
基于改进语音处理的卷积神经网络中文语音情感识别方法
2022-02-24 05:07陈章进屠程力
计算机工程 2022年2期
乔 栋,陈章进,2,邓 良,屠程力
(1.上海大学 微电子研究与开发中心,上海 200444;2.上海大学 计算中心,上海 200444)
0 概述
语音情感识别作为人机交互领域的重要技术,能使机器理解人类的情感状态,并使智能机器具有感知情感的能力。目前,语音情感识别越来越受到重视[1-3],语音信号中用于情感识别的特征包括能量、音高、过零率、共振峰、语谱图[4-5]、梅尔倒谱系数等[6]。将这些低层特征以语音帧为单位进行提取,并把它们在语音段的全局统计特征值输入到分类器中进行情感识别。传统的语音情感识别方法通常使用人工选取的特征输入浅层机器学习模型进行分类识别,例如高斯混合模型[7]、支持向量机[8]、隐马尔科夫模型[9]等。支持向量机和隐马尔科夫方法在机器学习中经常被使用,具有较高的确定性。而人的情感具有较强的复杂性和不确定性,因此在语音情感识别中表现较差。随着机器学习技术的应用和发展,研究人员开始使用神经网络分类器来执行各种语音情感识别任务,神经网络在处理不确定和非线性映射问题方面具有独特的优势,并且可以检测其他分类技术无法检测到的规律和趋势,是模式识别中使用最广泛且最成功的多层前馈网络。由于语料库中没有统一的标准,因此识别效果差异很大[10-12],人类情感信息的复杂性和不确定性导致卷积神经网络识别中文语音情感的准确率仍然不高。
对标准的中文语音情感库CASIA 而言,仅对卷积神经网络进行改进的方法,其识别准确率不足60%[13]。在卷积神经网络的基础上,为缓解过拟合,有研究人员使用参数迁移的方法,并加入了数据增强[14],使其在CASIA 数据集上的识别准确率提高到了72.8%。文 献[15]通过改进Lenet-5网络,在CASIA 数据集上取得 了85.7% 的识别率[15]。文献[16]在卷积神经网络的基础上加入循环神经网络层,将CASIA 数据集上的识别准确率提升至90%左右[16]。
为进一步提高中文语音情感的识别效果,本文提出一种基于卷积神经网络的中文语音情感识别方法。通过改进MFCC 特征提取方法以及加入高斯白噪声进行数据增强,提高识别效率。同时,建立一种轻量化的Trumpet-6 卷积神经网络模型用于中文语音情感识别,提高识别准确率。
1 语音情感识别的相关研究
1.1 语音的MFCC 特征提取
在语音识别领域,MFCC 是最常用的语音特征之一。通过对人类听觉机制的研究发现,人耳对不同频率的声波具有不同的听觉敏感性,低频率的声音往往会掩盖高频率的声音,低频段声音掩蔽的临界带宽小于高频段。因此,根据从密集到稀疏的临界带宽,从低频到高频设置一组梅尔带通滤波器对输入信号进行滤波[17],以梅尔带通滤波器输出的信号能量作为信号的基本特征,对语音的输入特征进行处理。由于MFCC 特征不依赖信号的性质,对输入信号没有任何假设和限制,因此,该参数具有更好的鲁棒性[18],更符合人耳的听觉特性,在信噪比(Signal-to-Noise Ratio,SNR)降低的情况下仍具有良好的识别性能[17]。
MFCC 特征与频率的关系可用式(1)近似表示:
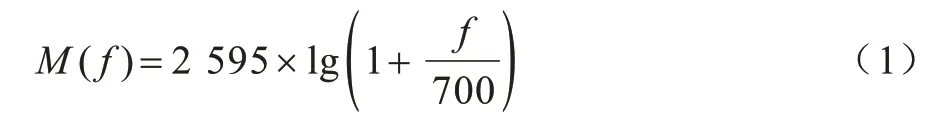
MFCC 特征的提取过程如图1 所示。

图1 MFCC 特征提取过程Fig.1 MFCC feature extraction process
分帧操作把N个采样点压缩为1 个单位,即1 帧,对这1 帧加窗(汉明窗等)计算后,再进行后续处理。帧与帧之间有重叠部分,是为了使帧与帧之间平滑过渡,保持其连续性。由于预加重操作实际相当于高通滤波,因此分帧加窗后得到的数据能够为后续时频变换初始化数据。
1.2 高斯白噪声
如果一个噪声的功率谱密度为常数,即功率谱均匀分布,则称其为白噪声;若此白噪声的幅度分布服从高斯分布,则称其为高斯白噪声。本文采用高斯噪音,是为了更好地模拟未知的真实噪音,因为在真实环境中,噪音往往不是由单一源头造成,而是很多不同来源的噪音复合体[19]。假设把真实噪音看成非常多不同概率分布的随机变量加合,并且每一个随机变量均独立,那么根据中心极限定理,其归一化和则随着噪音源数量的上升,呈现高斯分布[20]形态。因此,使用合成的高斯白噪声为合理的近似仿真。
1.3 数据增强
在深度学习中,数据与模型均为影响最终训练结果的重要方面。在神经网络训练之前对数据集进行数据增强,是有效缓解模型过拟合的方式。通过对输入特征图进行数据增强,可以让网络模型将经过处理后的同一幅图片当成多幅图片,扩充数据集的样本数量[21-23]。通过给神经网络模型输入足够的图片,可以保证神经网络模型能够提取足够多的有效信息。
数据增强的传统方法包括对图片进行旋转、平移、翻转等。由于在语音识别领域,图片是提取语音信息后所得数值矩阵产生的图像,因而具有一定的声音特性。例如,对于图像来说,横轴和纵轴没有实际意义,而对于MFCC 特征矩阵来说,横轴代表时间,纵轴代表通频带上的滤波器编号。因此,传统数据增强方法在处理图像时所运用的图像旋转、平移、翻转等破坏了语音信号的连续性,导致声音特性出现混淆与丢失的现象,准确率难以提高[14]。而现阶段的研究较少关注中文语音情感识别数据增强方法的改进。
2 基于卷积神经网络的中文语音情感识别方法
2.1 改进的数据处理方法
本文使用的CASIA 数据集为短句形式,句子长度约为1~2 s,语音连续特征相对于长语音句较少,因此将语音信号转化为图片,并利用卷积神经网络进行语音情感识别。
本文对语音情感数据集的MFCC 特征提取以及预处理方法进行了改进,主要包括分帧加窗的采样点个数选取及高斯白噪声数据增强这两个方面。
2.1.1 分帧加窗的采样点个数选取
分帧加窗对特征图的影响如图2 所示,将语音信号按S个采样点取走分帧,经过后续加窗(汉明窗w(s))、快速傅里叶变换等操作,最终变为MFCC 特征图中的一列,S的值不同,MFCC 矩阵的列数就不同。当S=512 时,横轴L的长度为252;当S=2 048 时,L仅为63。
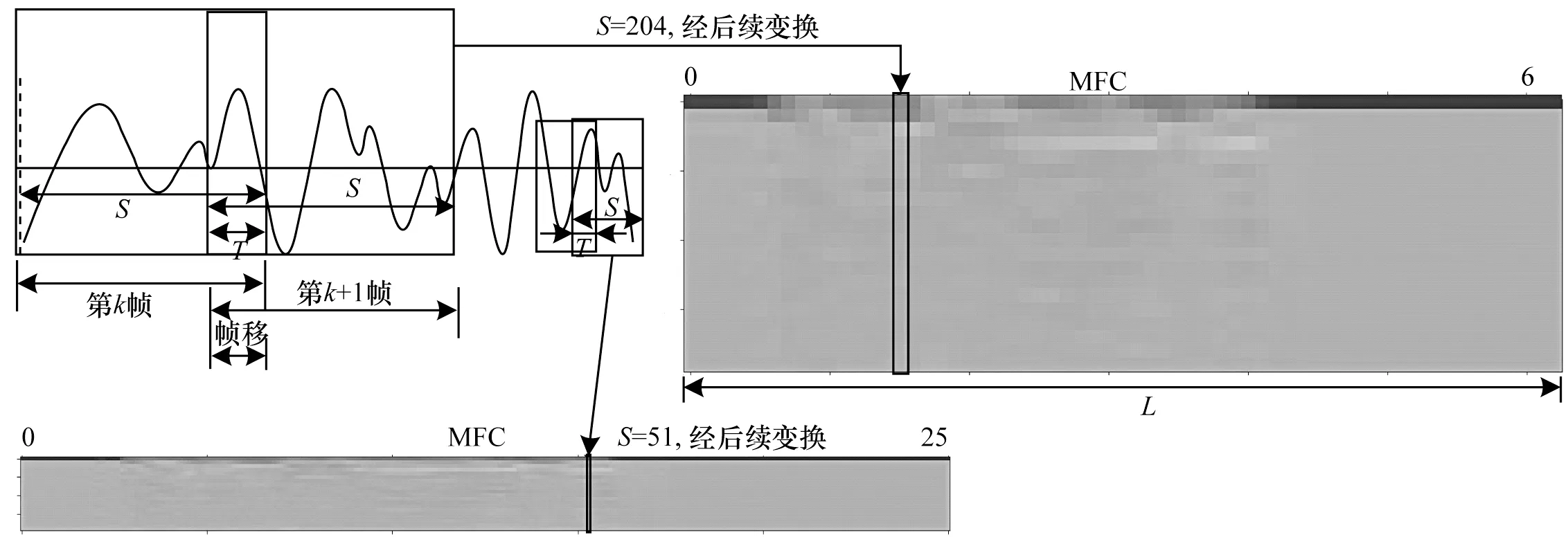
图2 分帧加窗对特征图的影响Fig.2 Influence of framing and windowing on feature map
分帧加窗直接影响特征图大小,经过归纳,计算公式如式(2)所示:

其中:L为特征图横轴长度;D为语音信号总的采样点个数,信号长度为2 s 时共有32 000 个采样点;S为帧长;T为帧移。
对于分帧加窗的采样点个数,以往传统的方式习惯选择2 的整数次幂,如256 或512。这种较少采样点的设置会使生成的MFCC 矩阵的横轴,即代表时间的轴过长,导致神经网络输入特征图过大,而设置过多采样点又会令特征图上每个像素点所代表的压缩后声音特征不明显,识别准确率下降。因此,本文经过实验后,将采样点确定为2 048,并视为单帧可容纳采样点的上限,将其作为帧长。同时,帧移设置为1/4 帧长,即512 个采样点。将帧内语音信号y(s)与汉明窗w(s)叠加[23],得到分帧加窗后的信号y′(s),计算公式如式(3)所示:

将一段语音Y[D]分帧提取MFCC 特征的流程如算法1 所示。
算法1分帧加窗提取MFCC 流程算法


MFCC 矩阵纵轴的长度由MFCC 特征提取时设定的滤波器个数决定,一般设定为22~26 个。本文通过对比发现,将其取整设定为20 并无明显性能下降,故最终选择滤波器个数为20。最终,经过归一化得到20 像素×63 像素的单通道特征图。
2.1.2 高斯白噪声数据增强
由于训练数据较少,训练出的模型往往泛化性差,容易过拟合,准确率不高。对原有1 200 条数据进行数据增强发现,传统的数据增强方法会破坏声音的连续特征,而高斯白噪声则均匀叠加在原有音频上,因此本文采用加入高斯白噪声作为数据增强方法。此外,由于模型是在有噪声的环境下进行训练,因此得到的神经网络模型具有一定的抗噪性。由于原有数据集的信噪比为35 dB,因此加入信噪比大于35 dB 的噪声可认为没有噪声。所以,在加入高斯白噪声进行数据增强时,需固定噪声的信噪比,并使其小于35 dB,如此也便于分析加入不同信噪比与样本数量的数据增强实验效果。生成一个标准高斯随机数较为容易,令该噪声(设其声音长度为N)乘以系数k即可得到一个固定信噪比的噪声。计算语音信号的功率PS和生成的噪声功率Pn1的计算公式如式(4)~式(5)所示:

给定固定信噪比X,求解k值,假设Pn为需要的信噪比的噪声功率,则有:

对式(6)进行整理可得:

继续整理,得到k值如式(8)所示:

高斯白噪声数据增强过程如图3 所示,将求出的不同信噪比对应的ki(i=1,2,…,N)乘以标准高斯噪声,再和纯净音频中提取的MFCC 特征图进行线性叠加。由于高斯白噪声为随机值,叠加后的特征图对应像素的值发生了非线性的随机变化,因此可以当作完全不同的图片。随后,将加过噪声的MFCC 特征图与纯净MFCC 特征图一同送入数据集[24]。
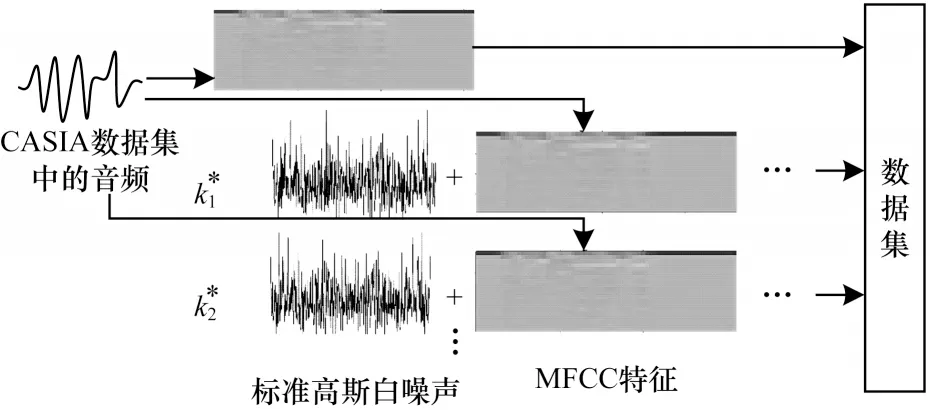
图3 高斯白噪声数据增强Fig.3 Gaussian white noise data augmentation
2.2 卷积神经网络设计
卷积神经网络一直是研究和应用的热门技术。不同于传统的全连接神经网络,卷积神经网络在进入全连接层进行标签的配对之前要先经过若干个卷积层和池化层,并对输入特征进行压缩和提取,从而简化训练过程。卷积操作可以视作滤波,而完成特征提取的卷积核即为滤波器。直接卷积的计算公式如式(9)所示:

其中:f是非线性激活函数表示偏移值;O(x,y)表示输入特征图坐标(x,y)处的值;w(kx,ky)表示卷积核坐标(kx,ky)上的权重值;ln(x+kx,y+ky)表示输出特征图坐标(x+kx,y+ky)上的输入值;kx、ky表示卷积核的尺寸;fi表示第i幅输入特征图;Nfi表示输入特征图的数目。
池化通常分为最大池化和均值池化,池化的作用是取局部区域内的某个值,将其他值舍弃,从而达到压缩图像的目的。本模型采用最大池化,其计算公式如式(10)所示:
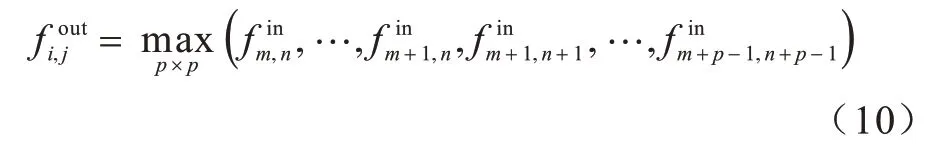
其中:fout表示输出图像(i,j)位置的值;fin表示输入图像中(i,j)位置的值;p表示池化核的尺寸。
对神经网络来说,理论上通过加深网络的深度,同时选用较小的卷积核可以取得更好的训练效果,但随着卷积神经网络的发展,3×3 大小的卷积核被验证为较合适的尺寸,因此得到广泛使用。本模型采用的卷积方式为二维卷积,卷积核尺寸均采用3×3,池化层采用最大池化,池化核的尺寸也为3×3。但是在卷积核已经很小的前提下,加深网络深度会导致待训练参数过多,存在过拟合的风险。
本文设计一种轻量级的Trumpet-6 卷积神经网络模型,其处理流程如图4 所示。

图4 卷积神经网络处理流程Fig.4 Processing flow of convolution neural network
传统经典网络,如Alexnet、MobilenetV2 等由于其本身用于图像处理,因此存在输入层卷积核较多、所采用滑动步长较大等特点。例如,Alexnet 的输入层有96 个卷积核,步长为4,MobilenetV2 的输入层步长为2,这两者由于容易造成过拟合,因此均不适用于处理语音信息。但将图像处理领域的经典神经网络迁移至语音处理领域已经是常用方法。因此,有必要设计一个语音情感识别领域的网络。根据语音的特性,在设计之初进行如下改进:1)由于MFCC特征图尺寸相比图像处理领域来说较小,因此输入层选用较少卷积核;2)由于声音特征具有连续性,因此将输入层滑动步长设定为1,而后续图像经过池化层压缩后,才可以将滑动步长提高为3 来提升训练效率。为了平衡准确率与训练效率,将第1 次池化的插入位置选择在第2 个卷积层之后,并通过实验进一步确定网络层数与具体超参数。
将提取到的MFCC 特征图送入输入层,卷积神经网络模型的卷积层一般用于提取浅层特征,将全连接层来提取目标的深层次特征。卷积神经网络模型的卷积层数初始设置为2,第1 个卷积层作为输入层,这2 个卷积层均为32 个卷积核,目的是作为特征图输入并提取浅层特征。卷积神经网络进行最大池化后为3 层卷积层,均使用64 个卷积核。随后再次进入最大池化层进行压缩,最后一层卷积层利用了128 个卷积核,能够将之前的特征图进行高层次提取。输入的特征图经过拉直层变为一维图像后,最后输入全连接层进行分类,全连接层有6 个神经元,对应6 种情感标签。
卷积层感受野只与核大小和滑动步长有关,三者间的关系如式(11)所示:

其中:Ri是第i层卷积层的感受野;Ri+1是(i+1)层上的感受野;si是第i层卷积的步长;Ki是第i层卷积核的大小。这样在卷积核大小已经确定的情况下,在第1 次池化后适当增大滑动步长可以增大感受野和提高训练效率。另外,将卷积层和池化层均设置为全零填充,从而尽可能还原输入特征图的尺寸,保留原有信息。全连接层中所用的分类器是softmax 分类器[25-26]:

其中:oi为全连接层的输出值;Pi是softmax 分类器的输出值,共有i个,对应i个标签的概率,本文中i取6,输出值[P1,P2,P3,P4,P5,P6]为6 种情感分别对应的概率值,取出其中的最大值对应的情感标签并输出,便完成了一次识别。
此外,激活函数全部使用ReLU,将除输入层外的所有卷积层均加入L2正则化,并以0.2的丢弃比例来缓解过拟合,损失函数使用交叉熵,采用Adam 优化器,学习率设置为0.001。经过计算,模型共有176 550个待训练参数。网络具体结构如表1所示。
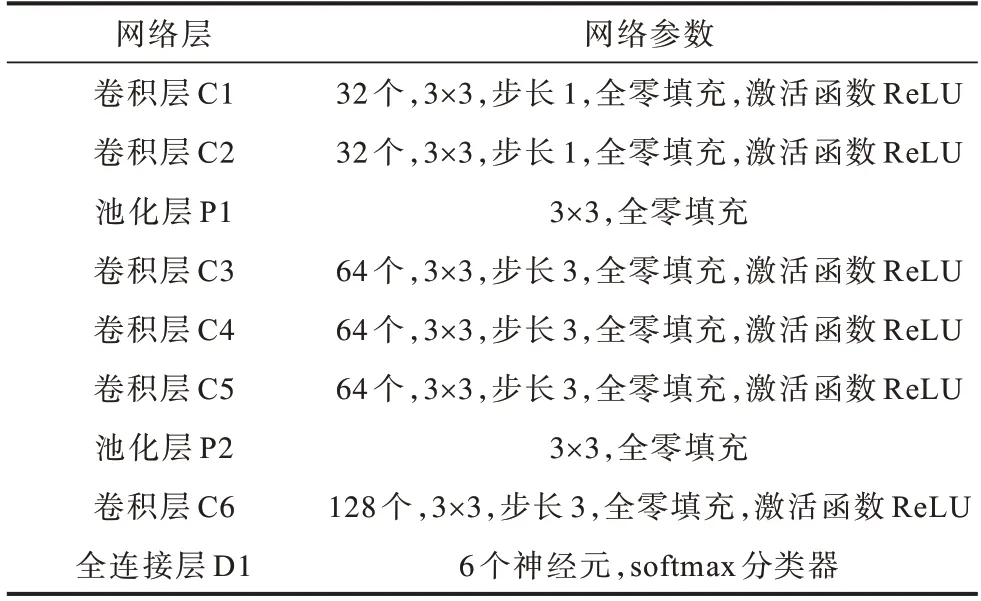
表1 Trumpet-6 卷积神经网络结构Table 1 Structure of Trumpet-6 convolutional neural network
3 实验与结果分析
3.1 实验条件
本课题的硬件实验平台为AMD Ryzen 7 3700x+NVDIA GeForce RTX2070 super,CPU 主频为3.6 GHz,GPU 显存为8 GB。使用Python 语言和TensorFlow 2.0的GPU 版本对神经网络模型进行搭建。
本文在确定改进方向时设计了3 组实验:第一组研究采样点大小对训练时间以及准确率的影响;第二组研究卷积结构对训练效果的影响;第三组研究添加高斯白噪声进行数据增强的方法与传统方法进行数据增强对测试集准确率的影响。
CASIA 汉语情感语料库由中国科学院自动化所录制,共包括4 个专业发音人,包含生气、高兴、害怕、悲伤、惊讶和中性6 种情绪。该数据集录制时采用16 kHz 采样和16 bit 量化,在信噪比为35 dB 的纯净环境中录制,本次实验收集到1 200 条语句,其中包含了50 句相同文本。
对1 200 条的CASIA 数据集进行数据乱序。由于本文中所使用的CASIA 数据集数据量较小,初始为1 200 条,而加入数据增强后最多为4 800 条数据。因此,针对较小数据集(数据量在万以下),主流的数据集划分比例为训练集与测试集7∶3,或训练集、验证集、测试集比例为6∶2∶2,其中,验证集主要用于调节卷积核个数、卷积核大小等超参数。由于本文除第2 个实验是探究卷积神经网络结构对测试集准确率的影响外,第1 组和第3 组实验主要是在同一平台上进行纵向比较以确定最佳的改进方向,在这个过程中使用验证集调节超参数无法控制单一变量,因此第1 组和第3 组实验把数据集划分为训练集与测试集7∶3,而第2 组实验数据集划分为训练集、验证集、测试集6∶2∶2。
3.2 实验结果
3.2.1 采样点影响实验
根据采样点个数为2 的整数次幂的规则,分别采用了256、512、1 024、2 048、4 096、8 192 个采样点进行分帧、加窗。仅对原有数据集进行实验,得到的MFCC特征图经过在2.2节中提出的Trumpet-6神经网络识别,统计模型收敛时的迭代轮数,测试集准确率以及平均单个样本的识别耗时,结果如表2 所示。
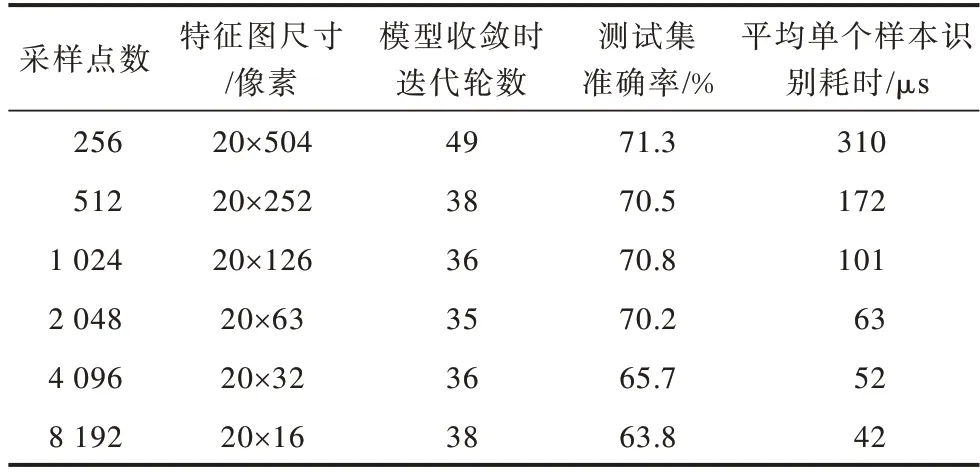
表2 采样点影响实验的结果Table 2 Result of experiment on the influence of sampling points
通过对比发现,采用256 个采样点进行分帧的模型收敛速度最慢,约为50 轮,其他5 组相近,均在30~40 轮左右。经过统计,这6 次实验的单个样本训练时间分别约 为310 μs、172 μs、101 μs、63 μs、52 μs、42 μs,可以看出,传统的选用256 个和512 个采样点进行分帧的训练耗时远大于选用1 024 个以上采样点的分帧方法。继续增大分帧时采样点大小,如将采样点设置为4 096、8 192,输入特征图尺寸会进一步缩小,进而减少训练时间。但从表2 中可以看出,继续增大采样点个数为4 096、8 192,会使模型的准确率严重下降,即单帧可容纳的采样点到达了一个上限、同时识别速度提升不大。综合考虑,选取2 048 个采样点较合适。相比于传统256 个采样点分帧的单个样本平均识别约310 μs 而言,2 048 采样点只需63 μs 即可完成一次训练或识别,处理效率提升了79.7%,准确率仅下降1.1 个百分点。
3.2.2 模型卷积结构实验
本组实验采用CASIA 原始数据集1 200 条,分帧采样点选取2 048,特征图尺寸为20×63,将数据集比例划分为训练集、验证集、测试集6∶2∶2,来对比卷积层数对测试集准确率的影响。具体实验方法为:建立3~10 层卷积结构的网络模型,并通过验证集调节超参数,找出其中测试集准确率最高的模型,统计测试集准确率和收敛时迭代轮数,模型的训练结果如表3 所示。
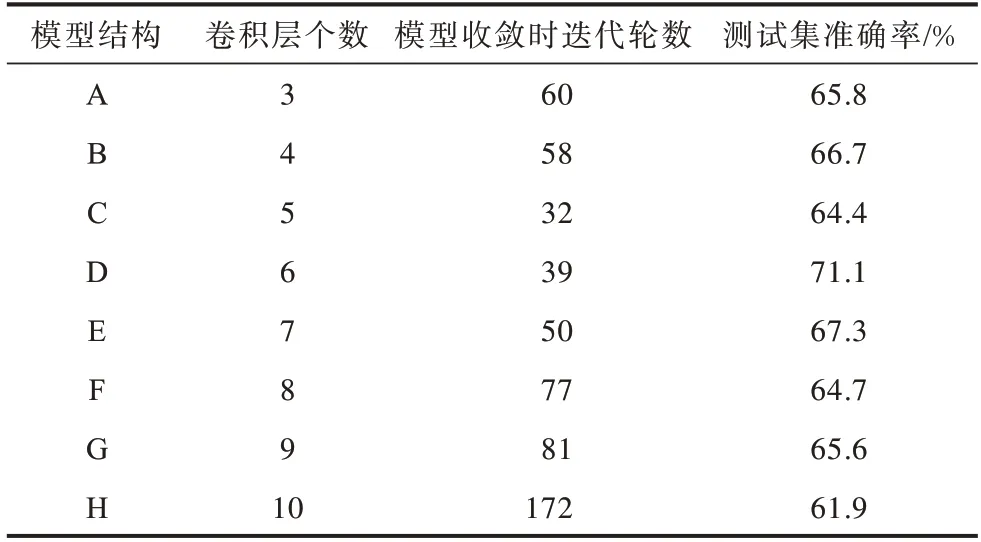
表3 模型卷积结构实验的结果Table3 Result of model convolution structure experiment
由表3 可知,6 层卷积结构的模型D 是相对而言更为优秀的网络结构,继续增加卷积层会使网络模型变复杂,泛化能力变差,从而导致测试集准确率降低。为得到一个较为简化的模型结构,将模型D 确定的超参数,如卷积核个数,向下取一个2 的整数次幂。经过调整的模型,迭代轮数为35,测试集准确率为70.2%,将其作为2.2 节提出的Trumpet-6 模型。
3.2.3 数据增强实验
不加噪声的MFCC 特征图与加入信噪比为5 dB高斯白噪声后的MFCC 特征图对比如图5 所示。由图5 可知,加入噪声后的MFCC 特征图的语音特征虽然被噪声淹没,但仍保留了一部分肉眼可见的特征。

图5 无噪声与5 dB 噪声的MFCC 特征图Fig.5 MFCC feature maps of non-noise and 5 dB noise
本组实验首先对4 种数据增强方法进行了对比,S1~S3 是传统数据增强方法,S4 为添加高斯白噪声的数据增强方法。S1组实验对MFCC特征图进行旋转(旋转角度为顺时针旋转15°);S2 组实验对特征图进行随机平移(水平或竖直平移图片宽度的0~10%);S3 组实验对特征图进行随机缩放(缩放比例为0~10%);S4 组实验对原音频文件加入信噪比为5 dB 的高斯白噪声。数据增强的扩充量与初始数据集相同,为1 200 条,即总共2 400 条数据,数据增强后的数据集划分方式采用了与文献[24]相同的方式,即扩充全部数据集后再将数据集划分为训练集与测试集7∶3。训练结果如表4所示。

表4 数据增强方式对准确率的影响Table 4 Influence of data enhancement methods on accuracy
由表4 可知,高斯白噪声进行数据增强的测试集准确率明显好于平移、缩放等传统数据增强方法。随后,在原有1 200 条CASIA 数据集的基础上,分别设置不加高斯白噪声的1 200 条语音,与加入信噪比为5 dB 的噪声进行数据增强的2 400 条语音、加入3 dB 和5 dB 噪声共3 600 条语音和同时加入3 dB、5 dB、10 dB 噪声的共4 800 条语音进行对比,训练结果如表5 所示。

表5 高斯白噪声数据扩充量对准确率的影响Table 5 Influence of Gaussian white noise data expansion on accuracy
由表5 可知,这4 组实验的模型收敛后,测试集准确率分别约为70.2%、80.8%、90.2%和95.7%。在同时加入3 dB、5 dB、10 dB 噪声进行数据增强后达到上限,此时共有4 800 条数据,继续增强数据收效甚微,此时模型的测试集准确率与训练集准确率基本吻合,有效缓解了过拟合。
3.3 本文方法有效性验证及与其他方法的对比
使用2 048 采样点分帧、加窗,输入图尺寸大小为20像素×63像素,并对初始1 200条CASIA 数据集加入3 dB、5 dB、10 dB 噪声进行数据增强,共得到4 800 条数据,使用网络模型Trumpet-6 作为最终的识别方法。最终在CAISA 数据集上效果如图6 所示。
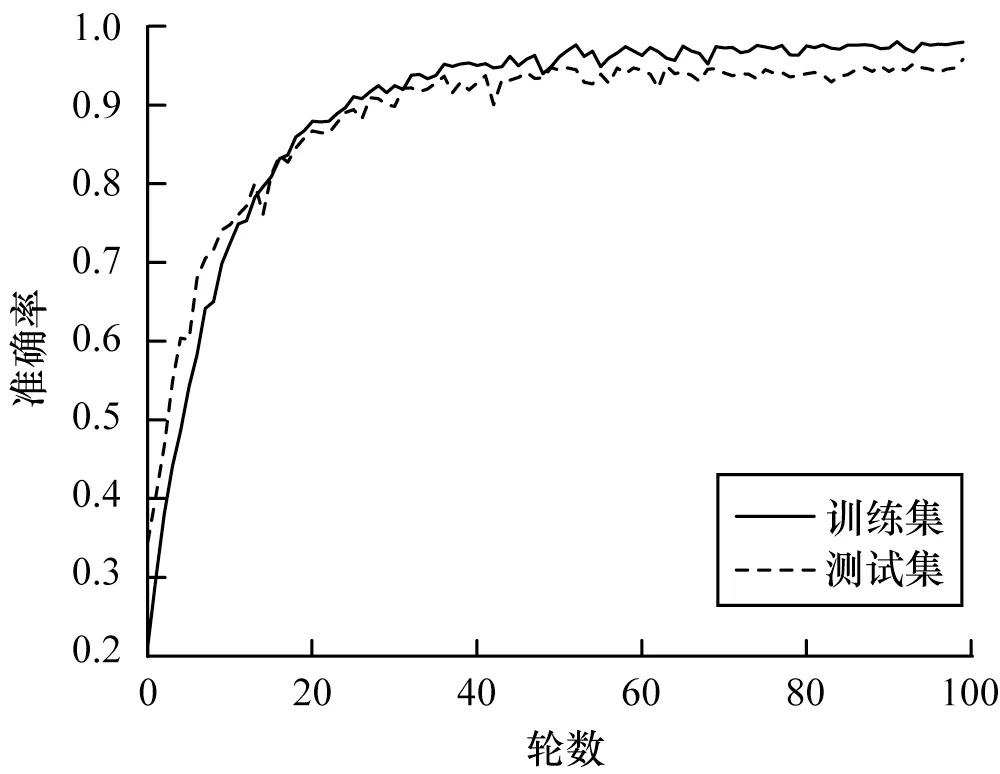
图6 基于卷积神经网络的中文语音情感识别结果Fig.6 Chinese speech emotion recognition results based on convolutional neural network
除了与在CAISA 数据集上进行测试外,为进一步验证本文方法的有效性与泛用性,将本文方法分别在采用本小组录制的中文语音情感库与国际上通用的经典语音情感库上进行实验,并对比本文与其他方法在迁移至自建数据集和上经典语音情感数据集上的实验结果。此外,将上述3 种库混合,进行方法迁移实验。由于混合库的效果不易于与其他文献所提方法效果直接比较,因此将本文方法与文献所提方法尽量复现并对比,本部分的数据集划分比例依旧为训练集与测试集7∶3。
3.3.1 在CASIA 中文语音情感库下的对比结果
由于复现文献中的方法存在一定的困难与误差,因此本节把本文方法与近年来针对CASIA 中文语音情感库的识别方法,包括文献[13-16]的结果直接进行对比。其中,文献[13]为1 200 条数据,训练集与测试集比例为8∶2,进行20 轮左右收敛;文献[14]为1 200 条数据,经过数据增强后为3 600 条,训练集、验证集、测试集比例为8∶1∶1,未给出其最优方法模型收敛时迭代轮数,但文中模型收敛均在1 000 轮左右;文献[15]为1 200 条数据,训练集与测试集比例为9∶1;文献[16]为7 200 条数据,训练集、验证集、测试集比例为6∶2∶2,且未给出模型收敛时迭代轮数,对比结果如表6 所示。

表6 不同方法在CASIA 中文语音情感库下的效果对比Table6 Effect comparison of different methods in CASIA Chinese speech emotion database %
由表6 可以看出,文献[13]所提识别方法在模型收敛时的迭代轮数最少且速度最快,但其准确率只有55.8%(文献[13]中采用的指标为错误识别率,为44.2%)。本文所提识别方法的模型收敛速度略低于文献[13]的方法,为50 轮,高于其他3 种,且准确率最高,达到了95.7%。
3.3.2 迁移至自建情感库的对比结果
本小组成员共5 人,对中性、生气、害怕、高兴、悲伤5 种情感(CASIA 与EMO-DB 共有的5 种情感),每种录制20 条,共500 条,建立了自建语音情感库。录制采样率为44.1 kHz,在语音领域内,44.1 kHz的高采样率不适宜进行机器学习方面的识别,需要经过采样压缩为16 kHz,并进行16 bit 的量化。由于语音情感识别方面的机器学习算法和语音特征提取方法种类繁多,且多数不易复现,因此本文在对比不同方法的实验结果时,选用相对容易复现的深度学习方法,包括文献[27-29]所提方法。本文方法与参考文献中所提方法在自建情感库的实验对比结果如表7所示。

表7 不同方法在自建数据集下的效果对比Table 7 Effect comparison of different methods in self-built data set %
由表7 可知,本文作为针对中文语音情感识别的方法,在中文自建数据集上也保持了较高的测试集准确率,达到90.4%;文献[28]所提方法利用了深度残差神经网络,有34 层之多,网络结构复杂度较高,准确率仅次于本文方法且相差无几,达到了90.1%;文献[27]所提方法在卷积神经网络基础上加入了循环神经网络,且输入特征图为三维特征图,但准确率只有77.8%;文献[29]基于循环神经网络加入了更为复杂的长短期记忆网络(Long Short-Term Memory,LSTM)算法,测试集准确率为86.3%。
3.3.3 迁移至EMO-DB 情感库的对比结果
EMO-DB 数据集是由柏林工业大学录制的经典开源德语情感语音库,由10 位演员(5 男5 女)对10 个语句(5 长5 短)进行7 种情感(中性、生气、害怕、高兴、悲伤、厌恶、无聊)的模拟得到,共包含535 句语料,采样率为16 kHz,进行16 bit 量化。本文方法在EMO-DB 数据集的实验结果与文献中的方法的结果对比如表8 所示。

表8 不同方法在EMO-DB 数据集下的效果对比Table 8 Effect comparison of different methods in EMO-DB data set %
由表8 可知,本文方法在德语的EMO-DB 数据集上的表现一般,测试集率为83.4%,仅高于文献[27]利用三维卷积循环神经网络的方法,与文献[31]仅利用openSMILE 提取语音特征的方法相近。文献[30]使用支持向量机分类器和深度卷积神经网络两种机器学习算法融合后进行的分类最准确,测试集准确率为95.1%。但由于文献[30]方法为两种机器学习算法的融合,参数众多,尤其是支持向量机的详细参数未给出,因此不容易进行复现,仅在本节利用文献中的结论与本文方法在EMO-DB 数据集上的实验结果进行了对比。文献[28]利用深度卷积神经网络ResNet34 的识别方法由于原本就是在EMO-DB 语音情感库训练得到的参数,因此得到了比3.3.2 节更高的识别准确率,为92.4%。
3.3.4 迁移至混合语音情感数据集的对比结果
将CAISA 数据集与自建语音情感库进行混合,之后再加入EMO-DB 经典库进行混合(混合时选取共有的中性、悲伤、害怕、高兴、生气5 种情感),分别通过实验验证本文方法在同语言下不同语料库中的效果,和不同语言、不同语料库中的效果,本文方法与参考文献中的方法准确率如表9和表10 所示。

表9 不同方法在CASIA+自建数据集下的效果对比Table 9 Effect comparison of different methods in CASIA+self-built data set %

表10 不同方法在CASIA+自建数据集+EMO-DB 数据集下的效果对比Table 10 Effect comparison of different methods in CASIA+self-built data set+EMO-DB data set %
由表9 可知,本文方法在CASIA 数据集与自建数据集进行混合的中文跨语料库中取得了较好的效果,但由于混合库中包含并非专业人录制的语音情感,因此总体结果不如在CASIA 数据集上理想,为93.3%。而通过表10 可知,加入EMO-DB 德语语音情感库后,识别效果有了一定程度的下降,为88.7%,但因为跨语言、跨语料库实验的数据集中,德语样本只占了大约1/4,所以仍旧能保持较高的识别准确率。从表9 和表10 可以看出,将文献[28]与文献[29]所提的两种深度学习方法直接迁移过来并没有对混合库进行参数的调节,所以与在EMO-DB 数据集上的结果相比有所下降。但由于模型本身较复杂,参数更多,因此针对不同情况的处理结果稳定性较强。相比之下,文献[27]所提方法在两种混合库中的效果依然较差。
3.3.5 对比实验总结
通过3.3.2 节~3.3.4 节的迁移实验可知,文献[28]与文献[29]的方法在整个迁移实验过程中结果均比较稳定,其中文献[28]方法在各个实验中表现较好,但由于其采用了ResNet34 进行迁移训练,因此网络模型比较复杂,参数过多,不适宜针对性地完成某些任务。而文献[27]与文献[29]的方法在卷积神经网络基础上加入了循环神经网络以及LSTM 算法,并没有取得十分理想的效果。这可能是由于本次实验所采用数据集的实验样本均为时长2~3 s 的短语音,并没有发挥出循环神经网络在时序预测方面的优势。文献[28,30]以及本文方法的实验结果充分说明,在较短的时间跨度内使用卷积神经网络的方法进行语音情感识别可行,且效果较好。
本文方法在处理中文语音情感识别时具有较高的识别准确率,但由于本小组录制人员非专业,情感不饱满,所以导致由CASIA 库预训练后迁移过来的Trumpet-6 模型并未达到和3.3.1 节同样的效果,而在混合两种中文语音情感库后,训练集变大,准确率有了一定的提升。此外,通过迁移至EMO-DB 库(德语)的实验结果与其他文献所提方法的实验结果对比后发现,本文方法在处理跨语言的语音情感识别方面存在不足,在混合库中文样本较多的情况下,相比于纯德语有一定提高。虽然本文方法不如文献[28]方法在各种情况下的识别结果稳定性强,但作为一种基于CASIA 数据集训练而来的方法,针对于中文语音情感识别的方法具有一定的优势,具体对比结果如表11 所示。此外,相比于ResNet34 深度残差神经网络而言,本文所改进的语音处理方法以及所设计的Trumpet-6 卷积神经网络结构较简单。

表11 文献[28]方法与本文方法的对比Table 11 Comparison between the method in reference[28]and in this paper
4 结束语
针对中文语音情感识别效率和准确率低的问题,本文提出一种新型中文语音情感识别方法。通过在MFCC 特征提取过程中提高采样点个数,并在改进语音处理方法的基础上使用高斯白噪声对数据集进行数据增强处理,从而提高处理效率及缓解训练过程中的过拟合现象。通过建立Trumpet-6 卷积神经网络模型并用于中文语音情感识别,提高识别准确率。在CASIA 数据集上的实验结果表明,本文方法的识别准确率达95.7%,优于Lenet-5、RNN、LSTM 等传统方法。本文网络模型采用2 048 个采样点,仅176 550 个待训练参数,与采用DCNN 的ResNet34 和循环神经网络模型相比,其结构较为优化,处理效率得到大幅提高。但经过迁移至其他语料库训练后发现,本文方法在处理不同语言、跨语料库的情感识别时准确率有待提高,且网络模型尚不能精确提取情感信息并舍去不必要的语言习惯。下一步将进行跨语料库的泛化性研究,并丰富开源语音情感库,促进语音情感识别领域的发展。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
电子制作(2019年13期)2020-01-14
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年11期)2019-07-04
电子制作(2019年9期)2019-05-30
