
大数据是对传统经济学研究范式的颠覆吗?
2022-02-19 01:20刘宽斌
重庆理工大学学报(社会科学) 2022年1期
刘宽斌,张 涛
(1.西南大学 经济管理学院, 重庆 400716; 2.中国社会科学院 数量经济与技术经济研究所, 北京 100735)
一、引言
现代科技技术的进步不仅改变了人类生产、生活的方式,也改变了人类认识事物的方式。近年来,随着计算机技术以及互联网技术的飞速发展,人类能存储下来的数据信息量出现了爆炸式的增长。互联网出现之前,人类存储数据信息最方便也最常用的方式是书籍。据国际数据公司(IDC)的研究报告显示,截止到2012年,人类所有印刷材料所记录的数据信息总量为200PB ,而在互联网时代,仅2008年一年产生的数据信息量就高达0.49ZB,并且数据信息量的产生呈现加速趋势,2009年产生了0.8ZB的数据,2010年为1.2ZB,到2011年就达到1.82ZB(1)https://www.idc.com/.。据2017年IDC的研究报告估计,到2025年人类产生的数据信息量将高达163ZB,将比2016年创造的数据信息量增加10倍(2)数据来源于IDC 2017年发布的白皮书《数据时代 2025》。。互联网时代不仅数据信息量出现高速增长,参与数据信息创造和使用的群体或对象也发生了改变。在人类还处于印刷时代时,被记录下来的数据信息源头只能是那些能够写书的个人或有出版书籍能力的单位以及其他愿意用纸质文件记录信息的群体,这一记录数据的方式很大程度上限制了数据信息源。社会中的广大普通成员及企业单位产生的、无法用纸质文件记录的信息均被遗失,这些信息都是描述整个社会运行状况信息的组成部分,但受限于条件,均无法被保存下来。进入当前计算机和互联网的时代,普通个人能通过互联网与他人分享生活状况,对社会事件表达自己的看法;工厂企业已经在一定程度上实现了电子化,甚至信息化,能够被记录的不仅仅是企业的财务状况、人员变动等基础信息,还能记录企业工厂机器运行信息等,所有的这些信息均被存储在互联网平台或者企业的数据库中并被长期保存。这类信息量巨大、数据源头广泛的数据信息被称为“大数据”。
大数据对人类生产生活产生了巨大的影响,也给研究人类社会经济规律的经济学带来改变。大数据可以从以下3个方面给经济学问题研究带来较大影响:检验当前经济理论的正确性、提供识别此前不能被识别的影响因素、提供经济理论新见解[1]。当前大数据,特别是网络大数据已经开始被应用到经济问题的分析当中,主要包括失业率、通货膨胀、社会宏观经济消费量、房地产市场、选举、社会舆情分析以及国内生产总值(GDP)等问题的研究[2]。虽然大数据已经在众多经济学领域开始被应用,但当前对大数据应用于经济学领域的研究范式问题却缺乏探讨,导致当前大多使用大数据分析经济学问题时缺乏理论依据,最终的研究结论也难以从经济学的角度来解释。
本研究试图从网络大数据的角度探讨大数据的概念、特点,分析大数据应用于经济学研究时与传统统计数据的区别以及大数据本身具有的优势,总结当前大数据应用于经济学分析过程中存在的问题,并在以上分析基础上探讨大数据应用于经济学分析时的范式问题,为大数据应用于经济学分析的研究范式提供思考。
二、大数据概念发展
为分析大数据在经济学中的应用范式,首先需要清晰界定大数据的概念并且总结出大数据相比于传统的统计数据所具有的独特优势。大数据是当前研究的热点,但关于大数据的概念或定义却难以统一。为分析大数据的概念、特点,本文从大数据的概念演进的角度来分析。大数据的概念有一个逐步发展的过程,不同时期、不同学者从各自不同研究领域提出了不同的见解。
最初,大多数学者对大数据的界定是从计算机技术角度来描述,重点关注大数据信息的体量,强调大数据信息难以被当时的计算机处理和分析。例如,2013年来自亚马逊公司的数据科学家约翰·老萨(John Rauser)在一次计算机研讨会上将大数据描述为“超过一台计算机处理能力的数据量”(3)https://www.networkworld.com/article/2188435/defining-big-data-depends-on-who-s-doing-the-defining.html.,这样的定义方式局限于大数据“量级大”特点。另外,日本野村综合研究所研究员城田真琴在其文章中将大数据定义为“用当期企业数据库中占主流地位的关系型数据库无法进行管理的、具有复杂结构的数据”[3]。该定义增加了数据的“响应时间”,认为大数据是数据量巨大,导致数据查询时间超过了容忍范围的数据集合。中国工程院院士李国杰也有过类似表述[4]。全球著名的管理咨询公司,也是世界上首次系统阐述大数据概念和应用的公司麦肯锡(McKinsey)定义大数据为:数据量大小超过典型数据库软件采集、存储、管理和分析等能力的数据集[5]。研究机构高德纳(Gartner)认为大数据需要新的处理模型才能增强决策力、洞察力、优化分析能力的高增长和多样化的信息资产(4)https://www.gartner.com/en/information-technology/glossary/big-data.。约翰·沃克(John Walker S)通过“4V”特征来定义大数据,认为大数据信息应该满足数据量巨大(Volume)、数据处理速度极快(Velocity)、数据形式多种多样而不局限于结构化的数据信息(Variety),有价值的信息隐含在海量的数据信息中,需要通过数据挖掘的技术方法提取出来(Value)[6]。维基百科中对“大数据”的定义是:利用传统的计算机和方法来管理、处理消耗的时间超过可接受范围的数据集。
国内学者对大数据的概念也有所阐述。《大数据时代的历史机遇》一书作者认为大数据是指“在多样的或者大量数据中,迅速获取信息的能力”[7]。中科院院士徐宗本认为,大数据是指不能够集中存储,并且难以在可接受的时间内分析处理的数据,其中个体和部分数据呈现低价值性而整体呈现高价值的海量复杂数据集[8]。中国通讯院(CAICT)在发布的《大数据白皮书(2016)》(5)http://www.cac.gov.cn/2016-12/28/c_1121534609.htm.中给大数据的定义是“复杂混合体的认知理念”。
在此,可以将关于大数据概念的不同阐述总结如表1。

表1 关于大数据概念的主要表述
通过以上对大数据概念的梳理可以看到,不同的机构和研究者对大数据的理解存在一定的差异,但均是从技术角度来界定,强调大数据信息体量超过了传统计算机技术处理能力范围。也有从价值角度来理解大数据概念的观点,主要的观点总结如表2。

表2 大数据概念外延
学者对大数据的概念外延表述时更多强调大数据的价值,认为大数据的核心在于能够创造价值,而不是数据集本身。
通过这些专家和学者对“大数据”的描述或界定发现能被视为“大数据”的数据信息应该具有如下特点:
(1)数据体量大。传统统计方法收集的数据信息量一般为KB级、MB级,而大数据的信息量在GB级以上,甚至是TB、PB、EB级别的数据信息。
(2)传统计算机在可接受的时间内无法处理。传统计算机计算能力有限,面对巨量的数据信息,无法有效胜任分析处理工作。
(3)数据信息多样性。传统的统计数据一般为截面数据、时间序列数据或面板数据,归结起来都是结构化的数据信息,而大数据的数据信息扩展了范围,不仅包括结构化的数据,还包含文本、图片、语音、视频、网络搜索、日志信息、URL等。
(4)高价值,但价值密度低。一堆无用的,对增强认识事物能力无帮助的数据是不能称之为“大数据”的,高价值体现在“大数据”蕴含的信息能够提供传统数据不能提供的精准信息,但是由于数据量巨大,单个样本或数据单元提供的价值信息降低,只能通过海量的数据分析才能提取出完整的价值信息。
三、大数据在经济学应用中的优势
当前,应用于经济学研究的大数据信息主要来源为网络大数据,包括百度搜索指数[12-13]、微博[14-15]、网络新闻信息[16-17]等。基于此,本研究以网络大数据为主要分析对象,介绍网络大数据在经济学研究中的优势。网络大数据是指通过网络平台汇聚的数字、文本、图片、语音、视频等各类信息,这些数据信息具有能被数据提供者以外的人通过网络平台及时获取的可能,是极度分散又涵盖范围极广的超大数据集。相比于传统统计数据,这类大数据信息具有如下独特的属性:
(1)时效性极强。通过互联网平台积累起来的数据信息存储于网络空间中,包括交易的数量、销售的价格、发表的言论、检索的关键词等,这些信息在发生时,实时在网络中留下记录痕迹,可以被一定的方法和技术提取出来,用于处理和分析问题,不存在时间滞后性。这是网络大数据与传统统计数据之间重要的区别。
(2)数据真实性强。网络平台记录下的信息是在事件发生时按照实际的发生情况自动记录,减少了人为的干预,提供原始的数据,而非人为搜集经过处理后的数据信息,相对更加真实。这里的真实性主要是指网络痕迹信息是真实的,被篡改的概率较小。
(3)获取数据成本较低。由于网络大数据信息均在事件或交易发生时自动被记录下来,无需人为调查和搜集,通过一定的技术方法即可提取出来,并用于经济问题的分析。基于程序化的数据搜集方式能够极大地节约人力成本的投入,相比于传统人工填报的方式,能够极大压缩数据搜集成本。
(4)数据细分度高。为了降低成本,传统的数据搜集会尽量搜集总量数据,而非细分数据信息。网络大数据时代,提取总量数据信息与提取细分数据信息的难度差异并不大,因此可以在不显著增加成本的前提下,提供更加详细和更加有意义的数据信息,这主要是由网络数据搜集方式决定的。网络数据信息繁杂,并且信息量巨大,数据搜集方式基本上是程序化的,利用计算机强大的数据处理能力和计算速度对数据按照设计者的思路来搜集并处理。由于所有个体微观行为或其他标识性信息均能够通过一定方式获取,设计者通过修改数据搜集和处理的程序即可改变数据的搜集范围,能够方便地处理细分化领域的数据信息。
(5)大样本。利用互联网大数据信息,可以获取总体或者接近全体的样本信息,而非通过统计抽样的方式获取样本信息来推断总体信息。在这样的大数据支持下,用于计算的样本量是海量的,并且能较大程度上接近全样本,直接获取较为全面的数据信息。传统统计数据受制于搜集成本,基本上会基于统计理论,设计一定的抽样方式,从整体中获取少量样本数据信息,利用抽样的样本信息来估计整体水平。这种方式获取的数据质量严重依赖于抽样方法设计的合理性、数据采集过程的准确性以及数据分析方案的科学性,容易造成选择性偏差、数据失真、估计误差等问题。利用接近全样本的数据信息能够有效缓解上述弊端。
以上总结了网络大数据信息的优点,这些优点能给经济学研究带来巨大的改变,主要体现在以下几个方面:首先,经济指标实时监控(Now casting)成为可能,由于大数据具有较强时效性,能够在短时间获取海量的实时数据,通过构建网络大数据与经济指标之间的联系,能够实现对经济状况的实时监控。其次,经济运行“拐点”预测成为可能,传统统计数据受制于滞后性问题,只能利用历史数据来归纳经济运行规律,利用历史规律来预测未来,但大数据信息具有较好的时效性,能够在更短的时间内发现经济运行的“拐点”,并指导做出及时的调控。第三,经济问题宏微观一体化研究成为可能。利用传统统计数据做经济问题分析时,微观数据信息无法直接用于分析宏观经济问题,大数据虽然获取的是微观个体的数据信息,但样本量却涵盖了数以亿计的群体(6)根据中国互联网信息中心(China Internet Network Information Center,缩写CNNIC)统计,截至2018年6月,我国网民规模已经达到8.02亿人,相比于2017年末增加3.8%,互联网在全国普及率高达57.7%。 另据互联网数据研究机构We Are Social和Hootsuite共同发布的“数字2018”(Digital in 2018)互联网研究报告显示2017年末全球网民人数达40亿人,占全球总人数的50%。,汇聚这样的数据信息量,足以反映宏观经济状况。最后,大数据信息能够扩展经济学研究范围,传统统计数据受制于数据搜集方式,难以统计全面的信息,而大数据可以更加细致地分析经济现象,扩展经济问题的研究范围。
经过以上的分析可以看到,由于大数据信息与传统统计数据存在较大的差异,在经济问题分析时具有独特优势,因此能够给经济问题的研究带来巨大改变。但大数据信息的出现仅是对传统统计数据的补充,是应该融入到传统经济问题的研究过程当中,还是对传统经济问题分析范式的颠覆?当前对该问题的探讨较少,但对这一问题的回答又十分重要,关系到利用大数据信息分析经济学问题的科学性。接下来本文将就这一问题进行分析。
四、大数据对传统经济学问题研究的改进
当前,应用大数据分析经济问题的研究缺乏机制分析,而机制分析对规范的经济问题研究十分重要。本节内容首先在总结传统经济问题分析范式的基础上提出应用大数据来做经济分析的研究范式。本研究认为大数据信息应用于经济分析,是对传统经济学分析方法中数据缺陷的改进,而非对传统分析方法范式的颠覆。
(一)传统经济问题分析范式
传统的经济问题分析方法强调经济模型背后的理论基础,无论是统计学理论还是经济学理论基础,均能够为经济模型稳定性提供良好的支撑。传统的经济学研究从方法论上来说是演绎法,其基本范式为“假设—检验”。在具体的经济问题研究过程中,通过已经接受的经济规律进行经济学逻辑推导,并基于一定的约束性条件,给出所研究的经济问题规律认识的假说,最后利用经验事实的数据信息来检验或验证假说的成立与否。若实证检验结果与假说一致,则暂时接受假说关于事物关系的判断,并指导实践活动;否则,拒绝假说,修改假设、重新进行逻辑推导并提出新的假说,再次进行验证分析。传统经济学的研究方法基于逻辑演绎推导结论,其遵循严格的科学规范,这种演绎推导的范式与自然科学并没有本质的区别[18]。其基本的研究范式可以用图1表示。
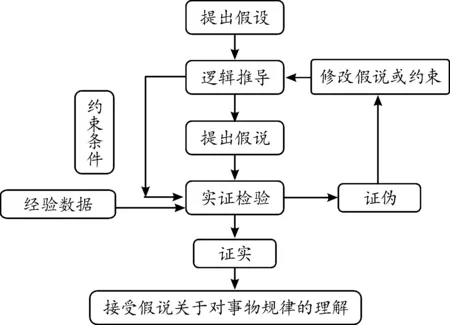
图1 传统经济学研究的基本范式(7)借鉴汪毅霖[18]对经济学研究问题范式的总结。
传统经济学研究方法的逻辑背景是经济学研究可解释性的基本要求以及传统统计数据的有限样本信息。首先,经济学是研究人类经济活动规律的学科,研究发现经济规律,以指导经济活动,创造价值。为了能够指导经济活动,经济学的研究结论必须具有一定的理论可解释性,若只是经验总结,难免造成“地心说”类的错误判断(8)“地心说”是古代人对观察到的现象进行的经验总结。,难以称为科学;其次,由于数据采集手段以及成本的限制,传统统计数据样本量有限,基本依靠有限样本来推断总体的规律,为了实现这一目的,需要对样本数据的统计属性进行大量假设或限制,以满足有限样本能够代表总体样本的统计规律。
(二)大数据对传统经济学研究的改进作用
基于前文可知大数据信息与传统统计数据之间存在较大差异,在分析经济问题时具有独特的优势,将大数据应用于经济问题的研究分析中应该遵循怎样的研究范式呢?接下来将就这一问题进行探讨。
维克托·麦尔-舍恩伯格(Viktor Mayer-Schonberger)的著作《大数据时代》(BigData:ARevolutionThatWillTransformHowWeLive,Work,andThink)认为在大数据时代,研究问题时不必注重数据之间的“因果关系”,而只需要关注数据之间的“相关关系”即可[6]。因此,当前许多利用大数据信息来做经济分析或预测的研究并不探求经济变量之间的内在逻辑联系,而是获取大数据信息后就直接用于模型分析,最后查看模型的效果,得出研究结论[19-24]。这种分析研究问题的方法从方法论的角度可以认为是归纳法,而归纳法研究问题的基本范式为“归纳—总结”。
由于大数据应用于经济学问题分析的研究还未形成标准的研究范式,还处于探索的过程中,因此,当前的大部分研究都只是应用大数据信息来分析经济学问题的尝试,但这些研究大都过分强调大数据分析问题时的“相关性”,较少去分析“因果性”问题。这样的处理方式的好处是研究者有充分的自由空间,设计模型时不再受到约束条件的限制,发现和应用数据来分析经济问题变得简单化,让数据自己发声。如果通过数据发现了某种规律就认为是真理,经济规律成了数据间相关关系的副产品,而非理性推导的必然结果。当前,大数据研究夸大相关性的作用,有意忽视经济问题的因果关系,这样的研究范式难以让大数据经济分析成为一门真正的科学,可能会成为一种迷信式的思维[18]。这样的经济问题研究方式将导致研究结论难以解释并且缺乏说服力。经济问题的研究目的是解释经济问题、指导经济活动,若经济研究的结论仅仅依靠的是数据之间的相关性表现,则难以从理论上解释为何具有这样的相关性,难以形成对经济规律认识的逻辑体系。另外,在大样本数据信息的条件下筛选变量之间的相关性,会存在“强相关性表现是否是偶然现象”这样的疑问,研究结论缺乏说服力。
本研究认为将大数据信息应用于经济问题的分析是对传统经济问题研究方法中数据缺陷的改进,而非对传统经济学研究方法范式的颠覆。因此,应用大数据来分析经济问题时,依然需要遵循一般化的经济问题研究范式。但由于大数据自身的信息特点,也会对一般化的经济问题的研究范式产生影响,这种影响主要是关于数据信息方面的假设。因为大数据信息的来源广泛,而且数据信息量巨大,获取全样本或近乎全样本的数据信息成为可能。传统经济问题研究使用的数据基本要求满足一定的抽样理论,以使获取的数据具有足够的代表性,而近乎全样本的信息量则不再考虑样本的代表性问题,可以放宽数据统计属性的假设。
大数据信息又增加了一个问题,那就是数据噪声的问题。大数据信息量巨大,但数据信息中无效信息也急剧增加,如果无法有效地去除噪声信息,将对经济问题的研究结果造成巨大的影响,甚至导致对经济问题规律认识的错误判断,没有经过去噪处理的大数据信息将会导致“垃圾进入,垃圾输出”(garbage in,garbage out)。在具体经济问题的分析过程中,网络数据信息的使用需要很强的技巧性来剥离与研究问题不相关的网络信息。例如在使用网民网络搜索“通货膨胀”的频率信息时,针对该搜索行为的动机可能是关注市场价格整体变动,也可能是查看经济学名词的含义,而这两种不同的搜索动机对具体的经济问题研究具有不同的意义,因此在利用网络数据时需要通过特定的方式来识别、剔除与研究问题无关的信息。若处理不当,可能会导致研究结论与真实情况之间存在较大的偏差。
当前,针对大数据信息的去噪方法,主要是通过统计学的方式来筛选[25-27],但这种方式依然基于“归纳—总结”的研究范式,只要具有统计学意义上的强相关性或者满足其他的相关性就认为数据信息有助于预测和分析经济问题。这样的研究思路依然避免不了“伪回归”类的错误,以此为依据的研究结论也不具有强说服力。例如Ginsberg等利用“谷歌”数据库,基于相关性来筛选与流感相关的“关键词”,最终得到了5 000多万个“关键词”的搜索时间序列数据,并利用该大数据信息来预测流感爆发时间,得到了较好的预测效果[27],相关成果发表在《NATURE》杂志上,轰动一时。但这样的研究思路得出的规律却无法应用于现实。2014年,《SCIENCE》杂志发表的一篇文章指出Ginsberg等的预测方法存在严重的问题,应用该方法来预测2011年8月至2013年9月流感爆发时间的结果误差比传统统计方法预测结果更高[28]。该研究以相关性为依据选择网络数据信息,缺乏对网络数据背后行为动机的考察,导致模型高精度的预测效果难以持续。在面对海量数据信息时,总能找到与研究问题强相关的数据,但强相关并不一定意味着存在直接的逻辑关系。因此,本研究认为针对大数据的“去噪”处理也应该基于经济学的理论分析,在筛选数据信息时,应在经济学理论指导下判断哪些数据信息应该被收纳到经济学问题的分析中,而不应该仅仅只是考察统计关系。
基于以上的分析,本研究总结了利用大数据做经济学问题分析时的一般范式,如图2。
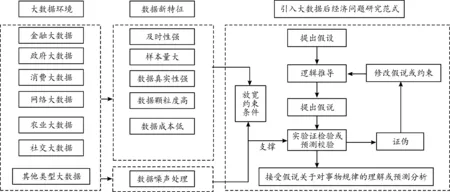
图2 大数据对传统经济学问题研究范式的改进
五、总结及展望
(一)总结
大数据(Big Data)概念自1997年首次提出来后(9)美国宇航局研究员迈克尔·考克斯(Michael Cox)以及大卫·埃尔斯沃斯(David Ellsworth)在当年美国电子电器工程师学会(IEEE)举办的第八届可视化会议上将超级计算模拟飞机在飞行过程中气流的超大信息称之为“大数据”。,自然科学和社会科学工作者均对其产生了浓厚的兴趣。自然科学关注大数据的技术特征,包括数据量的大小,是否能够在较短的时间获取以及是否能够在传统计算机上在可接受的时间内处理和分析等技术细节;社会科学则更加关注大数据的价值特征,强调大数据能够增强当前人类对社会经济问题的认识能力,能够改进人类社会生产和生活方式。整体而言,大数据信息具有体量大、难处理、信息多样性以及高价值的特征,具有这样特征的大数据信息应用于经济学问题的分析能够带来传统数据无法具备的一些优势,包括高时效性、数据误差率低、数据成本低、数据细分度高以及大样本属性。传统经济学主要研究因果判断问题,基于抽样理论获取有限样本信息用于实证,并在一系列严格假设基础上推断因果关系。这样的研究范式对样本数据信息的假设过于严苛,以至于有些假设在实际问题中难以完全满足,因此具有一定的局限性。大数据信息在一定程度上能够缓解小样本或者有限样本的缺陷,有助于适当放宽对样本数据的假设条件,进而带来经济学问题分析范式的改进。
(二)展望
大数据时代的来临,带来了与传统统计数据不同属性的数据信息,经济学问题研究者为之兴奋,甚至认为大数据已经突破传统假设检验的研究范式,大数据使得因果关系变得不太重要[29]。做出如此乐观判断的主要依据是大数据可能获取总体样本信息,暂且认为这种判断是合理的,即使如此,经济学研究经济规律,总体数据信息仅仅是经济规律影响下的外在表现而已,而从经济内在规律到外在表现之间并不是一一对应的关系。例如我们分析X影响Y的问题时,并不会简单看两者之间的相关系数就判断他们之间的关系,而是会通过计量模型控制其他重要的影响因素,更多可能的影响因素则放置到随机干扰项中。全样本信息也仅仅能获取某一维度或有限维度的信息量,无法获取影响Y的全息数据信息(10)笔者认为的全息数据信息是能够描述影响该经济规律或现象的一切有关因素的数据信息。。在全息数据信息条件下,或许可以颠覆传统经济学研究范式,通过简单的数据统计分析即可发现经济规律,但在可见的未来,全息数据信息依然是无法实现的目标。
大数据的出现给当前的经济学研究带来了不同的数据信息来源,通过这些数据来源获取的数据信息能够改进传统统计数据的不足。由于大数据信息并不等同于全息数据信息,因此无法完全涵盖影响某一经济学问题的全部因素。基于以上的分析,大数据仅是对传统统计数据的补充,能在局部改变经济学的研究范式,而非对传统经济问题研究范式的颠覆。
当前,大数据在经济学中的应用相对混乱,还没有形成固定范式。另外,大数据概念发展至今,也依然没有形成广泛认可的理论来支撑大数据的应用。截至目前,最为常用的大数据信息为网络搜索数据以及文本数据。本研究认为未来可以研究网民检索行为的规律,组成大数据理论的一部分,为应用大数据信息来分析经济问题提供理论支撑。此外,随着自然语言处理(NLP)技术的发展,文本数据将极大扩展经济问题研究思路,为大数据理论分析和应用带来广阔的应用前景。大数据噪声是影响大数据应用于经济问题分析的主要因素,探索合理有效的大数据去噪方法或理论是未来大数据应用研究的主要方向。
猜你喜欢
社会科学战线(2022年8期)2022-10-25
甘肃教育(2021年10期)2021-11-02
福建基础教育研究(2020年3期)2020-05-28
中国国情国力(2020年1期)2020-03-06
社会观察(2018年9期)2018-11-17
领导决策信息(2018年16期)2018-09-27
英美文学研究论丛(2018年1期)2018-08-16
数学学习与研究(2017年3期)2017-03-09
计算技术与自动化(2014年1期)2014-12-12
西南学林(2011年0期)2011-11-12
