
基于多尺度融合GAN的水下图像增强方法
2022-02-20 10:25孙建
实验室研究与探索 2022年11期
孙 建
(重庆工程学院,重庆 401320)
0 引言
水下光学图像作为传输海洋信息的主要载体,对探索与开发海洋起着至关重要的作用。但由于水下成像环境复杂,水体以及悬浮颗粒对光的吸收与散射作用,导致水下拍摄到的图像存在颜色失真、细节模糊等问题[1-3],给准确地提取图像信息带来了极大的困难.因此,为了获得清晰、真实的水下光学图像具有重要的意义[4-5]。
随着生成对抗网络(Generative Adversarial Network,GAN)被广泛地应用于水下图像处理方面[6],Zhu 等[7]使用循环对抗神经网络(CycleGAN)来学习各种各样的自然图像,提出了图像到图像转换的循环变换,CycleGAN可以在没有混浊干净图像对的情况下进行训练,但是因数据集的分布特性可能会导致图像恢复效果不理想。Xu 等[8]利用CycleGAN 建立浑浊和洁净水下图像之间的直接映射,同时利用暗通道优先方法(Dark Channel Prior,DCP)估计介质传输,以提高水下图像质量,但在非均匀光照下无法产生一个可信的图像。Li 等[9]提出了水对抗神经网络(WaterGAN)在无监督管道中从空中图像和深度对生成真实的水下图像,用于单目水下图像的颜色校正,提出了一种需要参数化的渐晕模型,此方法在对WHL数据集的还原上仍然显示一些渐晕。Phillip 等[10]提出了一种基于条件GAN 的监督图像增强框架并把它命名为pix2pix,并建立了一个全卷积鉴别器来处理图像块,但训练方法需要大量的成对图片。Chen 等[11]提出了一种具有多分支鉴别器GAN-RS来提高水下图像的质量,但训练参数需要仔细设置或调整,如果使用不正确的设置进行训练,生成模型可能会在输出图像中产生伪影。这些模型仍然存在一些缺点,如增强图像中的伪影、不切实际的颜色偏移或模糊效果。
本文提出了一种基于多尺度融合GAN 水下视频图像增强方法,将特征融合与跳级连接引入到生成器结构中,建立生成器和判别器网络,并通过与现有的水下图像增强方法定性与定量进行比较,从而使水下图像图片更符合真实的水下环境,也可解决因退化现象而保留下来的偏色问题。
1 水下图像增强方法
本文的水下视频图像增强方法MSFF-GAN 的模型结构,如图1 所示,其中,Convnxn-256 为卷积核大小为n×n通道数为256 的卷积层,upsample为上采样,G为生成网络和D为判别网络。其增强过程:①在G中对放入训练的噪声图像X进行多尺度特征提取,使G在训练过程中生成虚假样本Y;②将Y与标签GT 通过Concate操作输入到D中,并经过5 层下采样操作,得到16 ×16 的矩阵;③D需要对输出的16 ×16 矩阵做真假判断,并返回一个概率值,并将这个概率值传递给损失函数进行调整。
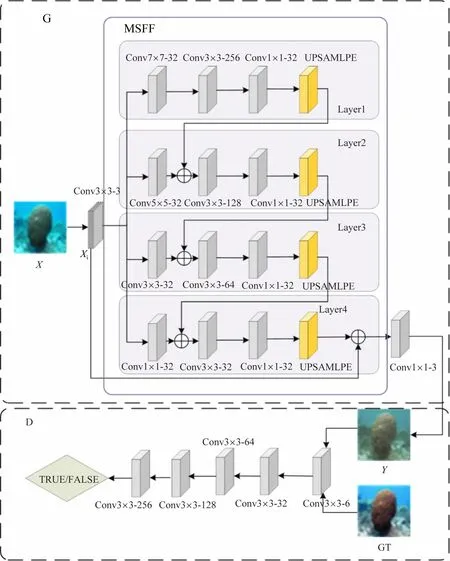
图1 图像增强模型
1.1 生成网络G
本文重新对G进行了构造:①对X进行一层3 ×3 卷积;②将结果X1输入到本文的多尺度特征融合模块(Multi-Scale Feature Fusion,MSFF)中,利用多尺度卷积对图像进行特征提取。多尺度特征融合模块共包含有4层,为了使每一层的输入特征图大小不一样:①每一层都是对X1进行卷积操作,卷积核大小分别为7×7、5 ×5、3 ×3、1 ×1;②对layer1 经过3 ×3 卷积,接着对提取得到的水下特征使用1 ×1 的卷积进行卷积操作,目的是进行特征的整合,便于后续的操作;③在layer1层,需要对1 ×1 卷积结果进行2 倍上采样,目的是为了将layer1 的结果与layer2 的输入进行Concat操作。layer2、layer3 的操作与layer_1 类似,而layer4的倍上采样结果需要与X1进行Concat 操作,其结果经过1 ×1 的卷积操作得到G的输出。
1.2 判别网络D
本文的判别网络D主要用于对生成网络输出的结果进行判断:在D中将Y和标签GT作为输入,进行真假的判断;D对Y和GT进行4 层下采样操作,且每层卷积核的大小均为3 ×3,步长为2,采用了Same 的方式对特征图进行了填充,同时还利用L-ReLU 和批量归一化(BN)对特征图进行非线性和归一化处理;对4 层下采样的结果进行一个3 ×3 的卷积取代传统的全连接层。D的输出为16 ×16 区域,并对多个16 ×16区域真假判断,实现对Y和GT的分块判别,分块判别的示意图如图2 所示。

图2 分块判别示意图
在D中对放入判别网络中的图片进行真与假的判断,对每一张图片划分成多个相同大小的16 ×16 的矩阵D[12],Di则表示第i个对应小块的概率值,并将这个概率值传递给G和D的损失函数,不断优化模型。这样的方法通过对每个块进行差别的判别,实现了局部图像特征的提取和表征,有利于实现更为高分辨率的图像产生,而且这种机制也能够将局部图像特征和整体图像特征相融合。
1.3 损失函数
网络的损失计算包括内容损失[9]平均绝对误差损失[10]和传统生成对抗损失3个,其中内容损失
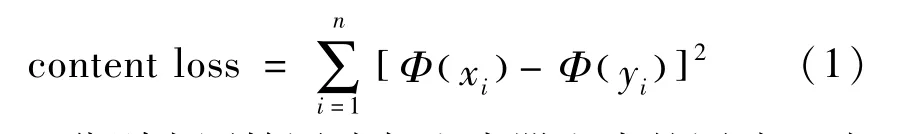
式中:x,y分别为原始图片与生成器生成的图片;i为第i个像素点;Φ(x)为从VGG19 网络[13]预处理提取到的内容特征,即内容损失表示为原始图片上的每个像素点减去生成图片上的每个像素点的值平方再求和。
平均绝对误差[10]表示原始图片上的每个像素点减去生成图片上的每个像素点的值取绝对值再求和,其表达式为
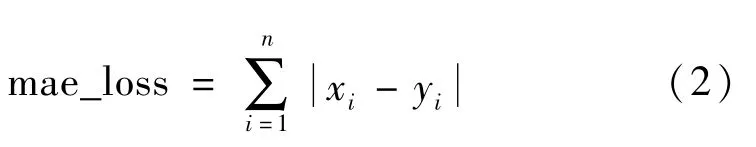
传统生成对抗损失LGAN包含了2 个部分:对生成器进行优化;对判别器的优化。其计算表达式为
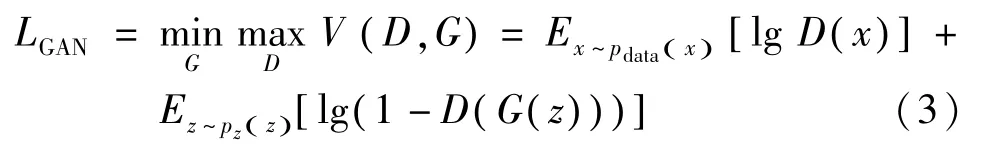
式中:E(*)为函数的期望值;D(*)为判别器;G(*)为生成器;z表示随机噪声;Pdata(x)为真实样本的分布;Pz(z)为定义在低维的噪声分布。本文的网络中,期望的判别器能够使D(G(z))值越小,1-D(x)的值越大,即生成器能够对图片上的随机噪声出去,这样可以使生成器生成的图片更好。
最终,损失函数的表达式为
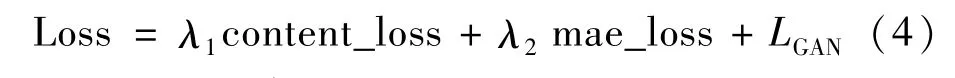
式中,λ1、λ2为超参数,本文设λ1=0.7,设λ2=0.3。
2 实验与分析
本实验均在Intel(R)Core(TM)i5-6300HQ CPU@2.30 GHz,8 GBRAM 的PC 机上进行,并且使用NVIDIA GeForce GTX 960M 显卡进行加速。使用TensorFlow库来实现本文提出的水下图像增强模型。
2.1 数据来源
训练数据集包括EUVP数据集[15]。EUVP数据集共含有22 430张图片,包含有4 260 张成对的图片,包含了在海洋探索和人机合作过程中收集的图像,也包含了一些从公开的视频中提取的图像。此外,本文还在测试阶段使用到了RUIE 数据集,该数据集包含UIQS、UCCS及UHTS三大类数据,其采集地点位于黄海海域张子岛附近0.5 m 处海床上方,所有视频均在每天8:00~11:00 和13:00~16:00 的2 个时段由22个防水摄像机拍摄,数据集内包含鱼类、海胆、扇贝、海参等海洋生物。从EUVP数据集中选取了3 000 对数据进行训练;从EUVP 未成对数据和RUIE 数据集中各选取了100 张图片进行测试。
2.2 训练参数设定
本文使用了Adam 优化函数来代替随机梯度下降,学习率为0.000 3,一阶矩估计的指数衰减率β1为0.5,二阶矩估计的指数衰减率β2为0.999。通过对收集到的4 200 对图片进行无监督地训练水下图像增强模型,本实验中,批处理大小为4,共迭代30 000次;训练过程中每隔50 次迭代计算出当前生成网络和判别网络的损失值;每隔2 000 次迭代随机输出3 张样张和样张增强后的图像;每2 100 次迭代输出当前训练的模型,并以h5 格式保存。
2.3 结果与分析
为验证本文方法的有效性,将本文的水下图像增强方法与DCP 方法、自适应直方图均CHALE[1]、Pix2pix[14]、CycleGAN[15]、WaterGAN、GAN-RS[12]等这些水下图像增强方法进行了PSNR、SSIM 以及UIQM指标的定性与定量比较列于表1。由表1 可见,相较于其他的水下图像增强方法,本文提出的方法在PSNR、SSIM 以及UIQM 值上均较对比方法有了明显的提升,其中PSNR值相较于GAN-RS提升了1.203 4,增幅约为5.1%;SSIM 值与GAN-RS 提升了0.035 8,增幅约为4.1%。
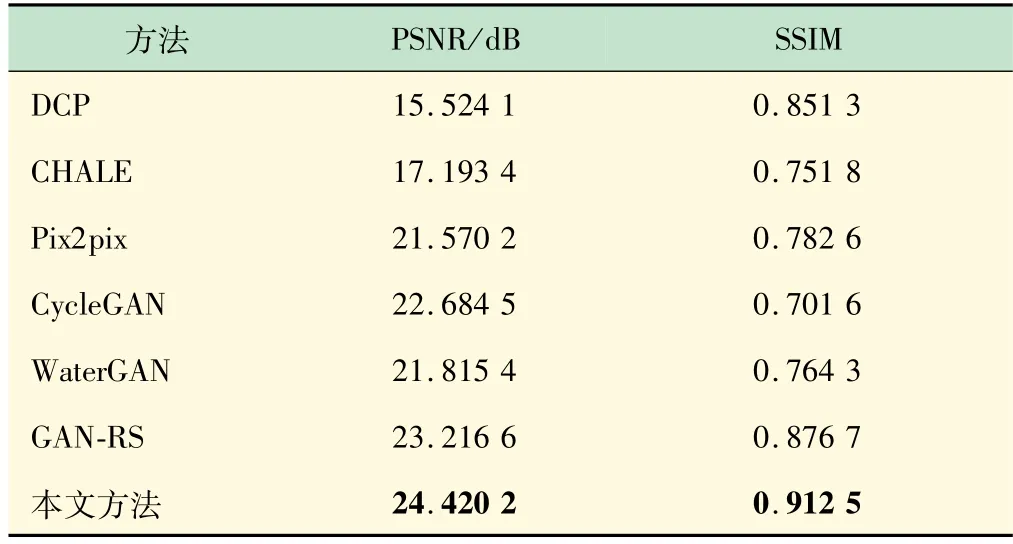
表1 各方法的PSNR,SSIM值对比
图3 为不同水下图像增强模型测试比较结果,由图可知,对比其他水下图像增强模型,DCP 方法[2]处理后的图像与原始图像并无太大差别,甚至在图3(d)~(e)图像的测试结果中加重了图像中的绿色,导致产生的图片颜色失真的加剧。CHALE 方法[1]虽然对图像进行了增强,但是对图3(a)~(c)增强的结果所示,可以清楚地看到在结果中对原始图像中颜色较深的区域过度重建。Pix2pix[14]方法产生的结果图3(b)~(e)中普遍呈现淡黄色,这与本文的事实并不符合。而ClycleGAN是与本文的结果最吻合的一组,但对图3(c)的增强后,对退化现象的处理仍不够完美。WaterGAN、GAN-RS这二者对比本文的方法都存在着同样的一个问题,对图3(b)~(e)增强后的结果显示对原始图像中的偏色问题处理不够好。本文提出的方法产生的数据在没有噪声产生的基础之上,既符合事实又消除了因退化现象而导致原始图片偏色问题。

图3 不同水下图像增强模型测试比较
表2 为各模型的UISM、UICM、UIConM、UIQM 值对比,由表可见,UISM值在WaterGAN中取得最大值,UICM在CycleGAN 中取得最大值,UIConM 在DCP 中取得最大值。本文方法虽然在UISM,UICM 以及UIConM三项数据上并不能取得最高的值,但本文方法能够得到最高的UIQM 值。相比于GAN-RS 模型,本文方法的UIQM值提高了0.031 7。
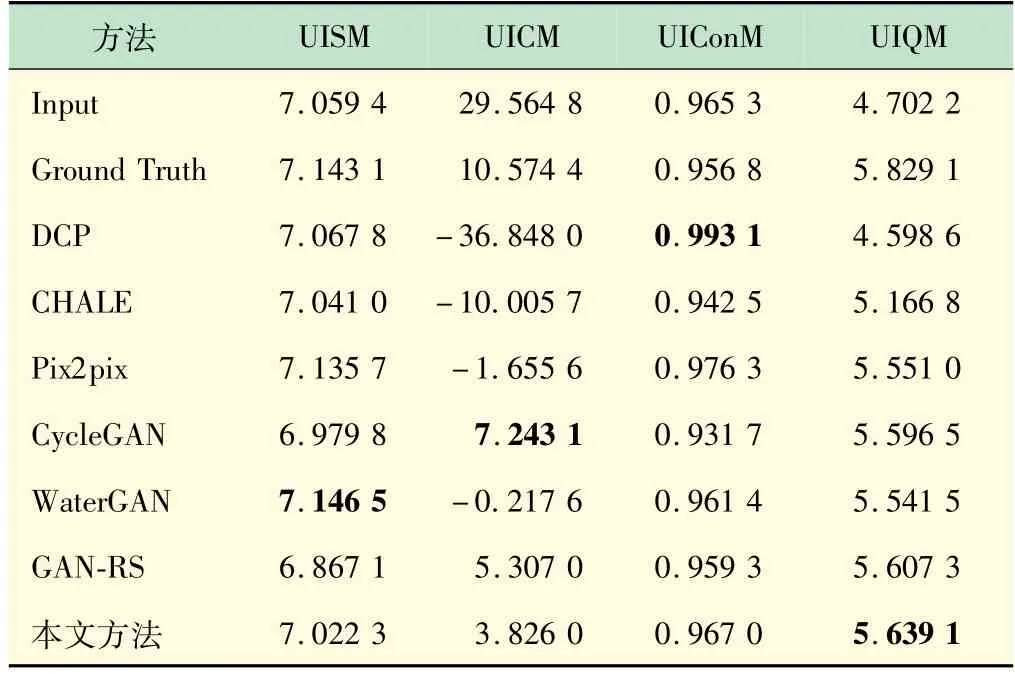
表2 各模型UISM,UICM,UIConM,UIQM值对比表
3 结语
本文提出一种基于多尺度融合GAN 水下视频图像增强方法,与目前已有的水下图像增强模型进行了比较实验,实验结果表明,本文提出的水下图像增强方法生成的水下图像图片更符合真实的水下环境,在解决因退化现象而保留下来的偏色问题上也具有良好的可行性。本文将利用通道补偿的方法进一步开展图像增强,以对高度退化的水下图片修饰修复工作。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
燃气涡轮试验与研究(2021年6期)2021-08-01
数学小灵通·3-4年级(2021年5期)2021-07-16
海洋信息技术与应用(2020年4期)2021-01-18
电子制作(2019年13期)2020-01-14
中国生物医学工程学报(2019年5期)2019-07-16
电子制作(2019年11期)2019-07-04
今日农业(2019年15期)2019-01-03
北京航空航天大学学报(2018年1期)2018-04-20
北京航空航天大学学报(2017年3期)2017-11-23
