
Transfer Learning Algorithm Design for Feature Transfer Problem in Motor Imagery Brain-computer Interface
2022-03-01 00:11YuZhangHuaqingLiHengDongZhengDaiXingChenZhuomingLi
China Communications 2022年2期
Yu Zhang,Huaqing Li,Heng Dong,Zheng Dai,Xing Chen,Zhuoming Li,*
1 School of Computer Science and Technology,Harbin Institute of Technology,Harbin 150001 China
2 School of Electronics and Information Engineering,Harbin Institute of Technology,Harbin 150001 China
3 School of Electrical,Computer and Energy Engineering,Arizona State University,Tempe,Arizona,85281 USA
Abstract: The non-stationary of the motor imagery electroencephalography(MI-EEG)signal is one of the main limitations for the development of motor imagery brain-computer interfaces(MI-BCI).The nonstationary of the MI-EEG signal and the changes of the experimental environment make the feature distribution of the testing set and training set deviates,which reduces the classification accuracy of MI-BCI.In this paper, we propose a Kullback–Leibler divergence(KL)-based transfer learning algorithm to solve the problem of feature transfer,the proposed algorithm uses KL to measure the similarity between the training set and the testing set, adds support vector machine(SVM)classification probability to classify and weight the covariance, and discards the poorly performing samples.The results show that the proposed algorithm can significantly improve the classification accuracy of the testing set compared with the traditional algorithms,especially for subjects with medium classification accuracy.Moreover,the algorithm based on transfer learning has the potential to improve the consistency of feature distribution that the traditional algorithms do not have,which is significant for the application of MI-BCI.
Keywords:brain-computer interface;motor imagery;feature transfer;transfer learning;domain adaptation
I.INTRODUCTION
Brain-computer interface(BCI)provides a direct communication between a person’s brain and an electronic device without the need for any muscle control[1].MIBCI is widely used due to its active and neurological relevance to movement.However,the non-stationarity of MI-EEG signal limits the development of MI-BCI[2–4], which is mainly caused by the decrease of attention, change of task, change of electrode position and impedance [3].The non-stationarity of MI-EEG is specifically represented by the feature transfer between sessions/subjects [5], which makes the feature distribution of the testing set data deviate from that of the training set data,and the model obtained from the training set will perform worse over time.The machine learning algorithm in traditional brain-computer interface cannot solve this problem,so it is necessary to apply transfer learning algorithm to MI-BCI.
Transfer learning is a approach for solving problems in different but related domains using already existing knowledge [6], which relaxes two assumptions of traditional machine learning [7].Transfer learning aims at learning characteristics that are consistent across sessions and at the same time adjusting those characteristics to the available target subject’s trials[8].Pan and Yang classified transductive transfer into the related sample selection bias, covariate shift[9] and domain adaptation learning [10] according to whether the training and testing samples are from the same domain.Domain adaptation learning is used with the assumption of different domains but same task,and sample selection bias and covariance shift are used with the assumption of same domain and same task.This means that the domain adaptation learning can be applied to more domains than the sample selection bias and covariance shift.Due to its highly adaptive characteristics, domain adaptation learning is widely used in MI-BCI.There are various similarity measures in domain adaptation [11], commonly known as the inner product [12], KL [3], Monge-Kantorovich distance [13], and Maximum Mean Discrepancy (MMD) [14, 15].The literature [16] proposed a method to measure the distribution difference between the source domain and the target domain by using Maximum Mean Discrepancy (MMD), which was applied in MI-BCI to solve the problem of feature transfer.In the literature [17], a similarity measure based on the Kullback-Leibler divergence (KL)is used to measure the similarity between two feature spaces obtained using subject-specific common spatial patterns (CSP).And the literature [18] proposed a semi-supervised learning with KL distance weighting to update the model trained from the calibration session by using unlabeled data from the online test session.In the literature[3], an EEG-DSA algorithm was proposed to solve the feature transfer problem of single subject, and finally it was concluded that the EEG-DSA algorithm is more suitable for subjects with poor and medium performance.A KLDA-WT algorithm was proposed with some improvements based on the unsupervised EEG-DSA algorithm.However,the KLDA-WT algorithm has some shortcomings in handling poorly performing samples.
This paper proposes a domain adaptation algorithm based on KL to improve the consistency of MI-EEG feature distribution of subjects.In the proposed algorithm, the KL is used to measure the similarity of the feature distribution between the training set and the testing set, and the SVM classification probability is proposed to classify the samples into two classes and weight the covariance matrix.In addition,the proposed algorithm uses the SVM classification probability to classify the samples into good and poor samples,and discards the poor samples, which can reduce the impact of the poor samples on the classification accuracy.The results show that the proposed algorithm can effectively improve the consistency of the feature distribution between the testing set and the training set.The classification accuracy of the testing set of subjects, especially for subjects with medium classification accuracy,is most significantly improved.
II.MATERIALS AND METHODS
2.1 Experimental Data
The dataset used in this paper is the 2a dataset from the BCI Competition IV 2008, provided by Institute for Knowledge Discovery.The sampling rate of the 2a data set is 250Hz, and it has passed 0.5-100Hz bandpass filtering and 50Hz industrial frequency trap filtering.The dataset includes motor imagery EEG data for four degrees of freedom (left hand, right hand, both feet and tongue), and each subject performs a total of two sets of experiments,T and E,with 72 samples in each set of experiments at each degree of freedom.In this paper only left-hand and right-hand motor imagery EEG data are used, and there are two sets of experiments for each subject,with a total of 144 samples.Data set 2a had a total of 9 subjects, numbered A01 to A09.
The subjects sat in a comfortable chair facing the computer screen and used the experimental paradigm shown in Figure 1.At the beginning of the experiment,a fixed cross symbol appeared on the screen,when the arrow cues appeared,pointing to the left,right,bottom or top, corresponding to the imagined movement of the left hand, right hand, foot or tongue, respectively,the cues lasted for 1.25 seconds, the subjects kept on imagining the movement until the cross symbol disappeared.
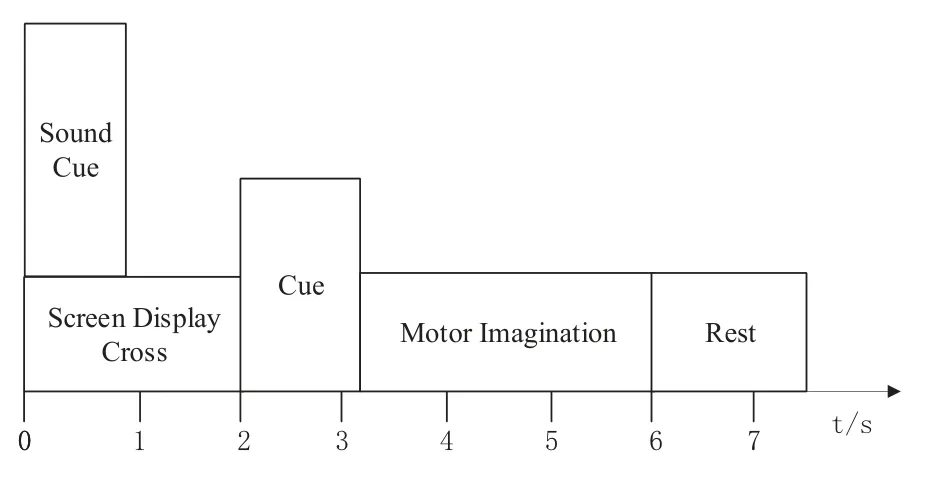
Figure 1. Experimental paradigm diagram of EEG signal acquisition.
The dataset of each subject contains 72 left-hand motor imagination data and 72 right-hand motor imagination data,a total of 144 experimental data.The first 34 experimental data are selected as the training set,and the last 110 experimental data are used as the testing set,and the testing set is divided into two parts,A and B, to observe the change of feature transfer over time,and the data distribution is shown in Figure 2.
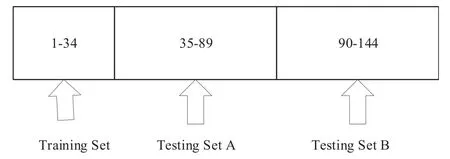
Figure 2. The distribution diagram of 144 experimental data.
2.2 Analysis of the Feature Transfer Problem
In traditional MI-BCI, binary classification is generally implemented using common spatial pattern(CSP)and support vector machine (SVM) algorithms.CSP is a space domain filtering feature extraction algorithm for binary classification, and its basic principle is to use diagonalization of matrices to find an optimal set of spatial filters for projection,so that the difference in variance values between two types of signals is maximized, thus obtaining feature vectors with high discrimination [19, 20].The basic idea of the SVM algorithm is to find a hyperplane so that the distance between the hyperplane and each type of sample set is maximized.In this paper,we use CSP and SVM algorithms for feature extraction and feature classification,and visualize the feature transfer problem and analyze the characteristics of feature transfer based on the feature extraction and SVM classification results.
It is too tedious and unnecessary to list the results of all 9 subjects,so only the results of representative A01 subjects’data after feature extraction by the CSP algorithm are listed here.The feature distribution of A01 subjects’training set data and testing set data is shown in Figure 3.In Figure 3,the red+denotes the left-hand features of the testing set;the black⋆denotes the lefthand features of the training set; the green * denotes the right-hand features of the testing set; the blue ♢denotes the right-hand feature of the training set.Figure 3 shows that there is a difference in the feature distributions between the training set and testing set,with the red + shifts to the upper left compared with the black⋆and the green*shifts to the lower right compared with the blue ♢.In addition, there is a partial interleaving between the left-hand feature distribution and the right-hand feature distribution of the testing set, and this phenomenon caused by feature transfer makes the trained model perform worse,resulting in a decrease in performance of the system.
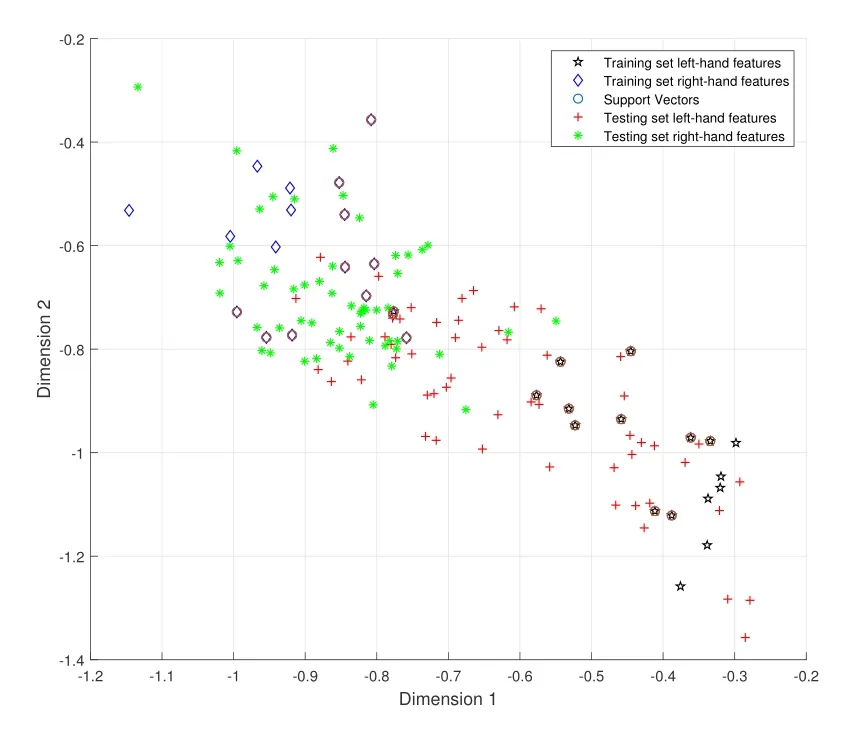
Figure 3.Feature distribution of the training set and testing set of A01 subject.
Table 1 shows the classification accuracies of testing set A, testing set B and the entire testing set of 9 subjects.From Table 1, we can see that the classification accuracy of 7 out of 9 subjects in testing set B is lower than that of testing set A.It can be concluded that the phenomenon of feature transfer becomes severe over time, leading to a gradual decrease in the classification accuracy.
2.3 Improved KL Algorithm Based Transfer Learning
The domain adaptation algorithm proposed in this paper uses KL to measure the similarity between distributions, introduces SVM classification probability to improve the calculation of covariance, and discards poor samples using SVM classification probability.KL,also known as relative entropy, is an asymmetric measure of the similarity between two probability distributions.The KL of two multidimensional Gaussian distributionsN1(µ1,Σ1)andN2(µ2,Σ2)is
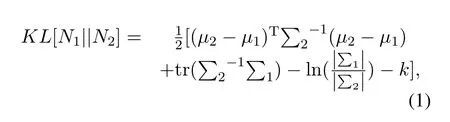

Table 1. Table of classification accuracies of 9 subjects.

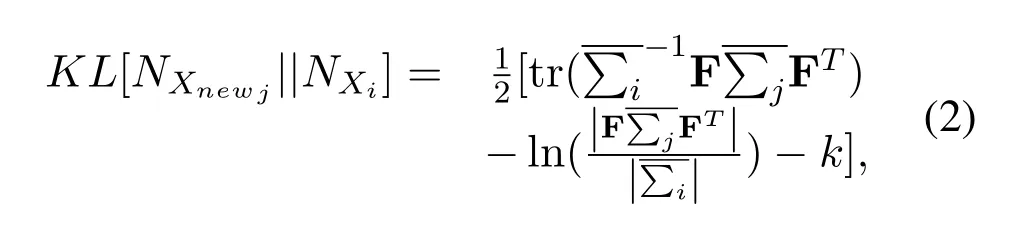
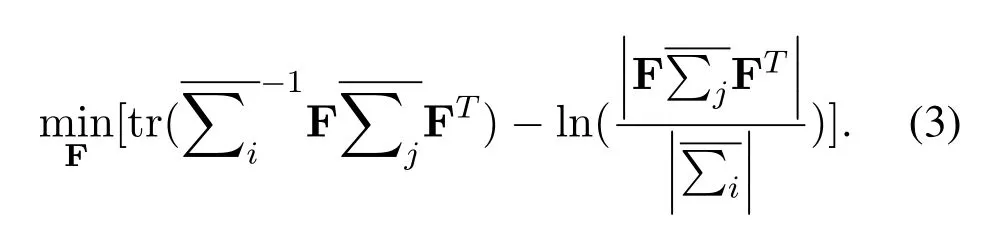
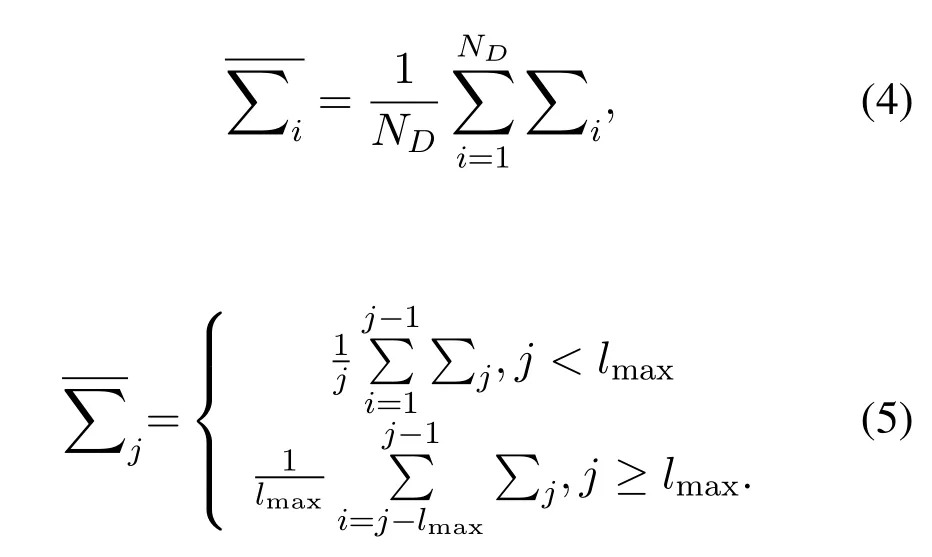
denotes the mean covariance of all data in the training set,enotes the mean covariance of thej-th groupj −1 or thelmax −1 data in the testing set,lmaxis the step size of the data.Derivation of (3)yields that
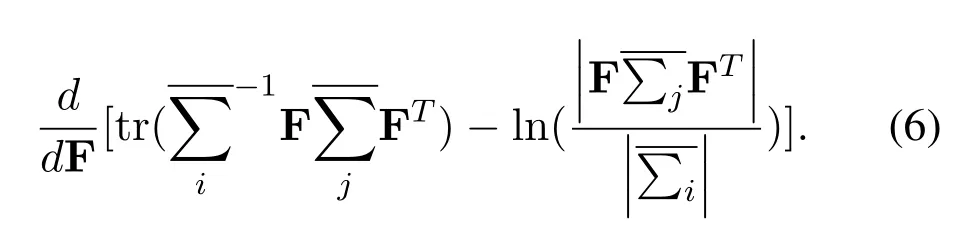
Letting (6)takes 0 yields that
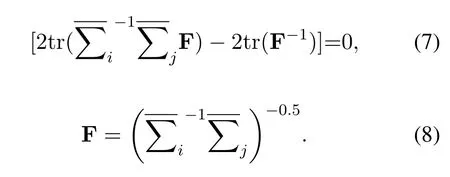
This yields the expression for the mapping F, and then the new testing set data can be obtained fromXnewj= FXj.The KLDA-WT algorithm pointed out that the number of left-hand and right-hand samples in the dataset is a factor affecting the classification accuracy, and changed the calculation ofin(5),the expression ofin the KLDA-WT algorithm is shown in (9).
In (9),PTLiandPTRiare the SVM classification probability of the left-hand and right-hand of theith sample, which can be used to distinguish the covariance of the left-hand data and the right-hand data when calculating the average covariance.The KLDAWT algorithm also set thethresholdfor the difference in feature distribution and a measure of the difference between the testing set data and the training set dataThe KLDA-WT algorithm is used whenthreshold, and the KLDAWT algorithm is not used whenthresholdas the feature distribution of the current testing set does not change much from that of the training set, whereis the feature average of thelmaxsamples closest in time to the current testing set sample.In the process of analyzing the KLDA-WT algorithm, it was found that the expression of (9) actually has three unreasonable points.The first problem is the denominator selection.The denominators in (9)are the sum of the probabilities ofPTLiandPTRi,respectively,which would make the samples with lower classification probabilities have a larger weight in the calculation of the covariance mean, this is obviously unreasonable.The second is the sample selection problem.Samples with a classification probability of about 0.5 are generally considered as poorly performing samples in the process of practical application and should be discarded.The final problem is the calculation of the covariance.In (9),a sample participates in the calculation of the covariance of the left-hand and the covariance of the right-hand, but for a single sample its classification result can only be left-hand or right-hand, so this calculation will make the lefthand sample interfere with the calculation of the covariance matrix of the right-hand sample,and likewise the right-hand sample interfere with the calculation of the covariance matrix of the left-hand sample.Combining the above three points,this paper improves (9)on the basis of KLDA-WT algorithm to obtain (10).
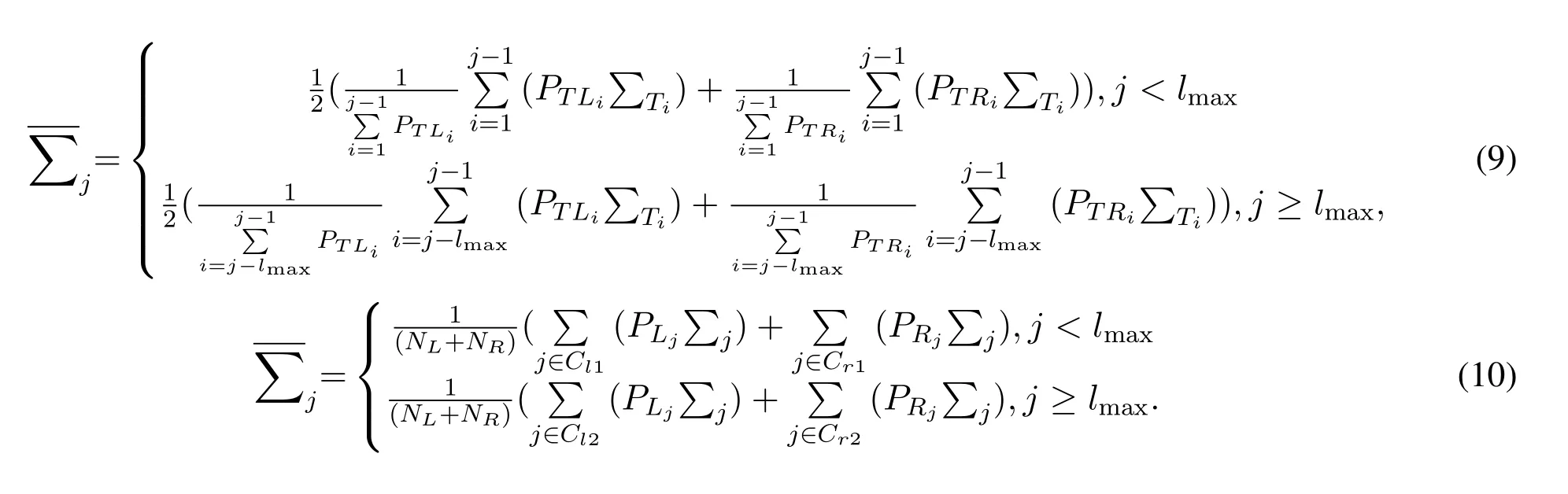
In (10),Cl1andCr1,Cl2andCr2respectively represent the set of samples labeled as left-hand and labeled as right-hand, and the classification probability of samples in the set is higher than 0.65.NLandNRdenote the number of samples in the corresponding set,PLiandPRidenote the SVM classification accuracy of the left-hand and right-hand samples.(10)solves the three problems in (9): First, the denominator is chosen as the sum of the number of samples from the left-hand testing set and the right-hand testing set,which avoids the problem that the poorer samples instead produce higher weights.Then the classification probability of samples inCl1,Cr1,Cl2andCr2are higher than 0.65, discarding the poorly performing samples.Finally a single sample only participates in the calculation of the covariance of the left-hand or right-hand.
III.RESULTS
The feature distribution of the training set and testing set data before and after applying the improved KL domain adaptation algorithm for subject A01 is shown in Figure 4 and Figure 5,respectively.
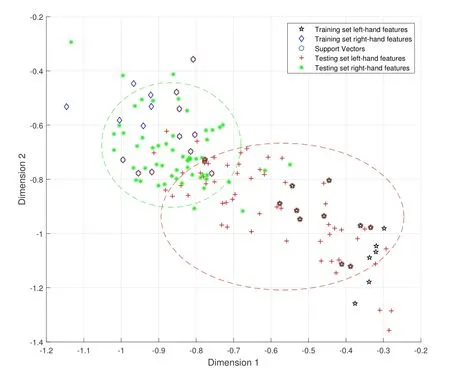
Figure 4.Feature distribution before applying the proposed domain adaptation algorithm.
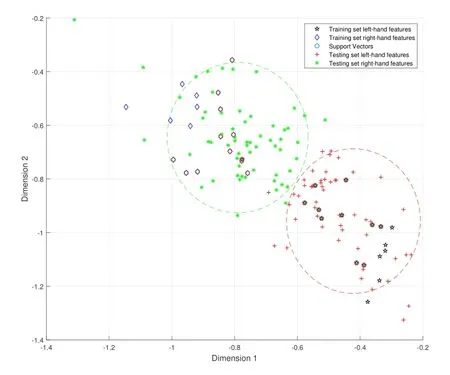
Figure 5. Feature distribution after applying the proposed domain adaptation algorithm.
In Figure 4 and Figure 5,the red+denotes the lefthand features of the testing set; the black⋆denotes the left-hand features of the training set; the green *denotes the right-hand features of the testing set; the blue ♢denotes the right-hand features of the training set.The range of red circle is the feature distribution of the left-hand data of the testing set, and the range of green circle is the feature distribution of the righthand data of the testing set.It can be seen that the feature distribution of the new testing set after applying the domain adaptation algorithm has changed significantly compared with the feature distribution of the original testing set.The centroid and mean offset distance of the feature distribution of the training set,the original testing set,and the new testing set are listed in Table 2.
From Figure 4,Figure 5 and Table 2,we can see that after applying the domain adaptation algorithm, the feature interleaving phenomenon originally caused by feature transfer has been significantly improved, and from Figure 5,we can see that the left-hand and righthand feature distributions of the new testing set have a clear boundary, and the left-hand and right-hand features can be clearly divided.Additionally,the feature distribution of the left-hand of the new testing set is closer to the feature distribution of the left-hand of the training set.In Table 2, the centroid of the lefthand feature distribution of the testing set is changedfrom (-0.61, -0.89) to (-0.47, -0.93), which is closer to the centroid of the left-hand feature distribution of the training set (-0.43, -0.99) and the average offset distance is reduced from 0.26 to 0.23,which is closer to 0.20.The changes in both parameters indicate that the domain adaptation algorithm has a significant improvement on the feature transfer problem.Finally,the improvement of the feature distribution of the righthand of the new testing set is not obvious.
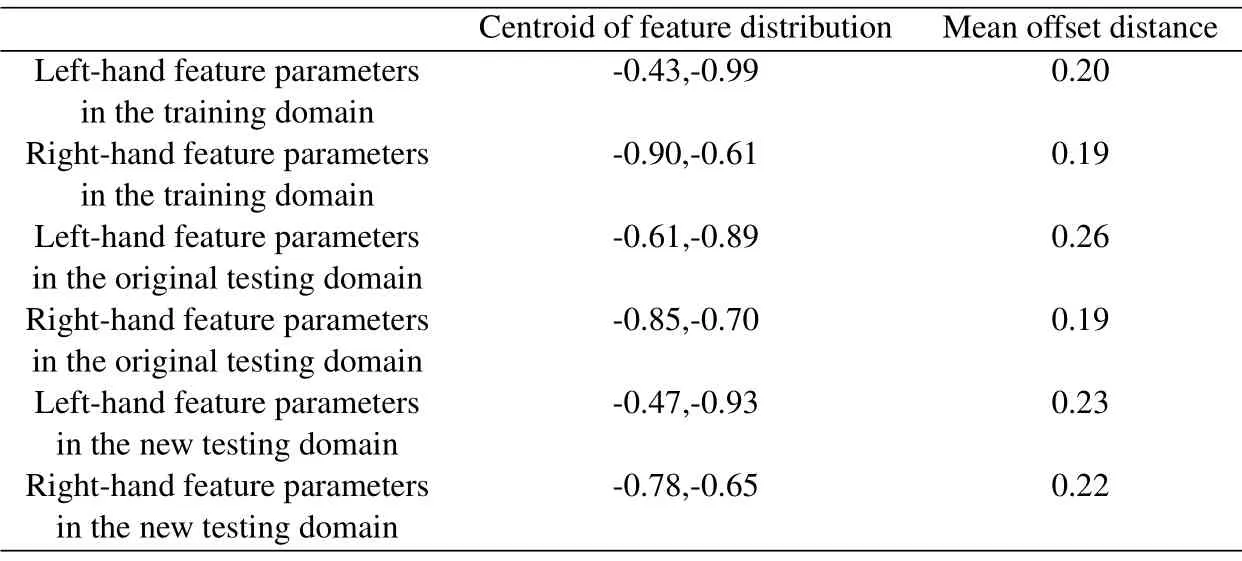
Table 2. Centroid and mean offset distance of A01 subjects’ feature distribution before and after applying the domain adaptation algorithm.
From Table 2, we can see that the feature distribution of the right-hand of the new testing set is not closer to the feature distribution of the right-hand of the training set.This is because the feature distribution of the right-hand of the original testing set does not differ much from the feature distribution of the right-hand of the training set,and the domain adaptation algorithm has no obvious improvement effect on distributions with small differences.
Table 3 shows the classification accuracies of all subjects before and after applying the domain adaptation algorithm.From Table 3, it can be seen that the classification accuracies of subjects A01, A02,A05,A06,A07 and A09 are improved,among which A01, A05 and A06 have a greater improvement with 7%, 7% and 8%, respectively.Additionally, for A03 and A08, whose original classification accuracies are above 90%, the classification accuracy does not get better,and A03 decreases by 1%instead.For subjects A02 and A04,whose classification accuracies are low originally, the proposed domain adaptation algorithm also has no obvious improvement.

Table 3. Comparison of classification accuracies before and after applying the proposed domain adaptation algorithm.
IV.CONCLUSION
In this paper,a domain adaptation algorithm based on improved KL is proposed to solve the problem of feature transfer in MI-BCI.In the proposed algorithm,SVM classification probability is innovatively used to classify and weight the covariance,and it is also used to distinguish good and poor samples and discard poor samples.The results show that the proposed algorithm has the ability to solve the feature transfer problem,and it is very effective for subjects with medium or poor classification accuracy performance.However,for subjects with very poor performance in classification accuracy, such as A02 and A04, the algorithm fails to improve their classification accuracy.In addition, the algorithm is less effective for subjects with high classification accuracy performance.As the dataset in this paper is from a single experiment, feature transfer problem is not obvious, and if the proposed algorithm is applied to scenarios where MI-BCI needs to be used for a long time, the improvement in classification accuracy will be more obvious.
In terms of the results, there is room for improvement in the classification accuracies of the 9 subjects in this paper.First, the number of training set can be varied.In order to facilitate the processing and to be able to make comparisons, the first 34 times of data are used as the training set uniformly in this paper,but setting the optimal number of training set for different subjects can lead to higher classification accuracy.The second problem is the selection of samples.Samples with classification accuracy below 0.65 are discarded in (10).0.65 was chosen as the optimal choice for subject A01,but there are better choices for other subjects.In addition, this paper only investigates the improvement of the improved KL algorithm for single subject,and the proposed algorithm can be applied to multiple subjects in the future to explore the performance of the proposed domain adaptation algorithm between multiple subjects.Moreover,the algorithm proposed in this paper can be applied not only in motor imagery braincomputer interface,but also useful in other situations.Finally,the algorithm proposed in this paper uses KL as a measure,and it is also a valuable direction to apply other measures in domain adaptation algorithms in the future.
ACKNOWLEDGEMENT
Authors appreciate Prof.Xuejun Sha,Dr.Lin Mei and Lab students including Zirui Lu, Xinbo Gao for their time on discussions and useful comments on the draft.

- China Communications的其它文章
- A User-Friendly SSVEP-Based BCI Using Imperceptible Phase-Coded Flickers at 60Hz
- Steady-State Visual Evoked Potential(SSVEP)in a New Paradigm Containing Dynamic Fixation Points
- Toward a Neurophysiological Measure of Image Quality Perception Based on Algebraic Topology Analysis
- Removal of Ocular Artifacts from Electroencephalo-Graph by Improving Variational Mode Decomposition
- BCI+VR Rehabilitation Design of Closed-Loop Motor Imagery Based on the Degree of Drug Addiction
- E3GCAPS:Efficient EEG-Based Multi-Capsule Framework with Dynamic Attention for Cross-Subject Cognitive State Detection