
Deep Learning-Based Prediction of Traffic Accidents Risk for Internet of Vehicles
2022-03-01 00:12HaitaoZhaoXiaoqingLiHuilingChengJunZhangQinWangHongboZhu
China Communications 2022年2期
Haitao Zhao,Xiaoqing Li,Huiling Cheng,Jun Zhang,Qin Wang,Hongbo Zhu
1 School of Communication and Information Engineering,Nanjing University of Posts and Telecommunications,Nanjing 210003,China
2 School of Electronic and Information Engineering,The Hong Kong Polytechnic University,Hong Kong,China
Abstract: With the increasing number of vehicles,traffic accidents pose a great threat to human lives.Hence,aiming at reducing the occurrence of traffic accidents, this paper proposes an algorithm based on a deep convolutional neural network and a random forest to predict accident risks.Specifically,the proposed algorithm includes a feature extractor and a feature classifier,where the former extracts key features using a convolutional neural network and the latter outputs a probability value of traffic accidents using a random forest with multiple decision trees,which indicates the degree of accident risks.Simulations show that the proposed algorithm can achieve higher performance in terms of the Area Under the Curve (AUC) of the Receiver Characteristic Operator as well as accuracy than the existing algorithms based on the Adaboost or the pure convolutional neural networks.
Keywords:road safety,risk prediction,Internet of Vehicles
I.INTRODUCTION
The increasingly common vehicles bring more convenience and efficiency to people’s lives.However, the massive vehicles also bring some risks,which not only destruct public transport facilities but also cause traffic jams in large areas[1].More seriously,traffic accidents pose a major threat to people’s life safety.To this end, the government has taken a series of measures,such as banning lane change and setting traffic lights at intersections during peak hours, but the improvement in traffic situations is not obvious.Thus, there is a consensus between academia and industry that the measures to reduce the occurrence of traffic accidents are very necessary.According to [2], risk prediction of traffic accidents is a positive and effective method,which can reduce the occurrence of traffic accidents by taking some actions in advance according to the prediction results.Risk prediction is practical since modern vehicles integrate with various sensors (such as radar devices,cameras,and global positioning systems) to gather information about their surroundings[3]for data analysis.In addition,with abundant computing and caching resources in the edge servers, 6G networks can analyze users’ behavior from big data of the past, autonomously learn the needs of users,and accurately predict the future behavior of users[4].However, risk prediction is not easy as the causes of traffic accidents are various, such as over-speed, obstacles blocking,drunk driving,fatigued driving,vehicle trouble,poor road conditions,and bad weather[5].These possible causes can be simply divided into two categories of accident factors, i.e., subjective driving behavior information and objective road information,and the factors are investigated by researchers[6].For example, Jeong et al.[7] captured various pedestrian data sets using a finite impulse response camera and detected Sudden Pedestrian Crossing at night.Considering the impact of rainfall, the rainfall-integrated deep belief network and long short-term memory were used to learn the features of traffic flow under various rainfall scenarios in[8].
On the one hand,analyzing real-time traffic data requires high computing power but the computing resource of the vehicles is limited [9].A convergence of communication and computing (COM2P) may be a promising solution [10].Mobile edge computing(MEC) is a basic enabling technology for future mobile communication networks with COM2P[11].For example,an accident detection system deployed in the edge server is used to automatically detect the occurrence of accidents and inform the near hospitals and traffic management departments in real-time[12].On the other hand,machine learning(ML)techniques especially recently popular deep learning (DL) can be used to capture the possible factors that may lead to traffic accidents due to the powerful data analysis capability of DL technique[13].For example,[14]proposed a road traffic accident prediction model based on the long short-term memory neural network to capture the timing dependence existing in traffic data.Meanwhile,this model has been verified to be able to accurately predict the safety level of traffic accidents and provide guidance for traffic management departments to make more scientific and accurate decisions[14].
However, the prediction accuracy of the existing methods based on traditional convolutional neural networks (CNNs) cannot meet the requirements of realtime vehicle traffic.To improve the prediction capability of traditional CNNs, we propose an algorithm based on a deep convolutional neural network(CNN)and a random forest network in this paper.The proposed algorithm in an edge server to predict the risks of traffic accidents.Our contributions in this paper are summarized as follows:
1) We consider a scenario of edge Internet of Vehicles (IoV), where the vehicles first pre-process the collected real-time traffic information and then transmit the pre-processed to an edge server for further processing.Finally, the prediction results are backed to corresponding vehicles.
2)We propose an algorithm, in which a deep CNN and a random forest(RF)are integrated.The former is used to extract features and the latter is for classifying features.And the output of the features classifier is the predicted results,which are returned to corresponding vehicles.
3)Finally,we validate the efficiency of the proposed algorithm by comparing the proposed algorithm with other existing algorithms in terms of the Area Under the Curve (AUC) of the Receiver Operating Characteristic (ROC), accuracy, and loss.We also give the ranking of the importance of the relevant features of traffic accidents.
The remainder of this paper is organized as follows.In Section II,we summary the existing works of traffic accident risk prediction and Section III presents the system model.Section IV proposes the algorithm.Simulation results are presented in Section V.Finally,concluding remarks are given in Section VI.
II.RELATED WORKS
There have been some existing works investigating on risk prediction of traffic accidents in IoV.Four popular ML methods, including K-Nearest Neighbors, Decision Tree, RF, and Support Vector Machine (SVM),and two statistical methods, including Ordered Probit model and multinomial Logit model, were compared in terms of crash injury severity prediction in[15].It was found in [15] that the ML methods have higher prediction accuracy than the statistical methods.Lee et al.[16]predicted the severity of road accidents based on different ML methods and showed that the existing SVM method has better prediction performance compared with the methods based on the decision tree, artificial neural network, and Bayesian network.
Meanwhile, many factors can lead to traffic accidents, such as bad driving behavior, sudden real-time traffic conditions,the quality of the vehicle itself,and so on[5].Hence,it’s necessary to extract some significant features from these possible factors.The authors in [17] ranked the possible factors according to their effects on traffic accidents using a deep neural network based on Granger causality analysis method.Yan et al.[18] used Bayesian Networks to extract the main factors that influence driving risk status.Through the statistical analysis of typical factors and LR analysis,the accident black spot prediction model was established in[19]to study the relationship between typical factors and traffic accidents.To select the most important features of the traffic accidents, a feature selection method based on Frequency Pattern Tree was proposed in[20].[21]proposed a traffic accident risk prediction algorithm based on a CNN and the results showed that the proposed algorithm had a lower loss rate and a higher accuracy compared with the traditional back propagation neural network.However,this algorithm based on the traditional CNN has redundancy and inefficiency due to the fully-connected layers at the back of the CNN.Therefore,it is necessary to find efficient ways to classify features.
We investigated some methods of classifying features.[22] used multi-kernel SVM based classifiers and the multi-feature fusion of feature weighting for image classification.[23] proposed a method classifying Electroencephalogram data automatically with high accuracy and compared six classification algorithms such as the RF, feed-forward neural network,C4.5 decision tree algorithm, SVM, and radial basis function neural network.[24] proposed a novel method for improving RF in hyperspectral image classification.The proposed the hybrid method combined the ensemble of features and the semi-supervised feature extraction technique [24].Based on the hybrid models previously fused with CNN and other models such as Conditions with Airports, SVM, and RF,[25] tested an RF classifier and CNN fusion model for forest mapping.Besides, [26] proposed a deep CNN based hyperspectral image classification (HSI)model named Deep Cube CNN with Random Forest and showed that the multi-feature fusion strategy can be used for performance improvement of HIS classification.[27] found that the hybrid model finishes the same tasks with fewer convolutional and fully-connected layers.This, in turn, allowed for robust training on smaller datasets.[28] showed that,as for the same datasets, trees of the shallow neural decision forests are less deep and fewer than them in corresponding alternating decision forests models[28].Meanwhile, the authors validated the high performance of the shallow neural decision forest model as a stand-alone classifier on standard machine learning datasets.Motivated by the observations, we attempt to combine the traditional CNN with the RF and propose a hybrid model to achieve better classification performance.
This paper proposes a traffic accident risk prediction algorithm in the edge IoV scenarios.The proposed algorithm runs on the edge server, which has powerful processing capability compared to the vehicles.The edge server makes it convenient for the calculation,analysis, and storage of all kinds of data collected in real-time,because of shorter transmission distance and more computing power.The predicted alarm results are packaged and sent to the vehicles in real-time, in order to remind the drivers to observe the surroundings carefully and adjust their behaviors.Compared to the traditional pure ML models, the proposed algorithm firstly uses CNN to capture multi-dimensional features from different perspectives.Then the collected features form a feature matrix and is input into the RF classifier for training.Finally,according to the output of RF,the risk of traffic accidents can be predicted.
III.SYSTEM MODEL
As shown in Figure 1, we consider a framework of edge IoV.The vehicles collect and pre-process the information about the surrounding environment and the driving conditions of the vehicle units.Then the preprocessed data is transmitted to the edge servers for further processing, i.e.feature extraction and feature classification.Finally,the edge servers return the prediction results to the vehicle units.
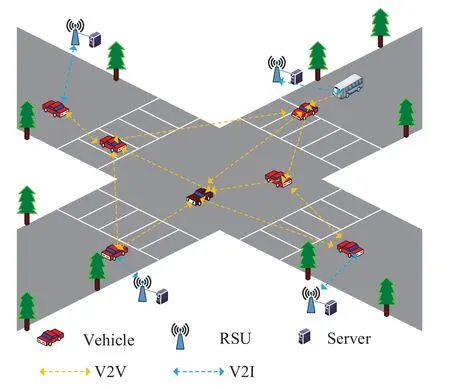
Figure 1. System model.
The process of traffic accidents risk prediction is shown in Figure 2.Firstly, selecting the significant features such as time,latitude,accident severity,speed limit, weather conditions, and so on, we construct the traffic state matrix as the input of the algorithm[29].Secondly,we pre-process the traffic state matrix by normalization.Specifically, we subtract the mean value of each dimension from the corresponding dimension to centralize each dimension of the input data into 0 and regulate the range of input features values to 0-1, which can accelerate the neural network convergence and prevent the saturation of the neuron output caused by the large absolute value of the network input.
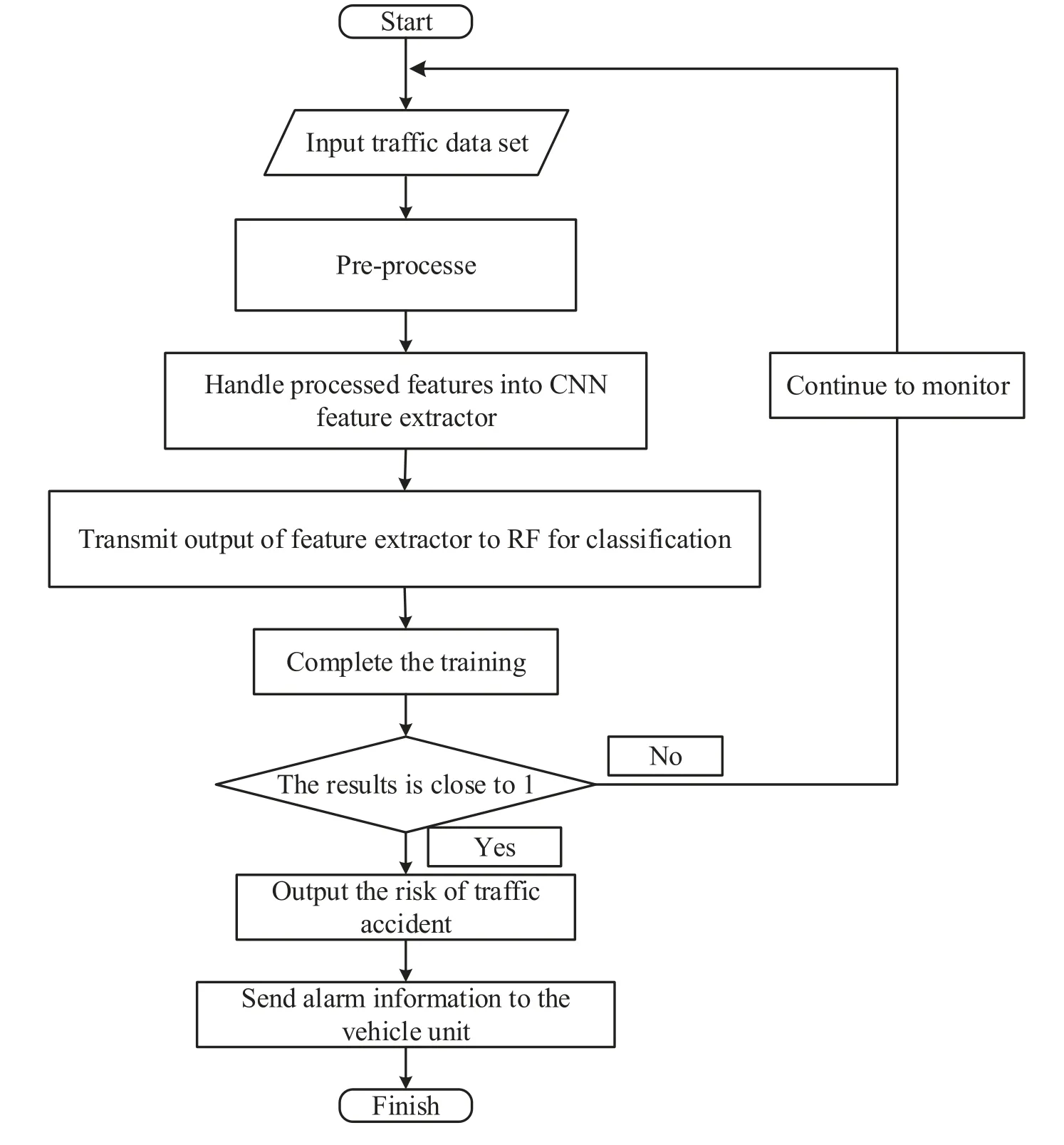
Figure 2. Process of risk prediction traffic accidens.
Then, the pre-processed data are put into the feature exactor.The multi-dimensional dependent features causing traffic accidents are extracted from the original matrix by convolutional layers of the CNN[30].Afterward the output of the flatten layer of CNN is transformed into a feature matrix of suitable size,which is directly input into RF for classification.Finally, the RF outputs the risk of traffic accident prediction,which is a probability value and ranges from 0 to 1.The number between 0 and 1 represents the risk of an accident happening, which is calculated by dividing the label values in the 2005-2015 UK traffic car datasets[31]by the maximum value of the labels.The more it is biased to 1 and the higher the probability of traffic accidents will be.Otherwise, the risk of traffic accidents will be lower.
IV.PROPOSED RISK PREDICTION ALGORITHM
This section describes the mechanism of our proposed algorithm in detail.Briefly speaking,the proposed algorithm contains two parts: feature extractor and feature classifier.The feature extractor is a CNN and the feature classifier is made up of an RF with multiple decision trees.
4.1 Feature Extractor
After pre-processing,features are input into the feature extractor [32].The feature extractor is a CNN, composed of an input layer, convolutional layers, pooling layers,and a flatten layer.The smallest computing unit of the feature extractor is the neuron.Neurons are the nodes through which data and computations flow[33].
The convolutional layer is to use trainable filters to convolute the input features and add a bias.The output of the convolutional layers is updated as follows:
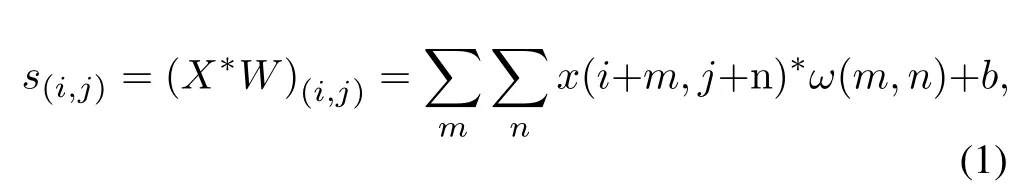
whereXis the input feature,Wis the convolutional kernel,bis the bias.
To further reduce the number of parameters and avoid over-fitting,the pooling layer sums the convolutional feature with feature per neighborhood and maps them into one feature.The activation function ReLU is used to generate a new feature map that is approximately times smaller.
The expression ability of the linear model is poor.To add non-linearity, the activation function ReLU must be introduced[34].
ReLU is defined as follows:
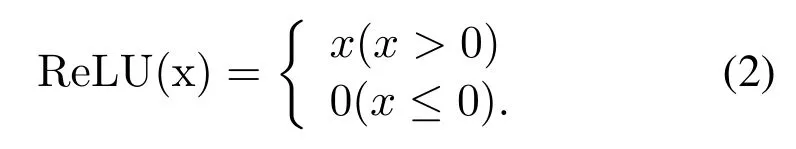
Compared with the traditional activation functions sigmoid and tanh,whenx >0,the gradient of ReLU is constant 1.The convergence rate of the feature extractor is fast and there is no gradient dissipation problem.Whenx<0,the output of ReLU is 0.ReLU not only can reduce data redundancy but also retains features as much as possible to achieve parameter sparseness.
4.2 Feature Classifier
The feature extractor is an RF, which works in a supervised way.The “forest” it builds, is an ensemble of decision trees, usually trained with the “bagging”method.We use several identical but independent classification and regression trees(CART)as the decision trees [35].And then the “bagging” method is a type of ensemble ML algorithm called Bootstrap Aggregation.An ensemble method combines predictions from multiple ML algorithms together to make more accurate predictions than an individual model.
The process of constructing a feature classifier is as follows: We use the bootstrap sampling method to extract the samples from the input feature maps and form sample sets, the remaining samples constitute out-ofbag sample sets[36].We assume that feature extractor outputs features.When each node of the CART classification decision tree needs to be split, it randomly selectsmfeatures fromMfeatures(m ≪M).Then,it chooses one ofmfeatures as the split feature of the node until it can no longer be split.Finally,it repeats the above operationsntimes to obtainnCART classification decision trees.These obtained CART classification decision trees constitute the RF.
The RF classifier is an ensemble method that trains several decision trees in parallel with bootstrapping followed by aggregation.When the RF builds the decision trees, the Gini coefficient is introduced to divide point for selecting the datasets.The Gini coefficient measures the degree or probability of a particular variable being wrongly classified when the particular variable is randomly chosen.If all the elements belong to a single class,then the Gini coefficient is thought to be pure.The degree of the Gini coefficient varies between 0 and 1, where 0 denotes that all elements belong to a certain class or if there exists only one class, and 1 denotes that the elements are randomly distributed across various classes.A Gini coefficient of 0.5 denotes equally distributed elements into some classes.While building the decision trees,we prefer choosing the attribute/feature with the smallest Gini coefficient as the root node.The formula of the Gini coefficient is given as follows:
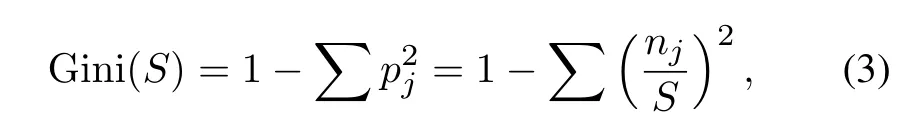
wherepjis the frequency of categoryjin sampleT,njis the number of category in sample , and is the number of samples.The higher the Gini coefficient,the greater uncertainty.On the contrary, the smaller the Gini coefficient,the less uncertainty[37].
As we traverse each split point of each feature,Sis divided into two parts, that is,S1(sample set that meetsA=a), andS2(sample set which doesn’t satisfyA=a).The Gini coefficient of under the condition of featureA=ais:
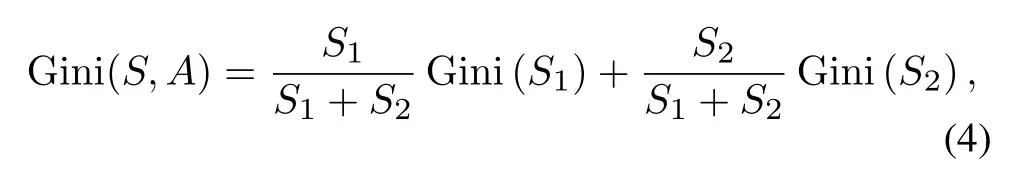
whereGini(S) represents the uncertainty of setS,andGini(S,A)represents the uncertainty of the setSpartitioned byA=a.
Each CART decision tree in the RF continuously traversal all possible segmentation points of the feature subset of the tree,in order to find the segmentation points of the feature with the smallest Gini coefficient and divide the data set into two subsets until the stop condition is met.
As shown in Figure 3, the proposed algorithm is a hybrid model [38], which uses the convolutional layers of the traditional CNN to deal with massive multidimensional traffic data and the RF to classify the processed features,so as to conduct data analysis and get the results of traffic accidents risk prediction.
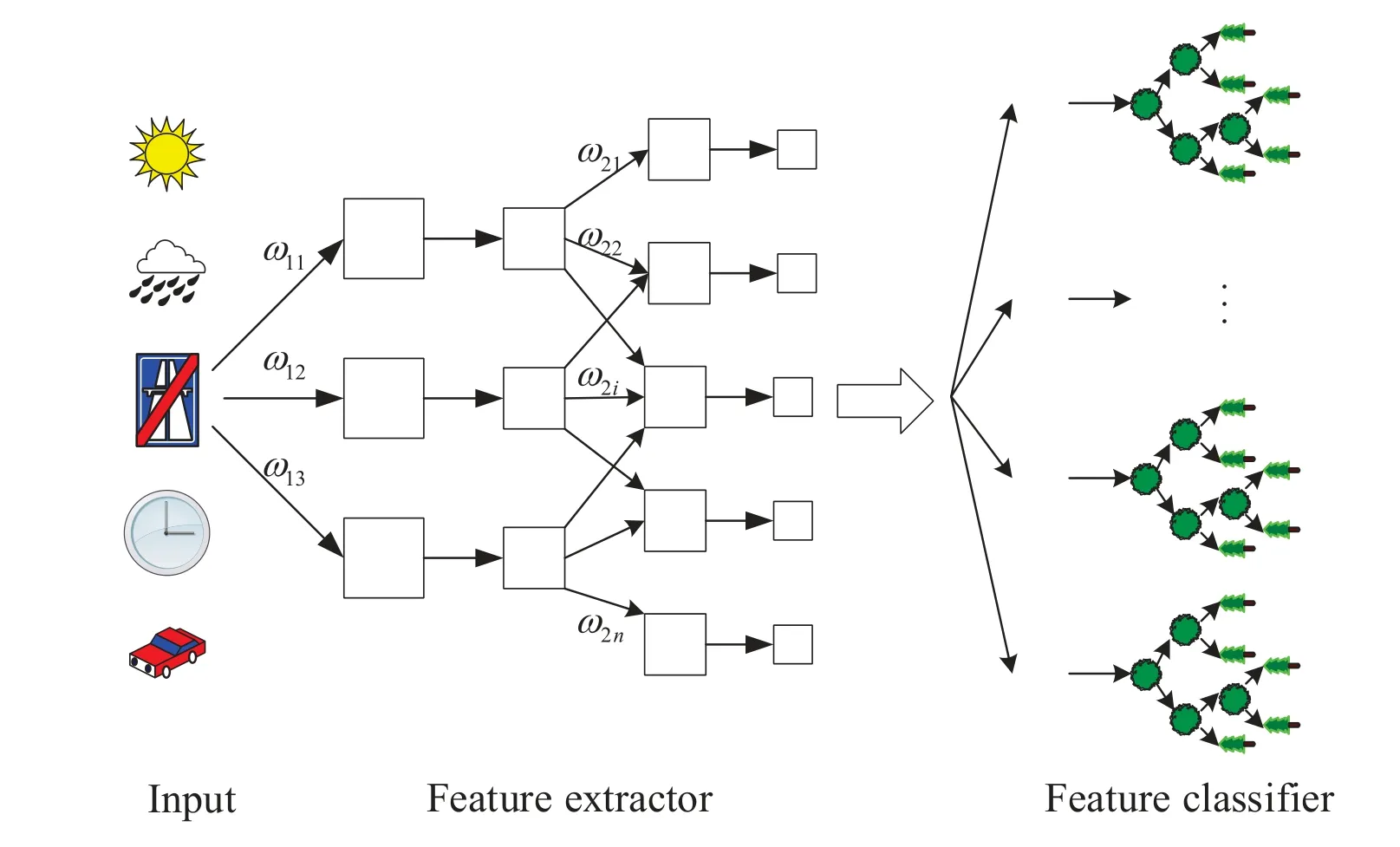
Figure 3. Architercture of the proposed algorithm.
V.PERFORMANCE EVALUATION
5.1 Experimental Settings
We perform the experiments on a computer with an Intel I5-7300HQ CPU, 12GB RAM, and NVIDIA GeForce GTX1050.The 2005-2015 UK traffic car datasets [31] are used in this work and its 16 different kinds of features are shown in Table 1.
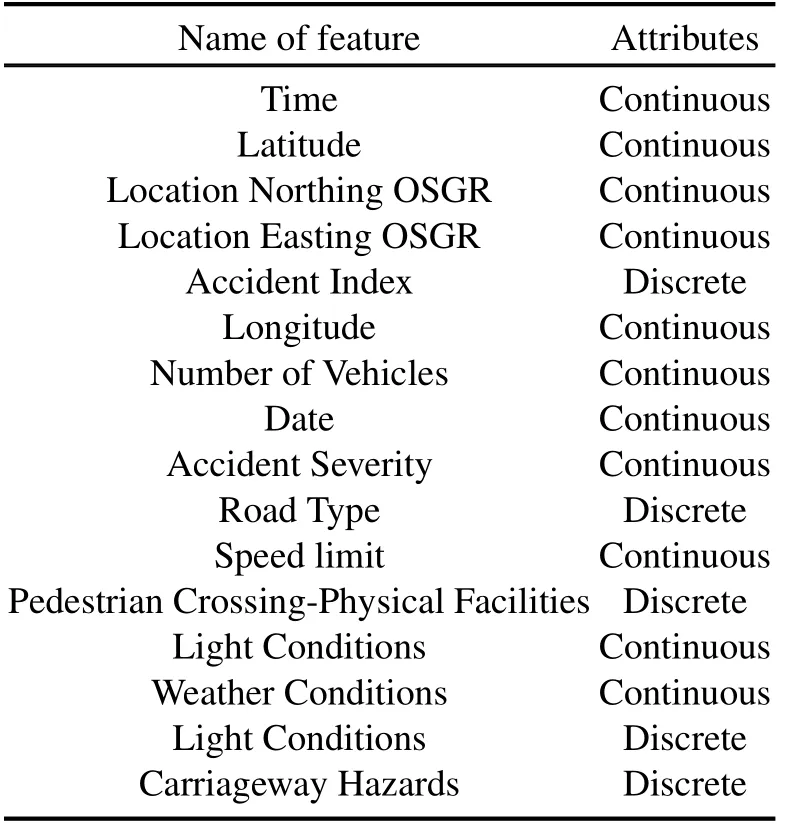
Table 1. Features of the UK car accident datasets.
The parameters of the hybrid model are given in Table 2.In addition,the mean square error(MSE)is chosen as a metric for model updating,which is computed as whereNis the number of samples,is the true value of the model input for samplei,andis the predicted value of the model output for samplei.
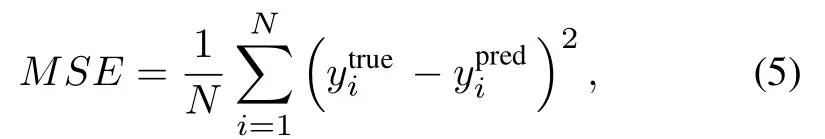

Table 2. The parameters of the hybrid model.
5.2 Experimental Results
For comparison, we introduce two algorithms, one is based on the traditional CNN and the other is based on the Adaboost[39].Figure 4 shows the ROC curves of the three algorithms when the number of data samples is 32000.It is found that the ROC curve of the proposed algorithm is closer to the upper-left corner than the two baseline algorithms,which means that the algorithm has higher precision and better generalization performance.We also observe that the AUC values of the proposed algorithm,the pure CNN based algorithm, and the Adaboost based algorithm are 0.9917,0.9572, and 0.9676, respectively.That is to say, the proposed algorithm has a stronger ability of classification.
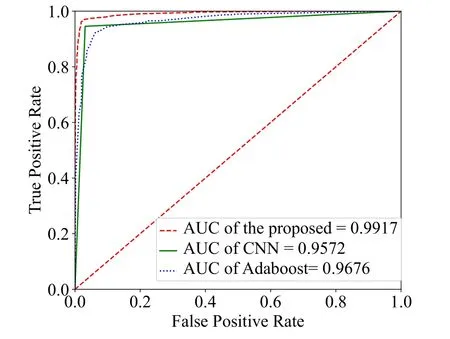
Figure 4. ROC comparison between the proposed algorithm,CNN,and Adaboost.
Table 3 clearly lists the AUC values of the three algorithms with respect to the number of data samples.We can see that the AUC of the three algorithms keep rising with the number of data samples are increasing.
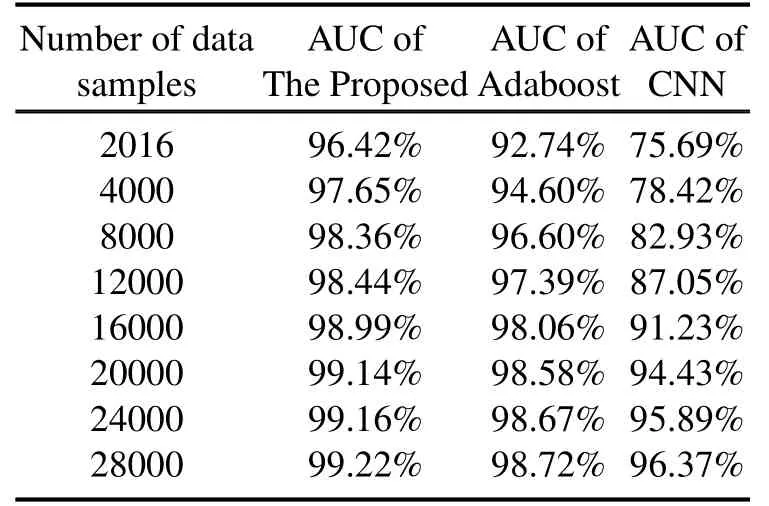
Table 3.AUC comparison between the proposed algorithm,CNN,and Adaboost.
We compare the accuracy and loss of the proposed algorithm, CNN, and Adaboost in Figure 5 and 6,respectively.
In Figure 5, dealing with different sizes of the datasets, the accuracy of the proposed algorithms is higher than that of the other two algorithms.Similarly,in Figure 6,we find that the loss of the proposed prediction algorithm is closer to 0 and lower than of the other two algorithms.
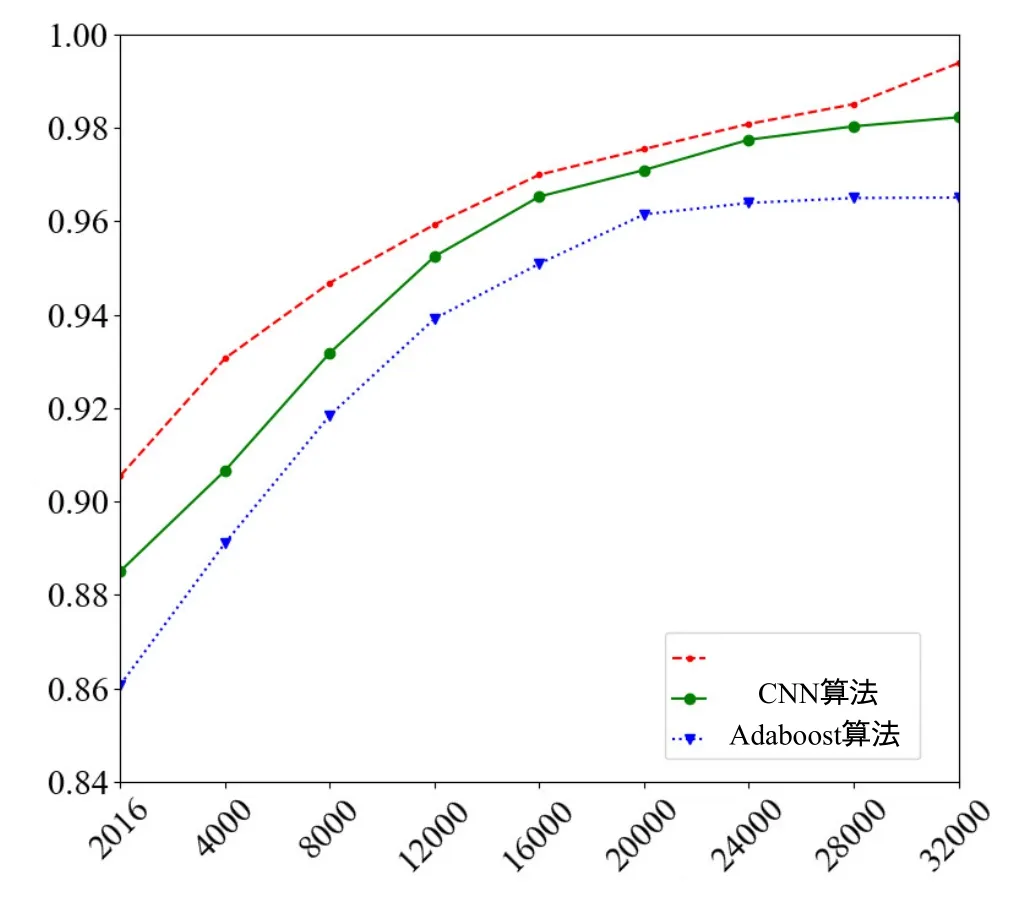
Figure 5. Accuracy of the proposed algorithm, CNN, and Adaboost concerning the number of samples.
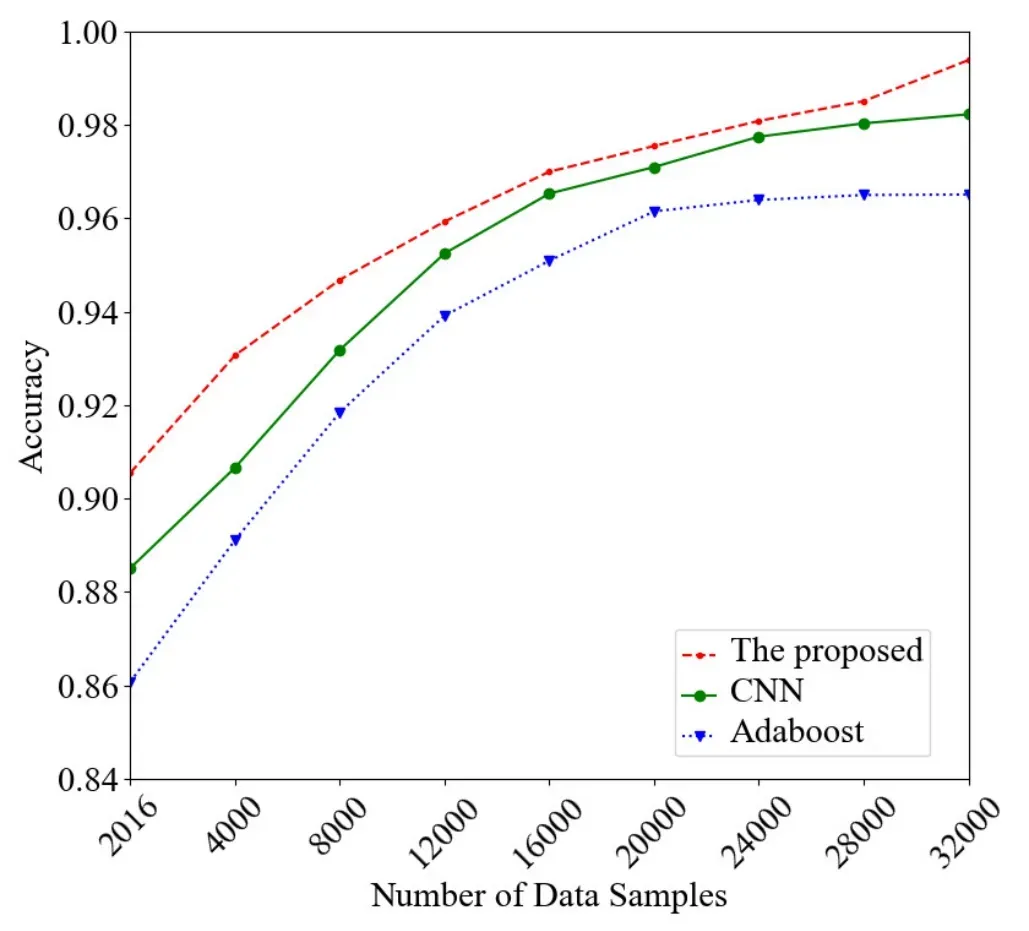
Figure 6. Loss of the proposed algorithm, CNN, and Adaboost concerning the number of samples.
In the process of RF feature classification,if random noise is added to a feature,the out-of-bag error of the feature will increase sharply,indicating that the feature has a great impact on the classification results.Therefore, we can use the function (.feature importances)of the RF classifier to rank the features according to their importance.
Figure 7 shows the influences of different features on traffic accidents risk.The features that may cause traffic accidents are not evenly distributed.Among them,the features that are significantly related to traffic accidents can be ranked as driving time>geographic position>number of vehicles>road shape>driving speed>completeness of physical facilities>weather,light,and other natural conditions.
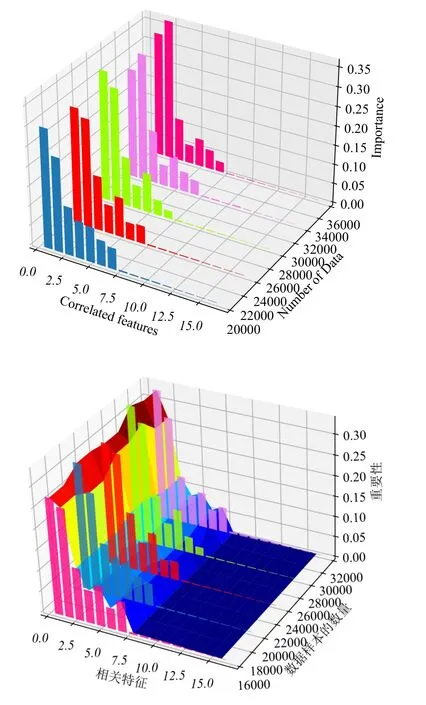
Figure 7. Importance comparison of 16 traffic accidentrelated features under different numbers of data samples.
VI.CONCLUSION
In order to predict traffic accidents risk,this paper proposed the prediction algorithm, which not only extracted multi-dimensional features by convolutional operations but also selected and classified the features by a decision tree of the RF.Our simulation results showed that the proposed algorithm has a higher AUC and a smaller loss than the existing algorithms based on the Adaboost or the pure CNN.Besides,the prediction performance of the proposed model is more stable when it deals with massive data.Finally, we rank the features according to their impact on traffic accidents.
ACKNOWLEDGEMENT
This work is supported by the National Key Research and Development Program (2019YFB2103004), the National Natural Science Foundation of China (No.61871446, 92067201), the Natural Science Foundation on Frontier Leading Technology Basic Research Project of Jiangsu(BK20212001),the Future Network Scientific Research Fund Project(FNSRFP-2021-ZD-8,FNSRFP-2021-YB-31).

- China Communications的其它文章
- A User-Friendly SSVEP-Based BCI Using Imperceptible Phase-Coded Flickers at 60Hz
- Steady-State Visual Evoked Potential(SSVEP)in a New Paradigm Containing Dynamic Fixation Points
- Toward a Neurophysiological Measure of Image Quality Perception Based on Algebraic Topology Analysis
- Transfer Learning Algorithm Design for Feature Transfer Problem in Motor Imagery Brain-computer Interface
- Removal of Ocular Artifacts from Electroencephalo-Graph by Improving Variational Mode Decomposition
- BCI+VR Rehabilitation Design of Closed-Loop Motor Imagery Based on the Degree of Drug Addiction