
开放获取下的过刊本体构建与应用*
2022-02-06 05:22:10刘雪琪
新世纪图书馆 2022年12期
刘雪琪
0 引言
科学的交流往往与当下信息传播速度趋于一致,在科研成本上升及信息传播自由需求的双重冲击下,开放获取运动在全球范围内快速开展[1]。公共图书馆为实现向公众提供无限制且免费信息的美好愿望,关键点之一是如何匹配读者需求,并通过调取关联信息实现精细化服务。报刊借阅是图书馆公共服务的重要组成内容,但部分图书馆过刊资源碎片化严重,借阅查询与个性化推荐存在欠缺。因此,如何集成过刊异构原数据,打破信息孤岛,构建合理标准的概念集合,交由计算机自动识别处理,成为图书馆员值得深思的问题[2]。本体构建是知识组织的一种表现形式,能够广泛聚集和深度融合领域知识元,并清晰表达概念间的关联[3]。但国内现有过刊本体数据集多偏重信息储存,查询与个性匹配推荐逐渐无法满足公共图书馆提供知识服务的需求。
南京图书馆过刊馆藏量大、资源丰富,但过刊储藏信息条目较少,不能全面概括过刊实体属性,信息关联度较低。因此,本文依托南京图书馆实际过刊工作需求,建造兼具完整性与合理性的过刊本体数据库,以提高过刊资源完备性、加深信息层次性,为信息关联检索及面向读者的个性化书目推荐等业务提供数据支持。通过复用期刊部分成熟本体概念,加以过刊特有的知识单元构建概念集合,以OWL语言为基础,使用SWRL语言进行层次化逻辑关联,调用SPARQL链接查询端口,实现过刊数据的开放获取。
1 关于本体研究现状
知识本体是明确领域内概念、并用规范化表述概念之间关系的知识组织方法[4],可以用于对知识进行系统化梳理与分析共享。机器学习与自然语言处理、自动信息发布,以及智慧图书馆等较为成熟的研究方向,均是知识本体已有的丰硕研究成果。本体概念的提出可以追溯至哲学领域,其构建原则大多遵循由T.R.Gruber提出的清晰性、一致性、可扩展性、编码偏好程度最小和本体约定最小[5]。
本体的构建由抽象、具体等不同维度扩展出骨架法、七步法、METHONTOLOGY法、TOVE法等不同方法。目前,最为成熟且被大众广泛使用的方法是七步法,首先考察是否存在构建完整可使用的本体,其次从概念类别着手,由上至下依次建造类的属性,并填充相关属性。骨架法、TOVE法等方法多用于企业领域本体,通过流程导向建立知识逻辑模型与框架[6]。
现有研究较为成熟的本体大多以OWL、RDF、XML等Web语言为基础。其中,OWL(Web Ontology Language)网络本体语言能够与其他语言兼容工作,是W3C推荐的满足RDF标准语法的本体语言。RDF(Resource Description Definition)采用主谓宾三种形式进行概念关系描述,能够涵盖其资源、属性和陈述,这种方式称之为三元组(S,P,O)[7]。XML(Extensive Markup Language)是高度形式化的语言,以文档类型分类表达高度自描述性[8],其通过使用DTD(Document Type Definition)自定义标签编写规则,如是否区分大小写、是否嵌套顺序等,可以创造贴近文档实体的标签。
近些年,国内外知识组织的研究成果日益丰硕,尤其是在开放获取活动的影响下,形成了大量实体丰富的本体模型。CIDOC CRM是国际通用的模型,较多用于文化遗产的本体构建,其基础框架牢固且全面,便于使用者根据研究需求对知识概念进行修改与扩展。中国历史人物传记数据库为CBDB知识库,其以唐至明代的重要历史人物为核心,大量记载了基本信息、社会存续、著作等属性信息与关联数据,通过连接API接口,可以向用户提供单机数据和资料库信息查询,帮助用户采用人口社会网络探索历史问题。
期刊及过刊的本体构建在国内外被日益关注,现有BIBO、Nature Ontologies等成熟词表于国内外通用。JSTOR始于美仑基金会的数字典藏计划,其以订购期刊的图书馆数量、期刊影响指数等条件筛选期刊,仅收录过去3~5年的过刊完整内容[9]。Nature实体模型以实用为目的,类目有效性高,但核心类数量少,其通过核心、领域、实例三层数据架构实现大规模数据的关联与交互。The ISSN Portal为ISSN国际中心建立的大规模出版数据库,已有200多万实体,其包含ISSN、标题、出版社等期刊连续出版物信息,并支持MARC21、RDF等格式下载。国内在期刊方面的本体构建有期刊库、期刊规范等研究成果。相关机构通过建立国家图书馆名称数据库等期刊规范库,对名称等类别统一规整。《中国期刊全文数据库(CJFD)》积累了论文800余万篇,拥有9大类别共计126个专题文献数据库,是目前最大的持续更新的中文期刊数据库[10]。中国医学信息研究所明确了期刊规范中“资源描述与检索”和“数据统计与分析”两类核心需求,通过建立期刊规范文档,实现了期刊名称内外部资源整合。中国农科院农业信息研究所基于OWL和SKOS建立了类目详实、关系充分的期刊本体,并通过Jena等语义中间件实现实例格式转换等。
综上所述,国内外对于本体研究有相当成熟的经验与成果,但期刊领域的知识库建设和本体框架模型缺乏翔实性与统一性,尤其是对于过刊的研究更是少之又少,且未能形成与计算机处理相匹配的形式化描述。因此,在国内外期刊标准库的构建的基础上,过刊本体语义模型的建立能在一定程度上提升图书馆的知识组织与服务能力。
2 本体构建思路与语料来源
南京图书馆作为我国第三大图书馆,馆藏资源丰富,每年处理过刊约2.5万册。现阶段,南京图书馆过刊数据储存与ALEPH编目系统相挂接,其录入的信息为过刊的主要特征属性,包括条码、价格、年份、合订期数等,南京图书馆官方网站与官方微信小程序查询系统仅可查看属性内容,暂不能转接与本属性相关联的其他信息或推荐刊物。基于以上思考,以过刊为研究对象,本着能够全面详实描述过刊资源的目标,将多元异构数据进行整合,并从南京图书馆实际需求出发,构建适用于现行公共图书馆过刊数据管理且信息关联的知识本体,用于信息存储与查询调用。
本研究使用七步法构建本体,以国际标准为主要依据,参考Nature本体构建原理,复用已有的部分本体,结合南京图书馆内过刊数据存储与查询需求,构建清晰的、一致的过刊本体,并在本体约定、偏好程度最小的同时保证其可扩展。将ALEPH系统中已有的数据导出XML文件,格式转换成Excel后可批量导入protégé本体构建工具,填充部分本体内容。对于编目系统外空缺的某些属性,通过程序爬取知网期刊信息后,编写正则表达式对部分对应概念信息进行匹配。如,使用d{4}-d{4}可直接提取ISSN信息。构建完成后,选用当下广泛认可与应用的本体建模工具Protégé软件进行实现,并利用SWRL规则、HermiT推理机推理运算、OntoGraf工具可视化表达,实现OWL本体自动化,为公共图书馆过刊模型与数据库开放共享提供支撑。
2.1 类的构建
过刊本体核心类别及其下属类别的设定,在一定程度上框定了本体结构与层次。本文选用混合法来进行本体构建,先确定重要类别,再向上与向下细化相结合逐步确定最终类别。经研究实验发现,罗婷婷、李娇等学者以OWL+SKOS为基础构建的期刊本体中部分类别同样适用于过刊数据库,但不能完全表述过刊属性。因此,保留上述期刊本体中的论文(Article)、机构(Organization)及其下属的主办单位(ProcessingUnit)、出版商(Publisher)及主管单位(Sponsor)[11]。除此以外,选取内涵互不相交,且与过刊相关性最强、最重要的概念作为核心类别。依托南京图书馆过刊管理工作需求及应用经验,经过统计研究与实验后,确定过刊本体的六个核心类别,并且其均属于互斥关系,不具有交叉性,分别是过刊(Back Issue)、机构(Organization)、刊物水平(Quality of publication)、单册状态(Status of periodical)、语种(Language)、论文(Article)。对每个核心概念进行内容细化与层层细分,以完善整个概念模型。其中,过刊(Back Issue)下的类别设置参照《中国图书馆分类法》,每个过刊实例都可以根据编目信息和学科属性从A~Z类找到相对应的类别并填入。单册状态(Status of periodical)由南京图书馆现有书册状态中期刊常用的四种状态组成,分别为未到(Not received)、期刊外借本(Journal loan)、典藏(Collection)、阅览本(Reading book)。刊物水平(Quality of publication)和语种(language)中不下设分类,填入固定个体。刊物水平(Quality of publication)包含从SCI、CSSCI到省级期刊不同的等级。语种(Language)有中文(Chinese)、港台(Traditional Chinese)、英文(English)等,包含了南京图书馆几乎全部期刊语种。论文(Article)下未设置细分类别,其主要收录某些受读者欢迎、学术性强、影响较大的单篇论文。对每个类别,分别根据其特有属性用等价于(Equivalent To)、不相交(Disjoint With)等约束关系对类别进行限定。
2.2 数据属性构建
数据属性是赋予类别的特定的内在属性,对一个类别设置数据属性,此类别中的所有个体便自动拥有此种属性。通过筛选与统计分析,选用读者最关注的过刊信息定义为数据属性。过刊(Back Issue)类别设置了8个数据属性,分别为CN,ISSN,出版年(Publication Year),合订期数(Number of binding periods),影响因子(ImpactFactor),价格(Price),索书号(Call number),条码号(Barcode)。其中,ISSN、出版年(Publication Year)、影响因子(Impact Factor)复用已有的期刊本体,其他数据属性基于过刊固有特点和南京图书馆读者服务日常工作经验积累进行自定义。
过刊除具有ISSN、出版单位等等同现刊的属性外,也有合订期数此类的独有实体概念[12],因此在对过刊本体构建中,也描述过刊所合订的杂志期数,即合订期数(Number of binding periods),价格(Price)由合订本所含有的期刊单价、合订费用(10元)相加所得,主要用于读者丢书后的价格赔偿参考。索书号(Call number)由南京图书馆编目部门负责撰写,用于过刊上架及查找。用于描述论文(Article)核心类目的数据属性则涵盖了文章的大致属性,共有4个,分别为作者(Author)、项目、课题(Project,subject)、单位(Company)和项目编号(Project number)。
2.3 关系属性构建
关系属性用来描述类别个体和类别个体之间联系,在过刊本体中设置合理详细的关系属性,可以建立不同类别实例间的联系。本次研究本体里,在部分复用现有成果中适用于过刊本体的关系属性的基础上,结合过刊基本特性和类别对剩余关系进行自定义,共设置7个关系属性,并通过逆属性、函数属性等属性特点对其进行约束,有被收录(Has hold)、被出版(Has Publisher)、主办单位(Has Hosted)等。被收录(Has hold)是指影响力较大、需要被单独列举的论文被收录在相对应的过刊个体中。剩余6个关系属性定义域均为过刊(Back Issue),值域为与关系相对应的类别,含义为某个过刊个体被出版/被主办等等。7个关系属性能最大限度且全面地描述过刊与其他类别中的个体一一对应的存在,以建立本体中不同种类个体之间的关系网络,使整个期刊本体数据库更加完整。过刊本体模型关系属性设置如表1所示。
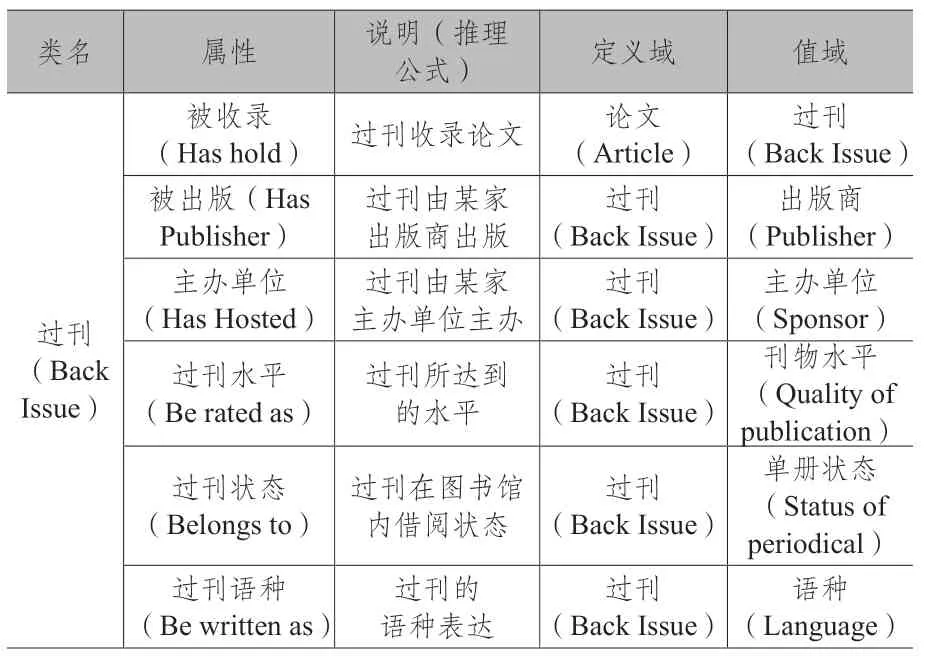
表1 过刊本体模型关系属性设置
2.4 推理关系构建
在本体语义模型中,仅靠人工信息输入无法形成完备的过刊知识网络,应在关系属性的基础上,根据逻辑建立规则,利用计算机自动推理过刊与论文实例间的联络,加深知识层次、理清知识脉络。在OWL语言的基础上所延伸出来的SWRL语言进行规则的符号化表述,调用protégé中HermiT 1.8.3.413本体推理机可以根据SWRL语言定义的规则进行逻辑推理运算,并将推理出的结果自动保存并更新本体库。已知某篇论文被发表在该过刊中的某本期刊中Has hold(?x1,?x2)和过刊个体发表水平Be rated as(?x1,?x2),那么可以推出该篇论文的发表水平Be_rated_as2(?x1,?x3)。同样,若已知某本过刊由某个语种编写,现有一篇论文被发表在该本期刊上,则可以推出该篇论文由哪个语种编写。过刊本体模型推理关系属性设置如表2所示。

表2 过刊本体模型推理关系设置
3 过刊本体可视化创建及应用
在过刊本体类及属性定义完成后,按照protégé要 求 的形 式输 入,在Class、Date Properies、Object properties等栏目下添加相应内容并做好关系衔接。通过图形与线相结合的方式可以直观感受过刊本体的类别层次与概念关联,有利于实例关系网络的清晰化。Protégé中所带有的OntoGraf功能可以创建视图,将本体层次及概念间的关系进行直观的图形化显示。其中,方框所代表的是类别,实线代表类的种属关系,虚线代表已经定义好的关系属性。OntoGraf可视化展示如图1所示。因篇幅限制,此处不对过刊(Back Issue)等大类下的子类展开展示。当输入实例后,通过OntoGraf可将信息网络展开可视化,可清晰明了地观察实例的信息关联。
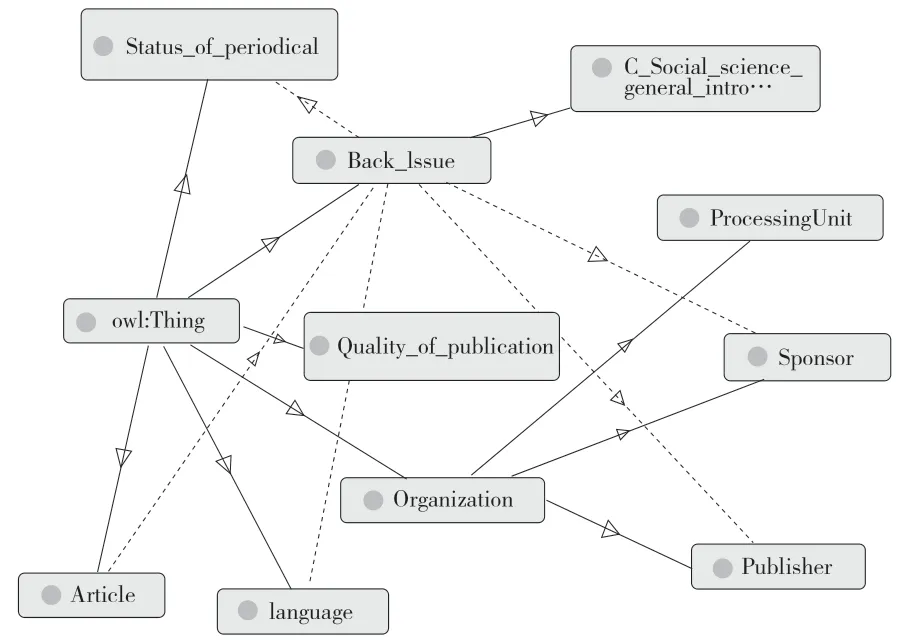
图1 OntoGraf可视化展示
在类和属性的约束下,给过刊本体添加相符合的实例,可以将图书馆过刊资源与数据库相关联,实现存储、查询操作简洁和扁平化。《图书情报工作》是图书情报界较有影响力的期刊之一,南京图书馆现有馆藏《图书情报工作》过刊合订本多册。以其2019年第7~9期作为个体实例,将特定属性与关系输入已构建完成的数据库,相关页面如图2。在Property assertions中可以直观了解《图书情报工作》个体的关系属性及数据属性。
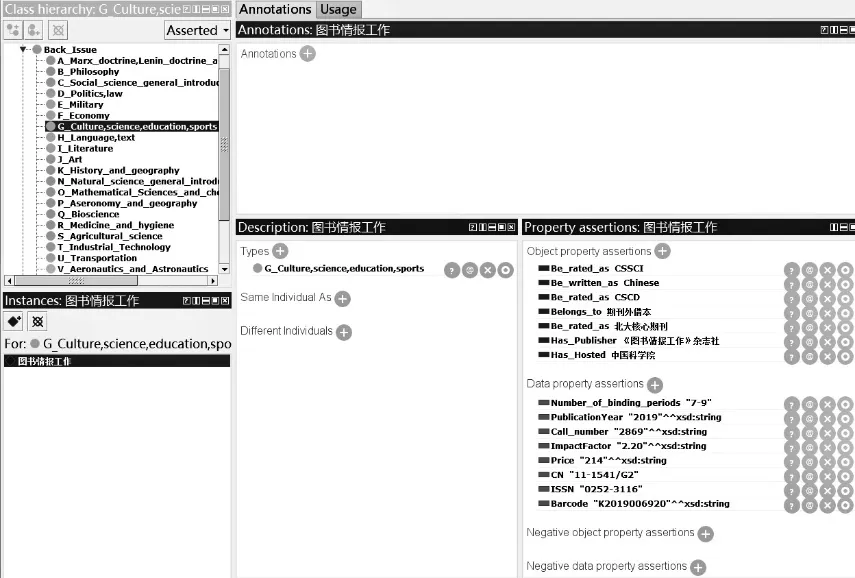
图2 过刊实例添加展示
该本过刊中,由李杨独著的《公共图书馆服务供给政社合作关系研究》描述了政府与社会组织建立合作关系对公共图书馆体制改革的积极影响[13]。现将本篇论文作为本体个体,列入论文(Article)类,并将其关系属性及数据属性补充完整,其内容如图3所示。在Property assertions下灰色部分属性为本体推理机自动推理过后所产生的关系。由于该篇文章收录于该本《图书情报工作》中,因此,本过刊实例所设定的论文水平、语种等关系属性通过推理机转接到文章本身,自动成为该篇论文的关系属性并储存。
通过设置查询终端接口、编写SPARQL查询语言,可以查找本体内容,为读者或第三方系统提供指定的过刊中个体信息属性及关联信息查询服务,并为阅读个性化推荐提供支持。其查找形式灵活多变,根据具体读者要求敲定具体需求、编写SPARQL查询语言,不仅可以以过滤条件为约束查找个体实例,还可以查询某个实例的数据属性与关系网络。例如,使用SPARQL语言“Select ?x where {eg:实例名称 eg:属性名称 ?x .}"可以查询某个过刊或论文实例的某个属性。
4 结语
本文搜集整理了国内外本体构建和期刊数据库建设的情况与数据信息,并以期刊本体为基础,结合南京图书馆过刊管理工作的需求,基于OWL语言建立了较为详实、层次分明的过刊本体语义模型,实现了逻辑推理与可视化展示,并支持SPARAL语言查询,为公共图书馆过刊本体构建提供了思路与参考。本文研究中不足之处是缺少本体质量测评体系的判别、实例查询方式较为简单等。
在未来的本体完善工作中,应探寻更多完备性与合理性的表达。在实例创建转换方面,因其数据体量大,可尝试批量转换RDF三元组,为实例创建可访问与解析的唯一标识符。在实体填充方面,可采用命名实体识别等方法,通过文本标注训练BERT等机器模型[14],使用训练好的机器对未识别的过刊属性数据与关系进行提取,使用数据对过刊本体进行实体填充。
猜你喜欢
新世纪图书馆(2016年12期)2017-01-05 09:27:52
科技视界(2016年1期)2016-03-30 19:53:03
国家图书馆学刊(2016年6期)2016-03-18 14:13:27
时代金融(2015年9期)2015-04-13 02:03:27
高中生学习·高三版(2014年3期)2014-04-29 06:11:18
高中生学习·高三版(2014年3期)2014-04-29 06:10:49
中国蔬菜(2013年8期)2013-09-08 08:45:38
中国蔬菜(2012年2期)2012-08-07 09:43:38
中国蔬菜(2012年10期)2012-02-23 06:17:42
中国蔬菜(2011年20期)2011-08-07 09:43:04
