
基于HAGA 的D2D-NOMA 资源分配优化算法
2022-02-24 05:07宋勇春王茜竹高正念
计算机工程 2022年2期
宋勇春,王茜竹,高正念
(1.重庆邮电大学 电子信息与网络工程研究院,重庆 400065;2.新一代信息网络与终端协同创新中心,重庆 400065)
0 概述
根据思科数据显示,预计到2022 年,全球每月数据流量将达到77 艾字节[1]。移动数据流量需求呈指数级增长,将导致当前无线网络的带宽资源匮乏以及基站严重过载。为缓解上述问题,D2D(Deviceto-Device)技术应运而生,该技术允许邻近设备在没有基站的辅助下进行数据交换[2],在短距离通信场景中可以大幅提升设备之间的信道增益,降低通信时延及终端发射功率并延长终端待机时间[3]。此外,通过复用蜂窝用户的信道进行通信,能够有效提高无线资源的利用率[4]。D2D 技术的引入使得无线通信网络的运行更加灵活高效,但是,基于传统的正交多址接入(Orthogonal Multiple Access,OMA)方式的D2D 通信,一个资源块只允许一个D2D 用户通信,无线资源并未得到充分利用[5]。
在非正交多址接入(Non-Orthogonal MultipleAccess,NOMA)技术中,接收端利用连续干扰消除(Serial Interference Cancellation,SIC)技术对发送的叠加信号进行解调[6],实现了多用户功率域的复用,从而大幅提高了系统吞吐量和频谱效率,因此,NOMA 被视为5G最有前景的候选技术之一[7]。文献[8]分析表明,将NOMA 技术应用于D2D 通信场景能较好地提高D2D系统的吞吐量,但其所带来的链路干扰问题不可忽略,且引入功率域复用后,同一个子载波被多个用户共用,使得该场景下的资源分配变得更加复杂,为解决该问题,需要合理优化信道与功率分配。
目前,对基于NOMA 的D2D 通信场景资源分配问题的研究已经取得较多成果。文献[9]在保证蜂窝用户服务质量(QoS)的条件下,提出一种逐步迭代算法,从而求解资源分配问题的次优解并实现D2D 用户对的速率最大化。文献[10]基于随机固定功率分配系数,研究一种求解子信道匹配问题的低复杂度算法,采用SCA(Successive Convex Approximation)迭代获得次优功率分配方案,从而最大化系统总速率。文献[11]研究一种联合子信道分配、用户配对、功率控制的资源分配方案,以最小化传输功率。文献[12]在多个蜂窝用户以NOMA 方式通信时,保证其SIC 解调顺序时的蜂窝用户功率,通过对偶迭代给D2D 用户分配合适资源,实现D2D 用户对的总速率最大化。文献[13]研究一种联合信道分配与功率分配的资源分配方案,基于一对一的双边匹配解决资源匹配问题,并利用拉格朗日乘子法求解最优功率分配系数。文献[14]以能效最大化和时延最小化为目标,提出一种基于多对一匹配进行子载波分配的方案,使用拉格朗日函数求得功率分配方案。文献[15]构建一种基于纳什均衡的模型,考虑NOMA 用户不同程度的干扰,从而最大化每个参与者的自身利益。但是,传统优化算法在解决此类NP 问题时计算复杂,而启发式算法鲁棒性高、容易实现、复杂度低,因此,其在最优化算法领域被广泛应用,且越来越多的学者将其用于资源分配任务。文献[16]以最大化D2D 通信性能为目标,提出一种基于DDM(Decoupled Direct Method)的优化框架,并利用DE(Differential Evolution)启发式算法进行求解。文献[17]提出一种基于GA(Genetic Algorithm)的资源分配方法,以最大化D2D 系统的总吞吐量。
启发式算法在很大程度上依赖于控制参数的选取,且存在搜索早熟、搜索慢等问题,使其难以跳出局部最优解,算法收敛时间长。针对传统遗传算法的不足,本文结合惩罚函数法与爬山算法对其进行改进,并提出一种基于HAGA(Hill-climbing Adaptive Genetic Algorithm)的优化算法,以最大化D2D-NOMA系统的吞吐量。具体地,本文建立一种基于NOMA的D2D 通信资源分配模型。在满足不同用户QoS、D2D 用户发射功率及信道分配约束下,最大化D2D系统吞吐量。针对资源分配问题,提出一种基于HAGA 的优化算法。利用惩罚函数法将原约束优化问题转化为无约束优化问题,并采用自适应惩罚系数优化解空间。在此基础上,对信道匹配标识和功率分配因子进行染色体编码、自适应交叉、自适应变异,以生成候选种群,然后利用爬山算法对候选种群进行二次搜索,避免优势个体丢失并加快收敛速度,从而得到全局最优解。
1 系统模型与问题描述
本文考虑单小区上行链路传输场景,假设基站可以获得所有用户的信道信息,且每一个蜂窝用户占用一个子信道,各子信道间相互正交互不干扰。在D2D 组内采用非正交多址接入方式进行下行通信,D2D 组内发射用户向接收用户发送叠加信号,系统模型如图1 所示。单小区包含一个基站、N个蜂窝用户和M组D2D 用户,每个D2D 组有一个发射用户和K个接收用户,接收用户随机分布在以发射用户为圆心、d为半径的圆中。本文假设每个D2D 组内的接收用户数相等,且每个D2D 组仅允许复用一个蜂窝用户信道,而同一个信道可以被多个D2D 组复用。因此,在同一个信道上,D2D 接收用户会受到蜂窝用户、同一组内其他接收用户以及复用同一信道的不同D2D 组发射用户的干扰。
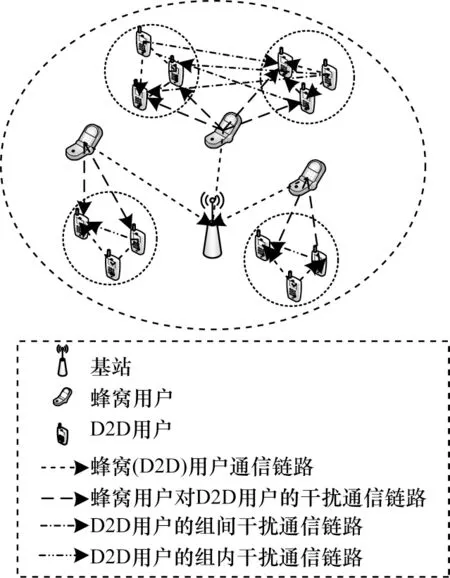
图1 系统模型Fig.1 System model
在本文系统中,假设集合C={c1,c2,…,cn,…,cN}表示蜂窝用户集合,其中cn表示蜂窝用户n,集合D={D1,D2,…,Dm,…,DM}表示M个D2D组的所有接收用 户,其中Dm={dm1,dm2,…,dmk,…,dmK}为 组m内K个接收用户。同时,假设蜂窝用户的发射功率均为PC,每个D2D 组内发射用户的发射总功率均为PD。蜂窝用户n与基站之间的信道增益表示为hcn,B,发射用户m与基站之间的信道增益表示为hm,B,cn与dmk之间的信道增益表示为hcn,mk,组m内发射用户与接收用户k之间的信道增益表示为hm,mk。不失一般性,假设|hm,m1|2≤|hm,m2|2≤…≤|hm,mk|2≤…≤|hm,mK|2,用表示信道匹配标识,为1 时表示D2D 组m复用蜂窝用户n的信道,为0 时表示不复用,用σ2表示用户接收到的高斯白噪声功率。
由模型分析可知,子信道n上基站接收到蜂窝用户的接收信噪比为:

假设D2D 组m复用cn信道进行数据传输,则用户dmk在子信道n上的接收信噪比为:
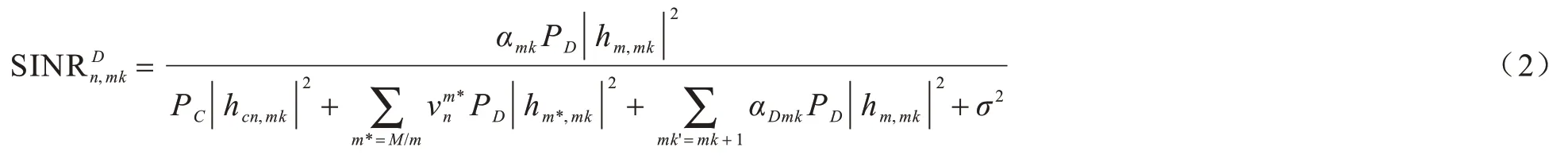
其中:αmk为组内接收用户k的功率分配系数。根据香农公式可知,第m个D2D 组在子信道n上的容量为:

因此,D2D 系统的总吞吐量为:

2 算法设计
2.1 优化问题构建
本文通过优化D2D 组信道匹配和组内用户在NOMA 方式下的功率分配,以最大化D2D 通信系统的吞吐量,目标优化问题建模为P1:

2.2 基于HAGA 的资源分配策略
考虑到目标函数的NP 难解性,使用传统方法不易处理,而遗传算法可以很好地解决此类NP 问题,该类算法具有良好的全局搜索能力,但是,遗传算法未有效利用反馈信息,导致搜索速度较慢,在解决大规模计算问题时容易陷入“早熟”,且其解依赖于参数的选择。基于此,本文利用自适应惩罚函数法改进传统遗传算法的适应度函数,同时采用基于爬山策略的自适应遗传算法提升全局搜索性能并加快收敛速度。本文算法由染色体编码、适应度计算、种群选择、交叉重组、染色体变异、爬山再搜索这6 个部分组成,算法流程如图2 所示。
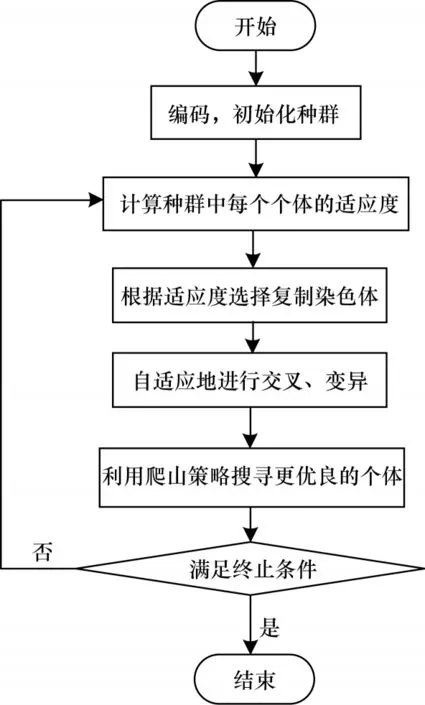
图2 本文算法流程Fig.2 The procedure of algorithm in this paper
2.3 基于HAGA 的信道匹配求解
假设每个D2D 组中功率分配系数为固定值,用αmk*表示,则原目标函数转化为P2:

本文算法具体步骤如下:
1)染色体编码。为了缩短染色体长度,加快算法收敛,并尽可能减少适应度计算过程中的约束条件,本文采取实值编码方式。D2D 组信道匹配染色体编码如下:

其中:vm(1≤vm≤N,1≤m≤M)的值对应其复用的子信道序号,如V=[2,1,…,2]中值一样的表示复用同一个信道。
2)适应度计算。本文优化模型是带约束的最大化吞吐量模型,因此,需要将约束优化问题转化为无约束优化问题,而惩罚函数法是遗传算法中处理约束条件最常用的一种方法,本文引用外点惩罚法对目标函数进行处理,如下:

为了提高算法的鲁棒性及搜索能力,本文参考文献[18]对传统惩罚函数进行改进。考虑到在优化早期种群中可行解数量较少,此时惩罚系数应较高,随着种群的进化,种群中产生的可行解增多,惩罚系数则应减小,当种群中全部是可行解时,惩罚系数应减小到0。因此,本文将惩罚系数表示为:

其中:α为当前个体不满足约束条件的个数;ρ为可行解比例,取值为(0,1]之间的实数,当ρ趋近于0 时表示当前种群几乎没有可行解,当ρ=1 时表示当前种群全为可行解。则当前个体的惩罚项表示为:

3)种群选择。本文使用轮盘赌选择方式,通过计算个体被选择的概率(即该个体的适应度f与当前种群的适应度之和),对每一代种群个体进行概率性的有放回选取,便于后续优化。因此,具体的选择概率Psel可以表示为:

4)交叉重组。本文针对取值为二进制整数的信道匹配标识,采取单点交叉法,通过随机产生的交叉位点选取2 个父代个体染色体的基因进行交换组合,以产生新的个体。自适应交叉概率Pcro为:
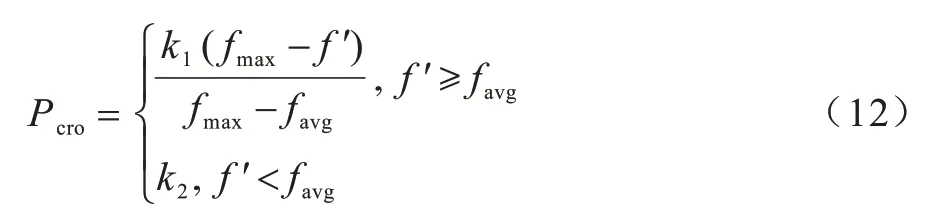
5)染色体变异。本文针对取值为整数的信道匹配标识,采取整数值突变算法,通过对子代个体随机产生的变异位点,变异染色体上的某些基因从而生成新个体。具体的自适应变异概率Pmut为:

其中:favg为当前种群平均适应度;fmax为当前种群最大适应度;f′为2 个交叉父代个体中较大的适应度;f为变异个体的适应度;k1、k2、k3、k4为[0,1]区间的常数。当种群内个体适应度较高时,为了使好基因尽可能保留到下一代,应使交叉概率和变异概率减小;当种群内个体适应度较低时,应使基因尽可能淘汰,因此交叉概率和变异概率应增加。通常在进化初期,种群的多样性较高,可适当增大其交叉概率,减小变异概率;在进化后期,种群多样性降低,应适当减小其交叉概率,增大变异概率[19]。
6)新种群的再次进化。为了进一步加快算法的收敛速度并提升搜索性能,本文使用爬山算法避免遍历搜索以快速找到局部最优解。采用爬山算法对新种群的个体进行二次搜索[20],选取选择、交叉过后的候选种群中适应度较高的优良个体,作为爬山算法的搜索空间,在完成变异操作后利用爬山算法对新个体进行再次搜索,若搜索空间的个体适应度函数值优于变异个体,则用其更新当前变异后的候选种群,否则将其舍弃。将经过爬山算法的种群作为新种群,进入适应度计算步骤。
2.4 功率分配问题求解
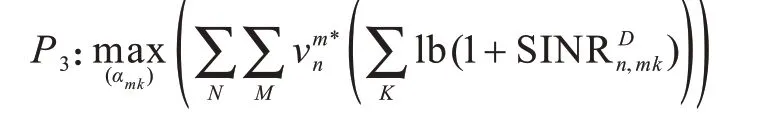
由于已经确认信道匹配方案,且正交发射用户的总功率固定,因此各子信道上的D2D 组功率分配系数可单独求解,原目标函数转换为P4:

与信道匹配模型相同,本文在功率分配问题求解时同样使用HAGA 算法,染色体编码同样采取实值编码;与信道匹配模型不同,该部分实值为连续值,处理如下:
1)染色体编码:
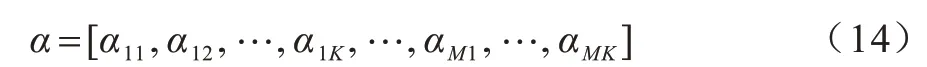
其中:功率分配系数αmk∈(0,1)。
2)适应度计算同样基于惩罚函数得到:

3)种群选择使用轮盘赌选择方式,选择概率为Psel。
4)交叉重组使用两点交叉法,且限制2 个交叉点的选择个数为K的倍数,以保证基因的片段性,交叉概率同样采用自适应交叉概率Pcro。
5)染色体变异:由于功率分配因子是(0,1)之间的连续变量,因此本文采用高斯变异法进行基因变异,变异概率同样采用自适应变异概率Pmut。
6)新种群的再次进化采取与信道匹配相同的基于爬山策略的二次搜索算法。
3 仿真与性能分析
3.1 仿真参数
对本文所提算法的信道匹配与功率分配性能进行仿真,并分析不同的D2D组数和D2D组发射功率对D2D系统总吞吐量、D2D 系统总能效的影响。仿真场景假设某小区基站覆盖范围为500 m,小区内随机均匀分布若干蜂窝用户及若干D2D 组,每个D2D 组内以D2D 发射用户为圆心、以50 m为半径,随机均匀分布2个或2个以上的D2D 接收用户。本文信道模型为基于路径损耗的信道模型,具体仿真参数如表1 所示,仿真取最优值作为该组参数对应的仿真结果。

表1 仿真参数设置Table 1 Simulation parameters setting
3.2 算法复杂度分析
针对信道匹配部分,该算法的计算复杂度取决于适应度计算,设O(f)为适应度计算的复杂度,每次迭代时种群进化具有随机性,将进化与爬山复杂度设为O(l),此外该算法的复杂度还取决于进化次数T与种群大小Q,则算法的复杂度为O(T(O(f)+O(l))+Q);针对功率分配部分,算法复杂度同理,但由于功率分配部分染色体长度是信道匹配的2 倍,因此其运行时间更长。
3.3 结果分析
本文首先对算法的收敛性能进行测试,需要注意的是,遗传算法受到很多因素影响,如初始种群的多样性、交叉机制、变异机制等,此外算法的收敛速度取决于种群的大小以及染色体的长度,如果种群较大或染色体较长,则收敛较慢。
在固定功率分配方案时,以信道匹配和最大化D2D 系统吞吐量为优化目标,将GA、AGA、HAGA(本文算法)这3 种算法运用于本文场景时的搜索及收敛性能比较如图3 所示。
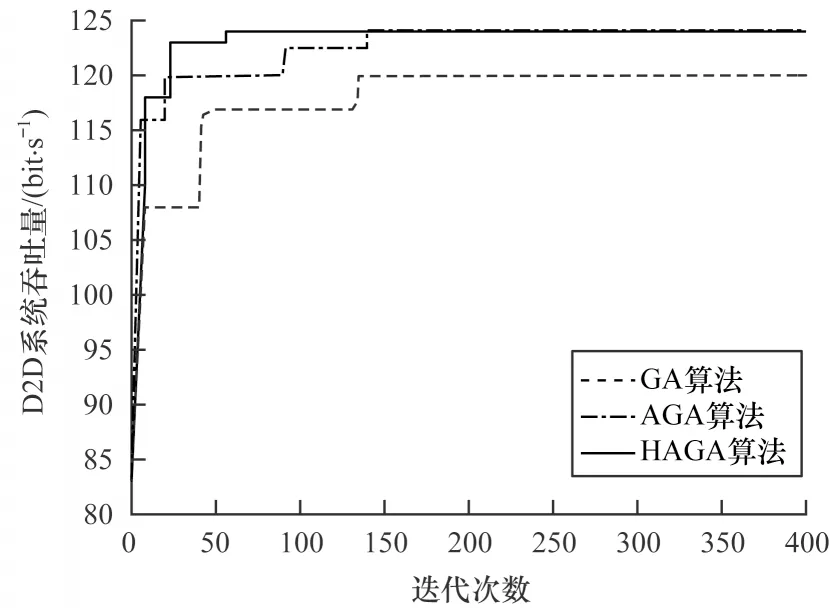
图3 固定功率分配方案下的D2D 系统吞吐量对比Fig.3 Comparison of D2D system throughput under fixed power allocation scheme
基于图3 所得的信道匹配方案,以D2D 组内功率分配因子作为优化变量、最大化D2D 系统吞吐量为优化目标,将GA、AGA、HAGA 这3 种算法应用于功率分配任务时的搜索及收敛性能比较如图4所示。

图4 固定信道匹配方案下的D2D 系统吞吐量对比Fig.4 Comparison of D2D system throughput under fixed channel matching scheme
从图3 可以看出,HAGA 大约在60 次收敛,从图4 可以看 出,HAGA 大约在160 次收敛。HAGA 的收敛、搜索性能优于AGA 和GA,这是因为相较于GA,HAGA 与AGA 在交叉与变异概率自适应处理后更容易跳出局部最优值,找到全局最优值,同时,HAGA 算法收敛性能优于AGA 与GA,这是因为在每次选择、交叉、变异后的种群中引入爬山算法,会进一步搜寻更优的种群作为下一次迭代的初始种群,使得优胜劣汰的速度加快。因此,HAGA 算法在全局搜索和收敛性能上都有一定提升。
图5所示为蜂窝用户数量一定时不同D2D 组数下D2D 系统吞吐量的对比结果。从图5 可以看出,随着D2D 组数的增加,D2D 系统吞吐量增大,且HAGA 算法性能最优。此外,将本文算法用于NOMA 技术所获得的D2D 系统吞吐量大于传统OMA 技术,这是因为传统OMA 技术只允许一个子信道复用一个用户,而NOMA 技术允许多个用户同时复用在相同的时频资源上,因此,随着D2D 用户组数的增加,系统吞吐量增大。

图5 不同D2D 组数下的D2D 系统吞吐量对比Fig.5 Comparison of D2D system throughput under different D2D groups
图6 所示为蜂窝用户与D2D 组数固定、D2D 组发射用户发射功率不同时的D2D 系统吞吐量对比,从图6 可以看出,HAGA 性能更优,且随着D2D 用户发射功率的提高,D2D 系统性能呈上升趋势,相较于OMA 技术,基于NOMA 技术的D2D 系统性能更优。

图6 不同D2D 用户发射功率下的D2D 系统吞吐量对比Fig.6 Comparison of D2D system throughput under different D2D user transmission power
4 结束语
本文提出一种基于HAGA 的无线资源分配算法,以在蜂窝用户与D2D 用户不同的QoS 约束条件下,优化D2D 组信道匹配和功率分配因子,最大化D2D 系统总吞吐量。考虑到优化目标函数包含二进制整数变量信道匹配因子及连续变量功率分配因子,求解难度较高,本文利用HAGA 算法进行全局搜索以寻找最优信道匹配方案,然后基于所得信道匹配方案对D2D 组内用户功率分配因子进行优化。仿真结果表明,该算法的收敛与搜索性能优于GA、AGA 算法,其能够有效提升D2D 通信系统的吞吐量。但是,在实际的D2D-NOMA 系统中,由于存在时延等问题,导致难以获取完美信道状态信息,下一步将基于不完美信道状态信息对D2D-NOMA 场景展开研究。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
包装学报(2022年2期)2022-05-13
现代装饰(2021年1期)2021-03-29
郑州大学学报(工学版)(2018年2期)2018-04-13
知识就是力量(2018年3期)2018-03-08
集装箱化(2017年4期)2017-05-17
集装箱化(2016年11期)2017-03-29
集装箱化(2016年12期)2017-03-20
集装箱化(2014年2期)2014-03-15
舰船电子工程(2010年1期)2010-04-26
