
基于预训练语言模型的关键词感知问题生成
2022-02-24 05:06:30于尊瑞毛震东张勇东
计算机工程 2022年2期
于尊瑞,毛震东,王 泉,张勇东
(1.中国科学技术大学 信息科学技术学院,合肥 230000;2.北京百度网讯科技有限公司,北京 100000)
0 概述
随着自动对话机器人、电子客服、问答式智能搜索等技术的广泛应用,人与机器之间的交流变得越来越自然流畅,然而,计算机准确理解和使用自然语言的水平仍有待进一步提高。问题生成技术在对话机器人[1]、教育[2-4]、搜索[5]等领域具有重要的应用价值,例如:训练问答模型、智能搜索模型等系统需要大量的“段落-问题-答案”数据,人工标注数据需要耗费巨大的人力、物力以及财力,而互联网(如百度百科、新华网等)中拥有海量的无标注文本数据,利用问题生成技术可以从无标注的文本段落中生成海量的“段落-问题-答案”数据[6-8],从而完成自动问答系统训练[9]。因此,提升问题生成技术的性能具有重要的实用与科研价值。
早期的问题生成研究多数采用基于语法规则和模板的方法,将问题生成任务拆分为“问什么”和“怎么问”2 个子任务[10]。具体步骤为:利用语言学知识设计规则和模板,根据输入文本的语法结构等信息自动从文本中提取出所需要的内容,然后填入预先构建好的问题句模板中,形成问句[11-13]。然而,此类方法依赖既定规则,不能根据数据自适应不同的文本领域,迁移成本过高,难以被广泛应用。
随后,“序列到序列”编码器-解码器神经网络被广泛应用于问题生成任务。文献[4]利用“序列到序列”编码器-解码器神经网络模型,根据所给的一个句子生成问题,但其不能输入给定答案信息,导致适用范围受限。文献[14]将答案信息添加到输入中,根据给定的段落和答案实现问题生成。在文献[14]研究成果的基础上,针对问题生成任务所进行的模型设计取得发展,例如:文献[15]根据特定的疑问词捕捉答案中的关键信息;文献[16]采用复制机制、占位符机制和上下文单词嵌入机制等多种策略实现问题生成;文献[17-19]使用段落线索、问题类型、问题风格等信息作为辅助信息进行问题生成;文献[20-21]控制问题的提问角度和难度。在此之后,强化学习策略在该领域的应用也取得了进展,例如:文献[22]在生成对抗框架下增加潜在变量和观察变量;文献[23]在生成评价框架下将所生成问题的语义评分和语法结构评分作为奖励;文献[24]使用语义评分和问答系统评分作为奖励;文献[25-27]将问题生成任务和问答任务作为对偶任务进行联合训练。上述方法在问题生成任务中取得的性能提升,使得问题生成技术在构建大规模问答数据集等研究中得到广泛应用。
近年来,预训练语言模型(如BERT[28]、ERNIE[29]等)在多项自然语言理解任务中表现突出。预训练语言模型通过“预训练-微调”框架来实现:“预训练”是指在海量无标注文本数据上,通过多种任务预先训练好模型参数;“微调”是指针对特定的下游任务,调整模型结构并在标注数据上进行训练,从而完成特定下游任务。在预训练模型中添加自注意力掩码,将双向语言模型改造成序列到序列语言模型,可以实现生成任务。该方法在问题生成任务中的性能表现已经远超传统的序列到序列编码器-解码器神经网络。
然而,现有方法仍无法避免问题生成任务中长期存在的2 个问题:一是“误差累积”问题,每个问题都由很多个连续的词组成,生成时需要一个词接一个词地连续迭代生成,因为模型不具备纠正错误的能力,所以在该过程中一旦有一个词生成错误,后续的词会根据错误的词继续生成,误差将进一步扩大;二是“一对多”问题,给定一个文本段落和一个答案,文本段落中会蕴含多种多样的信息,人类可以提出多个问题,也可以判断出哪些问题更具价值,而对于模型而言,难以找到全局最优解,原因是逐个词地连续迭代生成倾向于找到局部最优解。
本文提出一种带有关键词感知的问题生成方法,用以克服问题生成过程中仅依赖局部最优解的不足,减少“误差累积”与“一对多”现象的发生,提升问题生成的质量。具体地,采用“两步走”的流水线式框架,基于预训练语言模型设计关键词分类网络结构和带有关键词信息感知的问题生成网络结构,
关键词分类模型从输入段落中提取关键词特征,在经过后处理之后将其作为全局信息融合到问题生成网络的输入中,最终完成问题生成过程。
1 问题生成任务定义
问题生成任务的定义是:给定一个文本段落C和一个答案A,答案A是文本段落C中的一部分连续文本,计算机根据段落C和答案A自动生成对应的问题Qˉ。问题生成数据示例如表1 所示。

表1 问题生成数据示例Table 1 Question generation data example
问题生成模型θ的目标是在生成问题时,使得数据集中真实的问题Q出现的概率尽量大,表示如下:
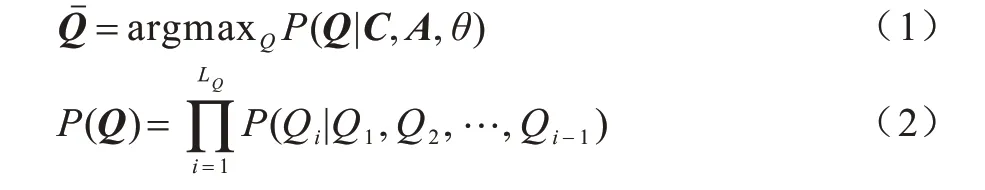
其中:Q1,Q2,…,QLQ是构成问题Q的词;LQ是组成问题Q的词数量。
2 本文方法
本文带有关键词感知的问题生成采用“两步走”的流水线式框架,包括关键词分类、问题生成2 个步骤:关键词分类模型针对输入的文本段落中的每个词,预测其为关键词还是非关键词并作为特征;问题生成的输入数据中融合上述特征,经过问题生成模型生成问题。关键词分类模型和问题生成模型的网络结构设计均基于预训练语言模型ERNIE[29]。
2.1 预训练语言模型ERNIE
预训练语言模型ERNIE[29]在自然语言理解任务中表现突出,在16 个公开数据集上性能领先,在国际通用语言理解评估基准GLUE 上率先突破90 分,在全球语义评测SemEval 2020 中摘得5 项世界冠军。基于ERNIE[29]的突出表现,本文选取ERNIE 作为基线模型。
ERNIE 的网络结构由嵌入向量层(输入)、双向自注意力编码器、下游任务层(输出)3 个部分组成,如图1 所示。
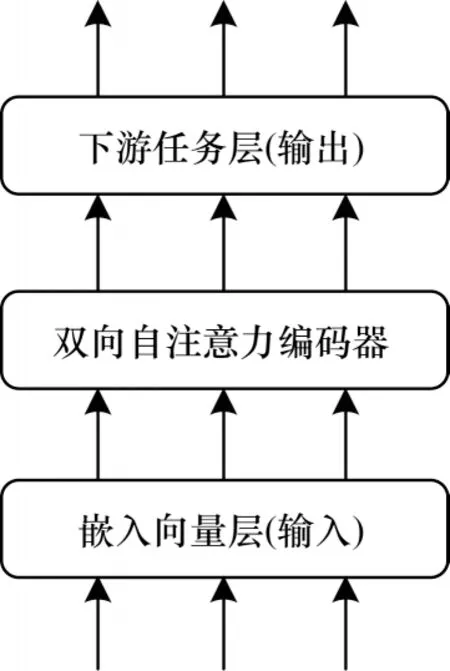
图1 ERNIE 网络结构Fig.1 ERNIE network structure
ERNIE 等预训练模型在预训练过程中使用的词表是子词(Sub-Token)表,“子词”即将一个英文单词拆分为几个具有一定意义的小单元,以更好地对子词语义嵌入向量进行预训练,例如:将单词“eating(正在吃)”拆分为“eat(吃)”和“ing(正在)”。
在预训练过程中,输入文本数据的格式是:“[CLS]句子1[SEP]句子2[SEP]…”,其中:[CLS]表示开始;[SEP]表示一个句子结束,两者均为子词表中的特殊标志子词。输入文本数据经过嵌入向量层后被转化为嵌入向量(Embedding Vector),具体过程为:嵌入向量层根据输入的编号查表映射为向量,例如输入的编号为2,则从表中取出第2 个向量。嵌入向量由4 个部分相加组成,分别是子词语义嵌入(Sub-Token Embedding)、位置嵌入(Position Embedding)、句子嵌入(Sentence Embedding)、任务嵌入(Task Embedding):子词语义嵌入以子词在词表中的顺序位置作为编号,学习子词本身到向量的映射,例如某子词在词表中的第521 个位置,其编号即为521;位置嵌入学习子词在输入文本中的位置到向量的映射,例如某子词在输入数据中的第4个位置,其编号即为4;句子嵌入学习子词所属的句子(或文本片段)的位置到向量的映射,例如某子词在第1 个句子(或文本片段)中,其编号即为1;任务嵌入学习任务类型到向量的映射。嵌入向量在双向自注意力编码器层进行计算(双向自注意力编码器层采用Transformer[30]结构),计算后的向量传给下游任务层以实现特定的下游任务。
2.2 关键词分类
2.2.1 关键词分类任务定义
在输入的文本段落中有很多实词(如动词、名词),在生成问题的过程中,为了确保问题与原文语义上的一致性,往往需要“拷贝”一些重要的实词,在本文中称这些需要被拷贝的词为“关键词”。关键词分类任务的定义是:给定一个文本段落C和一个答案A,答案A是文本段落C中的一部分连续文本,C由连续的词C={C1,C2,…,CLC}构成(LC是段落C中的词数量),计算机根据段落C和答案A预测段落C中的每一个实词Ci(1≤i≤LC)是否为关键词。
2.2.2 数据标注
实现关键词分类任务需要在训练集中标注关键词,具体操作是:遍历文本段落中的单词,如果该单词不在停词表(包含常用的高频虚词,使用开源工具spaCy 和NLTK 获取)中,并且该单词也出现在问题中,则将其视为关键词。标注关键词的算法描述如下:
算法1标注关键词

该算法的运算过程包括对问题中所有词的一次遍历运算、对停词表的查表运算、对问题词集合的查表运算、对关键词集合的插入运算。算法的空间复杂度为O(n),时间复杂度为O(n)。
2.2.3 关键词分类网络结构
关键词分类网络结构如图2 所示。输入数据的格式为“[CLS],C1,C2,…,CLC,[SEP]”。在嵌入向量层中,子词语义嵌入的编号设定方式与ERNIE 预训练过程中的设定方式相同,子词语义嵌入所需要的编号由子词在词表中的顺序位置决定;因为[CLS]和[SEP]需要2 个位置,所以位置嵌入所需要的编号按顺序设置为0,1,…,LC,LC+1,LC+2;因为输入的只有一个文本段落,所以统一将句子嵌入所需要的句子编号设置为0;因为该任务没有在预训练过程中使用过,所以将任务嵌入所需要的任务编号设置为默认值0。
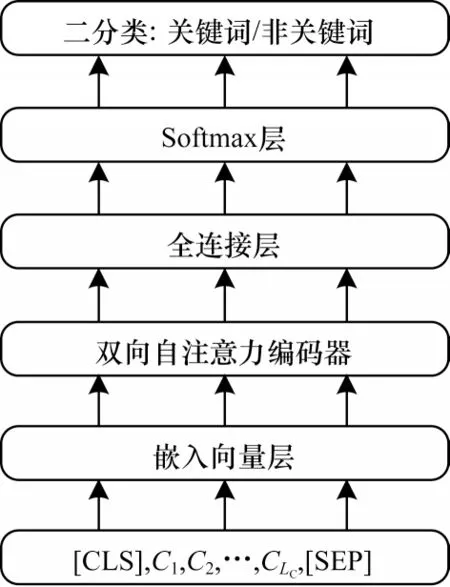
图2 关键词分类网络结构Fig.2 Keyword classification network structure
嵌入向量在经过双向自注意力编码器与全连接层后,利用Softmax 层执行二分类任务,将每一个子词分成关键词或非关键词,表达如下:
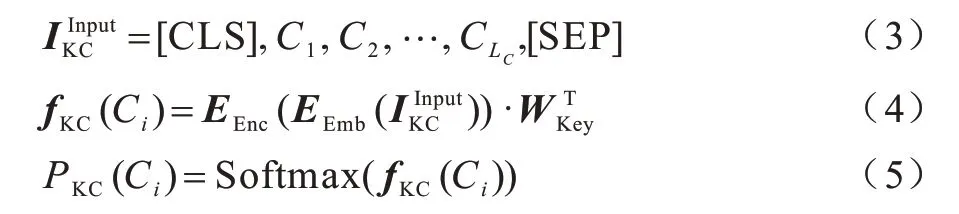
2.2.4 后处理
为了提升问题生成的效果,关键词分类模型输出的结果PKC(Ci)需要经过后处理,原因有以下两点:
1)由于问题生成任务固有的“一对多”的特点,关键词分类任务不可能实现准确率和召回率都逼近100%的结果。例如:
段落:学术性刊物《计算机工程》于1975 年创刊。
答案:1975 年
问题1:《计算机工程》是哪年创刊?
问题2:学术性刊物《计算机工程》是哪年创刊?
在该例中,问题1 与问题2 都是正确的,但问题1中不包含“学术性刊物”,问题2 中包含“学术性刊物”,因此,“学术性刊物”可以是关键词也可以是非关键词。
如果将准确率和召回率都不够高的特征输入到问题生成模型中,必然引入大量噪声,影响问题生成的结果。为解决该问题,可以降低判定为关键词的概率阈值,将特征调整为高召回率的特征,高召回率的直观理解是:对于判定为关键词的子词,问题生成模型应该进行复制;对于判定为非关键词的子词,问题生成模型应该自适应地计算是否复制。
2)原文段落相对较长,问题相对较短,原文段落中存在大量无关词汇,导致数据标注过程中被标注为关键词与非关键词的比例不均衡。可以通过降低关键词的判定概率阈值来解决该问题。
基于以上两点原因,后处理至关重要,其能影响关键词特征的质量以及问题生成的效果。后处理的具体方法是:设定一个关键词阈值T,如果关键词分类模型输出的关键词概率大于等于阈值T,则将其判定为关键词;否则,判定为非关键词。公式描述如下:
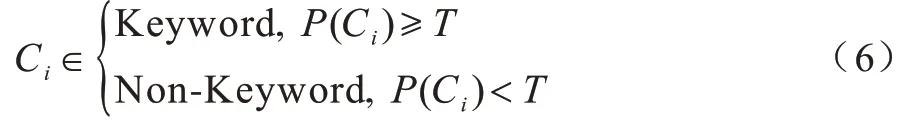
经过后处理的关键词分类结果将作为特征融合到问题生成模型MQG的输入中,并要保持问题生成模型MQG在训练和预测过程中接收到的特征具有一致性。预测过程中的特征是由关键词分类模型MKC得出的,因此,在问题生成模型MQG的训练过程中,也应该使用关键词分类模型MKC预测得出的特征,而不是数据集标注的真实特征。具体做法是:在训练集上训练好关键词分类模型MKC后,用MKC在训练集和测试集上均执行一遍预测过程,然后执行调整关键词分类阈值的后处理操作,将结果作为问题生成模型MQG的输入特征。
2.3 带有关键词感知的问题生成
带有关键词感知的问题生成网络在结构设计时主要考虑三点:一是在输入层中融合关键词特征;二是在编码器层中添加自注意力掩码,将双向自注意力机制改为序列到序列的自注意力机制;三是在输出层实现训练阶段的并行训练与预测阶段的迭代生成。
基于ERNIE 的问题生成网络结构如图3 所示。问题生成任务训练过程的输入文本数据格式为“[CLS],是问题,问题的长度LQ是定值,对于数据中长于LQ的问题,在LQ处截断,对于数据中短于LQ的问题,用特殊标志子词[PAD]填充至LQ长度。对文本段落也做同样处理。在预测过程中,所有的问题子词均以[PAD]作为输入,目的是保持问题在训练和预测的过程中所处位置不变。
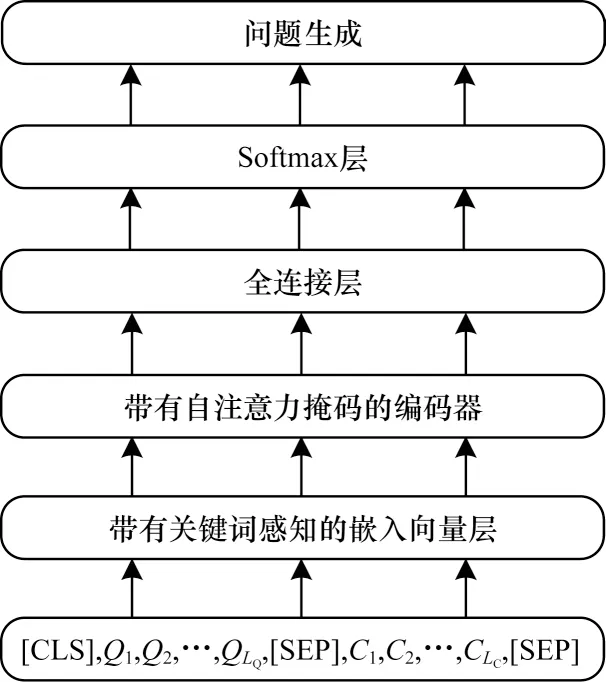
图3 问题生成网络结构Fig.3 Question generation network structure
在嵌入向量层,子词语义嵌入、位置嵌入、任务嵌入的设置方法与关键词分类所用ERNIE 方法相同。对于句子嵌入,需要进行特殊处理以区分段落、答案以及问题部分,具体为:将问题的句子嵌入所需编码设置为0,将输入文本段落中非答案部分的句子嵌入所需编码设置为1,将答案部分的句子嵌入所需编码设置为2。
在嵌入向量层,添加关键词特征嵌入并与原来的4 种嵌入向量相加。对于关键词,其关键词嵌入的编码设置为1,对于非关键词,其关键词嵌入的编码设置为0。在此,将关键词分类模型及后处理得到的特征信息融合进问题生成模型的输入中,以实现问题生成模型的关键词感知能力。
在编码器层,预训练语言模型ERNIE 的自注意力是双向的,即在计算每个子词的向量时,根据其上文和下文2 个方向的子词进行向量计算。对于问题生成任务,不能使用双向的自注意力,这是因为在训练过程中要保持并行训练效率,一个问题中的所有子词并行参与训练,不能让问题中后边的子词“看到”前边的子词;另外,问题中所有子词的向量计算均需要“看到”所有文本段落部分的子词,不能让文本段落部分的子词“看到”问题部分的子词,以防数据泄露。如图4 所示,本文采用类似UniLM[31]中提出的自注意力掩码机制,实现问题生成任务所需的序列到序列自注意力编码器。在编码器中计算向量时,问题中的子词可以“看到”问题中前边的子词和文本段落中的子词,文本段落中的子词仅可以“看到”文本段落中的子词。自注意力掩码结构的设计,使得一条数据问题中包含的所有词可以并行训练,不会发生数据泄露,提升了训练效率。在预测过程中,为了保持和训练过程的一致性,也使用该自注意力掩码机制。
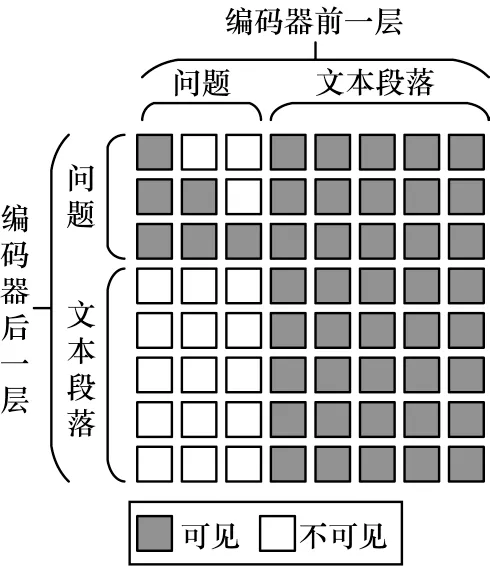
图4 自注意力掩码示意图Fig.4 Schematic diagram of self-attention mask
带有自注意力掩码的编码器输出的向量经过全连接层后,用问题部分前一个子词Ci-1位置的向量乘以子词嵌入矩阵的逆矩阵,得到的子词编码对应的子词作为当前子词Ci的预测输出,用公式表示如下:
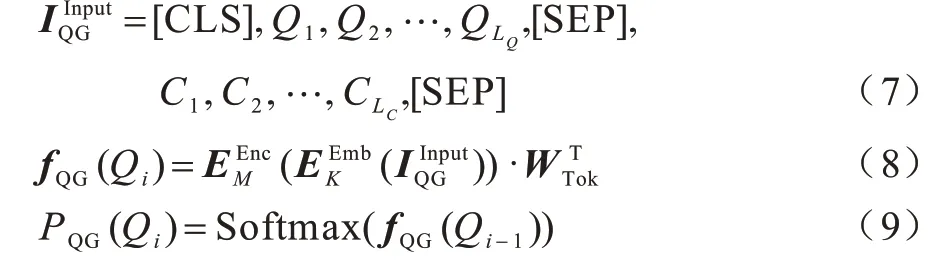
3 实验结果与分析
3.1 实验设置
实验代码在开源深度学习框架PaddlePaddle[32]上实现,在V100 GPU 上训练与测试。使用预训练模型ERNIE 初始化参数,并设置所有参数为可训练状态。设置问题的最大长度LQ为40,文本段落的最大长度LC为341。优化器为Adam,dropout 比率为0.1。使用指数滑动平均(Exponential Moving Average,EMA)进行评估,衰减率设置为0.999 9。学习率使用线性warm up 和decay,warm up 步数设置为总训练步数的10%。最大学习率为2e-5,批大小(batch size)为16,关键词分类的训练轮数(epoch)为4,问题生成的训练轮数(epoch)为5。
3.2 数据集与评价指标
现有的问题生成研究主要在英文问答数据集SQuAD[33]上进行评价,SQuAD 中的数据由段落、问题、答案3 个部分组成,其中:段落和问题从维基百科中获取;答案由人工标注。但是SQuAD 数据集中官方没有提供测试集,只提供了训练集和验证集。为解决该问题,文献[34]将原始的训练集划分为新的训练集和新的验证集,将原始的验证集划分为新的测试集,这种划分方式在问题生成领域被广泛使用,为了对比实验的公平性,本文同样使用文献[34]中的数据划分方式。
BLEU-4[35]是目前问题生成领域常用的评价指标。BLEU 通过计算数据集真实数据和模型生成数据中共同出现的n-gram 占所有n-gram 的比率,以此来衡量生成质量的高低。BLEU 还引入长度惩罚因子,避免过长或过短的句子获得过高的分数。
3.3 问题生成实验
问题生成实验结果如表2 所示。其中,选择3 个具有代表性的模型作为对比模型:带有复制机制的问题生成模型[34]带有最大值指针与门控结构复制机制,在段落级的问题生成中取得了突破性的进展与性能提升;带有语义监督的问题生成模型[24]用问答任务来监督问题生成任务,在效能上具有较大的提升;带有序列到序列预训练的问题生成模型UniLM[31]在“序列到序列”预训练之后进行“微调”,是首个将预训练语言模型应用于问题生成任务的方法,在该领域具有很大的影响力。不带关键词感知的问题生成模型是本文的基线模型,其在问题生成模型的嵌入向量层没有添加关键词特征的嵌入向量。从表2 可以看出,本文带有关键词感知的问题生成模型的性能优于基线模型以及对比问题生成模型。

表2 问题生成实验结果Table 2 Question generation experiment results
3.4 关键词分类阈值对问题生成的影响
用准确率和召回率评估关键词分类及后处理之后的问题生成质量,多组关键词分类阈值下的实验结果如表3 所示。从表3 可以看出,准确率和召回率无法同时达到很高水平,这是由于问题生成任务固有的“一对多”特点所造成的,需要采用后处理的方法调整关键词分类阈值T来解决该问题。

表3 关键词分类实验结果Table 3 Keyword classification experiment results
为进一步探究后处理中关键词分类阈值T对问题生成质量的影响,本文评估多组阈值设置下的问题生成BLEU-4 指标,结果如图5 所示。
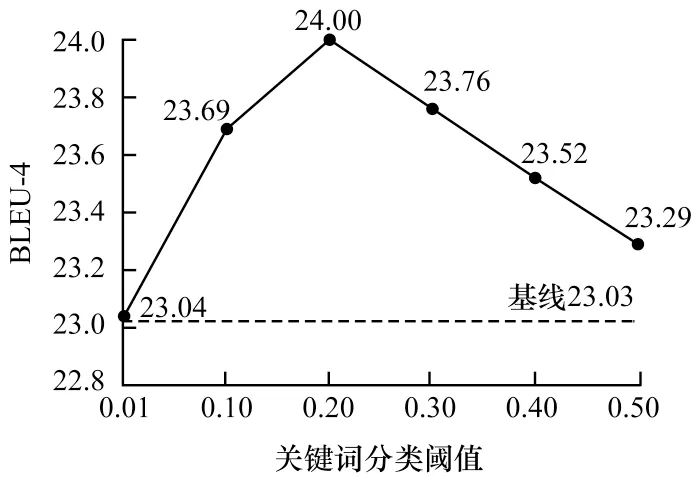
图5 关键词分类阈值对BLEU-4 的影响Fig.5 Influence of keyword classification threshold on BLEU-4
从图5 可以看出:当阈值设置为0.01 时,BLEU-4指标结果与基线模型持平;当阈值设置为0.50 时,BLEU-4 指标略高于基线模型;当阈值设置为0.20时,BLEU-4 指标明显优于基线模型。由此可见,关键词后处理操作具有有效性。
3.5 应用场景
带有关键词感知的问题生成方法已经借助千万级规模的数据平台——百度百科实现了大规模工业应用。一条百度百科数据由一个“词条名”和对该词条名的文字介绍构成,例如,词条“红嘴鸥”中有大量文字系统性地介绍了红嘴鸥的形态特征、栖息环境、生活习性等信息。将百度百科数据中的某一个段落以及标记的答案作为问题生成的输入,将词条名作为关键词,通过带有关键词感知的问题生成方法生成包含词条名的问题,将问题加入搜索引擎的问题库,当用户使用搜索引擎搜索该问题时,即可将该段落和答案作为搜索结果。
4 结束语
本文基于预训练语言模型ERNIE,提出一种带有关键词感知功能的问题生成方法。利用关键词分类模型提取关键词信息,经过后处理操作后将其作为全局信息来引导问题生成过程。在SQuAD 数据集上的实验结果表明,该方法能够显著提升问题生成效果,BLEU-4 指标值可达24。目前,该方法的有效性已在大规模工业应用中得到验证,下一步将探索其在摘要抽取、标题生成等其他自然语言生成任务中的适用性。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
小学阅读指南·低年级版(2020年9期)2020-10-12 02:43:08
阅读(快乐英语高年级)(2020年9期)2020-01-08 02:20:52
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
散文诗(2017年17期)2018-01-31 02:34:11
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
