
基于CNN-LSTM-lightGBM组合的超短期风电功率预测方法
2022-02-13 11:52王愈轩刘尔佳黄永章
科学技术与工程 2022年36期
王愈轩, 刘尔佳, 黄永章*
(1.华北电力大学电气与电子工程学院, 北京 102206; 2. 国网湖北省武汉电力公司信息通信分公司, 武汉 430000)
随着风力发电技术的日臻成熟,风力发电装机规模逐年加大,依据国家能源局发布的2022年上半年全国电力工业统计数据显示,全国风电装机容量约3.4×108kW,同比增长17.2%,风电已成为中国可再生能源的重要组成部分[1]。由于风电功率变化受环境气象影响较大,其出力呈现较大的间歇性和波动性,并网过程对电网安全稳定运行影响较大[2-3]。因此,提高风电功率预测精度对于风电并网的安全稳定运行具有重要意义。
为有效提高风电功率预测精度,学者们提出许多研究方法,预测方法按模型大致可分为单一模型预测和组合模型预测。单一模型预测方法简单,预测精度有待提高,常见的单一模型包括支持向量机(support vector machine, SVM)[4]、BP神经网络(back propagation neural network,BPNN)[5]、卷积神经网络(convolutional neural networks, CNN)[6]、长短期记忆网络(long short-term memory,LSTM)[7]、极端梯度提升 (extreme gradient boosting,XGboost)[8]、梯度提升学习(light gradient boosting machine, lightGBM)[9]等方法。组合模型通常在单一模型的基础上,通过组合方法来优化模型特征输入或者模型权重分配,从而获得更高的预测精度,更广泛地应用于各类时序预测问题当中,常见的组合方法有模态分解法、自适应权重学习法、最优加权组合法、误差倒数法等[10-12]。文献[13-14]首先采用变分模态分解法(variational mode decomposition,VMD)对风电功率数据集进行分解,然后使用权值共享门控循环单元(weight sharing gate recurrent unit, WSGRU)算法对其分量进行建模预测,最后对所有子分量预测值叠加输出风电功率预测值。文献[15]采用集合经验模态分解(complete ensemble empirical mode decomposition,CEEMD)对风电数据序列进行分解,分解得到的不同特征尺度的各分量作为最小二乘支持向量机(least square support vector regression, LSSVR)模型的训练输入量,将各分量的预测输出值叠加得到最终的风电功率预测值。文献[16]首先通过完全集成经验模态分解(complete ensemble empirical mode decomposition with adaptive noise analysis,CEEMDAN)对原始风电功率数据进行分解处理,然后利用改进的天牛须搜索算法(improved beetle antennae search algorithm, IBAS)和极限学习机(extreme learning machine,ELM)构建预测模型,分别预测每个序列分量,最后叠加每个序列分量的预测值得到最终预测值。文献[17]采用CNN对风电数据集进行特征提取, 然后基于自适应权重法建立CNN-LSTM&循环神经网络(gate recurrent unit,GRU)组合预测模型;文献[18]将负荷、温度、日期等数据信息作为数据输入,然后分别基于LSTM和lightGBM算法构建预测模型,最后基于最优加权组合方法确定组合预测模型。文献[19]首先采用LSTM和XGboost构建两种单一预测模型,然后应用误差倒数法建立了LSTM-XGboost的组合模型。
综上所述,组合模型在时序预测问题中的取得了不错的效果,但风电功率受当地环境气象和风力发电机组自身参数影响较大,如风速、风向、气压、空气密度、温度、风力发电机组利用率、功率曲线保证率等,环境气象数据多维、波动性较强,导致风电功率出现较大的日变化率和季节变化率,不同的风电资源呈现的风电功率特性完全不同,以张北曹碾沟风电场实际年运行数据统计为例,全年日平均出力变化率为32%~44%,全年季节平均岀力变化率可达21%~56%,面对海量多维、强波动的风电数据挑战,风电功率预测精度仍有待提高,探索新的组合预测模型需要深入研究。
鉴于此,以提高风电功率预测精度为目标,提出了基于CNN-LSTM-lightGBM组合的超短期风电功率预测方法。首先,分别建立CNN-LSTM和 lightGBM 的风电功率超短期预测模型。其中,CNN-LSTM模型,采用CNN对风电数据集进行特征处理,并将其作为LSTM模型的输入,从而建立CNN-LSTM融合的预测模型。然后,采用误差倒数法对CNN-LSTM和lightGBM的预测数据进行加权组合,建立CNN-LSTM-lightGBM组合的预测模型。最后采用张北某风电的风电数据集,以未来4 h风电功率为预测目标,验证组合模型的有效性。以期为超短期风电功率预测问题提供一种有效的解决方法。
1 CNN-LSTM预测模型
风电场采集的风电数据集主要包括风电功率、风速、风向、气压、空气密度、温度等,风电数据集包含海量多维数据,数据特征波动性较强,建立高精度的预测模型难度较大,为有效解决该问题,引入CNN算法对输入数据进行特征提取,然后将提取的特征提供给LSTM模型以进行读取,以此建立 CNN-LSTM 融合的风电功率预测模型。
1.1 CNN特征提取
CNN是处理具有类似网格结构数据的神经网络方法,其基本结构包括卷积层、池化层、全连接层[20]。卷积层通过卷积运算,可以使原数据特征增强,便于提取局部特征。池化层用于数据二次特征提取,同时降低神经网络参数数目。全连接层采用Softmax进行全连接,把提取的局部特征结合变成全局特征。二维卷积神经网络(2D CNN)被广泛应用于图像识别领域,而时序预测问题适用于一维卷积神经网络(1D CNN),故采用1D CNN提取风电数据集序列的特征信息,其特征提取过程如图1所示,数据经过多次重复卷积和池化,在此过程中提取的特征信息不断强化,该特征信息能有效反应风电功率变化的规律,最后将提取的特征信息展平,得到可用于LSTM模型的特征输入。

图1 1D CNN特征提取过程Fig.1 1D CNN feature extraction process
1.2 CNN-LSTM 模型结构
LSTM是一种特殊的循环神经网络(recurrent neural network,RNN),可在模型训练当中学习长期的数据变化规律。LSTM预测模型通过控制3个门完成预测任务,其中遗忘门控制信息保留,输入门控制信息输入,输出门控制信息输出[21],其原理结构图如图2所示。
LSTM学习训练过程如式(1)~式(5)所示。
Ft=ε(Mf[Ht-1,Xt]+bf)
(1)
It=ε(Mi[Ht-1,Xt]+bi)
(2)
Ot=ε(Mc[Ht-1,Xt]+b0)
(3)
Ct=FtCt-1+Ittanh(Mo[Ht-1,Xt]+bc)
(4)
Ht=Ottanh(Ct)
(5)
式中:ε为激活函数;Ft为遗忘门输出;It为输入门的输出;Ot为输出门输出;Ct为当前时刻神经单元状态;Ht为t时间步下的LSTM记忆单元的输出;Mf为遗忘门权重矩阵;Mi、Mc为隐藏输入门权重矩阵;Mo为单元到输出门权重矩阵,bi为输入门参数矩阵;Xt为当前t时间步的输入;bf为当前隐藏层遗忘门的偏差值;b0为当前隐藏层输入门的偏差值;bc为当前隐藏层记忆单元的偏差值。
CNN特征提取后,将提取特征展平并提供给LSTM模型输入层进行读取,然后经过多个隐藏层处理,将信息传入全连接层后得到预测输出,图3展示了CNN-LSTM的模型结构预测过程。
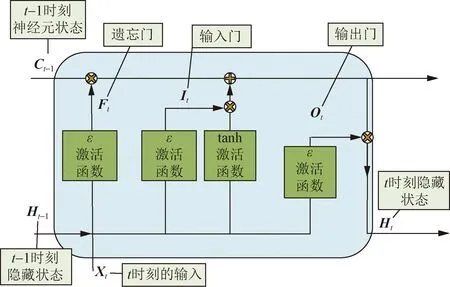
图2 LSTM原理Fig.2 LSTM principle

图3 CNN-LSTM 模型结构Fig.3 CNN-LSTM model structure
2 lightGBM预测模型
lightGBM是微软2017年基于梯度提升树(gradient boosting decisiontree,GBDT)提出的一种决策树集成学习算法[22-23],lightGBM通过引入基于梯度的单边采样(gradient-based one-side sampling,GOSS)和互斥特征捆绑(exclusive feature bundling,EFB)方法解决了传统GBDT在特征的分裂点需要遍历全部数据计算信息增益所造成的耗时问题。lightGBM的基本思想是通过集成cart回归树建立预测模型,其预测结果可表示为

(6)
式(6)中:fM(x)为预测值;ft(x)为第t棵树的输出值;R为树集合空间。
预测结果为每棵树的预测输出值的累加和。lightGBM模型采用Histogram(直方图)和带深度限制的叶子生长(leaf-wise)策略改进极大地提升了模型预测速度。直方图算法因其不需要额外存储预排序的结构,而是直接保存特征离散后的值,从而大大降低了内存的占用量,这也是直方图算法最大的优点,图4展示了直方图构建过程。
Leaf-wise是一种更为高效的叶子分裂成长策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子再次分裂,如此循环,其分裂过程如图5所示。Leaf-wise策略的缺点是可能会长出比较深的决策树,导致过拟合。因此,lightGBM在Leaf-wise基础上增加了一个最大深度的限制,从而保证高效率的同时防止过拟合。

图4 直方图构建过程Fig.4 Histogram construction process
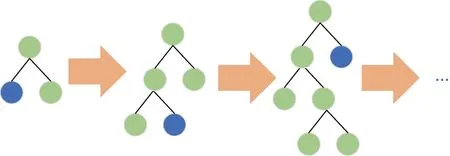
图5 leaf-wise树分裂过程Fig.5 Leaf-wise tree splitting process
3 组合模型设计
3.1 组合模型方法


(7)

(8)
3.2 组合模型预测流程
风电功率预测流程如图6所示,预测流程主要包括风电数据集预处理、CNN-LSTM和lightGBM模

图6 CNN-LSTM-lightGBM预测流程Fig.6 CNN-LSTM-lightGBM prediction process
型预测及参数优化、组合模型构建、预测结果误差分析,其中CNN特征处理和组合模型构建方法分别在1.1节、3.1节做过相关说明,在此不再赘述。
3.2.1 风电数据集预处理
数据预处理主要是剔除风电数据集中的不良坏数据,并将各量纲不同、数值差异较大的数据进行标准化处理。
采用max-min方法对数据标准化处理,计算公式为
(9)

3.2.2 CNN-LSTM和lightGBM模型预测及参数优化
该过程主要是将提取的风电数据特征代入CNN-LSTM和lightGBM模型进行预测,通过设置不同的模型参数观察模型的收敛速度和预测效果。因此,选择合适的模型参数是提高模型预测精度的关键步骤。
3.2.3 预测结果误差分析
为有效评估模型预测效果,选用4个评价指标:平均绝对误差(mean absolute error, MAE),记为τmae、均方根误差(root mean square error, RMSE),记为τrmse、平均绝对百分比误差(mean absolute percentage error, MAPE),记为τmape、确定系数(coefficient of determination),记为τR2对预测结果进行分析,其计算方式分别为

(10)
(11)
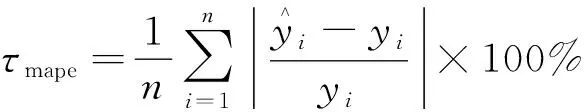
(12)
(13)

4 算例分析
以张北曹碾沟风电场年实际运行数据为例,该项目安装单机容量为1 500 kW机组,总装机容量49.5 MW,风电数据采样周期为15 min(每天96个采样点)。研究对象为超短期风电功率预测,依据《风电功率预测功能规范》对超短期风电功率预测定义为未来0~4 h的风电功率变化[24],故选取4h时长(16个采样点)作为预测目标。CNN-LSTM和lightGBM模型采用Python3.9语言编程实现,计算平台主要配置为Win10系统,Intel i7-10700@2.9 GHz,RAM 16 GB。
4.1 模型参数设置
首先,将风电数据集作为CNN模型的特征输入,包括风电功率、风速、风向、气压、空气密度、温度6个特征向量, CNN模型数据输入大小为 1×6,卷积核3,池化层大小为1×1,数据在经过卷积池化全连接计算后得到处理后的特征信息,并将其展平作为LSTM模型的输入。LSTM模型隐藏层数目和神经元大小影响着模型预测误差,需要经过调试寻优得到最佳的网络结构。
表1展示了不同隐藏层和神经元结构下的预测误差,可以看出第一层隐藏层神经元(128)、第二层隐藏层神经元(64)的LSTM模型结构的预测平均绝对百分比误差τmape最小。
同理,通过设置不同的lightGBM模型参数,搜索预测误差较小的模型参数,最优参数为:树最大深度(max depth)5,学习器的数量(n estimators)100,学习率(learning rate)0.01,树复杂度控制器(num_leaves)为64,booster类型为gbdt,叶子可能具有的最小记录数(Min_date in_leaf)50。lightGBM模型参数较多,从实际调参的结果看,树的最大深度设置对测试数据预测误差影响较大。
表2展示不同树最大深度的测试结果,当树最大深度为5时测试数据的预测误差最小。

表1 不同隐藏层结构预测误差对比Table 1 Comparison of prediction errors among different hidden layer structures

表2 树最大深度和预测误差Table 2 Max depth and the prediction MAPE error
4.2 预测结果分析
为验证CNN-LSTM-lightGBM组合模型在超短期预测误差上的优越性,选择SVM、LSTM、lightGBM 3种单一模型进行对比分析。风电功率变化受季节气候影响较大,其变化过程包括上升期、高峰期、下降期、低谷期4个特征区段,为全面衡量模型在不同季节的预测效果,分别选取春夏秋冬季节典型日上午8:30—12:30(4 h)作为预测对象,并展示不同模型预测效果。表3展示了不同季节典型日预测对象风电功率大小的基本参数。
在完成CNN-LSTM和lightGBM模型参数设置后,将上述各典型日的预测结果按第3节所述的方法进行组合,得到图7所示的CNN-LSTM-lightGBM组合模型的预测曲线。
从图7可以看出,相较于其他3种单一模型,本文模型预测曲线更贴近真实值,具有较高的预测精度,组合模型在风电功率上升、高峰、下降、低谷变化的4个特征区段均具有较好的跟随性,能有效应对风电功率突变和缓和变化的预测任务。
表4展示了典型日各模型的预测误差对比,可以看出,组合模型的4个评价指标误差值均最低,SVM模型的预测误差最大,SVM模型在9月3日(秋)的τmape为9.782%,误差高的主要原因是当天10:00—12:30风电功率急剧上升,SVM模型在预测的时候未能很好地学习到该变化特征,难以应对风电功率突变的预测任务。为进一步说明组合模型的优越性,以2月10日各模型的预测结果为例,相较于SVM、CNN-LSTM、lightGBM单一预测模型,组合模型的τmape分别降低了60.01%、22.62%、15.32%。

表3 典型日风电功率大小基本参数Table 3 Typical daily wind power size parameters
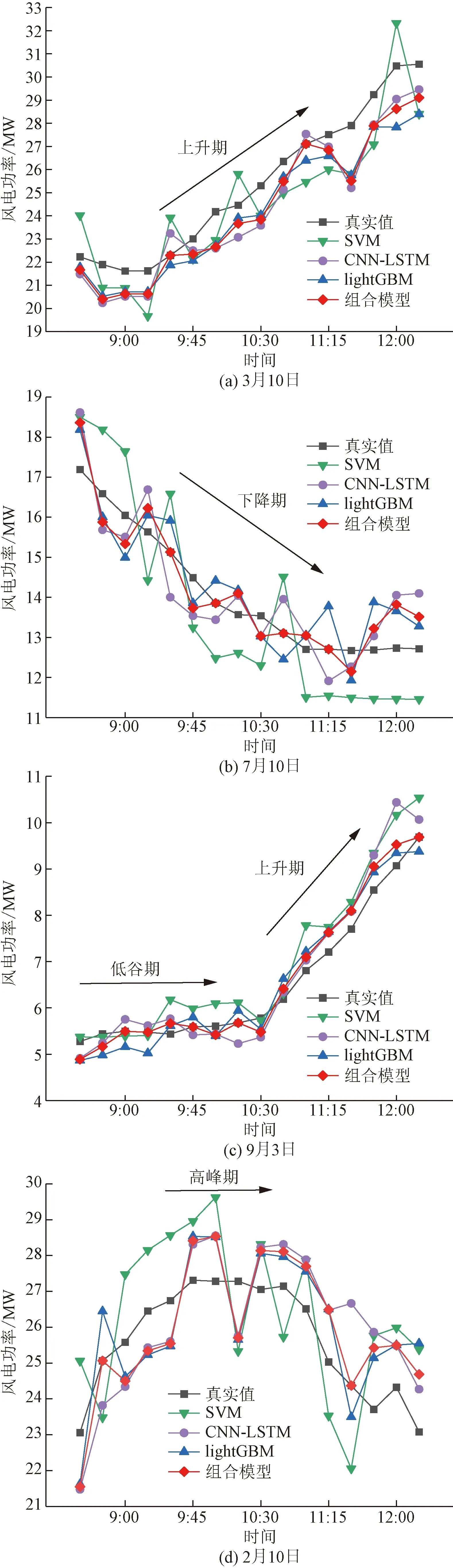
图7 日风电功率预测曲线Fig.7 Daily wind power forecast curve

表4 典型日各模型的预测误差对比Table 4 Comparison of prediction errors of each model on a typical day
5 结论
针对风电功率变化的复杂特性,为提高风电功率预测精度,降低预测误差,建立一种基于数据驱动的短期风电功率预测方法,该方法通过CNN-LSTM-lightGBM模型组合,实现了风电功率超短期预测,并以张北曹碾沟风电场全年实际运行数据验证了模型的有效性,得出如下主要结论。
(1)相较于SVM、CNN-LSTM、lightGBM单一预测模型,组合模型的预测误差最小,具有较高的预测精度。
(2)面对不同风电功率变化特征区段,组合模型均具有较好的跟随性,组合模型具有较强的特征学习能力,能有效应对风电功率突变和缓和变化的预测任务,适用于解决大规模风电数据量且气象数据复杂的风电预测问题。
(3)采用误差倒数法构建了CNN-LSTM-lightGBM的组合模型,组合模型通过发挥不同模型预测优势,进一步提高了模型的预测精度。
随着风电数据集采样周期变短,风电数据采集量剧增,加大了对模型预测能力的考验,如何高效挖掘气象数值信息特征规律,构建高精度的风电功率预测模型是未来重点研究方向。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·中考版(2020年12期)2021-01-18
中学生数理化·中考版(2020年12期)2021-01-18
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
中学生数理化·中考版(2018年12期)2019-01-31
能源(2018年6期)2018-08-01
能源(2018年6期)2018-08-01
北京航空航天大学学报(2018年1期)2018-04-20
