
基于多BP神经网络的内存组合特征分类方法
2022-02-26 06:58段佳良蔡国明徐开勇
计算机应用 2022年1期
段佳良,蔡国明,徐开勇
(信息工程大学网络空间安全教研室,郑州 450001)
0 引言
近年来,由于互联网的快速发展,大部分电子产品的使用方式出现了巨大改变。数以亿计的电子设备管理并监测着交通系统、工业系统、电力系统等公共资源,同时也记录着各种各样的隐私数据,例如个人健康、线上消费、社交等线上业务,因此,电子设备的安全性至关重要,其中智能终端的安全问题更是该研究领域一直以来的热点方向。
智能终端安全主要分为系统安全、通信安全、组件安全、数据安全等[1]。系统安全作为设备的运行环境基础,影响了整个智能终端的安全状况,而现代移动终端的操作系统功能愈发强大,可安装运行第三方软件并提供数据存储与处理等各种服务,导致操作系统存在漏洞,往往成为恶意软件的攻击目标,面临巨大的安全威胁[2]。操作系统的安全状况可以通过完整性度量技术进行测量、验证,并实时监控其运行状态。完整性度量技术可以度量内核的完整性,评估内核在内存中的运行状态、资源的完整性,有效保护和增强内核和操作系统的安全。
目前关于完整性度量的研究主要使用基于硬件虚拟化与软件辅助的方式进行度量,两种都使用了计算哈希值对比基准值的度量方法[3-9]。文献[7]中介绍并分析了现有针对动态完整性度量结构的攻击方法,认为现存动态完整性度量结构存在较多问题,但没有给出实质性的解决方法。文献[8]中使用了基于ARM(Advanced RISC(Reduced Instruction Set Computing)Machine)虚拟化扩展的内核动态度量方法,主要使用硬件辅助的方法保护度量程序的安全,然后度量程序获取初始值并进行度量,该方法需要硬件支持因此具有较大局限性。文献[9]中提出了动态完整性度量架构(Dynamic Integrity Measurement Architecture,DIMA),可以解决其他架构难以避免的TOC-TOU(Time Of Check-Time Of Use)问题,但其主要度量方法为使用基准值进行度量,特征选取方法较为单一,且可移植性较弱。文献[10]中采用语义约束描述内核动态数据的动态完整性,可以有效地对动态数据进行可信度量,但语义约束集合需要不断更新,对处于互联网中实时更新的设备保护十分有限。由现有研究可以看出,传统度量方法仅适用哈希值进行度量,并且特征选取方法较为单一,导致其保护能力越来越有限。
神经网络以及深度学习在图像、语音、机器翻译等领域获得了突破性的进展,产生了大量的研究成果[11]。而关于内核完整性度量方面的研究与应用较少,同类研究主要为关于恶意代码检测的研究。文献[11]提出的基于全连接网络的恶意代码检测算法使用了TensorFlow 框架进行训练以及恶意代码片段检测,可以较为准确地识别存在恶意代码的存储数据,但其对使用环境的要求较高,需要上层框架支持,在系统内核层面无法实现。文献[12]中提出的基于二维二进制程序特征的恶意软件检测是基于深度神经网络的检测方法,与传统检测方法相比,检测率有较大提升,但其仅只能学习已有软件的二进制文件特征,且学习时间较长。文献[13]中提出的基于卷积神经网络(Convolutional Neural Network,CNN)的恶意代码检测技术的检测率较高,但要基于沙箱环境对软件进行检测,对系统整体性能影响未知,对系统内核及内存数据的功能性也没有说明。文献[14]中提出了基于行为的恶意代码检测,通过检测API 函数调用并用CNN 进行训练学习,但在只能检测调用API 函数的程序,无法对系统整体安全进行监控。
由于在不断发展的系统里传统度量方法的保护能力较弱,且关于内核完整性度量的机器学习类型研究较少,因此为了解决完整性度量系统中内存特征选取方法过于单一、灵活性不足等问题,本文提出了一种基于多反向传播(Back Propagation,BP)神经网络的内存组合特征分类方法。BP 神经网络是目前应用广泛的一种多层前馈神经网络模型,主要应用于数据压缩、模式识别、函数逼近等方面[15]。本文首先构建位于Linux 系统中的完整性度量系统,对不同安全状态下系统的关键不变量等内容进行数据预处理,提取特征后的数据75%用于训练BP 神经网络模型,15%用于模型验证集,10%用于模型测试集。经实验数据验证,与传统基于固定基准值的内存特征分类算法、单BP 神经网络及其他神经网络模型相比,本文提出的基于多BP 神经网络的内存组合特征分类算法具有更高的准确率。
1 特征提取与处理
机器学习算法需要大量真实的数据作为学习样本,因此本文利用实验室条件采集了2 000 条不同安全状况下的系统内存数据。由于操作系统内存中数据对象众多,为满足神经网络输入的统一,需要对内存数据中需要重点关注的度量对象进行分析。
通过对系统内核各类资源的观察,发现内核代码段、中断描述符表只有在内核策略或控制流发生改变时才会发生改变;熵池资源为系统随机数生成所需资源,一般数据内容在一定范围内变化。然后分析了多种rootkit 攻击行为,发现内核攻击主要有几种攻击方式:例如kbeast 主要是通过修改系统调用表来破坏内核完整性,adore-ng 通过系统拦截破坏或隐藏恶意进程,wipemod 将自身从模块链表中移除以实现恶意模块隐藏[16]。因此所有内存数据主要分为两类对象:静态度量对象与动态度量对象:静态度量对象在系统加载到内存中后基本保持不变,主要指内核的代码段、只读数据段、中断描述符表、系统调用表、全局描述符表等。这些静态对象在系统加载完成后,其所在内存地址及偏移量都已经固定,一旦这部分内容遭到破坏,系统预期行为将会发生变化,说明系统遭到攻击。而动态度量对象主要指在系统运行过程中会根据系统运行状况进行动态变化的资源对象,如进程、模块、熵池资源等。
本文要判断系统内核完整性就需要重点关注内存数据中上述两类对象,其中内核代码段、中断描述符表等内容仅需要进行静态度量即可实现度量操作,因此本文主要选取只读数据段、系统异常表、系统调用表、进程、模块和熵池资源作为系统度量对象。目前关于内存数据提取主要是通过对整体内存进行映射保存[17-20],而本文算法仅需提取有效特征值,针对不同度量对象进行处理,因此本文设计了度量对象提取算法(Measuring Object Extraction Algorithm,MOEA),算法主要通过获取内核符号表的内存地址,根据内存地址内容获取度量对象信息并进行分析,避免了整块内存进行映射保存带来的系统性能损失。

提取度量对象后,将其逻辑地址对应的物理地址与结构定义经过格式化处理后,可得到Ni个特征值,i为度量对象类别。
2 模型建立与训练
2.1 模型建立
本文特征分类方法为各类特征值综合判断系统安全状况,每个特征值都会影响系统安全的最终结果,属于神经网络应用中模式识别的研究范畴。在常用的神经网络模型中,卷积神经网络(CNN)主要用于语音识别与图像识别,K最邻近(K-Nearest Neighbor,KNN)算法主要用于数据挖掘中的数据分类问题,生成对抗网络(Generative Adversarial Network,GAN)主要用于图像识别中的数据伪造生成。全连接网络是最符合本文特征分类要求的模式识别神经网络模型[15],因此本文选择BP 神经网络模型。在内存特征分类过程中,特征值的数量较为庞大,且每类特征值之间并不存在强联系。为了减少神经元数量,提高训练速度,同时也为了防止发生过拟合现象,因此本文中的模型由两组BP 神经网络组成;同时为了体现本文方案选取模型的突出优势,实验部分也采用了常见神经网络模型进行同数据集的实验比较,从实验的角度验证了前文选取多BP 神经网络模型的优势。
在本文设计中,每个BP 神经网络模型都为经典三层神经网络,由输入层、隐含层、输出层组成,层与层之间采用全连接的方式。模型结构如图1 所示。

图1 多BP神经网络模型结构Fig.1 Structure of multiple BP neural network model
图1 中,第一组BP 神经网络由k个神经网络组成,每个神经网络的输入层均为上文提取特征值,由ik个神经元组成;输出层为1 个神经元φk;隐含层由mk个神经元组成,由经典算法[21]决定,公式为mk=+1+α,其中α为1~10 的常数,一般根据实际效果决定分别表示第k个神经网络内输入层到隐含层、隐含层到输出层的神经元之间的权值集合分别表示第k个神经网络内输入层到隐含层、隐含层到输出层的神经元之间的偏置集合。
第二组为1 个神经网络,其输入层为第一组神经网络的k个输出节点组成,隐含层由m个神经元组成,由经典算法决定,公式为m=+α,输出为1 个神经元φ;ωx,ωy分别表示输入层到隐含层、隐含层到输出层的神经元之间的权值集合;θx,θy表示输入层到隐含层、隐含层到输出层的神经元之间的偏置集合。
2.2 模型训练
BP 神经网络的训练主要分为正向传播的计算输出与反向传播的修正参数。在训练开始前,初始权值与偏置都为随机生成。
首先对于算法的描述引入一些参数的定义:
定义1权值ω。ω表示每个神经元连接间的权重。

定义2偏置θ。θ表示每个神经元的偏置。

定义3特征数量N。N表示特征数量,对应类别i的特征数量为Ni,N≥Ni。
2.2.1 正向传播过程
正向传播过程中,通过公式计算每个神经网络的隐含层与输出层各神经元输出,其计算公式如下:

其中f(x)为神经网络模型中的激活函数。
在本文算法中,经过前期实验对比,在第一组隐含层使用Sigmoid 函数作为激活函数,收敛速度略快,最后训练及测试结果较好。其公式如下:

由于目的是判断系统安全性,仅存在安全与非安全两种情况,若某一特征值被认为可能为非安全特征,则需要通过模型放大其特性;若某一特征值被认为是安全的,将逐渐降低其对神经网络结果的激励效果。同时为了提高神经网络的收敛速度,在第一组的输出层与第二组的隐含层使用ReLU(Rectified Liner Unit)作为激活函数进行处理,其公式如下:

在整个模型的输出层,由于需要输出整个度量结果是否安全,即安全概率,结果一定小于1 且大于0,因此使用将多个神经元的输出能够映射到(0,1)区间内的Softmax 作为激活函数,公式如下:
2.2.2 反向传播过程
在得到输出后,使用训练算法来不断修改神经网络的权值与偏置,使其逼近期望值,而训练算法的选取则会影响最终效果与训练速度。本文采用小批量随机梯度下降算法作为改进算法,减少了网络训练的迭代次数,提高了网络的收敛速度,并且最终训练出来的模型精度更高。
首先定义损失函数Cost(x),对于样本数量为N的模型,可得公式如下:
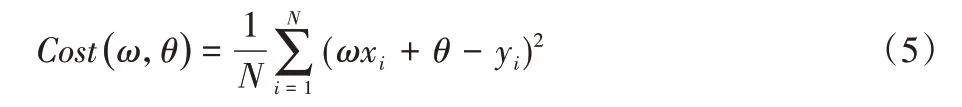
其中yi为第i个样本的期望输出。
然后为了更新神经网络中的权值与偏置的参数,需要分别对损失函数(4)关于ω和θ进行求导。可得偏导数分别为如下:
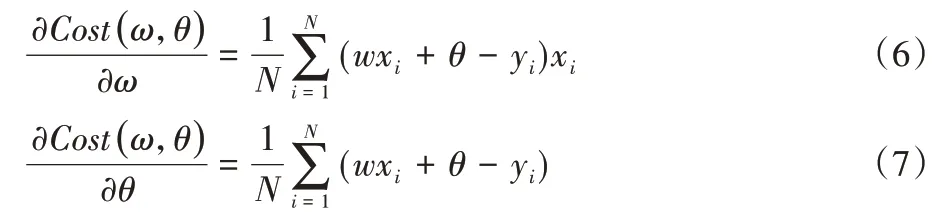
随机梯度下降法(Stochastic Gradient Descent,SGD),批量梯度下降法(Batch Gradient Descent,BGD)分别是使用N=1与N=样本容量进行优化。由于本文研究内存特征样本容量较为庞大,使用BGD 与SGD 会出现收敛速度慢的问题,导致训练速度过于缓慢,因此使用小批量梯度下降法(Mini-Batch Gradient Descent,MBGD)作为训练优化算法。每次选取m个样本进行更新,1 <m<N,可以极大减少收敛所需要的迭代次数,同时可以使收敛到的结果更加接近梯度下降的效果[22]。
最后根据正向传播与反向传播过程,对神经网络中各神经元的权值与偏置进行修改,训练完成后得到神经网络模型。使用模型测试集对模型进行验证,除非验证准确率达到要求,否则更新批量样本数量并进行新一轮训练,直到最终完成训练过程。训练流程如图2 所示。

图2 训练流程Fig.2 Training flowchart
3 实验结果及分析
本文算法实验通过ubuntu 18.04+CUDA10.0 实现。所使用的实验环境的计算机配置如表1 所示。

表1 计算机配置信息Tab.1 Computer configuration information
数据集使用实验室的完整性度量原型系统采集的2 000条系统内存数据,将内存数据通过MOEA 进行提取,共分为6个类别的度量对象,数据集相关数据如表2 所示。

表2 数据集相关数据Tab.2 Related data of dataset
实验中数据集由1 500 条训练数据、300 条验证数据和200 条测试数据组成。训练数据集主要用于训练模型以及确定模型权重,验证数据集用于确定网络过结构以及调整模型的超参数,测试集主要用于检验模型的泛化能力。本文神经网络模型通过训练后,得到结果如表3 所示。
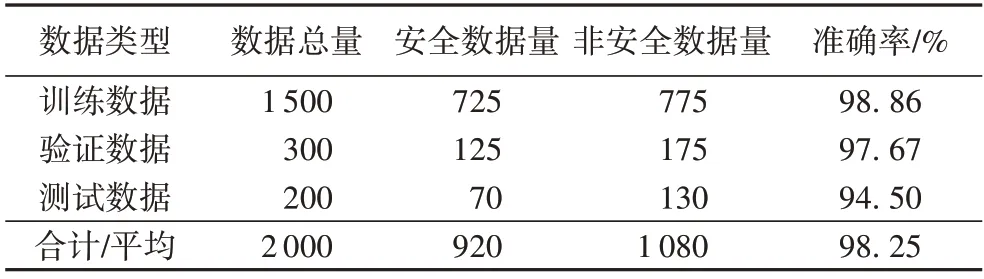
表3 训练完成的本文神经网络模型的数据结果Tab.3 Data results of the proposed neural network model after training
为验证本文所提算法的可行性与优越性,本文对性能进行了进一步分析,并用相同数据集使用不同神经网络进行比较,结果如表4 所示。实验分别使用了基于基准值的完整性度量、一维CNN、K近邻,以BGD 为训练算法的传统单BP 神经网络进行对照实验。

表4 内存特征提取模型方法的对比Tab.4 Comparison of memory feature extraction models and methods
其中,基于基准值的完整性度量使用每次系统启动时的内存特征作为基准值,不需要进行模型训练,具有较大局限性,因此总准确率较低;CNN 与KNN 训练迭代次数均为提前确定,因此训练时间比较暂无意义;单BP 除网络结构不同,其余均使用本文相同参数。由表4 可知,除了基于基准值的方法外,不同的分类方法准确率均能达到90%以上,而BP 神经网络能达到95%以上。但在相同参数情况下,使用了多BP 结构与小批量梯度下降算法的本文模型方法具有准确率更高、训练迭代次数更少的优势;而在分类所用时间上,BP神经网络分类速度均高于CNN 与KNN 算法。而单BP 与本文算法分类时间较为接近,其影响因素主要在多BP 之间的数据传输上,若除去数据传输对分类的影响,分类所用时间将会更短。综上所述,本文算法基于多BP 神经网络结构提高了特征分类的准确率与分类速度,优于其他几种算法。
4 结语
本文提出了一种基于多BP 神经网络的内存特征分类方法,通过完整性度量系统获得内存数据,并对采集的数据进行特征值提取,经过多个BP 神经网络进行训练,使得该算法可以较为准确地将系统安全状况进行分类,给出系统安全状况评分。实验结果表明,本文所提算法与其他几种算法相比,准确性与效率有明显提高,并且具有普适性,可以移植其他平台上使用。但本文算法也有一定局限性:由于训练与测试数据集均为已有攻击样例攻击系统得到的数据,在应对未知攻击时还没有数据进行训练与测试,所以该系统需要到实际应用场景进行进一步训练与验证。
猜你喜欢
机械工业标准化与质量(2022年8期)2022-10-09
上海文化(文化研究)(2022年3期)2022-06-28
国外畜牧学·猪与禽(2022年1期)2022-04-23
作品(2021年9期)2021-09-22
现代装饰(2021年1期)2021-03-29
中国计算机报(2019年12期)2019-06-21
作文与考试·初中版(2019年15期)2019-04-28
江西教育B(2019年2期)2019-04-12
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
中国校外教育(上旬)(2006年5期)2006-05-25
