
工业机器人预测式健康管理本体半自动化构建*
2022-01-27 09:50柳少峰黄子豪姜文超贺忠堂
组合机床与自动化加工技术 2022年1期
柳少峰,肖 红,黄子豪,姜文超,,熊 梦,贺忠堂
(1.广东工业大学计算机学院,广州 510006;2.中国科学院云计算产业技术创新与育成中心,东莞 523808)
0 引言
随着工业机器人的普及,企业内部积累了许多工业机器人PHM相关案例记录和知识信息,资源丰富,但缺乏深度利用。如何提取和重用这些案例和知识,并应用于工业机器人后续故障预测、故障诊断以及日常健康管理,困难程度较高,构建工业机器人PHM 本体成为一种可行的解决方案。本体被定义为客观现实的一个本质抽象,是对客观事物的形式化、规范化描述[1]。
传统领域本体构建方法是领域专家和研究人员参与的人工构建方法[2]。刘鑫[3]结合故障树分析法,采用手动构建本体方式,构建了故障诊断领域本体。然而,这种人工构建方法不够智能、成本高,易受主观影响,构建的本体不完备。因此,自动化构建本体正在逐渐取代人工构建方式。目前,国内外学者关于自动化构建本体的研究主要针对概念抽取和关系抽取。郑姝雅等[4]使用主题模型(LDA)完成用户生成内容领域的概念抽取,验证了LDA算法的有效性。唐琳等[5]认为领域学术论文关键词是领域中的核心概念,因此采用词频筛选出核心概念。在概念关系抽取方面,郑姝雅等[4]构建出概念完全图,使用基于最小生成树改进的层次聚类算法来处理概念间的层次关系。SATHIYA等[6]提出CBC(clustering by committee)聚类算法,获得了准确率较好的层次关系抽取。
然而,上述方法对于构建工业机器人PHM本体并不十分适用,一些概念抽取算法在不同领域有不同适用性,通用概念抽取算法对该领域概念抽取效果并不好;其次,已有非层次关系抽取方法只能判断出哪两个概念具有非层次关系,而无法得出具体关系标签[7],此外在处理非层次关系时倾向于先处理同义关系,这会导致被合并同义词所附带的其他语义关系消失。针对以上问题,本文提出一种工业机器人PHM半自动化构建的方法,本方法已成功应用于某型号国产机器人日常健康管理,实际应用效果证明本方法的有效性与可行性。
1 工业机器人PHM本体半自动化构建
工业机器人PHM本体半自动化构建框架如图1所示,主要包括:数据获取及预处理、概念抽取、概念关系抽取、本体形成四个阶段。其中概念抽取以及概念关系抽取采用自动获取方式,数据获取及预处理、本体形成需要人工参与,具体步骤如下:

图1 工业机器人PHM本体半自动化构建框架图
步骤1:获取工业机器人PHM语料,对语料进行筛选、分词、去除停用词等预处理获得候选概念集;
步骤2:利用本文提出的概念抽取算法从候选概念集中抽取核心概念;
步骤3:基于Dice测度测量概念关联强度,基于CSC语义词库和搜索引擎抽取上下属关系,基于SAO结构抽取交叉关系,基于词典抽取同义关系;
步骤4:将抽取出的概念和概念关系进行整合,使用Protégé工具构建OWL本体,并持久化与可视化。
1.1 数据获取及预处理
本文语料包括企业工业机器人故障维修文档、垂直网站文章、学术文献等。定义若干关键字,根据该关键字检索知识服务平台、博客服务平台,使用爬虫工具爬取相关文献、博客。这些文档合并定义为工业机器人PHM领域相关文档集合A。采用规则过滤和人工过滤方式筛选无关文章文献。筛选后的文档定义为工业机器人PHM领域文档集合A(pro),作为本文实验语料库。
对语料库中的文本进行分词,考虑到该领域对概念准确性的要求,选用Jieba分词工具精确模式进行分词。此外,该领域部分词汇采用词组形式,比如词汇“一相电源”在一般情况下会分成“一相”和“电源”两个词语,为了提高分词准确度,在分词时加载自定义领域词典,词典词汇由搜狗细胞词库中机械专业词库、机械工程词汇表等组成。完成分词后,使用专业中文停用词表将一些领域相关性不强、含义较为广泛的常用词如“得到”、“怎么”等过滤掉,最终得到分词结果,分词后的所有词语定义在候选概念集合W中。
1.2 PHM本体概念抽取
从集合W中确定具有领域代表性的概念是构建本体的关键步骤。一般来说,工业机器人PHM领域核心概念和该领域文档中的关键词非常相似,此外,可以发现工业机器人PHM中词汇之间存在嵌套现象,类似复合词,如“减速机”与“齿轮减速机”存在嵌套关系。因此,筛选核心概念时不仅要考虑词汇词频还要结合该领域中词汇特点,所以本文融合词频、文档频率、TF-IDF算法、C-value算法来提取核心概念。
词频和文档频率(包含该词汇的文档数)两个指标均反映了该词汇在语料库中出现的频率。TF-IDF(term frequency-inverse document frequency)算法可以衡量语料库中一个词汇对所在文档的重要程度,词汇在文档中出现次数越高,该词汇越重要,同时,词汇在语料库其他文档出现的频率越高,该词重要性下降。TF-IDF值计算如式(1)所示。
(1)
式中,f(i|a)表示词语i在a文档中的词频;Y(i)表示i的文档频率;Y表示语料库中文档总数。
C-value算法充分考虑到嵌套词汇影响,若词汇i不是被嵌套词汇,则i的C-value值取决于i的词频值和i的长度。若i被嵌套,则会降低i的C-value值。具体计算如式(2)所示。
(2)
式中,len(i)表示词汇i的长度;f(i)为i的词频;Ti表示嵌套i词汇b的集合。
考虑到工业机器人PHM核心词汇特点,本文提出工业机器人PHM领域概念抽取综合算法领域相关度DR(domain relevance),DR计算如式(3)所示。
DR=β1·log2f(i)+β2·log2Y(i)+
β3·TF-IDF(i)+β4·C-value(i),i∈W
(3)
式中,β1+β2+β3+β4=1,均为4个指标对DR的权重。根据各方法影响程度不同,本文设置权重分别为:β1=0.15,β2=0.15,β3=0.35,β4=0.35。对DR值进行排序,设置阈值得到工业机器人PHM领域概念集合Wkey。
1.3 PHM本体概念关系抽取
概念间关系抽取发现作为本体构建最重要的步骤之一,抽取的三元组(概念,关系,概念)是工业机器人PHM本体的基本组成元素。
工业机器人领域概念间关系纷繁复杂,结合逻辑学[8],将该领域概念间关系分为5种:全同关系、上属关系、下属关系、交叉关系和全异关系。上属关系表示被包含关系,例如,“齿轮减速机是减速机的一种”,可以看出,“齿轮减速机”和“减速机”是上属关系。下属关系表示包含关系,例如“电机转子由铁芯、转子绕组、轴承、转轴等组成”,可以判断出“电机转子”与“铁芯”是 下属关系。交叉关系表示两个概念间有交集,例如“减速机的轴承损坏或者过分磨损”,“轴承”与“损坏”或者“磨损”就是交叉关系。全同关系指两个词概念完全相同。全异关系指两个概念完全没有交集,例如,冷却装置和传动转置属于全异关系。
5种关系具有互斥性,本文对概念间关系的抽取主要集中在抽取概念全同关系、上下属关系以及交叉关系,全异关系抽取不做研究。此外,抽取全同关系和上下属关系时不需要抽取关系名称。交叉关系则相反,需要抽取概念对的关系名称。
综上所述,本文提出该领域概念间关系抽取“三步法”,具体步骤如下:
步骤1:确定概念集合Wkey中哪两个概念具有关系;
步骤2:对有关系的概念对进行上下属关系、交叉关系的识别、抽取,初步构建三元组;
步骤3:识别、抽取全同关系,对有全同关系的概念对的三元组进行合并。
1.3.1 基于Dice测度的关联强度测量
本文定义了工业机器人PHM本体概念间关系R,R的描述如式(4)所示。
R={R(i,j)=
(4)
式中,i和j为一对概念对;CRS(correlation strength)表示概念间的关联强度;α表示概念间关系类型;S为上下属关系倾向性评分,评分越高说明概念对是上下属关系的可能性越大;[rn]表示抽取出来的关系名称列表。CRS越高说明两个概念间存在关系的可能性越大。CRS和概念对共现的次数有一定相关性,因此确定CRS可以使用基于Dice测度的方法。Dice测度通过结合概念的词频以及概念对共现的频次来计算CRS,具体计算如式(5)所示。
(5)
式中,D2(i,j)表示概念i和j的CRS;f(i)为i的词频;f(j)为j的词频;f(i,j)为i和j共同出现的频率。此外,D2(i,j)值和D2(j,i)值是相同的,因此R中R(i,j)和R(j,i)的CRS也是相同的。
本文对于关联强度超过一定阈值min_CRS的概念对认定为具有关系,将min_CRS的值设定为0.003,对于没有关系的概念对移出工业机器人PHM概念间关系集R,对于有关系的概念对使用两种方法识别概念对的上下属关系,式(4)中S打分分别为基于CSC语义词库的上下属关系抽取和基于搜索引擎上下属关系抽取。
1.3.2 基于CSC语义词库的上下属关系抽取
CSC中文语义词库收入超过190 000词条,每个词条包含了丰富语义信息,因此可作为自然语言处理领域的辅助资源。
基于CSC词库抽取上下属关系的流程为:给定概念i和j,在CSC中查找i的同义、近义词集合wi,查找i和集合wi的所有下位词集合wh,查找j的同义、近义词集合wj,如果在wh中能找到j或wj中的一个词,那么说明i是j的上属概念,i和j是上属关系。对于这两个概念,依据这种方法获取的关系对的评分记为S1(i,j)=1。
若i和j不存在上属关系,而存在下属关系,则S1(i,j)=0,但是由上文可知,上属关系和下属关系可以相互转换,如i下属于j能够转换为j上属于i,即S1(j,i)=1,因此为了便于研究,本文对概念对上下属关系的抽取更集中于对上属关系的抽取识别。
1.3.3 基于搜索引擎的上下属关系抽取
受语料库文档数量限制,仅从语料库中提取概念对关系远远不够,部分概念间关系可能无法得到表示,需要结合数据量更大的搜索引擎进行抽取。
搜索查询前需要制定查询三元组,查询三元组由概念对以及语义特征词构成,首先构建表示上下属关系的特征词模板集合,如表1所示,其中,A和B为两个概念,表中A上属于B,其次构建查询三元组,例如(A,“组成”,B)等,查询三元组应保证A和B的上下属关系方向性一致。

表1 上下属关系语言模板
采用查询三元组(概念i,特征词,概念j)在语料库A(pro)和谷歌、百度等搜索引擎中分别进行检索查询,查询时以句子为单位,并且将概念对限制在N个词窗口内,本文N=10。统计查询三元组在语料库A(pro)中出现的次数记为numA(i,j),在搜索引擎中出现的次数记为numW(i,j)。提出通过语料库或搜索引擎中获取概念对关系的评分计算如式(6)所示。
(6)
式中,num(i,j)表示概念对i和j构成的三元组在语料库或者搜索引擎中查询出的次数。计算出在语料库A(pro)中的得分为S2A(i,j),搜索引擎中的得分为S2W(i,j)。
结合两种方法得出式(4)概念对i和j关系R(i,j)中S的具体计算如式(7)所示。
S(i,j)=γ1×S1(i,j)+γ2×S2A(i,j)+γ3×S2W(i,j)
(7)
其中,γ1、γ2、γ3为三种方式评分权重,γ1+γ2+γ3=1,通过实验经验,取γ1=0.4,γ2=0.4,γ3=0.2。当S(i,j)值超过设定阈值时,认定i和j为上属关系。由上文可知,此时i和j不存在下属关系,j不会上属于i,即R(j,i)不存在,R(j,i)移出概念关系集合R。
1.3.4 基于SAO结构的交叉关系抽取
工业机器人PHM本体概念对交叉关系基本上都具有noun-verb-noun结构形式,这种形式与SAO结构(subject-action-object)[9]近似,SAO结构表示为主语、谓语、宾语的关系,而动词常做谓语。比如:“减速机箱体内有杂物”,其中“箱体”与“杂物”就是“有”的关系,因此,对交叉关系抽取集中于对概念间动词抽取。具体算法如下:
(1)提取出PHM语料库中非上下属关系的概念对i和j之间的所有动词,作为i和j间(方向i→j)的备选概念关系集;
(2)循环取出备选概念关系集中的动词v与概念对组成三元组C={i,j,v},用集合E={C1,C2,...,Cn}表示概念对和所有动词的三元组的集合;
(3)从E中循环取出C,计算概念对与动词的正点互信息值PPMI,具体计算如式(8)所示。式中P(·)为以句子为单位的概率;
(8)
(4)对所有的PPMI值进行排序,选取PPMI最大的动词作为i和j的交叉关系。继续提取交叉关系,跳至步骤1,如果全部提取完毕,跳至步骤5;
(5)对于i与j的两个方向关系R(i,j)、R(j,i),这里只保留PPMI值最大的交叉关系,若两个PPMI值均为0,则人工给出概念间具体的交叉关系。
1.3.5 全同关系抽取
因为不同企业之间对于工业机器人PHM概念可能存在二义性情况,不同概念间可能具有全同关系。全同关系的识别采用通用同义词典匹配,使用以哈尔滨工业大学修订的同义词典为主进行同义匹配。对于确定是全同关系的概念对(i,j),需要将概念进行合并,将j所附带的语义关系转移到i中。
1.4 本体形成
前述抽取的关系可能存在错误情况,需要人工检查,剔除错误的三元组。在获取工业机器人PHM概念以及概念关系后,需要将这些概念及其关系进行持久化、可视化,便于工业机器人PHM本体信息管理以及后续知识应用,也有利于用户直观了解该领域的知识信息。当前主流的本体构建工具包括OntoLearn、TextStorm/Clouds、ASIUM、Protégé等[10]。本文应用Protégé工具编辑工业机器人PHM本体,对本体进行持久化与可视化。
2 实验结果与分析
2.1 实验数据
定义“工业机器人预测式健康管理”“工业机器人PHM”“工业机器人故障维修”等关键字,使用这些关键词检索维普期刊平台、简书博客,使用爬虫工具爬取相关信息。企业维修记录和爬取的文档共1690篇。使用规则过滤和人工过滤方式筛掉非该领域的文档。最后为工业机器人PHM文档集作为本文构建本体的语料库,一共1276篇。
2.2 实验结果分析
通过对工业机器人PHM语料预处理后,使用本文概念抽取算法进行实验,对所有词汇DR值进行计算,部分词汇DR值如表2所示。对于DR值超过预设阈值时,将其作为该领域的核心概念,实验最终设定阈值为4.000,共抽取出核心概念243个。
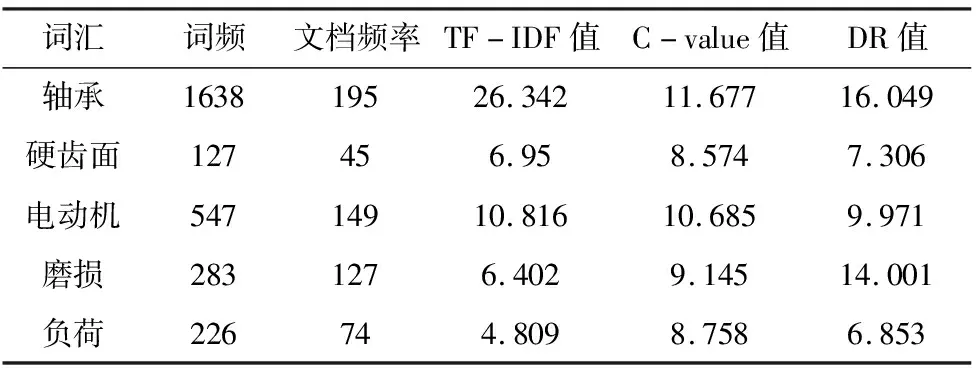
表2 部分词汇DR值
此外,本文基于相同语料库A(pro)展开了多种本体概念抽取主流算法对比实验,分别与TF-IDF算法、C-value算法、LDA主题模型[11]对比,对比数据为使用算法后排序的前K个概念,通过人工方法对抽取的结果进行评估,统计准确率指标,实验结果如图2所示。可以看出,本文概念抽取算法在准确率上有显著提升,比最好的TF-IDF算法平均高出10%。LDA主题模型在短文本数据诸如企业记录上进行概念抽取效果不佳,而单一TF-IDF算法和C-value算法无法结合工业机器人PHM概念特点进行抽取,效果一般。

图2 概念抽取算法对比实验结果
使用基于Dice测度的方法对概念间CRS进行测量,部分概念对关联强度如表3所示。对确定具有关系的概念对,使用基于CSC语义词库和搜索引擎的上下属关系抽取。实验设定式(4)概念间关系集R(i,j)中S的阈值0.400,共挖掘出上下属关系126对,工业机器人PHM本体上下属关系抽取效果如图3所示。本文算法分别与基于Beta分布的聚类算法BRT(Bayesian Rose Tree)和JIANG等[12]提出的方法进行对比,BRT聚类算法准确率为0.61,JIANG等[12]所提方法准确率为0.68,本文方法准确率为0.71。由此可知,本文方法针对工业机器人PHM概念上下属关系抽取有较好效果,准确率优于其他两种方法。

表3 部分概念对关联强度表

图3 工业机器人PHM概念上下属关系
使用基于SAO结构抽取交叉关系,共挖掘交叉关系330对,部分概念间交叉关系如表4所示。针对全同关系,采用同义词典进行同义匹配,并对同义词语义关系转移。得到工业机器人PHM核心概念以及概念对关系后,使用Protégé5.5.0工具构建本体、形成本体。通过Protégé将本体持久化为OWL本体文件,以便后续使用。

表4 部分工业机器人PHM概念间交叉关系提取结果
3 结束语
本文提出了一种工业机器人PHM本体半自动化构建方法。实验结果表明,本文方法在概念抽取和关系抽取两个阶段均获得更高准确率。本方法已成功应用于某型号国产机器人日常健康管理,实际应用效果进一步证明本方法有效可行。
本文在构建工业机器人PHM本体中仍存在一些不足,比如该领域本体概念间交叉关系并不全是由动词来表达的,概念间也可能不存在动词,因此,研究如何更好提取概念间交叉关系,使得构建的本体更加全面,将是下一步的研究重点。
猜你喜欢
计算机与生活(2022年3期)2022-03-13
哈哈画报(2021年10期)2021-02-28
文化创新比较研究(2020年13期)2021-01-14
天津外国语大学学报(2020年1期)2020-03-25
五邑大学学报(自然科学版)(2019年3期)2019-09-06
小型微型计算机系统(2019年6期)2019-06-06
计算机技术与发展(2018年12期)2018-12-20
计算机系统应用(2017年5期)2017-06-07
外语教学理论与实践(2014年4期)2014-06-13
图书与情报(2013年1期)2013-11-16
