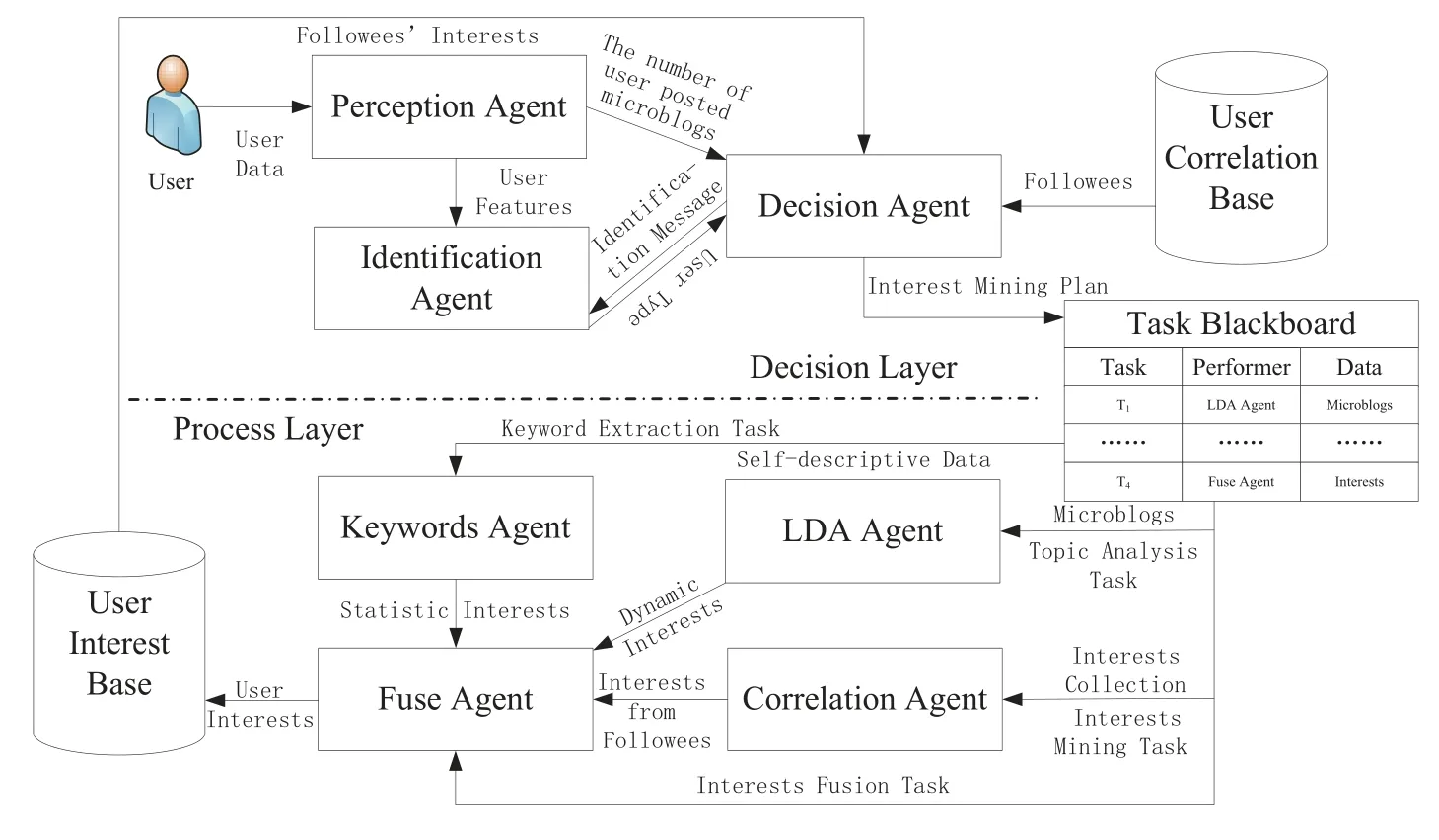
Figure 4. AMUIM architecture.
The decision layer includes the Perception Agent,Identification Agent, Decision Agent, Task Blackboard and User Correlation Base.The Perception Agent perceives user data, and extracts user features,such as the total number of the user’s posted microblogs in the past month, the mean value of reposts, comments, and likes for all microblogs, and so on.The Identification Agent uses an SVM to identify user types.2000 samples are labeled as the training set.Here,the number of followers,the mean value of reposts, comments, and likes for all microblogs, the original microblogs ratio and certification are selected as features.The linear function is used as the kernel function.The Decision Agent develops a plan for user interest mining and uses the plan to assign user interest mining tasks according to the user’s posted microblogs in the last month.The Decision Agent also prepares data for user interest analysis.All tasks and data are published on the Task Blackboard.The Task Blackboard is composed of the Task,Performer,and Data.It publishes user interest mining subtasks and assigns the corresponding Agents to perform subtasks.The Task Blackboard also provides preprocessed data for analysis.The User Correlation Base stores users’ followees.The Agents in the Process Layer read the data from the Task Blackboard and execute specific tasks.The process layer consists of the Keywords Agent,LDA Agent,Correlation Agent and Fuse Agent.The Keywords Agent extracts keywords from signatures and certifications using NLPIR because signatures and certifications represent long-term static interests.The LDA Agent analyzes microblogs and obtains short-term dynamic interests based on the LDA model.All valid microblogs are defined asM, which is divided into intervals.Therefore,M={Mt1,Mt2,...,Mtn,}whereMtirepresents the texts of all valid microblogs that a user posted during time periodti.The LDA Agent uses NLPIR to conduct Chinese word segmentation and removes stop words fromMti.Then, the remaining words are used as the input of the LDA model.Initially, the number of topics is determined by the training corpus based on the perplexity.Every few days, the recent historical microblogs are used as a new training corpus to update the topics.The topic distribution for textMtiduring time periodtiis represented asPti= (p(T1|Mti),p(T2|Mti),...,p(Tk|Mti)), wherep(Tj|Mti)refers to the probability thatMtibelongs to topicTjandkis the number of topics.User interests change over time.Thus,we use the forgetting curve as the time function,as shown in Eq.(2):
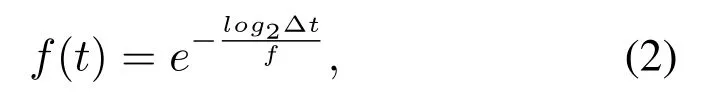
wheref(t)is the time function,fis the half-life(i.e.,afterfdays, half of the interests of a user are forgotten),and ∆trepresents the time period between t and the current time.
Then, the short-term dynamic interests, which are represented as{((t1,p1),(t2,p2),...,(tn,pn))}, are calculated by Eq.(3):
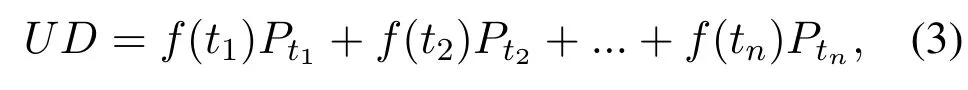
wherenis the number of topics, andPtiis the topic distribution for textMtiduring time periodti.
The Correlation Agent is used to obtain user interests from social correlations.This agent calculates the contribution of each followee for a user, which based on the type of the followees’type,as shown in Eq.(4),
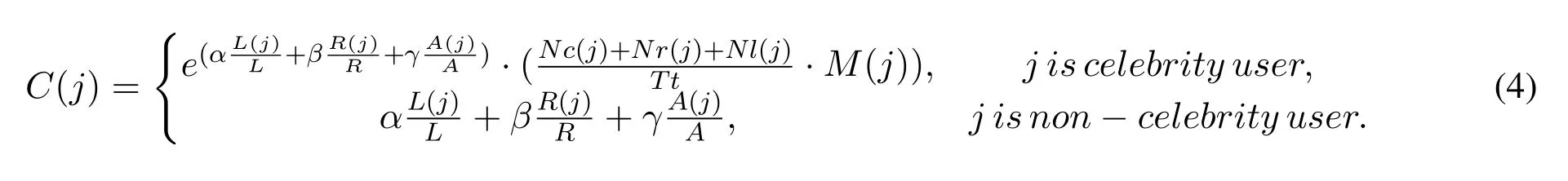
where, the analytic hierarchy process is utilized to determine the values ofα,β, andγ, thenα= 0.16,β=0.54,γ=0.3.Nc(j)is the number of comments on all microblogs of followeej,Nr(j) is the number of reposts of all microblogs of followeej,Nl(j)is the number of likes on all microblogs of followeej,andM(j)is the frequency of microblogs posted by followeejin the past month, andTtis the number of all micoblogs posted by followeej.L(j) is the number of microblogs that the current user likes followeej,Lis the number of all microblogs that the current user likes,R(j) is the number of microblogs that the current user reposted followeej, andRis the number of all microblogs that the current user reposted,A(j)is the number of comments made by the current user to followeej’s microblogs, andAis the number of all comments made by the current user.IfL= 0,R= 0,A= 0 orTt= 0, then setC(j) to a smaller value,this paper sets to 10−5.
Rank the non-celebrity followees and celebrity followees according to the contribution, respectively.Then select the top 8 users non-celebrity followees and celebrity followees to supplement the current user’s interests.Take the selected followees’ interest words which greater than a certain threshold as the interest word sets,denoted asUcandUnrespectively,and integrate the interest words from non-celebrity users and celebrity users as the supplemented interest words,as shown in Eq.(5):
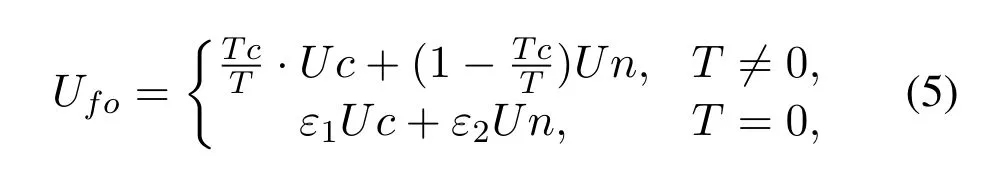
whereTis the number of all microblogs reposted,commented, and liked by the current user, andTcis the number of microblogs reposted, commented, and liked by the current user from celebrity followees.To obtain the value ofε1andε2, the average ratio of 8000 users reposted, commented, and liked microblogs from celebrity followees to that of noncelebrity followees are analyzed, then setε1= 0.63,ε2=0.37.
The Fuse Agent generates the user interest model and stores the final interests in the User Interest Base.All the tags from the Task Blackboard and the extracted keywords from the Keywords Agent are regarded as user interest words.The weight ratio of certification, tags and significations is 13 :9 : 8.Then, the long-term static interests of the user are obtained and represented asUS={(w1,ω1),(w2,ω2),...,(wm,ωm)},wherewiis theith interest word, andωiis the weight ofwi.If the Fuse Agent received the short-term dynamic interests of a user from the LDA Agent, it fuses the static and dynamic interests using Eq.(6)):
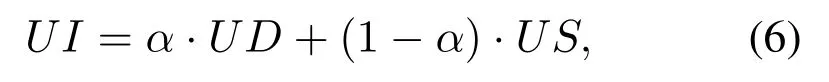
whereUDis the short-term dynamic interests of a user,USis the long-term static interests of a user,andαis a weight coefficient.This paper setαto 0.6 according to the experimental results.
If the Fuse Agent also received the predicted user interests from the Correlation Agent, then the Fuse Agent takes the union of the fused interests from the user’s self-descriptive data and microbolgs and the interests from the Correlation Agent as the users’ final interests and normalizes the weights of the user interest words.
Agents in the same layer communicate by sending messages, while Agents in different layers communicate through the Task Blackboard.
AMUIM works as follows.The Perception Agent analyzes a user’s data,and extracts user features.The Perception Agent send user features to the Identification Agent and informs the user related data to the Decision Agent.The Decision Agent determines the user interest mining method, prepares the data, and publishes the task on the Task Blackboard.If the current user has published self-descriptive data and posted microblogs,the Decision Agent assigns tasks to the Keywords Agent and the LDA Agent.If the total number of the user’s posted microblogs in the past month is less than 10,the Decision Agent schedules the Correlation Agent to mine the user’s interests from social correlations, and informs the Identification Agent to identify the current user’s followees.According to the results from by the Identification Agent, the Correlation Agent calculates the contributions of each followee for the current user, and generates the supplemented user interest words.The LDA Agent, Keywords Agent and Correlation Agent perform user interest mining tasks according to the Task Blackboard.Finally, they send the obtained interests to the Fuse Agent.The Fuse Agent fuses all of the interests for the current user and stores the information in the User Interest Base.
V.EXPERIMENTAL RESULTS
In this section, the performance of AMUIM is discussed.We crawled data from 208 users and used the collected data to evaluate AMUIM.The crawled data is composed of self-descriptive data, microblogs and correlation data.The user interest mining method based on the self-adaptive data, which was similar to [21], is defined as USM.USM extracts the keywords from the tags, signatures, and certifications, as the user interest words.The term frequency is taken as the weight of each user interest word.User interest mining by the LDA Model acting on microblogs is called ULM.For ULM, all the microblogs posted by a user are spliced into a long document.Utilize the LDA model to obtain the topic distribution of the long document as the user interest model [22].Refer to the evaluation in the field of information retrieval,F-measure and MAP value are utilized to evaluate the performance of ULM,USM,AMUIM.
We obtained user interest words by these three methods to generate a user keyword library, and invited each user to judge whether each word in the library was his/her interested word.F-measure values of these three methods were calculated by shown in Eq.(7):
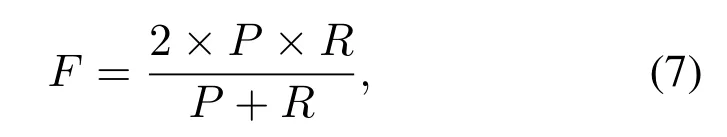
where,Prefers to precision,calculated by Eq.(8),Rrefers to recall,calculated by Eq.(9),
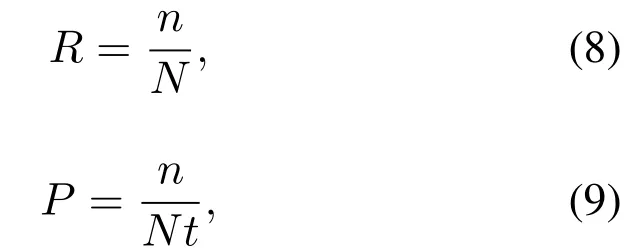
where,nis the number of interest words obtained by the current method and marked as interested words by the user,Nis the number of all interest words marked by the user in the keyword library,andNtis the number of interest words obtained by the current method.
Then, for these three methods, calculated the average F-measure value of all users respectively, the results are shown in Figure 5.
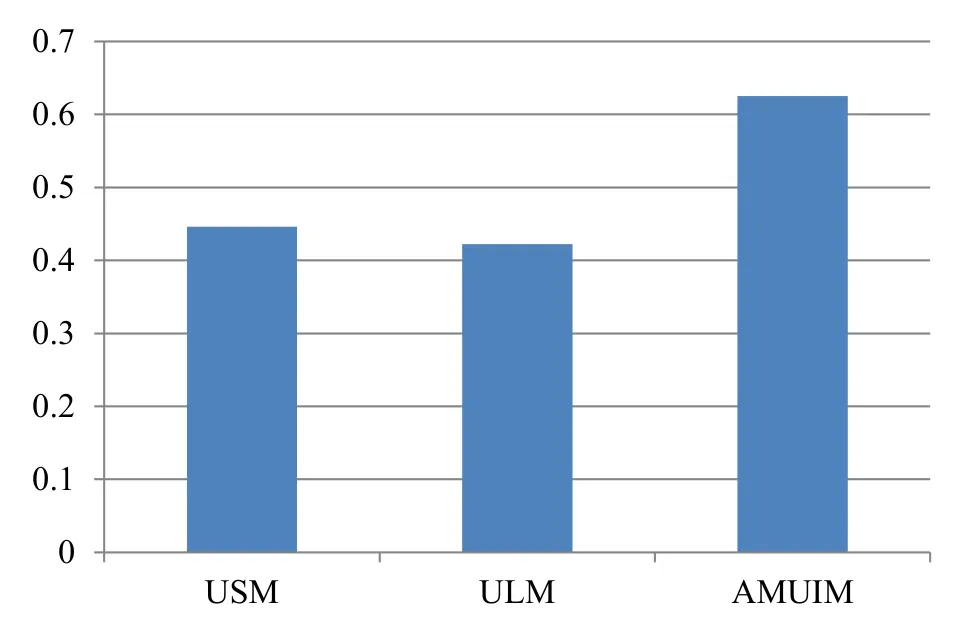
Figure 5. F-measure values of USM,ULM and AMUIM.
It can be seen from Figure 5 that the F-measure value of the proposed AMUIM is higher,and its value reaches 0.63.While the value of USM method is about 0.45, and That of the ULM method is the smallest,which is 0.42.Since the F-measure value considers the precision and recall at the same time,it is obvious that compared to the baselines,our proposed AMUIM has the best performance in terms of F-measure.
We also ranked the interest words extracted by these three methods according to the corresponding weights,and referred to the MAP evaluation in the information retrieval field to judge the performance of each method.The calculation of MAP value calculation is as Eq.(10):
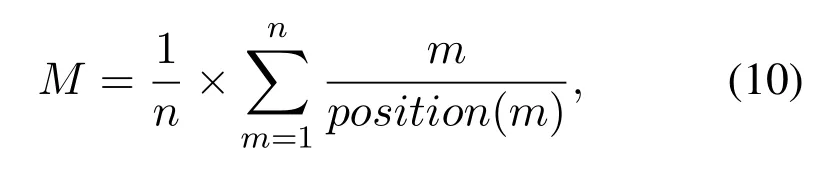
where,nis the number of words that are marked as interested words by the user,andposition(m)indicates the position of the interested word m after ranking.For these three methods,calculate the average values of all users respectively,and the results are shown in Figure 6.
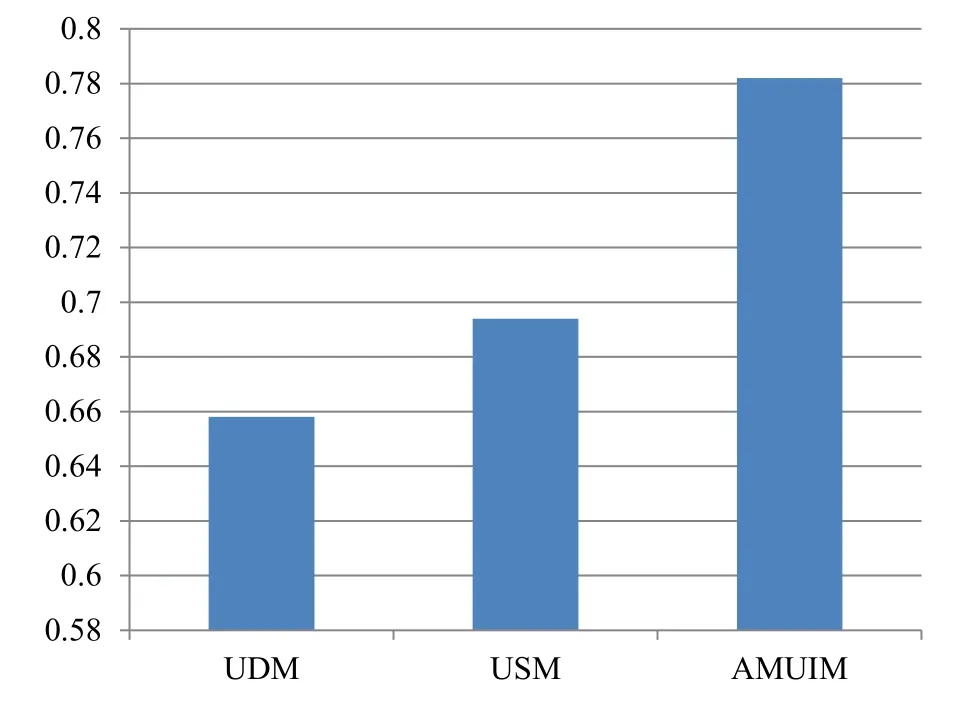
Figure 6. MAP values of USM,ULM and AMUIM.
It can be seen from Figure 6 that the MAP value of the proposed AMUIM method is higher, which reaches 0.78.The value of the USM method is 0.69,while that of the ULM method is about 0.66.MAP takes into account the ranking of each interest word according to its weight.The larger the MAP value,the better the calculated weights, which means users are more satisfied with the corresponding method.Therefore,in terms of MAP value,our proposed method performs better.
In addition, our proposed method AMUIM fuses user’s dynamic interests with static interests based on the weight coefficientα.To determine the best value ofαand analyze the influence ofαon user interests,we tookαfrom 0.1 to 0.9 and calculated MAP values for these 208 users.The results are as shown in Figure 7.We can see, Whenαis from 0.6 to 0.7, our proposed method has better performance.This paper setαto 0.6.
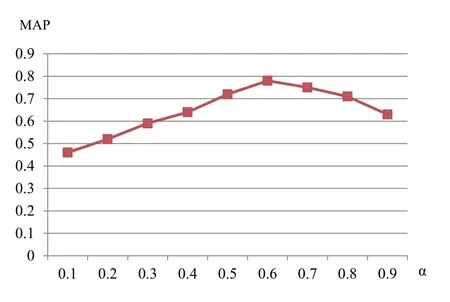
Figure 7. Influence of α on user interests.
VI.CONCLUSIONS
This paper proposed a Multi-agent based model,called AMUIM, for mining user interests from Sina Weibo.The proposed method analyzes self-descriptive data,microblogs and correlation data to obtain user interests.Furthermore, AMUIM utilizes the perceptibility and adaptability of agent to consider the data differences among users and select the best user interest mining strategy for each user.The experimental results show that the proposed method performs better than other mainstream methods in terms of F-measure and MAP.However,the following open issues remain to be addressed: 1) To better fuse dynamic interests and static interests,a semantic analysis of user interest words must be considered.2) Because online social network data have big data characteristics (i.e., volume,variety,velocity,and veracity),analyzing online social network data is time consuming; thus, improving the speed of user interest mining is also important.

- China Communications的其它文章
- A User-Friendly SSVEP-Based BCI Using Imperceptible Phase-Coded Flickers at 60Hz
- Steady-State Visual Evoked Potential(SSVEP)in a New Paradigm Containing Dynamic Fixation Points
- Toward a Neurophysiological Measure of Image Quality Perception Based on Algebraic Topology Analysis
- Transfer Learning Algorithm Design for Feature Transfer Problem in Motor Imagery Brain-computer Interface
- Removal of Ocular Artifacts from Electroencephalo-Graph by Improving Variational Mode Decomposition
- BCI+VR Rehabilitation Design of Closed-Loop Motor Imagery Based on the Degree of Drug Addiction