
LRSAR-Net语义分割模型用于新冠肺炎CT图片辅助诊断
2022-02-24 08:58张桃红郭徐徐
电子与信息学报 2022年1期
张桃红 郭徐徐 张 颖
①(北京科技大学计算机与通信工程学院 北京 100083)②(材料领域知识工程北京市重点实验室 北京 100083)
③(华北理工大学轻工学院 唐山 064000)
1 引言
自2019年末新冠(Covid-19)疫情爆发以来,全球已经有1亿9千万人感染了新冠病毒。Covid-19病毒传播能力强,可通过人与人之间的直接接触、接触带有病毒的物体和气溶胶的方式进行传播。通过对人体的肺部进行入侵,造成肺部感染,主要症状为咳嗽、感冒和发烧等。直接对患者的情况进行分析很难判断是否感染新冠病毒[1],一般采用X射线对患者的肺部进行计算机断层扫描(Computed Tomography, CT),通过CT图片可以进行判断,但是这需要经过专门训练的医生才可以。近年来,随着人工智能、深度学习的快速发展,使用计算机辅助诊疗可以显著提高诊断效率。常用的是分类和语义分割,其中语义分割不但可以诊断患病类型,还可以指出病患部位,是智能诊断的有效辅助手段。
随着深度学习的快速发展,基于卷积神经网络(Convolutional Neural Network, CNN)的图像分割方法在医学领域已经展开了广泛而深入的研究[2—4]。近年来,注意力机制的提出进一步提高了神经网络的识别精度和准确率。注意力机制最早由Vaswani等人[5]为解决机器翻译的问题所提出。注意力机制可以对学习到的权重进行调整,使重要的特征权重更高。Wang等人[6]首次将注意力机制引入到计算机视觉当中,通过计算像素之间的相关性来对特征图的权重进行调整。随后,注意力机制在医疗图像领域被广泛应用。Li等人[7]设计了一种基于注意力的嵌套U-Net模型来对肝脏肿瘤图片进行分割。该网络提出了注意力门(attention gate)的模块,注意力模块可以对编码器和上采样的信息进行聚合,同时对权重调整。Fan等人[8]提出了一种用于分割新型冠状肺炎CT图像的网络Inf-Net。该网络利用一组隐式的反向注意力模块和显式的边缘注意力指导来建立区域和边界之间的关系。Liu等人[9]设计了一种基于注意力条件随机场的CANet网络来对脑胶质瘤进行分割,注意力可以调节不同特征之间流动的信息量。Dou等人[10]设计了一种带有深度注意力模块卷积核的分割网络来对胎儿皮质板进行分割。Jiang等人[11]提出了一种基于Ray-Shooting和长短期记忆网络的神经元结构分割模型。该模型使用包含通道注意力模块的双向长短期记忆网络对图像进行分割,通道注意力可以强调重要的特征信息。Zhang等人[12]提出了一种用于检测视网膜连接点的O型注意力网络。该网络设计了具有注意力模块的局部增强分支来增强视网膜中的低对比度的连接点,并利用注意力机制来帮助检测分支进行识别。Chen等人[13]为了解决UNet中卷积步骤的采样局部性,使用Transformer自注意力机制[5]对全局信息进行编码并且与经过卷积得到的特征相结合实现更精确的定位。注意力机制通过对全局特征点的相关性信息进行聚合,可以获取长范围的特征信息同时对特征点的权重进行调整。虽然注意力机制的提出显著提高了模型的识别准确率,但是注意力机制存在时间复杂度高、训练速度慢和权重参数多的问题。对于大小为H×W的特征图,注意力模块的时间复杂度为O(H×W×H×W)[6]。语义分割网络为了保证丰富的语义信息通常使用大尺寸的特征图,从而造成模型的时间复杂度过高。
为了解决注意力机制所带来的时间复杂度等问题,张量分解可以很好地降低注意力机制的时间复杂度。张量分解广泛应用于计算机视觉加速中。依据张量分解理论[14],高秩张量可以分解为低秩张量的线性组合。Lebedev[15]等人提出了一种基于CP张量分解的大型卷积网络中的卷积层加速方法。该方法首先将4维卷积核的高秩张量分解为多个秩一张量,然后使用秩一卷积核来加速网络训练。Wu等人[16]将全连接层的权重矩阵分解为多个子张量的Kronecker的乘积来近似全连接层,同时减少神经网络中的参数。Sun等人[17]设计了一种用于网络优化的张量分解方法。该方法通过利用网络各层之间的权重张量包含相同或独立分量的特性,对共享的网络结构进行耦合张量的序列分解,实现了模型的压缩。Chen等人[18]提出了一种3维上下文特征表示语义分割模型Reco Net。该模型通过低秩子张量特征的线性组合来实现高秩张量的近似,相较于原特征图显著降低了模型的计算量。以上方法通常用多个低秩张量的来替换一个高秩张量。张量分解可以将计算复杂度较高的原始张量分解为一组低秩子张量。通过对低秩子张量计算,可以降低网络模型的参数量同时进行网络加速。虽然张量分解的方法可以提高模型的压缩率,但是在模型压缩率很高的情况下模型的识别效率会降低。为了缓解张量分解导致识别效率低的问题,本文在网络中使用共享的结构来提高模型的性能。
在医疗图像领域,张量分解通常用于高光谱成像和图像去噪。Zhang等人[19]提出了一种基于CP张量分解字典学习方法进行光谱CT图像重建。Wu等人[20]为解决光谱CT成像衰减的问题,提出了基于KBR(Kronecker Basis Representation)张量分解的方法应用于光谱CT重构模型。Hatvaniy等人[21]提出了一种基于规范多元分解的单图像超分辨率去噪方法来对牙科CT图像进行去噪。张量分解的方法可以解决图像重构所带来的模型复杂度过高的问题,但在医疗图像分割领域应用较少。本文通过使用张量分解的方法来降低自注意力模块的时间复杂度并对新冠肺炎图片进行分割。
为了降低自注意力模块的时间复杂度并且计算各个特征点之间的相关性,本文作者提出了一种基于低秩张量自注意力重构的语义分割网络LRSARNet(Low Rank Self-Attention Reconstruction Net),此网络使用的是编码解码结构,实现了不同尺度特征信息的融合。为了获取更丰富的语义信息和降低自注意力模型的复杂度,本文设计了低秩张量自注意力重构模块,将高阶张量分解为低秩张量,使用低秩张量来构建自注意力特征图,然后将多个低秩自注意力映射图聚合生成高秩自注意力特征图。与经典的Non-Local[6]自注意力模块相比,低秩自注意力重构模块计算量更小,网络的预测速度更快。同时,实验与相接近的Reco-Net网络[18]进行了比较,体现自注意力机制的重要性。
2 模型结构
2.1 LRSAR-Net整体结构
本文所提出的低秩张量自注意力重构语义分割模型LRSAR-Net如图1所示。网络主要包括3个部分:编码器、解码器和低秩自注意力重构模块。编码器用来获取图像的特征信息。编码器可以提出5个不同层次的多尺度特征信息,低层的特征主要用来获取图像的细节特征和位置信息,高层的特征为抽象的语义特征信息。主干网络以带有残差结构的ResNet50[22]为例,并移除了全连接层进行图像信息编码。残差结构可以对网络的深度进行延伸,获取更加丰富的语义信息。编码器主要包括的下采样结构块为卷积层、最大池化层和ReLU激活函数。

图1 LRSAR-Net网络结构图
注意力模块用来获取更加丰富的上下文信息,虽然卷积结构可以通过叠加更多的层数来扩大感受野,并提取丰富的信息,但是更深的卷积层结构并不能很好地对全局信息进行获取。注意力模块则可以对全局的信息进行调整,图片中的每个点都会与其他的点计算相关性。通过注意力特征图得到的相关性信息对图片中的像素权重进行调整,属于相同类别的点的权重会得到聚合,不同类别的像素点信息会得到抑制,来突出图片中重要的部分。注意力机制可以获得丰富的语义信息,但是计算量会比较大。本文所提出的低秩张量自注意力重构模块LRSAR Block可以很好地解决计算量复杂的问题。
解码器用来聚集不同层次的特征信息。解码器可以将编码器提取到的特征与上采样特征图进行拼接,将不同层次的特征信息进行融合。上采样结构如图2(a)所示,特征图X1表示编码器特征,特征图X2表示解码器特征。特征图X2经过双线性插值上采样之后,与特征图X1从通道维度进行拼接。经过拼接的特征图输入到通道注意力模块(Squeeze Excitation Block, SE Block)[23],最后得到特征图Y。通道注意力模块的详细结构如图2(b)所示,特征图X经过全局平均池化GAP提取到通道权重信息Z,Z经过两个全连接层FC,将获取到的通道信息与特征图X相乘进行通道权重调整得到特征图Y。
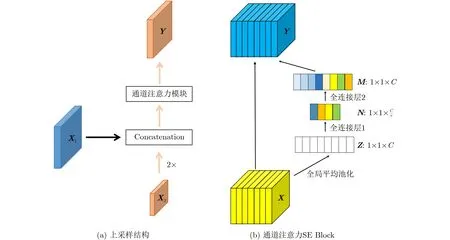
图2 解码层的上采样结构和通道注意力
2.2 低秩张量自注意力模块
低秩张量自注意力模块包括3个部分:低秩张量生成子模块、低秩自注意力子模块和高秩张量重构子模块。
2.2.1 低秩张量生成子模块
低秩张量生成子模块如图3所示,该子模块可以沿宽、高和通道维度进行高秩张量分解。依据CP张量分解理论[14],高秩张量可以分解为多个秩一张量的线性组合。秩一张量可以由3个1维向量的外积组成。根据秩一张量的定义,作者将高秩张量沿宽、高和通道维度进行分解生成多个1维向量,这些1维向量输入到低秩张量自注意力子模块中可以生成秩一张量。编码层提取到的高秩张量输入到3个低秩张量生成模块中,提取低秩张量特征信息。高秩张量多次输入到低秩张量生成模块中,生成多个不同的低秩张量特征。即高秩张量特征X输入低秩张量生成子模块s次会产生s个不同的低秩张量特征,沿着相同维度分解的低秩张量有相同的网络结构,但是参数信息不同。如特征图X沿高、宽和通道3个维度多次输入到低秩张量生成子模块生成不同的特征向量(Q1,K1,V1), (Q2,K2,V2), …(Qi,Ki,Vi), …, (Qs,Ks,Vs)。Qi,Ki和Vi分别代表沿高、宽和通道维度分解产生的1维向量,s代表沿某个维度生成的1维向量的个数,式(1),式(2)和式(3)分别表示Qi,Ki和Vi。这些低秩特征向量经过低秩自注意力模块生成不同的低秩自注意力子特征图Y1,Y2, …,Yi, …,Ys。每个低秩张量生成子模块由全局平均池化(Global Average Pooling,GAP)、全连接层(Fully Connected layer, FC)和Sigmoid激活函数组成,并生成1维的特征向量,用于自注意力特征图的构建。全局平均池化原理为先对高秩张量沿某个维度进行切片,对于每个切片矩阵进行全局平均池化。通过全局平均池化,每个向量中的每个元素都聚合了相应的切片矩阵信息。全连接层可以实现向量中任意一个元素对所有元素信息的聚合。Sigmoid激活函数可以增强网络的非线性拟合能力,并且将特征信息映射到0至1的范围内,突出特征向量中重要的特征信息。文献[20]低秩张量生成模块使用的是卷积结构,本文将卷积替换成了FC层。FC层中的每个特征点都会与其他的特征信息进行聚合,而单层卷积结构只能聚合局部的特征信息。不同的低秩张量特征的FC层参数信息是不相同的。虽然FC层会增加参数量,但是编码层的最后一层特征维度比较低,参数量增加不会太多。
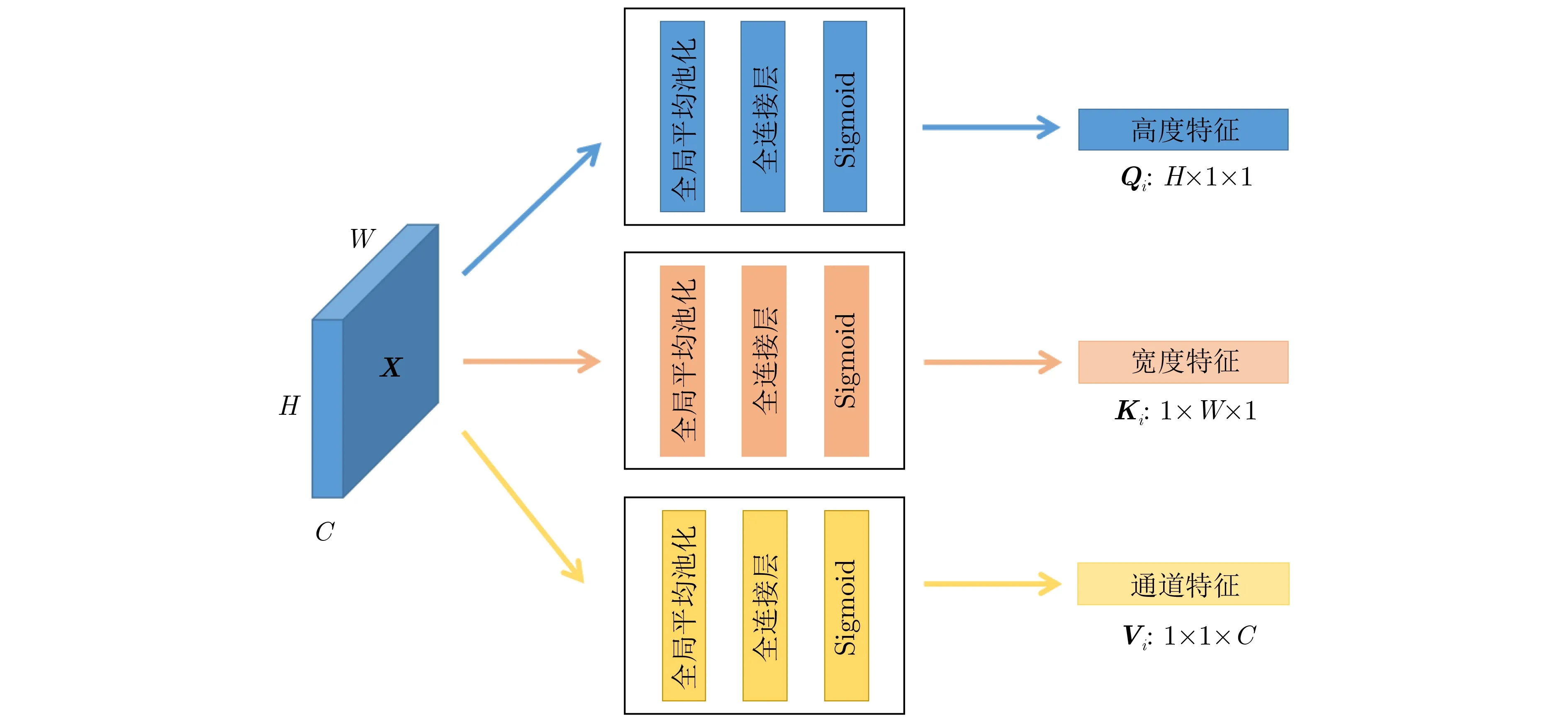
图3 低秩张量生成子模块
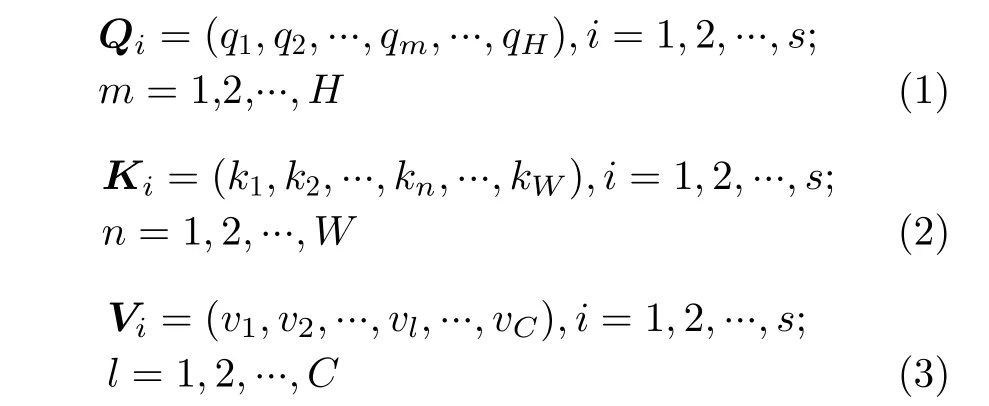
2.2.2 低秩自注意力子模块
如图4所示,特征图X ∈RH×W×C首先输入到低秩张量生成子模块中,产生多个不同的低秩张量特征Qi,Ki和Vi。高度特征Qi与宽度特征Ki相乘获得空间相似度矩阵Ai ∈RH×W×1,使用Softmax层进行激活,具体的计算过程如式(4)所示。式(5)是对特征相似度矩阵Ai更详细的解释,amn表示空间相似度矩阵上的每一个点,qm和kn分别表示宽度特征信息和高度特征信息。获得的空间注意力特征图Ai没有通道之间的相关性信息,特征Vi对通道之间的信息进行了聚合。注意力特征图Ai与通道注意力信息Vi相乘,获得3维的注意力信息,计算过程如式(6)所示。输入的特征图X与注意力特征相加,获取长范围的语义信息特征,得到特征图Yi。
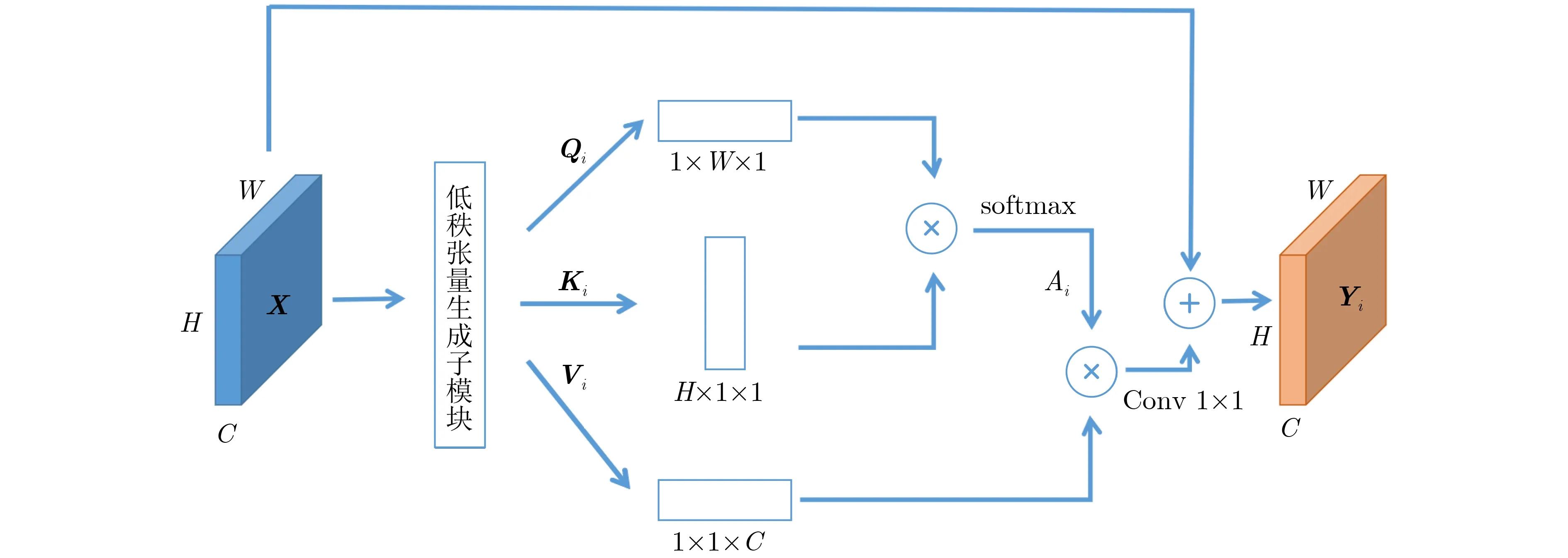
图4 低秩自注意力子模块

自注意力模块Non-Local Block[6]在计算像素的相似度时,计算图像中任意两个点之间的相关性。对于特征图X,自注意力模块的时间复杂度为O(H×W×H×W),而LRSAR Block只需要计算两个向量的外积,时间复杂度为O(H×W),时间复杂度更低。相较于自注意力模块,本文提出的LRSAR-Net时间复杂度更低,速度更快。
2.2.3 高秩张量重构子模块
依据张量分解理论,高阶张量可以分解为多个秩一的张量的线性组合。如图5所示,特征图X经过低秩自注意力模块生成多个秩一注意力特征图Yi,Yi只包含了低层次的语义信息。秩一注意力特征图Yi是由不同的参数低秩张量生成模块产生的,所以不同的秩一注意力特征图所包含的特征信息是不相同的。作者在每个秩一注意力特征图Yi之前引入了一个可学习的权重参数λi,λi会随着训练而调整。各个低秩自注意力特征图会与相应的权重参数λi相乘,然后相加组合成高秩自注意力张量Y。张量重构方法如式(7)所示。高秩注意力特征图Y包含了丰富的语义信息,实现了全局特征信息的聚合,同时降低了自注意力特征图的计算量。在本实验中,为了平衡模型的复杂度和计算量,将s设置为4。
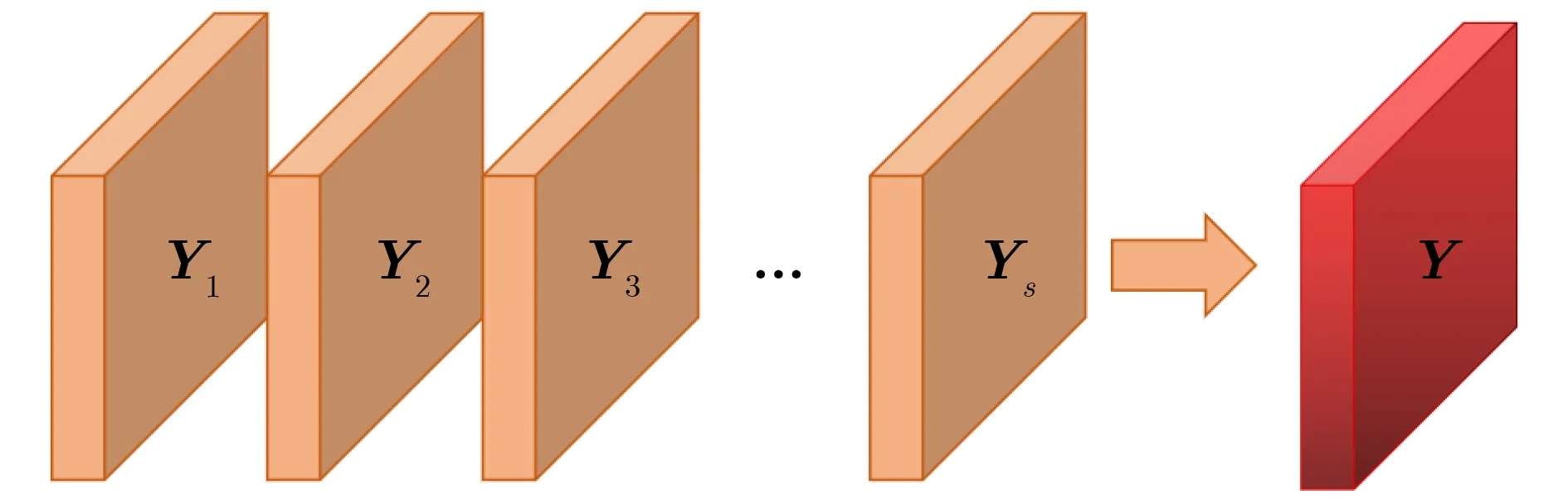
图5 高秩张量重构子模块

3 实验与分析
3.1 数据集
如表1所示,本实验使用了Covid-19 CT100和Covid-19 P9[24]两个新冠患者CT图片数据集。Covid-19 CT100数据集有100张轴向CT图片,如图6所示。Covid-19 P9数据集有829张CT图片,其中有373张Covid-19的患病图片。数据集包括3个标签:毛玻璃、病变和胸腔积液。数据集的标签是由经过专业训练的放射科医生通过自动标注程序MedSeg[25]完成的。为了更好地训练模型,我们将两个数据集合成1个数据集进行训练,其中训练集图片561张,验证集图片184张和测试集图片184张。训练集、测试集和验证集之间的比例为6∶2∶2。
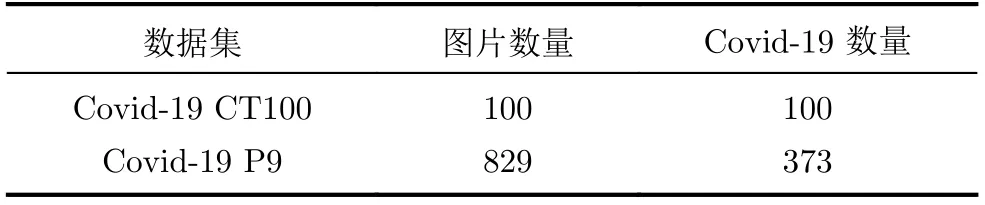
表1 不同的特征提取网络的模型对比DataSet

图6 Covid-19患者肺部CT图片
3.2 实验过程
本实验基于深度学习框架Pytorch。在图片输入到模型之前,先将大小为512×512×1的图片进行通道复制,得到的输入为512×512×3。模型的迭代次数为80,批量大小设置为16,初始学习速率为0.001,使用的是Adam[26]优化器。在训练的过程中,使用了早停的策略,当验证集损失函数多次不下降时,停止训练。为了提高模型的泛化性能,防止模型过拟合,在实验中使用了数据增强的策略。对训练集图片进行了裁切、旋转、水平翻转和垂直翻转。
实验使用平均交并比(mean Intersection over Union, mIoU)和像素精确度(Accuracy, Acc)两种指标来验证Covid-19新冠肺炎数据集的模型训练精确度。两个指标的数值越大,表示模型的效果越好。真正例(True Positive, TP)表示真实值和预测值都为正例的像素个数。假正例(False Positive,FP)表示预测为正例,但实际值为反例的像素个数。假反例(False Negative, FN)表示预测为反例,实际为正例的像素个数。mIoU和Acc的计算方法如式(8)和式(9)所示,α表示类别个数。

实验用ED Net(Encoder-Decoder)表示不包括注意力机制的基础的编码解码网络。ED Net和LRSAR-Net模型训练过程如图7和图8所示,通过对比可以发现,在模型训练的过程中ED Net在5到40代之间波动程度比较大,在训练40代之后,模型趋于稳定。ED Net从5到40代之间波动比较频繁,测试集的Acc变化范围从65%到95%,测试集的mI-oU变化范围从25%到65%,测试集的Loss的变化范围从1.2到0.4。LRSAR-Net模型从训练到第5代之后,模型的Acc, mIoU相较于ED Net迅速上升到一个较高的数值,而损失也迅速降低到0.3左右。ED Net在加入LRSAR-Net模块后,模型趋于稳定的代数更早,提高了模型的稳定程度。
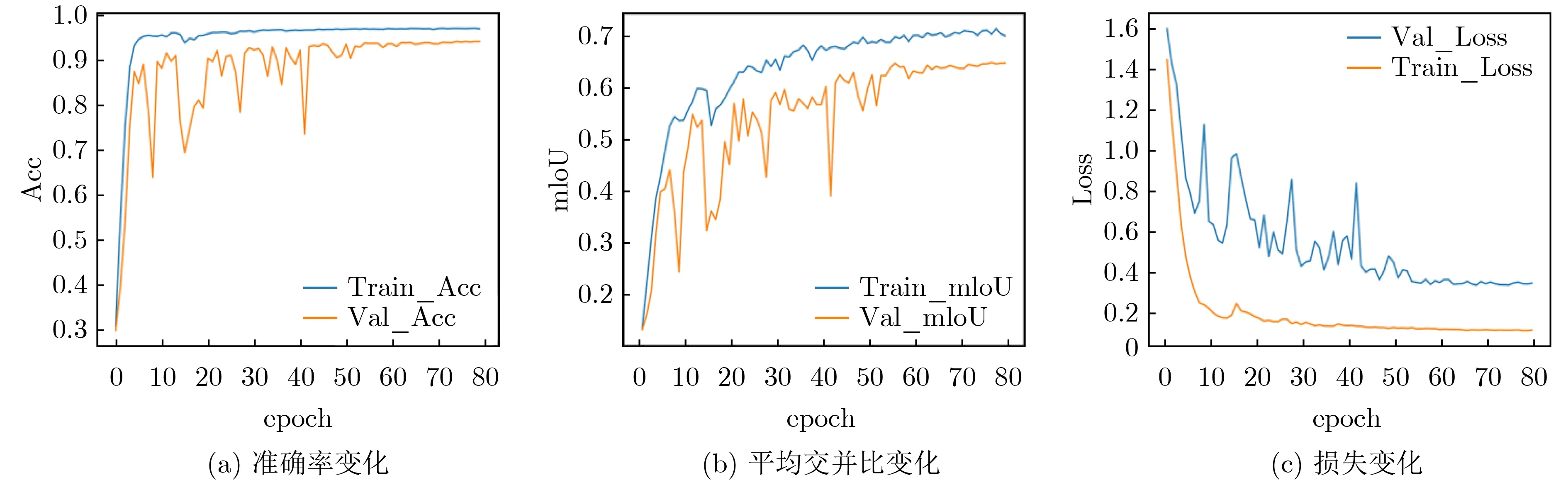
图7 ED Net训练过程中的准确率Acc、平均交并比mIoU和损失的变化

图8 LRSAR-Net训练过程中的准确率Acc、平均交并比mIoU和损失的变化
表2为不同的注意力机制对模型的影响,Non-Local为自注意力模块、LRSAR为本文提出的低秩张量自注意力重构模块,SE表示通道注意力。Non-Local模块与原模型相比,测试集的mIoU提升了1.6%,测试精确度Acc略有下降。本文模型与原模型相比,测试集的mIoU提升了3.6%,同时测试集准确度提升了0.3%。SE通道注意力和LRSAR注意力效果相当,但是精确度Acc提升了0.3%。由于Reco Net网络使用的也是张量分解的方法来降低模型的时间复杂度,本实验选择Reco Net[18]作为对比模型。ED Net+LRSAR网络相较于Reco Net网络在测试集上提升了1.5%的mIoU准确度,像素精确度Acc提升了0.5%。本文提出的LRSAR-Net比Reco Net网络提升了2.5%的测试集mIoU准确度,像素精确度Acc上提升了0.6%。虽然Reco Net网络使用的是空间注意力模块,但是没有考虑像素点之间的相关性。由实验结果可见,LRSAR-Net同时融合了自注意力LRSAR和通道注意力SE,效果提升明显,mIoU为70.0%,Acc为95.1%。由于疾病类型的像素数量相比较背景而言占比较小(尤其毛玻璃、病变的像素),故整体的精确度较高,导致精确度参数的数值提升不明显;但衡量图片语义分割的交并比参数反映了本文方法的有效性,本文方法提高了整体分割的交并比。通过实验可以发现自注意力模块和通道注意力模块都可以显著提升模型的性能,但是LRSAR低秩张量自注意力重构模块的模型复杂度更低。本文提出的LRSAR-Net模块考虑像素点之间的相关性关系使得模型的识别精确度要比Reco Net所提出的注意力效果更好,同时时间复杂度更低。
从表2的参数量和FLOPs可以看出,低秩张量注意力重构LRSAR模块的参数量为17.13M,而非局部自注意力NonLocal模块的参数量为34.27M。从模型的计算复杂度比较,LRSAR模块的复杂度为1.28G,而NonLocal模块的复杂度为2.56G。NonLocal模块的参数量和时间复杂度是LRSAR模块的两倍。LRSAR低秩张量自注意力重构模块要比NonLocal非局部自注意力模块参数量更小,但是精确度提升更明显。Reco Net网络的参数量为LRSAR-Net网络模型的两倍,时间复杂度增加了4.47G。由于Reco Net划分了过多的子张量,导致模型的参数量和时间复杂度都显著增加。本文提出的LRSAR-Net网络在参数量和时间复杂度小于Reco Net的情况下,识别精确度更高。实验表明,自注意力模块要比简单的空间软注意力模块效果好,因为自注意力模块考虑特征点之间的相关性。
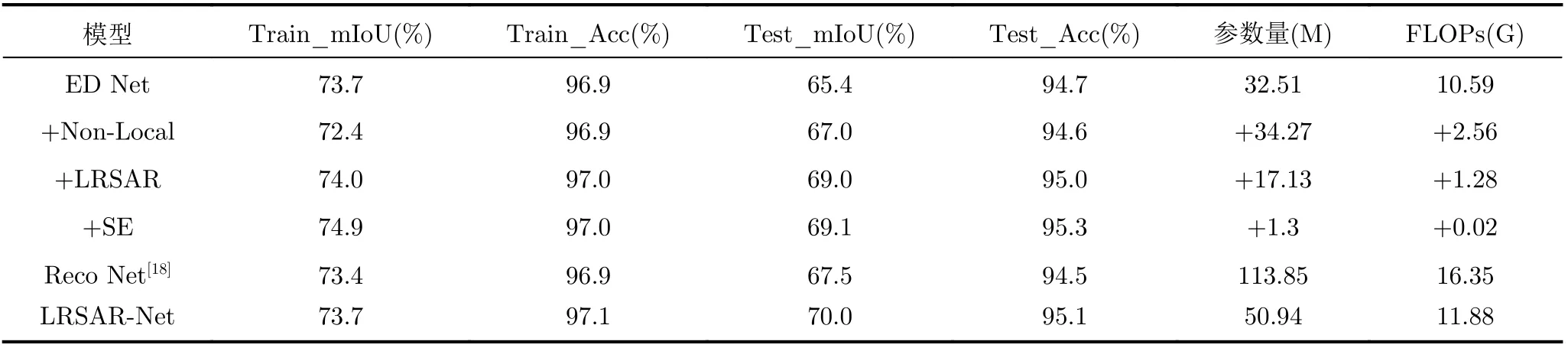
表2 注意力模块的影响
3.3 对比分析
为了对比不同的主干网络特征提取对模型的影响,对比了不同的特征提取网络之间的准确率。从表3可以发现InceptionV4网络的分割效果最好,测试集mIoU最高为70.9%,测试集准确度Acc最高为95.5%,但是网络的参数量和FLOPs也最大。MobileNetV2网络的参数量和FLOPs都比较低,但是网络的准确度也是最低的。ResNet50网络的准确度仅次于InceptionV4,但是参数量和FLOPs都远低于InceptionV4。综合考虑网络的参数量和时间复杂度,本实验选择ResNet50作为特征提取网络。

表3 不同的特征提取网络的模型对比
为了验证本文LRSAR-Net模型的有效性,本实验与其他优秀的语义分割网络比较了在新冠肺炎数据集上的准确度。UNet是标准的编码解码结构,并且使用了跳跃连接来增强模型的性能,但是UNet模型的测试集mIoU最低。UNet++网络在UNet的基础上采用了更加灵活的跳跃连接结构,实现了更丰富的特征信息融合,同时参数量和FLOPs最大。所表4所示,UNet++网络的分割效果提升不明显,mIoU和Acc仅比U-Net高0.7%和0.2%。DeepLabV3网络使用了空洞卷积金字塔,用来扩大卷积核的感受野并提取多尺度的特征信息。该网络的参数量和时间复杂度FLOPs都比较大,分割效果与UNet++相接近。DeepLabV3+网络对DeepLabV3的解码结构进行了改进,使得模型细化效果更好,参数量和FLOPs显著降低。PSPNet使用了金字塔池化模块来提取多尺度信息,网络的分割效果仅次于LRSAR-Net。虽然PSPNet的参数量和FLOPs比较低,但是该网络在训练过程中占用内存比较大,不适合快速图片分割。本文提出的LRSAR-Net网络的mIoU和Acc都要比其他分割模型好,mIoU比UNet网络提升了4.6%,精确度Acc也提升了0.4%。
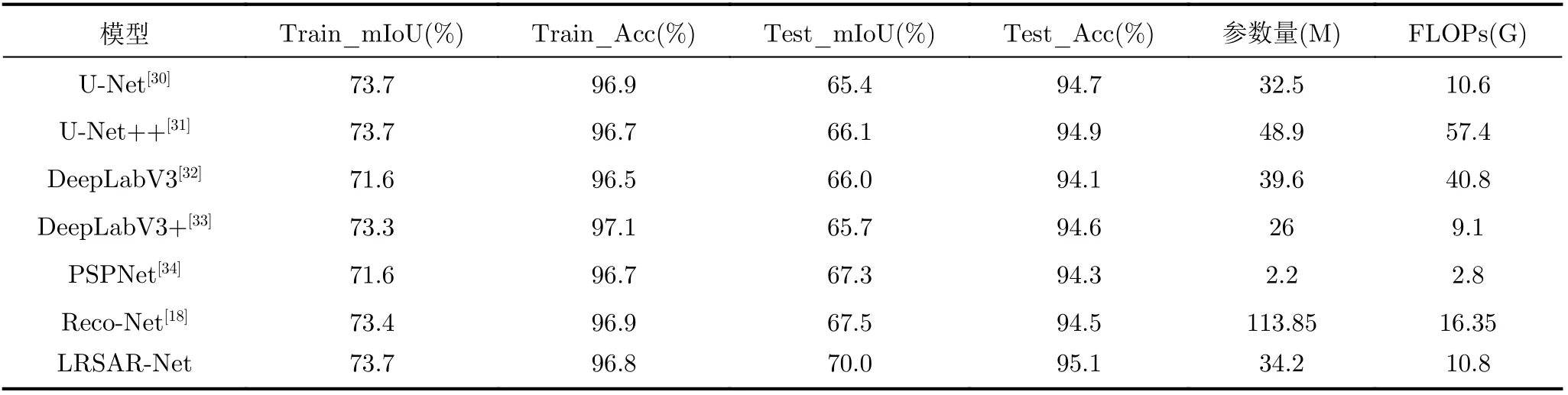
表4 不同的语义分割网络之间的对比
图9展示了LRSAR-Net在新冠肺炎数据集上的分割效果,第1行为原始图片,其他行依次为毛玻璃、病变、胸腔积液和背景的分割结果。从图9可以发现毛玻璃和病变的样本比较少,在网络训练过程中本文改变了交叉熵损失函数的权重,来解决类别不平衡的问题。在数据集中,毛玻璃和病变两个类型比较重要并且在图像中占比较小,所以本文提升了两种疾病的权重,降低了背景类的权重。4个类别毛玻璃、病变、胸腔积液和背景的权重比为1∶1∶0.5∶0.2。网络可以很好地分割出这两种肺部疾病类型。胸腔积液和背景类占比较大,网络可以分割出清晰的轮廓和类别。本文提出的LRSARNet网络的分割效果可以帮助医生对新冠患者的病情进行诊断和分析,也可以实现计算机自动的病情分析。

图9 实验分割结果
4 结论
本文提出了一种基于低秩张量自注意力重构的语义分割网络LRSAR-Net来对新冠肺炎患者的CT图像进行分割。其中,低秩张量自注意力重构模块用来获取长范围的语义信息,与经典的自注意力模块Non-Local相比,参数和时间复杂度降低了50%。为了更好地获取通道权重信息,网络在上采样过程中添加了通道注意力来增强网络的学习能力。为了验证网络的有效性,分别对比了不同的特征提取网络和其他优秀的语义分割网络,LRSARNet网络的效果比其他语义分割模型效果要好。实验结果证明,低秩张量自注意力重构模块LRSAR Block可以获得长范围的语义信息有助于新冠肺炎患病情况进行监测。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
西南师范大学学报(自然科学版)(2022年1期)2022-03-02
华南师范大学学报(自然科学版)(2021年3期)2021-07-03
五邑大学学报(自然科学版)(2020年4期)2020-12-09
杭州电子科技大学学报(自然科学版)(2020年1期)2020-04-09
开放教育研究(2020年2期)2020-03-31
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
中国惯性技术学报(2019年6期)2019-03-04
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
长江学术(2016年4期)2016-03-11
