
融合轻量化网络与注意力机制的果园环境下苹果检测方法
2022-02-06 00:53胡广锐周建国李传林孙丽娟
农业工程学报 2022年19期
胡广锐,周建国,陈 超,李传林,孙丽娟,陈 雨,张 硕,陈 军
融合轻量化网络与注意力机制的果园环境下苹果检测方法
胡广锐,周建国,陈 超,李传林,孙丽娟,陈 雨,张 硕,陈 军※
(西北农林科技大学机械与电子工程学院,杨凌 712100)
为提高复杂果园环境下苹果检测的综合性能,降低检测模型大小,通过对单阶段检测网络YOLOX-Tiny的拓扑结构进行了优化与改进,提出了一种适用于复杂果园环境下轻量化苹果检测模型(Lightweight Apple Detection YOLOX-Tiny Network,Lad-YXNet)。该模型引入高效通道注意力(Efficient Channel Attention,ECA)和混洗注意力(Shuffle Attention,SA)两种轻量化视觉注意力模块,构建了混洗注意力与双卷积层(Shuffle Attention and Double Convolution Layer,SDCLayer)模块,提高了检测模型对背景与果实特征的提取能力,并通过测试确定Swish与带泄露修正线性单元(Leaky Rectified Linear Unit,Leaky-ReLU)作为主干与特征融合网络的激活函数。通过消融试验探究了Mosaic增强方法对模型训练的有效性,结果表明图像长宽随机扭曲对提高模型综合检测性能贡献较高,但图像随机色域变换由于改变训练集中苹果的颜色,使模型检测综合性能下降。为提高模型检测苹果的可解释性,采用特征可视化技术提取了Lad-YXNet模型的主干、特征融合网络和检测网络的主要特征图,探究了Lad-YXNet模型在复杂自然环境下检测苹果的过程。Lad-YXNet经过训练在测试集下的平均精度为94.88%,分别比SSD、YOLOV4-Tiny、YOLOV5-Lite和YOLOX-Tiny模型提高了3.10个百分点、2.02个百分点、2.00个百分点和0.51个百分点。Lad-YXNet检测一幅图像的时间为10.06 ms,模型大小为16.6 MB,分别比YOLOX-Tiny减少了20.03%与18.23%。该研究为苹果收获机器人在复杂果园环境下准确、快速地检测苹果提供了理论基础。
图像处理;可视化;苹果检测;收获机器人;卷积网络;视觉注意力机制
0 引 言
苹果收获是季节性强、劳动密集型的农业活动。现阶段,鲜食果实采收作业仍为人工采收,效率低,且劳动强度大[1-2]。Verbiest等[3]调查表明每年纺锤形苹果园人工采摘劳动时间为466 h/hm2,约占总人工劳动时间的67%。越来越高的劳动力成本、较低的市场价格和缺乏合格的劳动力给果业经济收益带来了越来越大的压力[4]。苹果收获机器人技术作为提高苹果生产效率与质量、解放果园劳动力的关键要素,对降低劳动成本、缓解果园劳动力短缺具有重要意义[2, 5]。果实检测是苹果收获机器人实现自动化采收的重要步骤之一,精度高、速度快、适应性强的检测方法更有利于提高苹果收获机器人的整体性能[6-7]。
视觉传感器作为主要的感知设备被广泛应用在收获机器人系统中[7-8]。国内外众多学者针对果园环境中果实检测问题,运用视觉技术展开研究工作,开发了针对不同水果的检测算法,如柑橘[9]、番茄[10-11]、猕猴桃[12-13]、芒果[14]、苹果[15-18]等。目标果实检测方法根据驱动类型可分为基于目标果实特征驱动的检测方法和基于数据驱动的检测方法[19]。基于特征驱动的检测方法主要依靠人类经验提取RGB图像中目标果实的颜色、几何形状、纹理信息等特征以实现目标果实的检测[8]。Wu等[20]使用 SVM(Support Vector Machine)融合HSV果实颜色和3D几何特征识别果实,试验表明该方法的果实识别精度为80.1%。孙建桐等[11]针对番茄识别不准确的问题,提出了一种融合几何形态学与迭代随机圆的番茄识别方法,识别正确率为85.1%。基于特征驱动的检测方法易于实现且具有较快的检测速度,但收获机器人在园间作业时基于特征的检测方法精度不足,且易受光照变化的影响。
为增强视觉检测方法对环境的适应性,基于数据驱动的深度学习目标检测方法受到越来越多研究者的关注[19,21-24]。其实现的基本步骤:1)获取大量图像,标注目标制作数据集;2)构建卷积网络模型;3)配置模型参数;4)反向传播,训练模型;5)前向推理,测试网络,实现应用[25-26]。卷积神经网络(Convolutional Neural Networks, CNN)在训练阶段从大量图像中自动提取目标果实特征,实现果实检测,具有适应性强、鲁棒性好、精度高等优点[27-28]。以Faster-RCNN[29-30]等为代表的两阶段目标检测方法,检测精度较高,但会消耗大量计算资源,检测时间较长。Gao等[29]基于Faster-RCNN(VGG16)提出了一种适用SNAP(Simple, Narrow, Accessible, Productive)苹果园的多类苹果检测方法,平均精度为87.9%,模型大小为533 MB,检测一幅图像时间为0.241 s。针对果园环境下果实快速检测问题,研究学者基于YOLO系列[12,31]、FCOS[32-33]等单阶段检测模型在保持检测精度的同时,提高了检测速度。赵德安等[34]基于YOLOV3(You Only Look Once Version 3)模型实现了复杂环境下对套袋、未成熟、成熟苹果的检测,平均检测精度为87.71%,检测一幅图像时间为16.69 ms。为进一步提高单阶段检测模型的检测精度,研究人员基于YOLO系列模型引入了卷积块注意模块(Convolutional Block Attention Module,CBAM)、挤压激发模块(Squeeze-and- Excitation block)、非局部块(Non-Local block)等视觉注意力机制[15,35-36]。改进后的模型在检测精度上均有所提升,但模型大小有所增加。收获机器人面向复杂果园等非结构化环境,其检测方法不仅需适应天气与光照的变化、枝叶遮挡、背景复杂等因素的干扰,还受到有限的计算资源与存储资源的限制。上述研究多注重模型精度与速度平衡,对模型大小考虑较少,不利于其部署在资源有限的收获机器人上。
综上,苹果采摘机器人在果园环境下进行苹果检测时,模型应能适应复杂、多变的果园环境,准确、快速地检测目标苹果,且检测模型规模要尽可能小,以方便在嵌入式设备中部署。然而目前苹果检测模型多是不同部分的交叉引用组合,缺少对模型的可解释性与综合性能考虑,因此本研究为提高复杂果园环境下苹果检测性能并降低模型大小,对单阶段检测网络YOLOX-Tiny的拓扑结构进行了优化与改进,引入轻量化视觉注意力模块,并应用特征可视化技术提高模型的可解释性,提出一种适用复杂果园环境下轻量化苹果检测网络Lad-YXNet(Lightweight apple detection YOLOX-Tiny Network),为苹果采摘机器人在果园环境下检测苹果提供参考。
1 材料与方法
1.1 图像获取
本研究获取了“烟富”和“蜜脆”两个品种的苹果图像,拍摄时间为2021年9月苹果收获季节,拍摄地点为中国陕西宝鸡凤翔区雨嘉果业果园(34°35′N 107°23′E)。两种果树的种植模式为纺锤形,种植行距约为3.5 m,株距约为1.2 m,具有相同的水肥管理条件。这两个品种的树冠与果实具有明显的差异,“烟富”苹果树冠较大,枝叶更丰茂,果形适中,“蜜脆”苹果树冠较小,枝叶较少,果形较大。图像使用手机进行拍摄,获取图像的宽高比统一裁剪为1∶1,像素大小为1 024×1 024像素。根据收获机器人视觉传感器安装位置,选择拍照距离为距果树为1~2 m,面向果树直立拍摄,以模拟收获场景。光线变化会对苹果检测结果造成较大影响,阴天或使用照明装置辅助的夜间具有较为稳定的光照条件,降低了苹果检测的难度,但晴天不同时间段的光照条件差异较大,对稳定、快速检测苹果提出了更高的要求。因此本研究在晴朗天气下,拍摄全天的顺光与逆光图像。从采集的图像中选取了1 200张图像制作数据集,其中顺光与逆光图像各600张,如图1所示。数据集中包括枝叶遮挡的果实、果实簇、不同光照强度的果实、运动模糊和高密集的果实。每幅图像中包括一个或多个干扰因素,以验证本研究模型的抗干扰能力。

a. 逆光环境下蜜脆苹果a. Micui apple in backlightb. 顺光环境下蜜脆苹果b. Micui apple in nature lightc. 逆光环境下烟富苹果c. Yanfu apple in backlightd. 顺光环境下烟富苹果d. Yanfu apple in nature light
1.2 图像预处理
本研究提出的苹果检测模型主要服务于苹果收获机器人,苹果收获机器人在采收过程中会根据果实的位置选择可采摘的果实,隔行果树上的果实因距收获机器人较远将不会被采摘,因此标注图像时隔行果树上的苹果将不会被标注。使用LabelImg对苹果图像进行标注,按照PASCAL VOC数据集格式保存图像类别和目标矩形框,生成XML格式的标注文件。选取水果暴露面积的最小外接矩形来标注苹果,以减少背景像素。模型训练集和测试集的样本数比为8∶2。
在线Mosaic增强方法是在训练过程中随机将图像进行增强变换后送入网络进行训练。该方法广泛应用在深度卷积模型训练中,以增强模型的检测精度与泛化性能。在线Mosaic包含的增强方法有:1)随机翻转图像;2)图像随机色域变换;3)图像长宽随机扭曲;4)图像随机组合,在训练集中随机选取4张图像组合成1张图像。在训练苹果数据集中采用在线Mosaic增强方式进行训练。但由于Mosaic增强的图像脱离自然,因此在训练中前280 epoch使用在线Mosaic增强方法,随后关闭Mosaic增强方法。为了验证在线Mosaic增强方法是否对检测结果有影响,本研究在保证训练集数量一致的前提下对Mosaic增强方法进行了消融试验。依次去除在线Mosaic中一种的增强方法,训练YOLOX-Tiny与Lad-YXNet模型,以验证增强方法的效果。通过在线增强的图像如图2所示。

a. 原始的在线Mosaica. Original online Mosaic b. 取消随机图像翻转b. Removing random image flipc. 取消图像随机色域变换c. Removing image random color gamut transformd. 取消图像长宽随机扭曲d. Removing random distortion of image length and widthe. 取消图像随机组合e. Removing random image combinations
1.3 改进模型
YOLO(You Only Look Once)网络是典型的单阶段目标检测模型,该模型根据输入图像的目标特征来预测每个目标的边界框。经典的YOLO网络,如YOLOV3、YOLOV4、YOLOV5,采用基于先验框的方法检测目标。该种网络将输入图像划分为具有3种不同网格尺寸的特征图,每个特征图又具有3个用于预测目标边界框的先验框,预测信息由5部分组成:边界框中心偏离特征图网格点的横纵坐标、边界框的宽高和置信度。
YOLOX是基于YOLOV3-SPP和YOLOV5的改进网络[31]。该网络模型打破了传统YOLO系列基于先验框的检测方式,采用SimOTA(Simplified Optimal Transport Assignment)为不同大小的目标动态匹配正样本的方式,构建了基于无先验框的目标检测网络。网络输出预测结果的总参数如式(1)所示。

式中out为网络输出的预测总参数;,为输入图像的宽与高;F1、F2、F3为3个特征图的下采样倍数;reg为确定目标框位置和大小的参数个数,reg=4;obj为目标框中含有目标的置信度分数的个数,obj=1;cls为目标框预测目标的类别个数;arc为每个特征图的先验框个数,基于先验框的经典YOLO网络中arc=3,YOLOX网络中arc=1。YOLOX输出预测结果的总参数是经典YOLO网络的三分之一,使YOLOX具有更快的检测速度。
YOLOX网络共包含了4个标准网络和两个轻量化网络。轻量化网络结构的YOLOX很好地平衡了检测速度与精度,具有应用在田间收获机器人上的潜力。因此,本研究综合考虑模型大小、检测精度和检测速度,基于轻量化模型对田间复杂环境下苹果目标检测网络进行了改进设计。
YOLOX-Tiny网络拓扑结构主要由主干网络、特征融合网络和预测网络组成。主干网络和特征融合网络借鉴了YOLOV5网络拓扑结构,采用CSPDarknet作为骨干网络提取图像特征;使用PANet(Path Aggregation Network)对输入特征进一步融合,输出3个不同尺寸(80×80、40×40和20×20)的特征图,特征图通道数依次为96,192,384。预测网络采用3个解耦头对输入特征图进行预测,每个解耦头输出一个6通道(1类别分数+1置信度分数+4个预测框参数)张量,整合3个不同尺寸特征图后,最终输出8 400×6的预测信息。
苹果检测网络需要在保证检测速度和精度的前提下尽量减少模型参数,以便模型移植到嵌入式设备中。改进的Lad-YXNet的结构如图3所示。主干网络主要是提取目标特征。苹果的浅层特征主要是颜色、大小、纹理等,因此将原CSPDarknet主干的Focus结构改进为Stem结构。Stem结构中使用两个分支,一个分支采用6×6的卷积核扩大卷积的感受野,1×1和3×3的卷积核调整通道数增加网络非线性;另一个分支加入最大池化操作,有利于提取苹果的浅层特征,然后将两个分支在通道维度上进行融合。随着主干网络的加深,提取图像的抽象特征,但深层网络结构参数增多,不利于提高模型的检测速度与降低模型大小。因此,Lad-YXNet的主干网络中仅使用3次CSPLayer,且每层CSPLayer中残差单元(Residual Unit)仅重复一次,从而降低网络整体参数与深度。在主干网络的尾部引入了快速空间金字塔池化(Spatial Pyramid Pooling Fast,SPPF)模块[37]。SPPF结构继承了空间金字塔池化(Spatial Pyramid Pooling,SPP)的优点,通过SPPF模块实现了局部特征和全局特征融合,丰富了特征图的表达能力,有利于检测图像中不同大小目标,且具有更快计算速度。

注:CBS为卷积、BN层和Swish激活函数的组合;ECA为高效通道注意力;SA为混洗注意力;SPPF为快速空间金字塔池化;CBL为卷积、BN层和Leaky-ReLU激活函数的组合。
考虑到苹果特征与图像背景(天空、地面、树干、枝叶)的不同,加入视觉注意力机制让网络更好地提取苹果特征。本研究提出的Lad-YXNet模型在主干网络中第一个CSPLayer前引入高效通道注意力(Efficient Channel Attention,ECA)模块[38],第三个CSPLayer后引入混洗注意力(Shuffle Attention,SA)模块[39]。ECA是一种轻量化通道注意力模块,其结构如图4a所示。
ECA模块将输入特征通过平均池化操作得到通道维度的统计值。通道的统计值经过一层自适应卷积和Sigmod函数操作后与原通道相乘,以增强贡献多的通道,弱化贡献少的通道。其中自适应卷积核大小的计算方法如式(2)所示。

式中ksize为自适应卷积核的大小;Cin为输入特征的通道数;| |odd表示取最接近的奇数。
SA是一种轻量化通道与空间注意力模块,其结构如图4b所示。注意力函数如式(3)所示。

式中in为函数输入;为注意力函数的权重,维度为1×in×1×1;bias为注意力函数的偏置,维度为1×in×1×1;in为in的通道数。
本研究应用SA模块将输入特征进行分组计算,从而降低整体计算量。每组分割成两个分支,每个分支的通道数降为原通道的十六分之一。一个分支通过平均池化与注意力函数得到通道统计值,通道统计值与原通道相乘后得到通道注意力特征;另一个分支通过组正则化与注意力函数得到空间统计值,空间统计值与原通道相乘后得到空间注意力特征;将两个分支的结果在通道维度上进行拼接,再聚合所有组的特征,最后采用通道混洗操作实现不同组间的信息流通,增强卷积网络的特征提取能力。
浅层网络感受野较小,提取的细节特征丰富,但提取抽象特征能力弱,去噪能力差。随着网络的加深能更好地提取图像的抽象特征,但会降低图像的分辨率,导致图像细节特征越来越模糊。为了解决这个问题,借鉴路径聚合网络(Pyramid Attention Networks,PANet)和特征金字塔网络(Feature Pyramid Networks,FPN)结构构建特征融合模块,融合来自浅层、中间层和深层的信息,构建了CSPLayer-2和SDCLayer(Shuffle attention and double convolution layer)模块对PANet和PFN进行轻量化改进,其结构如图3所示。CSPLayer-2将输入特征分为两部分,并通过短接操作增加了输入特征的复用。SDCLayer包含一个SA模块和两个1×1的卷积,以增加特征融合模块的非线性。SA模块使卷积网络更关注待检测目标的特征,1×1卷积等效于跨通道池化操作,跨通道操作可以增强网络学习图像复杂特征的能力。CSPLayer-2和SDCLayer改善了特征融合流程,有助于加强特征提取能力,并提高模型的检测速度。
激活函数的选择对提高卷积网络模型的准确性与速度至关重要。激活函数如ReLU(Rectified Linear Unit)、Leaky-ReLU(Leaky Rectified Linear Unit)、Swish和Hard-Swish等已广泛使用在各种目标检测模型中。Leaky-ReLU激活函数是在ReLU的基础上引入修正项,使得输出负值的信息不会全部丢失,缓解了深度神经网络梯度为0的现象。Leaky-ReLU激活函数的表达式如式(4)所示。

式中l为修正参数,取l=0.01。
相关研究表明使用Swish函数代替ReLU、Leaky-ReLU等激活函数将显著提高卷积网络的性能,但Swish函数存在次幂运算增加了计算成本,其表达式如式(5)所示。

式中s为修正系数,取s=1。
为平衡网络性能与检测速度,主干网络中使用Swish激活函数以保证主干网络具有良好的特征提取性能,特征融合网络中使用Leaky-ReLU激活函数以提高网络检测速度。
1.4 模型训练
试验硬件平台为Dell工作站,处理器型号为英特尔Xeon E5-1620,内存32GB,显卡型号为Nvidia GeForce RTX 2080Ti。操作系统为Ubuntu18.04,深度学习框架采用Pytorch1.2,Python3.6。
本研究在网络训练中采用自适应动量估计法更新参数,输入图像为640×640像素,权重衰减设为5×10-4,动量因子设为0.937,学习率衰减采用预热训练与余弦退火组合的方式,更新公式如式(6)所示。

式中t为训练总轮数,取t=400;warm为预热训练总轮数,取warm=3;cos为使用余弦退火方法训练总轮数,取cos=385;cur为当前训练轮数,每完成一个周期的训练自增1;t为当前训练轮数的学习率;max为学习率最大值,取max=2.5×10-4;min为学习率最小值,取min=2.5×10-6;为预热训练衰减率,取=0.1。
为了评价Lad-YXNet的准确性、鲁棒性和稳定性,在相同的数据集下训练了其他四种目标检测网络,包括SSD,YOLOV4-Tiny,YOLOV5-Lite,YOLOX-Tiny。
1.5 评价参数
本研究通过平均精度AP、1值、召回率、精度和检测速度对模型检测效果进行评估,计算公式如式(7)~(10)所示。检测速度为模型检测单张图像需要消耗的时间。



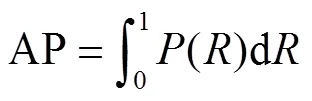
式中P表示模型正确检测苹果的数量,P表示模型将背景检测成苹果的数量,N表示模型未检测出苹果的数量,AP表示以召回率为横坐标,精度为纵坐标绘制的-曲线与坐标轴间的面积,能综合反映模型性能。
2 结果与分析
2.1 模型训练结果与分析
训练过程中,Lad-YXNet与YOLOX-Tiny模型在训练集与验证集上的损失曲线如图5所示。

图5 Lad-YXNet与YOLOX-Tiny模型训练损失曲线
由损失曲线可知,两种模型的损失值均能快速收敛,Lad-YXNet的在训练集与测试集上的收敛速度更快,且在测试集上的损失较低。这表明Lad-YXNet比YOLOX-Tiny模型具有更强的学习苹果特征的能力。训练完成后,Lad-YXNet与YOLOX-Tiny模型的-曲线如图6所示,Lad-YXNet的-曲线与坐标轴间的面积比YOLOX-Tiny模型更大,表明Lad-YXNet较YOLOX-Tiny具有更好的综合性能。

图6 Lad-YXNet与YOLOX-Tiny模型P-R曲线
本研究在相同的数据集下训练了SSD、YOLOV4-Tiny、YOLOV5-Lite、YOLOX-Tiny和Lad-YXNet模型。在测试模型检测时间时,SSD模型输入图像为512×512像素,其余模型输入图像均采用640×640像素,结果如表1所示。

表1 5种模型苹果检测性能对比
注:P表示模型正确检测苹果的数量,P表示模型将背景检测成苹果的数量,N表示模型未检测出苹果的数量。
Note:Pis the number of apples correctly detected by the model.Pis the number of apples that model background errors.Nis the number of apples missed by the model.
由表1可知,Lad-YXNet的平均精度AP、1值和召回率均高于其他模型。Lad-YXNet的平均精度AP、1值和召回率较SSD、YOLOV4-Tiny、YOLOV5-Lite和YOLOX-Tiny模型均有提升,其中平均精度AP分别提高了3.10个百分点、2.02个百分点、2.00个百分点和0.51个百分点。SSD模型的检测精度最高,为93.45%,但模型漏检苹果个数最高,约为Lad-YXNet的2倍,且模型大小为95 MB,不利于部署到嵌入式设备中;YOLOV4-Tiny模型检测一张图像的时间最短,为6.87 ms,但检测精度最低,为89.62%,将背景误检测成苹果的个数最高,较Lad-YXNet多117。Lad-YXNet检测一幅图像的时间为10.06 ms,较YOLOX-Tiny提高了20.03%,Lad-YXNet模型大小为16.6 MB,较YOLOX-Tiny减少了18.23%。这表明Lad-YXNet很好地平衡了模型大小、检测精度和检测速度,为部署在嵌入式设备中提供了基础。
5种模型在两种光照环境下(逆光与顺光)对两种苹果(烟富与蜜脆)的检测结果如图7所示。由图7可知SSD模型在逆光和顺光环境下漏检苹果数(模型未检测出目标苹果的个数)最多,表明在面对密集的检测目标和光照变化的环境,SSD模型易产生漏检情况。YOLOV4-Tiny模型对密集目标检测能力有所提升,但不易检测出被枝叶严重遮挡的小目标。YOLOX-Tiny模型在逆光环境下漏检苹果数为7,误检苹果数(模型将背景错误检测成苹果)为1,在顺光环境下漏检苹果数少于YOLOV5-Lite,相较于SSD、YOLOV4-Tiny模型能很好地适应不同光照条件,同时能检测出相互遮挡的果实与被枝叶遮挡的果实。Lad-YXNet模型继承了YOLOX-Tiny的优点并减少了漏检与误检,在逆光和顺光环境下漏检苹果数分别为4与1,进一步提升了苹果的检测性能。
本研究根据光照环境将测试集图像分为逆光图像与顺光图像,其中逆光图像114张,苹果数为1 578;顺光图像126张,苹果数为3 948。根据果实品种分为“烟富”与“蜜脆”,其中“烟富”72张,苹果数为1 546;“蜜脆”168张,苹果数为3 980。顺光图像中“富士”约占38.10%,逆光图像中“富士”约占21.05%。Lad-YXNet模型在两种光照环境下(逆光与顺光)对两种苹果(烟富与蜜脆)的检测结果如表2所示。

注:蓝色框为5种模型的检测框,黄色方框与圆框分别为手动标注的漏检框与误检框。

表2 Lad-YXNet模型在不同图像上的检测结果
由表2可知,“蜜脆”的1值较“烟富”高2.33个百分点。“烟富”苹果树冠较大,枝叶更丰茂,果实受遮挡严重,导致“烟富”更不易被检测。在逆光环境的1值较顺光环境高1.64个百分点,这与“富士”在顺光图像占比较高有关。
2.2 不同激活函数的试验结果与分析
激活函数是增加卷积网络非线性能力的重要组成部分,本研究选择3种激活函数(Swish,Hard-Swish,Leaky-ReLU)探究主干和特征融合网络采用不同激活函数时对苹果检测模型性能的影响,试验结果如表3所示。
由表3可知,不同激活函数的组合方式对检测模型的检测精度与速度均有较大的影响。与Swish激活函数相比,当主干网络采用Leaky-ReLU激活函数时,检测模型的平均精度偏低;而当Leaky-ReLU作为特征融合网络的激活函数时,检测模型都具有较高的平均检测精度。当主干采用Swish激活函数,检测模型的1值均高于Hard-Swish激活函数,特征融合网络采用Leaky-ReLU激活函数具有最高的平均检测精度为94.88%和最高的1值为90.40%。与Leaky-ReLU相比,主干或特征融合层采用Hard-Swish激活函数时虽能将检测精度提升至92.38%,但会明显降低模型检测速度与召回率,当主干和特征融合都采用Hard-Swish激活函数时,模型的检测时间最长,为12.51 ms。由此可见,本研究所提出的苹果检测模型Lad-YXNet主干采用Swish激活函数,特征融合网络采用Leaky-ReLU激活函数,检测模型具有较好综合性能与检测速度。

表3 不同激活函数的苹果检测模型性能对比
2.3 在线增强方法的消融试验结果与分析
YOLOX-Tiny与Lad-YXNet模型在相同的数据集和不同在线增强方法上进行训练,在测试集上检测结果如图8所示。
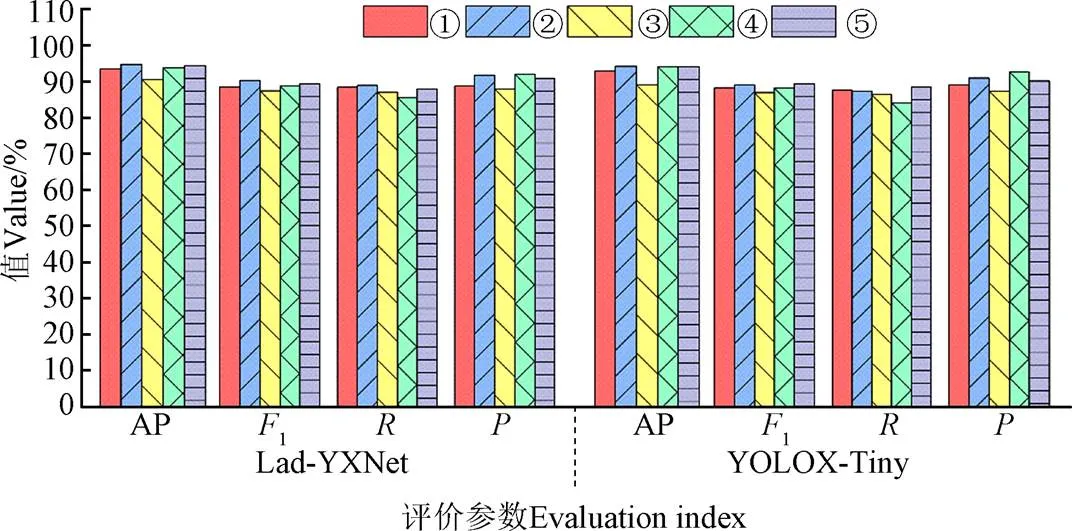
注:①取消图像随机翻转;②取消图像随机色域变换;③取消图像长宽随机扭曲;④取消图像随机组合;⑤原始的在线Mosaic增强处理。
由图8可知,与完整的在线Mosaic增强方法相比,去除图像随机翻转与图像长宽随机扭曲后,Lad-YXNet模型的平均检测精度AP分别下降了0.89个百分点与3.81个百分点;1值分别下降了0.91个百分点和1.95个百分点;精度分别下降2.21个百分点和2.99个百分点。YOLOX-Tiny模型具有类似的规律性,其中去除图像长宽随机扭曲对两种模型的综合性能影响较大,表明了图像长宽随机扭曲对提高模型综合检测性能贡献较高。与在线Mosaic增强方法相比,去除随机图像组合后Lad-YXNet与YOLOX-Tiny模型的检测精度虽有提升,但平均精度AP分别下降了0.56个百分点和0.07个百分点,1值分别下降了0.68个百分点和1.15个百分点,召回率分别下降了2.35个百分点和4.49个百分点,表明训练过程中使用随机图像组合有助于提升模型泛化能力;去除图像随机色域变换后Lad-YXNet与YOLOX-Tiny模型的平均精度AP分别增加了0.38个百分点与0.10个百分点;精度分别增加了0.85个百分点与0.84个百分点,表明在线Mosaic增强方法中的图像随机色域变换不利于两个模型的训练。颜色是苹果的主要特征之一,图像随机色域变换会改变图像中苹果的颜色,模型不易提取苹果的颜色特征,导致两个的模型的综合检测性能下降。因此,在训练苹果检测模型时,去除图像随机色域变换有利于提取苹果的颜色特征。
2.4 视觉注意力机制分析
为进一步探究视觉注意力机制在卷积网络中的有效性,本研究进行了去除Lad-YXNet中两种视觉注意力模块和交换Lad-YXNet中两种视觉注意力模块位置的试验。试验结果如表4所示。

表4 不同视觉注意力模块的苹果检测模型对比
由表4可知,与Lad-YXNet模型相比,交换了两种注意力机制位置的模型精度仅提高了0.04个百分点,而、1、AP分别降低了0.78个百分点、0.39个百分点和0.13个百分点。不使用注意力模块的模型比Lad-YXNet的、、1、AP值分别降低了1.15个百分点、0.64个百分点、0.89个百分点和0.46个百分点。当交换两种注意力模块的位置时,模型的综合性能指标下降,表明Lad-YXNet模型中两种注意力模块的位置设计合理。当不使用注意力模块时,模型的检测时间降低为9.41 ms,但检测精度与综合性能均有不同程度的下降,其中检测精度降低最为明显。与不使用注意力模块相比,仅使用SA模块与仅使用ECA模块的、、1、AP值均有所提升,其中仅使用ECA模块的1与AP值分别提高了0.75个百分点与0.24个百分点,表明引入SA与ECA两种注意力模块增强了Lad-YXNet提取苹果特征的能力,有利于提升模型的综合检测精度。
2.5 模型的可解释性与特征可视化
目前,CNN检测物体的过程缺乏相应的解释,对卷积网络学习的物体特征的理解有限,这阻碍了模型结构的进一步优化。有研究者采用特征可视化技术来提高模型的可解释性,即将不同卷积层输出的特征转换为可视化图像,通过可视化图像展现出不同卷积层提取的特征[21,40]。本研究采用特征图可视化技术提取了Lad-YXNet的主干、特征融合网络和检测网络的特征图,探究Lad-YXNet检测苹果的过程。将主干网络与特征融合网络3个尺寸(80×80、40×40和20×20)的输出特征映射为相同尺寸(640×640)的伪彩图,并与原图像进行叠加,即得到输出特征的可视化图像,其可视化示例如图9所示。

注:颜色越红表示卷积层的输出值越大,下同。
由图9可知,主干网络80×80的浅层特征图提取细粒度强,提取到杂乱的背景信息。随着网络的加深,主干网络40×40的特征图中的特征逐渐变得模糊和抽象。由主干网络20×20的特征图可知,深层网络更注重提取果实所在的图像区域。主干提取的特征送入特征融合网络将图像特征进一步融合,以增强模型的特征提取性能。特征融合网络的特征图如图9所示。经过特征融合网络,80×80和40×40的特征图中分别突出显示了苹果背景区域与苹果所在区域。由特征融合网络20×20的特征图可知,随着特征融合的加强,提取的特征包括平滑的背景信息与果实抽象特征,这有助于在检测阶段过滤背景信息,突显目标果实。
检测网络输出的特征图可视化如图10所示。由图10可知,大量背景信息已被去除,并在特征图中显现出苹果形态。由此可见,Lad-YXNet模型的主干网络提取果实与背景的颜色与纹理等特征,并确定果实和背景所在区域;随着网络深度的增加与特征的融合,进一步提取果实的抽象特征并平滑背景信息;最终在检测网络中融合所有特征信息,去除背景信息并显现苹果形态。本研究从特征提取的角度,展现了Lad-YXNet在复杂自然环境下检测苹果所提取的特征,解释了卷积网络检测果实的过程。
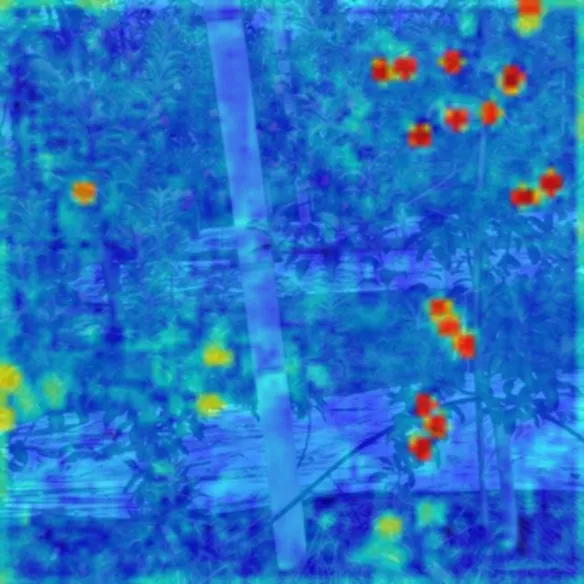
图10 Lad-YXNet的检测网络特征图可视化示例
3 结 论
本研究为提高复杂果园环境下苹果检测性能、速度并降低模型大小,引入ECA(Efficient Channel Attention)和SA(Shuffle Attention)两种轻量化视觉注意力模块,提出一种适用复杂果园环境下轻量化苹果检测网络Lad-YXNet(Lightweight apple detection YOLOX-Tiny Network),较好地平衡了苹果检测模型的检测速度、精度和模型大小。本研究主要结论如下:
1)Lad-YXNet的平均精度AP为94.88%,与SSD、YOLOV4-Tiny、YOLOV5-Lite和YOLOX-Tiny模型相比,分别提高了3.10个百分点、2.02个百分点、2.00个百分点和0.51个百分点。Lad-YXNet检测一幅图像的时间为10.06 ms,较YOLOX-Tiny减少了20.03%,Lad-YXNet模型大小为16.6 MB,较YOLOX-Tiny减少了18.23%,为部署在嵌入式设备中提供了基础。
2)为探究在线Mosaic增强方法对模型训练的有效性,本研究设计了消融试验。消融试验结果表明,图像长宽随机扭曲对提高模型综合检测性能贡献较高,图像随机色域变换由于改变训练集中苹果的颜色,使模型检测综合性能下降。因此使用在线Mosaic增强方法时,去除图像随机色域变换更有利于模型的训练。
[1] 王丹丹,宋怀波,何东健. 苹果采摘机器人视觉系统研究进展[J]. 农业工程学报,2017,33(10):59-69.
Wang Dandan, Song Huaibo, He Dongjian. Research advance on vision system of apple picking robot[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2017, 33(10): 59-69. (in Chinese with English abstract)
[2] 苑进. 选择性收获机器人技术研究进展与分析[J]. 农业机械学报,2020,51(9):1-17.
Yuan Jin. Research progress analysis of robotics selective harvesting technologies[J]. Transactions of the Chinese Society for Agricultural Machinery, 2020, 51(9): 1-17. (in Chinese with English abstract)
[3] Verbiest R, Ruysen K, Vanwalleghem T, et al. Automation and robotics in the cultivation of pome fruit: Where do we stand today?[J]. Journal of Field Robotics, 2020, 38(4): 513-531.
[4] Wang Z, Xun Y, Wang Y, et al. Review of smart robots for fruit and vegetable picking in agriculture[J]. International Journal of Agricultural and Biological Engineering, 2022, 15(1): 33-54.
[5] 杨睿,王应宽,王宝济. 基于Web of Science文献计量学和知识图谱的农业机器人进展与趋势[J]. 农业工程学报,2021,38(1):53-62.
Yang Rui, Wang Yingkuan, Wang Baoji. Progress and trend of agricultural robots based on WoS bibliometrics and knowledge graph[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 38(1): 53-62. (in Chinese with English abstract)
[6] Montoya-Cavero L-E, Díaz De León Torres R, Gómez-Espinosa A, et al. Vision systems for harvesting robots: Produce detection and localization[J]. Computers and Electronics in Agriculture, 2022, 192: 106562.
[7] 郑太雄,江明哲,冯明驰. 基于视觉的采摘机器人目标识别与定位方法研究综述[J]. 仪器仪表学报,2021,42(9):28-51.
Zheng Taixiong, Jiang Mingzhe, Feng Mingchi. Vision based target recognition and location for picking robot: A review[J]. Chinese Journal of Scientific Instrument, 2021, 42(9): 28-51. (in Chinese with English abstract)
[8] Fu L, Gao F, Wu J, et al. Application of consumer RGB-D cameras for fruit detection and localization in field: A critical review[J]. Computers and Electronics in Agriculture, 2020, 177: 105687.
[9] 吕石磊,卢思华,李震,等. 基于改进YOLOv3-LITE轻量级神经网络的柑橘识别方法[J]. 农业工程学报,2019,35(17):205-214.
Lü Shilei, Lu Sihua, Li Zhen, et al. Orange recognition method using improved YOLOv3-LITE lightweight neural network[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2019, 35(17): 205-214. (in Chinese with English abstract)
[10] 龙洁花,赵春江,林森,等. 改进Mask R-CNN的温室环境下不同成熟度番茄果实分割方法[J]. 农业工程学报,2021,37(18):100-108.
Long Jiehua, Zhao Chunjiang, Lin Sen, et al. Segmentation method of the tomato fruits with different maturities under greenhouse environment based on improved Mask R-CNN[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 37(18): 100-108. (in Chinese with English abstract)
[11] 孙建桐,孙意凡,赵然,等. 基于几何形态学与迭代随机圆的番茄识别方法[J]. 农业机械学报,2019,50(S1):22-26,61.
Sun Jiantong, Sun Yifan, Zhao Ran, et al. Tomato recognition method based on iterative random circle and geometric morphology[J]. Transactions of the Chinese Society for Agricultural Machinery, 2019, 50(S1): 22-26, 61. (in Chinese with English abstract)
[12] Fu L, Feng Y, Wu J, et al. Fast and accurate detection of kiwifruit in orchard using improved YOLOv3-tiny model[J]. Precision Agriculture, 2021, 22(3): 754-776.
[13] 傅隆生,冯亚利,Elkamil T,等. 基于卷积神经网络的田间多簇猕猴桃图像识别方法[J]. 农业工程学报,2018,34(2):205-211.
Fu Longsheng, Feng Yali, Elkamil T, et al. Image recognition method of multi-cluster kiwifruit in field based on convolutional neural networks[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2018, 34(2): 205-211. (in Chinese with English abstract)
[14] Zheng C, Chen P, Pang J, et al. A mango picking vision algorithm on instance segmentation and key point detection from RGB images in an open orchard[J]. Biosystems Engineering, 2021, 206: 32-54.
[15] Lu S, Chen W, Zhang X, et al. Canopy-attention- YOLOv4-based immature/mature apple fruit detection on dense-foliage tree architectures for early crop load estimation[J]. Computers and Electronics in Agriculture, 2022, 193: 106696.
[16] 刘天真,滕桂法,苑迎春,等. 基于改进YOLO v3的自然场景下冬枣果实识别方法[J]. 农业机械学报,2021,52(5):17-25.
Liu Tianzhen, Teng Guifa, Yuan Yingchun, et al. Winter jujube fruit recognition method based on improved YOLO v3 under natural scene[J]. Transactions of the Chinese Society for Agricultural Machinery, 2021, 52(5): 17-25. (in Chinese with English abstract)
[17] Kang H, Chen C. Fast implementation of real-time fruit detection in apple orchards using deep learning [J]. Computers and Electronics in Agriculture, 2020, 168: 105108.
[18] Jiang M, Song L, Wang Y, et al. Fusion of the YOLOv4 network model and visual attention mechanism to detect low-quality young apples in a complex environment[J]. Precision Agriculture, 2022, 23(2): 559-577.
[19] Wang X, Tang J, Whitty M. Data-centric analysis of on-tree fruit detection: Experiments with deep learning[J]. Computers and Electronics in Agriculture, 2022, 194: 106748.
[20] Wu G, Li B, Zhu Q, et al. Using color and 3D geometry features to segment fruit point cloud and improve fruit recognition accuracy[J]. Computers and Electronics in Agriculture, 2020, 174: 105475.
[21] Bai Y, Guo Y, Zhang Q, et al. Multi-network fusion algorithm with transfer learning for green cucumber segmentation and recognition under complex natural environment[J]. Computers and Electronics in Agriculture, 2022, 194: 106789.
[22] Wang Z, Jin L, Wang S, et al. Apple stem/calyx real-time recognition using YOLO-v5 algorithm for fruit automatic loading system[J]. Postharvest Biology and Technology, 2022, 185: 111808.
[23] Wang D, He D. Channel pruned YOLO V5s-based deep learning approach for rapid and accurate apple fruitlet detection before fruit thinning[J]. Biosystems Engineering, 2021, 210: 271-281.
[24] Roy A M, Bose R, Bhaduri J. A fast accurate fine-grain object detection model based on YOLOv4 deep neural network[J]. Neural Computing and Applications, 2022, 34(5): 3895-3921.
[25] 张政馗,庞为光,谢文静,等. 面向实时应用的深度学习研究综述[J]. 软件学报,2020,31(9):2654-2677.
Zhang Zhengkui, Pang Weiguang, Xie Wenjing, et al. Deep learning for real-time applications: A survey[J]. Journal of Software, 2020, 31(9): 2654-2677. (in Chinese with English abstract)
[26] 葛道辉,李洪升,张亮,等. 轻量级神经网络架构综述[J]. 软件学报,2020,31(9):2627-2653.
Ge Daohui, Li Hongsheng, Zhang Liang, et al. Survey of lightweight neural network[J]. Journal of Software, 2020, 31(9): 2627-2653. (in Chinese with English abstract)
[27] Tian H, Wang T, Liu Y, et al. Computer vision technology in agricultural automation: A review[J]. Information Processing in Agriculture, 2020, 7(1): 1-19.
[28] Tang Y, Chen M, Wang C, et al. Recognition and localization methods for vision-based fruit picking robots: A Review[J]. Frontiers in Plant Science, 2020, 11(510): 1-17.
[29] Gao F, Fu L, Zhang X, et al. Multi-class fruit-on-plant detection for apple in SNAP system using Faster R-CNN[J]. Computers and Electronics in Agriculture, 2020, 176: 105634.
[30] 闫建伟,赵源,张乐伟,等. 改进Faster-RCNN自然环境下识别刺梨果实[J]. 农业工程学报,2019,35(18):143-150.
Yan Jianwei, Zhao Yuan, Zhang Lewei, et al. Recognition of Rosa roxbunghii in natural environment based on improved Faster RCNN[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2019, 35(18): 143-150. (in Chinese with English abstract)
[31] Ge Z, Liu S, Wang F, et al. YOLOX: Exceeding YOLO series in 2021[C]//Kuala Lumpur: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
[32] Tian Z, Shen C, Chen H, et al. Fully convolutional one-stage object detection[C]//Seoul: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019: 9626-9635.
[33] 龙燕,李南南,高研,等. 基于改进FCOS网络的自然环境下苹果检测[J]. 农业工程学报,2021,37(12):307-313.
Long Yan, Li Nannan, Gao Yan, et al. Apple fruit detection under natural condition using improved FCOS network[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 37(12): 307-313. (in Chinese with English abstract)
[34] 赵德安,吴任迪,刘晓洋,等. 基于YOLO深度卷积神经网络的复杂背景下机器人采摘苹果定位[J]. 农业工程学报,2019,35(3):164-173.
Zhao Dean, Wu Rendi, Liu Xiaoyang, et al. Apple positioning based on YOLO deep convolutional neural network for picking robot in complex background[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2019, 35(3): 164-173. (in Chinese with English abstract)
[35] Yan B, Fan P, Lei X, et al. A Real-time apple targets detection method for picking robot based on improved YOLOv5[J]. Remote Sensing, 2021, 13(9): 1619.
[36] 宋怀波,江梅,王云飞,等. 融合卷积神经网络与视觉注意机制的苹果幼果高效检测方法[J]. 农业工程学报,2021,37(9):297-303.
Song Huaibo, Jiang Mei, Wang Yunfei, et al. Efficient detection method for young apples based on the fusion of convolutional neural network and visual attention mechanism[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 37(9): 297-303. (in Chinese with English abstract)
[37] Jocher G. YOLOV5[EB/OL]. (2020-06-26) [2022-03-10]. https://github.com/ultralytics/yolov5.
[38] Wang Q, Wu B, Zhu P, et al. ECA-Net: Efficient channel attention for deep convolutional neural networks[C]// Seattle: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
[39] Zhang Q, Yang Y. SA-Net: Shuffle attention for deep convolutional neural networks[C]// Toronto: Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021: 2235-2239.
[40] Selvaraju R R, Cogswell M, Das A, et al. Grad-CAM: Visual explanations from deep networks via gradient-based localization[C]//Venice: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
Fusion of the lightweight network and visual attention mechanism to detect apples in orchard environment
Hu Guangrui, Zhou Jianguo, Chen Chao, Li Chuanlin, Sun Lijuan, Chen Yu, Zhang Shuo, Chen Jun※
(,,712100)
Apple harvesting is a highly seasonal and labor-intensive activity in modern agriculture. Fortunately, a harvesting robot is of great significance to improve the productivity and quality of apples, further alleviating the labor shortage in orchards. Among them, the detection model of the harvesting robot is also required to accurately and rapidly detect the target apples in the complex and changing orchard environment. It is a high demand for the small size to be deployed in the embedded device. This study aims to improve the speed and comprehensive performance of apple detection in a complex orchard environment. A Lightweight apple detection YOLOX-Tiny Network (Lad-YXNet) model was proposed to reduce the size of the original model. Some images of “Yanfu” and “Micui” apples were obtained during the apple harvest season in 2021. The images were uniformly clipped to the 1024×1024 pixels. As such, 1 200 images were selected to make the dataset, including the fruits with shaded branches and leaves, fruit clusters, varying degrees of illumination, blurred motion, and high density. This model was then used to optimize the topology of the single-stage detection network YOLOX-Tiny. Two lightweight visual attention modules were added to the model, including Efficient Channel Attention (ECA), and Shuffle Attention (SA). The Shuffle attention and double convolution layer (SDCLayer) was constructed to extract the background and fruit features. Swish and Leaky Rectified Linear Unit (Leaky-ReLU) was identified as the activation functions for the backbone and feature fusion network. A series of ablation experiments were carried out to evaluate the effectiveness of Mosaic enhancement in the model training. The average precision of the Lad-YXNet model decreased by 0.89 percent and 3.81 percent, respectively, after removing random image flipping and random image length width distortion. The1-socre also decreased by 0.91 percent and 1.95 percent, respectively, where the precision decreased by 2.21 percent and 2.99 percent, respectively. There was a similar regularity of the YOLOX-Tiny model. After removing the image random combination, the average precision of the Lad-YXNet and the YOLOX-Tiny model decreased by 0.56 percent and 0.07 percent, the1-socre decreased by 0.68 percent and 1.15 percent, as well as the recall rate decreased by 2.35 percent and 4.49 percent, respectively. The results showed that the random distortion of image length and width greatly contributed to the performance of model detection. But the random color gamut transformation of the image decreased the performance of model detection, due to the change of apple color in the training set. Two specific tests were conducted to explore the effectiveness of visual attention mechanisms in convolution networks. Specifically, one was to remove the visual attention modules from the Lad-YXNet, and another was to exchange the position of visual attention modules from the Lad-YXNet. Compared with the Lad-YXNet, the precision of the improved model to exchange the position of the visual attention modules only increased by 0.04 percent, while the recall,1-socre, and average precision decreased by 0.78 percent, 0.39 percent, and 0.13 percent, respectively. The precision, recall,1-socre, and average precision of the models without the attention module were reduced by 1.15 percent, 0.64 percent, 0.89 percent, and 0.46 percent, respectively, compared with the Lad-YXNet. Consequently, the SA and ECA enhanced the ability of the Lad-YXNet to extract the apple features, in order to improve the comprehensive detection accuracy of the model. The main feature maps of Lad-YXNet's backbone, feature fusion, and detection network were extracted by the feature visualization technology. A systematic investigation was made to determine the process of detecting apples with the Lad-YXNet in the complex natural environment, particularly from the point of feature extraction. As such, improved interpretability was achieved in the apple detection with the Lad-YXNet model. The Lad-YXNet was trained to be an average accuracy of 94.88% in the test set, which was 3.10 percent, 2.02 percent, 2.00 percent, and 0.51 percent higher than SSD, YOLOV4-Tiny, YOLOV5-Lite, and YOLOX-Tiny models, respectively. The detection time of an image was achieved in 10.06 ms with a model size of 16.6 MB, which was 20.03% and 18.23% less than YOLOX-Tiny, respectively. Therefore, the Lad-YXNet was well balanced with the size, precision, and speed of the apple detection model. The finding can provide a theoretical basis to accurately and quickly detect the apples for the harvesting robot in the complex orchard environment.
image processing; visualization; apple detection; harvesting robot; convolutional network; visual attention mechanism
10.11975/j.issn.1002-6819.2022.19.015
TP691.4
A
1002-6819(2022)-19-0131-12
胡广锐,周建国,陈超,等. 融合轻量化网络与注意力机制的果园环境下苹果检测方法[J]. 农业工程学报,2022,38(19):131-142.doi:10.11975/j.issn.1002-6819.2022.19.015 http://www.tcsae.org
Hu Guangrui, Zhou Jianguo, Chen Chao, et al.Fusion of the lightweight network and visual attention mechanism to detect apples in orchard environment[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2022, 38(19): 131-142. (in Chinese with English abstract) doi:10.11975/j.issn.1002-6819.2022.19.015 http://www.tcsae.org
2022-06-01
2022-09-29
国家自然科学基金项目(No. 32272001);国家重点研发计划项目(No. 2018YFD0701102);国家自然科学基金项目(No. 32001428)
胡广锐,博士生,研究方向为智能化果园装备。Email:2017050952@nwsuaf.edu.cn
陈军,博士,教授,博士生导师,研究方向为智能化农业装备。Email:chenjun_jdxy@nwsuaf.edu.cn
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
一重技术(2021年5期)2022-01-18
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
中学生数理化·八年级物理人教版(2019年9期)2019-11-25
电子制作(2019年11期)2019-07-04
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
电子制作(2018年11期)2018-08-04
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
