
融入双注意力的高分辨率网络人体姿态估计
2022-02-24 05:07:10罗梦诗叶星鑫
计算机工程 2022年2期
罗梦诗,徐 杨,2,叶星鑫
(1.贵州大学 大数据与信息工程学院,贵阳 550025;2.贵阳铝镁设计研究院有限公司,贵阳 550009)
0 概述
随着计算机视觉技术的发展,人体姿态估计作为人机交互[1]不可或缺的组成部分,逐渐引起研究人员的关注。人体姿态估计任务在不同领域中扮演着不同的角色,被广泛应用于智能监控、医疗康复与体育事业中的人体分析。在人体姿态估计中,通过一张图片或者一段视频对人体的2D 姿态进行估计是一个相当重要的基础阶段,例如人体跟踪、动作认知、3D 姿态的研究或者人机交互应用都需要精确的人体2D 姿态估计作为支撑。因此,对2D 姿态估计的研究尤为重要。
人体姿态估计分为两个步骤进行,即人体目标检测和人体关键检测[2]。目前主要通过深度学习方法[3-4]进行人体姿态估计,而用于人体关键点检测的网络主要为深度卷积神经网络[5],深度卷积神经网络的方法又可细分为关键点热图的估算[6-7]方法和关键点位置的回归[8-9]方法两种。通过对每张图片学习后提取相应的特征信息,然后选择热值最高的位置作为关键点,从而可以学习得到人体的关键点。
2016 年NEWWLL[10]等提出堆 叠沙漏网 络,按照从高到底的分辨率子网[11]串联组成。因此,堆叠沙漏网络是通过下采样和上采样的方式对不同分辨率从高到低,再从低到高进行操作。而此过程不能完全有效地利用空间特征信息,导致部分空间特征信息丢失,从而使输出的高分辨率表征不够完善。文献[12]提出的级联金字塔网络(CPN)则弥补了堆叠沙漏网络的这一缺点,在采用上采样的操作时能够融合低分辨率和高分辨率的特征图信息。
2019 年SUN 等[13]提出了高 分辨率网 络(HRNet),HRNet 摒弃了以往常规网络所用的串联方式,它采用并联的方式将不同分辨率子网从高到底地进行并行连接,在实现多尺度融合时能有效利用特征信息。
尽管HRNet 相比其他高分辨率网络可以得到更好的预测结果,但其在通道分配权重和空间域上分配权重依然存在难点。文献[14]提出的ECA-Net 通过一维卷积实现,避免了降维,能够有效捕获跨通道交互的信息。相比文献[15]的通道注意力,ECA-Net 只增加了少量的参数,可以更轻量、稳定、高效地建模通道关系,从而获得明显的性能增益。
2018 年WANG[16]等提出的 空间注意 力模型最大特点是拥有非局部均值去噪的思想。优点在于针对全局区域进行操作,对全局信息能够得到有效的利用,防止特征信息的丢失或损失。
受以上研究的启发,本文以高分辨率网络作为实验的基础网络架构,在其基础上进行相应的优化,提出一种融入双注意力的高分辨率网络ENNet。通过融合通道注意力机制的残差模块(E-ecablock 模块、E-ecaneck 模块)和结合空间注意力的多分辨率融合模块,增强网络对多通道信息的提取及多尺度融合时对空间信息提取和融合能力。
1 高分辨率网络
高分辨率网络摒弃了以往网络从高分辨率到低分辨率之间的串联方式。高分辨率网络结构总体分为4 个阶段,第一阶段由一个高分辨率子网构成,第二阶段~第四阶段则和第一阶段有所不同,由多分辨率块组成,多分辨率块可分为多分辨率组卷积和多分辨率卷积两种。图1为多分辨率组卷积,图2为多分辨率卷积。将每一阶段的多分辨率子网以并行的方式进行连接,然后在每一子网上反复交换信息进行多尺度特征的重复融合,使网络从始至终保持高分辨率的特征表示,最后通过上采样的方式输出高分辨率的特征表示。
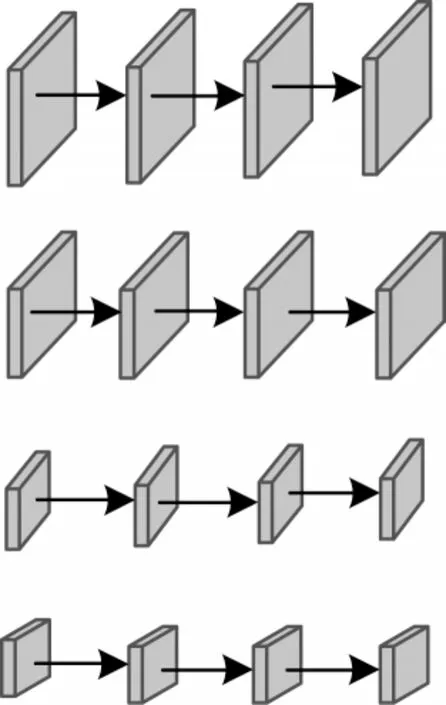
图1 多分辨率组卷积Fig.1 Multiresolution group convolution

图2 多分辨率卷积Fig.2 Multiresolution convolution
2 ENNet 方法
本文以HRNet 网络作为基础网络进行改进得到融入双注意力的高分辨率网络ENNet,其整体的网络结构如图3 所示。融入双注意力的高分辨率网络ENNet 分为4 个阶段,由4 个通过并行连接的从高到低的分辨率子网所构成。每一个子网从上往下,每一级分辨率以1/2 的倍数逐步降低,通道数则以2 倍的速度升高。第一阶段由一个高分辨率子网构成,包含了4 个线性变换的E-ecaneck 残差模块;第二阶段~第四阶段均由改进的E-ecablock 模块和空间注意力机制的融合模块(Non-localblock)组成,其目标是对特征进行更广泛且更深层提取与融合。

图3 ENNet 网络结构Fig.3 ENNet network structure
本文首先通过融入通道注意力构造出E-ecaneck模块和E-ecablock 模块作为基础模块,最大程度地提取更多更有用的通道信息。然后在融入通道注意力机制的基础上融入空间注意力机制中的Non-localblock模块,实现空间信息的有效提取与融合。最后通过上采样操作将经过重复融合的信息表征以高分辨率的形式输出,从而实现人体关键点检测任务和人体姿态估计。
2.1 通道注意力模块的融入
ECA 模块是一种新的捕捉局部跨通道信息交互的方法,它在不降低通道维数的情况下进行跨通道信息交互,旨在保证计算性能和模型复杂度。ECA模块可以通过卷积核大小为K的一维卷积来实现通道之间的信息交互,如图4 所示。
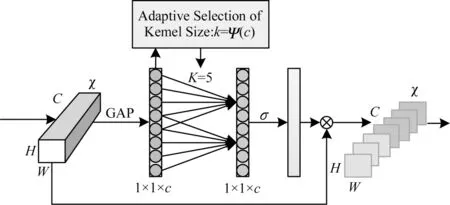
图4 ECA 结构Fig.4 ECA structure
设一个卷积块的输出为χ∈RW×H×C,其中,W、H和C分别表示宽、高和通道数,GAP 表示全局平均池化。ECA 模块通过卷积核大小为k的一维卷积来实现通道之间的信息交互,如式(1)所示:

其中:σ是一个sigmoid 函数;C1D 代表一维卷积;k代表k个参数信息;y为输出信号。这种捕捉跨通道信息交互的方法保证了性能结果和模型效率。
本文参考了ResNet 网络模块中的bottleneck 模块与basicblock 模块的设计方法,将ECABlock 模块融入到高分辨率网络(HRNet)的瓶颈模块(bottleneck)和残差模块(basicblock)中,得到改进的E-ecablock 模块和E-ecaneck 模块,并将其代替原网络的bottleneck 模块与basicblock 模块,从而实现不降低通道维数来进行跨通道信息交互。
本文提出的E-ecablock 模块包含2 个3×3 卷积核尺寸大小的ECABlock 模块和1 个残差连接,如图5 所示。E-ecaneck 模块包含2 个1×1 卷积核尺寸大小的ECABlock 模块、1 个3×3 卷积核尺寸大小的ECABlock 模块以及1 个残差连接,如图6 所示。

图5 E-ecablock 模块Fig.5 E-ecablock module
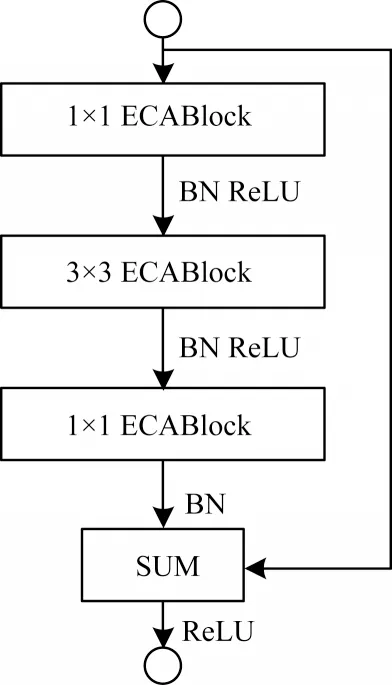
图6 E-ecaneck 模块Fig.6 E-ecaneck module
受文献[17]启发,本文在卷积操作前加入通道注意力模块可以使特征提取得到较好的效果,因此,本文在E-ecablock 模块中的2 个3×3 的卷积操作前加入一个ECABlock 模块,每一次进行卷积操作前先通过对输入特征图的不同通道进行注意力权重赋值得到有意义的特征,然后进行卷积操作后输出,最后将卷积操作后输出的结果与初始输入的特征信息通过残差连接进行求和再输出,从而获得更优的通道特征提取效果。
为了使通道信息的提取效率增高,采用相同的方法,在E-ecaneck 模块中的每一层卷积操作前添加ECABlock 模块。通过ECABlock 模块对特征图通道维度进行降低和提高,并多次卷积操作进行特征提取,使网络得到更多有用的特征信息。
2.2 空间注意力融合模块的融入
Non-localblock 模块是空间域注意力模型的核心模块,它作为非局部的空间注意力方法,不仅局限于局部范围,而是针对全局区域进行操作,计算公式如式(2)所示:

其中:i和j是某个空间位置;C(x)是归一化因子,x和y分别为尺寸大小相同的输入和输出信号;xi为向量,f(xi,xj)是计算xi与所有xj之间的相关性函数;g(xj)计算输入信号在位置j处的特征值。
通过式(2)可得到式(3):

其中:z为最后的输出;Wz是由1×1 的卷积操作实现的线性转换矩阵。
本文采用空间注意力模块(Non-localblock)模块对第二阶段~第四阶段的融合模块进行改进,在融入通道注意力的基础上将其加在各个分辨率表征融合前,如图7 所示。Non-localblock 模块是在全局区域进行操作,可以扩大感受野。因此,它能有效提取更多有利信息进入不同分辨率表征的信息交互环节,即先提取尽可能多的有用信息,再进行多尺度融合,从而使多尺度特征融合时的效果得到较好的改善。

图7 融入空间注意力的融合模块Fig.7 Fusion module with spatial attention
3 实验结果与分析
3.1 COCO 数据集
在COCO2017 数据集上对本文方法进行评估。数据集包含了200 000 张图片,其中含有17 个关键点的人体样本为250 000 个。在57K 张图像的训练集上进行训练,在5K 张图像的验证集上进行验证,在20K 张图像的测试集上进行测试。在COCO 据集中人体姿态的17 个关键点分别是鼻子、右眼、左眼、右耳、左耳、右肩、右肘、右手腕、左肩、左肘、左手腕、右臀、右膝盖、右脚踝、左臀、左膝盖、左脚踝。
3.2 图像预处理
由于MS COCO2017 数据集中收录的原始图片大小不一,需对图像进行预处理再进行训练。本文需对两种尺寸大小的图像训练进行对比,因此,预处理过程分为如下2 个部分:
1)从数据集图像中以主要人体髋部为中心进行裁剪,图像的尺寸大小裁剪为256×192,并调整为固定比例,高宽的比例为4∶3,便于网络训练。
2)使用随机旋转(-45°,45°)和随机缩放规模(0.65,1.35)的数据增强方式来对数据进行处理。从数据集图像中以主要人体髋部为中心进行裁剪,按照高宽为4∶3 的比例,将图像的尺寸大小裁剪为384×288,从而达到网络训练所需的输入效果。
3.3 评估标准
本文在COCO2017 数据集上进行实验验证,评估方法有以下2 种:
1)采用MS COCO 官方给定的关键点相似性(OKS)进行评估。
2)采用正确关键点百分比(Percentage of Correct Keypoints,PCK)[18]作为实验评估指标。
3.4 实验环境与实验设置
本文实验使用的软件平台是Python3.6,服务器的系统是Ubuntu18.04 版本,显卡是NVIDIA GeForce GTX 1080Ti,深度学习框架是PyTorch1.6.0。
在本文实验中,选用Adam 优化器对模型进行优化。将训练周期设置为200,训练批量大小设置为20,学习率为0.001。
3.5 实验过程
本文方法使用深度卷积神经网络的方法中的关键点热图的估叶算法,用多分辨率的热图(Heatmap)图像去学习关节点的坐标,此时需要估算图像中每个像素对应的概率的值,将与关节点最接近的像素点处的概率值记为1,与关节点距离最远的像素点处的概率记为0,若所检测到的像素点处的概率越接近1,则越接近目标点。对图像进行训练后将所得到的热图结果映射到原图像,经过整合,得到人体对应的各个关节点的坐标位置,从而实现关键点的检测来完成人体姿态估计的任务。
Heatmap 示意图如图8 所示。

图8 Heatmap 图像示意图Fig.8 Schematic diagram of Heatmap image
3.6 实验验证与分析
本文通过对原网络进行改进和优化后,在COCO VAL 2017 数据集上进行实验。将输入尺寸为256×192时结果与其他方法在同一数据集上的结果进行比较,如表1 所示。从表1 结果可以看出,本文方法ENNet相比于CPN、CPN+OHKM、SimpleBaseline-152[19]、SimpleBaseline-101[19]、SimpleBaseline-50[19],在mAP 上的估计精确度都得到了较好的提升。相比于HRNet-32,AP50提高了4.1%,AP75提高了3%,APL提高了3.4%,APM提高了3.1%,mAP 整体提高了3.4%。

表1 不同方法在COCO VAL 2017 数据集上的对比结果Table 1 Comparison results of different methods on COCO VAL 2017 dataset
通过实验结果可以看出,本文方法在HRNet-32上引入双注意力机制,不仅在原网络的基础上提高了关键点的估计精确度,更进一步地提升了网络在高精度要求下的关键点估计精确度。
表2 是本文方法在COCOtest-dev2017 数据集上与其他方法测试结果的对比实验。实验结果表明,与文献[20-21]、CPN、CPN+OHKM、SimpleBaseling、HRNet-32 等方法相比,在输入尺寸相同的情况下,本文方法在降低网络复杂度的同时,mAP、APL和APM的估计精确度都具有较好的效果。

表2 不同方法在COCOtest-dev2017 数据集上的对比结果Table 2 Comparison results of different methods on COCOtest-dev2017 dataset
表3 是本文方法在COCO2017 验证集上图像输入尺寸均为384×288 时与不同网络模型对关键点估计精确度的对比。通过计算关键点正确估计的比例PCK 来对比不同网络模型对人体关键点的估计精确度。其中头部、肩部、肘部、腕部、臀部、膝部和脚踝分别代表头部5 个关节点平均值、肩部两关节点平均值、肘部两关节点平均值、腕部两关节点平均值、臀部两关节点平均值、膝盖两关节点平均值和脚踝两关节点平均值,平均代表所有关节点平均值。实验结果表明,本文方法具有较高的平均估计精确度,在单个关节点的估计精确度上都有一定程度的提升。
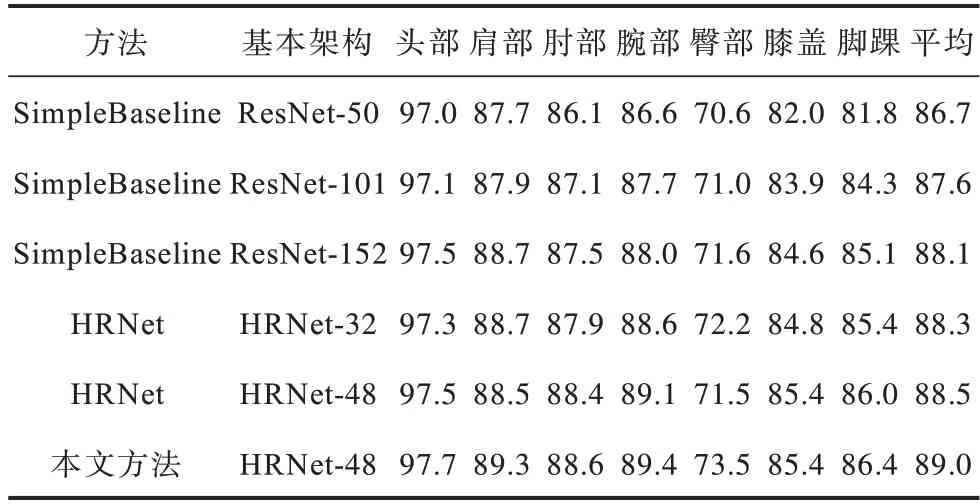
表3 不同网络对不同关键点检测的PCK 值比较Table 3 Comparison of PCK values detected by different networks for different key points %
3.7 模块分解实验
本文实验通过在通道注意力的基础上引入空间注意力来对网络模型(基础网络架构为HRNet-32时)进行改进,最终使平均估计精确度提高3.4%。在COCO VAL2017 数据集上对本文方法进行模块分解实验,其结果如表4 所示。

表4 融入双注意力方法的模块分解实验结果比较Table 4 Experimental results comparison of module decomposition with dual attention method
通过引入通道注意力构造E-ecaneck 模块和E-ecablock 模块作为基础模块,提取特征图的不同通道信息,网络的平均估计精确度相比较于高分辨率网络(HRNet)提升1.2%。单独将空间注意力引入到网络的多分辨率融合阶段,网络的平均估计精确度相比较于高分辨率网络(HRNet)提升1.6%,相比较于仅含有通道注意力的网络平均估计精确度提升了0.4%。
在引入通道注意力的基础上引入空间注意力的网络,相比较于原HRNet,平均估计精确度提升3.4%,在仅含有通道注意力融合方法基础上获得1.4%的性能提升,在仅含有空间注意力融合方法基础上获得1%的性能提升。
3.8 可视化实验分析
图9 为本文方法对COCO2017 数据集测试的部分结果展示。从图9(a)~图9(d)可以看出,在相同光照情况下,图像中人体无遮挡时可准确地检测出各个部位的关键点,只有当图像中人体存在严重遮挡时检测出的关键点出现稍微的偏差。图9(a)和图9(c)表明,当图像中人体无遮挡时,在不同光照情况下都可以检测出准确的关键点位置。图9(e)和图9(f)表明,在针对不同分辨率的图像时,网络仍然可以得到准确的结果。

图9 本文方法在COCO2017 数据集上的测试结果Fig.9 Test results of this method on COCO2017 dataset
以上实验结果表明,在不同光照条件、人体是否遮挡、不同图像分辨率的情况下,本文方法有一定的鲁棒性,能准确地检测出人体各个关键点,从而估计人体的姿态。
4 结束语
本文提出一种融入双注意力的高分辨率人体姿态估计网络ENNet。以高分辨率网络(HRNet)为基础网络架构进行优化,设计2 种注意力模块E-eacblock 和E-ecaneck 作为基础模块,在多分辨力融合阶段融入空间注意力,从而使网络在进行特征提取时可以增强网络对多通道信息的提取,改善多分辨率阶段特性信息的融合能力。在公开数据集MS COCO2017 上的测试结果表明,相比于HRNet,本文方法的mAP 综合提高了3.4%,有效改善了网络多分辨率表征的信息融合能力。本文网络模型复杂度还有待提高,如何在保持估计精确度较高的前提下降低模型参数量和复杂度,将是下一步的研究方向。
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16 07:36:56
今日农业(2021年8期)2021-11-28 05:07:50
雷达学报(2020年3期)2020-07-13 02:27:16
数学物理学报(2019年3期)2019-07-23 01:15:40
家庭影院技术(2018年9期)2018-11-02 05:31:32
自动化学报(2017年5期)2017-05-14 06:20:52
成都信息工程大学学报(2017年6期)2017-03-16 03:04:32
太空探索(2015年8期)2015-07-18 11:04:44
浙江大学学报(工学版)(2015年1期)2015-03-01 01:17:19
中国卫生(2014年2期)2014-11-12 13:00:16
