
一种基于深度可分离卷积的轻量级人体关键点检测算法
2022-01-23 03:42孔令军刘伟光周耀威裴会增沈馨怡赵子昂
无线电工程 2022年1期
孔令军,刘伟光,周耀威,裴会增,沈馨怡,赵子昂
(1.金陵科技学院 网络与通信工程学院,江苏 南京 211169;2.南京邮电大学 通信与信息工程学院,江苏 南京 210003)
0 引言
计算机超大规模并行计算能力的提升以及各种传感技术的研发,极大地推动了深度学习技术在图像识别[1]、自然语言处理、语音识别等各个领域中的发展。特别地,作为图像识别领域的典型代表,人体关键点检测的重要性日益凸显[2]。
人体关键点检测[3-4]是指基于图像来重建人的关节和肢干,即找出人体骨骼的关键点并将其组合。在计算机视觉[5-6](Computer Vision,CV)领域,人体的关键点(通常是特殊部位或骨骼关节点)定位至今依旧是热门的研究方向。发展到现在,人体关键点检测已经催生了很多应用,在人机交互[7]、病人监护系统[8]、智能视频监控[9-10]、虚拟现实、运动员辅助训练、智能家居[11]、人体动画、智能安防等领域都有着重要的意义和广泛的应用前景,是诸多计算机视觉任务的基础,例如动作分类、异常行为检测以及自动驾驶等[12]。这些研究除了需要较高的精确度外,还对执行速度有要求,进一步催生了对模型精简化的需求。除了使用常见的轻量化网络结构的方式外,为了解决网络对资源消耗过大的问题,本文首先提出在人体关键点检测方向上应用编解码结构(Codec)来减少网络计算量的方法,提出了一种全新的网络架构,称为编解码结构的深度可分离网络(Codec Depth Separable Network,CSDNet)。
1 算法框架设计
经实验验证,属性金字塔模块(Feature Pyramid Module,FPM) 以及多维自学习模块 (Multidimensional Self-Learning Module,MSLM) 能够提升关键点检测的效果,前者主要通过结合特征矩阵的高低级语义特征,后者则通过使得网络具有自学习能力增强其有用信息的表达能力,然而这种网络通过叠加的方式需要大量的计算节点,面临原有的神经网络参数量大、内存占用多、计算缓慢的问题。为了解决这些问题,改进轻量化的卷积网络被提出来,例如深度可分离卷积等;另外一方面,人体关键点检测和像素级切割都是对整张图进行预测[13]。
图1展示了2个学习任务,其中图1(a)、图1(b)分别是人体关键点的原始输入图片以及峰值图,图1(c)、图1(d)是像素级切割的原始输入图片以及预测细胞间质的切割图,这些都是对整张图片进行预测得到整张图的结果,为此,本文尝试在像素切割上寻找适用的轻量级网络方法。

(a) 人体图片
目前,轻量级的像素切割任务是以编解码为主,其中编码结构是以下采样[14]为主,而解码结构则以上采样为主,最终将编解码过程中产生的特征图进行融合来增强模型的表达能力,而FPM正是通过对高低级语义特征进行融合的操作来提升网络的效果。通常的主干结构往往是ResNet[15]、VggNet[16]等网络结构,为了实时推理,本文设计了一种轻量型的主干模型,并且研究了如何在有限的计算量下提升预测效果。在主流的网络结构中使用FPM,以丰富上下文特征,同时也带来了大量的计算;另外,传统的方法通常从单路径中丰富特征映射,高层特征没有与前一层特征相融合,而前一层特征又保留了网络路径中空间细节和语义信息,为了增强模型的学习能力同时增加接受域,特征重用变得极其迫切。本文部署了几种策略实现模型中跨层特征聚合,并且使用了深度可分离卷积以降低模型的计算量。
本文设计的轻量级的网络架构如图2所示。
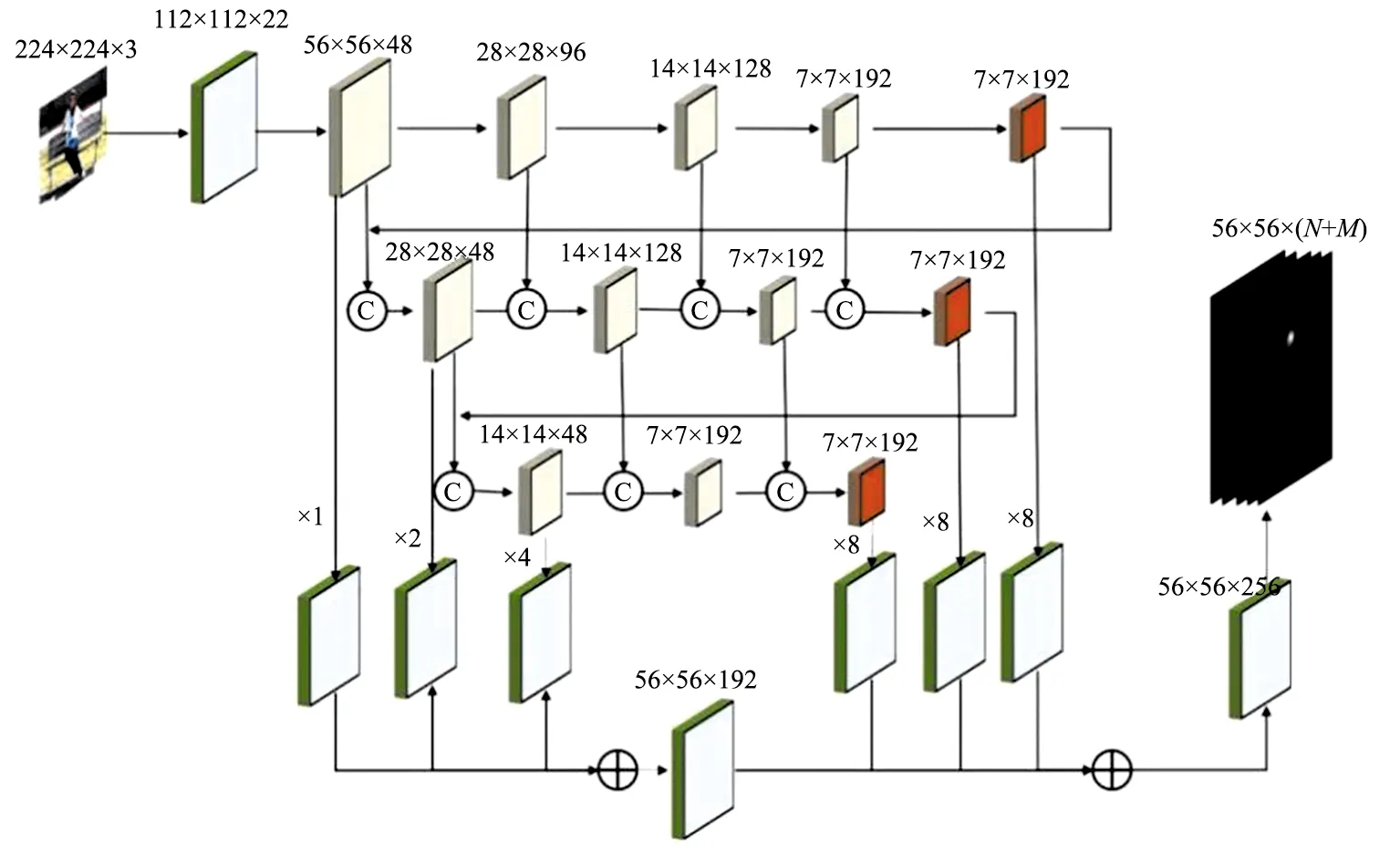
图2 CSDNet网络架构Fig.2 Structure of CSDNet
大小为224 pixle×224 pixle×3 pixle的RGB图片作为网络的输入,然后通过绿色的普通卷积网络进行特征提取得到112×112×22的特征矩阵,接下来使用深度可分离卷积对特征矩阵进行特征提取操作,分别得到了不同分辨率的特征矩阵,结合多维度的自学习模块,本网络在维度为7×7×192的特征图上使用了多维自学习的注意力模块使得网络具有自学习的能力,此时实现了主干结构的特征提取;另外,为了增强模型对不同深度特征的利用率,网络使用了通道合并方式进行了第二层处理以及第三层处理,如图2中的第二排以及第三排,此模块实现了对特征图的编码过程;与此同时,为了增强网络的感受野,还使用了上采样将编码过程中获得的特征图进行解码,解码后通过点加操作来增强网络对高低级语义特征的提取能力。其中N为关键点数+1,M为关键点间关系数量。
1.1 轻量级主干结构
本节介绍网络的主干结构细节,已知深度可分离卷积能够在保证精度损失不大的情况下提升性能,本文主要工作在编解码部分以及注意力机制部分,因此主干结构并不需要太复杂的结构。图3(b)所示为本文设计的轻量级主干结构,其中的蓝色模块为普通卷积,绿色模块为深度可分离卷积,黄色的为多维自学习模块,多维自学习模块应用到主干结构的深层上能够显著提升检测的效果,因此本文在最终的特征图上应用此自学习模块,轻量级主干网络结构如表1所示。
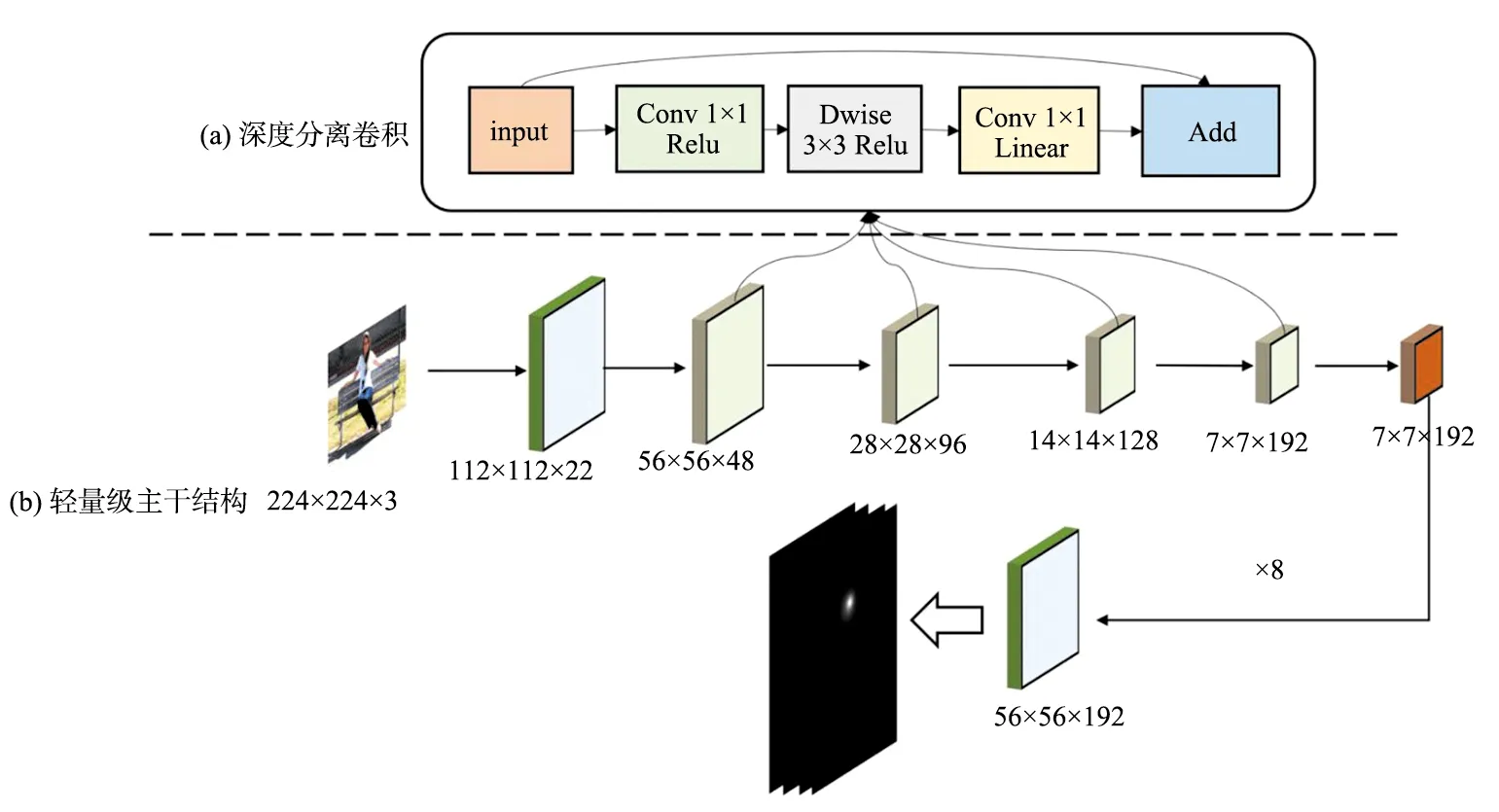
图3 融合深度可分离卷积的轻量级主干结构Fig.3 Lightweight backbone structure fused with depth-separated convolution

表1 轻量级主干网络
由表1可以看出,本文设计的轻量级网络第一层使用的普通卷积为了降低计算量将通道层设计为22,中间使用了深度可分离卷积作为特征提取模块,虽然每个模块还有重复次数设置,但受益于深度可分离卷积的高性能,此过程并没有显著增加计算量。网络使用了多维自学习模块,用通道以及空间为基本单位进行调整特征矩阵中的权重来增强有用信息的表达能力,最终使用上采样以及卷积输出最终的预测热点图,为了证明此模块的高效性以及多维自学习的注意力模块的有效性,本文将在实验部分进行对比。
1.2 编解码结构
金字塔模型是被设计提取不同的高低级语义特征,另外一方面,单独使用金字塔模型会造成信息丢失的问题。为了解决这个问题,本文尝试使用一个类似编解码形式的网络来增强对这些特征的利用率,如图4所示。该结构被广泛应用到各种目标检测或分类等任务中,但这种网络缺点比较明显,网络的层次特征都是分辨率比较低的,如果想使用高分辨率的特征图,特征提取的不全面,继而图5被提出,利用上采样来解决这个问题,使得高分辨率的特征也能够出现在深层特征上,但缺点依旧明显,浅层特征容易被浪费,最终图6被提出来,这是一种能够重用低层特征的结构,类似于编解码形式。

图4 单向的编解码金子塔结构Fig.4 Unidirectional codec pyramid structure
图5 双向的编解码金字塔特征结构Fig.5 Bidirectional codec pyramid feature structure

图6 双向的编解码金字塔特征重用结构Fig.6 Bidirectional codec pyramid feature reuse structure
在本文所设计的编码结构中直接对高低级别的语义特征进行融合,所用的编码器首先从3个模块的底部融合高层特征,其次对高层次特征进行下采样或者上采样来保持融合特征具有相同的空间分辨率,最后将高层次特征与低层次特征相加得到最终的预测,在解码器中仅使用了少量的卷积以及相加操作来尽量避免增加计算量。
本文使用轻量级的结构作为网络主干对图片进行编码,提出的基于特征聚合网络包含3部分:轻量级的主干网络、特征编码聚合网络以及特征解码聚合网络[17]。一方面,深度可分离卷积已经证明了能够极大降低计算量;另一方面,特征编码聚合网络可以看作是一个由粗到精的预测过程;同时,特征解码聚合网络通过聚合“粗”和“细”的部分在相应阶段之间的特征表示,将相同尺寸的层组合在一起传递感受野,在这3个模块之后采用一个卷积以及上采样操作组成轻微译码器,将每一级的输出进行合并,得到“粗”到“细”的预测结果,最终设计的网络架构如图2所示。
2 网络训练
本文提出的基于特征聚合的轻量级网络结构第一次被用于人体关键点检测的主干特征网络中,为了证明其有效性,本文将使用相同的COCO人体关键点检测数据集[18]进行训练,训练过程中使用相同的训练策略以及训练参数。由于本文设计的轻量级的网络结构具有更小的网络参数,因此训练过程中选择了更大的Batch_size来加速训练收敛的时间。
训练过程中使用分辨率为368 pixel×368 pixel的图片作为输入进行训练。训练MSLM模块时,为了解决MSLM模块对网络结构的影响,首先训练了一个不包含MSLM模块的网络,然后将网络中的权重固化后,再将MSLM添加到网络中进行训练,第二次训练仅仅只训练MSLM模块。
3 实验结果与分析
进行对比实验以及分析。首先介绍了该实验的条件,然后与现有的人体关键点检测模型进行了比较,并在COCO测试数据集上进行了精度以及速度分析,测试过程中使用原始图片的分辨率作为网络输入进行测试。
3.1 测试实验参数设置
本文实验使用了Tensorflow深度学习框架、实验中使用到的数据集是MS COCO。训练以及测试过程中使用的硬件设备如表2所示。

表2 硬件平台
训练过程中,显存与内存需要进行大量的数据交换,如果内存容量太低,会出现使用交换空间导致数据处理速度慢,因此需要尽量使内存大于显存容量。
3.2 结果对比与分析
实验指标使用了平均精度(Average Precision,AP)来评比人体关键点检测精度。本文主要从以下几个方面设计实验:
(1) 为了证明轻量级主干结构的高效性,与不同的轻量级主干结构或非轻量级的主干结构进行对比实验;
(2) 为了证明基于编解码对轻量级主干网络的性能提升明显,与不同的网络作为主干结构以及编解码结构(Codec)进行对比实验;
(3) 为了证明MSLM模块的效果,着重对比添加以及不添加此模块的效果;
(4) 在CSDNet网络中进行消融实验。
仅使用本文所设计的轻量级与现有的开源网络进行实验,如表3所示以及表所对应的指标性能图7,其中FPS(每秒帧数)=1 / 平均每张耗时(秒)。
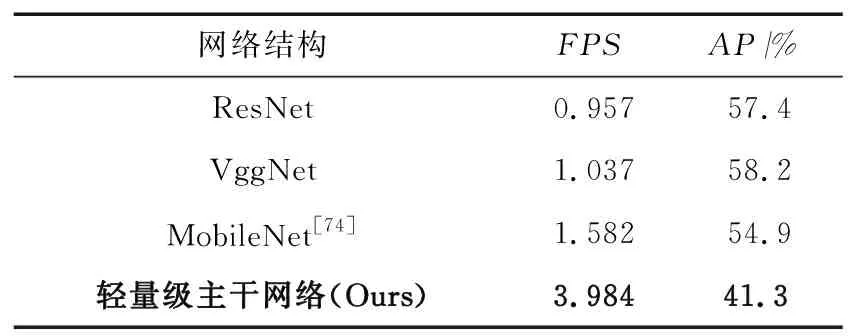
表3 轻量级主干网络与开源网络实验对比
由表3可以得到以下结论:
(1) 对比使用了深度可分离卷积作为卷积基本模块的网络结构MobileNet和轻量级主干网络以及没有使用的网络结构ResNet和VggNet可知,使用CSDNet结构带来了性能上的提升,但精度也有一定的损失;
(2) 将表中AP最好的网络VggNet与MobileNet和轻量级主干网络进行对比,MobileNet性能相比VggNet提升了52%,而AP指标相比下降了5%;轻量级主干网络的性能和正确率分别提升了284%以及降低了30%;
(3) 轻量级主干结构的性能最好,目前实验表明了如果能解决AP指标低的问题,将具有非常大的前景。

图7 本文所提出的轻量级主干网络与现有的 网络性能指标对比Fig.7 Comparison of the performance indicators of the proposed lightweight backbone network and existing networks
当使用不同的主干网络作为主要提取网络时,实验对比及结果如表4和图7所示。

表4 使用编解码结构的实验对比

图8 使用编解码结构(Codec)前后的性能AP对比结果Fig.8 AP comparison of performance before and after using Codec
由表4和图7可以看出:
(1) 添加编解码结构(Codec)后,对所有不同的主干结构都有促进作用,证明了基于特征融合的Codec能够有效的促进性能;
(2) 对比轻量级主干结构以及其他的开源网络,能够发现,使用轻量级的主干结构提升最为明显,而且平均每张耗时最低。
表5和图9展示了在使用了Codec的情况下,并且使用MSLM模块的对比结果,其中训练基础是使用训练好的不包含MSLM模块的网络权重初始化并固化,仅仅训练MSLM内的权重,这样能够更直观的展示MSLM的作用。

表5 使用MSLM的实验对比

图9 对比使用MSLM的性能与AP对比结果Fig.9 Comparison of the performance and AP when using MSLM
总的来说,表5实验证明了本文提出的轻量级的主干网络搭配编解码结构(Codec)以及MSLM模块相比使用其他模块作为主干结构提升更加明显,并且本身由于编解码结构(Codec)具有类似金字塔模块的特征融合效果,因此效果更好,而性能也更优,虽然AP降低了1%,但是FPS相比于其他网络都有显著提升。
本文还做了一组消融实验来探究网络中各个子模块带来的性能提升,实验对比和结果如表6和图10所示 。

表6 CSDNet网络的各个子模块对比实验

图10 Codec,MSLM的消融实验对比Fig.10 Comparison of Codec and MSLM ablation experiments
由表6和图10可以看出:(1) 主干结构使用了本文所设计的轻量级网络作为主干结构,单独使用Codec在性能上以及正确率上相对轻量级主干结构分别降低了40%以及提升了37%;单独使用MSLM在性能以及正确率上分别降低了12%以及提升了4%;一起使用2个模块相比原始的网络,FPS降低了54%,但是正确率提升了40%;
(2) 一起使用2个模块相比原始的ResNet,VggNet,MobileNet,FPS分别提升了125%,108%,36%,正确率分别提高了0.6%,-0.7%,5.2%;
(3) 和同样加入了Codec和MSLM的ResNet,VggNet,MobileNet相比正确率大致相同,但是性能分别提升了170%,140%,72%,证明了本文所设计的轻量级网络的有效性。
4 结束语
本文使用深度可分离卷积作为人体关键点检测网络的基本模块,并融合了多维自学习模块,首次提出使用编解码的形式设计人体关键点检测网络。在COCO数据集上的实验结果表明,相较于传统网络(如ResNet、VggNet和MobileNet),深度可分离卷积模块显著提升了网络性能,但AP指标有明显下降;通过结合编解码结构和多维自学习模块,FPS相比于其他网络仍有显著提升且AP指标仅下降约1%,证明了本文所设计轻量级网络的有效性。
猜你喜欢
建材发展导向(2022年3期)2022-04-19
广东教育·高中(2022年1期)2022-03-16
西北园艺(果树)(2021年2期)2021-11-30
今日农业(2021年8期)2021-11-28
建材发展导向(2021年11期)2021-07-28
传播与制作(2019年9期)2019-10-20
民用飞机设计与研究(2019年2期)2019-08-05
科技与创新(2016年5期)2016-03-17
新高考·高一物理(2015年5期)2015-08-18
中学理科·综合版(2008年3期)2008-03-07
