
基于深度学习的司法判决预测算法研究
2022-02-13 11:53周法国刘文葛逸凡李夷进
科学技术与工程 2022年36期
周法国, 刘文, 葛逸凡, 李夷进
(中国矿业大学(北京)机电与信息工程学院, 北京 100083)
2020年最高人民法院工作报告指出,地方各级人民法院和专门人民法院受理案件3 080.5×104件,而在2010年,这个数字为1 170×104件。由于法律工作的专业性,面对庞大且不断增长的各类纠纷,从事司法相关工作的人员缺口也越来越大。2015年3月25日,最高人民法院信息化建设工作领导小组首次提出智能法院的概念,2018年开始举办的司法人工智能挑战赛[1]也加速了司法人工智能研发,促进了学科发展。将人工智能应用与司法领域有很多场景,如司法判决预测、相似案件匹配以及信息抽取等。
司法判决预测指的是依靠真实案情陈述文本,确定案件的最终判决。它在智能司法中发挥着不可替代的作用。它不仅能为法律工作者提供参考,也能为不了解法律相关知识的普通人提供法律建议。
司法判决预测的研究工作已经进行了几十年。早期的研究人员使用数学计算方法来分析影响决策的事实因素并预测罪名。但是只有特征明显的案例和规模较小的数据集才会有一定的效果,很难将方法进行推广。后来,随着机器学习的发展,研究人员开始从案情陈述中提取有效特征,并通过机器学习方法进行预测,如朴素贝叶斯或支持向量机等[2]。然而,这些方法对手动特征有严重的依赖,很难在更大的数据集上收集特征。近年来,随着深度学习在自然语言处理、计算机视觉和语音方面的成功,神经网络被广泛应用于对案情陈述文本进行建模。
然而,罪名预测在现实场景中仍然存在两个主要挑战:少样本罪名和易混淆罪名预测,并且有些容易混淆的罪名往往样本数量少。一方面,在真实司法数据集中,不同罪名的案件数量极不平衡,前10种罪名占数据集中近80%的案件;后10种罪名在数据集中的占比不到0.2%。在少样本数据类别较多的情况下,一般的深度学习模型表现不佳。为了解决这个问题,Wang等[3]引入Mixup方法进行数据增强,同时提出使用图卷积神经网络进行特征提取并增强。Zhang等[4]使用基于共同信息的损失函数解决样本不平衡问题。另一方面,在真实的司法数据集中,还存在一些难以区分的罪名,如放火罪和失火罪、滥发林木罪和盗伐林木罪等。这些罪名在案情描述上极其相似,但司法判决结果却各不相同。为了区分相似罪名在案情陈述上的细微差别,Xu等[5]提出了使用图神经网络来提取法律文本之间的易区分特征,从而提高模型识别能力。Hu等[6]引入10个具有区分性的罪名属性标签,为区分混淆罪名提供了帮助,同时人工标注只需要少量的工作,但模型可解释性欠佳。Zhong等[7]提出了QAjudge,提高了司法判决预测可解释性。殷敏等[8]结合支持向量机与预测解释框架,对影响因素进行分析,提高预测结果解释性。张虎等[9]对裁判文书进行要素抽取,提高模型预测效果,但子任务间耦合度较高。王婉臻等[10]总结了近年来人工智能在司法判决预测领域的研究成果。
综上,提出一种基于BERT(bidirectional encoder representations from transformer)预训练模型和双向门控循环单元(bidirectional gated recurrent unit,BiGRU)的混合模型提升性能,并借鉴了Hu等[6]提出的罪名属性标签思想,使用自注意力机制对每个属性标签进行对应的特征提取,同时利用10个属性标签增强司法判决预测任务的可解释性,并通过实验证明所提方法的有效性。
1 自注意力机制
自注意力使得每个词向量都能考虑整句话的前后文相关信息[11],假设向量a1、a2、a3表示某句案情陈述所提取的特征向量,那么自注意力层的流程操作如图1所示。
通过输入向量a1、a2、a3,得到输出向量b1、b2、b3。其中每一个bi都是考虑过整句信息的,具体流程如下。首先对每一个向量a,都要计算自身和其余向量之间的注意力分数,也就是找到序列中的相关向量,计算方式有很多,采用常见的点积进行计算,具体地,由向量a1乘以矩阵Wq计算得出q1,再由其余向量如a2乘以矩阵Wk得到k2,最后计算q1和k2的点积,即可得出向量a1和向量a2之间的注意力分数。值得注意的是,每一个向量ai均要与a1进行计算,包括a1本身。

图1 自注意力机制结构图Fig.1 Self-attention mechanism structure diagram

(1)
式(1)中:qi为查询向量;ki为特征向量;Wq和Wk为系数矩阵,随模型训练进行计算更新。
经过上述计算得到向量a1和其他向量的相关程度a1,1、a1,2、a1,3,然后采用常见的softmax进行归一化处理得到注意力分数α′1,1、α′1,2、α′1,3,其表达式为
(2)
将向量ai乘以矩阵Wv得到对应的向量vi,将vi与式(2)得到的注意力分数相乘并求和得到b1,其余向量bi的计算方式类似,故不再赘述。计算过程可表示为

(3)
式(3)中:vi为值向量;系数矩阵Wq、Wk、Wv由神经网络通过大量文本语料训练得到。
自注意力机制自2017年开始受到研究人员的广泛关注,并将其应用于自然语言处理的各个任务中。
2 BERT预训练模型
BERT模型是基于Transformer的网络模型,仅使用其编码器部分。因此在介绍BERT前,首先进行Transformer介绍,2017年 Google团队提出了Transformer新型网络架构,它完全基于注意力机制,如今已有多种变体[12],其模型结构如图2所示。

图2 Transformer模型结构图Fig.2 Transformer model structure diagram
2.1 自注意力
自注意力使用注意力机制来推断句子中标记之间的关系,并学习同一个句子的表示。在Transformer中,自注意力是通过缩放点积注意力和多头注意力来实现的。

(4)
式(4)中:Q、K和V分别为query、key和value序列;dk为k的维数。
多头注意力之所以如此命名,是因为它依赖于多个注意力实例。将从输入向量中获得的K、Q和V乘以不同的学习矩阵,以生成多组K、Q和V。每组K、Q和V都被送入缩放的点积注意力函数并返回输出值。然后将所有返回的头连接为矩阵并投影以得出最终值。与单头注意力相比,多头注意力扩展了模型在不同位置处理信息的能力,而不会增加总计算成本,计算公式为
(5)
2.2 位置全连接前馈网络
在自注意力层之后,是一个完全连接的前馈网络(fully connect feedforword network, FFN),独立地应用于输入序列的每个位置。自注意力的输出被送到一个线性函数,然后是一个Relu函数,最后后用另一个线性函数进行投影,可表示为
FFN(x)=max(0,xW1+b1)W2+b2
(6)
式(6)中:Wi为权重矩阵;bi为偏置向量;x为输入的向量。
2.3 残差连接和层归一化
编码器和解码器层中每个子层的输出通过残差连接和层归一化进行修改。残差连接被提出来解决深度卷积神经网络中增加的训练错误和模型性能的下降,残差学习将输入添加到神经网络层的输出。层归一化使用层中所有输入值的均值和标准差对神经网络层中的输入值进行归一化,这种归一化加速了神经网络的训练时间。
2.4 位置编码
与考虑序列中标记顺序的循环神经网络相比,Transformer结构不存储位置信息。为了解决这个问题,在编码器和解码器堆栈的入口处的输入中添加了位置编码。Transformer中的位置编码采用正弦函数对序列中的位置信息进行编码,因为它可以毫不费力地处理相对位置,位置编码PE的表达式为
PEpos,2i=sin(pos/10 0002i/dmodel)
PEpos,2i+1=cos(pos/10 0002i/dmodel)
(7)
式(7)中:pos为位置;i为维度;dmodel为词向量维数。
BERT是预训练语言表示的最先进模型,通过执行掩码语言模型任务和下一句预测任务来考虑双向表示[13],适合处理文本数据。
2.5 掩码语言模型任务
通过随机屏蔽输入序列中特定百分比的标记并基于未屏蔽标记预测被屏蔽标记来处理输入序列的左右上下文。在将日志序列中的标记转换为嵌入向量之前,选择了15%的标记并替换为[MASK]标记。在实践中,[MASK]标记不会出现在微调过程中。为了减轻这个,当一个标记被屏蔽之后,80%的时候这个标记都会被替换为[MASK]标记,10%会替换成语料库里随机的词,还有10%不变,BERT的目标函数只考虑被屏蔽的标记的预测。
2.6 下句预测任务
NSP(next sentence prediction)专为需要理解句子关系的下游任务而设计。在预训练中,下一句预测从语料库中生成由两个句子A和B组成的句子对。给定前面的句子A,50%的时候B是A之后的后续句子,而50%的时候B是来自语料库的随机句子。为了区分两个句子,在每个句子的末尾注入了一个特殊的标记[SEP]。此外,在输入样本的开头插入了[CLS]标记。[CLS]表示可以馈送到输出层进行分类。在将这些特殊标记合并到输入序列中后,将段嵌入添加到标记嵌入和位置嵌入中。段嵌入暗示每个标记属于哪个句子。NSP任务使用IsNext或NotNext标签来确定句对之间是否存在连接。因此,NSP损失函数被视为二元分类损失。
3 BiGRU模型
介绍GRU(gated recurrent unit)之前,首先需要了解RNN(recurrent neural network),它是一种具有记忆功能的人工神经网络。RNN之所以被称为循环神经网络,是因为它们可以学习并保存过去的信息,然后将其用于未来的预测,可表示为
ht=tanh[Wx(t)xt+Uh(t)ht-1+b)
(8)
式(8)中:xt为时间t的输入;ht为单元在时间t的隐藏信息;Wx(t)为x在t时刻的权重矩阵;Uh(t)为ht-1在时间t的权重矩阵;b为偏差。
在t时刻,新的输入和上一个单元格的记忆同时输入,在两个不同的权重矩阵的作用下组合成一个新的向量。这个向量包含了当前的输入信息和之前的记忆,在激活函数tanh的激活下,得到了t时刻新的隐藏记忆。然后输入下一个以时间t的信息作为输入的单元格。
循环神经网络(recurrent neural network,RNN)在处理长文本时容易出现梯度消失的问题,因此产生了长短期记忆(long-short-term-memory,LSTM),它是一种用于深度学习领域的长期短期存储网络,可以学习长期依赖,LSTM在每个时刻t都引入了细胞状态Ct,用于表示当前时刻保存的信息。LSTM的具体步骤如下。
步骤1决定哪些信息将被称为“遗忘门”的sigmoid层放弃或保留在细胞状态中。门的输入是隐藏特征ht-1和当前时刻输入xt,输出是细胞状态Ct-1的权重(0-1)矩阵,其中1代表“完全保留”,0代表“完全摆脱”,遗忘门的表达式为
ft=σ(Wfxt+Ufht-1+bf)
(9)


(10)
步骤2中,通过从输入门获得的信息更新旧的细胞状态Ct-1。首先,将“遗忘门”中得到的ft与Ct-1相乘,对旧信息进行过滤,确定旧信息的保留和丢弃,乘以1表示信息完全保留,乘以0表示信息完全丢弃。然后将输入门中得到的结果相乘,得到需要添加的新信息,将更新后的旧信息组合起来,形成新信息记录在细胞状态中,可表示为

(11)
步骤3需要从细胞状态决定这个重复模块的输出是什么。首先,生成一个加权矩阵,通过一个sigmoid层来决定细胞状态的输出部分,其中“1”代表输出所有信息,“0”代表什么都不输出。然后,通过tanh函数将单元格状态的值推到-1和1之间,然后将其乘以加权矩阵以输出决定的单元格状态ht部分,如式(12)所示。

(12)
式中:ft为遗忘门;it为输入门;ot为输出门;Wi、Wo、Wf、WC为不同门控机制对输入xt的权重;Ui、Uo、Uf、UC为不同门控机制对隐藏特征ht的权重;bi、bo、bf、bC为偏置向量;σ为sigmoid函数,作用是把数据范围映射在0~1内,成为门控制信号;ct为当前t时刻的存储单元信息
GRU是LSTM的一种变体,它将遗忘门和输入门组合成一个“更新门”,并且还合并了单元状态和隐藏状态,将长期和短期信息保持在一起。因此,与传统的LSTM相比,GRU的效率更高[14],算法流程可表示为

(13)

GRU继承了RNN的优势,也解决了RNN在长文本下梯度消失的问题。但GRU只能顺序进行,也就是说只能联系前文信息。BiGRU能同时关注到上下文信息,适合处理长文本任务。
4 算法流程与实现
传统的基于深度学习的司法判决预测方法,存在各种各样的问题,有些方法需要借助额外法条任务辅助,有些方法从未考虑少样本罪名和易混淆罪名预测场景或者仅考虑一种情况,有些方法使用不同的网络模型进行伪数据生成来解决数据不平衡问题,有些方法则没有考虑司法判决预测任务的特殊性而进行可解释性分析。因此,使用BERT模型和BiGRU模型进行文本的特征提取,通过添加AATT模块(罪名属性标签模块)辅助司法判决预测任务,缓解了易混淆罪名判别问题,借助10个罪名属性标签,可以提升模型对混淆罪名的识别准确率。例如,放火罪和失火罪在案情描述中内容极度相似,但在罪名属性标签故意犯罪中,两种罪名的标签具有区分性,放火罪的故意犯罪标签为是,失火罪的故意犯罪标签为否,为混淆罪名的判别提供辅助。同时,AATT模块还有另一个功能,就是通过添加自注意力机制生成可视化图来缓解司法判决预测可解释性。
为了缓解司法数据集样本极度不平衡的问题,提出罪名分类权重方案,具体如下:首先用数据集样本总数除以各个罪名在数据集中的数量得到初步权重信息,通过对权重信息的分析观察,将权重值缩小 2 000 倍,得到的最小权重值为0.001 746,最大权重值为9.594 875。通过上述简单计算,将所有罪名分类的权重值压缩在10以内,需要注意的是,为了模型总体效果不受影响,故将权重值不足1的所有权重变为1,减少权重对样本数量很多的罪名的影响,同时使少样本罪名权重提升,增强其性能表现。最后在罪名分类和属性标签分类中均添加自注意力机制,通过可视化来增强算法的可解释性,总体算法流程如图3所示。

图3 算法流程图Fig.3 Flowchart of the algorithm
5 实验结果与分析
所使用的数据集均来自中国裁判文书网公开的真实案件判决。数据集分布如表1所示,数据集中的罪名属性标签说明如表2所示。

表1 不同数据集分布Table 1 Distribution of different datasets

表2 罪名属性标签信息Table 2 Charge attribute tag information
所使用的评价指标为司法判决预测常用的Acc(准确率)、P(精确率)、R(召回率)和F1(综合考虑P和R的指标),计算公式为

(14)
式(14)中:TP为预测为正例且预测正确;TN为预测为负例且预测正确;FP为预测为正例且预测错误;FN为预测为负例且预测错误。
图4展示了模型训练过程中损失函数loss和Acc的变化趋势。其中,模型的训练损失前期快速下降后期趋于稳定,验证损失稳中有降;模型的训练准确率无限接近于1,验证准确率稳步提升并趋于稳定。综上所述,所提出的BGAAT(BERT BiGRU attribute self-attention)网络模型符合深度学习神经网络训练客观规律,结果也符合预期。
表3展示了模型在3个数据集上的表现,并与基线模型及研究人员近两年提出的模型进行对比,由表中可以看出,本文模型效果有显著提升。
借助更为详细的罪名属性标签,提高模型效果的同时也将属性标签预测时的权重进行了可视化,如图5所示,由于案情描述文本过长,仅选择3处进行展示。图5中案例为寻衅滋事罪,可以看出各属性对关键信息权重更高,在提升性能的同时更好的解释了模型根据哪些内容进行罪名属性预测,提高了模型的可解释性。
为了说明模型在少样本罪名预测上的准确性,部分研究人员把数据集分为3部分,其中数据集中罪名出现次数小于10次的定义为少样本罪名,数据集中罪名出现次数大于100次的定义为高频罪名,中间部分定义为中频。
由表4可知,所提出的司法判决预测方案在保证中高频罪名预测效果的前提下,显著提高了模型在少样本罪名分类中的有效性,具体表现为保证中高频罪名预测任务中的F1指标不降低甚至有微弱提升的前提下,显著提升模型在少样本罪名预测任务中的F1值。
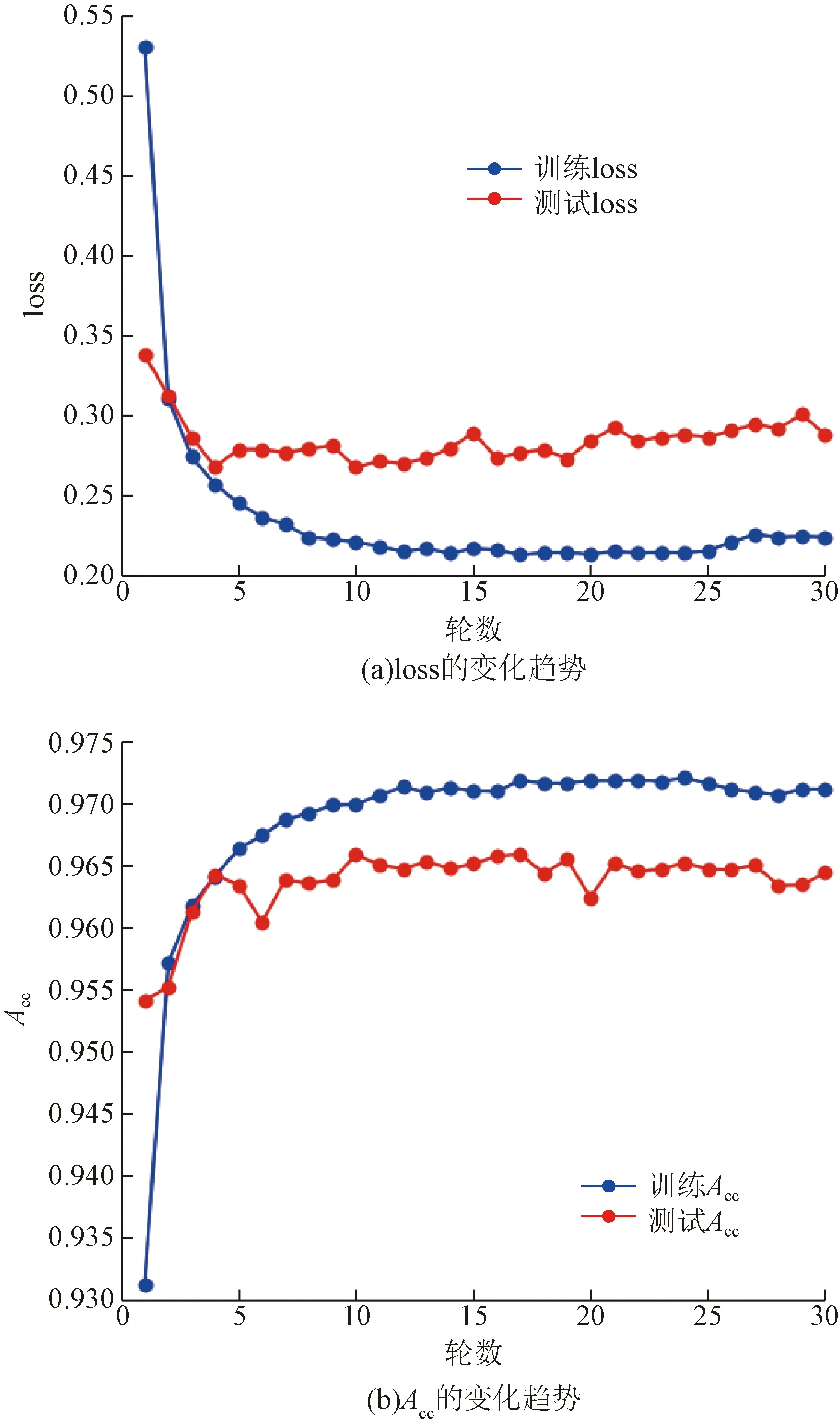
图4 模型训练过程中指标变化趋势Fig.4 Trend of metrics during model training

表3 3个数据集上各模型的效果对比Table 3 Comparison of the effects of each model on the three datasets

图5 罪名和属性标签的权重分布Fig.5 Distribution of charge and attribute labels
为了说明模型在易混淆罪名预测上的有效性,以常见的4组易混淆罪名为例,进行有效性分析和效果对比,它们分别是盗伐林木罪与滥伐林木罪、行贿罪与受贿罪、放火罪与失火罪、抢夺罪与抢劫罪。表5展示了本文模型与其他模型在易混淆罪名预测下评价指标F1值的比较结果。
为了更好地说明这些工作的有效性,进行了一系列的消融实验,验证所提出的AATT模块、标签属性损失权重以及各个罪名分类权重对模型性能的影响。
首先是AATT模块对司法判决预测结果的影响,表6展示了添加前后的结果,可以看出虽然Acc

表4 低频罪名预测Table 4 Low-frequency charge prediction

表5 易混淆罪名预测Table 5 Confusing charge prediction

表6 AATT模块添加前后对比Table 6 Comparison of AATT module added and not added
值仅有微弱的提升,但F1值提高了8.7个百分点,说明本模块对模型性能有明显的辅助作用。
其次是罪名属性标签损失权重对司法判决预测结果的影响,在多任务模型中损失权重的分配会对模型产生极大的影响,不同的权重分配会导致模型更关注某一个罪名属性标签信息,影响模型整体效果。表7显示了不同的标签属性损失权重产生的预测结果,可以看出,在罪名分类权重与罪名属性标签权重比例为2∶1时,模型的Acc、F1值更高,效果表现更好。
最后是各个罪名分类的权重对模型性能的影响,由于引入10个罪名属性标签,司法判决预测任务模型变为多任务模型,焦点损失函数无法适用。并且司法判决预测任务数据集罪名分布极其不均衡,故添加罪名分类权重并对权重压缩范围进行对比实验得到最优方案。如表8所示。

表7 不同标签属性权重对比Table 7 Comparison of different label attributes weights

表8 不同分类权重对比Table 8 Comparison of different classification weights
6 结论
目前的司法判决预测算法存在很多问题,例如模型性能欠佳,过于依赖伪样本生成或外部法条预测任务,没有考虑少样本和易混淆场景下的性能表现或者仅考虑其中一种情况,在可解释性方面没有细分等问题。结合BERT和BiGRU深度学习网络,同时借鉴了罪名属性标签的思想,提出BGAAT网络模型。使用BERT预训练模型进行文本向量化表示,使用BiGRU网络进行特征提取并通过训练更新参数,最后将自注意力机制应用在每一个罪名属性标签中并进行分类,通过可视化图形提高模型可解释性。本文算法在司法判决预测任务中Acc、F1指标均优于其他算法,并在少样本罪名预测和易混淆罪名预测场景中均有明显提升,可视化图形也有良好的解释性效果,从而提高模型在司法判决预测任务的效果。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
山东警察学院学报(2022年3期)2022-02-05
车迷(2018年11期)2018-08-30
环球时报(2018-05-19)2018-05-19
海峡姐妹(2018年3期)2018-05-09
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
浙江警察学院学报(2016年5期)2016-08-15
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
