
基于改进的Mask R-CNN自然场景下苹果识别研究
2022-02-15 05:27吕继东王艺洁夏正旺马正华
常州大学学报(自然科学版) 2022年1期
吕继东, 王艺洁, 夏正旺, 马正华
(常州大学 微电子与控制工程学院, 江苏 常州 213164)
国内经济的蓬勃发展,给人们提供了越来越多的就业机会,但是却导致从事农业领域的人员不断减少,人工劳动成本的增加,给果树种植业带来很多不利的影响。因此,开发具有视觉功能的智能采摘机器人,有助于降低人工生产成本,提高劳动生产率,保证果实的适时采收,具有极大的应用价值和现实意义[1-2]。
视觉系统是果蔬采摘机器人的重要组成部分[3],是保证果蔬采摘机器人在采摘任务过程中能够快速识别和准确定位目标的关键子系统之一。刘继展[4]详细阐述了目前国内外温室采摘机器人视觉技术的发展现状及遇到的困境,发现许多国家已经研制出温室环境采摘机器人,但是这些采摘机器人在非结构化环境中采摘效果并不理想。项荣等[5]对采摘机器人中常用的目标快速识别与定位方法进行了总结分析,果蔬的识别定位受自然环境因素的影响很大,如光照变化、枝叶遮挡等,都是急需解决的关键难题。
与传统的图像目标识别算法相比,人工神经网络在图像识别领域中展现出了巨大的优势,并引起了研究人员的广泛关注。例如,傅隆生等[6]使用LeNet网络模型来进行田间多簇猕猴桃的识别,相比于传统的果实目标识别方法,识别率提升了5.37%,表明卷积神经网络在田间果蔬识别方面具有巨大的优势。薛月菊等[7]采用改进的带密集连接Tiny-yolo-dense的YOLOv2网络来实现特征的复用和融合,提高了检测的精度。虽然至今还没有完全理想的深度神经检测网络,但是在一定程度上表明它在果蔬目标检测领域具有广泛的应用前景[8-9]。
基于改进的Mask R-CNN神经网络模型对不同光照角度下多种颜色苹果的识别展开研究。Mask R-CNN网络能够同时对输入图像进行目标检测与分割,比单独进行目标检测的网络模型具有更高的识别性能。同时,在采集数据时综合考虑苹果目标的生长阶段、光线强度、光照角度等因素,构建了一个具有广泛代表性的数据集。
1 深度学习目标检测与实例分割网络
深度神经网络模型是一类可以从低级特征构建出高级特征来学习特征层次结构的多层网络模型,通过对海量训练数据的周期迭代来学习更有用的特征,提升深度网络模型的分类或预测的准确性。因此,深度模型是手段,特征学习是目的。
文章的方法建立在Mask R-CNN[10]网络架构之上,它是Faster R-CNN在实例分割领域的扩展,下面分别对这2种架构进行简要的介绍。
1.1 Faster R-CNN
Faster R-CNN的架构主要分为3大部分:共享的卷积层-backbone、候选区域生成网络-RPN(Region Proposal Network)和候选区域分类网络-classifier,如图1所示。输入的图片首先通过卷积神经网络进行特征提取,将得到的Feature maps送入RPN网络,RPN网络生成待检测区域(Regions of Interest, RoI),RoI Pooling Layer根据RPN网络的输出在Feature map上面选取每个RoI对应的特征,并固定维度值。最后通过全连接层(FC Layer)对目标框进行分类,最后输出物体的类别和位置。Faster R-CNN真正实现了端到端(end-to-end)的训练。

图1 Faster R-CNN网络结构图Fig.1 Faster R-CNN network structure diagram
1.2 Mask R-CNN
Mask R-CNN和Faster R-CNN最大的差别是多出1条掩码分支,它在每个感兴趣区域加上了1个用于预测分割掩码的分层,称为掩码层(Mask Branch),该分支与目标分类和检测回归的分支并行执行。Mask R-CNN不仅能够有效地检测图像中的目标,同时为每个实例生成一个高质量的分割掩码(Segmentation Mask),如图2所示。与Faster R-CNN相比,掩码层只是给整个系统增加了一小部分的计算量,但却能同时得到目标检测和实例分割的结果。应用到采摘机器人中,不仅可以识别出当前图像中的目标果实,并且可以得到精确的位置信息,这是采摘机器人执行采摘动作所需的关键信息参数。

图2 用于实例分割的Mask R-CNN框架
Faster R-CNN中的RoI Pooling在运行过程中,存在着两次量化,又称为取整操作。这样的操作会降低检测目标位置的准确性,对单纯的目标分类影响不大,但是对于像素级图像分割就会存在很多问题。因此,Mask R-CNN中使用RoI Align代替原先的RoI Pooling,它不再进行直接的取整操作,而是保留经过网络层压缩之后存在的浮点数,并用双线性插值算法取代Faster R-CNN中的第2次量化,这样就可以得到更加精确的位置信息。
2 数据集制作与模型优化
2.1 多样性数据集制作
深度神经网络的训练离不开数据集的支撑,本次实验采用的原始数据通过自行拍摄和网络图片爬虫两种方式获得。数据集中包括顺光、逆光、侧光和LED照明4种不同光照情况下的红色苹果、黄色苹果、红绿相间的苹果以及绿色苹果等多种种类苹果数据,如图3所示。

(a) 顺光

(e) 红色
数据集中包含不同光照条件下各种颜色苹果图片100幅,合计1 600张。为减少后续实验运行时间,首先将1 600张原始图片通过双线性插值算法缩放为512×384像素,然后对图像进行人工标注。本次实验采用python版本的Labelme,为实现图像分割操作,在标注时采用“多边形”选项进行标注,需完全拟合苹果轮廓,属于1个物体的苹果目标给予1个标签位。对所有种类的苹果,只设置apple 1个标签。图像标注后,随机选取不同光照和颜色共320张图像作为测试集,其余1 280张图像作为训练集用于网络的训练。
由于光照条件的不确定因素,导致图像采集时光照条件十分复杂,为了提高训练模型的泛化能力,对1 280张训练集图片进行了图像亮度增强及减弱、色度增强及减弱、对比度增强及减弱、锐度增强及减弱8种处理。其中,图像的亮度、色度和对比度均增强为原始图像的1.5倍,锐度增强为原始图像的3倍,亮度、色度、对比度和锐度分别减弱为原始图像的50%,50%,50%和10%。此外,为了模拟设备在图像采集过程中可能产生的噪声,对原始图像添加了方差为0.01的高斯噪声。图像扩增后,原始标注仍然有效。为了更好的检测模型的拟合能力,同时更贴近真实的非结构化作业环境,对320张测试集样本采用不同的样本增强策略,随机组合颜色抖动、左右翻转、随机裁切以及随机噪声4种策略中的2种对每张图进行变换扩充样本,训练集与测试集之间无重叠。
2.2 基于膨胀卷积的多层特征提取策略
Mask R-CNN的主干网络 (backbone)即特征提取网络,主要用于提取整个图像上的特征,主干网络性能的好坏会直接影响网络后续的检测与分割效果。Mask R-CNN的主干网络有多种网络结构可以进行选择,深度残差网络(Residual Neural Network, ResNet)能很好的解决神经网络训练过程的梯度消失问题。本次实验选取常用的2种残差网络模型ResNet50和ResNet101[11]分别作为Mask R-CNN的主干网络。
深度神经网络模型是一类可以从低级原始特征中自动学习抽象出高级语义特征的多层网络模型。卷积神经网络(Convolutional Neural Network, CNN)[12]通过训练滤波器和局部邻域池化操作交替作用于原始输入数据,其间会输出一系列抽象、复杂的特征[13]。卷积层的主要作用是进行特征提取,卷积层中的每个神经元分别连接到上一层的局部感受野提取特征。卷积神经网络中卷积操作示意图如图4所示,中间红色矩阵为3×3的卷积核,计算方式为卷积核对应位置的数据与局部感受野对应位置的数据进行相乘求和操作。卷积核会在原始数据上执行滑动窗口操作,大部分情况下,步长都设置为1。ResNet采用跳连的方式,去掉了CNN中常用的池化操作,是一种减轻网络训练负担的残差学习框架,在一定程度上避免了网络训练过程中的梯度弥散、梯度爆炸等问题。然而,本文的主要目标是对输入数据中的苹果进行识别,针对成簇的苹果和比较密集的苹果,ResNet可能会受限于神经元感受野大小,对苹果目标的轮廓特征等并不能进行有效的学习,在网络后续进行像素级分割时会出现边界混乱的情况(即距离特别近的一簇苹果容易被识别为1个苹果)。增大神经元的感受野在深度学习中通常又是通过池化操作或增大卷积核尺寸来实现, 但是在ResNet中执行池化操作会造成信息的损失,增大卷积核尺寸又会增加训练参数,两者都不是特别有效的方式。所以文中采用Dilated Convolutions(膨胀卷积或叫空洞卷积)[14]对ResNet50和ResNet101的残差学习模块进行改造,这样既可以增大神经元的感受野,还可以避免空间信息的丢失。膨胀卷积操作是在原始卷积操作的基础上增加了一个膨胀系数r,能将卷积核扩张到膨胀系数所约束的尺度中。单个神经元在不同膨胀系数下的感受野如图5所示。

图4 卷积神经网络卷积操作Fig.4 Convolutional neural network convolution operation
(a) r=1
于是,可以得到有效卷积核的高和宽分别如式(1)、式(2)所示:
Ch=fh+(fh-1)×(r-1)
(1)
Cw=fw+(fw-1)×(r-1)
(2)
式中:fh为原卷积核的高;fw为原卷积核的宽。
本文将res2层b模块中卷积核为3×3大小的卷积层改造为空洞卷积层,如图6所示,采用的膨胀系数为{1,2,3}的排列[15],下文详细讨论分析网络改进前后的性能。

图6 带膨胀卷积的ResNet网络模块Fig.6 ResNet network module with dilated convolution
3 实 验
3.1 改进前后模型性能对比
为了验证文中所提方法在苹果识别中的性能优势,需要同时考虑准确率和召回率,故用F1值对网络识别结果进行评价。
(3)
(4)
(5)
式中:λpre为准确率;λrec为召回率;TP为算法识别正确的苹果区域的像素点个数;FP为算法将背景区域像素点误识别为苹果的像素点个数;FN为算法将苹果区域的像素点误分为背景的像素点个数。
Mask R-CNN的损失函数主要包括3部分,见式(6)。
L=Lcls+Lbox+LM
(6)
式中:Lcls和Lbox与Faster R-CNN中的相同,分别是利用全连接预测出的每个RoI所属类别和最小外接矩形框的损失函数;LM为Mask损失函数。
本文使用随机梯度下降法对网络以端到端的方式进行训练,为了提高训练效率,使用在线难例挖掘(online hard example mining, OHEM)策略,网络的初始学习率设置为0.001,权重衰减设置为0.000 1,动量因子设置为0.9。实验在采用自己制作的数据集进行训练前,分别将原始Mask R-CNN与改进的Mask R-CNN网络模型在COCO2017数据集上进行了预训练。
实验采用相同的训练集测试集对比分析对改进前后的Mask R-CNN性能差异,并绘制2个网络模型的loss曲线,如图7所示。由图7可以看出,改进Mask R-CNN的收敛速度要比原始Mask R-CNN网络快。当迭代周期达到5次时,改进Mask R-CNN网络基本趋于收敛,原始Mask R-CNN网络模型则要迭代到27次左右,模型才趋于收敛。改进Mask R-CNN的损失值最终趋近于0,要低于原始Mask R-CNN网络。
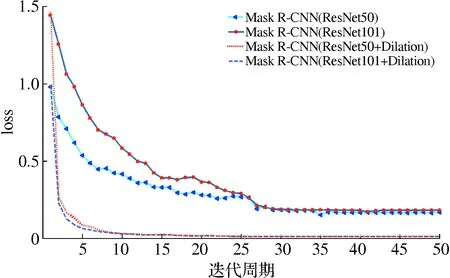
图7 改进前后loss函数曲线图Fig.7 Loss function curve before and afterimprovement
4种网络模型训练过程的准确率-召回率曲线如图8所示。引入AUC(Area Under Curve)曲线下面积用于量化对比不同网络模型的泛化性能。AUC值可以直观的反映学习器性能的优劣,由图8可以看出,改进前后的Mask R-CNN的AUC值均可达到了0.90以上,但改进后的Mask R-CNN网络算法的AUC值提高了0.05左右。

图8 准确率-召回率曲线Fig.8 Precision-recall curve
为了更好地对比不同网络模型特征提取的差异,将特征提取的部分结果进行可视化操作。由于高层特征图的维度较低,显示的特征较少,图9给出了根据最终权重模型得到的输入RoIAlign模块的特征二值化可视化结果。每一行第1列为原图,中间为可视化结果,右边为识别结果。对比分析可以发现,4种网络模型都对苹果的边缘特征比较敏感,而改进Mask R-CNN网络模型提取的边缘特征较原始Mask R-CNN亮度要亮。

(a) Mask R-CNN(ResNet50)

(c) Mask R-CNN(ResNet50+Dilation2)
3.2 多类型目标识别性能对比分析
为了验证本文改进Mask R-CNN算法模型对不同属性苹果目标的识别性能,进一步统计分析了5种不同网络模型在测试集不同类型图片上的识别结果。YOLO v3网络因在目标检测领域具有较快的运行速度和较高的准确率,许多科研工作者将其应用于水果自动采摘领域。本文将原始Mask R-CNN算法和改进Mask R-CNN算法与YOLO v3目标检测网络进行对比。
针对不同光照条件和不同颜色的苹果,5种不同网络模型的具体识别性能结果见表1和表2。

表1 不同网络模型在不同光照角度下的识别性能

表2 不同网络模型对不同颜色苹果的识别性能
由表1和表2可知,基于Mask R-CNN框架的多种网络模型在多种场景下的识别效果均优于YOLO v3网络,这主要是因为Mask R-CNN网络能够同时对输入的图像进行目标检测与分割操作,比单独进行目标检测的网络模型具有更好的检测效果。同时,容易发现5种网络模型对顺光和红色苹果的识别效果最好,对逆光和黄色的识别效果最差,这可能是因为红色苹果与绿叶等背景色差比较大,顺光的情况下苹果轮廓比较清晰;黄色苹果因为颜色比较淡,在逆光的情况下色差不明显等原因造成的。在识别速度方面,YOLO v3达到了每帧20.18 ms;对基于Mask R-CNN框架的网络模型,主干网络是ResNet101的网络模型比对应的ResNet50网络模型检测速度平均慢10 ms左右,膨胀改造后的网络模型比对应的Mask R-CNN网络模型速度平均慢2 ms左右。在识别性能方面,膨胀卷积改造后的网络模型要比原始的Mask R-CNN网络模型F1高2%左右,说明膨胀卷积结构有助于提升模型的识别性能。
不同类型苹果在不同网络模型结构下的识别效果如图10所示。图10中,每一行最左边的图为待识别的原图,第2张到第6张分别代表网络模型YOLO v3, Mask R-CNN (ResNet50), Mask R-CNN (ResNet101), Mask R-CNN (Dilation+ResNet50)和Mask R-CNN (Dilation+ResNet101)的识别效果图。从图10可以看出,红色苹果与背景色差大,轮廓清晰,易识别;黄色、绿色苹果颜色与背景色差小,识别难度有所增加;红绿相间的苹果识别难度介于两者之间。此外,苹果在顺光、侧光和LED灯等光照条件下纹理清楚,表面光照强度均匀,识别难度小;在逆光情况下,苹果边缘轮廓模糊,识别难度大。观察逆光黄色苹果的识别结果可以发现,从识别数量上可以看到,Mask R-CNN (ResNet50)和Mask R-CNN (ResNet101)网络模型均未识别出右上角的苹果,改进后的Mask R-CNN模型较好的识别出图片中右上角的苹果,这说明膨胀卷积有助于提取更加抽象有效的特征。

(a) 顺光红色苹果

(b) 逆光黄色苹果

(c) 侧光红绿相间苹果

(d) LED照明绿色苹果
3.3 大小成簇目标识别性能结果分析
小目标检测一直是深度学习领域亟待解决的一大难题。因为小目标常常成簇聚集在一起,目前主流的目标检测模型难以进行有效地分辨,常会出现漏识的情形。在苹果采摘环节,也存在着大小成簇目标聚集的情况,摄像头距离苹果的远近不同,采集到的图像中苹果目标大小也不相同,识别难度也全不相同。针对大小目标的情形,由于本文神经网络模型输入图片的大小固定为512×384像素,根据图片中待识别目标距离的远近划分大小目标。分析发现,距离较近的苹果目标,表现出目标数量少,尺寸大的特征,因此,根据图片中苹果数量的多少划分大中小苹果目标。实验中将测试集图片共划分成3个等级,大目标(图片中包含1~2个苹果)、中等目标(图片中包含3~5个苹果)、小目标(图片中苹果数量超过5个),待识别苹果数量越多,识别难度越大。5个不同的网络模型具体识别性能对比如图11所示。图11中不同网络编号对应的不同网络模型具体为:编号1对应的网络模型是YOLO v3;编号2对应的网络模型是主干网络为ResNet50的Mask R-CNN网络;编号3对应的是主干网络为ResNet101的Mask R-CNN网络;编号4对应的是主干网络为ResNet50的膨胀卷积Mask R-CNN 网络模型;编号5对应的是主干网络为ResNet101的膨胀卷积Mask R-CNN 网络模型。

图11 不同大小目标识别性能结果Fig.11 Recognition results of large and small object
由图12容易看出,5种不同网络模型针对大目标的识别效果都特别好,识别性能F1值都在0.95以上。在对小目标进行识别时,YOLO v3的识别性能只有0.84左右。针对小目标,识别性能最好的是5号网络,F1值接近0.95。4号网络和5号网络模型识别性能比较接近。5种网络模型针对不同大小苹果的识别效果如图12所示。图12中,每一行最左边的图为待识别的原图,第2张到第6张分别代表编号为1~5网络模型的识别效果图。在识别结果中也可以看出,大目标和中等目标均未出现漏识的情况;观察小目标识别效果图可以发现,虽然红色苹果与背景色差大,由于苹果遮挡严重,待识别目标轮廓模糊等原因,使得许多苹果出现了漏识;对比可以发现,改进的Mask R-CNN取得了最好的识别效果。

(a) 大目标

(b) 中等目标

(c) 小目标
4 结 论
以自然场景下果园苹果果实的识别为研究对象,研究结果发现,与原始Mask R-CNN网络相比,针对不同光照角度、不同颜色以及不同大小的苹果,基于膨胀卷积改进的Mask R-CNN网络在多种情形下的识别性能均有提升。主干网络为ResNet50或者ResNet101时,经过膨胀卷积改进过的Mask R-CNN网络不仅收敛速度快,而且网络的损失值也有所降低。这证明了本文的网络模型优化策略是可行的。采用包含膨胀卷积结构的ResNet代替原始的特征提取网络ResNet网络,不同光照角度、不同颜色苹果的F1值提升2%左右,加快了模型的收敛速度。针对不同大小苹果的识别,与经典Mask R-CNN相比,改进Mask R-CNN的识别效果与原始Mask R-CNN相比,改进Mask R-CNN的F1值提升了4.93%。
猜你喜欢
分子催化(2022年1期)2022-11-02
今日农业(2022年14期)2022-09-15
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
电脑报(2019年17期)2019-09-10
初中生世界·九年级(2018年12期)2018-12-22
读者(2015年9期)2015-05-04
初中生世界·八年级(2014年2期)2014-03-15
