
E3GCAPS:Efficient EEG-Based Multi-Capsule Framework with Dynamic Attention for Cross-Subject Cognitive State Detection
2022-03-01 00:11YueZhaoGuojunDaiXinFangZhengxuanWuNianzhangXiaYanpingJinHongZeng
China Communications 2022年2期
Yue Zhao,Guojun Dai,2,Xin Fang,Zhengxuan Wu,Nianzhang Xia,Yanping Jin,Hong Zeng,2,*
1 School of Computer Science and Technology,Hangzhou Dianzi University,Hangzhou 310018,China
2 Key Laboratory of Brain Machine Collaborative Intelligence of Zhejiang Province,Hangzhou 310018,China
Abstract: Cognitive state detection using electroencephalogram (EEG) signals for various tasks has attracted significant research attention.However, it is difficult to further improve the performance of crosssubject cognitive state detection.Further, most of the existing deep learning models will degrade significantly when limited training samples are given,and the feature hierarchical relationships are ignored.To address the above challenges, we propose an efficient interpretation model based on multiple capsule networks for cross-subject EEG cognitive state detection,termed as Efficient EEG-based Multi-Capsule Framework (E3GCAPS).Specifically, we use a selfexpression module to capture the potential connections between samples, which is beneficial to alleviate the sensitivity of outliers that are caused by the individual differences of cross-subject EEG.In addition, considering the strong correlation between cognitive states and brain function connection mode,the dynamic subcapsule-based spatial attention mechanism is introduced to explore the spatial relationship of multi-channel 1D EEG data, in which multichannel 1D data greatly improving the training efficiency while preserving the model performance.The effectiveness of the E3GCAPS is validated on the Fatigue-Awake EEG Dataset (FAAD) and the SJTU Emotion EEG Dataset (SEED).Experimental results show E3GCAPS can achieve remarkable results on the EEG-based cross-subject cognitive state detection under different tasks.
Keywords: electroencephalography (EEG); capsule network;cognitive state detection;cross-subject
I.INTRODUCTION
Since electroencephalogram(EEG)is regarded as the signals that can best reflect the cognitive activities of the human brain,and therefore considered to be a crucial indicator in the tasks of cognitive state detection[1].Recently, EEG-based cognitive state recognition methods have attracted more and more research attention because of their high temporal resolution, noninvasiveness, and relatively low financial cost.The existing EEG-related works have been widely used in cognitive state detection under different tasks[2],such as disease diagnoses,driver fatigue state detection[3–5]and emotion recognition[6].
Traditionally, machine learning (e.g., SVM, KNN,ANN) combines feature extraction methods to extract and analyze EEG potential features [7], and identifies different cognitive states for different tasks.Most of these earlier methods use EEG to detect cognitive states for intra- or inter-subject [8, 9], in which intra-subject EEG-based detection is sessionto-session generalization for the same subject and that of inter-subject is cross-session generalization by mixing sessions from different subjects together respectively[10].However,due to significant individual differences, low signal-to-noise ratio, and non-linearity characteristics of EEG signals,the performance of the above mentioned methods might degrade heavily in cross-subject analysis[11],which hinders the development of potential EEG-based cognitive state detection across subjects.
Recently, deep learning (DL) has shown great promising in helping make sense of complex EEG signals due to its capacity of good feature representations[12].However,in order to achieve better performance of DL-based neural network,it requires a larger amount of data,a deeper network,and a more complex structure, which is why the current DLs may not be optimal for cross-subject EEG analyzing.Specially,for the classical CNN and its variants,it is difficult to establish an inherent mechanism in explicitly learning or interpreting the correlations between EEG features and cognitive states[13].That’s why they may not be readily applicable to analyze cross-subject EEG data with strong correlations in the spatial level.
The capsule network proposed by Hinton [14] is a kind of interpretable architecture, which adopts a new ‘vector in vector out’ feature information transmission strategy and introduces the dynamic routing algorithm to describe the relationships between the part (vector representations of features in the underlying layer) and the whole (vector representations of features in the overlying layer).In addition, its dynamic routing mechanism can even obtain better performance with limited training samples.Some recent works have applied the capsule network and its variants for EEG-based analysis,such as emotion recognition [15], driver vigilance estimation [16], motor imagery classification[17],etc.
Despite the existing capsule-based methods have made rapid progress, there are still many challenges in cross-subject EEG analysis.Firstly, for crosssubject EEG analysis,the weakness of the original dynamic routing algorithm is sensitive to outliers that are caused by significant individual differences of EEG.Secondly, although the existing dynamic routing process can describe the hierarchical relationship from the part to the whole,it can not interpret the inter-part interaction in the underlying layer.Specific to the multichannel EEG analysis,it is difficult to describe the interaction between EEG channels.Theoretically,there is a strong correlation between cognitive states and brain function connection mode, and different cognitive states lead to variations in the activities of different brain functional areas.In particular, the capsule network sacrifices training performance to achieve its interpretability.How to improve the training efficiency while preserving the performance of the capsule network is still a problem to be solved.
In response to the above mentioned challenges, we propose a novel efficient multi-capsule framework with dynamic attention for EEG-based cognitive state detection,namely Efficient EEG-based Multi-Capsule Framework (E3GCAPS).The main contributions of our study are as follows:
1.Considering the interaction between different EEG channels,multi-channel 1D EEG features,instead of commonly adopted 2D features, are extracted as input of E3GCAPS, which not only retains the potential feature information between channels, but also significantly speeds up the training process.
2.Introducing the self-expression module.The module computes the category coefficients by considering the potential connections between different samples to weight the capsule routing module,it is beneficial to alleviate the sensitivity to outliers.In addition,an appropriate regularization algorithm is used to optimize the joint probability distribution of the batch samples,which can effectively avoid overfitting.
3.Proposing an improved dynamic subcapsulebased spatial attention algorithm (subcapsules are defined as vector representations of features in the underlying layer).Considering the strong correlation between cognitive states and brain function connection mode, we introduce the dynamic subcapsule-based spatial attention mechanism to explore the spatial relationships of multi-channel 1D EEG data.This novel algorithm can effectively characterize both the potential spatial relationships(inter-part)and the hierarchical relationships(part-whole)of EEG features.
The rest of this article is organized as follows.Section II provides a brief introduction of EEG-based related work.In Section III, the E3GCAPS framework is described in detail.Experimental results are shown in Section IV.Further, Section V discusses and analyzes all of the results.At last, conclusions are given in Section VI.
II.RELATED WORK
In recent years, deep learning (DL) techniques have received considerable attention for cognitive state detection with EEG signals, which can better characterize important discriminant EEG features that correlate with potential cognitive activities [18].Based on different task objectives, deep learning algorithms can be divided into several subcategories[19],mainly including discriminative DL (e.g., convolution neural network(CNN),recurrent neural network(RNN)),representative DL (e.g., deep belief network (DBN)),and generative DL (e.g., generative adversarial network(GAN)).Further,these DL-based methods have increased the interest in the field of brain-computer interface(BCI),including disease diagnoses[20],workload evaluation[21,22],emotion recognition[23],etc.For example, the improved CNN-based approaches were used to detect epileptic seizure[24,25];In[26],the DL method based on DBN was proposed for feature extraction and dimension reduction to improve the prediction accuracy for predicting the driver’s cognitive states.[27] presented a novel deep-RNN framework to predict the levels of cognitive load from EEG data by learning robust features, and [28] used long short term memory recurring neural network(LSTMRNN) to recognize EEG-based emotion.In order to track the mental changes during driving, [29] combined LSTM and GAN networks to improve the performance of the driver sleepiness detection task.
Neural networks based on DL have achieved superior performance in various fields.However, due to its lack of stratification and reasoning ability of spatial, DL recognition becomes difficult when the sample perspective changes.This is why it is necessary to provide enough and various (translation, reversal,etc.) data for network learning during network training.In order to make up for these shortcomings,Hinton proposed an interpretable capsule network (CapsNet)[14],which is more in line with the principles of human neurons.One of the advantages of the capsule is interpretable, which can represent the relationship between part features and the whole object [30].In addition, it can adapt to the learning task with small amounts of data, while achieving better performance.Further, various capsule-based improvement methods have been proposed to optimize the original CapsNet,e.g.,DeepCaps[31,13],Efficient-CapsNet[32],TransCaps[33].
Specifically, as a kind of interpretable model, CapsNet provides a new way to explain the correlations between cognitive states and their corresponding physical activities.In [34], emotion recognition from multiband EEG signals by using capsNet, which can extract the multidimensional feature information related to emotion states.In order to directly characterize the multi-level features from the raw EEG signals, [30] proposed an end-to-end framework named multi-level features guided capsule network to determine the emotional states.To address the limitations of the DL methods in analyzing EEG data, a novel method based on the capsule network to classify twoclass motor imagery signals was presented[35],which implicitly learned more robust and reliable features to achieve better performance than existing DL-based approaches.In [36], the method called EEGCAPS was presented to recognize EEG-based motor imagery tasks, which considered spectral as well as temporal resolutions of EEG signals.Due to the complexity of the capsule network, [37] proposed a novel capsule network compression method to distill EEG representations for affective computing by employing the knowledge distillation pipeline,and its goal was to distill information from a heavy model to a lightweight model.
In order to pay more attention to the relevant features of the input and less attention to the irrelevant features,some researchers utilize the interpretation of capsules to improve the attention algorithm or introduce the attention mechanism to optimize the performance of CapsNet-based methods.[16] used capsule attention to learn the part-whole hierarchical relationships in the representations of EEG and EOG.Indeed, the dynamic routing algorithm of the capsule network was considered to be a compact and robust attention algorithm [38], which could replace the traditional multi-step attentions with a better robustness in capturing the deep correlation.In order to further improve the efficiency of capsule networks, the efficient-capsnet with self-attention routing was proposed to prove that better performance could also be maintained with a small number of parameters in the visual field[32].However,all of the above mentioned works ignored the relationships between local capsules.Moreover,for the EEG data with significant differences across subjects,there are no efficient capsulebased framework to analyze cross-subject EEG data.
However,despite some works have made impressive progress,there is still space for considerable improvement with respect to several important aspects of EEGbased cognitive state detection[39],including the accuracy,interpretability,and efficiency for applications.Therefore, we propose a novel E3GCAPS framework to improve the performance on these aspects, which have been approved on the Section IV.
III.METHOD
Framework Overview:E3GCAPS is a novel efficient capsule-based multi-source domain interpretability framework for performing EEG-based cross-subject cognitive state detection under different tasks, as shown in Figure 1.In this section, we will describe E3GCAPS in detail, includinginput representation module, self-expression moduleanddynamic spatial attention routing.Firstly, theinput representation moduletransforms the dimensionality of the input data and extracts domain-invariant features across multiple sources with a shared common feature extractor.Secondly, theself-expression modulewith a fully connected layer receives the extracted domain-invariable features and calculates the output category coefficients, which can capture the potential connections between samples and effectively alleviate the sensitivity to outliers.The final category coefficients are used to constrain the capsule network to supervise the dynamic routing learning of the capsule network.Thirdly, an improved routing algorithm based on dynamic spatial attention, termed asdynamic subcapsule-based spatial attention routing,is designed as follows: considering the strong correlation of EEG at the spatial level, ECA-based attention weights(efficient channel attention,ECA)and the spatial-based prior probability are introduced to explore the inter-part spatial relationships in the underlying layer.Specifically,we train and optimize all modules in a unified framework so that three modules can benefit each other.
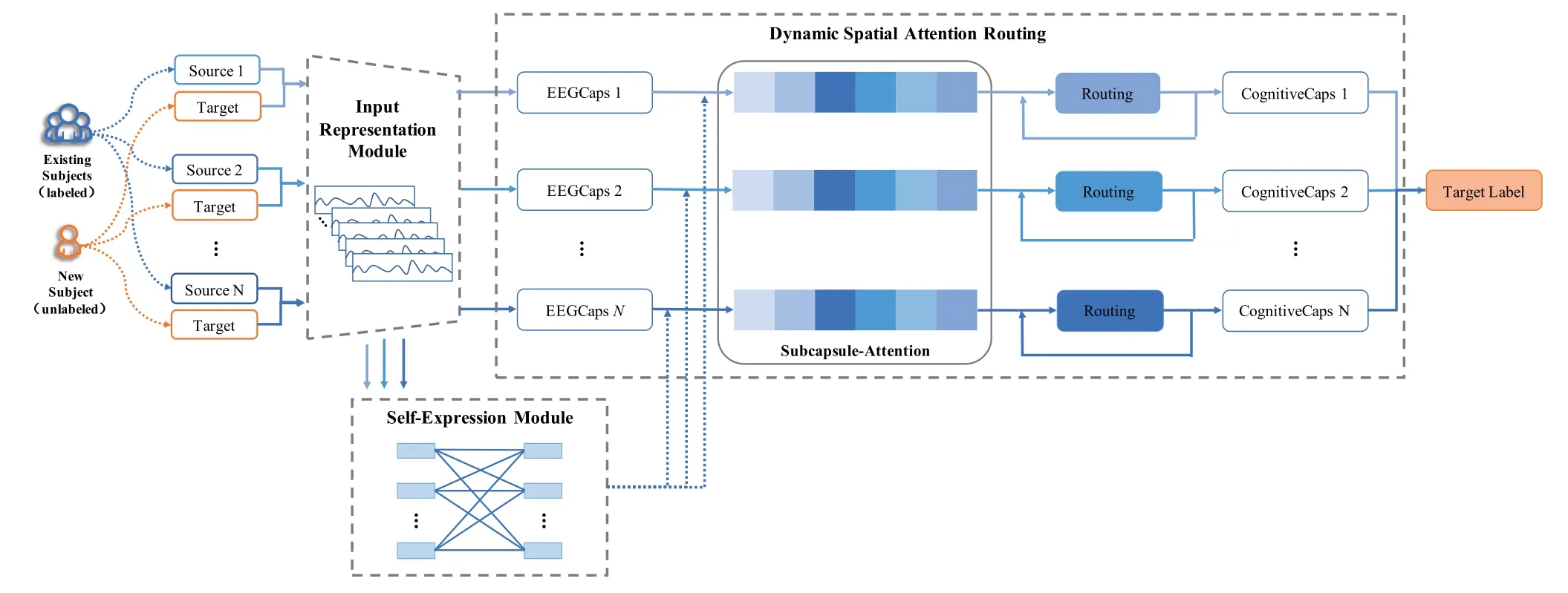
Figure 1. The framework of our proposed E3GCAPS for cognitive state detection.It includes three modules,input representation module,self-expression module,and dynamic spatial attention routing.
Symbol Definition:Before introduction, definitions of various symbols are given first:
•N: the number of source domains, equivalent to the number of subjects.For a particular EEGbased BCI task,there are N subjects,one of which is the target domain, and each of the remaining subjects is regarded as one source domain(a total ofN-1 source domains).

3.1 Input Representation Module
This module encodes the input EEG data as extracted domain-invariant features with the following steps.
Input Data:Considering the relationships among EEG channels, the commonly used 2D EEG data is transformed into multi-channel 1D structure while improving the training efficiency of the model.Therefore, we represent each sample as multi-channel 1D structurex ∈RChannels×1×Features,whereChannelsrepresents the number of channels ofxandFeaturesis the number of features per channel.
Features Extraction:For E3GCAPS based on multi-source domain adaptation, there are multiple capsule-based classifiers to learn domain-specific features between each pair of the source and target domain respectively.However,due to the significant individual differences of EEG across subject, it is difficult to extract domain-specific features directly.To address this issue, we first extract domain-invariant features for all samplesxi(x ∈{xsn,xt}) by a common feature extractor.Here, thepointwiseconvolution withbatch normalization(BN) andexponential linear unit(ELU) activation as the common feature extractorf(·) to perform the feature representations of multi-channel 1D data,which make effective use of spatial feature information between different channels.Finally, we obtain domain-invariant featuresZsnandZtfrom common feature extractor.
3.2 Self-Expression Module
For EEG data with significant individual differences and non-linearity characteristics, some outliers in the feature distribution degrade the model performance in the cross-subject analysis task.In order to effectively alleviate the sensitivity of outliers,the self-expression module is introduced to learn the potential connections between samples, the structure of which is depicted in Figure 2.The category coefficient output of this module is used to constrain the capsule network.The predicted category labels can simultaneously supervise the training of the feature extraction module.The module is designed with a fully connected layer(FC),regarded as a classifier that mapping the learned feature distribution to the sample label space.Finally,we obtain the category coefficientCfrom the output of this layer with a softmax function:
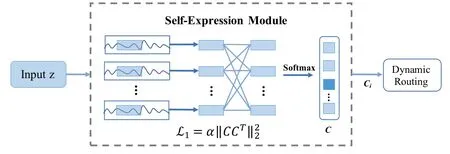
Figure 2. The structure of self-expression module in E3GCAPS.The self-expression module is expected to alleviate the sensitivity of outliers by considering the potential connections between samples,and its output category coefficient C is used to constrain the dynamic routing.

whereCidenotes the probability that the sampleibelongs to thekth category,Ci ∈[0,1]and=1.Andfϕis the transform of FC layer.Note that the category coefficientCioutput by the FC layer will be regarded as the category constraint of the capsule routings.
To effectively eliminate the dependence on a few data, a regularization item is added to constraint the coefficientCof self-expression.The improved regularization encourages classifiers to learn features on all dimensions to prevent overfitting and improve the generalization ability, it is suitable for EEG analysis with fewer samples.Further, we define the improved regularization as follows:
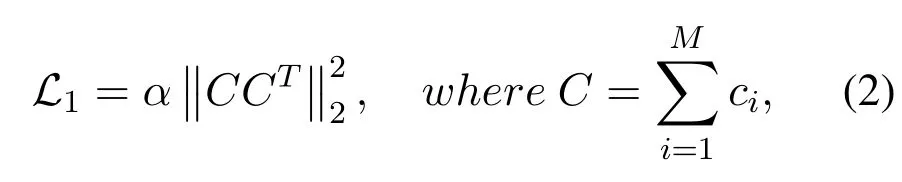
whereTrepresents matrix transposition,Mis the number of batch samples,andαis a hyper-parameter.In Eq.(2),CCTwill obtain the joint probability distribution between batch samples, and address the sensitivity of outliers by learning the relationship between samples.According to the literatures [40, 41], regularization is proposed for overfitting.In order to avoid the self-expression module outputting the same onehot vector for all samples,we use theL2 norm to limit the joint probability distribution space of the training sample set.TheL2 norm chooses the common features of the joint probability distribution to capture the correlation between samples, so as to realize the optimization of the self-expression module.It can prevent the model training from being too complex and effectively reduce the risk of overfitting.Therefore,we add theL2 norm to the joint probability distribution to prevent overfitting.And the joint probability distribution of batch samples is optimized by minimizing the loss of the regularization, so that each sample will be allocated to the dominant category space, and the sensitivity to outliers and the boundary points will be effectively alleviated.
3.3 Dynamic Spatial Attention Routing
In E3GCAPS, each classifier is designed by the interpretable capsule network to extract domain-specific features between each pair of the source and target domain for EEG-based cross-subject analysis,mainly includingEEGCaps,dynamic subcapsule-based spatial attention routing, andmargin loss, as shown in Figure 3.The domain-invariant features output by the common feature extractor are used as the input of multiple classifiers,which effectively extract various finegrained features of EEG.In addiction,considering the multi-scale information based on the attention mechanism,both the spatial relationships(inter-part)and the part-whole hierarchical relationships can be better expressed.
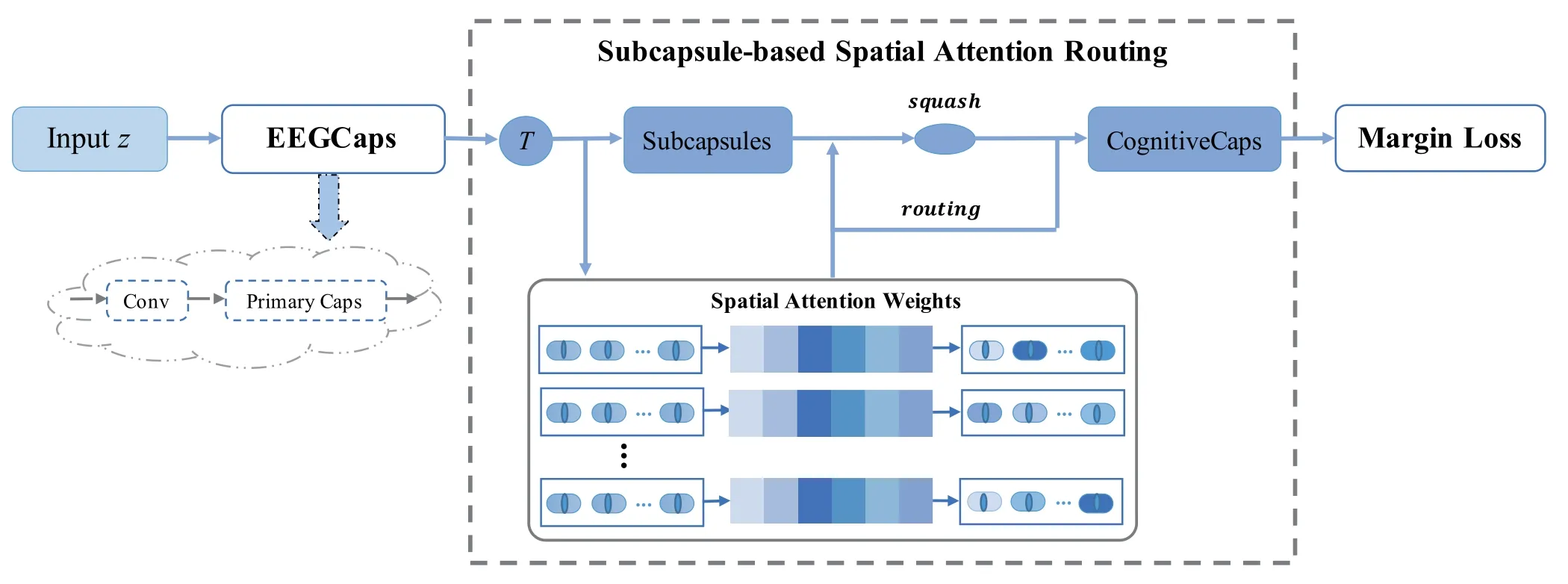
Figure 3. The structure of dynamic spatial attention routing in E3GCAPS.It consists of three parts, EEGCaps, dynamic subcapsule-based spatial attention routing,and margin loss.
EEGCaps:It consists of aConvlayer and aprimary capsule(PrimaryCaps) layer, termed as EEGCaps layer.For each EEGCap, before entering the primary capsule layer,we extract domain-specific features from the domain-invariant featuresZby designing a set ofConvlayer.We apply BN and ELU along the feature map dimension.This operation maps the domain-specific features onto a higher dimensional space that facilitates capsule creation.Then, expand the conventional function as the main instrument of PrimaryCaps to obtain the vector-output capsule layerwith theelsubcapsules and each subcapsule dimensiondlofl-th layer.
After that operation, the feature representation of the model is not anymore a single neuron but a vector capsule.To contrast the strength of features, here we compute the vector norm of the capsules to measure its own significance.The vector can represent each feature information,that is to say,the norm length of each vector can be used to represent the probability of the feature.Concretely, the significant features with the larger norm length.To normalize features,the norm is compressed to the range of 0-1 as a bounded measurement index.Overall, this operation is regarded as a non-linear activation function called squashing,which can be formulated as:
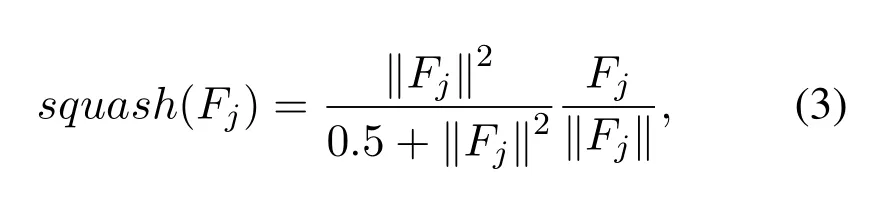
Subcapsule-based Spatial Attention Routing:The original capsule network constructs routing weight coefficients by updating parameters, thereby mapping the correlation between the underlying(part)features and the overlying(whole)features.However,this method depends on the parameter initialization and updating mechanism, which will affect the stability of the algorithm.Considering the strong spatial correlation of EEG signals,we introduce a spatial attention mechanism to constrain the dynamic routing coefficients,which is defined assubcapsule-based spatial attention routing.This method can capture the relationships on the spatial level,thereby learning the correlations between subcapsules and capsules.This constraint will be used as the initial value of the dynamic routing coefficient,which can effectively eliminate the dependence on parameter initialization and updating algorithms.In order to learn effective representations of prior information, we add a prior probability to the routing, which is updated based on the weight parameters of the model and is learned at the same time as the other weights of the model.
In E3GCAPS,we make use of our subcapsule-based spatial attention routing algorithm to route active subcapsules to the whole they belong, the detailed process is presented in Alg.1.Before entering the overlying layer, each subcapsule will be multiplied by a matrix for transformation.Matrix multiplication uses the weight matrixWto map the relative relationship between the underlying features and the overlying features.Considering the sensitivity of outliers,the category coefficientCicalculated above(Eq.(1))is introduced to constrain feature representations of the underlying layer and weight the mapping relationships between features.For each subcapsuleTiof the layerl,the projection formula is as follows:
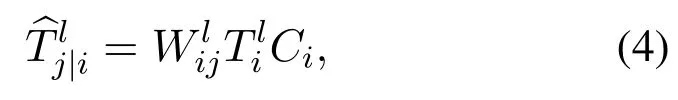
where the weight matricesWcontains all affine transformation between two adjacent layers,obtain subcapsuleTj|i.That is to say,the representations of the samples are mapped through these underlying features,so as to further determine the categories they belong to.After that,a weighted summation is performed on the subcapsules to measure the importance of the part features to the whole, that is, the dynamic routing process.Since the spatial relationships between subcapsules are ignored, we introduce the subcapsule-based spatial attention module to learn potential spatial characteristics.Indeed, capsules of the overlying layer,can be formulated as follows:
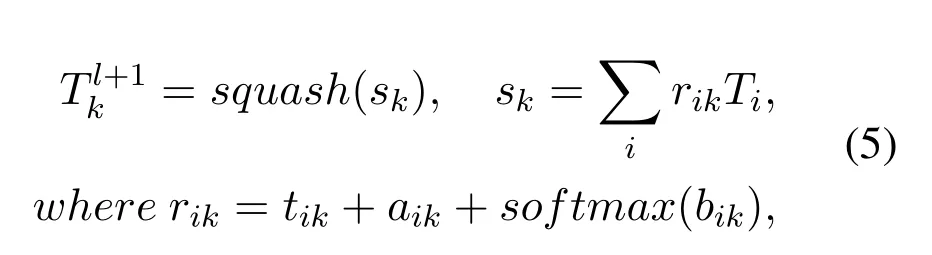
whererikis the matrix containing all coupling coefficients producing by the dynamic attention-based algorithm.Among them,tis the spatial attention weight calculated by learning the spatial relationships between subcapsules,ais the spatial-based prior probability matrix learned with all the other weights simultaneously, and the last itemsoftmax(bi) is the selfattention coupling coefficient used to detect features to the whole they represent (bicomputed in Eq.(6)).The integrated coupling coefficients of the attentionbased routing dynamically assign the part features to the whole by considering multi-scale feature information.By introducing these weights updating strategy,the inter-part and part-whole relationships between features can be considered, and so, the model can interpret the features in the samples more clearly.
Theoretically,the spatial attention weight of subcapsules is learned based on the efficient channel attention(ECA) mechanism.ECA is a lightweight channel attention module.The idea of the ECA module is to learn features directly by designing a 1D convolution that can be weight-shared to achieve a cross-channel(spatial level)interaction strategy without dimensionality reduction.In order to capture the potential spatial relationships between subcapsules, the ECA mechanism is introduced to learn the subcapsule-based spatial attention weightst.

Algorithm 1. Attention-based routing algorithm.Require:Subcapsule feature matrix Tli,category coefficient representation C,spatial-based prior probability matrix a Ensure:The output capsule Tl+1 1: Initialize prior matrix,the W and a, ˆT(0)j ←WlijTli Ci 2: Initialize bij =0 3: for r iterations do 4: obtain subcapsule-based attention coupling coefficient: ci ←tik+aik+softmax(bi)5: obtain weighted-sum feature: sk ←images/BZ_88_929_1030_973_1071.png i rikTi 6: obtain output capsule: Tl+1 k ←squash(sk)7: update routing agreement: bi ←cos(Tl+1, ˆTl)+bi 8: end for 9: return Tk
For the itembi, when updating the model parameters, the underlying featuresand the overlying capsule featuresTl+1are considered comprehensively.The self-attention coupling coefficients are computed from the self-attention tensor:
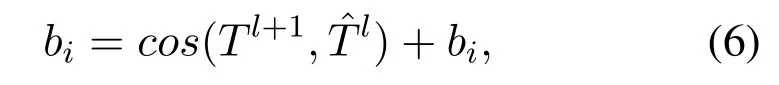
wherecos(·)represents the cosine similarity function,cosevaluating their similarity by calculating the cosine of the angle between vectors, which can effectively measure the spatial difference of sample features.Theoretically, the higher the similarity between the two,the better the subcapsule features can represent the characteristics of the whole sample.
Margin Loss:Finally, the output layer is represented by K vectors (i.e., K capsules).These K vectors represent the categories of cognitive states, and the norm length of each vector represents the probability that a cognitive capsule exists.Indeed,the norm length should be close to one if the cognitive state it represents is the only one present in the samples.Therefore, to allow multi-category, a separate margin loss functionLcapis given for each capsule of the characterization category.The formulate is shown below:
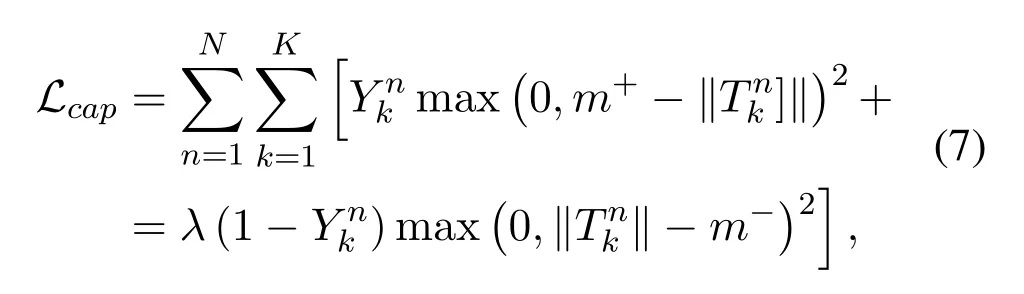
whereYkis equal to one if the categorykis present,m+,m−andλare hyperparameters and set to 0.9,0.1 and 0.5,respectively.Among them,Ykis the indicator function of classification (Yk= 1 if a cognitive state of the categorykis present, otherwiseYk= 0),m+is the upper bound,penalizing false negative(the case where the existence of the category is not predicted),m−is the lower bound,and penalizing false positives(the case where a non-existent category is predicted).λis the proportion coefficient,which is used to ensure the stability of values during training.Then, the total margin loss is the sum of the loss of each recognition capsule.
IV.EXPERIMENTS
In order to evaluate the performance of our proposed E3GCAPS for cognitive state detection, we conduct extensive experiments on two cognitive EEG datasets.The first one is the Fatigue-Awake EEG dataset collected by the industry and neural science laboratory in University of Rome Sapienza[42,43], while the second one is the publicly SJTU Emotion EEG dataset(SEED)[44–46].
4.1 Datesets
Fatigue-Awake dataset:The Fatigue-Awake dataset(FAAD) was approved by the local ethics committee of University of Rome Sapienza (Rome, Italy).In FAAD, there were 15 healthy subjects aged 23 to 25.The immersive driving platform used Alfa Romeo Giulietta QV was designed to perform driving tasks under different conditions.One of the tasks, called alert and vigilance (TAV), was introduced with additional video and audio (simulate real-world traffic jams)to stimulate the awake state during driving.After completing this task, another of the most boring and monotonous task,namely DROW,was finally performed without any stimuli,which induced the mental state prone to fatigue.Hence,the collected EEG data of fatigue and awake states were used for cross-subject analysis.EEG data were recorded using a digital ambulatory monitoring system (Brain Products GmbH,Germany)from 61 active electrodes conforming to the international 10-20 system,and all the electrodes were referenced to the earlobes.The data was sampled at 200 Hz.
SEED dataset:The SEED dataset consisted of 15 subjects that aged 23.27±2.37 years.Movie slips were selected to stimulate the real emotions on a three-level scale: positive, neutral, and negative emotions, each of which was distributed over five slips.Then, there are 3 sessions for each subject and 15 EEG trails for each session.The EEG signals were recorded using a 62-channel Neuroscan electric source imaging device followed the international 10-20 system,and the reference electrode was near the top of the head.The sampling rate was 1000 Hz,as well as the down-sampling rate was 200 Hz.In addition,to make sure that the real emotions of the subjects maintained consistent with the expected emotions, the subjective self-assessment was carried out for each subject simultaneously.
4.2 Preprocessing
After collecting EEG data, the raw data were preprocessed,mainly including denoising and feature extraction,as shown below.
Fatigue-Awake dataset:For the raw EEG data,a bandpass filter with a range of 1-30 Hz and independent component analysis(ICA)was applied to filter the noise and remove the artifacts, respectively.Then, the data of each channel were divided into segments with 0.5 s sliding windows.Each channel would be conducted with 1400 segments,and the total number of segments for 15 subjects would be 21000(15×1400).Due to the 200 Hz sampling rate, the length of each segment was 0.5×200=100.Finally,we used power spectral density (PSD) to characterize the EEG segments [47].For the FAAD, the main task was to detect fatigue-related cognitive states,and existing studies [48, 49] have indicated that the EEG power of theta (4-7 Hz), alpha (8-13 Hz), and beta(14-30 Hz)bands can reflect the mental states changes during driving.Hence, three frequency bands (theta,alpha, and beta) were selected as the neurophysiologic indexes for characterizing fatigue-related cognitive states.For each segment,all the frequencies in 61 channels were characterized by 61×27=1647 feature dimension.
SEED dataset:The raw EEG data were downsampled to 200 Hz.To further filter the noise and remove the artifacts, the data were preprocessed with a bandpass filter (0-75 Hz).After that, each channel of the data were divided into 842 segments with 4 s sliding windows, and the total segments number of 15 subjects in each session was 12630 (15×842), in which the length of each segment is 4 s×200 Hz=800.In order to be consistent with the above,we also adopted the PSD method to extract features of each segment.For the SEED, the main task was to recognize three categories of emotion states.Refer to the existing works [45, 50], the significant EEG activities often happen in four frequency bands, including theta (4-7 Hz), alpha (8-13 Hz), beta (14-30 Hz), and gamma(30-45 Hz).Therefore, these four frequencies bands were selected to recognize emotion states.Finally,the feature dimension of each segment with 62 channels was 62×42=2604.
4.3 Baselines
In our experiments, for the EEG-based cross-subject cognitive state detection tasks,we mainly compare our E3GCAPS model with the following existing models: (1)traditional machine learningmethods, e.g.,Support Vector Machines(SVM)[51],and K-Nearest Neighbor (KNN) [52]; (2)multi-source deep learningmethods,including CNN[53],EEGNet[54],Capsule network (CapsNet) [34].For each multi-source deep learning model,one of the unlabeled subjects of the EEG dataset as the target samples for testing, the remaining labeled subjects as the source domains for training,each of which is regarded as an independent source domain used to train a specific classifier.Further,considering that the ensemble is an effective way to improve the model generalization ability [55], we utilize the voting strategy to integrate the classifiers from all source domains to make final decision results for the new unlabeled target samples.Subsequently,we performN(subjects number of each dataset)times experiments, the average results of which are used to evaluate the performance of each compared model.In the following experiments, the classification task of FAAD is two cognitive states (fatigue and awake),while cognitive states of SEED are divided into three categories(positive,neutral,and negative).
4.4 E3GCAPS Evaluation
4.4.1 The Number of Source Domains
For the multi-source model of cross-subject EEG analysis, each subject is regarded as the independent source domain, as well as corresponding with a specific classifier.More sources mean we ensemble more classifiers to predict the new target subject.To verify the effect of different source numbersNson the multi-source model,we perform the model to statistic both the best and worst situations as the floating interval of accuracy.The best represents that we select the most similar cases between the source and target subjects to train the model.Conversely,select the subjects with the biggest difference to complete the worst performance of the model.In other situations of subject selection, the accuracies fluctuate within this interval shown in Figure 4.
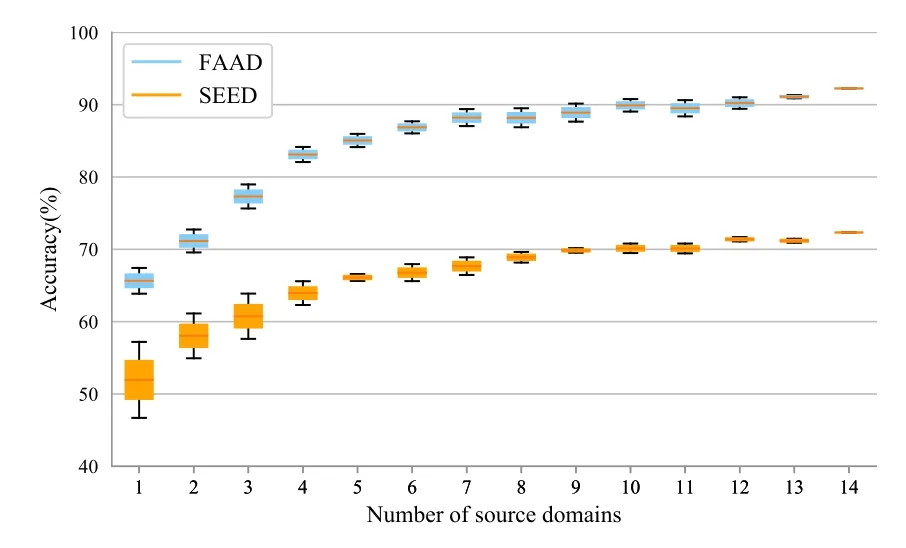
Figure 4. Accuracy of our proposed E3GCAPS model with different number of source domains on FAAD and SEED datasets.
From both on FAAD and SEED datasets,asNsincreases from 1 to 6, the accuracy of the model rises sharply and follows a stable growth, which indicates more sources can learn more specific information to encourage better performance.WhenNsis 14, the best performance is achieved on both two datasets.For SEED, the early large-scale fluctuation means that there are more significant individual differences among subjects than FAAD dataset.
4.4.2 Auxiliary Training Data Ratio
To improve the transferability of the model, learning the feature distributions of target samples in the training process is an effective way.Therefore,in this article, we set a parameterλfor the unlabeled target domain,which is the ratio of unlabeled auxiliary training data randomly selected from the target samples.They are used to assist the source domains to train the classifiers by learning the feature distributions,and the remaining unlabeled data in the target domain will be used for testing in the target domain.Whenλis 0, it means all the target samples are used for testing and no data can be used to assist training.While the setting ofλis 1, all target samples are used not only as the test set but also for auxiliary training.
Figure 5 shows the accuracies with different ratios of auxiliary training data both on FAAD and SEED datasets.For the FAAD dataset,as theλincreases the accuracy improves steadily.The results of E3GCAPS on SEED show that the auxiliary training data have a continuing influence on the performance.From the analysis in the previous section,we can find that there are great individual differences in SEED data.Further, the results prove that the auxiliary training data from target samples can efficiently assist the source domains to train the classifiers by learning the feature distributions of auxiliary training data,so as to achieve better performance.Therefore,it can be used as an effective way to eliminate the negative impact of EEG data with significant individual differences.
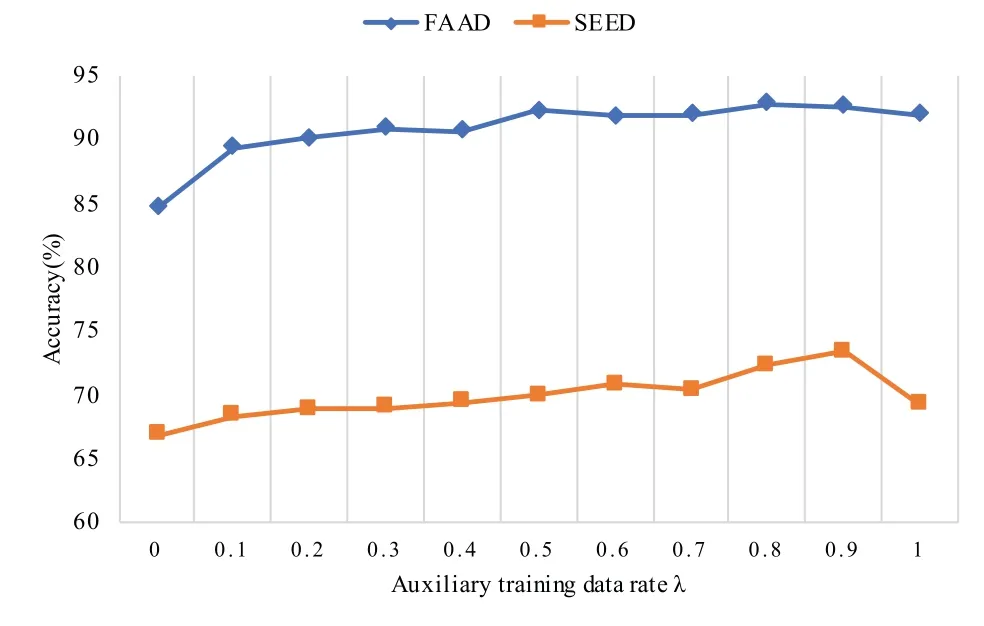
Figure 5. Performance of our proposed E3GCAPS model with different auxiliary training data ratio on FAAD and SEED datasets.
4.4.3 Ablation Exprements
The effect of feature structure with multi-channel 1D.In general, the input data of most existing mod-els are mapped into 2D liking single-channel images.We compare it with our multi-channel 1D input data of E3GCAPS, experimental results summarize in Table 1.All comparison methods are based on multisource domain structure.To indicate the performance of each structure both on FAAD and SEED datasets,we take different aspects into account,including training time(i.e.,the total time spent on training and testing), classification accuracy, and training parameters of the model.From Table 1, it can be found that the training time of the model with multi-channel 1D data is faster than that of 2D, which takes about 385s on FAAD, while for feature structure with 2D, the training time increases to 618s.In terms of total parameters,the CapsNet with 2D input data requires the most parameters during training,while the accuracy of CapsNet with multi-channel 1D data structure (ours) is still outperforming the 2D one by 9.44% with only 7%parameters.Simultaneously,on SEED,the multichannel 1D feature structure greatly reduces the number of parameters and training time, while achieving higher accuracy.

Table 1. The ablation experiments of our proposed E3GCAPS.
The effect of self-expression module(SE).To verify the effectiveness of the SE module,we perform the ablation experiments that only considering SE module of E3GCAPS,as shown in Table 1 experiments#2 and #3.The SE module is introduced to capture the potential connections between samples, and we can observe that ours-SE provides an improvement in accuracy with 6.66% and 2.92% for FAAD and SEED,respectively,and there is a slight increase in time and parameters.Therefore,we conclude that the SE module can extract effective features to alleviate the sensitivity to outliers.
The effect of dynamic subcapsule-based spatial attention.To illustrate the effectiveness of the proposed dynamic subcapsule-based spatial attention algorithm on spatial relationships’learning,ablation experiments are performed to compare the performance between different modules.Form Table 1 experiments#3 and #4, it can be found that ours-E3GCAPS displays the highest accuracy both on FAAD and SEED datasets,which further exceed ours-SE by 1.51%and 2.17%.In this module, we introduce the ECA-based strategy to weigh the inter-part attention coefficient,which is the reason for the increase of training time and parameters.Overall, our proposed E3GCAPS is still able to achieve state-of-the-art results with higher efficiency on two datasets.
4.4.4 Training Samples Scale of Source domains
Most existing DL-based methods are limited by the amount of training data,model performance degrades heavily when samples are scarce.To address the above issue,we propose a novel interpretable framework that can achieve better performance with fewer samples to learn.In this section, to verify the effectiveness of E3GCAPS on training with fewer samples, we perform the E3GCAPS under different scale of training samples.We denoteδas training model on the randomly selectedδpercent of each subject,the remaining samples are dropped.From the results shown in Figure 6,we can find that with the reduction of training sample scale, the average classification accuracy fluctuates around 1% of all training samples (δ= 0)performance on FAAD.For SEED dataset, the accuracy increases when the sample size is limited,and the biggest gap is 7.52%.This indicates that our model can maintain or even improve the performance when the limited training samples are given.
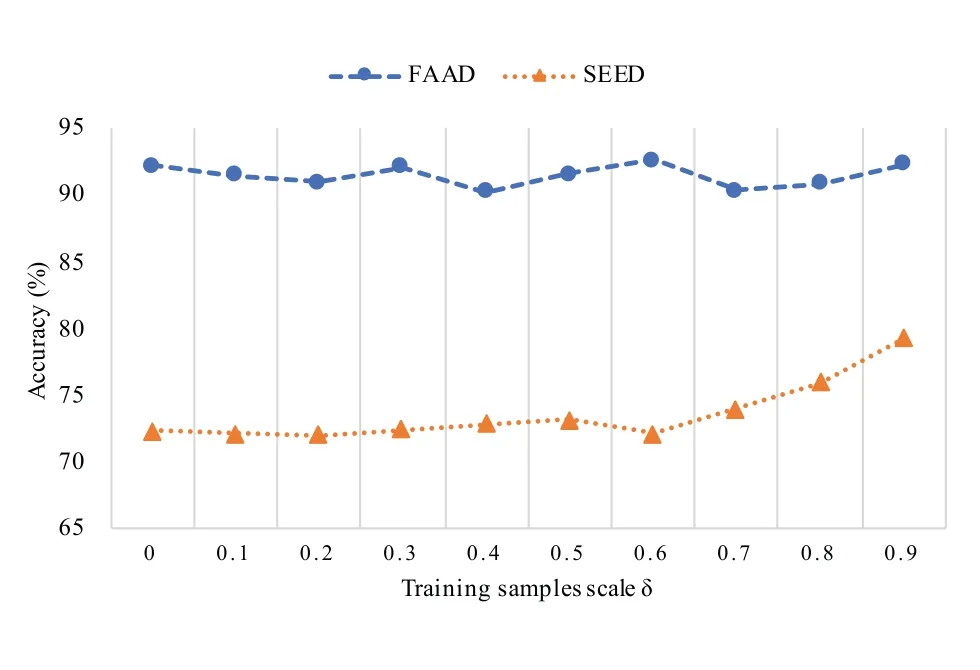
Figure 6. Performance of our proposed E3GCAPS model on FAAD and SEED datasets when the training samples scale is reduced.
4.4.5 Individual Performance
Transfer with multi-source domains.E3GCAPS is associated with the multi-source domain framework, where each subject is regarded as an independent source domain and a new subject is seen as the target domain.In another way, combing all available subjects as a single source domain.We compare the model performance of cross-subject analysis between single-source domain model and multi-source domains model.Results on both FAAD and SEED datasets are shown in Figure 7 and Figure 8, respectively.It can be found that the model based on multisource domain outperforms than the single-source domain model on each subject.The average accuracy of multi-source-based model beats that of single-sourcebased model by a margin of 15.1% and 6.38% on FAAD and SEED datasets, respectively.The significant advantage of multi-source domain model show that design models based on multi-source is more favorable to obtain the better performance.
Individual performance for cross-subject analysis.To show the results more intuitively for E3GCAPS,we display the individual performance for cross-subject EEG analysis task in this section.For FAAD dataset, the fatigue status detection task with two categories, the average accuracy of 15 subjects achieves 92.74% on FAAD dataset, as shown in Figure 7.Among 15 subjects of FAAD, almost all subjects have accuracy higher than 85%,except subject 1 and 11.For SEED dataset, the emotion classification task with three categories,the results of E3GCAPS are shown in Figure 8.Under cross-subject EEG analysis,the average accuracy of all 15 subjects is 71.70%.There are only two subjects(2 and 12)lower than 67%in terms of classification accuracy.
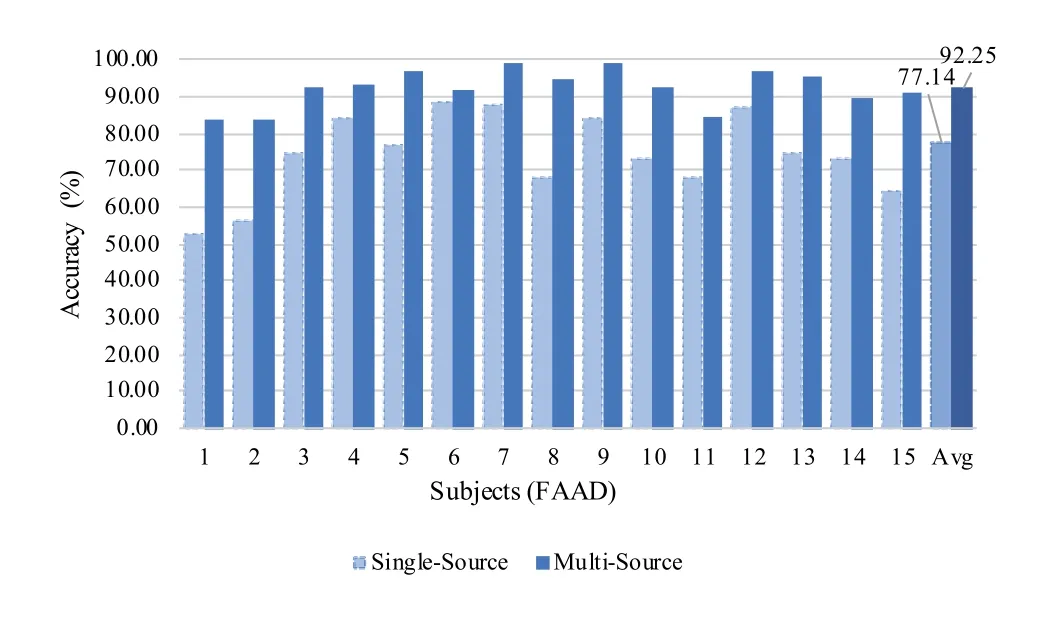
Figure 7.Individual performance of our proposed E3GCAPS model with single-and multi-source domains on FAAD dataset.
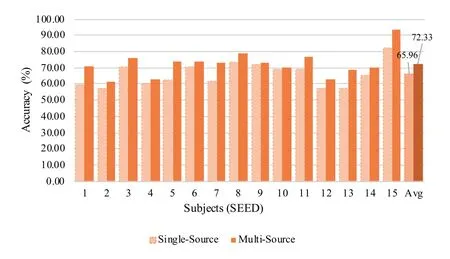
Figure 8.Individual performance of our proposed E3GCAPS model with single-and multi-source domains on SEED dataset.
4.4.6 Method Comparison
Table 2 presents the performance of our proposed E3GCAPS in comparison to the aforementioned baseline methods (see Section 4.3) for two EEG-based cognitive datasets.Besides, based on the confusion matrix, we select Accuracy, Precision, Recall, and F1score as the metrics to further evaluate the model performance,which are the average values of all subjects on each dataset.Compared with various methods, it is observed that E3GCAPS achieves state-ofthe-art results by outperforming both classical MLbased methods and multi-source DL methods.
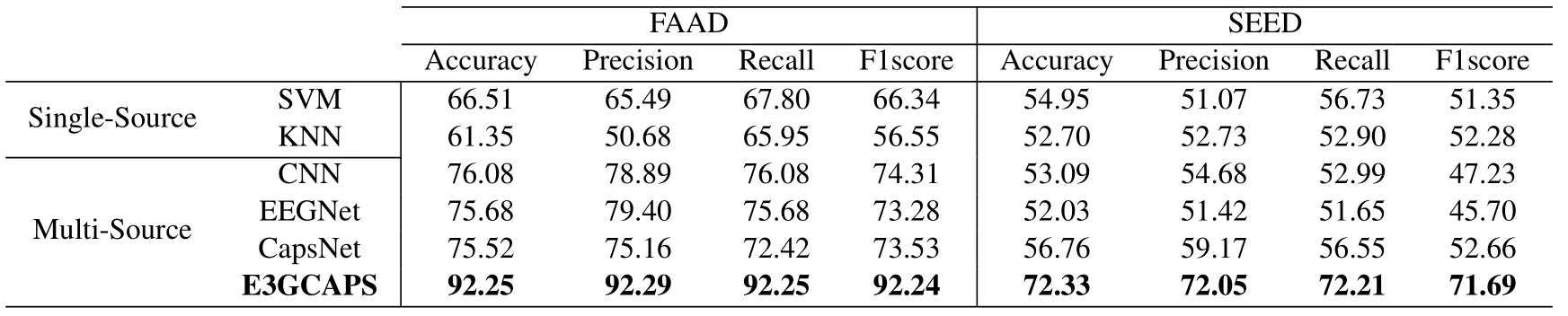
Table 2. Accuracies achieve with different methods.
The comparison of ML-based methods, including SVM and KNN, are used as the baseline models to upgrade the classification accuracy and verify the ef-fectiveness of datasets.On this basis, the classification accuracy of E3GCAPS is sharply rise, which reaches 92.25% on the FAAD dataset and 72.33%on the SEED dataset.For the DL-based comparison methods,to maintain the consistent structure with E3GCAPS,the multi-source structure is adopted.The details are described below:
1.From the view of interpretation.CNNis a kind of data-driven neural network with depth structure and convolution computation[56].It adopts the pooling operation to reduce training parameters, as well as the ’scalar in scalar out’ transmission strategy to process feature information.To verify the interpretation of our E3GCAPS on hierarchical relationships’ learning, we compare it with traditional CNN models.The results are shown in Table 2, CNN gets the worse performance,which is lower than E3GCAPS by 16.17%on FAAD and 19.24% on SEED.Therefore, we conclude that E3GCAPS can capture the partwhole hierarchical relationships of EEG with significant individual differences effectively,reasons that E3GCAPS outperforms CNN.
2.From the view of generalization.EEGNetis a general and compact CNN-based network designed for EEG-based recognition tasks [54].It utilizes depthwise conv and separable conv to decrease the number of convolution parameters,so as to improve the training efficiency and reduce the possibility of overfitting.In order to compare the generalization ability of EEGNet and our E3GCAPS in cross-subject EEG analysis, we perform the classification tasks on two datasets respectively.In the experiments, all the input data are consistent, the results show that E3GCAPS achieves the best performance both on FAAD and SEED datasets.E3GCAPS exceeds EEGNet by 16.57% and 20.3% for crosssubject EEG cognitive state detection on FAAD and SEED, respectively.In addition, the other metrics of E3GCAPS also outperform EEGNet on both datasets.Finally, we conclude that E3GCAPS possesses better generalization ability than EEGNet, and achieves better performance in cross-subject analysis under different cognitive state detection tasks.
3.From the view of efficiency.CapsNetis an interpretation model with a ’vector in vector out’transmission strategy and the dynamic routing algorithm [57], which can effectively capture the hierarchical relationships between samples.E3GCAPS is an efficient variant CapsNet,which further presents a new dynamic subcapsule-based spatial attention algorithm to learn fine-granted spatial feature information on the spatial level.In order to adapt to the complex EEG signals, the self-expression module is introduced to alleviate the sensitivity of outliers.Under the same classification task, to prove the effectiveness of our E3GCAPS on the fine-granted spatial feature information learning, we compare it with the original CapsNet both on FAAD and SEED datasets.The classification results can be found in Table 2.It can be observed that our E3GCAPS obtains an improvement in four metrics with more than 16%on FAAD and 13% on SEED.In general, our proposed E3GCAPS is an efficient interpretable model, which can achieve remarkable results on EEG-based cross-subject analysis tasks.
V.DISCUSSION
5.1 Effectiveness of CapsNet with Dynamic Attention
The classical DL-based networks used for EEG analysis,e.g.,CNN,EEGNet,still exist some weaknesses.For example, the pooling operation and the scalar transmission mechanism of CNN drop a huge amount of feature information, which heavily degrade the model performance in the complex EEG data analysis.Morerover, it requires a large number of training samples to reach a better performance, which is not applicable to EEG datasets with small sample size.As shown in Figure 6,E3GCAPS is still able to maintain stability when the limited training samples are given.In addition,the existing methods are applied to a single BCI paradigm and lack a general EEG analysis framework based on CNN.To address these issues,the EEGNet is introduced to analyze EEG data suitable for different tasks, and further reduce the model training parameters.However, the hierarchical relationships among features are ignored.Then, the interpretation CapsNet is presented to explore the hierarchical relationships.It adopts the ’vector in vector out’transmission strategy and introduces the dynamic routing mechanism to interpret the part-whole hierarchical relationships, which can reach better performance when given limited training data.Considering the strong correlations on the spatial level of EEG data,the E3GCAPS is proposed with dynamic spatial-based attention to further capture the potential spatial relationships of EEG for cross-subject cognitive state detection,which can learn the correlations between subcapsules and capsules.Based on the original routing algorithm, this proposed algorithm further considers multi-scale spatial information, including the ECAbased attention weights and the spatial-based prior probability.Both the inter-part spatial relationships and the part-whole hierarchical relationships can be captured to optimize the representation of features, it also efficiently eliminates the negative impact of significant individual differences in EEG data.The results shown in Table 2 further validate this conclusion,and our proposed E3GCAPS achieves the best performance in EEG-based cross-subject cognitive state detection compared with the above mentioned comparison methods.
5.2 Impact of Feature Structure
For the original CapsNet, the common feature structure is 2D,and a vector structure is designed to characterize the sample information to achieve an interpretation transmission process.However,the training efficiency is prone to lower when the features can be interpreted, as shown in Table 1.In E3GCAPS, the input data dimension is converted to multi-channel 1D because there is a strong correlation between cognitive states and brain function connection mode.For multi-channel 1D EEG data, the channel-based feature information can be learned to capture the potential spatial relationships between different channels.Furthermore,it greatly improves the efficiency of training and reaches a higher classification accuracy.In Table 1,experimental results show that the multi-channel 1D data structure of CapsNet can improve accuracy by 9.4% on FAAD and 2.92% on SEED, and reduce the training parameters by more than 90%of 2D with less training time on both datasets.Generally speaking, the feature structure of multi-channel 1D greatly improved the training efficiency,as well as the performance.
5.3 Performance of Cross-subject EEG Analysis
Most existing DL-based methods are typically used for intra- or inter-subject EEG analysis, and the model performance degrades significantly when used for cross-subject.E3GCAPS is proposed to detect EEGbased cross-subject cognitive states, and it is an efficient interpretation model based on multiple capsule networks.Based on the original CapsNet with multiple sources, the multi-channel 1D data structure of E3GCAPS achieves better performance than CapsNet(see Section 5.2).Due to the sensitivity of outliers caused by the EEG characteristic of significant individual differences, the self-expression is introduced to capture the potential connections between samples,the results shown in Table 1 demonstrate that this module can efficiently eliminate the negative impact of outliers.Further, considering the potential relationships on the spatial level of EEG, the dynamic subcapsulebased spatial attention mechanism is presented to explore the spatial hierarchical relationships, including inter-part and part-whole.The inter-part relationships are taken into account to learn the fine-grained feature information.Therefore, E3GCAPS learns more details of EEG than other comparable models and performs better in cross-subject cognitive state detection.
VI.CONCLUSION
In this article,theEfficient EEG-based Multi-Capsule Framework(E3GCAPS)is proposed as an efficient interpretation model for cross-subject EEG-based cognitive state detection.E3GCAPS achieves state-of-theart performance both on FAAD and SEED datasets.The main contributions are described as follows: first,we build the EEG data into the multi-channel 1D structure, which greatly improves the training efficiency and also achieves better performance of model.Second, the self-expression module is introduced to capture the potential connections between samples,which can be well adapted to cross-subject EEG data analysis with significant individual differences under different tasks.Third,we present a novel dynamic subcapsulebased spatial attention algorithm to further learn finegrained feature information at the spatial level of EEG data,which can effectively characterize both the interpart spatial relationships and the part-whole hierarchical relationships.Overall,the experiment results confirm that the performance of E3GCAPS is greatly improved in cross-subject EEG-based cognitive state detection.
ACKNOWLEDGEMENT
This work was supported by NSFC with grant No.62076083.Firstly, the authors would like to express thanks to the Key Laboratory of Brain Machine Collaborative Intelligence of Zhejiang Province with grant No.2020E10010 and Industrial Neuroscience Laboratory of Sapienza University of Rome.Secondly,the authors would also like to thank Sapienza University for providing the FAAD dataset and STJU for providing the SEED dataset.At last, many thanks to the anonymous reviewers for the careful comments.

- China Communications的其它文章
- A User-Friendly SSVEP-Based BCI Using Imperceptible Phase-Coded Flickers at 60Hz
- Steady-State Visual Evoked Potential(SSVEP)in a New Paradigm Containing Dynamic Fixation Points
- Toward a Neurophysiological Measure of Image Quality Perception Based on Algebraic Topology Analysis
- Transfer Learning Algorithm Design for Feature Transfer Problem in Motor Imagery Brain-computer Interface
- Removal of Ocular Artifacts from Electroencephalo-Graph by Improving Variational Mode Decomposition
- BCI+VR Rehabilitation Design of Closed-Loop Motor Imagery Based on the Degree of Drug Addiction