
基于历史查询概率的K-匿名哑元位置选取算法
2022-02-24 05:06胡晓辉杜永文
计算机工程 2022年2期
杨 洋,胡晓辉,杜永文
(兰州交通大学电子与信息工程学院,兰州 730070)
0 概述
随着物联网和移动定位技术的发展,基于位置的服务(Location Based Service,LBS)被广泛应用于导航、查找附近的服务、接收基于位置的广告等领域[1-2]。用户使用基于位置的应用向不可信的LBS服务器发送包含用户的地理位置信息、兴趣点等内容的服务请求,LBS 服务器根据用户发送的服务请求为用户提供基于位置的服务[3]。用户提供的位置越精确,获得的服务质量越高;位置越模糊,服务质量越低[5]。如果不可信的服务提供商掌握用户的真实位置信息,与用户相关联的个人信息会进一步泄露,如家庭住址、社会关系等。
针对位置隐私保护中存在的问题,研究人员提出多种解决方案[6],其中,最常用的位置隐私保护技术是基于历史查询概率的K-匿名技术[8-9]。K-匿名技术最早出现在数据库领域,对于准标识符属性,任意一条记录无法与至少k-1 条记录区分[11]。哑元位置是一种与用户位置极相似的虚假查询位置,普遍采用K-匿名集的方式。K-匿名集技术的原理是将用户的真实位置与K-1 个哑元位置组合形成包含k个位置的匿名集[12]。用户使用匿名集代替真实位置发起查询,LBS 提供商响应查询并返回每个查询位置需要的服务列表,用户则根据其真实位置筛选查询结果,获取属于自己的服务[14]。
哑元位置作为位置泛化的重要方法,具有部署简单且不影响服务质量的优点[15]。现有的哑元选取方案都聚焦在如何能合理有效地选取哑元位置以防止攻击者从匿名集中获取用户的真实位置[16]。攻击者如果获取了用户位置相关的边信息并过滤一些不合理哑元,例如位于湖泊、海洋、沙漠等特殊的地理位置的哑元,则能够大幅增加攻击者获取用户真实位置的概率,降低匿名集的隐私级别。针对此类问题,文献[16]提出虚假位置选择(Dummy Location Selection,DLS)算法,该算法通过将地图上位置单元的历史查询概率作为一种边信息划分用户的位置隐私等级,并使用位置熵选择合适的哑元位置构造K-匿名集。但是DLS 算法需要消耗大量的算力来选取具有最大熵值的匿名集,算法时间复杂度高,不适用于资源受限的物联网设备,同时算法也未考虑哑元位置的离散度问题。文献[17]通过分析DLS 算法存在的问题,设计了DLS 攻击(Attack for Dummy Location Selection,ADLS)算法,并验证ADLS 攻击算法的有效性,进而提出一种新的哑元选取DLP 算法,该算法具有较好的隐私保护效果,却忽略了历史查询概率为零的特殊位置情况。文献[18]根据DLP 算法提出改进的Enhanced-DLP 算法,引入增强型贪心算法,使其具有较高的匿名集生成效率和较强的隐私保护效果。文献[19]提出基于虚拟网格的GridDummy 算法和基于虚拟圆的CircleDummy 算法。这两种算法将K-匿名需要的K个位置全部用哑元位置代替,即提交的所有位置都不包含用户的真实位置,虽然提高了攻击者推测用户真实位置的难度,但是降低了服务质量,同时也未考虑到哑元匿名集的位置离散度问题,无法有效保证哑元位置在地理上均匀离散分布。
本文提出基于历史查询概率的K-匿名哑元位置选取算法,考虑用户历史查询概率为零的特殊情况,在保证用户位置信息不被泄露的同时,从地理分散度和零查询用户两个维度增强匿名集的隐私性,从而提高位置隐私保护的安全性。
1 相关理论
1.1 基本概念
本节主要介绍文中使用的相关概念。
1)位置查询概率
位置查询概率(Location Query Probability,LQP)将地图划分成N×N的网格,每个网格代表一个位置,单元,对于网格地图上的位置单元i均有一个对应的历史查询次数ni,地图上所有位置单元的查询次数总和为,则i位置单元的历史查询概率如式(1)所示:
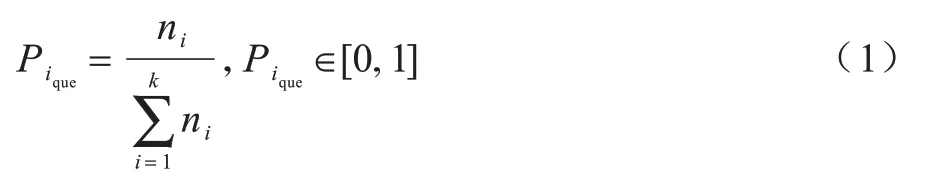
2)零查询用户
在网格化的地图位置单元中,历史查询概率为零的位置称为零查询位置。在零查询位置发起服务请求的用户称为零查询用户(Zero-Query Users,ZQU)。
3)用户最大偏移距离
用户u选取其位置附近的某个位置单元l′代替其真实位置l,l′称为l的偏移位置。位置偏移会造成用户服务质量的损失,用户服务质量由偏移位置与用户真实位置的数学期望表示。在用户可接受的最大服务质量损失时,用户与偏移位置的欧氏距离为用户最大位置偏移距离(User Maximum Offset Distance,UMOD),如式(2)、式(3)所示:
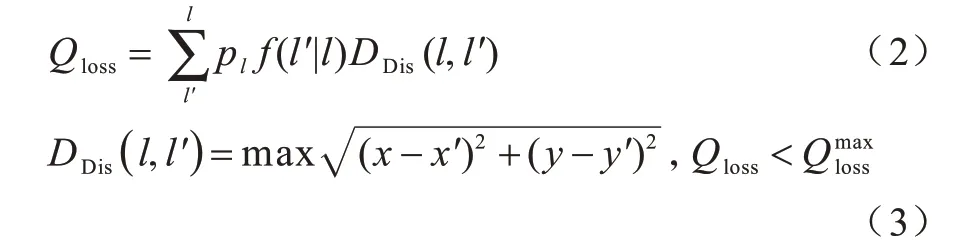
其中:pl为用户真实位置的历史查询概率;f(l′/l)为在用户位置l的情况下获得偏移位置l′的概率,位置隐私的保护算法需要保证Qloss<,因为超过该值时,所得到的位置服务请求结果就无法满足用户最低服务质量的要求。
1.2 LBS 架构
LBS 架构如图1所示。
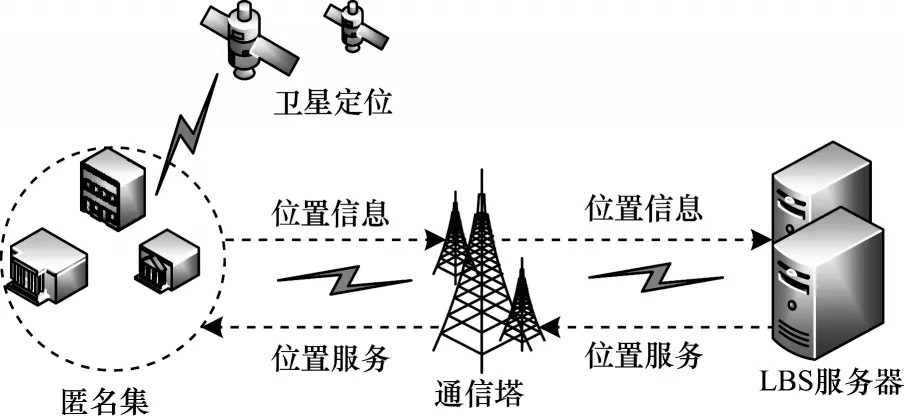
图1 LBS 架构Fig.1 Framework of LBS
LBS 架构主要包括GPS 卫星、具有定位功能和处理能力的终端、通信基站和位置服务提供商4 个部分。
1)GPS 卫星为移动终端提供当前的地理位置信息,位置隐私保护算法认为此过程是可靠的,默认在位置获取的过程中是安全的。
2)用户通过具有定位功能和处理能力的终端对请求服务的位置进行匿名保护,将用户的真实位置隐藏在哑元匿名集中发送至通信基站。
3)通信基站将接收到的服务请求发送至相应的LBS 提供商的服务器,通信基站只对用户的服务请求进行转发,不对服务请求进行修改。通信基站在收到服务器响应后将其转发至用户终端,不对响应信息进行修改。但在通信过程中,相关的信息可能会被恶意攻击者获取,故本阶段是不安全的。
4)服务位置服务器在收到用户的服务请求后,解析请求内容,产生匿名集所有位置的查询结果,然后通过通信基站将结果返回给用户。由于恶意的服务提供商可能会通过泄露用户的隐私信息来获取利益,攻击者也可以通过攻击服务器获取用户相关的隐私信息,故本阶段也是不安全的。
1.3 隐私度量
隐私度量主要有基于历史查询概率K-匿名的隐私度量、基于信息熵的隐私度量、位置离散度。
1)基于历史查询概率K-匿名的隐私度量
根据哑元选取方案得到的哑元匿名集为C,C={l1,l2,…,lk-1,lk},即|C|=k。攻击者从 匿名集中获取用户的真实位置概率Q,如式(4)所示:

2)基于信息熵的隐私度量
位置查询概率经过地图网格化处理以后,生成N×N个单元,从中选取包含用户真实位置在内的k个位置,根据位置单元的历史查询概率pi确定匿名集k中每个位置单元归一化后的查询概率qi如式(5)所示,熵值如式(6)所示:
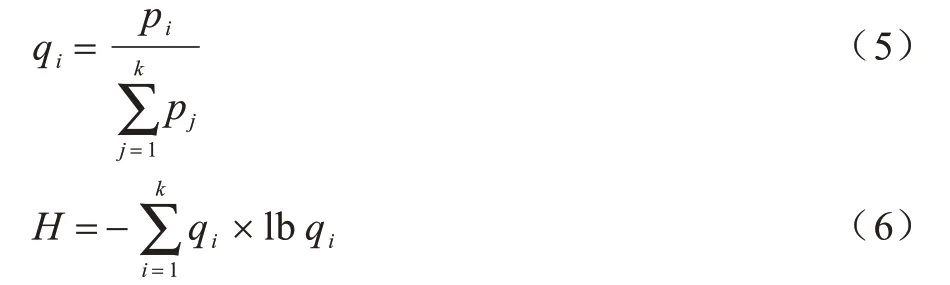
隐私度量使用信息熵来度量匿名集的隐私程度[19]。熵值越大,表示集合中元素的区分度越低,攻击者从匿名集中识别用户的真实位置概率就越小,匿名集的隐私级别就越高。匿名集中位置单元的历史查询概率越相似,熵值越大。当历史查询概率相等时,熵值取得最大值。
3)位置离散度
哑元匿名集的位置离散度(PPD)通过计算匿名集中所有位置单元之间的距离来获得,如式(7)所示:

PPD值越大,表示对于同一个位置数据集选取的哑元位置地理分布越离散,匿名集隐私效果越好;相反,哑元位置越聚集,越容易被攻击者缩小隐私区域,哑元匿名集隐私保护效果越差。
1.4 哑元位置选取
哑元位置选取方法的主要目的是使匿名用户选择合适的哑元位置构建K-匿名集,使得用户真实位置和其他K-1 个哑元位置无法区分,将地图网格化为5×5 的位置单元,根据每个网格的历史查询次数,计算各个位置单元的查询概率,用不同灰度代表位置单元查询概率的大小,颜色越深,历史查询概率越大,颜色越浅,历史查询概率越低,白色代表该位置单元的历史查询概率为零。
1.4.1 未充分考虑特殊查询概率位置单元
哑元K-匿名集经过地图网格化处理后存在零查询的位置单元。如果直接对零查询用户的位置单元进行哑元选取,则可能会生成含有多个零查询位置单元的匿名集。零查询位置单元在地理语义上可能是一些无人区、河流、沙漠等特殊位置。如果哑元匿名集含有这些特殊位置,则攻击者结合地理信息分析过滤这些特殊位置单元,从而降低哑元K-匿名集的规模。
5-匿名哑元位置选择如图2 所示,从图2 可以看出,右侧的数值代表对应位置的历史查询概率,位于新开发区的用户u1通过熵度量的算法取得匿名度K=5 的最佳隐私保护效果,需要选择4 个与其能形成最大熵值的位置单元{u2,u3,u4,u5}。获取该匿名集的攻击者通过分析相关位置信息可过滤{u3,u4,u5},用户的隐私泄露概率由1/5 增加到1/2,增加了隐私泄露的风险。
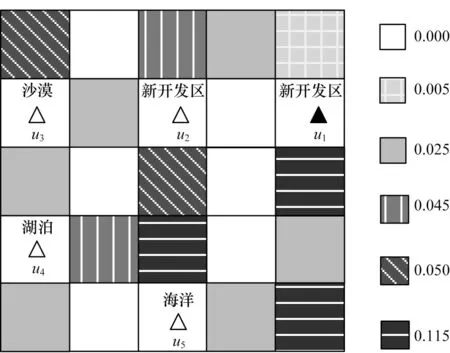
图2 5-匿名哑元位置选择Fig.2 Location selection of five-anonymous dummy
1.4.2 未充分考虑哑元位置离散度
由于一些基于历史查询概率进行哑元选取的算法没有考虑位置单元的地理分布情况。对于一个给定k匿名规模的哑元匿名集,构造哑元匿名集的位置离散度应该尽可能大。
3-匿名哑元位置选择如图3 所示。右侧数值代表对应位置的历史查询概率,位于新开发区的用户u1通过熵度量的算法取得匿名度K=3的最佳隐私保护效果,从与用户具有相同历史查询概率的{u2,u3,u4,u5,u6}中随机选择2 个位置单元,即pu1=pu2=pu3,构造位置匿名集C1={u1,u2,u3}。在地理上用户{u1,u2,u3}不是均匀离散分布,攻击者可以将匿名集划分成不同部分进行攻击,最坏的情况是攻击者第一次攻击就选择了用户所在的部分,识别用户的概率则由1/3 增加到1/2,增加了隐私泄露的风险。
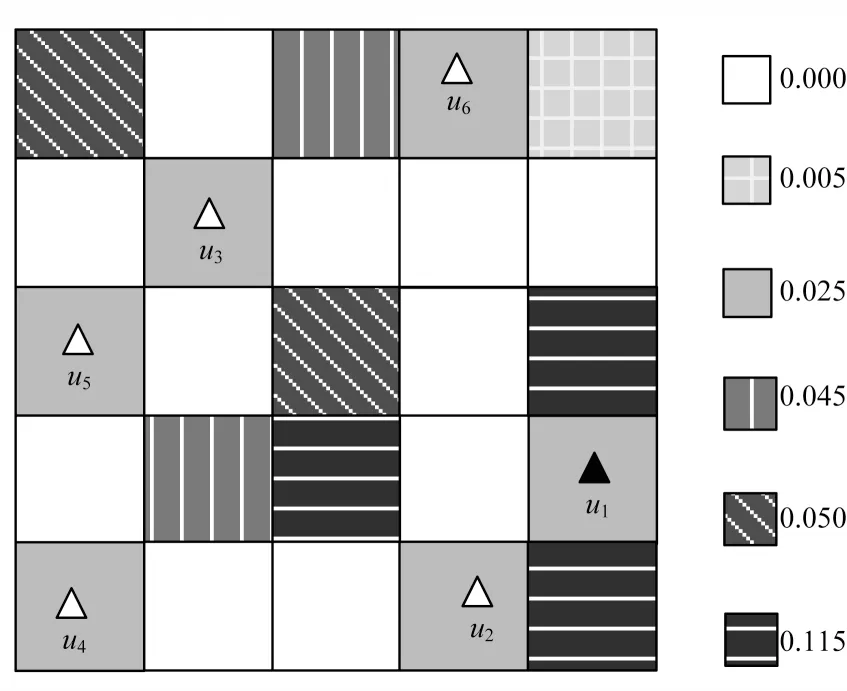
图3 3-匿名哑元位置选择Fig.3 Location selection of three-anonymous dummy
如果构造的匿名集过于聚集,且位于某个特定的区域,攻击者可以通过地图信息获取与用户相关的隐私信息。同一区域哑元位置如图4 所示,右侧数值代表对应位置的历史查询概率,根据3 个位置都处在大学可以推测出用户的身份信息和相关学校,进一步推测更多的隐私信息。
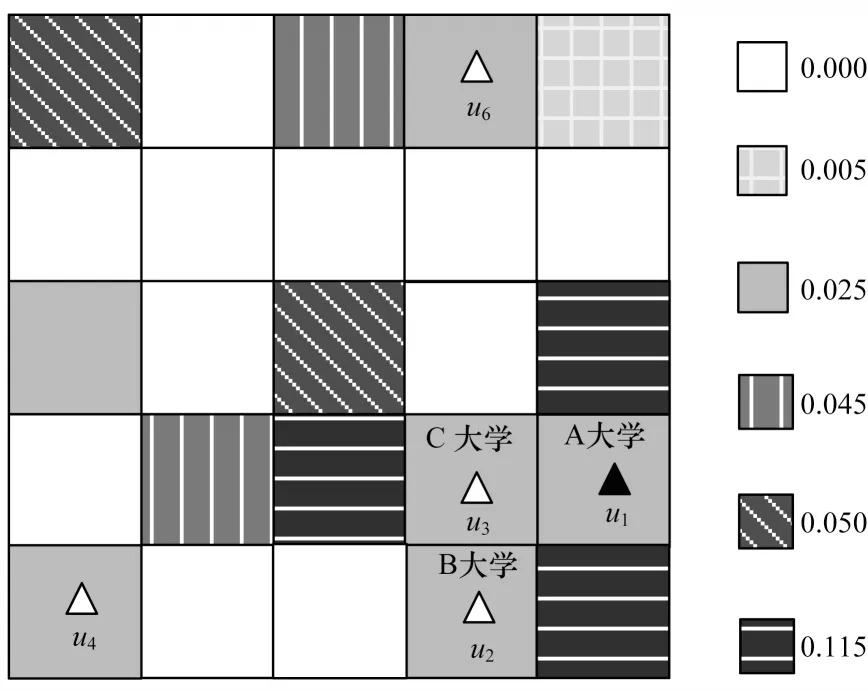
图4 同一区域哑元位置选择Fig.4 Dummy location selection in the same region
因此,单一考虑位置单元的历史查询概率通过熵度量的方式构造哑元匿名集,无法抵御攻击者针对零查询用户的特殊地理信息攻击,同时无法避免由于匿名集中的位置分布不均造成离散的哑元位置易被过滤的问题。为了保证匿名度K,本文在基于熵度量的哑元选取原则上,加入了对零查询概率以及位置离散度两个方面的考量,设计一种改进算法。
2 攻防模型
位置隐私保护算法的设计也需要加入对常用攻击模型的考量,基于相应的攻击方式设计保护算法的防御思路。
2.1 攻击方式
攻击方式主要有边信息攻击和位置同质攻击。
1)边信息攻击
在位置隐私领域,边信息与真实位置不直接相关联,但是攻击者能利用它们筛选出更有价值的位置服务数据,达到辅助攻击的效果[21]。边信息攻击[22]是指攻击者根据已知边信息筛除一些不合理位置,增加获取用户真实位置信息的概率。假设位置匿名度为K,当选择的K-1 个哑元位置中有多个哑元位置被攻击者过滤,则不满足K-匿名要求,降低隐私保护水平。
2)位置同质攻击
位置同质攻击[22]是指攻击者通过分析匿名集中的多个位置信息来缩小匿名区域。如果位置间非常接近,即使可以达到K匿名度,但是隐匿区域太小,攻击者就能获取相关的隐私信息;其次攻击者可以通过位置聚类的方法进行分类推理来增加推测用户真实位置的概率。
2.2 位置概率模型
对于含攻击者的位置隐私保护模型,隐私源为网格化地图的概率分布l,随机变量l的取值表示用户u的真实位置是网格化地图中某个哑元位置li,{l1,l2,…,lm}表示网格化的地图位置集。假设每个哑元位置对应的概率为pi,则l概率模型如式(8)所示:
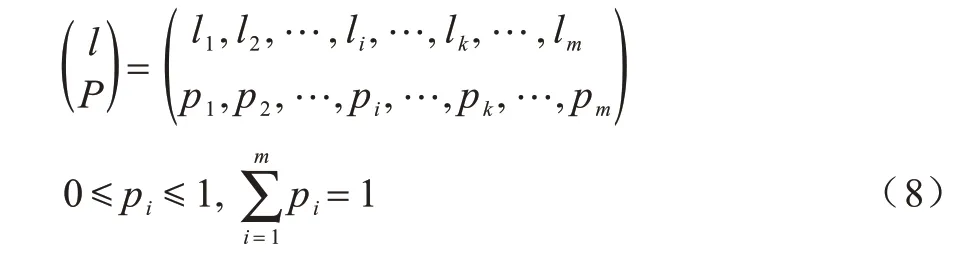
用户的真实位置分布信息是隐私信息,为了防止攻击者直接获取用户的真实位置信息,需要对用户的位置进行匿名处理,将用户的位置泛化成可被攻击者直接观察到的位置分布l′,则l′的概率模型如式(9)所示:
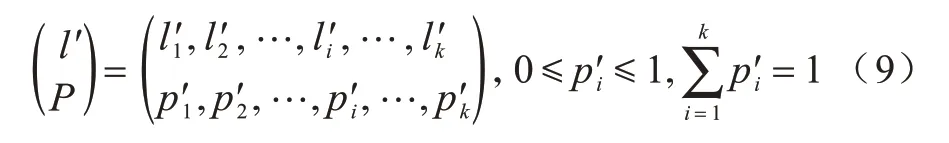
攻击者获得用户的可观察位置分布l'后,结合相关的边信息对用户u进行位置攻击,攻击者得到用户的推断位置分布表示攻击者推测的位置为用户真实位置的概率,^对应的概率模型如式(10)所示:
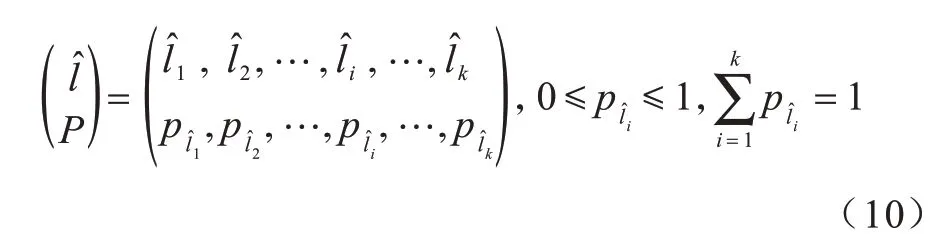
具有边信息攻击者的攻防模型结构如图5 所示。
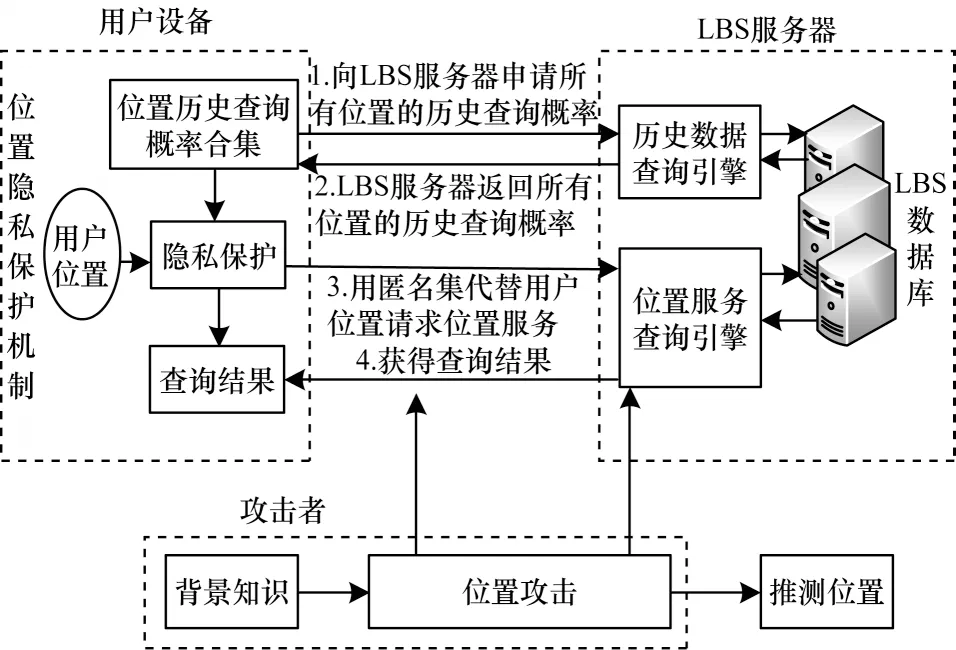
图5 攻防模型结构Fig.5 Structure of attack and defense model
3 本文算法设计
本文算法将位置隐私保护的用户分为两种类型:1)用户发起位置服务请求所在位置单元的历史查询概率为零的零查询用户,零查询用户在进行哑元位置匿名集构造之间,根据偏移算法进行位置偏移,选择合适的偏移位置;2)用户发起位置服务请求所在位置单元的历史查询概率不为零,通过此位置单元的历史查询概率构造匿名集,无论是零查询用户还是非零查询用户,最后的匿名集要保证哑元位置地理上尽可能的均匀离散分布,构造哑元匿名集形成匿名区域要尽可能大。
3.1 最优哑元匿名候选集算法
哑元选取算法的目标是保护用户的位置信息不被泄露。攻击者通过重构匿名集与用户匿名集最相似的位置单元作为用户的真实位置,从而获取用户隐私信息。
最优的哑元匿名候选集算法是基于熵度量考虑攻击者可能掌握边信息的情况下,根据输入网格化的数据集S,用户的真实位置l,以及隐私匿名度K,利用增强型贪心算法高效地选取哑元位置,最后构造具有最大熵值哑元匿名集。
算法1最优哑元匿名候选集算法


最优哑元匿名候选集Ch。
3.2 零查询用户位置偏移算法
零查询用户位置偏移算法主要针对零查询用户发起服务请求时,根据用户给定的位置偏移距离DDis(l,l′),选择合适的偏移位置l′代替用户的真实位置l。用户在进行请求时,通过最大服务质量损失,给定算法最大的位置偏移距离DDis(l,l′)。首 先算法根据用户给定的最大位置偏移距离,构造符合条件的偏移位置候选区C′;其次通过候选区构造候选偏移位置集,筛除候选集中历史查询概率为零的位置;最后随机在候选集中选择一个位置l'作为用户的替代位置,增加偏移位置的随机性。
算法2零查询用户位置偏移算法

3.3 K-匿名哑元位置选取算法
算法1 构造的匿名集虽具有最大的熵值,但其哑元位置的地理离散度没有得到保障。攻击者即使没有获取用户的真实位置,也能根据该区域相关信息推测用户的隐私信息。除此之外,哑元位置的选取在地理上如果出现明显的分类,也不利于隐私保护。
离散度最大哑元匿名集构造算法的目的是尽可能选取距离较远的位置单元,保证哑元匿名集的位置离散度尽可能高。在选取哑元位置的过程中,计算两个位置之间的距离实现位置离散分布和,但这种方法在某些情况下无法获得最优的离散度。离散哑元位置选取示意图如图6 所示。

图6 离散哑元位置选取示意图Fig.6 Schematic diagram of discrete dummy location selection
用户的位置为点B,当已经选择A作为哑元位置以后,选择C点和D点与A点、B点构成的哑元匿名集的熵值相同,如式(11)所示:
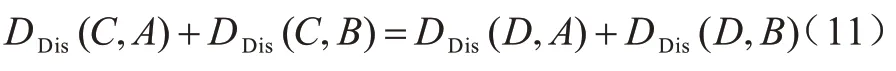
哑元位置的选取考虑到地理分布对于隐私的影响,选择D点优于选择C点加入哑元匿名集,如式(12)所示:
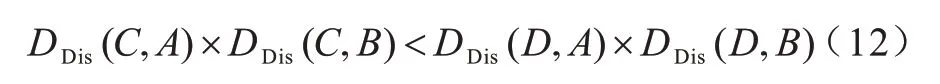
所以相对于选择两个位置的距离和,本文算法选择距离积作为构造匿名集的哑元选取方法。
本文构造离散度最大哑元匿名集Clist={l1,l2,…,lk},描述为一个多目标优化问题,如式(13)所示:
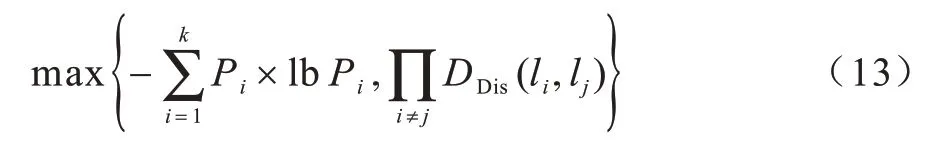
其中:Pi、Pj分别为li、lj对应的历史查询概率。由于哑元位置的选取同时满足上述两个目标非常困难,本文将上述问题分解成两个部分,首先根据熵度量构造具有最大熵值的最优的2K哑元匿名候选集Ch,如式(14)所示:
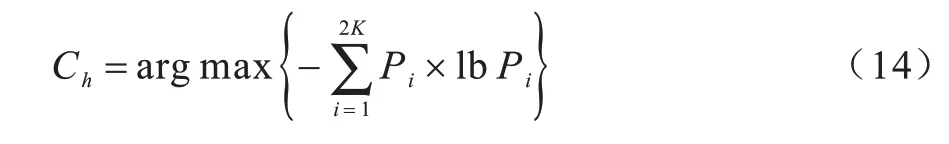
基于熵度量构造具有最大熵值的最优的2K哑元匿名候选集Ch,通过位置距离乘积选择K个最离散的哑元位置匿名集Clist,如式(15)所示:
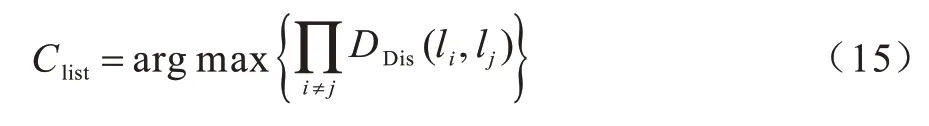
基于以上分析,本文首先根据用户的真实位置,综合使用算法1 和算法2。通过算法1 判断是否进行位置偏移,然后通过算法2 选择2K个具有最大熵值的匿名候选集,最后选择K个具有最大离散度的哑元匿名集,从而构建基于历史查询概率的哑元选取算法。
本文进行K个最大离散度哑元匿名集的构造时,首先将用户的真实位置或者偏移位置加入匿名集Clist,然后通过轮选择K-1 个哑元位置加入匿名集Clist。
针对每一轮,本文对于候选集Ch中所有的位置单元都要计算其到Clist所有位置的乘积,然后计算每个位置单元占候选集Ch中所有的位置单元到Clist所有位置乘积之和的比率,最后构造候选集对应的候选概率矩阵,根据概率矩阵中的概率选择一个哑元位置加入匿名集。
本文每选择一个哑元位置都要对应计算一个概率矩阵,经过K-1 轮形成包含K个用户的匿名集。在第一轮时,概率矩阵是通过候选集所有位置到用户位置的距离计算形成,其他轮则都是通过计算距离乘积。
算法3基于历史查询概率的K-匿名哑元选取算法


4 安全性分析
假设匿名集Clist中的匿名度为K,因此攻击者从匿名集中推测出用户偏移位置的概率为pex=1/K。设用户历史查询概率分布中的位置总数为n,攻击者通过偏移位置确定用户真实位置是可能发生的事件,但存在小概率函数o(n)使得攻击者确定用户的真实位置的概率为preal,满足preal≤o(n)。攻击者在获取用户的匿名集合Clist的情况下获得确切的用户位置信息的概率p=pexpreal≤o(n)×(1/K)。
攻击者根据已获得的地图信息和历史查询概率数据来推测哑元匿名集中用户的真实位置信息,本文算法能够有效应对此类进行攻击。在进行哑元位置的选取过程中,本文算法每次都选择与用户真实位置历史查询概率最相似或相等的位置单元作为哑元,即满足pi≈pj(其中i表示用户,j表示哑元,pi表示用户的历史查询概率,pj表示匿名集中任一哑元的历史查询概率),根据式(6)可知,哑元位置的历史查询概率越接近,熵值越大,匿名集的信息混乱程度越高。本文算法在选择哑元时,将考虑熵值和地理离散度较高的位置选为哑元位置。因此,本文算法生成的哑元匿名集能抵抗攻击者基于历史查询概率的位置同质攻击和边信息攻击,有效控制攻击者推测出用户真实位置的概率约为1/K。
5 仿真实验
为验证本文算法的有效性,本文设计一系列仿真实验。实验采用Python3.8 软件在PC 机(Windows10 操作系统,2.40 GHz Intel i7 CPU,12 GB 内存)上进行模拟仿真。数据集为北美路网NA 数据集,该数据集包含175 812个真实的位置记录,NA数据集分布如图7所示。实验将数据集网格化为100×100 的网格地图,用户的最大偏移距离均设置为2。
图7 NA 数据集分布Fig.7 Distribution of NA data set
5.1 离散度对比
离散度越大,哑元位置越分散。实验通过统计不同隐私度K下哑元匿名集位置单元的距离总和来衡量哑元匿名集的离散度。本文K-匿名哑元选取算法K-DLS、DLS算法、DLP算法、Enhanced_DLP 算法、Optimal 算法、CircleDummy 算法、GridDummy 算法在不同隐私度K下哑元匿名集的离散度对比如图8 所示。
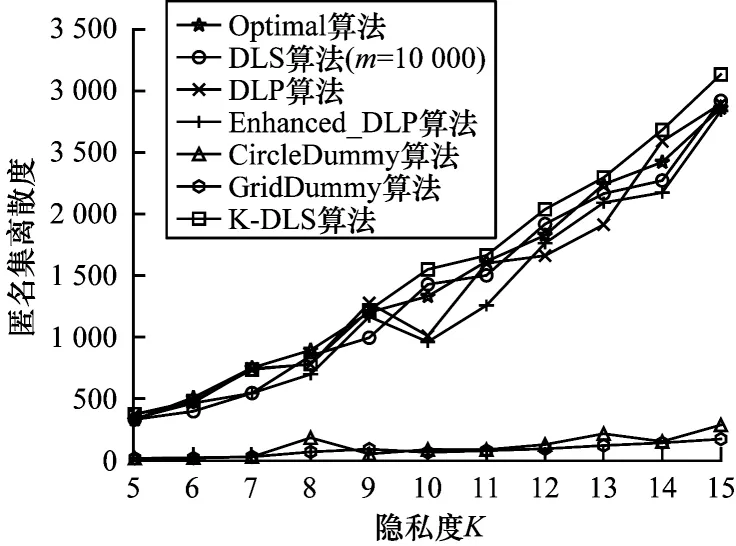
图8 不同算法的匿名集离散度对比Fig.8 Anonymity set dispersion comparison among different algorithms
从图8 可以看出,所有算法生成哑元匿名集的离散度都呈现上升趋势,在相同隐私度K下K-DLS算法构造的哑元匿名集离散度大于其他两种算法。随着K值增大,本文算法的匿名集离散度均高于其他算法。因为本文算法在选择哑元位置时,引入侯选位置集与哑元位置集所有位置元素距离乘积作为指标,通过位置概率候选矩阵选择哑元位置,每次都选择了能构成最大离散度的位置作为哑元,保障生成的哑元匿名集具有最大的离散度。
5.2 哑元匿名集生成效率对比
哑元匿名集的生成效率是通过CPU 的运行时间表示。为验证本文算法的哑元匿名集生成效率,K-DLS、DLP 和Enhanced_DLP 算法在不同隐私度K下生成时间对比如图9 所示。
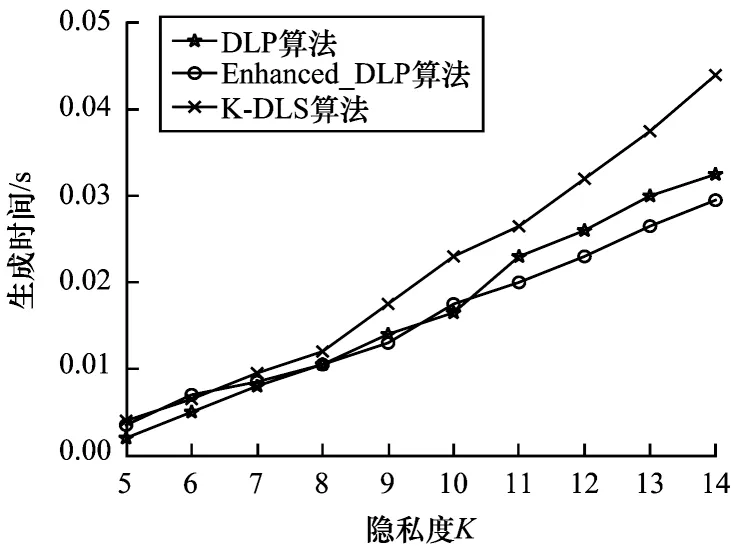
图9 隐私度K 与匿名集生成时间Fig.9 Privacy K and generation time of anonymity set
从图9 可以看出,本文算法在构造哑元匿名集时,需要验证用户的历史查询概率,同时进行离散选择,故其运行时间比DLP 和Enhanced_DLP 算法的运行时间略高。本文算法在保证取得最大熵值的情况下,考虑了哑元位置的地理离散性,哑元匿名集的生成效果整体较好。
5.3 隐私保护熵值对比
在LBS 的位置隐私保护方案中,位置熵可以衡量用户位置信息的不确定性,熵值越大表示哑元匿名集的隐私度越高。图10 表示本文K-匿名哑元选取算法K-DLS、DLS算法、DLP算法、enhanced_DLP算法、Optimal 算法、CircleDummy 算法、GridDummy 算法在不同隐私度K下生成哑元匿名集的熵值对比。
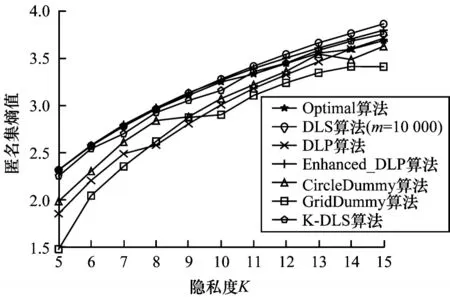
图10 不同隐私度K 对匿名集熵值影响Fig.10 The entropy of anonymity set versus different privacy K
从图10 可以看出,随着K值不断增大,7 种算法生成哑元匿名集的熵值整体呈现上升趋势。但是DLS、DLP、Enhanced_DLP、Optimal 和K-DLS 算法生成的熵值明显大于CircleDummy、GridDummy 算法。K-DLS算法在保证哑元匿名集离散度最大的情况下,匿名集熵值也取得了最优的效果,能够有效保证用户的隐私。
5.4 攻击算法识别概率对比
攻击者获得用户的哑元匿名集C后,结合相关的边信息对用户进行位置攻击,攻击者得到用户的推断位置分布,根据分布概率确定用户的真实位置。K-DLS、DLS、DLP 和Enhanced_DLP 算法在不同隐私度K下生成哑元匿名集的位置识别率对比如图11 所示,其中每个算法重复实验1 000 次。
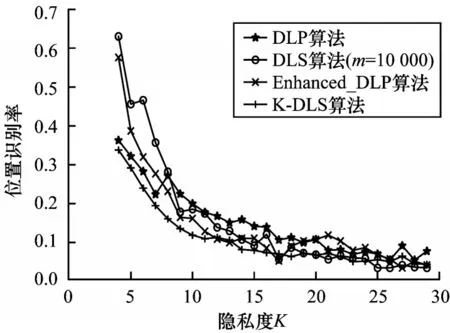
图11 不同隐私度K 对位置识别率的影响Fig.11 Location recognition probability versus different privacy K
从图11 可以看出,K-DLS 算法的位置识别率略低于其他算法,因为用户在进行位置隐私保护时,考察了历史查询概率为零的用户,对其进行位置偏移,随机在候选集中选择用户位置的偏移位置,增加匿名集的随机性;其次算法考量了位置离散度,生成哑元匿名集在地图上尽可能的均匀离散分布,攻击者很难通过位置聚类等特殊方法增加推测概率,能够有效提升用户位置的隐私保护效果。
6 结束语
本文分析现有位置隐私保护算法存在的不足,提出基于历史查询概率的K-匿名哑元位置选取算法。利用熵度量选择哑元位置,使得哑元匿名集熵值最大,并根据距离对匿名结果进行优化。仿真结果表明,与DLP、DLS 等算法相比,K-DLS 算法在保证匿名集离散度最大的情况下,匿名集熵值为最优,能够提高位置隐私保护的安全性。本文算法主要针对基于快照查询的LBS 服务位置隐私保护,下一步将对用户连续查询移动轨迹的位置隐私保护进行研究。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
中学生数理化·中考版(2022年6期)2022-06-05
中学生数理化·中考版(2021年6期)2021-11-22
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
五邑大学学报(自然科学版)(2019年3期)2019-09-06
江西教育B(2019年2期)2019-04-12
中国诗歌(2018年6期)2018-11-14
爱你·心灵读本(2018年6期)2018-09-10
爱你(2018年16期)2018-06-21
