
Cryptomining Malware Detection Based on Edge Computing-Oriented Multi-Modal Features Deep Learning
2022-03-01 00:12WenjuanLianGuoqingNieYanyanKangBinJiaYangZhang
China Communications 2022年2期
Wenjuan Lian,Guoqing Nie,Yanyan Kang,Bin Jia,*,Yang Zhang
1 College of Computer Science&Engineering,Shandong University of Science and Technology,Qingdao,Shandong 266590,China
2 College of Foreign Languages,Shandong University of Science and Technology,Qingdao,Shandong 266590,China
Abstract: In recent years, with the increase in the price of cryptocurrencies, the number of malicious cryptomining software has increased significantly.With their powerful spreading ability, cryptomining malware can unknowingly occupy our resources, harm our interests, and damage more legitimate assets.However, although current traditional rule-based malware detection methods have a low false alarm rate, they have a relatively low detection rate when faced with a large volume of emerging malware.Even though common machine learning-based or deep learning-based methods have certain ability to learn and detect unknown malware,the characteristics they learn are single and independent,and cannot be learned adaptively.Aiming at the above problems,we propose a deep learning model with multi-input of multi-modal features, which can simultaneously accept digital features and image features on different dimensions.The model in turn includes parallel learning of three sub-models and ensemble learning of another specific sub-model.The four sub-models can be processed in parallel on different devices and can be further applied to edge computing environments.The model can adaptively learn multi-modal features and output prediction results.The detection rate of our model is as high as 97.01% and the false alarm rate is only 0.63%.The experimental results prove the advantage and effectiveness of the proposed method.
Keywords: cryptomining malware; multi-modal; ensemble learning;deep learning;edge computing
I.INTRODUCTION
Blockchain has been one of the hotspots in the field of security and communication networks in recent years[1–5].Cryptocurrencies such as Bitcoin [6], Monero and Ethereum [7] are traded through blockchain technology.Miners who can obtain monetary rewards through packaging transaction blocks need to solve complex mathematical problems as Proof of Work(PoW) to qualify for packaging.Generally speaking, there is a positive correlation between problemsolving speed and computing power.Therefore,in order to obtain more computing power and reduce purchase costs,miners try to use malware to control multiple hosts and obtain illegal benefits.
In 2009,Bitcoin became the first decentralized cryptocurrency and was sold in many places around the world,which promoted the rapid development of cryptocurrency transactions[8].In 2020,the price of Bitcoin once exceeded USD 50,000,and its market value reached USD 920 billion, ten times that of the end of 2019 [9].Therefore, cryptocurrency has become one of the most serious cybersecurity threats,and has contributed to illegal cryptomining [10], which will reduce the execution speed of normal processes, increase the power consumption of system resources such as CPU and GPU,and reduce the service life of the hardware.
Therefore, more researchers are devoted to the detection of mining malware.The traditional methods,such as searching for known strings in the source code[11],and calculating hash value of software and matching it with virus database, are highly targeted and have a low false alarm rate.However, with a low detection rate, they cannot resist a large number of newly generated malware every day.
Later,with the development of artificial intelligence,the emergence of traditional static machine learning models (such as support vector machines [12], naive Bayes, decision trees [13], etc.), and malicious code detection techniques using machine learning and deep learning have emerged[14].The technology is essentially based on statistics and probability,and relies on feature extraction methods such as Strings, API/System Calls and N-grams [15].But it relies heavily on specific domain knowledge in feature extraction,and it is difficult to deal with various mining malware.Subsequently, some other forms of feature engineering and methods based on deep learning appeared, such as the method of converting Portable Executable(PE)files into images[16–18],and the method of constructing sequences using N-grams [19–22], etc.The deep learning methods can perform feature extraction adaptively and do not rely on feature engineering.However, most of the current researchers are limited to single-model features, with insufficient sample information.
Based on the shortcomings and limitations of the above methods, we propose a deep learning detection method for malicious mining software with multimodal features,which can be extracted into the following three parts:
• Grayscale images feature: Convert every eight bits into a number from 0 to 255, and then convert the sample into a grayscale image based on the above grayscale number.
• Byte/Entropy histogram feature: Extract the byte histogram and byte entropy histogram of the program file.
• Feature engineering: Use expert knowledge for traditional feature engineering.
We use three deep learning sub-models to accept the features of the three modalities, and use another deep learning sub-model to learn and predict the output of the above three sub-models.In other words,the overall deep learning model actually contains four deep learning modules with different functions,which can be executed separately or simultaneously.The networks such as EfficientNet and Bi-directional Gated Recurrent Unit (Bi-GRU) can be used to build the model.Our main work and innovations are as follows.
• The features of the software in different modes are extracted and the sample information description is more comprehensive.
• The proposed model separately learns the features of different modes and optimizes the effect of each model.
• A single model can be incorporated into the overall model as a block, the outputs of each block can be spliced and deformed, and the next stage of deep learning model can be output for further learning and prediction.
The data used in our research, are provided by the Datacon community [23].The detection rate of our method is up to 97.01% and the false alarm rate is 0.63%, and the final score can be 96.25% with a penalty factor of 1.2 for false alarm rate.Besides, Precision-Recall (P-R) curve, Receiver Operating Characteristic (ROC) curve, Area Under Curve(AUC), F1-score, and other metrics are provided to evaluate our method.The proposed method has achieved excellent results under various evaluation metrics,and its effectiveness and superiority have also been proved.
Mining malware even generates serious potential threats to the smart devices in the edge Internet of Things(IoT).Security researchers from Romanian antivirus provider Bitdefender discovered a botnet that attempts to mine cryptocurrency after infecting home routers and other IoT smart devices[24].It also means that the IoT smart devices(routers,refrigerators,color TVs and the like) may unknowingly be occupied by mining malware in the future.
Furthermore, with the improvement of edge computing technology[25–27],our model can be more efficiently deployed.The reasons are as follows: edge devices can extract corresponding features by themselves instead of uploading file as a whole and extracting it by the server; and our model is detachable and can also be deployed in a distributed manner to further improve service efficiency.
The rest of this article is arranged as follows.Section II mainly introduces the work related to the encryption mining malware research; Section III describes the feature extraction method of mining software dataset of the Datacon community; Section IV focuses on the design and optimization methods of the model; Section V gives the experimental result and analysis to verify our methods and models; and Section VI is the summary and prospect of our work.
II.RELATED WORK
Malware detection methods are divided into static analysis and dynamic analysis [28].Static analysis[29] is to analyze and extract original program and source code.It can analyze and detect samples that need not be run in less time.Meanwhile, dynamic analysis obtains more analysis features by extracting information and behaviors generated when the program runs.It requires a running environment, so the speed is slower, and the program must be executable[30].Just like the Datacon dataset used by us,the PE header of the sample is erased,and the sample cannot be run directly.The paper adopts static program analysis,without building a sandbox,directly reading and extracting binary files.Although many features that need to be run dynamically cannot be extracted,static analysis is fast and easy to deploy.
Static analysis proposed by Anderson et al.[31]is more comprehensive and detailed.It includes such raw features as overall sample features,file header features,import table features,export table features,section features, string features and histogram features,and provides a more comprehensive reference for future research.Researchers can select suitable features and add some other important elements based on specific research.The traditional machine learning methods,with fewer parameters,faster speed and easier deployment,must be based on better feature engineering[12, 13], which is the necessary condition for a comprehensive description of samples.
Then, deep learning developed rapidly, and many methods based on the technology emerged.The advantage of deep learning is its no requirement for complex feature engineering.The deep learning model[16, 17] uses the binary form of the sample to read it as a set of 8-bit unsigned integers,which can adaptively learn useful features from the original data.The 8-bit corresponds to the decimal range[0,255],which further corresponds to the color from white to black in the image.Generally, the width of the picture is fixed,and the length is adaptively generated according to the file size.Then, these grayscale images can be input into general image deep learning models, such as many existing models based on Convolutional Neural Network(CNN),for learning and prediction.Saxe et al.[32]proposed byte/entropy histogram features in 2015.The features are based on window sliding calculation and reflect entropy context.The final grayscale image can also be learned using deep learning models such as CNN.
In addition to image-based algorithms, Yazdinejad et al.[19] proposed a cryptocurrency malware detection method based on Recurrent Neural Network(RNN).The method uses application operation codes(opcodes) as sequence data and Long Short-Term Memory(LSTM)for classification.Although embedding technology is used, ordinary RNN cannot learn ultra-long sequences of the opcodes.Darabian et al.used one-dimensional CNN and RNN in Ref.[33]to learn sequence data.If the dataset is static, the accuracy of the two methods can reach 0.95.
The extraction method of a single modal of features is relatively single,and cannot completely extract and describe the sample.Moreover, the single model is easily affected by strong features, and its generalization ability may be insufficient.Some ensemble methods mentioned in[14,34]are relatively simple.Most researchers usually use the simple voting method of multiple models or directly mix features into one single model.For traditional machine learning methods,ensemble learning based on Stacking[35]is used.In order to enable the deep learning model to receive input of multiple features in different forms at the same time,we design a deep learning ensemble model based on multi-modal features.
In recent years, multi-modal technology has made certain progress[36].Kahou et al.proposed a multimodal deep learning method in Ref.[37]to judge the emotion of the characters in the video.Facial features,audio features,and mouth features are input into different models, which further form the integrated model.Compared with the prediction result of a single model, the method can obtain a higher accuracy rate.Also, our research is inspired by multi-modal deep learning,trying to learn and predict the different modal features at the same time.
The modeling process includes two parts: feature extraction and model selection.Generally speaking,data and extracted features always determine the upper limit of the final performance, and the selection,training and optimization of the model are the means to keep approaching this upper limit.
With the rise of edge computing,deep learning can better solve the problems of speed and model size[38].Hsu et al.introduced a case[39]that uses edge computing technology to deploy an Android malware detection model.The characteristics of the model can be generated by the terminal itself,and simple model deployment and prediction can be carried out.Then,the generated features and prediction results of the simple model are uploaded to the cloud,and the final prediction is completed through the cloud server.It not only improves the speed and reduces the pressure on the cloud server,but also protects user privacy to a certain extent.
In summary,the previous work has achieved excellent results in some aspects, but the combination of multiple methods is not enough.Therefore, we propose a multi-modal deep learning method that can simultaneously combine the advantages of multiple works.The method uses multi-modal features based on images,histograms,and feature engineering.It can not only analyze the static characteristics of samples,but also be applied to the dynamic characteristics analysis.We hope the method will be a good inspiration and promotion for future research.
III.MULTI-MODAL FEATURES PROCESSING
In the feature extraction part,we extract the features of the three modalities from three different perspectives,that is,grayscale images,byte/entropy histogram,and feature engineering.Meanwhile, we present that multi-modal features can be input into deep learning model,and multi-modal features can be learned.
3.1 Grayscale Images Feature
For the characteristics of the first modal, we adopt the grayscale image model which has been commonly used in deep learning in recent years.We convert every eight bits into a number from 0 to 255, and then convert it into a grayscale image based on the grayscale value.As a picture feature,the value can be adopted by many mature deep learning models.Usually, this method fixes the width of the grayscale image, and the file size fixes the length.We use the dimension of(512,-1).The picture we get after visualizing the grayscale image is shown in Figure 1.

Figure 1. Grayscale representation of mining malware.
3.2 Byte/Entropy Histogram Feature
After that,we extract byte histogram and entropy histogram of the sample.The byte histogram is similar to the Bag-of-words model,which counts the number of occurrences from 0x00 to 0xff in the binary file.The Bag-of-words model is prone to overfit,so it should be standardized, and the Term Frequency-Inverse Document Frequency(TF-IDF)idea for transformation can be used.
The byte entropy histogram is developed based on the byte histogram, and it introduces the concept of information entropy.There are 256 values from 0x00 to 0xff:U1,U2,U3,...,U256, and the corresponding probability is:P1,P2,P3,...,P256.The appearance of various symbols is independent of each other.At this time,the information entropyH(U)of the source is defined as Eq.(1),n=256.Functionally speaking,the byte entropy histogram is similar to the joint distributionp(H,X)of entropyHand byte valueX.We define a 16×16 matrix to store the calculated byte entropy histogram.If we only calculate the information entropy of the upper four bits of each byte, then the value of the byte can be converted into 0x00-0x0F.The horizontal axis of the byte entropy histogram represents bytes and its length is 16,which represents byte values 0x00-0x0F respectively.The vertical axis represents entropy and the length is 16,which represents the information entropy multiplied by 2 and the integer bits are from 0 to 15.
After the two histograms are merged,a vector with a dimension of (256, 2) is got.It should be reshaped and a vector with dimension of (32, 16) can be obtained.Next, the vector is input into the proposed CNN-based deep learning model for learning.If this feature is scaled to the range of[0,255],it can also be visualized,as shown in Figure 2.

Figure 2. Visualization of byte/entropy histogram feature.
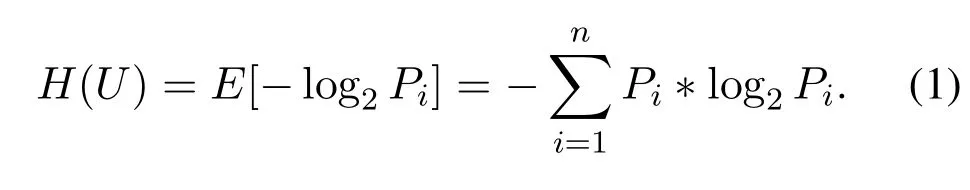
3.3 Feature Engineering
Finally, we combine commonly used features of binary samples and use expert knowledge to perform traditional feature engineering.In addition to the commonly used features, including section information,entropy values,etc.,we also extract some unique features to mining software according to specific research scenarios.These features include the matching results of specific characters, such as CPU, GPU,common mining pool names and addresses, binary codes of common mining machines,etc.Also,after a simple and incomplete repair of the erased head of the sample, the part of the sample can be shelled or partially executed.By using these techniques,some shell samples can smoothly extract useful features.Ultimately,we get the feature vector with dimension(54,1).
IV.CRYPTOCURRENCY MALWARE DETECTING METHODOLOGY
Overall, the proposed model consists of two stages,which include four sub-modules.The first stage includes three sub-models that aim to learn and extract different single features respectively.The second stage includes an ensemble learning sub-model which aims to ensemble learning of the three extracted features.Each block can be considered as a deep learning model.Four small deep learning sub-models form an overall deep learning model.If each feature extraction model is added with a classification layer, the model can be trained separately and the best parameters can be obtained.In the final model,the part of the parameter loading method can be used to load the parameters of the feature extraction model.In the final training,the learning rate of the feature extraction model can be reduced, and final ensemble fusion model can be focused on training.The overall design and workflow of the model are shown in Figure 3.
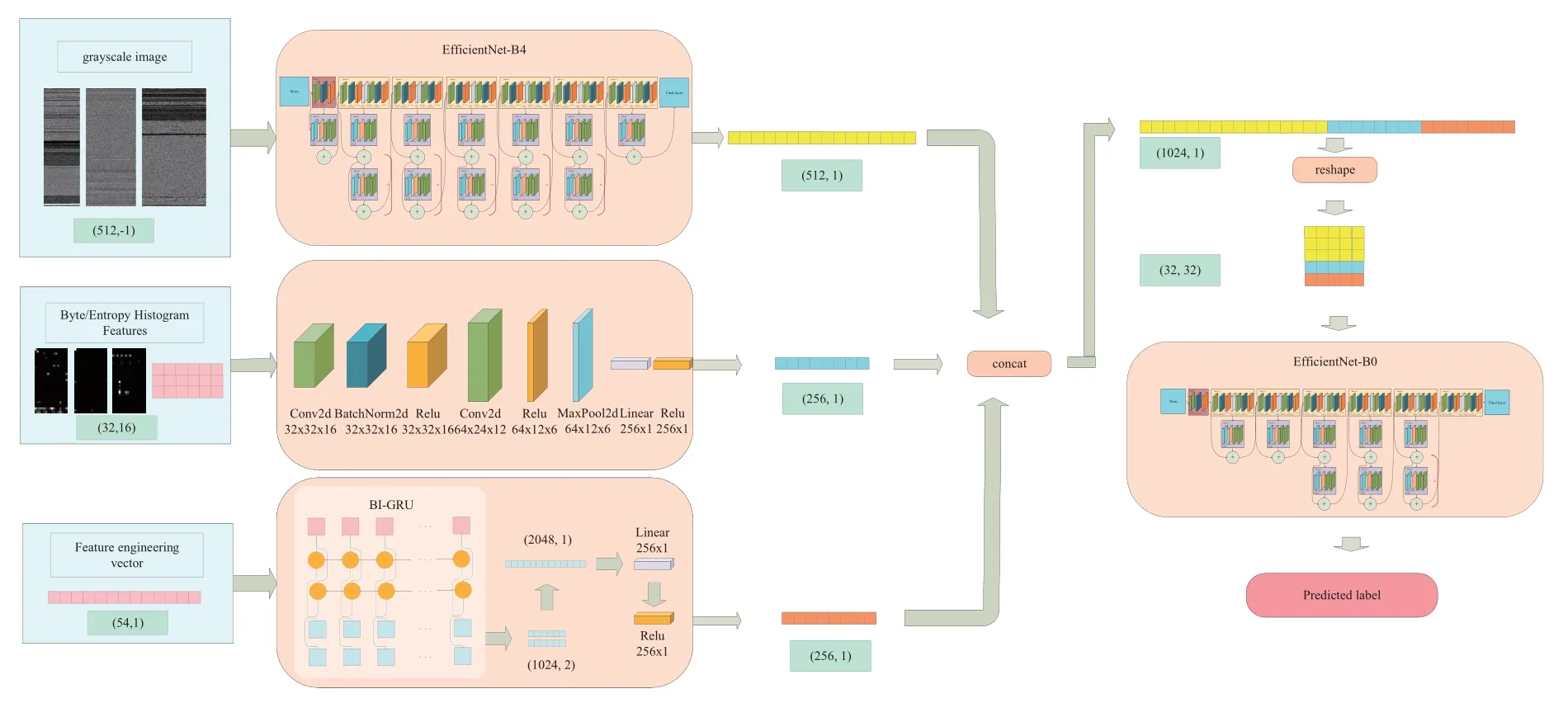
Figure 3. The overall design and workflow of the multi-modal deep learning model.
4.1 Feature Extraction Learning Blocks
4.1.1 Grayscale Images Learning Block
For the features of grayscale images,we use Efficient-Net, which is a multi-dimensional model that integrates scaling method, and is one of the best models on ImageNet image classification task[40].With simple design idea, it could achieve a good final effect.The scaling method and Neural Architecture Search(NAS)are the core ideas of EfficientNet.Researchers use NAS technology and a large number of computing resources to obtain the best baseline model, and then scale the three directions of depth,width,and resolution of the baseline model to obtain other models of different sizes.Experimental results show that this simple idea achieves the state-of-the-art performance in each dimension after zooming in.
Assume the feature of the gray image isXa, and EfficientNet-B4 isE4.The gray image features(512,512)are input into EfficientNet-B4 to get the extracted features(512, 1).The feature extraction process of Grayscale images is shown in Eq.(2).
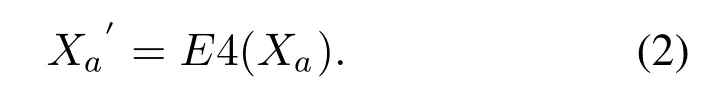
4.1.2 Byte/Entropy Histogram Learning Block
In the learning module of byte histogram and entropy histogram, we have designed a basic model based on CNN.Through convolution, batch normalization,pooling and other functions, the characteristics of the histogram have been learned.As shown in the Eq.(3),the feature of byte histogram and entropy histogram is expressed asXb, and the custom convolution model is expressed asIC.The histogram feature (32, 16)passes through the convolution-based feature extraction module to obtain the featureXb′(256,1).
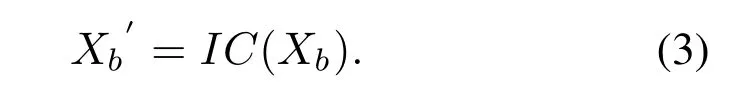
4.1.3 Feature Engineering Learning Block
For feature engineering vectors extracted by using professional domain knowledge, we use a deep learning model based on Bi-GRU to learn them.We treat feature vectors as sequence data.Bi-GRU can learn sequence features in two directions simultaneously.Assume the feature of feature engineering isXc,and the custom Bi-GRU isFG.The feature vector (54, 1) is obtained through the Bi-GRU module to obtain the extracted featureXc′(256,1).
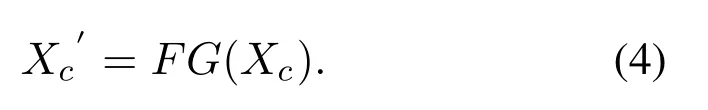
4.2 Ensemble Learning Block
After obtaining the features extracted by the three feature extraction models, we need to splice and transform them.First, we concatenate three vectors with dimension of(512,1),(256,1),and(256,1)to obtain a vector with dimension (1024, 1).After that, we reshape the obtained vector into an image-like vector of size(32,32).Finally,it is input into the model based on EfficientNet-B0 to get the final prediction result.
As shown in the Eq.(5) and Eq.(6), assume EfficientNet-B0 isE0,and the final result isY.Afterare concatenated and reshaped by the Eq.(5),we get the combined featureX.Xpasses through the final EfficientNet-B0 to produce the final resultY.
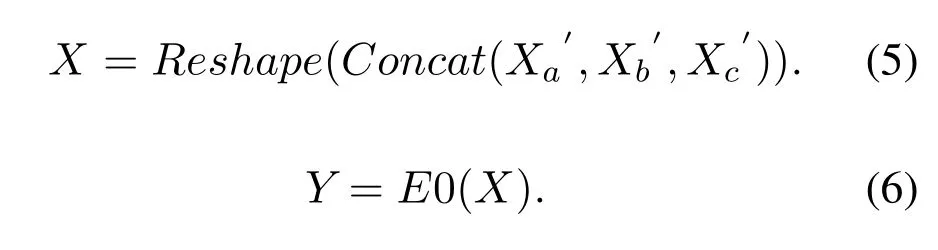
4.3 Edge Computing
The diversified applications in the 5G era have promoted the rapid development of edge computing,which plays an increasingly prominent role in IoT devices.In the near future,it can be predicted that more IoT smart devices will be hijacked and infected with mining.Therefore, with the help of edge computing,we can consider deploying models to detect malicious mining software methods[41,42],in order to prevent the above problems before they happen.
The proposed model consists of four parts, each of which has different computational costs and required resources.Edge computing combined with cloud technology can greatly improve the efficiency of the model[43, 44].The process from the mining malware to the three features can be completed independently by edge devices,and then the features are uploaded to the cloud.For devices with higher hardware configurations,we can even complete the first stage model prediction task on edge devices.The model firstly outputs the intermediate features and then uploads them to the cloud for final prediction.It not only improves efficiency but also protects the privacy of samples provided by users.Just like the way we deal with federal learning, we can complete learning and analysis without uploading samples.As shown in Figure 4,the edge terminal can convert the original file into features, and submit the features to cloud distributed model for learning and prediction.For the edge units with better computing capabilities, the first stage of feature extraction in the model can be completed locally, and more abstract security data can be submitted.
4.4 Tricks
In the process including model training and feature extraction,some other tricks are also used.
4.4.1 Focal Loss
There are 5,898 mining samples and 11,759 nonmining samples, which is extremely unbalanced.In order to solve this problem, we adopt the loss function of focal loss[45].By applying different weights to different labels,the samples with small volumes are made more important to the model.Focal loss can be used not only on the final overall model but also on the separately trained feature extraction models.
4.4.2 Pre-Training
In the model training phase,we adopt the pre-training method.Classification layers are added after each feature extraction model,and the three models are trained separately by using focal loss.The training process of each model has been independently optimized,and three better feature extraction models have been obtained.Next, the parameters of the three feature extraction models are partially loaded into the overall model.During the overall model training, the feature extraction models require little training and are set to a small learning rate.Meanwhile,the ensemble fusion part of the overall model imposes a relatively large learning rate.
4.4.3 Yara
Yara is a common tool for security personnel to analyze and detect malicious samples [46].We write some Yara rules through reverse analysis of a small number of malicious encrypted mining samples.Through Yara rules,we can detect about 90%samples.Although the detection rate is not high enough, we can do a lot of work because its false positive rate approaches zero.For example, in the actual production environment, the number of samples is often insufficient and uneven.In this way, the matching mining programs can be found from a test set or a new set of unlabeled samples, and then they can be put into the training set for enhanced learning.Since these techniques are complementary to the model, they are not used to improve the final results in this paper.
V.EXPERIMENTAL RESULTS
5.1 Datasets
The dataset used by us is provided by the Datacon community[23].This dataset is only available for research fields, and includes 17,657 samples, of which 5,898 are mining samples and 11,759 are non-mining samples.This dataset comes from a large amount of mining malware, non-mining malware and normal software that are captured from the live network.After data cleaning, samples with a size between 20KB and 10MB are extracted, and excessive codes are removed by code similarity analysis and the other methods.Overly similar samples are removed through the method of code similarity analysis,so as to ensure the diversity of the samples.Not all non-mining samples are benign software,and some non-mining malware is also included.This classification also brings research value to the further analysis of this work.To avoid the sample being run,MZ header,PE header,import table,and export table in the sample PE structure have been erased.Although the cleaned samples cannot be analyzed dynamically,the code instruction characteristics of the mining function still exist.
We appreciate the Datacon community for their contributions to scientific research.We will also strictly abide by relevant academic ethics and will not use this dataset for profit.If any research purpose is needed,please contact the Datacon community for the dataset.
The environment for the experiment is shown in Table 1.
Table 1. Experimental environment.
5.2 Evaluation Metrics
In terms of the evaluation metrics of the experimental results,we obtain the values of True Positive(TP),False Negative (FN), False Positive (FP), and True Negative(TN)by calculating the confusion matrix.TP represents how many mining samples are detected;FN represents the number of mining samples predicted as non-mining samples; TN represents how many nonmining samples are detected; and FP represents the number of non-mining samples predicted as mining samples.According to these four values, the evaluation metrics can be calculated.
First, we calculate the traditional metrics, such as Accuracy rate, Precision rate, Recall rate, and F1-score.Suppose that the samples which are predicted as mining samples areYm−in−pis the number of actual mining samples inPrecision rate refers to the ratio ofYm−in−pto.Recall rate refers to the ratio of predicted mining samples to actual mining samples.Precision rate and Recall rate are a pair of evaluation metrics that check and balance each other.Taking the two metrics into consideration,we also use F1-score.The calculation method of F1-score is shown in Eq.(10), which uses the metrics of Precision rate and Recall rate at the same time.Only when the Precision rate and Recall rate are both high,the value of F1-score will perform better.Besides,the P-R curve and ROC curve have also been drawn.In addition, the value of AUC is also added to the ROC curve.
According to the actual production environment,we employ the metrics shown in Eq.(11).True Positive Rate(TPR)and Recall rate are completely equivalent, which means the detection rate.False Positive Rate (FPR) indicates the proportion of false predictions among the detected mining samples.αis the penalty factor,which determines the importance of the false alarm rate in the final result.In other words,we can customize the tolerance for false positives according to actual needs.

5.3 Results Analysis
We conduct tests on three multi-modal feature extraction modules and an ensemble fusion module.The performance of the four modules on the test machine is shown in Table 2,Figure 5 and Figure 6.Our metricuses a penalty factor of 1.2,which means that for mining samples, 1.2 times the incorrect judgment score should be subtracted from the correct judgment score.We hope to discuss the detection capabilities of the model with a lower false alarm rate.It can be seen that our model has reached the optimal result under any index.That is to say,the proposed model uses different model modules and absorbs effective information with different characteristics at the same time.It also determines the better performance of the deep learning model based on multi-modal features.
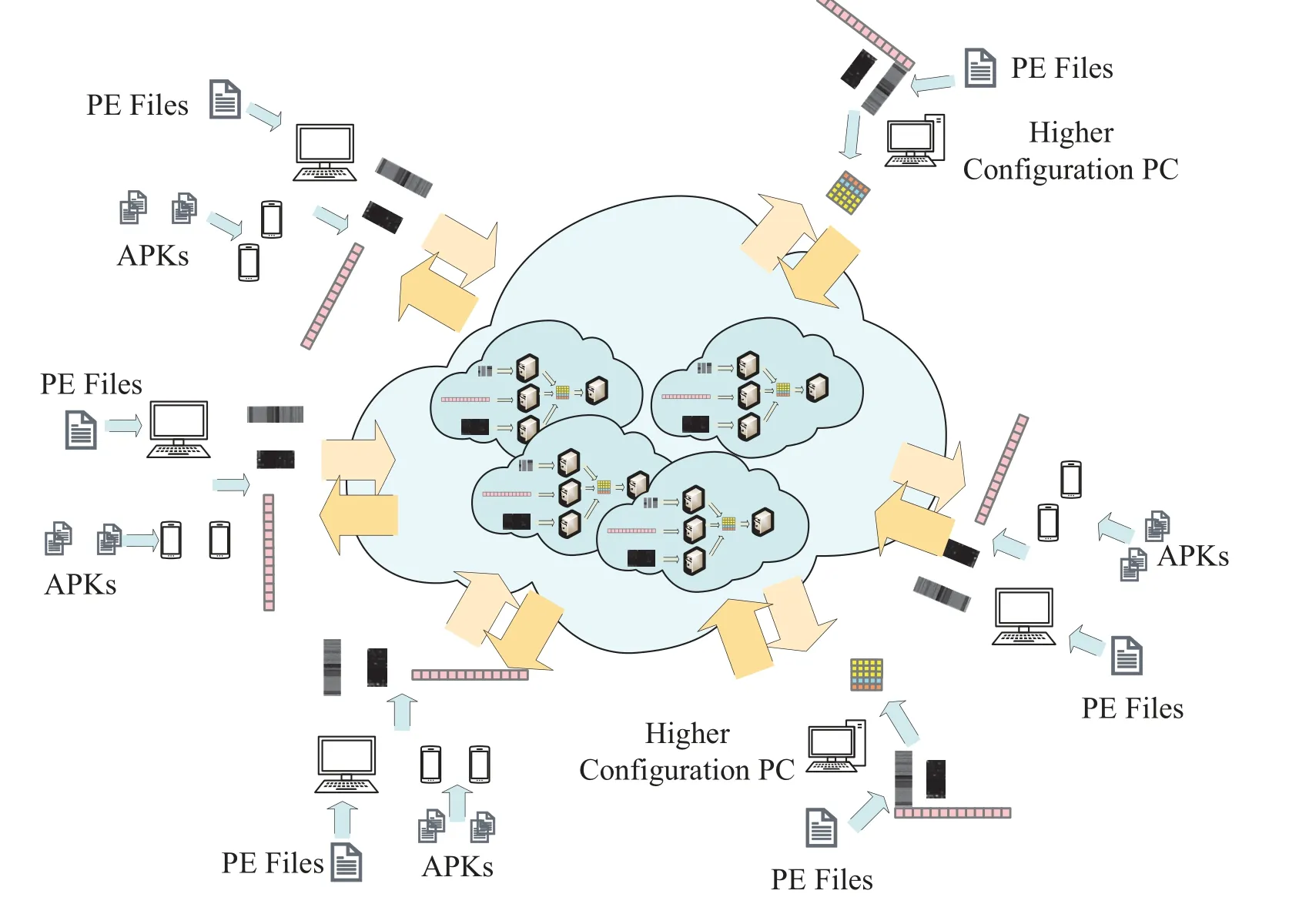
Figure 4. Model deployment based on edge computing.
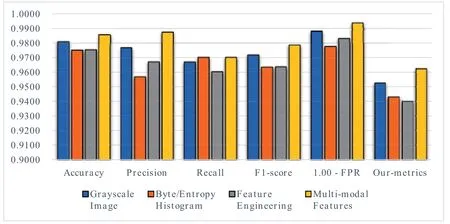
Figure 5. Model performance comparison based on various metrics.
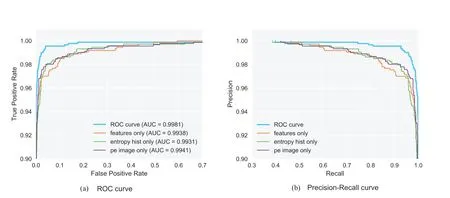
Figure 6. Performance on ROC curve and P-R curve.

Table 2. Comparison of various evaluation metrics.
Since PE files are converted into pictures, we can use the other techniques of traditional picture classification tasks.For example, we can visualize the heat map of the black-box model,which represents the distribution of the model attention to the sample.We reshape the heat map and add it to the original sample.The results of the visualization are shown in Figure 7.The function of visualization is that we can reversely analyze important areas according to the attention of the model.It can be seen that the model has learned the effective information for itself,which can also help us to perform better feature engineering and rule matching.
VI.CONCLUSION AND FUTURE SCOPE
In the paper, we use the static analysis method to extract three different features:grayscale images feature,byte/entropy histogram feature, and feature engineering.Through the ensemble learning of features,some good results are achieved while the false alarm rate is well controlled.The method benefits from the simultaneous and adaptive processing of different modal features, avoiding the blindness of traditional manual scoring.In the detection task of malicious mining samples, the performance of the deep learning model based on multi-modal features provides a new solution for future multi-scenario applications.More importantly, combining technologies such as edge computing and cloud computing can make the deployment a nd service of the model more effciient.
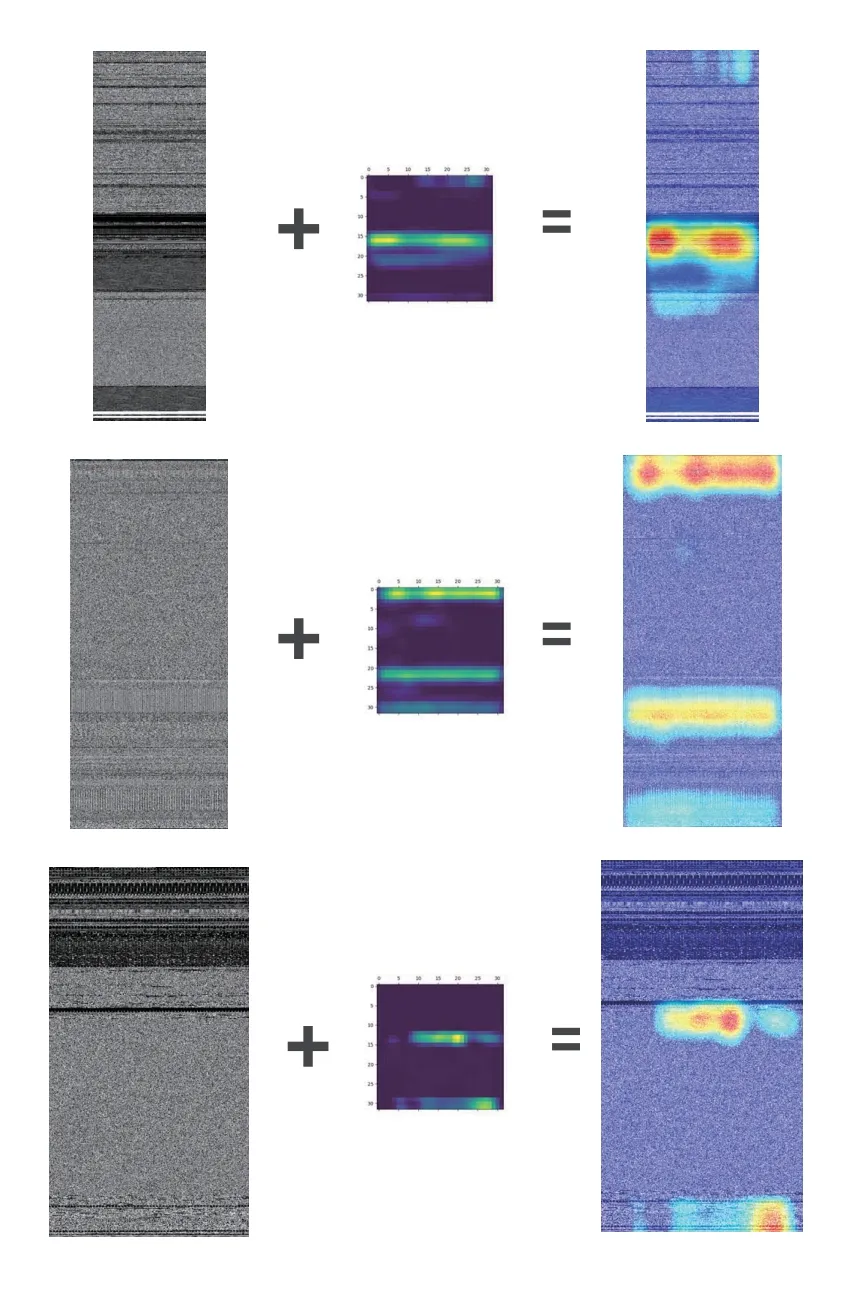
Figure 7. Examples of heat-map visualization.
However,static analysis has inherent shortcomings.It can hardly deal with obfuscated and shelled samples, and the execution of the program could even produce additional behaviors and characteristics.Dynamic analysis can both better extract the confused or potential parts,and detect the special behavior and resource occupation of the program.Static and dynamic analysis are not mutually exclusive, but complementary.Therefore,when conditions permit,the combination of the two will be better.
ACKNOWLEDGEMENT
This work was supported by the Key Research and Development Program of Shandong Province (Soft Science Project)(2020RKB01364).

- China Communications的其它文章
- A User-Friendly SSVEP-Based BCI Using Imperceptible Phase-Coded Flickers at 60Hz
- Steady-State Visual Evoked Potential(SSVEP)in a New Paradigm Containing Dynamic Fixation Points
- Toward a Neurophysiological Measure of Image Quality Perception Based on Algebraic Topology Analysis
- Transfer Learning Algorithm Design for Feature Transfer Problem in Motor Imagery Brain-computer Interface
- Removal of Ocular Artifacts from Electroencephalo-Graph by Improving Variational Mode Decomposition
- BCI+VR Rehabilitation Design of Closed-Loop Motor Imagery Based on the Degree of Drug Addiction