
基于层级多任务BERT的海关报关商品分类算法
2022-02-26 06:58:00阮启铭王业相
计算机应用 2022年1期
阮启铭,过 弋,2,3*,郑 楠,王业相
(1.华东理工大学信息科学与工程学院,上海 200237;2.大数据流通与交易技术国家工程实验室-商业智能与可视化技术研究中心,上海 200436;3.上海大数据与互联网受众工程技术研究中心,上海 200072)
0 引言
为了应对世界各地迅速增长的国际贸易,世界海关组织(World Customs Organization,WCO)创建了编码协调制度,又称关税税则目录协调制度。通过使用海关(Harmonized System,HS)编码,根据说明、数量单位和分类关税对贸易产品进行标准化。自1988 年生效以来,该制度已被超过200 个国家作为国际贸易的数字语言,占国际商品贸易的98%[1]。HS 编码采用6 位数编码,把全部国际贸易商品分为22 类、98章。章以下再分为目和子目。商品编码第1、2 位数码代表“章”(chapter),第3、4 位数码代表“目”(heading),第5、6 位数码代表“子目”(subheading)。前6 位数是HS 国际标准编码,HS 有1 241 个4 位数的税目,5 113 个6 位数子目。我国根据本国的实际情况,使用10 位HS 编码,其中前8 位称为主码,后两位称为附加码。为了在贸易便利化方面保持竞争力,世界各地的贸易公司投入巨资,进一步自动化和优化当前的贸易流程。然而,贸易研究表明,大约30%的申报提交使用了错误的HS 编码[2]。使用错误的HS 编码这一不合规行为,可能会导致装运延迟、检查次数增加、罚款和其他行政处罚,因此设计一个根据商品的描述给出商品对应的HS 编码的分类系统,将会改善海关商品申报的过程,提高贸易系统的效率。
与一般文本相比,海关报关商品文本具有以下特点:
1)专业性强、术语词汇较多,例如“丁二醇”“丁内酯”等化学词汇;
2)类间相似度高,例如要区别“改良种用马”和“其他马”类,对特征表达能力要求高;
3)类别众多,数以万计,例如本文中的数据集分类目标涉及了9 346 个HS 编码;
4)不同章目下的类别数和不同类别间的样本数严重不均衡。
对于问题1)、2),本文采用了使用预训练词向量且特征表达能力更强的BERT(Bidirectional Encoder Representation from Transformers)模型;对于问题3)、4),文本采用了层级多任务的方式融合不同层级的类别信息(章、目、HS 编码),提出了基于层级多任务BERT(Hierarchical Multi-task BERT,HM-BERT)分类模型。
1 相关研究
1.1 文本特征表示
早期的海关报关商品采取人工设计规则的方式获取文本特征表示,如谢维等[3]设计了一个HS 编码查询知识库,该系统对商品名进行语义识别,并基于知识库进行推理得到可能结果集,最后计算出相关置信度并返回结果。
后来利用神经网络进行词嵌入(word embedding)的方式被广泛应用于文本特征表示,这避免了人工设计复杂的规则,如使用词袋模型(Bag Of Words,BOW)或TF-IDF(Term Frequency-Inverse Document Frequency)提取文本特征,再使用KNN(K-Nearest Neighbor)或支持向量机(Support Vector Machine,SVM)分类方法对文本进行分类。在海关商品分类中,Ding 等[4]曾使用背景网,统计共现词频表示文本文档,这往往忽略文本数据中的自然顺序结构或上下文信息[5];文献[6-8]中提出了Word2Vec 模型,其本质是通过CBOW(Continuous Bag-of-Word)和Skip-Gram 两种结构提取文本局部信息训练获得词向量。在此基础上,龚丽娟等[9]先使用Word2Vec 对海关报关商品文本降维获得词向量,再使用SVM 进行归类,取得了不错的分类效果,但该方法只考虑了文本的局部信息,未有效利用整体信息。为克服Word2Vec模型的缺陷,Pennington 等[10]提出全局词向量(Global Vectors for word representation,GloVe)模型,该模型基于全局词汇共现的统计信息来学习词向量,同时考虑了文本的局部信息与整体信息。Kim[11]提出的TextCNN可以基于Word2Vec 或GloVe 初始化词向量表示,利用卷积神经网络对文本进行归类。以上特征表示方法训练的词向量均为静态词向量,舍弃了文本中大量词语的位置信息,不能表示出文本的完整语义。
随着深度神经网络发展,随上下文变化的动态词向量被验证出有更好的文本表示能力:Peters 等[12]提出了词向量会跟着上下文场景的变化而改变的语言模型ELMo(Embeddings from Language Model),采用双层双向长短期记忆(Bidirectional Long Short-Term Memory,BiLSTM)网络生成词的上下文表示;Radford 等[13]采用Transformer[14]结构提出生成式预训练词向量(Generative Pre-Training,GPT)模型,在多项自然语言处理(Natural Language Processing,NLP)任务中取得SOTA(State Of The Art)效果;Devlin 等[15]结合ELMo和GPT 各自的优势,提出了数据规模更大的BERT(Bidirectional Encoder Representations from Transformers)预训练语言模型。该模型通过使用双向Transformer 编码器对语料库进行训练得到文本的双向编码表示,使用MLM(Masked Language Model)和NSP(Next Sentence Prediction)两种方法分别捕捉词语和句子级别的向量表示,在海关报关商品文本领域还未有以上模型的应用。
1.2 多任务学习
多任务学习(Multi-Task Learning,MTL)是机器学习的一个分支,其中多个任务通过共享模型同时学习。这种方法具有提高数据效率、通过共享表示减少过度拟合以及通过利用辅助信息快速学习等优点。MTL 比单一任务学习更准确地反映了人类的学习过程。当一个新生婴儿学会走路或用手时,它就积累了一般的运动技能,这些技能依赖于抽象的平衡概念和直观的物理学。一旦学习了这些运动技能和抽象概念,它们就可以在以后的生活中被重用和增强,用于更复杂 的任务。如在自然语言处理领域中,Søgaard 等[16]、Hashimoto 等[17]和Sanh 等[18]提出在更早的层监督“较低级别的”任务,以便为这些任务学习的特征可以被更高级别的任务使用。这样就形成了一个明确的任务层次结构,并为来自一个任务的信息提供了一种直接的方式来帮助解决另一个任务。Liu 等[19]通过将共享BERT 嵌入层添加到架构中,扩充了模型的表示能力。MTL 现有的方法经常被分成两类:硬参数共享和软参数共享。硬参数共享是在多个任务之间共享模型权重的做法,如图1 所示,使每个权重都经过训练,共同最小化多个损失函数。在软参数共享下,不同的任务有各自的特定任务模型,权重不同,但不同任务的模型参数之间的距离被加入到联合目标函数中。
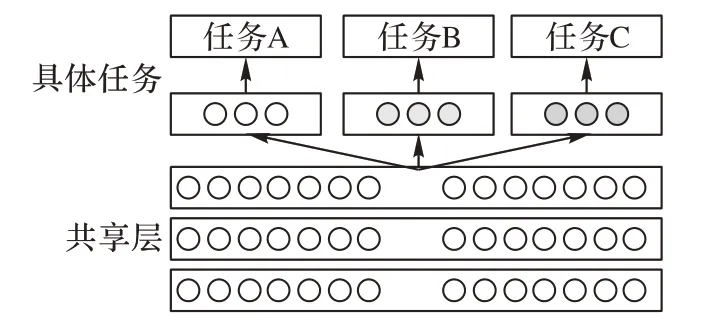
图1 硬参数共享结构Fig.1 Hardware parameter sharing structure
综合以上研究,本文基于海关报关商品文本的特点,在文本特征表示和特征学习方式上进行了改进。文本特征表示上使用BERT 作为预训练语言模型对海关报关商品文本进行句子层面的特征表示,以提升词向量的表征能力;在特征学习方式上,本文将目标分类任务由易到难分为章、目、HS 编码三个任务对模型进行多任务训练,通过监督“较低级别的”章、目分类任务,使学习的特征可以被更高级别的HS编码分类任务使用。这种多层级任务结构共享参数,最大限度地减少了过拟合,提高了模型的收敛速度,改善了分类效果。通过不同文本特征表示、是否分层级、是否多任务的对比实验,证明了本文所提方法的有效性。
2 模型实现
搭建HS 编码分类器最大的难点在于,分类目标涉及9 346 个HS 编码,数量众多,若使用常规的方法,即使用预训练模型BERT 进行训练,过于稀疏的向量会导致模型无法收敛。然而通过观察HS 编码可以发现,HS 编码分类有别于其他传统的多分类问题,传统多分类问题标签之间并不存在联系,而HS 编码之间存在树形结构,如图2 所示,编码“01012100”与“01012900”为兄弟节点,它们的父亲节点为编码“0101”。本文采取了多任务的研究路线合理利用了树形结构,通过将HS 编码的上层信息(商品所属章)加入到模型训练当中,进而带动中层分类(商品所属目)的训练,最后中层又促进底层(商品所属HS 编码)分类的收敛。基于这种研究路线,本文提出了HM-BERT 模型。

图2 HS编码树形结构Fig.2 HS code tree structure
2.1 HM-BERT结构
文本提出的HM-BERT 模型结构如图3 所示。本文采用BERT 预训练语言模型作为词嵌入层,来学习商品描述的文本表示;本文多任务采用了硬共享模式,共享了BERT 模型的参数,取BERT 最后一层作为多任务共享的输出,主要由以下6 部分构成:输入层、BERT 层、语义向量层、全连接层、Softmax 层和输出层。

图3 HM-BERT模型结构Fig.3 HM-BERT model structure
输入层 从报关数据集中选取商品名(G_NAME)和商品描述(G_MODEL)字段内容,组成商品文本通过输入层输入到BERT 层当中。作为文本分类任务,先要在商品文本的两端加入BERT 特殊的token,[CLS]表示句子的分类,[SEP]表示句子的结束;接下来将文本处理为固定长度N,若输入文本过长会被截断,而不足的文本会被padding 到长度N;在BERT 层对上述处理后的文本进行序列化,即每个词转化为BERT 预训练字典中对应的编号;最后商品文本表示X如式(1)所示:
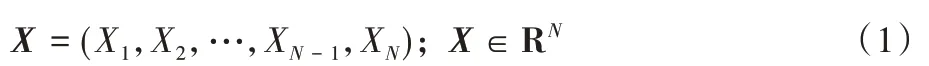
其中:Xi表示该条文本的第i个词,N表示设置的文本最大长度。
BERT层商品文本X经过Word Embedding 使其与位置向量(Position Embedding)和分段向量(Segment Embedding)相加得到商品文本表示向量E如式(2)所示,过程如图4 所示,其中Ei表示第i个词的特征向量,H为特征向量的向量长度。经过多个双向Transformer 编码器编码后得到最后一层文本表示向量S如式(3)所示:
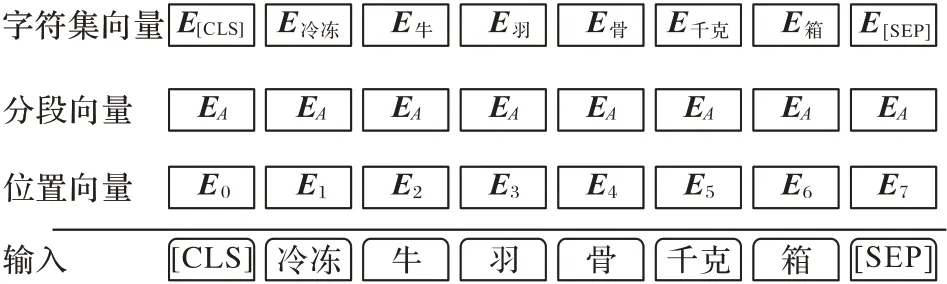
图4 词嵌入构造Fig.4 Word embedding structure
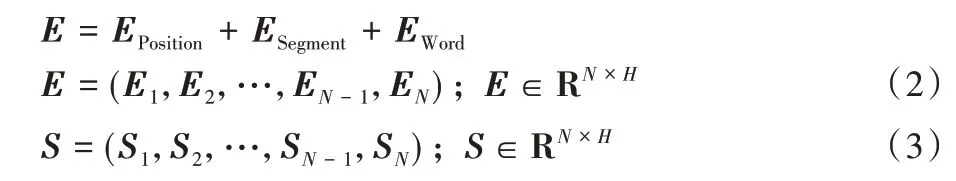
语义向量层 本模型采用的共享方式为硬共享,共享参数为整个BERT 模型的参数。由BERT 表示预测句子分类token:[CLS]位于句首,因此S1经过编码后表示了句子语义向量,取BERT 最后一层S1位置与下一层的三个全连接层分别进行全连接。
全连接层 通过三个彼此独立连接层与共享层全连接,三个全连接层的维度分别与对应位数的HS 编码标签相等,其中代表10 位HS 编码标签数Nhs=9 346,代表2 位章标签数Nchapter=97,代表4 位目标签数Nhead=1 196。
Softmax 层 对三个全连接层的输出结果进行Softmax 归一化,得到商品文本属于三个分类目标的概率分布向量Pchapter、Phead、Phs。
输出层:对上述概率按行取最大值索引,即可得到最终商品文本分类标签。
2.2 HM-BERT训练
如图3 所示,HM-BERT 模型更新的参数包括BERT 共享层中的参数。在多任务模型训练过程中,需要分别计算Loss对模型进行优化,本文采用交叉熵作为损失函数,计算过程如式(4):
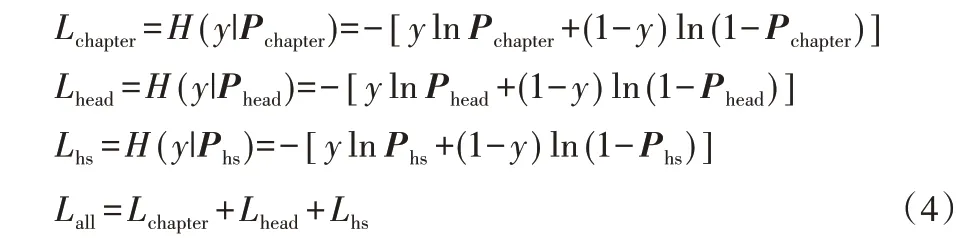
由于真实标签用1 表示,因此模型Loss 可以看作章、目、HS 编码三者概率相乘,即符合在树型结构当中,商品文本分类是每一层分类共同作用的结果,推导过程如式(5):
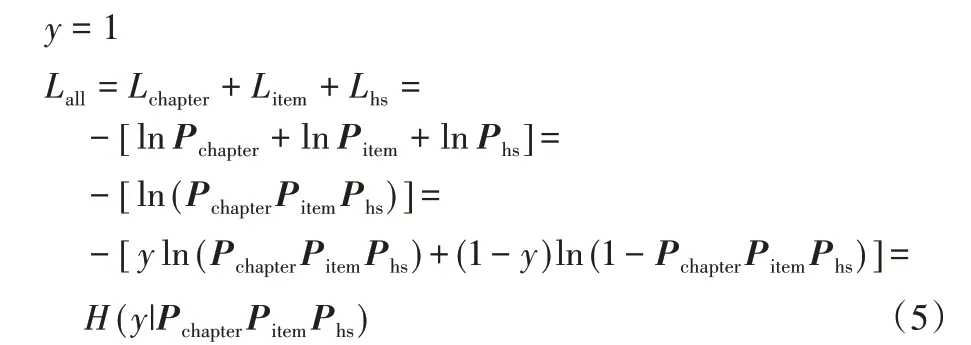
为进一步防止过拟合,本文采用了权重衰减的adamW来优化损失函数:
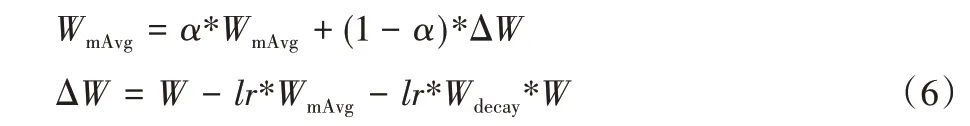
其中:WmAvg为学习率的移动均值,lr为学习率,α表示衰减速率,Wdecay表示衰减权重。
2.3 对照模型结构
为对比模型效果,除单独使用BERT 与fastText 外,本文还将分层级的思想应用于fastText 模型,提出H(Hierarchical)-fastText,如图5 所示。
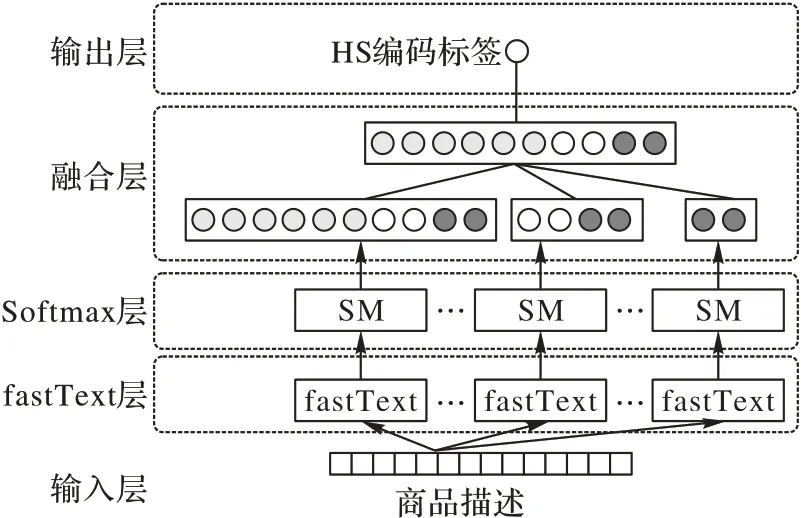
图5 H-fastText结构Fig.5 H-fastText structure
H-fastText 模型也采用了层级概率相乘的思想,包括输入层、fastText层、softmax 层、融合层、输出层,其中输入层内容与HM-BERT模型相同。
fastText 层 商品描述经由输入层输入的fastText 层集成了五个不同层次编码标签训练的fastText 模型,分别使用了2位(章标签),4 位(目标签),6 位(子目标签),8 位,10 位的HS编码进行训练。
softmax 层 不同层次的输出通过softmax 转换为分类的概率分布按代表位数分为P2、P4、P6、P8、P10。
融合层 10 位编码与其对应不同层次编码概率相乘,得到一个每个层次共同作用的概率分布。计算过程如式(7):

输出层 对融合输出的概率按行取最大值索引,得到最终的HS编码标签。
3 实验与结果分析
3.1 实验准备
本文一共设计了两组实验:第一组验证不同基础模型和组合模型对分类效果的影响,分别对比了TextCNN、fastTextBERT 基础模型和H-fastText 模型;第二组验证了层级多任务方式对分类效果的影响,分别对比了HM-BERT 对章节、目、全HS 编码三个层次与原始BERT 分别对不同层次的分类效果。
3.1.1 数据预处理
本文的报关数据集来源于国内某报关服务商2019 年的报关数据共计29 392 037 条,涉及9 346 个HS 编码,数据字段包括商品名(G_NAME),商品描述(G_MODEL),HS 编码(CODE_TS),具体信息如表1 所示。其中G_NAME 为申报商品时单独填写的名称字段,不允许为空,但允许重复;G_MODEL 为申报商品时的商品描述,包括各个申报要素,不同的章节存在差异,一般为原料、尺寸、用途,用空格隔开;CODE_TS 表示商品申报时的编码,所有编码均为10 位,前2位表示章,前3、4 位表示目,5、6 位表示子目,不允许为空。在数据样例中可以发现,商品描述未出现明显的上下文语义信息,但事实上报关对于申报要素输入有顺序的要求,这可以看作是一种序列信息被应用于分类当中。

表1 报关数据集描述Tab.1 Description of customs declaration dataset
在去除重复数据与空数据后,对所有97 章数据进行统计(77 章被保留将来使用),如表2 所示,可以发现各章节之间存在较大的不平衡性,如代表电器和零件的84、85 章占有百万级的数据量,占有近千的HS 编码数,而代表活动物的01 章只有几百的数据量,十几个HS 编码。为缓解这种情况,本文采取分层抽样,每个HS 编码随机抽样500 个样本,多次实验取平均值的方法进行实验。
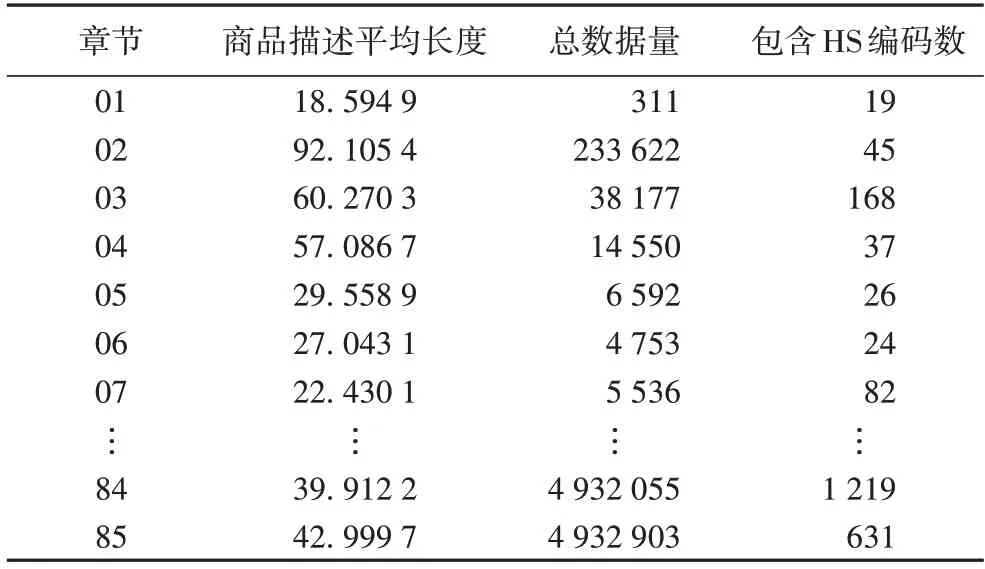
表2 报关数据集统计信息(部分)Tab.2 Customs declaration dataset statistics(part)
为充分利用数据信息,实验中使用的文本输入由商品名与商品描述拼接而成,抽样产生数据662 373 条,将处理后的数据按0.81∶0.09∶0.10 的比例划分为训练集、验证集与测试集。
3.1.2 实验设置
1)参数设置。
本文中分类模型的参数包括:文本数据词向量维度embedding_size=768、文本保留最大长度max_length=128、学习率lr=1E-5、训练轮数epoch=10、批数据长度batch_size=64、衰减率weight_decay=1E-3。
2)实验环境。
本文的实验环境为:操作系统centos 7.2;CUDA10.1;处理器Intel-i5 2.5 GHz 24 核,GPU 2*2080Ti;内存128 GB;显存32 GB;开发框架Pytorch1.5;编程语言Python 3.7。
3)评价指标。
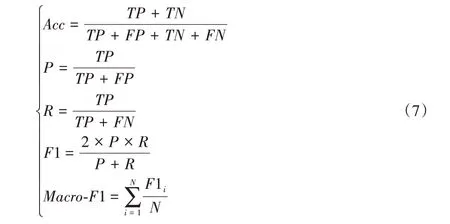
由于数据不均衡,为了更全面评价模型的分类效果,本文采用了以准确率(Accuracy,Acc)为主要评估指标,精确率(Precision,P)与召回率(Recall,R)的调和平均值(F1)对模型效果进行评价,如式(7),其中TP(True Positive)表示实际为正例且预测为正例,FP(False Positive)表示实际为负例但预测为正例,TN(True Negative)表示实际为负例且预测为负例,FN(False Negative)表示实际为正例但预测为负例。宏平均(Macro-F1)对每一类计算F1 后取平均值。
3.2 对比实验
3.2.1 对比模型
本文将与以下模型进行比较:
1)TextCNN[11]:TextCNN 卷积使用一维卷积,通过卷积池化操作快速捕获文本特征,文本使用了Word2Vec 初始化TextCNN 词向量。
2)fastText[5]:fastText 采用n-gram 统计表示词向量,使用神经网络进行分类,适用于多分类任务。
3)H-fastText:集成使用了2 位(章标签)、4 位(目标签)、6位(子目标签)、8 位、10 位的HS 编码进行训练的5 个fastText集成模型,如3.3 节所示,融合不同层级信息,采用概率相乘的思想,用于对比分析分层级对分类效果的影响。
4)BERT[15]:使用动态词向量表示和Transformer 结构进行分类
5)HM-BERT:本文使用的多任务融合不同层级信息的BERT 模型
3.2.2 模型对比分析
表3 展示了不同模型在HS 编码(全10 位编码)数据集中的表现。
从表3 可以看出,相较于其他模型,本文模型取得了最好的效果。首先,使用Word2Vec 进行词向量表示的TextCNN 模型比使用n-gram 统计表示词向量的fastText 模型具有更好的分类效果;而采用了动态词向量表示的BERT 模型在三者中效果最优,这是因为BERT 模型能自适应不同上下文动态词向量,与Word2Vec 和n-gram 相比,在句子层面的表示上更具优势。H-fastText 相较于普通fastText 模型性能取得了巨大的提升,分别在准确率和宏平均指标上提高了5.47 个百分点和7.97 个百分点,这是由于分层级的方式充分利用了HS 编码中的层级编码信息,初步证实了分层归类的有效性。与原始BERT 模型的相比,HM-BERT 可以在不增加训练参数的同时,在准确率和宏平均指标上分别提高1.99 个百分点和3.40 个百分点,且在分层多任务的训练中,每次迭代充分考虑了不同层级编码信息,HM-BERT 在训练速度也优于原始BERT 模型。
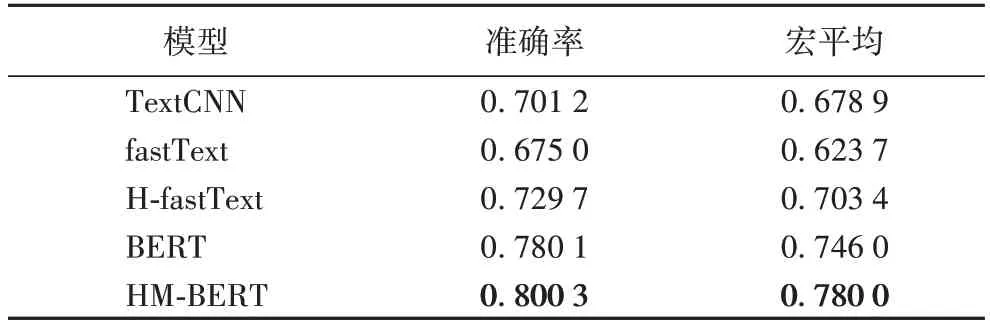
表3 各模型实验结果对比Tab.3 Comparison of experimental results of different models
3.2.3 层级对比分析
为了进一步验证本文所提模型的有效性,对不同层级的任务分类效果进行了实验,如表4 所示。
表4 中,HS 编码表示对全10 位HS 编码进行预测,目和章表示对4 位、2 位编码进行预测。实验结果显示,采取层级多任务方式融合不同层次的归类参数可以让不同层次归类效果均有所提升。由于融合了上层的章、目信息,该信息在反馈至共享句子表示层时,可以进一步缩小HS 编码的分类范围,提高分类的精确率。实验结果表明,HS 编码分别在准确率和宏平均上提升了2 个百分点和3.4 个百分点,效果显著,这也说明了融合不同层级的类别信息也有助于提高归类的准确性。
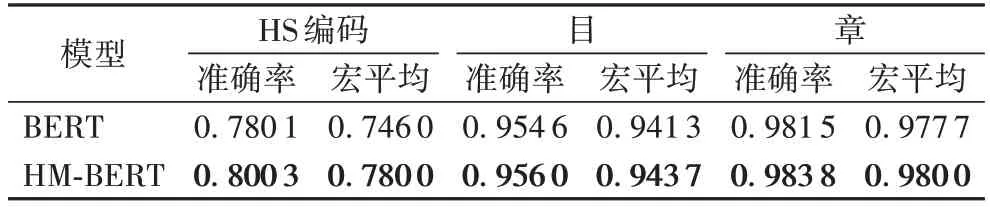
表4 各层级实验结果对比Tab.4 Comparison of experimental results of different levels
3.2.4 速度对比分析
为验证本文所提模型在收敛速度上的优势,本文对比了HM-BERT 与BERT 模型训练过程中loss 随epoch 的变化,如图6 所示。
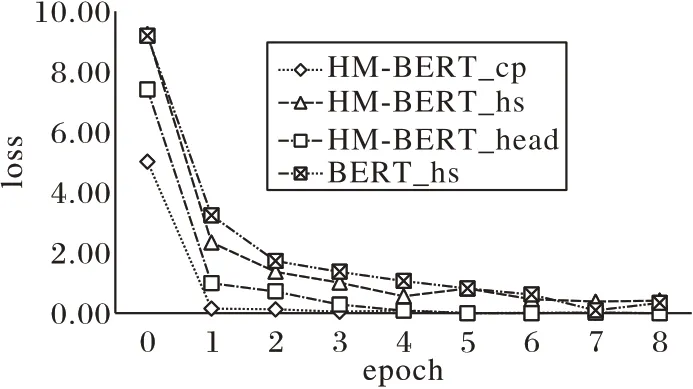
图6 模型收敛速度对比Fig.6 Comparison of convergence speed of models
图6 中 的HM-BERT_cp、HM-BERT_head、HM-BERT_hs分别表示HM-BERT 在章、目、HS 编码分类任务中的loss 值,BERT_hs 表示BERT 模型在HS 编码分类任务的loss 值。图6显示,章节分类作为层级最高,最简单的任务,收敛速度最快;其次是目分类,同为HS 编码的分类任务当中,使用HMBERT 的收敛速度明显高于使用原始BERT 的收敛速度,这可能是前者由于共享了章分类和目分类的参数,在高层级任务的带动下,HM-BERT 会有更快的训练速度。
4 结语
针对海关报关商品文本类别多、类别样本不均衡,现有的分类方法大都采用n-gram 和Word2Vec 等方式获取文本的词向量表示,舍弃了大量词语的位置信息的问题,本文提出了一种采用层级多任务训练的BERT 模型。该模型不仅通过BERT 预训练语言模型提升了词向量的表征能力,还将目标分类任务由易到难分为章、目、HS 编码三个任务,对模型进行多任务训练,通过监督“较低级别的”章节、目分类任务,使学习的特征可以被更高级别的HS 编码分类任务使用。这种多层级任务结构共享参数,最大限度地减少了过拟合,提高了模型的收敛速度,改善了分类效果。本文在国内某报关服务商2019 年的报关数据上进行了实验,实验结果表明,使用BERT 预训练语言模型在海关报关商品文本应用上效果优于传统的词向量,使用分层级的方式进行多任务训练的效果在多个任务中的分类效果均有所提高。
本文所提出的HM-BERT 模型各项评价指标中均有着较好表现。在下一步工作中,可以考虑应用到更多带有层级的数据集中。
猜你喜欢
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09 06:12:12
航天工业管理(2020年9期)2020-12-28 00:38:02
军事运筹与系统工程(2020年1期)2020-09-11 06:41:00
汉字汉语研究(2020年2期)2020-08-13 07:52:48
电子制作(2019年22期)2020-01-14 03:16:24
中国生物医学工程学报(2019年6期)2019-07-16 07:52:40
疯狂英语·新读写(2018年3期)2018-11-29 22:37:11
自动化学报(2016年3期)2016-08-23 12:02:56
电测与仪表(2016年5期)2016-04-22 01:13:46
系统工程与电子技术(2016年2期)2016-04-16 05:17:09
