
Outsourced Privacy-Preserving Anomaly Detection in Time Series of Multi-Party
2022-03-01 00:12ChunkaiZhangWeiZuoPengYangYeLiXuanWang
China Communications 2022年2期
Chunkai Zhang,Wei Zuo,Peng Yang,Ye Li,Xuan Wang
1 School of Computer Science and Technology,Harbin Institute of Technology,Shenzhen,Shenzhen 518055,China
2 National Computer Network Emergency Response Technical Team/Coordination Center of China,Beijing 100029,China
Abstract: Anomaly detection has practical significance for finding unusual patterns in time series.However, most existing algorithms may lose some important information in time series presentation and have high time complexity.Another problem is that privacy-preserving was not taken into account in these algorithms.In this paper,we propose a new data structure named Interval Hash Table (IHTable) to capture more original information of time series and design a fast anomaly detection algorithm based on Interval Hash Table (ADIHT).The key insight of ADIHT is distributions of normal subsequences are always similar while distributions of anomaly subsequences are different and random by contrast.Furthermore,to make our proposed algorithm fit for anomaly detection under multiple participation, we propose a privacy-preserving anomaly detection scheme named OP-ADIHT based on ADIHT and homomorphic encryption.Compared with existing anomaly detection schemes with privacy-preserving, OP-ADIHT needs less communication cost and calculation cost.Security analysis of different circumstances also shows that OP-ADIHT will not leak the privacy information of participants.Extensive experiments results show that ADIHT can outperform most anomaly detection algorithms and perform close to the best results in terms of AUC-ROC,and ADIHT needs the least time.
Keywords: anomaly detection; interval hash table;privacy-preserving;multiple participants
I.INTRODUCTION
With the development of the Internet and IOTs, massive data is generated and distributed in different areas[1].Data mining under multy-party is importanat, and data privacy protection is highly required at the same time[2].Anomalies in data contain important information[3],anomaly detection is to find these anomaly data that have different data characteristics from normal data.Therefore, it is important to design privacy-preserving anomaly detection algorithms for multi-party participants.There are some existing privacy-preserving anomaly detection algorithms[4–7], but [4], [5] are not applied in time-series, and [7]also need communications between data owners,even in the case of two parties.[6]can be applied in timeseries,but it needs to calculate the maximum distance of each subsequence to its nearest non-self match on the ciphertexts as the anomaly degree, which needs many additions and multiplication operations on ciphertexts.At present, most of anomaly detection algorithms are only suitable to the case of data stored in single party and have not taken privacy protection into account, which will increase the difficulty of designing privacy-preserving anomaly detection scheme based on them.For example, in case of calculating the distance between subsequences,[8,9]contain the operation of multiplication, which is easy to implement in plaintext while hard in ciphertext, especially when data encrypted by different public keys.What’s more,most of these algorithms may lose some important information in data presentation and suffer from“curse of dimension”which will bring great burden to calculation based on ciphertexts.SAX-based algorithms[8, 9] symbolize subsequence according to the mean value of equal-sized segments, which may change the shape of subsequences and cause the missing of some important trend patterns.Isolation Forest (iForest) [10] algorithm constructs isolation trees by selecting data attributes randomly, but it will neglect the time-order information.In similarity calculation, distance-based algorithms such as TSAX[11],Interval[12] and so on always need to calculate the pairwise distance of subsequences, and algorithms based on hidden Markov model such as OutRank[13]and PAPR-RW[14]also consume too much time in the iterative optimization process.Deep-learning anomaly detection algorithms[15–17] take even more time in the model training process.Considering the communications and the complexity of the encrypted data in privacy protection, we propose a novel anomaly detection and design a privacy-preserving anomaly detection scheme OP-ADIHT for multi-party participants with the outsourced cloud platform.First, we propose a new data structure named Interval Hash Table (IHTable) to capture more original information of time series, then propose an anomaly detection algorithm based on Interval Hash Table(ADIHT)to detect anomalies quickly without calculating the pair-wise distances.Based on ADIHT, we designed a privacy-preserving anomaly detection scheme OPADIHT for multi-party participants.To protect data privacy, data owners will transform their IHTable to SIHTable (security IHTable) by encrypting with their public key, then outsource the SIHTable to the cloud platform and communicate with it to do anomaly detection tasks.We also analyze the security of OPADIHT to ensure privacy information will not be leaked during the anomaly detection process.Compare to algorithm[7] which not only needs communications between data owners and the cloud platform but also communications between data owners, OPADIHT can avoid communications between data owners and reduce communication costs.The main contributions of this paper are as below.
• To capture more original information of time series,a new data structure named Interval Hash Table(IHTable) is proposed to represent time series data.Compared with the existing time series representation methods, IHTable can preserve more trend information.
• To reduce the time complexity, we propose ADIHT: a novel Anomaly Detection algorithm based on Interval Hash Table, which takes only linear time to detect anomalies.The key insight of ADIHT is normal subsequences always have a similar distribution,while anomaly subsequences distribute differently and randomly by contrast.
• What’s more, we adapt our algorithm to the case of the data distributed in multi-parties and leverage the outsourced cloud platform to detect anomalies.We propose an Outsourced Privacy-preserving Anomaly Detection scheme(OP-ADIHT)based on ADIHT and homomorphic encryption.
Extensive experiments on data sets of UCR Repository[18] and the BIDMC database[19] show that: (i)ADIHT can detect meaningful anomalies and get overall good performance in terms of AUC-ROC.(ii) ADIHT outperforms other competing algorithms in terms of time complexity.(iii) OP-ADIHT can effectively detect anomalies under multiple participants.Security analysis under different circumstances also indicates that OP-ADIHT can preserve privacy information during anomaly detection.
This paper is organized as follows.In section II, we introduce the background knowledge used in our work.In section III, we introduce the proposed anomaly detection algorithm ADIHT in detail.In section IV,we first present the anomaly detection model under multiple participants with the outsourced cloud platform and then introduce the privacy-preserving anomaly detection scheme OP-ADIHT in detail.In section V,we perform extensive experiments to illustrate the effectiveness of ADIHT and the significance of OP-ADIHT under multi-party anomaly detection,we also analyze the security of OP-ADIHT under different circumstances.Our work is concluded in section VI.
II.BACKGROUND
In this section,we will introduce the Distributed Two Trapdoors Public-Key Cryptosystem (DT-PKC)[20]and the security protocols used in this paper.
2.1 DT-PKC
The homomorphic encryption scheme used in our work is DT-PKC, which is based on the BCP cryptosystem[21] and follows the idea[22].BCP has the property of additive homomorphic under the same key (see Eq.(1)).BCP cryptosystem has two independent decryption mechanisms.In the first decryption mechanism, ciphertexts can be decrypted by the corresponding private key.In the second decryption mechanism,any given ciphertexts can be decrypted by the master key[21].
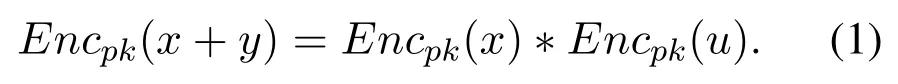
However,the master key leakage is a risk to the BCP system,since all encrypted data in BCP cryptosystem can be decrypted by the master key.DT-PKC solves this problem by splitting the strong master key into different shares(see Eq.(2)).The weak decryption algorithm in DT-PKC also supports distributed decryption to solve the authorization problem in the multikey environment.The detail of DT-PKC can be seen in[20].
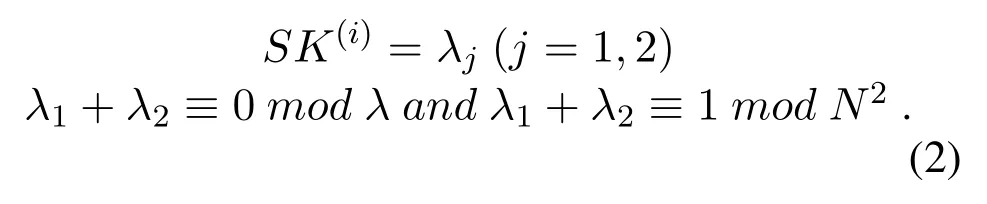
2.2 Security Protocols
There are two main security protocols used in our scheme.One is Secure Addition Protocol Across Domains (SAD) protocol[20] and the other isTrans-Decprotocol[23].The public keypkibelongs to data providerDPi,and the joint public keypkΣ is owned by the outsourced cloud platform CP and the computation service provider CSP.CP has the partial strong private keySK(1)and CSP has the other partial strong private keySK(2).
SAD:Given two encrypted data[x]pkaand[y]pkbunder different keys,the goal ofSADprotocol is to calculate[x+y]pkΣ.
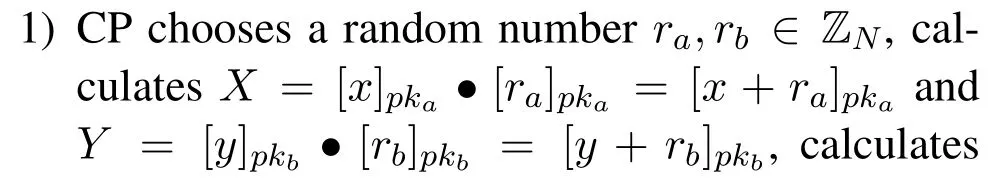

III.THE PROPOSED ANOMALY DETECTION ALGORITHM:ADIHT
Before introducing ADIHT in detail, we will show symbols used in our method(Table 1).

Table 1. The description of symbolic.
3.1 Time Series Representation: Interval Hash Table(IHTable)
Time seriesXwith lengthNcan be split toN/msubsequencesXiwhose length ism.For subsequence representation, both the time-order information and point value information are important.Inspired by interval division and hash function, we designed a new data structure named Interval Hash Table(IHTable)to keep important information for data representation.
The detailed steps of constructing IHTable are as following,and the pseudo-code is shown in Algorithm 1.
1.Use the Max-Min normalization[24] to scale the value of each column into [0,1].Normalize all data pointsxijby Eq.(3), in which maxtjand mintjdenotes the max and min value of allxijat time pointtj(j=0,1...,m−1).Min-Max normalization is sensitive to outliers.For example,for three points 1,2,100, assuming that the value of 100 is an outlier.After normalization, normal 1 and 2 will be“squeezed”together while the outlier will be far away, and this is exactly what we need.Normalization is also important for the following hash procedure.
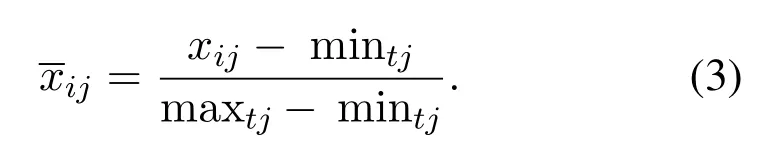
2.Determine the parameterw(0< w <1) and calculate the interval number 1/w.Hash all data pointsxijinto the corresponding interval by Eq.(4).Then the indexsof the interval can be calculated by Eq.(5).By using the hash function and intervals, we can capture the approximate trend information of a subsequence.For example, two subsequences in Figure 1(a)can be represented by Figure 1(b)after hashing.
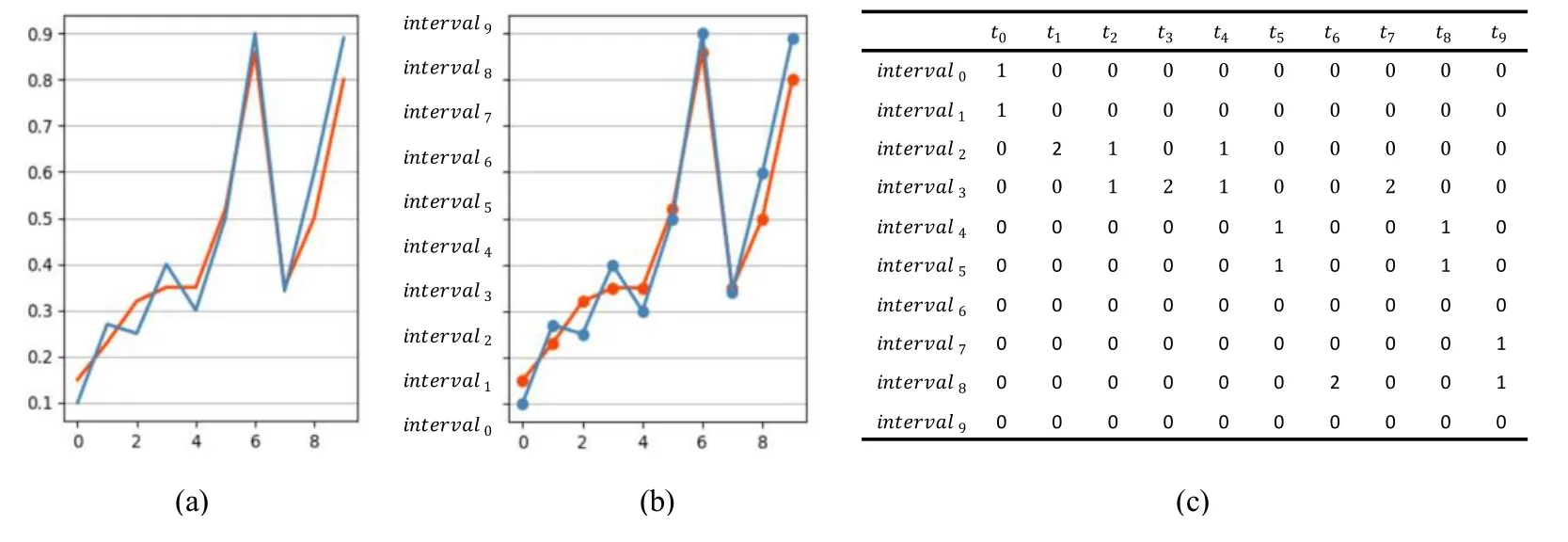
Figure 1.Set w=0.1 and hash all data points into the corresponding interval.(a)The original two subsequences(b)After hashing.(c)Constructing the IHTable.
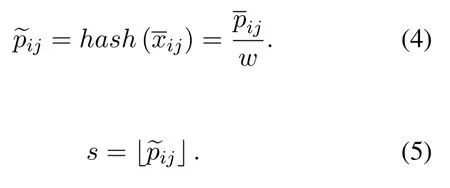
3.Construct IHTable based on the hash results.We can construct a IHTable of 1/wrows andmcolumns (Table 2).Each elementhi,jis set to zero at first, then if thejthdata point of subsequences is hashed intointervals , hs,jincrease by 1.Since Normal points will be hashed in the same or near intervals, and abnormal points will be hashed in far intervals,largerhi,jmeans higher density and points in this interval has higher probability to be normal.
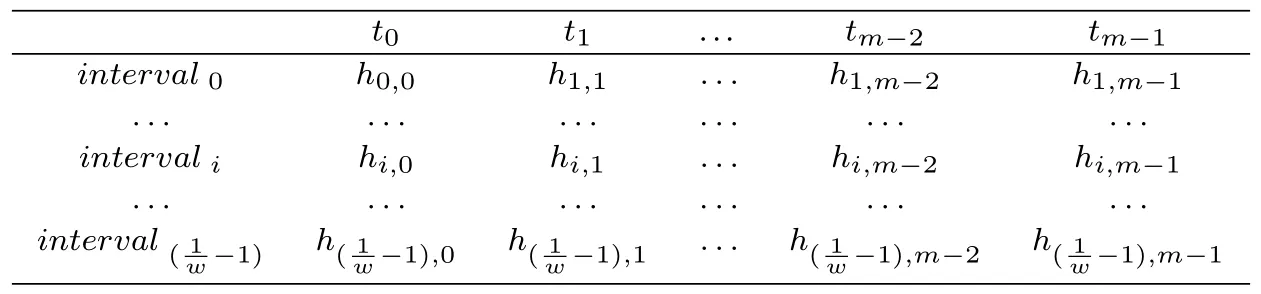
Table 2.The structure of IHTable.

Algorithm 1. Construct the interval hash table.Require: Time-series X with length N, the subsequence length m,hash parameter w.Ensure: Interval Hash Table(IHTable).1: Normalize time-series X 2: Initialize IHTable with size 1w ∗m 3: for i=0 to N/m −1 do 4: for j =0 to m −1 do 5: calculate the index s of the interval which xij hashed to 6: IHTable[s][j]+=1 7: end for 8: end for
3.2 The Proposed Anomaly Detection Algorithm: ADIHT
The insight of our algorithm is normal subsequences always have a similar distribution,while anomaly subsequences distribute differently and randomly by contrast.Considering that the characteristic of anomaly is“less and different”, some points in abnormal subsequence must be different from these points of other normal subsequences.So, we can quickly evaluate the anomaly degree of each data point based on the IHTable and calculate the average score as the anomaly score of this subsequence.
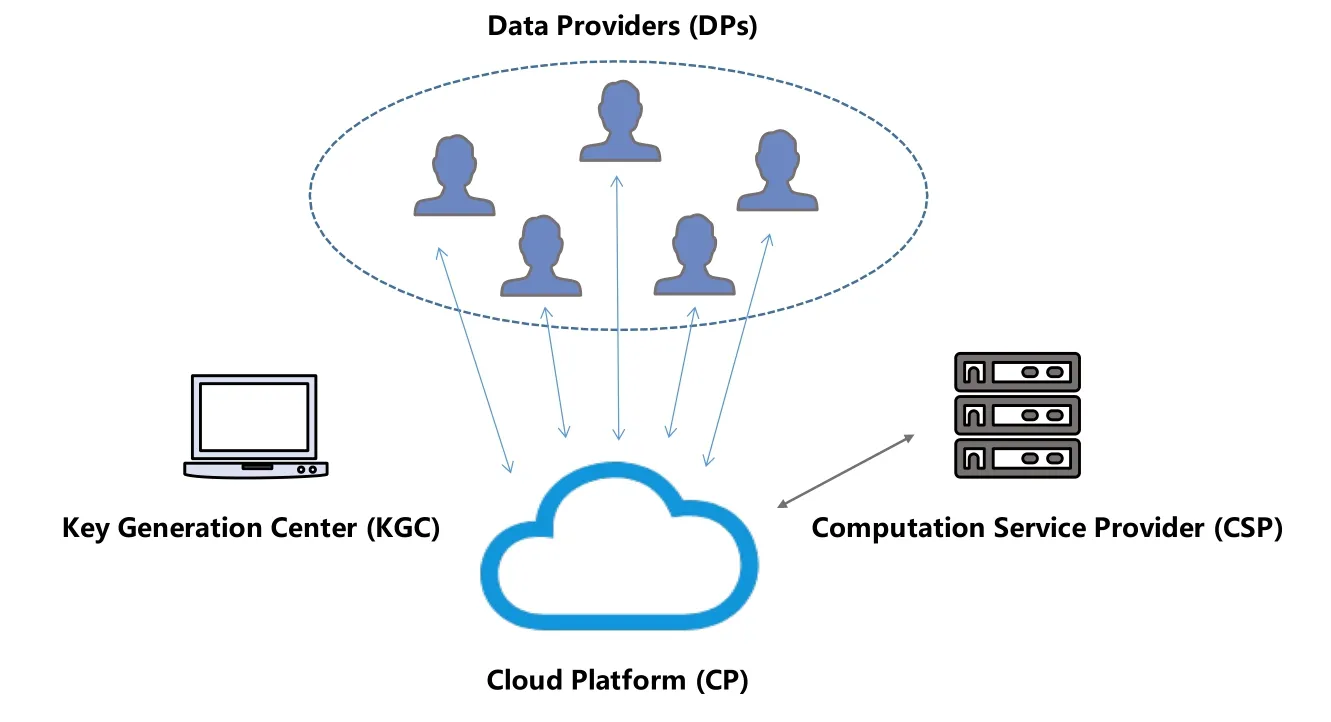
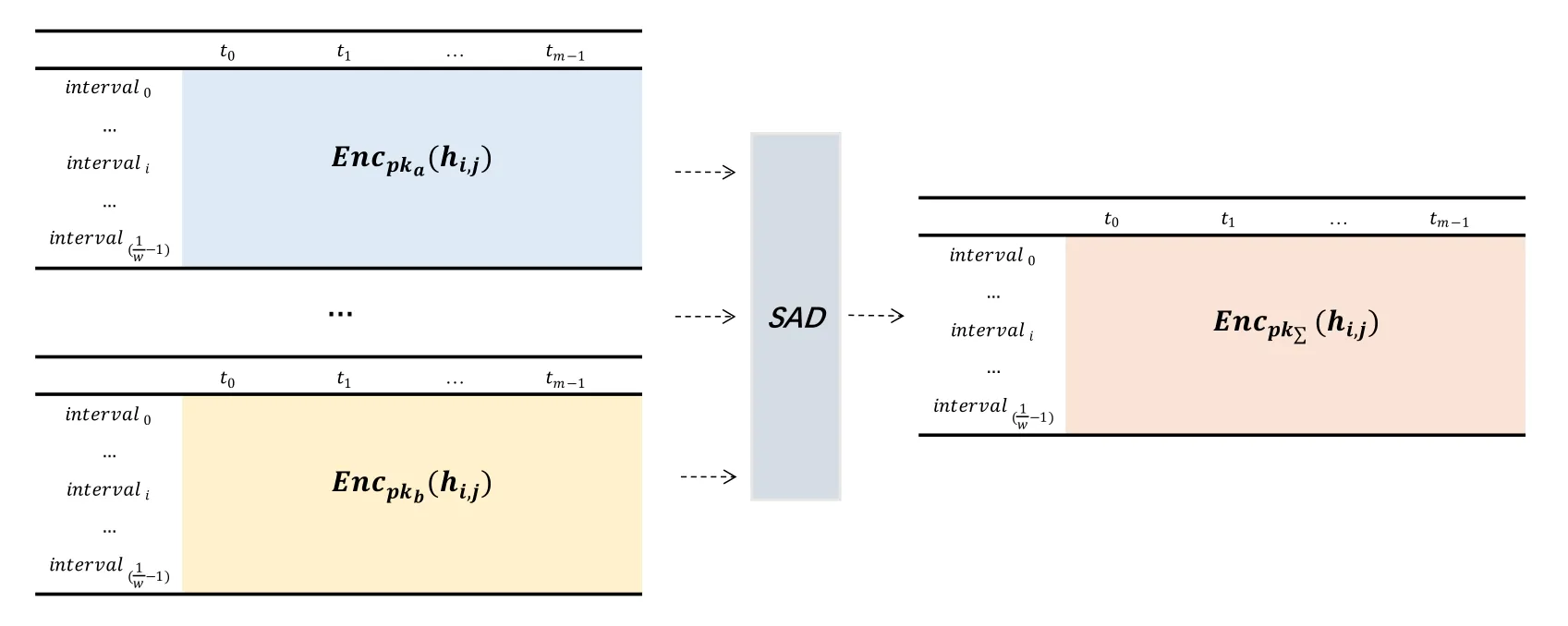
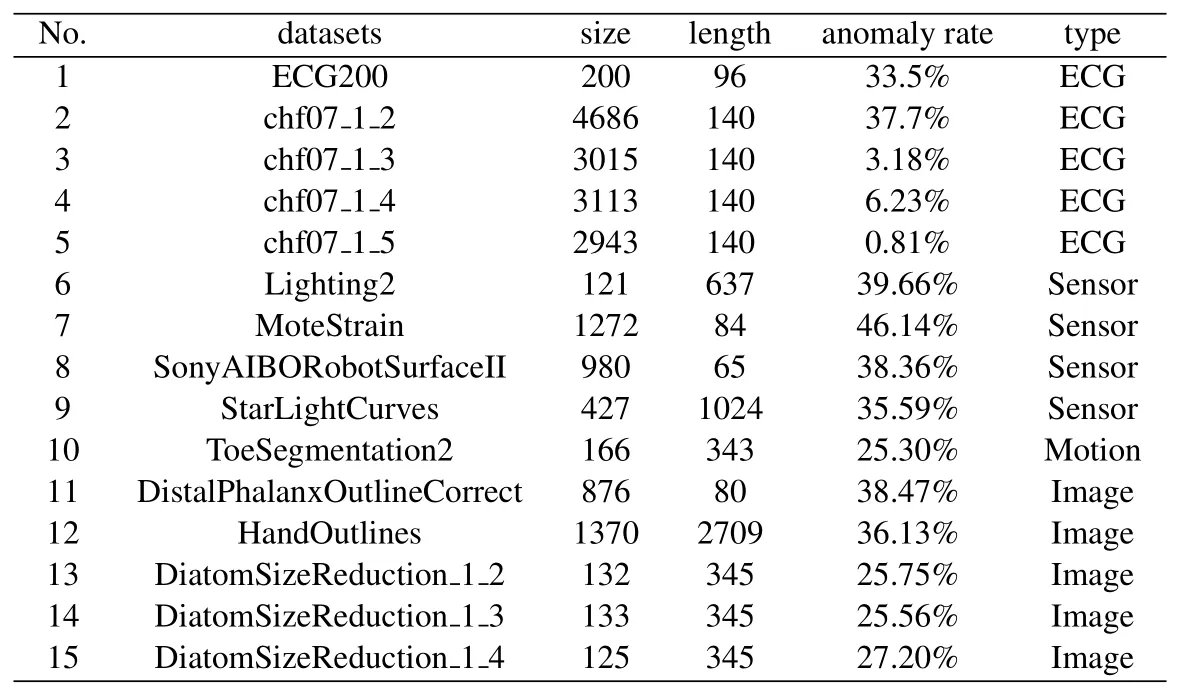
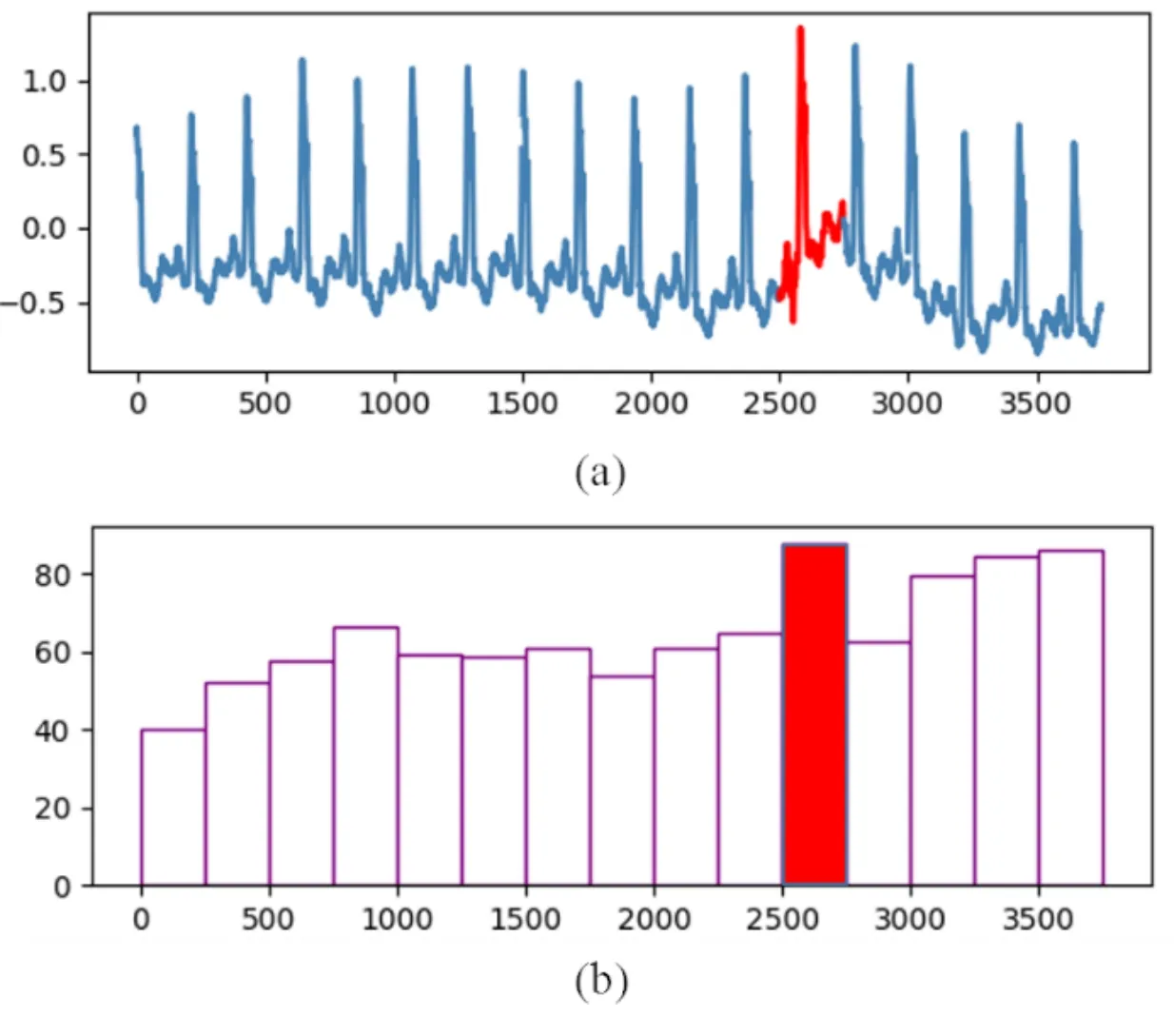
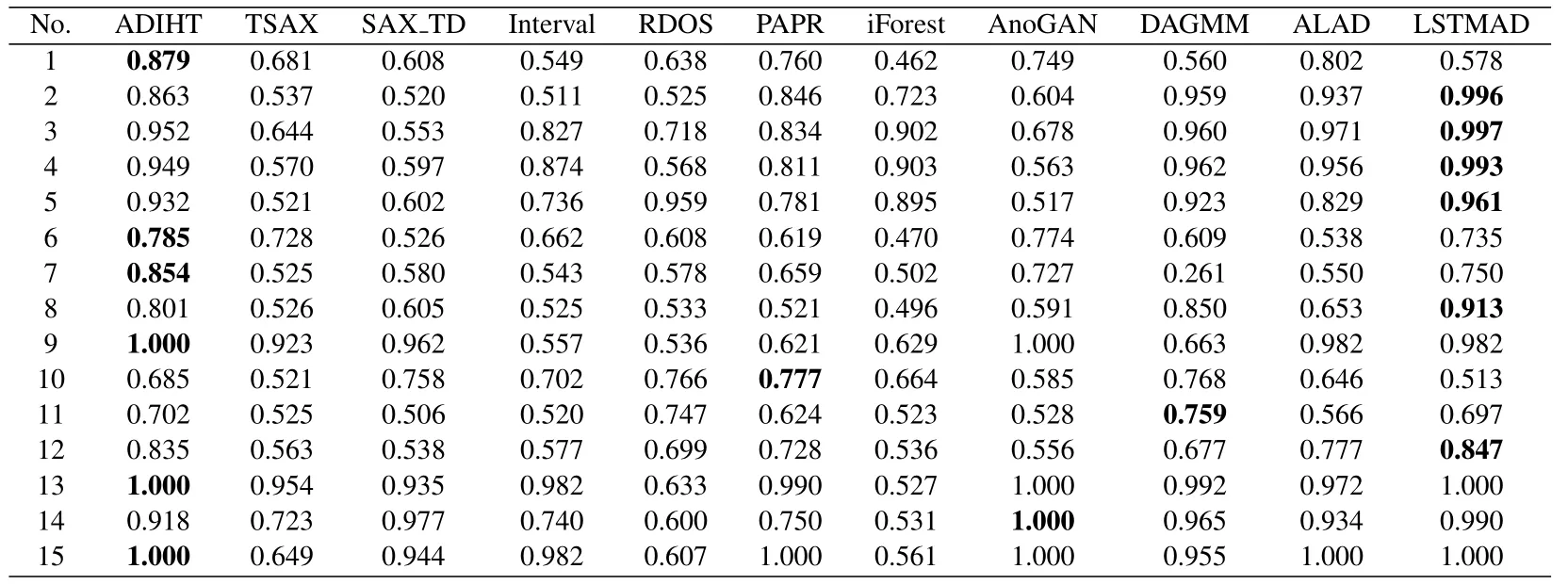
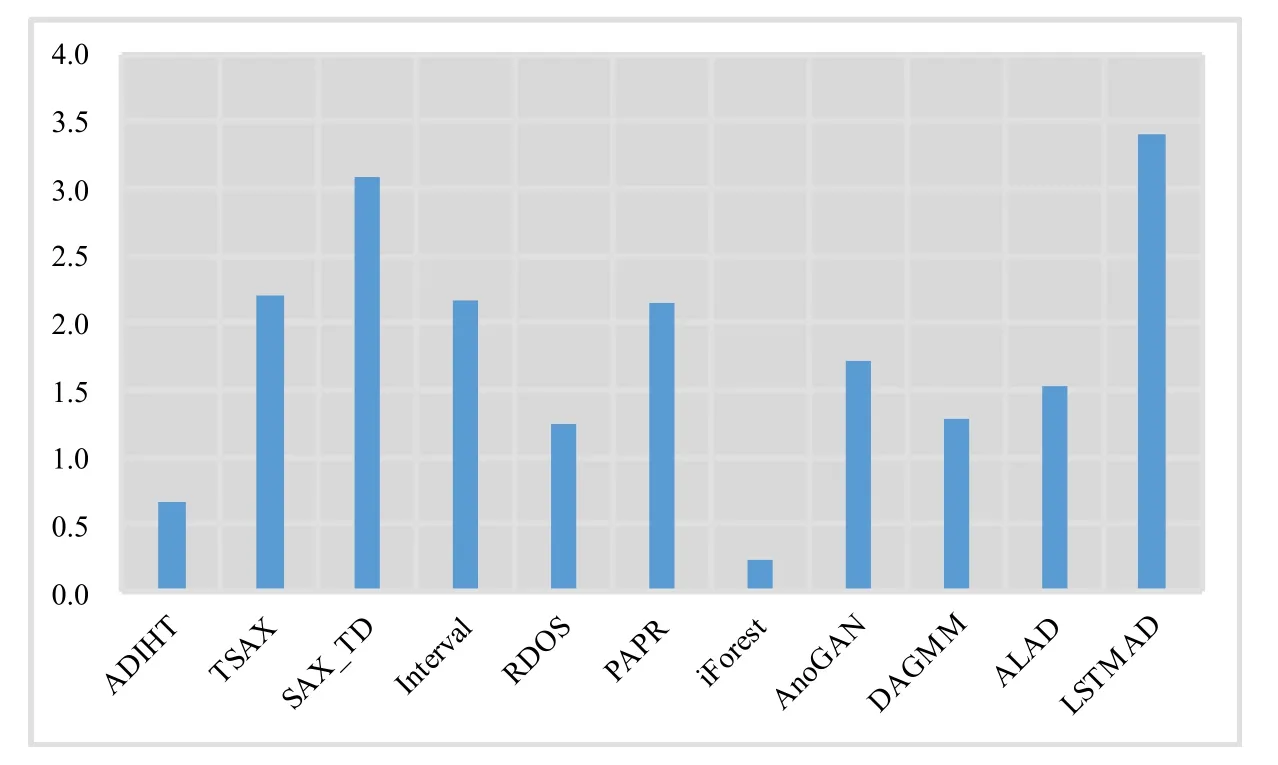
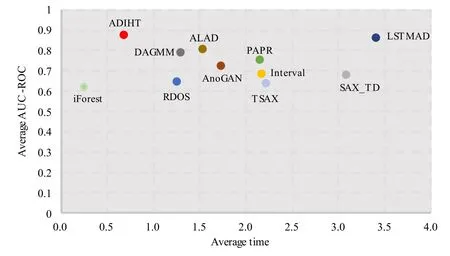
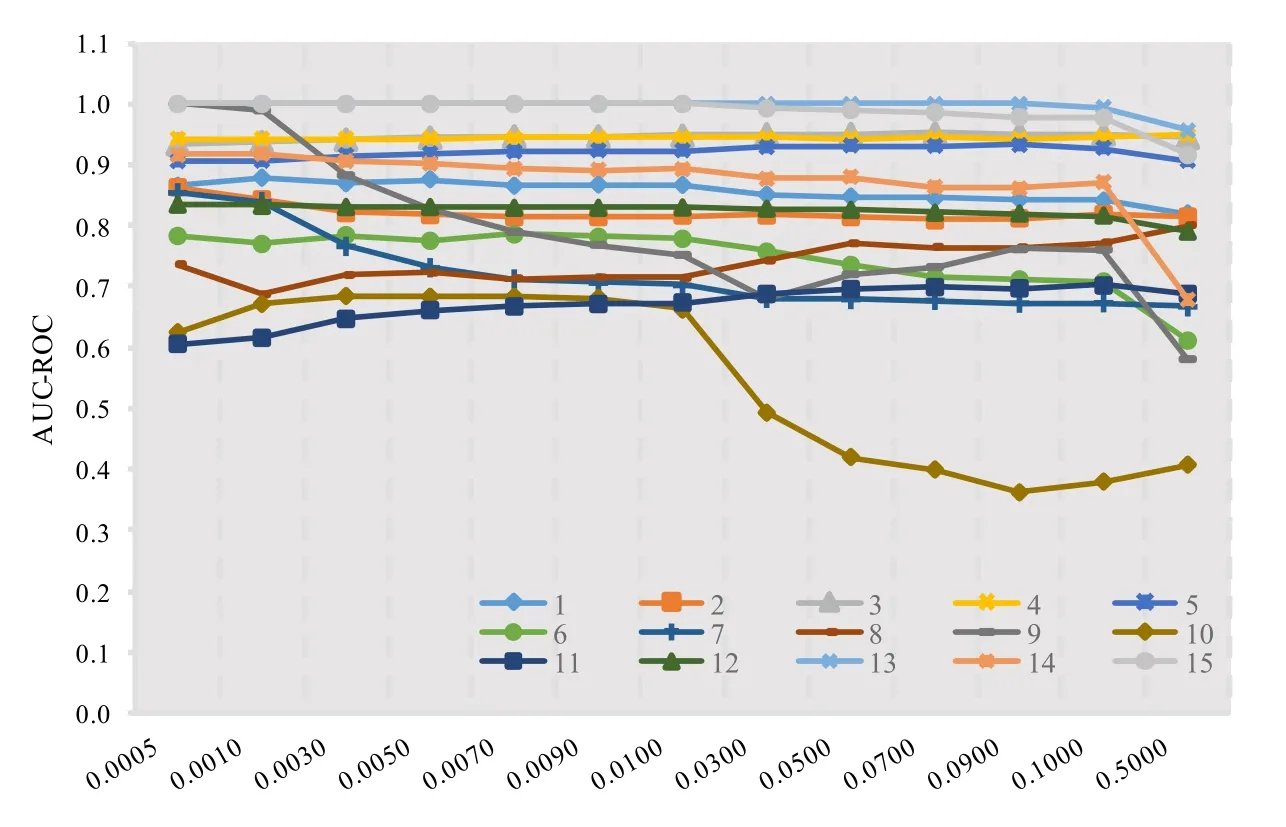
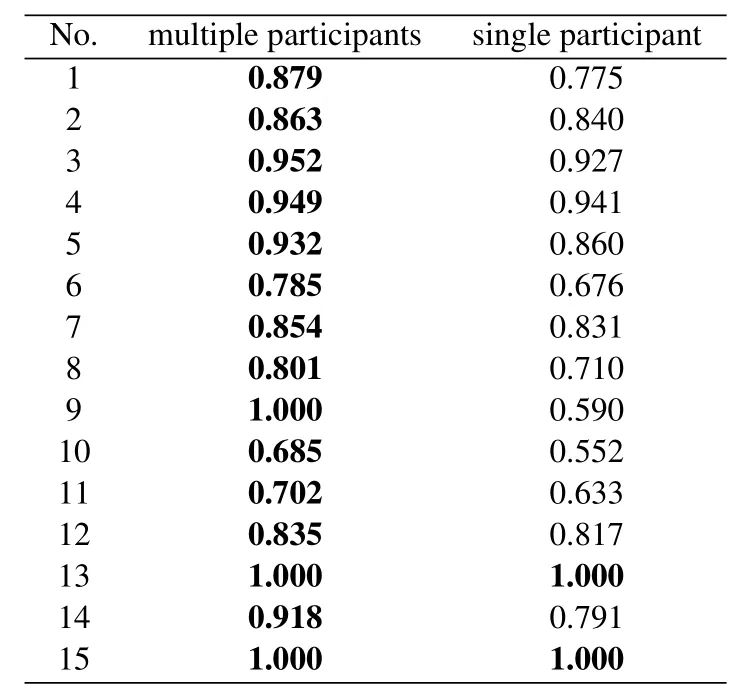
For gettinganoscore(xij)of data pointxijin subsequenceXi, we consider both the density and distance.Compared to normal points, the anomaly will locate in intervals with lower density.As is shown in Figure 2(a),interval1has the highest density, and most normal points(blue points)locate ininterval1,While anomaly points(red points)locate ininterval4with low density.Another circumstance need to pay attention is intervals with equal density but different distance should be considered with different anomaly degree.As is shown in Figure 2(b), two normal points (blue points) locate ininterval0which has the same density asinterval4, butinterval0has a shorter distance to the center ofinterval1(d0−1 Figure 2.Consider both the density and distance to evaluate anomaly degree.(a)Anomalies locate at lower density interval.(b)Anomalies stay far away from normal points. After getting anoscore(xij) we can calculate AnoScore(Xi,) of subsequence Xiby Eq.(7).The higher AnoScore(Xi), the more likely subsequence Xiis an anomaly.The process of our anomaly detection algorithm is described in Algorithm 2. In this section, we propose an Outsourced Privacypreserving anomaly detection scheme based on ADIHT:OP-ADIHT.First,we will introduce the system model.Then, we will give a more detailed description of OP-ADIHT. Algorithm 2.Calculating the anomaly score of subsequences.Require: Time-series data X with N/m subsequences,the subsequence length m,IHTable.Ensure: AnoScore of subsequences.1: AnoScore[N/m]←[].2: for i 0 to N/m −1 do 3: for j←0 to m-1 do 4: s ←query(data point xij of Xi)//query the interval index 5: anoscore(xij)=ds−c ∗hc,j hs,j 6: end for 7: AnoScore[i]= 1 m images/BZ_213_1750_2189_1798_2234.png j=1 anoscore(xij)8: end for In our scheme,the system model is composed of data providers(DPs), an outsourced cloud platform(CP),and computation services provider(CSP).This system model can be seen in Figure 3. Figure 3. The system model of OP-ADIHT. • Key Generation Center (KGC): KGC is tasked with the distribution and management of both public and private keys in the system.KGC will also use the SkeyS method to split the strong private key into two parts. • Data Providers (DPs): Before storing the data with a CP, DP will use its public key to encrypt the data.Each DP has its private key which can decrypt data encrypted by its public key. • Cloud Platform(CP):CP stores and manages data outsourced from all DPs.CP can perform certain calculations over encrypted data and stores all intermediate and final results in encrypted form.CP owns all public key of DPs and partial strong private keySK(1),and can partially decrypt ciphertexts from DPs. • Computation Service Provider(CSP):CSP cooperates with CP and provides online computation services.CSP owns all public key of DPs and partial strong private keySK(2).CSP can partially decrypt ciphertexts sent by the CP,and then re-encrypt the calculated results to CP. Different from existing schemes, OP-ADIHT only needs data owners to send their encrypted IHTable to CP, and CP cooperates with CSP to do the anomaly detection task.Except for requesting the parameterwof IHTable,data owners only need to communicate with CP,which will also reduce communication costs.Steps of our scheme are as follows: Generate key:First KGC run theKeyGento generate the public keypkiand private keyskifor DPs and the strong private keySK.KGC also need to use theSkeySto splitSKintoSK(1)andSK(2).Then,KGC sendSK(1)to CP and sendSK(2)to CSP.CP and CSP also know the public keys of DPs. Encrypt data:First DPs will run Algorithm 1 to construct IHTable and use theEncto encrypt the value ofhi,jin IHTable to construct the Security Interval Hash Table (SIHTable).Then DPs send SIHTables to CP.The structure of IHTable encrypted bypkiis shown in Table 3. Table 3. The structure of SIHTable. Merge IHTables:Once receiving a SIHTable form other data providers,CP will cooperate with CSP and use theSADprotocol to merge SIHTable encrypted by differentpki.The process is as shown in Figure 4. Figure 4. CP merges SIHTables. Anomaly Detection:Assume data provideri(DPi)wants to detect anomalies in his data, and his public key ispkiand the private key isski. • DPi requests CP and CP will send the merged SIHTable encrypted bypkΣ to DPi.The purpose of encrypting the merged SIHTable withpkΣ but notpkiis to prevent information leakage of SIHTable.In this way,we can ensure that DPi cannot decrypt the SIHTable by his private keyski. • DPi receives the merged SIHTable and calculates the encrypted anomaly scores as shown in Algorithm 3.Then DPi sends the encrypted anomaly scores to CP. • CP cooperate with CSP and useTransDecprotocol to transform anomaly scores encrypted bypkΣ to anomaly scores encrypted bypki.Then CP sends the result to DPi. After receiving anomaly scores encrypted bypki,DPi can use his own private keyskito decrypt anomaly scores.Then, DPi can detect which subsequences are more likely to be anomaly according to anomaly scores. In this section, we first demonstrate the utility of our proposed algorithm ADIHT with different real-life datasets.Then, we will analyze the performance of our scheme OP-ADIHT under multiple-party participation and single participation.We also analyze the security of OP-ADIHT. Metrics:In anomaly detection, the AUC represents the probability that the measured algorithm assigns an anomaly subsequence higher anomaly score than a random normal subsequence.So,AUC is appropriate to compare different anomaly detection methods[25],and a larger area under the ROC curve means better performance.We also record the run time of each algorithm. Algorithm 3. OP-ADIHT:anomaly detection with privacy.Require: Time-series data X with N/m subsequences, the subsequence length m, the merged SIHTable.Ensure: Encrypted Anomaly scores of subsequences.1: Enc AnoScore[N/m]←[]2: for i 0 to N/m −1 do 3: for j←0 to m-1 do 4: s ←query(xij of Xi)//query the interval index of data 5: Enc anoscore(xij)=ds−c ∗EncpkΣ (hc,j)EncpkΣ (hs,j)6: end for 7: Enc AnoScore[i] =1 m images/BZ_215_1448_1142_1496_1187.png j=1 Enc anoscore(xij)8: end for Experimental Setup:There are two experiments designed to illustrate the effectiveness of our anomaly detection algorithm ADIHT and the significance of our privacy-preserving anomaly detection scheme OPADIHT. • First, eleven real-life data sets are selected from the UCR Time Series Repository and BIDMC database.These data sets represent typical problems in time-series anomaly detection,and the description of these data sets is summarized in Table 4. Table 4. Description of time-series data sets. • In the first experiment,we compare ADIHT with other state-of-art algorithms.In these compared algorithms, TSAX, SAX TD, and Interval are distance-based algorithms; RDOS is a densitybased algorithm; PAPR is based on the hidden Markov model; iForest is based on the concept of isolation; AnoGAN, DAGMM, ALAD, and LSTMAD are deep-learning anomaly detection algorithms.All the above algorithms are used to calculate anomaly scores for all subsequences in time-series datasets. • In the second experiment,we mainly compare the anomaly detection performance under single participant and multiple participants to verify the effectiveness of OP-ADIHT.First,we assume eachdataset is the combination of data from multiple participants, and we select 25% data from each dataset as the dataset of the single participant.Then, we will compare the performance of our proposed algorithm on data from multiple participants and single participant. Effectiveness:The “chf01” dataset is a heartbeat recording about 20 hours in the duration of a person,and contains signals sampled at 250 samples per second with 12-bit resolution over a range of ±10 millivolts.We select a segment of 15 subsequences, and the length of the subsequence is 250.The anomaly detection result is shown in Figure 5, and we can see the difference in anomaly scores of each subsequence.Anomaly subsequences marked in red have higher anomaly scores, while anomaly scores of normal subsequences are smaller and closer. Figure 5. The anomaly detection result of ECG 200. Accuracy Analysis:All algorithms are executed to obtain stable results on all data sets, and the experiment results are shown in Table 5.From Table 5, we can find that ADIHT has good performance in overall results: 1)ADIHT outperforms non-deep-learning anomaly detection algorithms and perform close to the best results of deep-learning anomaly detection algorithms; 2) ADIHT has more stable results when applying to different datasets.AnoGAN, DAGMM,and ALAD have poorer performance since they all based on reconstruction to find anomaly and generation models sometimes will generate unreasonable data, resulting in inaccurate reconstruction errors and failure to find anomalies.LSTMAD has better performance due to its special structure used for handling time series data.However, LSTMAD has poor performance in the dataset (1, 10, 11), and the sizes of these datasets are small, which is not enough to train the model.Experimental results demonstrate the ability of ADET is good for different classes of time-series datasets. Table 5.AUC-ROC Performance.The best AUC-ROC are highlighted in bold. Running Time Analysis:Figure 6 summarizes the log average time for each algorithm on all datasets.TSAX, SAX TD, and Interval need lots of execution time since they all need to calculate pair-wise distances of subsequences.PAPR also consumes too much execution time as it uses Random Walk to calculate the anomaly score iteratively.Deep-learning methods need even more time, so we use GPU to run deep-learning anomaly detection algorithms.LSTMAD needs the most time of these three deep-learning algorithms.Because each LSTM cell requires four linear layers (MLP layers) for each sequential time step which requires a large amount of computing resources.Of all algorithms, ADIHT and iForest only need linear time, but ADET has better performance in terms of AUC-ROC. Figure 6.Log average running time of these algorithms on fifteen data sets. Overall performance evaluation:we calculate the average AUC-ROC and log average running time of different algorithms based on fifteen datasets to give an overall performance evaluation.As shown in Figure 7, each circle represents an algorithm, plotted by log average running time on the horizontal axis and average AUC-ROC on the vertical.Circle which is closer to the top left represents better overall performance, which has lower time and higher AUC-ROC.It can be seen that ADIHT has the best overall performance compared to other anomaly detection algorithms.ADIHT achieves a better trad-off between AUC-ROC and time complexity. Figure 7.Ovegorithms. Sensitivity Analysis:There is only one parameterwin our algorithm ADIHT, which can affect the anomaly detection accuracy.we record the AUC-ROC of these fifteen data sets with differen values ofwin this experiment when the range ofwis from 0.0005 to 0.5.The results of this experiment are shown in Fig-ure 8,the horizontal axis is parameter w and the vertical axis is AUC-ROC.From this figure,we can notice that AUC-ROC of most datasets is not very sensitive to the parameter w and a small part of datasets have big fluctuations when w >0.01.we can also find that most data sets can get relatively better results when w =0.001.Therefore,ADIHT is not very sensitive to parameter w when w ∈[0.0005,0.01],and we recom mend to set the parameterw=0.001. Figure 8. Figure 8.Sensitive analysis of the parameter w. Accuracy Analysis:Results of anomaly detection based on data from multiple participants and the single participant are recorded in Table 6.Comparing the results of these two columns, it can be seen that the column multiple participants have higher AUC-ROC on most of all data sets.Hence, anomaly detection based on multiple participants is necessary,which can be helpful to find more anomalies and improve accuracy.This experiment also indicates that our algorithm is effective under multiple participants. Table 6. AUC-ROC on data from multiple participants and single participant. Security Analysis:In our scheme, we assume that all participants, including CP, CSP, and data owners,will do anomaly detection tasks based on the proposed protocols.Our model is a semi-honest model and all participants will comply with the security protocols,but they may collect the received information(inputs,outputs, calculated results) to look for some privacy information. • Security analysis under attacks on encrypted data.We use the BCP cryptosystem to encrypt the private data.BCP cryptosystem is semantically secure in the standard model, based on the decisional Diffie-Hellman assumption modulo a square composite number[21].Therefore,privacy information will not be leaked by the encrypted data. • Security analysis under attacks from CP.In our scheme,CP will receive and use theSADprotocol to merge SIHTables form different data provider,but CP cannot decrypt them as it only owns the partial strong private keySK(1).In the anomaly detection stage, CP will use theSADprotocol to transform anomaly scores encrypted bypkΣ to anomaly scores encrypted bypki, and CP also cannot decrypt anomaly scores only with the partial strong private keySK(1).Hence, CP cannot obtain privacy data and anomaly scores in our scheme. • Security analysis under attacks from CSP.In our scheme, CSP is mainly responsible for cooperating with CP and provide calculation resources.Before sending data to CSP, CP will choose a random numberr ∈ZN, calculatesX= [x]pkΣ•[r]pkΣ= [x+r]pkΣ, calculatesX′=PDOSK(1)(X), and sendsXandX′to CSP.CSP can use the partial strong private keySK(2)to obtain the plain text (x+r) and CSP does not know the random numberr.Hence,CSP cannot obtain privacy data and anomaly scores during the calculation too. • Security analysis under attacks from different data owners.There is no more communication among DPs except obtaining the parameter hash parameterw.So, the original dataset will not be leaked.In the anomaly detection stage, DPi will receive the merged SHITables encrypted by the joint public keypkΣ, and DPi cannot decrypt it with the private keyski.So, Dpi will not obtain the HITables of other data providers.Hence,privacy information will not be leaked to other data providers in OP-ADIHT. In this paper, we first propose a data structure named Interval Hash Table(IHTable), which stores distribution information of time series data.Considering that normal subsequences always have a similar distribution and anomaly subsequences distribute differently and randomly,by contrast,we design an anomaly detection method ADIHT based on IHTable.We consider both the density and distance to evaluate the anomaly degree in ADIHT, and the time complexity of our method is linear to the size of the dataset.Since most anomaly detection algorithms are only suitable for the case of data stored in a single party and unable to realize data privacy protection.We extend our algorithm a privacy-preserving anomaly detection scheme OP-ADIHT for multi-party participants with the outsourced cloud platform.To protect data privacy, data owners will transform their IHTable to SIHTable (security IHTable) by encrypting with their public key.Each data owner only needs to outsource their SIHTable to the CP (cloud platform) and then communicate with it to do anomaly detection tasks, which can avoid communications between data owners and reduce communication costs. We also design extensive experiments to show the effectiveness of ADIHT and the significance of our privacy-preserving anomaly detection scheme OPADIHT.Experiment results of fifteen real-life datasets show that ADIHT can outperform most non-deeplearning anomaly detection algorithms and perform close to the best results of deep-learning algorithms in terms of AUC-ROC.What’s more, ADIHT needs the least time to detect anomalies.Anomaly detection results under multiple participants and single participant also demonstrate that anomaly detection based on multiple participants is necessary and helpful to find more anomalies.This experiment also indicates that OP-ADIHT is effective under multiple participants.Security analysis under different circumstances also shows that OP-ADIHT can preserve data privacy in case of anomaly detection under multiple participants. ACKNOWLEDGEMENT This work was supported by Natural Science Foundation of Guangdong Province, China (Grant No.2020A1515010970) and Shenzhen Research Council (Grant No.JCYJ20200109113427092,GJHZ20180928155209705).
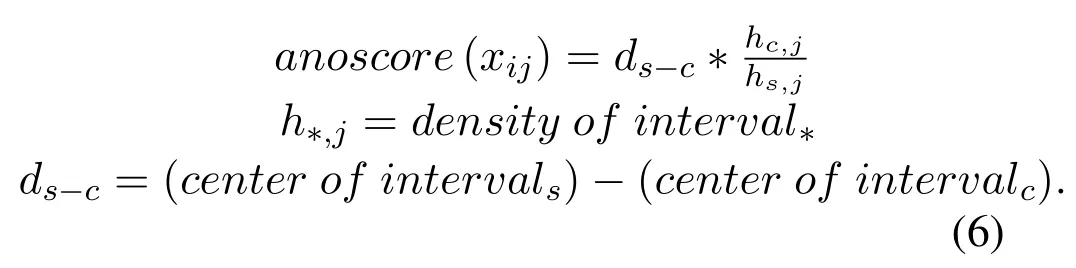
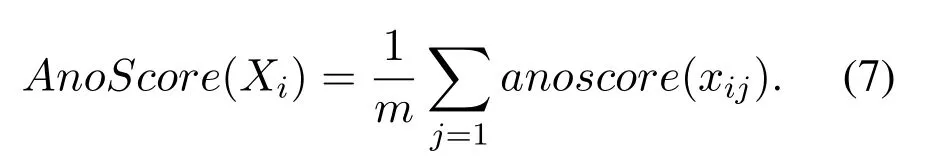
IV.THE PROPOSED OUTSOURCED PRIVACY-PRESERVING ANOMALY DETECTION SCHEME:OP-ADIHT

4.1 System Model
4.2 Outsourced Privacy-preserving Anomaly Detection Under Multiparty
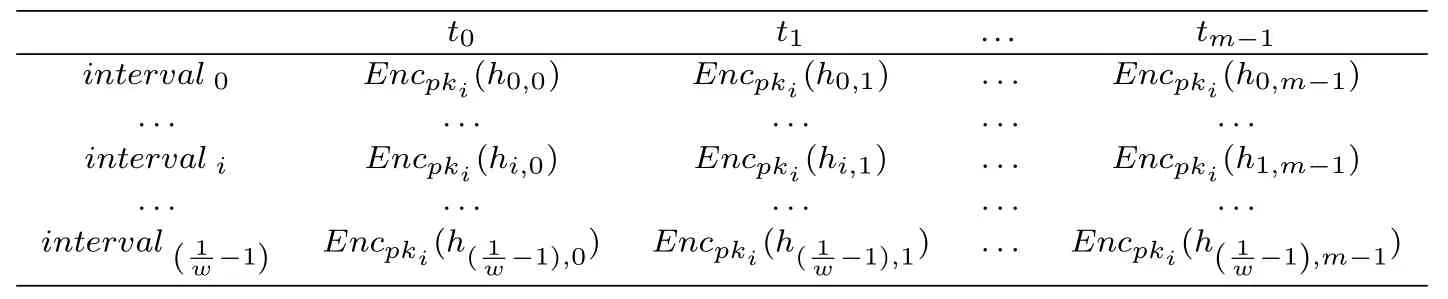
V.EXPERIMENTS
5.1 Evaluation Metrics and Experimental Setup

5.2 Performance of ADIHT
5.3 Performance of OP-ADIHT
VI.DISCUSSION AND CONCLUSIONS

- China Communications的其它文章
- A User-Friendly SSVEP-Based BCI Using Imperceptible Phase-Coded Flickers at 60Hz
- Steady-State Visual Evoked Potential(SSVEP)in a New Paradigm Containing Dynamic Fixation Points
- Toward a Neurophysiological Measure of Image Quality Perception Based on Algebraic Topology Analysis
- Transfer Learning Algorithm Design for Feature Transfer Problem in Motor Imagery Brain-computer Interface
- Removal of Ocular Artifacts from Electroencephalo-Graph by Improving Variational Mode Decomposition
- BCI+VR Rehabilitation Design of Closed-Loop Motor Imagery Based on the Degree of Drug Addiction