
基于文本分类的Fisher Score 快速多标记特征选择算法
2022-02-24 05:11:46汪正凯沈东升王晨曦
计算机工程 2022年2期
汪正凯,沈东升,王晨曦
(1.福建省粒计算及其应用重点实验室,福建 漳州 363000;2.闽南师范大学 计算机学院,福建 漳州 363000)
0 概述
在传统的单标记监督学习中,样本仅由一个标记属性描述,这种假设常违背现实生活的真实情况。在一类非互斥属性中,样本的标记属性可能同时包含多个语义信息,例如,一部电影可能是喜剧电影的同时也是爱情电影,在这种情况下,单一属性标记无法有效地对样本进行类别划分,因此一种多标记学习框架[1-3]被提出。相对于单标记学习,在多标记学习中,每一个样本具有多个以上的属性标记,在非分层任务中,样本在属性标记下仅有二值取值,即为正或负,将样本所有标记中具有正值的标记称为标记集合,样本的标记集合即构成了对样本属性的完整描述。随着数据挖掘技术与移动互联网技术的发展,数据的规模不断增长,描述样本属性的标记集合的规模也随之增长,而丰富的标记集合往往需要高维的特征空间描述[4]。但过高的特征维度会使得学习器的消耗提升,同时一些噪声特征也会对分类结果产生影响,最终降低分类精度[5]。因此,高维特征带来的维度灾难[6]已经成为多标记学习面临的重要挑战之一。
作为一种有效的特征降维技术,特征选择[7]的目的是在保持学习器性能不改变太多的前提下能够有效地约简数据集的维度。目前,针对多标记学习任务的特征选择算法已有很多,这些算法按照与学习器的关系可以分为过滤式[7-9]、包装式[10]和嵌入式3 种。其中过滤式不依赖于学习器,而是寻找独立指标来评价每个特征对分类能力的贡献大小,以此过滤出含有更丰富信息的特征子集[11-12],或以某个评价指标结合搜索算法来搜索特征子集[13-14],前者需要预设阈值,而后者可根据搜索策略自动结束算法;相对于过滤式特征选择算法,包装式特征选择算法以特征子集在分类器上的分类性能作为搜索指标指导搜索方向,嵌入式特征选择算法在进行特征选择的过程中即同时进行了学习器的训练。因此,在算法运行时间和计算资源的消耗以及模型的普适性上,过滤式特征选择算法具有更大的优势。
Fisher Score(FS)作为一种基于距离度量的特征评价指标,通过计算类间散度与类内聚度的关系度量特征分类能力的强弱,在单标记监督学习中已有了较多的研究与应用。XIE 等[15]提出一种基于改进的F-score 和支持向量机的包装式特征选择方法,以SVM 分类器的分类结果指导搜索方向;SONG 等[16]提出了不均匀分布下的FS 特征选择算法,以两两类别之间的距离代替类与总体中心的距离作为类间散度的计算方式;MUHAMMED[17]等提出一种结合FS评价准则和贪心搜索的特征选择算法,在阿尔茨海默病的分类上取得了较好的结果;SONG[16]等提出一种基于Fisher 判别分析(FDA)和F-score 的特征排序方法用以多类样本分类,BEHESHTI[18]提出一种集合FS 评价准则和T 检验分数来寻找最优的特征集的特征选择算法。
然而,以上的算法都忽略了样本极值对类中心带来的偏差影响,以距离度量的类中心的意义仅在统计学上得以体现,在实际应用中很容易被异常值影响,当方差很小的一类样本中加入一个相对量纲较大的样本时,会使得该类样本的中心发生偏移,此时需要对该异常值进行处理以避免最终FS 得分产生误差。同时,上述算法都仅能应用于单标记特征选择,而多标记任务更能体现生活中的实际情况,因此将单标记任务下的FS 算法应用于多标记任务具有一定的实际研究意义。基于此,本文提出一种多标记FS 特征选择算法,计算每个样本在各个标记下经过去极值后的特征集合的FS 得分,若多标记任务中标记包含信息对分类的贡献,则根据样本具有的标记数量可以得到该样本标记集合的标记权值,以此更新样本在特征空间下的FS 得分。
1 相关知识
FS 是一种经典的评价特征对分类贡献能力的指标,特征的FS 得分越高,表明在该特征下类内样本间间距尽可能得小,类间样本间距尽可能得大,即类间样本间距与类内样本间距的比值越大。在传统单标记学习中FS 的相关描述如下:
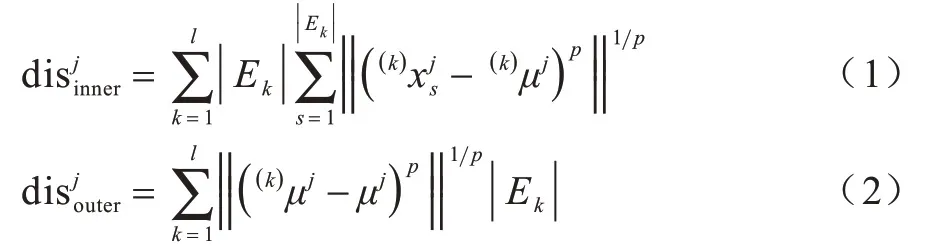
disinner和disouter分别表示在特征fj下所有类别的类内距离与所有类与样本中心类间距离的和,可分别称为特征fj下的类内聚度与类间散度。当类内聚度越小时,样本类内分布越稠密,类间散度越大,样本类间分布越稀疏,由于特征辨识类别的能力与该特征下的类间散度和类内聚度比值成正相关,则定义特征fj对类别辨识的能力评价指标FS 如下:
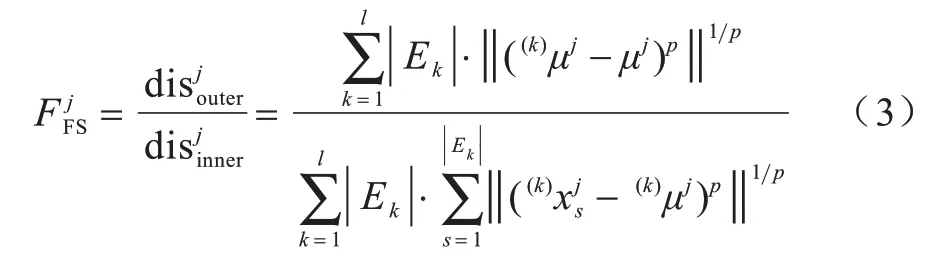
式(3)为单个特征下的FS 得分计算公式,若以单个特征的FS 得分作为评价指标,则可计算出所有特征的FS 得分,通过设置阈值筛选出特征子集。若采用启发式搜索的方式筛选特征子集,则需要设置合适的搜索策略,不断迭代搜索当前候选子集中的最优特征,直至满足搜索终止条件,得到最终的特征子集。相对于启发式搜索,前者的时间复杂度更低,算法性能消耗更少。
2 基于多标记FS 的特征选择模型
式(3)给出了在单标记学习下任意特征的FS 得分的计算公式,但都是直接对一类样本计算其均值作为类中心,并没考虑到极值带来的方差增大的影响,假设某一特征下所有样本的划分情况如图1 所示。其中,直线两边表示各自不同的一类样本,圆圈选中的样本代表多数真实样本的分布,圆圈的圆心代表这些样本的中心点,而圆圈外样本会使得类样本的中心点发生偏移,极端值样本距离多数样本越远,偏移程度越大,而在理想状况下是同类样本尽可能分布在一起,因此,需要根据类别样本的分布情况对已划分的样本进行处理,去除其中距离多数样本较远的样本,再对剩下的样本进行FS 得分计算。
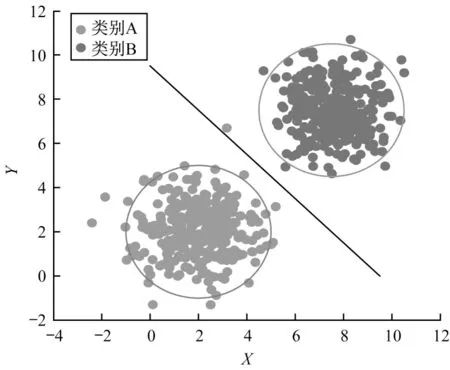
图1 类中心偏差示意图Fig.1 Schematic diagram of class center deviation
同时式(3)仅能应用于单标记特征选择,但在更复杂的多标记学习中,式(3)无法直接应用,若将多标记任务简单地分解为多个单标记任务再应用式(3),则会损失多标记任务中标记集合之间的关联信息,基于此,考虑从样本角度对标记集合进行遍历,且针对各个标记对整体标记集合的贡献值,将样本的标记集合下的全体特征的FS 得分与根据样本本身具有的标记集合所得出的标记权值系数相乘,以此更新FS 的计算公式。
下文将给出相关定义来描述本文算法模型。假设存在一个决策系统其中论域U={x1,x2,…,xn}∈ℝn×m为全体样 本组成的 非空有限 集合,xi∈U是维度为1×m的一维向量,表示论域U中的第i个样本,A={f1,f2,…,fm}为全体特征组成的集合,fj∈A表示特征集合中第j个特征,为论域U中的一个实值,表示样本xi在特征fj下的取值,D={y1,y2,…,yn}∈ℝn×l为样本的标记集合,yi∈D是维度为1×l的一维向量,表示标记集合D中第i个样本xi在全体决策属性上的标记结果为xi在第k个标记上的标记结果,在多标记学习中,xi在标记k下被标记时,反之=0,且对任意 一个样本xi,有≥1。综合上述条件,有如下定义:
定义1假设存在一个随机样本xi∈U,xi的标记集合为yi,定义xi在标记空间上的真实标记集合y_truei如下:
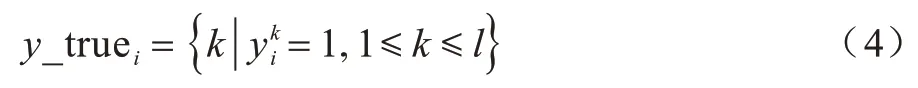
定义2假设存在一个随机样本xi∈U,xi的真实标记集合为y_truei,对任意标记k∈y_truei,则标记k将论域U划分如下:
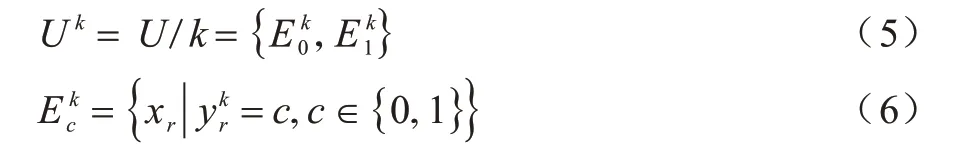
其中:c表示样本xr在标记k下的值表示论域U中在标记k下具有值为c的样本组成的集合。
xi的真实标记集合y_truei对论域U的划分结果分布如下:

定义3假设存在一个随机样本xi∈U,有一个划分情况Uk∈Ui,Uk中的任意一类样本集合在特征fj下的均值如下:
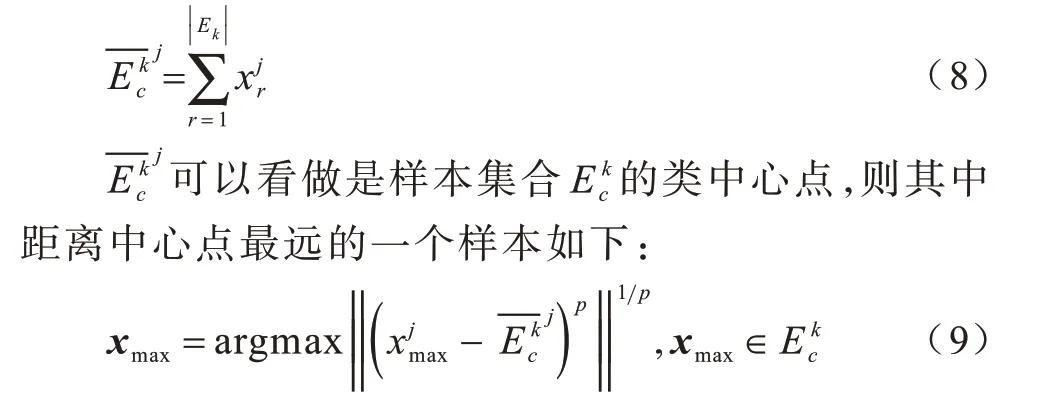
定义4假设存在一个随机样本xi∈U,在标记k划分的论域空间中存在一个样本类别集合,其中距离该类中心点最远的一个样本为xmax,则定义该类中心点的有效样本集合如下:
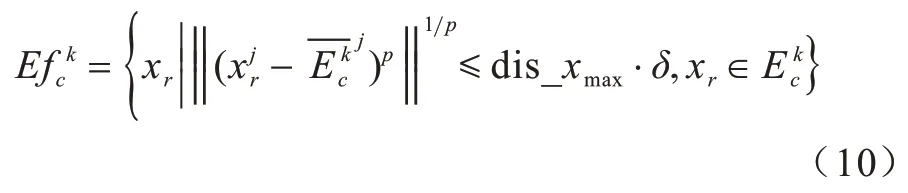
其中:dis_xmax表示xmax距离中心点的距离;δ∈(0,1]表示半径系数,且δ和样本数量正相关,当δ=1 时,即相当于不做中心偏移操作。
定义5假设存在一个随机样本xi∈U,有划分情况Uk∈Ui,Uk中任一类样本集合在特征fj上经过中心偏移之后的样本集合为,则特征fj在随机样本xi的标记k划分论域U加中心偏移处理之后的FS 得分如下:
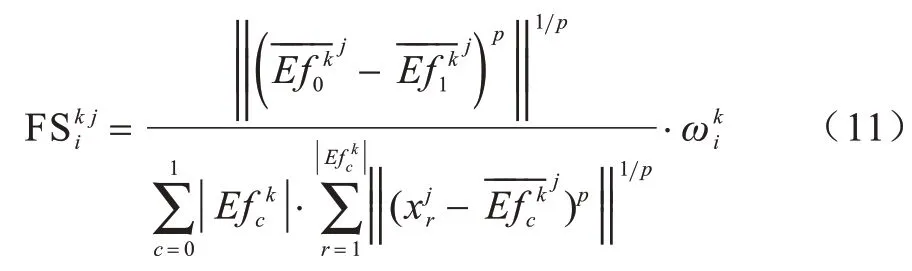
其中:分子表示类间散度,相对于原始的每一类减去总体中心,在类别之间计算距离可以避免不均匀分布情况下的类间散度差异表示随机样本xi的标记k的权值系数,为k与xi的真实标记集合y_truei中的其余标记的余弦系数的和再加1,如果样本只具有1 个标记,则为1,可以理解为标记k与其余标记的额外信息,显然随机样本的真实标记数量越多,任一标记k的权值系数越大,因为标记数量越大,其中包含的分类信息应当更多,所以FS 分数计算更加重视具有更多标记的情况。
定义6假设存在一个随机样本xi∈U,xi的真实标记集合为y_truei,根据式(11)得出特征fj在xi的标记k上的FS 得分,则定义fj在整体标记集合y_truei上的FS 得分如下:

根据式(12)可得出特征fj在全体样本上的FS得分如下:

式(13)是单个特征的FS 得分,则最终全体特征集合A的FS 得分为:

式(14)为全体特征的FS 得分分布,对FS 进行降序可以得到分类能力更强的特征,从而实现特征选择的目标。
上述定义中之所以采用全体采样,是因为对全体样本的遍历使得所提算法的结果具有较强的鲁棒性,避免随机采样所导致结果产生不确定性。定义3和定义4 对一类样本进行了中心偏移操作,前提是该类样本数量较多,因为数量较少时,并不足以准确地决定多数样本的类中心,但并不是全部数据集中每个标记下每类的样本数量都足够多,基于此在后续实验中进行到中心偏移操作前都会对该类样本数量进行检测,当该类样本数量占总体样本数量比例小于0.05 时,即不进行中心偏移操作。式(11)中类间散度计算没有采用原始FS 计算类间散度的方式,而是改用了文献[18]中提出的方式,该计算方式如式(15)所示:
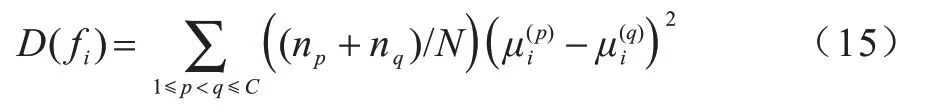
其中:D(fi)表示特征fi的类间散度;p、q分别表示类别p和类别q;np表示类别p的数量;N为全体样本数量;表示类别p在特征fi上的均值。可以看出,式(15)是采用类别间的序关系来实现类别间的两两距离计算,以避免类间重复计算。本文模型的算法流程如算法1 所示。
算法1MLFS 算法

在算法MLFS 中,主要的计算消耗在于对每个标记k计算其FS 得分,若假设某数据集有n个样本、m个特征和l个标记,平均每个样本在标记空间上的标记数量为LC,则计算全体特征的FS 得分的代价为O(m),步骤3 计算全体标记下的FS 得分的代价为O(m·l),步骤4~步骤6 并没有太多计算消耗,计算代价为O(n·LC),步骤7 的排序代价为O(mlogam),算法MLFS 的主要计算消耗在于计算每个标记下的FS 得分,且并不依赖于任何分类器。
3 实验与结果分析
3.1 实验数据集
为验证本文算法的有效性,选取MuLan 库中的8 个公开多标记数据集进行实验。由于数据集在MuLan 库中已经分好,训练集和测试集会直接采用已经分好的结果,在训练集中对所提算法进行特征选择,再将特征选择结果应用于测试集进行分类测试,数据集的详细信息如表1 所示。
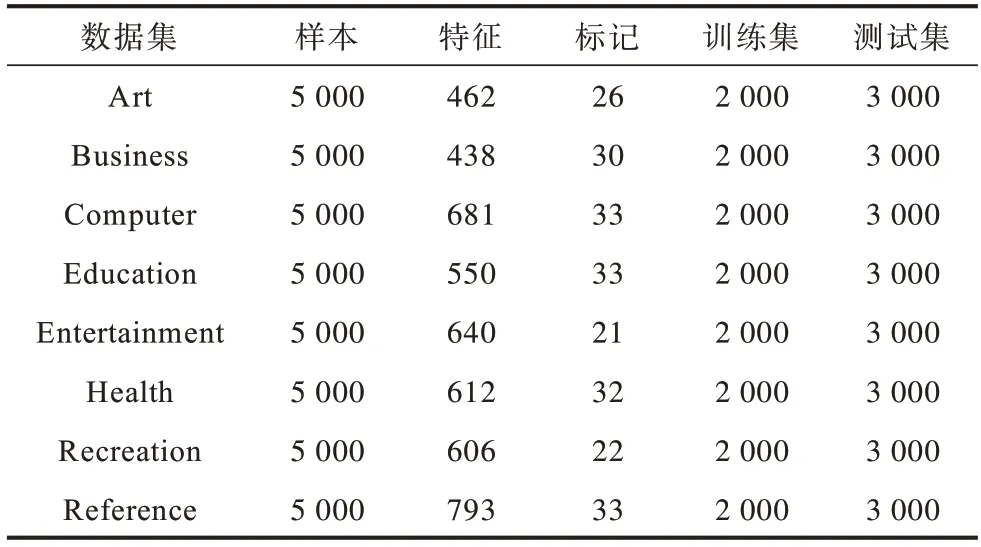
表1 多标记数据集Table 1 Multi-label datasets
3.2 实验环境及评价指标
实验运行环境为Pycharm Professional 2019.2.3+Python 3.7.1 64 位,硬件环境 为Inter®Xeon®CPU E5-26xx series 2.49 Hz,16 GB内存,操作系统 为Windows10 64 位。实验采用5 种评价指标[14]:Average Precision,Hamming Loss,One Error,Ranking Loss,Coverage,分别简写为AP、HL、OE、RL、Cov,其中,HL、OE 的计算基于标记预测,AP、RL、Cov 基于标记排序,AP 指标表示数值越高,分类性能越好,其余指标表示数值越低,分类性能越好。
3.3 相关参数设置及算法选择
本文算法是通过设置半径系数δ来选择有效样本集合的,因此不同大小的半径系数会选取不同规模的样本集合,实验会首先比较不同大小的半径系数对实验结果产生的影响。
为比较本文算法的有效性,选择了各类型的多标记特征选择算法作为对比算法,分别为基于蚁群优化的多标签特征选择算法(MLACO)[19]、多标记ReliefF 特征选择算法(MLRF)[8]、基于多变量互信息的多标记特征选择算法(PMU)[9]和多标签朴素贝叶斯分类的特征选择算法(MLNB)[14],其中MLACO为PANIRI 等提出的一种基于蚁群算法(ACO)的多标记特征选择算法,通过同时引入计算标记相关性的有监督启发式函数与计算特征空间冗余性的无监督启发式函数在特征空间迭代搜索最优子集,是一种最新的性能优异的多标记特征选择算法;MLRF算法是基于距离度量的多标记ReliefF 算法,通过引入汉明距离在标记集合上寻找样本的同类与异类近邻;PMU 算法是LEE 等提出的基于互信息度量的特征选择算法,通过三元互信息度量特征子集与标记集合间的相关性;MLNB 是ZHOU 等提出的基于主成分提取PCA 和遗传算法(GA)的混合型特征降维算法。
上述算法兼顾各种类型,便于本文所提算法与各类型算法进行比较。在对比算法的参数设置上,MLACO 算法参数与原文保持不变;MLRF 采用全体采样方式,近邻个数设为5;PMU 算法需要先进行离散化,以PMU 算法离散化方式为标准对实验数据预先进行了两折离散化;MLNB 设置一阶段预留特征比例ratio 为0.7,平滑因子默认为1。在特征数量的选择上,由于MLNB 算法可以直接得到一个特征子集,而其他算法得到排序后的特征集,则按照MLNB算法得到的特征子集数量,在其他算法排序后的特征子集上取相同数量的特征子集进行对比。
此外,实验所采用的分类器为MLKNN[20]分类器,默认近邻个数为10,平滑因子为1。
3.4 实验结果
本文首先比较所提算法中参数δ对实验结果的影响,由于δ是一类样本中心点选择样本的距离范围占一类样本中距离该类样本中心点最远的样本到中心点的距离的比例,实验设置3 个数据集在δ∈(0,]1 上进行实验,实验结果如图2 所示。
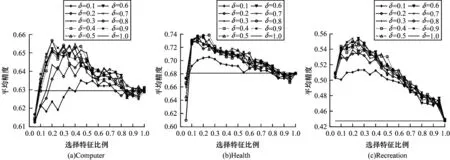
图2 各数据集上不同半径系数随着特征比例变化的情况Fig.2 Variation of different radius coefficients with feature proportion on each datasets
图2 中选择 了Computer、Health、Recreation 3 个数据集,在每一类数据集中,横线表示不做中心偏移的算法取全部特征的分类结果。可以看出,在文本类数据集中,基本符合半径系数越大分类性能越好的预期,这是由于文本类数据集中特征空间较为稀疏,在半径系数较小时会损失多数样本,而期望效果是仅去除小部分极端值样本,因此分类结果较差。随着半径系数的增大,Computer 数据集中分类性能逐渐提升,而其余数据集中并没有很明显的变化,这是由于半径系数是基于离类中心点最远样本的比例确定的,可能存在一种情况,当该样本离类中心点足够远时,此时半径系数选择0.5 或者0.9,而筛选的样本数量是一样的,对于这种情况,可以选择加入数量判定,当不同比例下半径系数筛选的样本数量不变时,选择原有类别样本数量的80%或者90%作为新的一类样本。但所提的算法模型是基于全体样本遍历的,且在多标记任务下每个标记的划分情况不同,尽管上述异常情况可能出现,但在全体样本数量n×LC(LC 为每个样本的平均标记数量)个标记的平均下,异常情况的影响会尽可能地被降低,因此所提算法没有加入数量筛选这一步骤。
综合以上分析可以得出,半径系数的确定需要预先知道平均类样本的分布情况,而在多数文本数据集中,特征空间是较为稀疏的,这使得在文本数据集中可以预先设定较大的半径系数,基于此,在后续实验中,将所有实验数据集的半径系数设定为0.9。
为了更加详细地验证所提算法的有效性,将所提算法与4 种对比算法在所有数据集中进行实验,实验结果如表2~表7 所示,其中加粗字体为结果最优。

表2 各数据集选择特征数Table 2 Numbers of selected features of each datasets
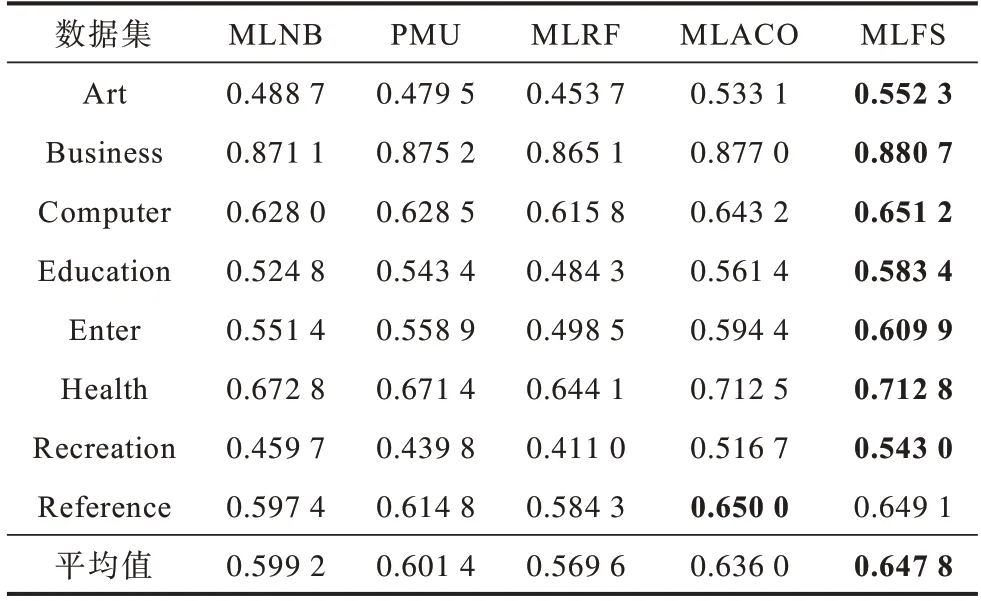
表3 AP 评价指标下各算法的性能比较Table 3 Performance comparison of each algorithms under AP evaluation index

表4 HL 评价指标下各算法的性能比较Table 4 Performance comparison of each algorithms under HL evaluation index

表5 Cov 评价指标下各算法的性能比较Table 5 Performance comparison of each algorithms under Cov evaluation index
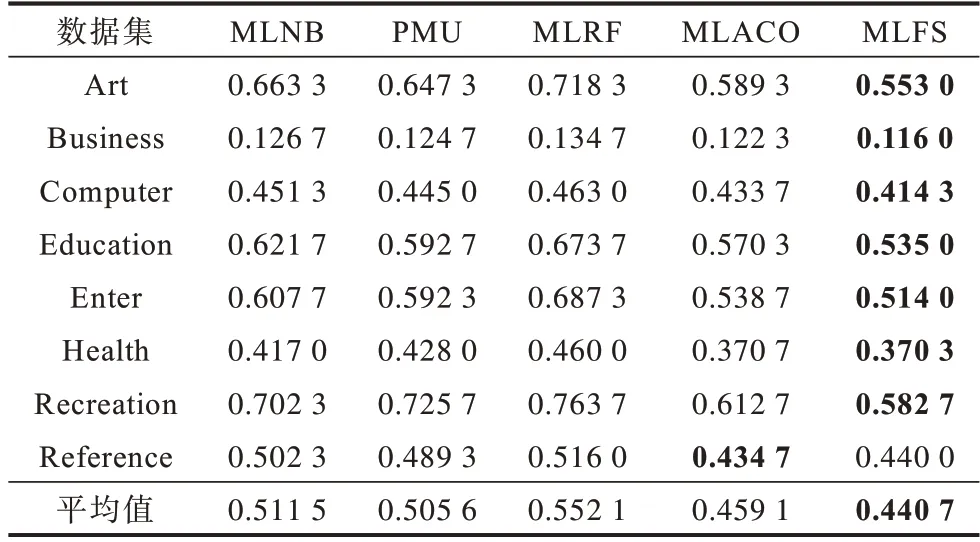
表6 OE 评价指标下各算法的性能比较Table 6 Performance comparison of each algorithms under OE evaluation index
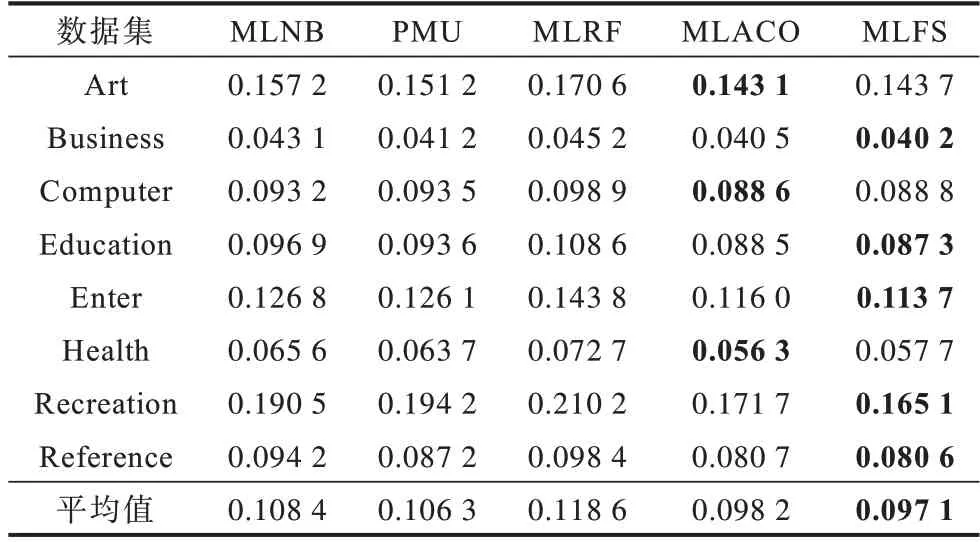
表7 RL 评价指标下各算法的性能比较Table 7 Performance comparison of each algorithms under RL evaluation index
由以上实验结果可以看出,本文MLFS 算法在Art、Business、Computer、Education、Enter、Health、Recreation、Reference 等8 个数据集中的各项指标的平均值都为最优,表明所提算法在整体上相对其余算法具有一定优势,对比各个指标可以发现:
1)在AP 指标上,MLFS算法仅在Reference 数据集中排名第2,在其余数据集中都是排名第1,且平均排序结果排名第1。综合比较4 种对比算法,MLFS 算法选择的特征子集分类性能达到最优。
2)在HL 指标上,MLFS 算法仅 在Computer 数据集中排名第2,在其余数据集中都是排名第1,且平均排序结果排名第1。综合比较4 种对比算法,MLFS 算法选择的特征子集分类性能达到最优。
3)在Cov 指标上,MLFS 算法仅在Art、Health 数据集中排名第2,在其余数据集中都是排名第1,且平均排序结果排名第1。综合比较4 种对比算法,MLFS 算法选择的特征子集分类性能达到最优。
4)在OE 指标上,MLFS 算法仅在Reference 数据集中排名第2,在其余数据集中都是排名第1,且平均排序结果排名第1。综合比较4 种对比算法,MLFS 算法选择的特征子集分类性能达到最优。
5)在RL 指标上,MLFS 算法在Art、Computer、Health 数据集中排名第2,在其余数据集中都是排名第1,且平均排序结果排名第1。综合比较4 种对比算法,MLFS 算法选择的特征子集分类性能达到最优。
6)在约简特征数量上,MLFS 算法相对于原始特征空间约简了70%以上的特征比例仍具有较好的效果,表明所提算法实现了特征选择的降维目标。
7)综合比较8 个数据集在5 个指标上的40 种分类情况,所提算法MLFS 具有最优结果的有32 种,占比80%,表明所提算法具有较好的稳定性。
上述实验结果表明,所提算法选择的特征子集在后续的分类结果的各个指标上相比其余4 种算法具有领先优势,同时具有较高的约简比例,验证了所提算法的有效性和鲁棒性。
为避免出现局部优势带来的误差影响,下文将给出部分数据集各特征选择算法在不同特征比例下的分类情况,由于所选数据集较多,且针对每一种指标共有40 种对比情况,限于篇幅,只选择了其中6 个数据集在5 种指标上的结果进行展示,其中,MLNB算法因为只能得到一个特征子集,并不能与其他算法一起比较特征比例上的分类性能,所以未给出变化情况。变化趋势如图3~图7 所示。
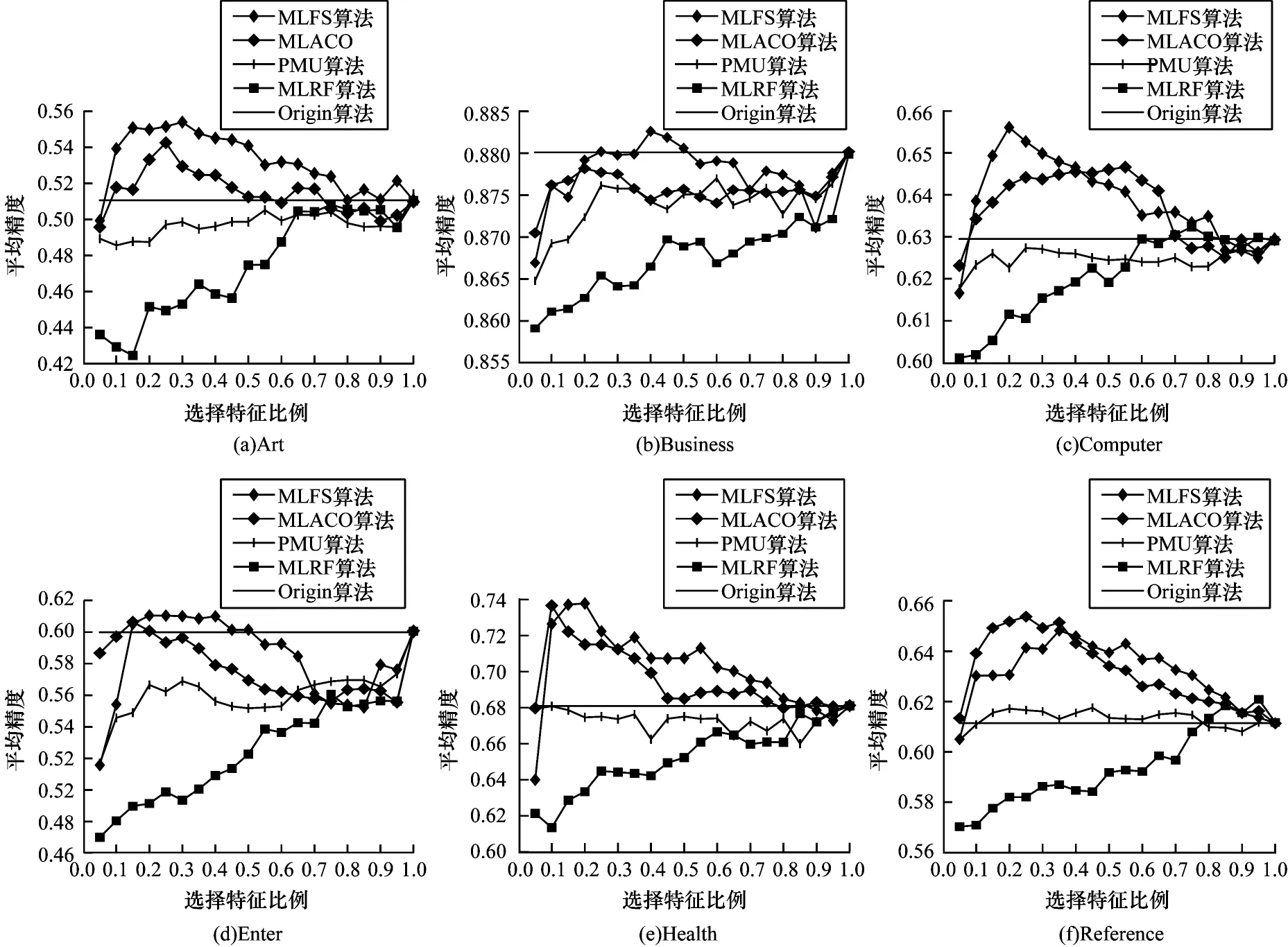
图3 AP 评价指标下各算法分类性能的变化情况Fig.3 Change situation of classification performance of each algorithms under AP evaluation index
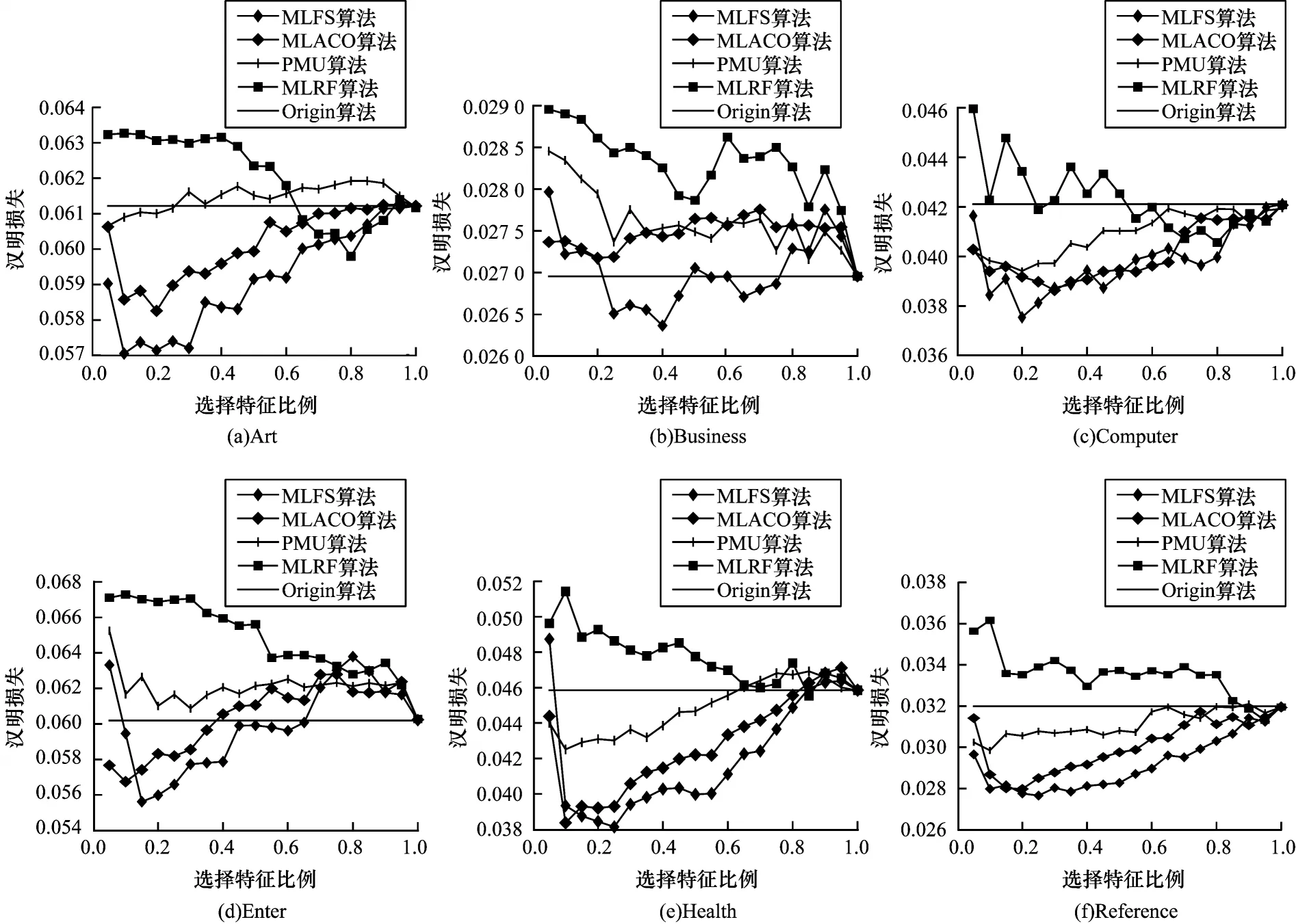
图4 HL 评价指标下各算法分类性能的变化情况Fig.4 Change situation of classification performance of each algorithms under HL evaluation index
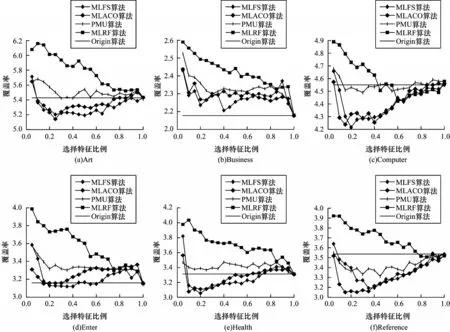
图5 Cov 评价指标下各算法分类性能的变化情况Fig.5 Change situation of classification performance of each algorithms under Cov evaluation index

图6 OE 评价指标下各算法分类性能的变化情况Fig.6 Change situation of classification performance of each algorithms under OE evaluation index

图7 RL 评价指标下各算法分类性能的变化情况Fig.7 Change situation of classification performance of each algorithms under RL evaluation index
从图3~图7 的变化趋势可以看出:本文算法MLFS在各个指标上均优于其余算法,且在AP、HL 指标中的优势较为明显,在其余指标中除MLACO 算法外,均大幅优于其余算法。在选取的特征比例上,本文算法在特征比例较小时即能达到较好的分类性能,表明本文算法基本能够实现特征选择的目标。
为从统计学意义上进一步检测所提算法与4种对比算法在各项指标上是否存在显著差异,将采用显著 性水平为10% 的Nemenyi test[18]对所提算法和其余算法进行比较。根据表3~表7 获得各个算法在所有数据上的平均排序,排序结果如表8所示。
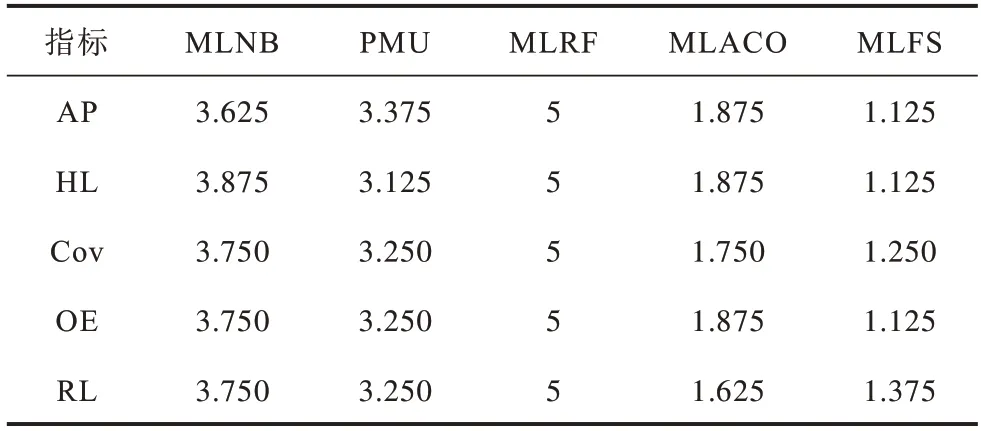
表8 各算法在不同评价指标下的平均排序Table 8 Average ranking of each algorithm under different evaluation indexes
在表8 中,若2 个算法在所有数据集上的平均排序的差值小于临界差值(Critical Difference,CD),则认为2 个算法并没有性能上的显著性差异,由于实验所采用数据集个数为8,总算法个数为5,根据临界差值计算公式可以得出CD 为1.944,则根据临界差值给出各算法在不同指标上的临界差值图,其中算法根据平均排名在坐标轴中由左向右排列,且与所提算法没有明显性能差异的算法用一根加粗的实线相连,临界差值如图8 所示。从图8 可以看出,本文算法在5 种评价指标中性能均排名第1,在除RL指标外的其余指标中,本文算法与MLNB、PMU、MLRF 算法具有显著的性能差异,与MLACO 算法没有显著差异,在RL 指标中,本文算法与MLNB、MLRF 算法具有显著的性能差异,与PMU、MLACO算法没有显著的性能差异。综合上述情况,本文算法与4 种对比算法的统计结果中,性能处于最优,表明所提算法的有效性和鲁棒性。

图8 各算法综合性能比较Fig.8 Comprehensive performance comparison of each algorithms
此外,由于不同的特征选择算法应有其适用的学习任务,在实际应用中应根据不同的情况选择适合的算法。在上述实验中,本文算法与其他算法均是在Yahoo网页文本数据集上进行实验,数据类型较为单一,为验证所提算法的普适性,本文选择2 个不同类型的数据集Scene 和Yeast 进行实验。Scene 数据集是一类语义索引类图像数据集,样本数为2 407,特征数为294,标记数为6,Yeast是一类关于酵母菌基因的生物数据集,样本数量为2 417,特征数为103,标记数为14。由于未知数据集特征空间的密集程度,因此无法事先确定所提算法中的半径系数δ,基于此,测试3 个不同尺度的半径系数,分别为0.1、0.5、0.9,将3 种不同的半径系数作为算法的参数与4 种对比算法在Scene 和Yeast 数据集上进行了实验,实验结果如图9 所示。从图9 可以看出:并不是半径系数越大越好,因为相对于特征空间较为稀疏的文本类数据集,Scene 数据集上的样本分布更为密集,较小的半径系数已足以覆盖类别中多数样本。半径系数越大,整体类别中心点产生的偏移越大,分类结果就越差,而Yeast 数据集上半径系数为0.5 时分类性能相对最优,这与数据集本身样本的分布有关,当半径系数为0.5 时筛选的样本集合的类中心与预期样本的类中心距离最近,此时半径系数过小或过大都会影响最终的分类性能。在与对比算法比较中可以发现,当特征数量较少时,PMU 算法性能最优,而在文本类数据集中表现优异的MLFS 和MLACO 算法性能反而较差,这说明不同的特征算法应该选择其适用的学习任务,对于所提算法应更适用于文本类数据集,而对于非文本类数据集,则需要预先分析其数据,获取标记划分下样本的分布情况,然后根据确定的半径系数进行特征选择。
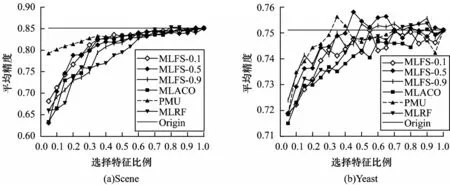
图9 非文本数据集的AP 指标比较Fig.9 Comparison of AP index in non text datasets
此外,对于非文本类数据集,可以使用基于距离排序的方式去除极值样本,以此避免未知样本分布情况下的半径系数的确定问题。距离排序是指对某一类样本中每一个样本到该类样本中心点的距离进行排序,然后去除恒定数量的样本。相对于半径系数的方式,距离排序的计算复杂度较高。假设现在存在某一类样本,该类样本数量是n个,经过计算存在一个极值点样本距离该类样本中心点最远,那么以该极值点到类样本中心点的距离乘以某一比例δ得到距离r,并以类样本中心点为圆心,以r为半径去构造圆,显然在圆外的是需要去除的样本,这里的计算复杂度主要在于找到最大距离的样本以及遍历该类样本集合中的每个样本,判断每个样本的距离与r的关系,前者最坏情况下的时间复杂度为O(n),后者的时间复杂度也为O(n),则总的时间复杂度为2O(n)。对于距离排序的方式,假设条件不变,则需要对样本集合中所有样本进行距离排序,再根据给定的去除样本的数量去除距离最大的一些样本,则最坏情况下的时间复杂度为O(n2),显然半径系数的方式在计算复杂度上要优于距离排序的方式,所以在比较好确定半径系数的稀疏类文本数据集中采用半径系数的方式去去除极值样本来减少计算消耗,而在不好确定半径系数的非文本类数据集中采用距离排序的方式。为了验证距离排序的效果,选择了两个较小的非文本类数据集Birds、Emotion 数据集来进行实验。其中Birds 数据集是记录鸟的叫声的数据集,有645 个样本、260 个特征、20 个标记;Emotion 数据集是音乐情感类数据集,有593 个样本、72 个特征、6 个标记。实验中设去除样本的比例占该类样本集合的10%,实验结果如图10 所示。
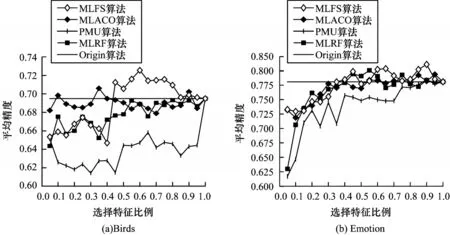
图10 基于距离排序的模型与对比算法的AP 指标比较Fig.10 AP index comparison between model based on distance ranking and comparison algorithms
从图10 可以看出,本文算法在特征比例较少时并没有显著优势,但是随着特征比例逐渐提升,分类性能逐渐提高。在Birds 数据集中当特征比例超过0.45 时即超过原始特征下的分类性能,且在特征比例为0.6 时达到最优,同时领先其余算法;在Emotion数据集中当特征比例超过0.35 时即超过原始特征下的分类性能,且在特征比例为0.9 时达到最优,同时领先其余算法。这表明所提算法在使用距离排序去除极值样本上具有一定效果,能够一定程度应用在非文本数据集上。
综上实验可以得出,本文算法主要适用在样本分布较为稀疏的文本类数据集上,在此类数据集上,每一维特征的重要度都较小,但是却可能与标记集合中某一个标记有关联信息,所以无法轻易去除特征。而本文算法能够有效计算每一维特征下样本被标记划分后的两类样本的区分程度,根据区分程度可以过滤出对整体分类贡献能力弱的特征,但本文算法的局限性在于无法去除特征子集中的冗余特征,当数据集中存在大量冗余特征时,本文算法将无法有效地应对这种情况。
4 结束语
本文通过改进单标记下的FS 计算方式,去除一类样本中的极端值,使得在统计意义上的样本中心更符合实际生活中的样本集合,即通过原始数据的中心偏移完成样本的过滤,并结合标记的权值系数,将其应用于多标记任务。实验结果证明了所提算法具有一定的有效性和鲁棒性。但本文在实验过程中还存在算法难以适用较密集数据集,以及对于多标记权值系数的确定较为简单等问题,这将是下一步需要完善的工作。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
制造技术与机床(2019年6期)2019-06-25 10:17:18
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
华东师范大学学报(自然科学版)(2017年1期)2017-02-27 13:41:05
电子制作(2017年23期)2017-02-02 07:17:06
西北工业大学学报(2015年4期)2016-01-19 03:31:47
中国海上油气(2015年3期)2015-07-01 16:32:08
振动工程学报(2014年4期)2014-03-01 01:15:41
