
基于刑事Electra的编-解码关系抽取模型
2022-02-26 06:58王小鹏孙媛媛林鸿飞
计算机应用 2022年1期
王小鹏,孙媛媛,林鸿飞
(大连理工大学计算机科学与技术学院,辽宁大连 116024)
0 引言
随着智慧司法建设的推进,如何帮助办案人员从海量的犯罪文书中获取有用的信息成为了一项非常有意义的研究工作,司法领域的自然语言处理技术也因此受到了研究者的广泛关注和重视,特别是对海量司法文书进行智能分析和处理已成为司法人工智能研究的重要内容。关系抽取作为信息挖掘的基础性工作,不仅可实现司法信息的获取,还在司法问答、刑期预判和司法知识图谱构建等任务中有重要应用。
司法文书,是指司法机关制作的具有司法效力或司法意义的文书[1]。司法关系抽取则是在已知司法文书中具有司法属性的名词或短语实体基础上,识别出实体之间的关系事实,据此构造三元组,如:[张三,攻击关系,李四],“张三”“李四”是司法实体,他们之间的关系事实是攻击关系。相较于通用领域的关系抽取研究,司法领域关系抽取面临以下问题和挑战:
1)通用领域预训练语言模型在司法领域的应用存在一定局限性。首先,司法文本是按照严格的模板进行撰写的,相较于通用语料库(如维基百科语料),在文本结构上存在较大差异;此外,通用语料库和司法文本语料库的词分布并不相同,因此很难确保通用领域预训练语言模型在司法任务上的性能表现。
2)司法文书中,存在许多同一实体对应多个关系的情况,这将严重混淆关系提取。如“被告人张三和被告人李四系邻居。”描述中“张三”和“李四”从司法层次讲是共犯关系,在社会层次中他们之间是邻里关系。当数据集中关系重叠较多时,模型就很难清楚地识别出所有的关系标签。现有关系抽取模型使用的MaxPooling[2]和词级注意[3]等方法虽然可以很好地将低层级语义合并生成高层级关系表示向量,使得模型在单标签关系识别上表现优异,但对于多重关系抽取,这种高层次的关系向量却很难准确地表达标签特征,进而影响性能。
针对以上问题,本文提出了一种基于刑事Electra(Criminal-Efficiently learning an encoder that classifies token replacements accurately,CriElectra)的编-解码关系抽取模型,解码器由双向长短期记忆(Bidirectional Long Short-Term Memory,BiLSTM)网络[4]和胶囊网络(Capsule Network,CapsNet)[5]构成,即CELCN(CriElectra-BiLSTM-CapsNet)。首先参考中文Electra[6]的训练方法,在一百多万份刑事案件数据集上训练得到了CriElectra;然后在双向长短期记忆网络上加入CriElectra 的词特征进行中文文本的特征提取;最后利用胶囊网络对特征信息进行矢量聚类,实现实体间的关系抽取。本文在自行设计并构建的故意伤害罪关系抽取数据集上进行实验,模型的F1 值可以达到79.88%,相较于其他基线方法,CELCN 可以取得非常不错的效果。本文的主要工作如下:
1)基于司法业务需求和罪名特点,提出了一种侧重于司法属性和社会属性的关系定义方案,并构建了故意伤害罪的关系抽取数据集。
2)提出了基于百万刑事数据的预训练语言模型CriElectra,该预训练语言模型能够更有效地学习表示司法领域文书中的语义信息。
3)基于胶囊网络进行高维矢量空间的特征聚类,能够有效地解决数据集中多标签关系的识别任务。
1 相关研究
1.1 关系抽取
关系抽取一般可分为基于机器学习的方法和深度学习的方法。基于机器学习的方法是以自然语言处理(Natural Language Processing,NLP)技术中的统计学语言模型为基础,从分类的角度研究关系抽取,即根据各种语言学特征识别实体对于每个标签的可能性,然后再通过基于统计模型的分类器进行关系的分类[7]。这种方法可按照有无标注好的数据集分为有监督、无监督和弱监督三种方法,其中有监督的方法是指所有数据集都是通过人工标注形成的,该方法具有很高的准确性,但过分依赖标注的数据集,成本较大;无监督方法不需要人工语料作为支撑,能自动识别文本中三元组,因此在处理大规模数据语料时具有其他方法无法比拟的优势,但缺少人工标注导致其准确率和召回率较低;弱监督的方法是指根据少量已标注好的语料三元组,在未标注的语料中发现新的三元组,进而形成大规模的语料集,但由于噪声等问题并未完全解决,其性能也受到了限制。基于深度学习关系抽取的方法,主要包括基于卷积神经网络(Convolutional Neural Network,CNN)[8]的方法、基于循环神经网络(Recurrent Neural Network,RNN)[9]的方法以及二者相结合的方法[10]。在此基础上,Lu 等[11]引 入PCNN(Piecewise Convolutional Neural Network)对传统卷积神经网络的池化层进行改进,并使用句子级选择注意力机制减轻错误标签的影响,最终F1 值的结果比基于多示例学习的方法高了5%。Kiyavash 等[12]引入词级别的注意力机制并结合BiLSTM 对文本进行建模从而实现结果的提升。Luo 等[13]结合双向GRU(Gate Recurrent Unit)和PCNN 模型实现对实体结构等信息的提取,在NYT(New York Times)数据集上表现优异。
1.2 预训练语言模型
近年来,针对预训练语言模型的研究发展迅猛,预训练语言模型是一种动态词向量表示方法,不同于静态词向量,该词向量基于上下文信息表示单词的语义知识,能够很好地解决一词多义的问题。在预训练语言模型研究中,Peters等[14]提出的预训练语言模型ELMo(Embedding from Language Models),利用BiLSTM 不仅解决了长距离信息丢失问题,还可对词在复杂特征(如句法和语义)和变化的语言语境下进行建模。Devlin 等[15]提出自编码语言模型BERT(Bidirectional Encoder Representation from Transformers),不同于GPT(Generative Pre-Training)[16]中单向的语义知识学习,它通过Transformer 实现了对文本的双向特征表示,并在11项自然语言处理任务中取得了最佳成绩。Yang 等[17]提出了自回归预训练模型XLNet(Transformer-XL Network),在多项自然语言处理任务中性能获得了显著的提升。在具体的任务应用中,李妮等[18]、王子牛等[19]、尹学振等[20]、王月等[21]采用基于BERT 的模型分别对通用领域、军事领域、警情领域命名实体的识别进行了研究,实验结果均有不同程度的提高。但随着预训练语言模型的进一步发展,研究者发现由于文本结构、词分布的差异,开放领域的预训练模型在特定领域表现一般,于是Lee 等[22]提出了生物医学领域的BioBERT(Biomedical BERT),实验结果表明,BioBERT 的F1值比BERT 高了2.8%;此外,2019 年清华大学公开了基于百万刑事数据集和百万民事数据集的刑事BERT 和民事BERT,从其公布的结果看,这两种模型相较于通用BERT 可以在司法领域任务上实现快速的收敛。因此,特定领域语言模型的研究逐渐成为大家研究和探讨的热点。
1.3 胶囊网络
为了改善CNN 和RNN 在特征学习过程中信息丢失问题,Hinton 等[23]首次提出了可自动学习部分与整体之间关系的胶囊网络。Sabour 等[5]基于胶囊网络进一步提出一种可识别高度重叠数字的动态路由算法,该胶囊网络算法在低层特征到高层特征的聚类过程中,不仅关注特征存在的可能性,还关注特征的空间分布信息,使模型获取的信息更加全面,因此在图像识别任务上取得了非常不错的效果。Hinton等[24]提出了一种基于EM(Expectation Maximization)算法的胶囊网络,该方法将一维向量胶囊改进为二维向量胶囊,使得胶囊可以表示更多的特征信息。Zhang 等[25]将胶囊网络引入关系抽取任务中,主要进行了两部分的工作:首先在动态路由算法引进注意力值;其次,在边界损失函数中设置了可学习阈值参数,从而优化了整个算法模型,在多标签关系抽取数据集NYT-10 上,F1 值可以得到2%的提升。随后,Zhang 等[26]将词注意力机制与动态路由结合,提出了Att-CapNet(Attentive Capsule Network)模型,进一步改进了胶囊网络,最近胶囊网络也被逐渐应用于文本分类[27]和疾病分类[28]等NLP 任务,且都取得了很好的性能表现和提升。
2 模型结构
CELCN 模型结构如图1 所示,包含三部分:基于CriElectra 的预训练层、基于BiLSTM 的特征提取层和基于CapsNet 的特征聚类层。该模型首先通过CriElectra 得到单个字符的动态语义向量表示;然后把字符向量输入到BiLSTM 模型,对其序列和层级建模以提取语义和结构特征;接着通过CapsNet 对特征矩阵进行矢量空间的特征聚类,形成高层胶囊,再根据高层胶囊的模长预测关系标签的可能性。

图1 CELCN模型结构Fig.1 Structure of CELCN model
2.1 基于CriElectra的预训练层
2.1.1 训练CriElectra
BERT 在预训练语言模型领域取得了非常好的成就,但BERT 采用的MLM(Mask Language Model)预训练方式并不高效,它只有15%的Token 对参数的更新有用,其他的85%不参与梯度更新;除此之外,预训练阶段与特征提取阶段存在信息不匹配,因为下游任务的特征提取阶段,并不会出现“[Mask]”这个词,而在上游预训练过程中却使用“[Mask]”替换Token。于是Clark 等[6]基于对抗网络设计了预训练模型Electra,该模型提出了RTD(Replace Token Detection)预训练任务,与MLM 方式不同,RTD 的预训练目标是学习区分输入的词是否被替换,尽管引入了“[Mask]”,但是在梯度传播的过程中,模型还需关注有没有发生过替换,因此降低了“[Mask]”的影响,在很大程度上缓解了MLM 引起的信息不匹配的负面影响。此外,由于RTD 在训练过程中全部Token会参与参数更新,因此Electra 训练速度更快,其实验结果还表明,在句对分类、阅读理解等任务上的Electra 性能要优于BERT,在自然语言推断、句对分类任务上性能表现相当。
基于Electra 训练更快、性能与BERT 相当等特点,本文基于中文Electra 提出了CriElectra,训练数据来源于中国裁判文书网公开的文书数据,首先通过下载获取百万份刑事文书数据,然后通过筛选形成100 多万份刑事案件数据集,其中所涉罪名包括盗窃、涉毒、交通驾驶罪等10 类469 个刑事罪名,地域包含23 个省、5 个自治区、4 个直辖市。
CriElectra 训练示例如图2 所示。
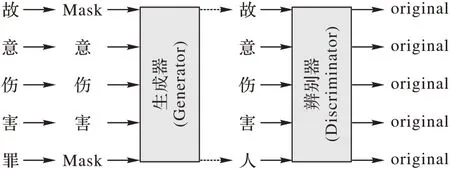
图2 CriElectra训练示例Fig.2 CriElectra training example
给定输入序列E={e1,e2,…,en},由生成器G 进行MLM任务预测屏蔽词,即随机屏蔽输入序列中的词生成带有“[MASK]”的序列,然后通过transformer 的结构编码器得到一组包含上下文信息的向量hG(E)=[hg1,hg2,…,hgn],再经归一化层预测屏蔽位置gt的词,过程如下所示:

生成器训练过程中的损失函数如下:

判别器的目标是判断输入序列中的词是否发生替换,即将生成器得到序列D={d1,d2,…,dn}通过Transfomer 结构的编码器得到hD(E)=[hd1,hd2,…,hdn],再经sigmoid 层输出,过程如下所示:
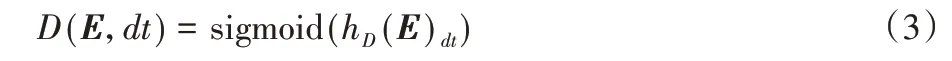
其中dt∈dn,更具体地说,通过用生成器样本替换屏蔽的标记来创建一个损坏的示例Ecorrupt,并训练鉴别器来预测Ecorrupt中的哪些标记与原始输入E相匹配。判别器训练过程中的损失函数如下:
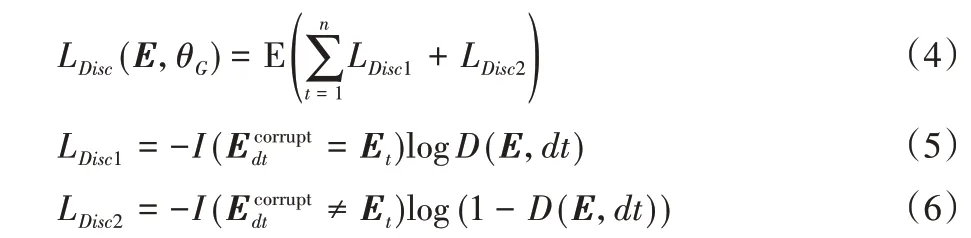
式(4)中:θG与θD分别为生成器和判别器的参数;I(a=b)为判别函数,当满足条件a=b时,取1,不满足时为0。CriElectra 训练通过最小化生成器和判别器的交叉熵损失函数进行,具体可以表示为:

由于生成器的体积是判别器的1/4,为避免模型间损失失衡,因此使用λ=0.5 平衡生成器和判别器的损失。该模型Pytorch 和Tensorflow版本在之后将会开源(https://github.com/DUTIR-LegalIntelligence),供学者共同研究。
2.1.2 CriElectra应用
CriElectra 预训练语言模型旨在让下游任务模型能够使用更好的司法文本的词表示,文本中句子可以表示成字符的集合E={e1,e2,…,en},en表示句子中第n(n∈N)个字符。整个CriElectra 进行向量矩阵转化的过程可以表示为:

其中:E为输入到模型的句子向量表示;X∈为模型输出的CriElectra 向量矩阵,X可以具体表示为X={x1,x2,…,xn};θElectra为Electra 模型相关参数。
2.2 基于BiLSTM的特征提取层
特征编码层所使用的模型为双向的长短期记忆模型BiLSTM,它是RNN 的一种变体,包含了一个门控记忆细胞来捕获数据中的长期依赖关系,并能够避免由标准RNN 引起的梯度消失和爆炸问题。双向长短期记忆循环模型由两个不同方向的长短期记忆(Long Short-Term Memory,LSTM)网络组成,两个LSTM 分别从前向和后向学习单词的上下文信息,再将二者拼接起来,作为当前时刻的输出。隐藏层状态可以用式(9)~(11)描述:

2.3 基于胶囊网络的特征聚类层
本文中胶囊网络结构如图3 所示,将BiLSTM 提取的特征h分割到低层胶囊u∈中,为保证胶囊的模长和为1,经非线性压缩函数g得到每个低阶胶囊utk,具体过程如下所示:
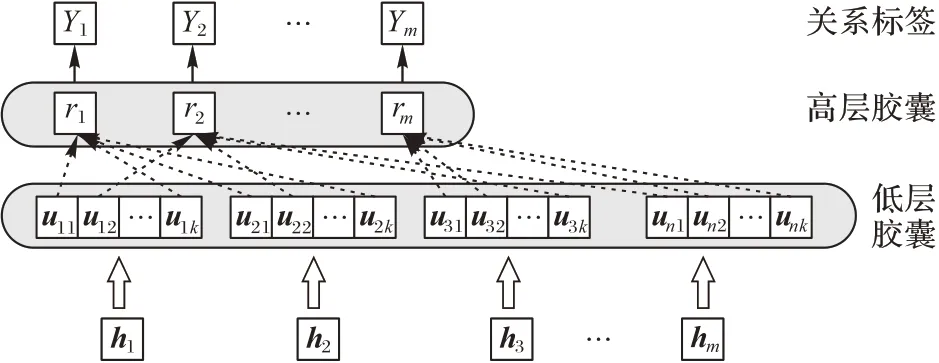
图3 胶囊网络模型结构Fig.3 Structure of capsule network model
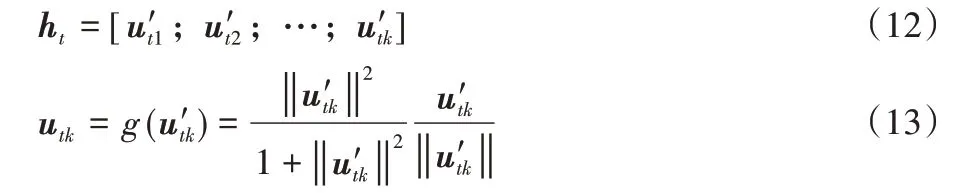
式(12)、(13)中:[x;y]表示x和y垂直连接,‖‖表示计算向量的模长。通过动态路由算法实现低层胶囊ui与高层胶囊Rj之间的信息传递,伪代码如算法1 所示。其中,z为路由的迭代次数。
训练过程中,通过最小化高层胶囊的边际损失实现训练。第j个高层胶囊的损失函数Lj为:
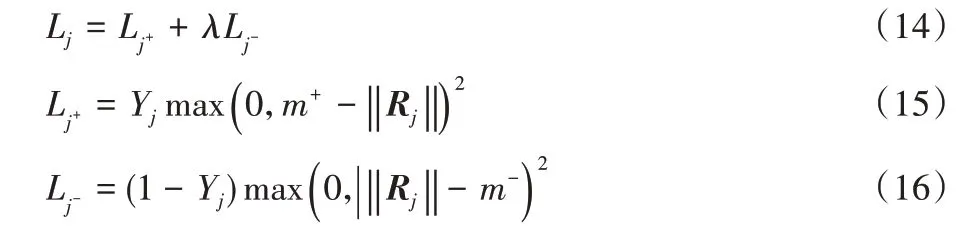
式(14)、(15)、(16)中:若句子的关系为Rj高层胶囊对应的标签,则Yj值取1,否则取0;m+=0.9 为上边界,m-=0.1 为下边界;λ=0.5,模型的全部损失是所有高层分类胶囊损失之和。
算法1 动态路由算法。

3 实验与结果分析
3.1 数据集
司法文本不同于其他领域文本,其每个罪名所涉及的概念与构成、罪名认定以及立案量刑的标准均不一致,所涉及的司法文书实体分布、业务也各有侧重。基于以上特性,目前采用统一模型抽取所有司法文书当中的关系较为困难,因此本文选取故意伤害罪司法文书作为关系抽取的研究对象。
由于故意伤害罪关注的核心要素是人和物,本文在参考通用领域人物关系定义的基础上,根据《刑法》中对社会属性和司法属性的关系需求,从“人”与“人”、“人”与“物”两种粗粒度出发定义了9 种分类关系,具体如下。
亲属关系 指两个自然人之间存在直系亲属或旁系亲属关系。
同事关系 指两个自然人在同一个公司工作或同一时间从事同一份工作。
邻里关系 指两个自然人生活在同一个社区、同一个单元或同一个村。
感情关系 指两个自然人之间未存在法律认可的情侣关系,如恋爱、情人关系。
施动关系 指两个自然人是被告人和被害人的关系。
共犯关系 指两个自然人同为被告人。
使用关系 在一起案件中,以某作案工具为中心,某自然人使用了该作案工具做出了攻击行为,则该自然人与该作案工具之间是使用关系。
攻击关系 在一起案件中,以某作案工具为中心,该作案工具攻击了某个自然人,则该自然人与该作案工具之间是攻击关系。
拥有关系 在一起案件中,存在的违禁作案工具的所属关系,违禁作案工具指枪、爆炸物品、剧毒物品等物品或工具。
除此之外,还定义了一种NA 关系,表明“人”与“人”、“人”与“物”之间不存在关系或者存在的关系不属于已定义的9 种关系。
本文标注的故意伤害罪的文书内容来自中国裁判文书网的公开文书数据。利用规则对犯罪事实描述部分进行抽取,再由志愿者进行手工标注,具体的数据分布如图4 所示。除此之外,由于司法文本的特殊性,其中关系重叠的语料占比为7.66%。同时,为了更好地描述案件中实体间的逻辑指向关系,构建过程中对关系的方向性也进行标注,如三元组,它们的实体对都为E1 和E2,但由于实体在文中出现前后顺序不一样,因此两实体之间的关系指向会发生变化,本文称R1 和R2 互为反向关系。具体的数据集会再经整理和扩充后进行开源(https://github.com/DUTIR-LegalIntelligence),供学者共同研究。

图4 关系分布Fig.4 Relationship distribution
3.2 实验设置
对于CriElectra 预训练语言模型,分别采用以下几种模型进行实验对比:
1)ELCN(Electra-BiLSTM-CapsNet)。预训练层使用中文Electra预训练模型(https://github.com/ymcui/Chinese-ELECTRA),模型结构为Electra-BiLSTM-CapsNet。
2)XBLCN(XBert-BiLSTM-CapsNet)。预训练层使用清华大学公开的刑事BERT 预训练模型(https://github.com/thunlp/OpenCLaP),模型结构为XBert-BiLSTM-CapsNet。
3)MBLCN(MBert-BiLSTM-CapsNet)。预训练层使用清华大学公开的民事BERT 预训练模型(https://github.com/thunlp/OpenCLaP),模型结构为MBert-BiLSTM-CapsNet。
为了评估BiLSTM 的特征提取的能力,分别采用以下几种模型进行实验对比:
1)CERCN(CriElectra-RNN-CapsNet)。特征提取层使用RNN,模型结构为CriElectra-RNN-CapsNet。
2)CECCN(CriElectra-CNN-CapsNet)。特征提取层使用CNN,模型结构为CriElectra-CNN-CapsNet。
3)CECN(CriElectra-CapsNet)。未使用特征提取层,模型结构为CriElectra-CapsNet。
对于胶囊网络,分别采用以下几种模型进行实验对比:
1)CELMP(CriElectra-BiLSTM-MaxPooling)。特征提取层采用MaxPooling特征聚类层[2],模型结构为CriElectra-BiLSTM-MaxPooling。
2)CELAP(CriElectra-BiLSTM-AvgPooling)。特征提取层采用AvgPooling 特征聚类层,模型结构为CriElectra-BiLSTMAvgPooling。
3.3 结果分析
实验中,关系抽取模型的性能由从非结构化文本中关系标签的最终提取结果的精确率(Precision,precision)、召回率(Recall,recall)以及F1 值(F1-score,F1)来进行评估。评价指标的计算式如下:

式(17)、(18)和(19)中:correct_num表示正确预测的标签个数,predict_num表示预测的标签总数,true_num表示实际正确的标签总数。
CELCN 与ELCN 训练的F1 曲线如图5 所示。由图5 可以看出,训练前期基于CriElectra 的模型相较于基于中文Electera 的模型,收敛更快;当模型趋于稳定时,CELCN 模型的F1 值更高,性能更优。因此可表明,相较于中文Electra,在故意伤害罪关系抽取数据集上,CriElectra 预训练模型能够更好地提供司法文本中词的向量表示,使得关系抽取的结果更优。
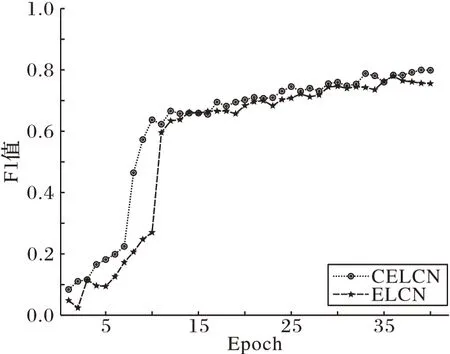
图5 CELCN与ELCN的F1值曲线Fig.5 F1-score curves of CELCN and ELCN
为了进一步地研究CriElectra 与别的司法领域预训练语言模型之间的性能差异,分别基于清华大学公开的刑事BERT 和民事BERT 展开实验,CELCN 与XBLCN、MBLCN 训练过程中的F1 值曲线如图6 所示。由图6 可以看出,三条曲线当中,民事BERT 不管是在收敛速度还是最终结果上表现都很一般;而CriElectra 与刑事BERT 相比性能表现相当。但由于CriElectra 在训练构建过程中,所花费时间成本更低,因此,基于Electra 构建特定领域预训练模型是一个很好的研究方向。
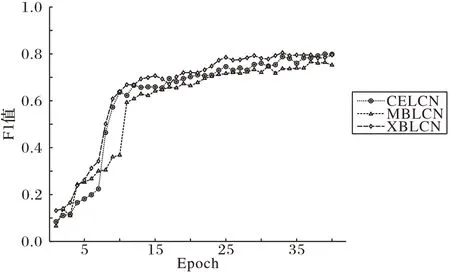
图6 CELCN与MBLCN、XBLCN的F1值曲线Fig.6 F1-score curves of CELCN,MBLCN and XBLCN
以CriElectra 预训练模型、中文Electra、刑事BERT 以及民事BERT 为预训练层实验的详细精确率、召回率和F1 值如表1 所示。可以看出使用CriElectra(CELCN)相较于使用中文Electera(ELCN),精确率可以提升1.54 个百分点,召回率可以提升1.17 个百分点,F1 的提升可以达到1.93 个百分点,效果显著。相较于使用民事BERT(MBLCN),CELCN 的精确率、召回率更高,F1 值可得到3.3 个百分点的提升。跟刑事BERT(XBLCN)相比,CELCN 性能表现相当。这也证明了CriElectra 能够更好地学习到法律文本的词向量表示。
为研究BiLSEM 的文本特征提取表现,本文分别基于RNN、CNN 做了对比实验,同时为了解BiLSTM 是否对模型的性能有所帮助,还进行了CECN 模型实验,实验的详细结果如表1 所示。从表1 中可以看出,BiLSTM 相较于RNN、CNN能够取得更好的F1 值,这是因为本文所用数据集语料句子长度较长,而RNN 和CNN 的长距离学习能力较弱。对于CECN 模型,BiLSTM 能够给模型带来0.41 个百分点的F1 值提升,尽管提升有限,但在一定程度上表明基于BiLSTM 的特征提取层能够使模型更好地学习到文本的特征表示。
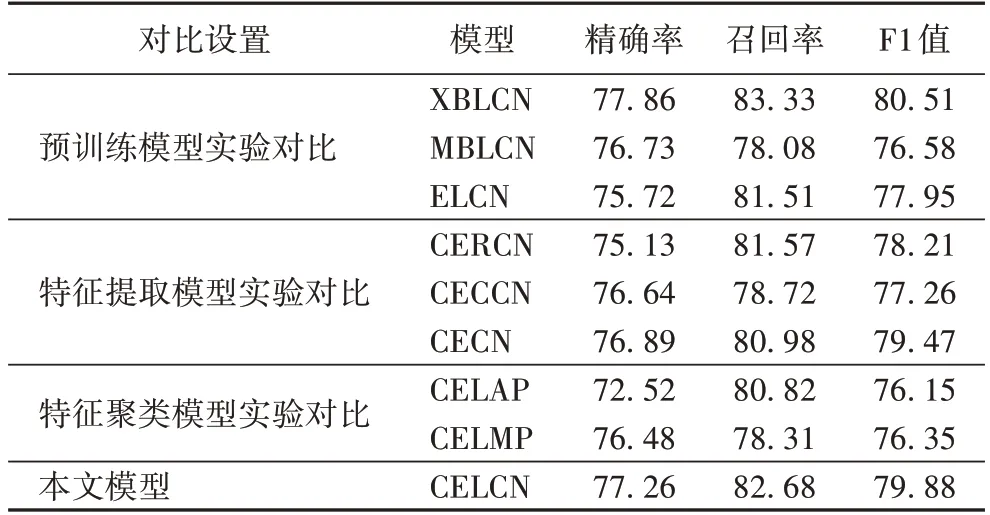
表1 不同模型的性能对比 单位:%Tab.1 Performance comparison of different models unit:%
为研究胶囊网络的性能表现,本文分别进行了基于Maxpooling 的特征聚类层和基于Avgpooling 的特征聚类层的实验,其中CELCN、CELMP 和CELAP 在实验过程中的F1 曲线如图7 所示。从图7 可以看出,尽管胶囊网络的收敛速度较慢,但实验的最终结果表明CELCN 的性能要明显优于CELMP 和CELAP。
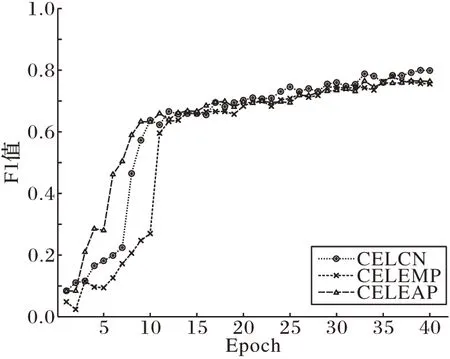
图7 CELMP和CELAP的F1值曲线Fig.7 F1-score curves of CELMP and CELAP
实验CELCN 与CELMP、CELAP 更详细的精确率、召回率和F1 值的实验对比结果如表1,其中CELCN 的精确率、召回率和F1 值分别为77.26%、82.68% 和79.88%,相较于CELMP 和CELAP,F1 值分别提升了3.53 个百分点和3.73 个百分点,表明了胶囊网络在特征聚类方面的优势。
为了进一步地研究胶囊网络带来的性能提升,本文从数据集中抽取一部分多标签关系数据进行测试,实验的测试结果如表2 所示,其中,CELCN 的准确率、召回率和F1 值分别为43.88%、41.32%和42.56%,比CELAP 的F1 值高0.26 个百分点,比CELMP 的F1 值高3.91 个百分点,进一步证明了胶囊网络在多标签关系抽取任务中的性能优势。
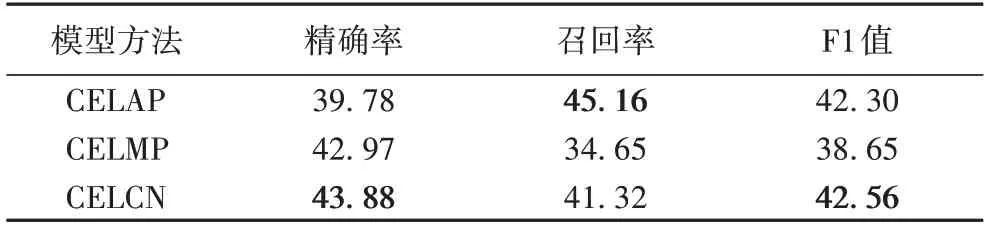
表2 部分多标签重叠关系数据上的实验结果 单位:%Tab.2 Experimental results of some multi-label overlapping relationship data unit:%
4 结语
本文针对司法领域提出了一种新的司法预训练模型CriElectra,然后利用中文通用的人物关系语料,结合司法知识和人工标注方法构建以被告人、被害人以及作案工具为中心的故意伤害罪关系抽取数据集,并提出了CELCN 模型,很好地解决了故意伤害罪关系抽取语料中一对实体多种关系的情况,为司法领域中文关系抽取研究提供了技术基础。在未来的工作中,将基于本文中CELCN 的研究,进一步开展多罪名的关系抽取研究。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
新高考·高一数学(2022年3期)2022-04-28
现代装饰(2021年2期)2021-07-21
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电机与控制学报(2018年9期)2018-05-14
计算机应用(2016年10期)2017-05-12
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
小学阅读指南·高年级版(2009年3期)2009-03-27
家庭医药(2009年1期)2009-02-05
